系列文章目录
文章目录
一、SDS
动态字符串(SDS):Redis 未直接使用 C 语言的原生字符串,而是自定义了 SDS 结构,包含长度字段、空闲空间字段和字符数组。
优势:O (1) 时间复杂度获取长度、避免缓冲区溢出、减少字符串修改时的内存重分配次数(预分配机制)。
二、IntSet

是set集合的一种实现方式,基于整数数组实现,并且具备长度可变,有序等特性
为了方便查找,redis会将intset中所有的整数按照升序依次保存在contents数组中
c
typedef struct intset{
uint32_t encoding;
uint32_t length;//元素个数
int8_t contents[];//整数数组,保存集合数据
}intset;三、Dict

由三部分组成:哈希表,哈希节点,字典
c
字典本身数据结构
typedef struct dict{
dictType *type;//dict类型
void *privdata;//私有数据,在做特殊hash运算时使用
dictht ht[2]//一个Dict包含两个哈希表,其中一个是当前数据,另一个一般是空,rehash使用
long rehashidx;//rehash进度,-1表示未进行
int16_t pauserehash;//rehash是否暂停,1暂停,0继续
}
typedef struct dictht{
//entry数组,数组中保存的是指向entry的指针
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小的掩码
unsigned long sizemask;
//entry个数
unsigned long used;
}dictht;
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_t u64;
int64_t s64;
double d;
}v;//值
struct dictEntry *nect;//下一个entry的指针
}disctentry
向dict添加键值对时,redis首先根据key计算hash值,然后利用h&sizemask计算元素应该存储到数组中的哪个索引位置, 新元素永远在链表的队首rehash
dict中的hashtable就是数组结合单向链表的实现,当集合中元素过多,必然导致哈希冲突多,链表过长,查询缓慢,所以要扩容
dict在每次新增检查负载因子,触发扩容:
负载因子>=1, 并且服务器没有执行bgsave等后台进程
负载因子>5
c
/* 检查是否dict需要扩容 */
static int _dictExpandIfNeeded(dict *d)
{
/* 已经在渐进式hash的流程中了,直接返回 */
if (dictIsRehashing(d)) return DICT_OK;
/* 如果哈希表为空,则初始化哈希表:默认大小4 */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* 当配置了可扩容时,容量负载达到100%就扩容。配置不可扩容时,负载达到5也会强制扩容*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d))
{
//扩容大小为used+1, 底层会对扩容大小做判断,实际上找的是第一个大于等于used+1的2^n
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}每次删除元素时,也会对负载因子做检查,当负载因子<0.1,rehash
所以,不管是扩容还是收缩,必定会创建新的哈希表,因此必须对哈希表的每一个key重新计算索引,插入新的哈希表,这个过程叫rehash,过程是
计算新的hash表的realeSize, 这个值取决于当前是扩容还是收缩
如果是扩容,新size为第一个大于等于dict.ht[0].used+1的2^n
如果是收缩,新size为第一个大于等于dict.ht[0].used的2^n按照新的size申请内存空间,创建dictht, 并赋值给dict.ht1
设置dict.rehashidx=0, 标示开始rehash
将dict.ht0中的每一个dictEntry都rehash到dict.ht1
将dict.ht1赋值给dict.ht0, 给dict.ht1初始化为空的哈希表,释放原来的dict.ht0的内存
渐进式rehash
dict的rehash并不是一次性完成,因为数据量特别大时,rehash极有可能导致主线程阻塞,dict 的rehash是渐进式的,分多次完成
计算新的hash表size
计算新的hash表的realeSize, 这个值取决于当前是扩容还是收缩
如果是扩容,新size为第一个大于等于dict.ht[0].used+1的2^n
如果是收缩,新size为第一个大于等于dict.ht[0].used的2^n按照新的size申请内存空间,创建dictht, 并赋值给dict.ht1
设置dict.rehashidx=0, 标示开始rehash(原来dict.rehashidx=-1)
每一次执行增删改查,都检查一下dict.rehasidx是否大于-1, 如果是则将dict.ht0.tablerehashidx的entry链表rehash到dict.ht1,并且将rehashidx++, 直到dict.ht0的所有数据都rehash到dict.ht1
将dict.ht1赋值给dict.ht0, 给dict.ht1初始化为空的哈希表,释放原来的dict.ht0的内存
将rehashidx赋值为-1,代表rehash结束
在rehash过程中,新增操作,直接写入ht1,查询,修改,删除会在ht0,ht1,依次查找并执行,可以确保ht0的数据只减不增。随着rehash最终为空。
四、SkipList
元素按照升序排列存储
查找中间元素高效,节点可能包含多个指针,指针跨度不同
最多允许32级指针,也就允许存放最多2^32个数
五、RedisObject
c
typedef struct redisObject{
unsigned type:4
unsigned encoding:4
unsigned lru: LRU_BITS;//表示该对象最后一次被访问的时间,占用24bits
int refcount;
void *ptr;
} robj六、数据类型
1、string
底层基于SDS实现的
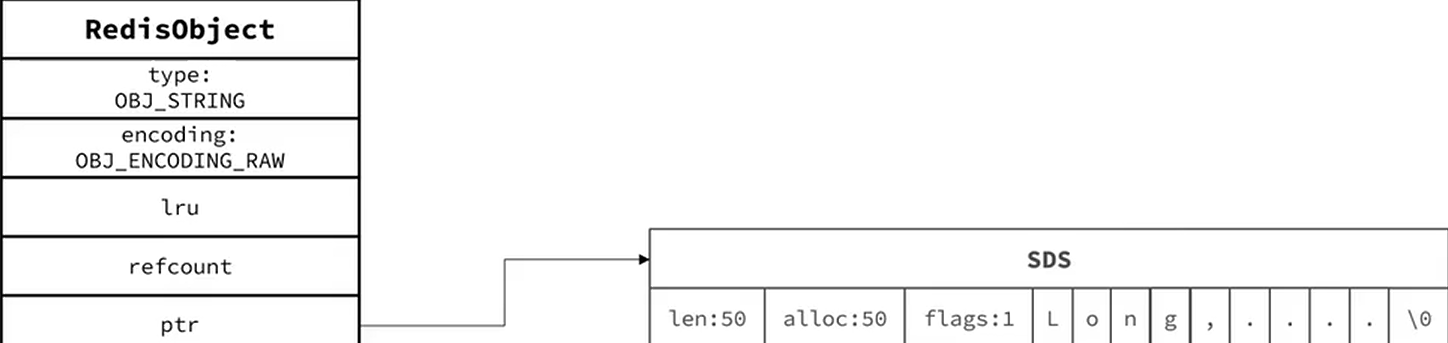
如果存储的SDS长度小于44字节,采用embstr编码,head和sds是一段连续空间,申请内存只需要调用一次内存分配函数

2、List
quickList:LinkedList+zipList, 可以从双端访问,内存占用较低,包含多个ziplist,存储上限高
3、set
不保证有序,保证元素唯一,求交并差集, 底层是基于hashTable,也就是redis的dict, key存储元素,value统一为null
4、zset
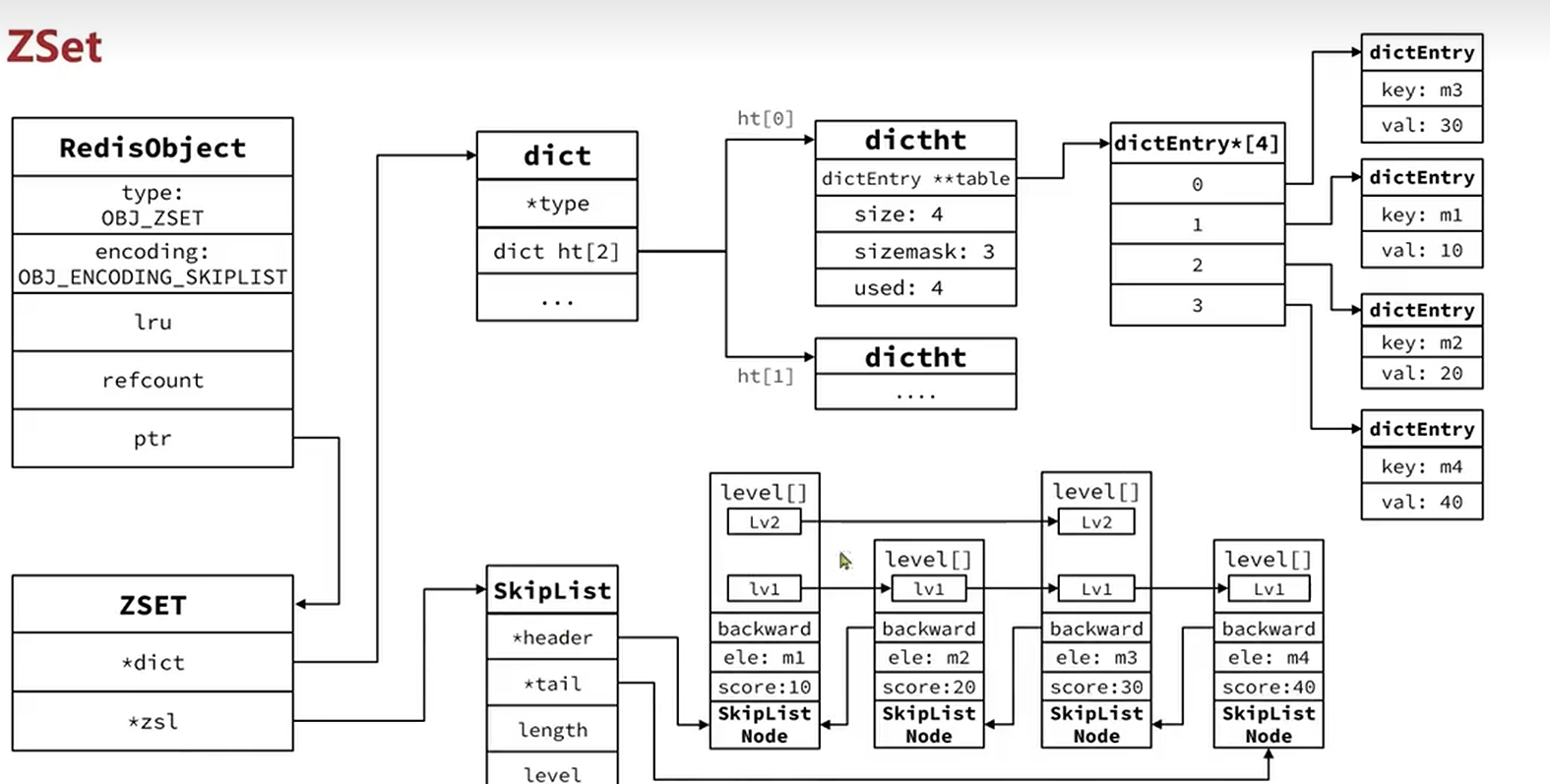
可排序集合,每一个元素都需要指定一个score和member
可以根据score值排序
member必须唯一
可根据member查分数

1. 压缩列表(ziplist)
当 ZSet 满足以下两个条件时,底层会使用压缩列表:
元素数量较少(默认阈值 zset-max-ziplist-entries 为 128);
每个元素的成员(member)长度较短(默认阈值 zset-max-ziplist-value 为 64 字节)。
压缩列表是一种连续内存的紧凑结构,ZSet 的元素按「分值(score)从小到大」顺序存储,每个元素以「member + score」的形式连续排列;
无需额外指针维护顺序,通过编码长度和偏移量定位元素,内存利用率极高,但修改(插入 / 删除)时可能需要移动大量数据,效率较低。
2. 跳表(skiplist) + 哈希表(hashtable)
当 ZSet 元素数量或成员长度超过上述阈值时,底层会自动转换为「跳表 + 哈希表」的组合结构:
跳表(skiplist):
核心作用是按分值排序并支持快速范围查询(如 ZRANGEBYSCORE);
本质是多层有序链表,通过随机层级的方式实现 O (logN) 复杂度的插入、删除和范围查询;
每个节点包含 member、score 以及多个指向其他节点的指针(用于不同层级的跳跃)。
哈希表(hashtable):
核心作用是快速查询 member 对应的 score(如 ZSCORE 命令);
以 member 为 Key,score 为 Value,实现 O (1) 复杂度的查找和更新。
c
zset范围查找案例
# 添加元素:格式为 ZADD key score member [score member ...]
# 这里创建一个名为 "student_scores" 的 ZSet,存储学生分数
redis-cli> ZADD student_scores 85 "Alice" 92 "Bob" 78 "Charlie" 95 "David" 88 "Eve" 72 "Frank"
(integer) 6 # 成功添加6个元素
# 示例1:查询排名第0到第2的元素(升序,即分数最低的3人)
redis-cli> ZRANGE student_scores 0 2
1) "Frank" # 72分(最低)
2) "Charlie" # 78分
3) "Alice" # 85分
# 示例2:查询所有元素(0到-1表示全部),并显示分数
redis-cli> ZRANGE student_scores 0 -1 WITHSCORES
1) "Frank"
2) "72"
3) "Charlie"
4) "78"
5) "Alice"
6) "85"
7) "Eve"
8) "88"
9) "Bob"
10) "92"
11) "David"
12) "95"
# 示例:查询分数最高的2人(降序排名0到1)
redis-cli> ZREVRANGE student_scores 0 1 WITHSCORES
1) "David"
2) "95"
3) "Bob"
4) "92"
# 示例1:查询分数在80到90之间的学生(闭区间)
redis-cli> ZRANGEBYSCORE student_scores 80 90 WITHSCORES
1) "Alice"
2) "85"
3) "Eve"
4) "88"
# 示例2:查询分数大于80且小于等于90的学生(开区间+闭区间)
redis-cli> ZRANGEBYSCORE student_scores (80 90 WITHSCORES
1) "Alice" # 85 > 80
2) "85"
3) "Eve" # 88 ≤ 90
4) "88"
# 示例3:查询所有分数的学生,从第2个开始取2个(分页)
redis-cli> ZRANGEBYSCORE student_scores -inf +inf LIMIT 2 2
1) "Alice"
2) "Eve"
# 删除排名0到1的元素(升序,即分数最低的2人:Frank和Charlie)
redis-cli> ZREMRANGEBYRANK student_scores 0 1
(integer) 2 # 成功删除2个元素
# 验证结果
redis-cli> ZRANGE student_scores 0 -1
1) "Alice"
2) "Eve"
3) "Bob"
4) "David"5、hash
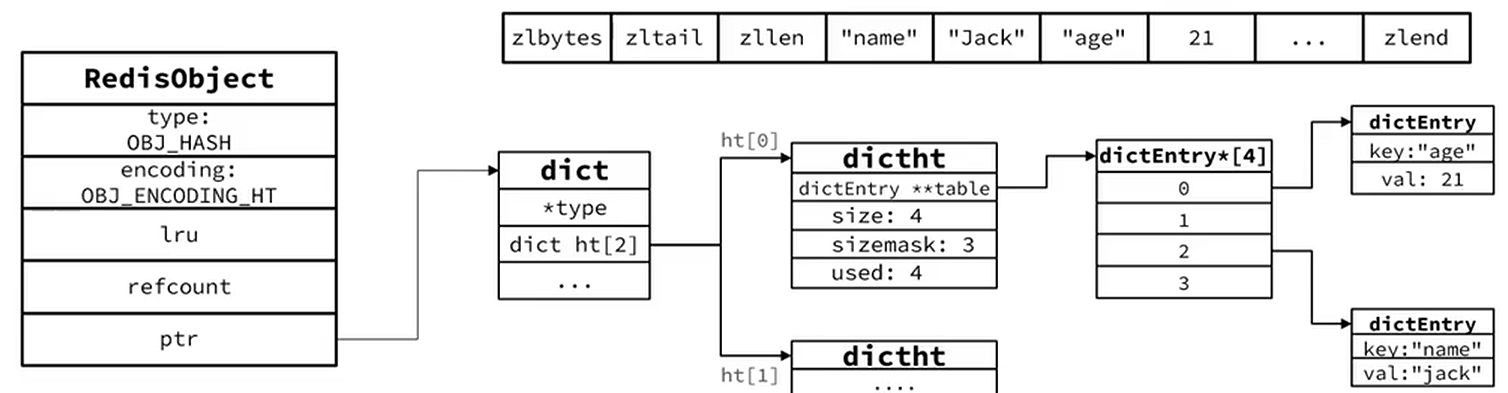
1. 压缩列表(ziplist)
当 Hash 满足以下两个条件时,底层会使用压缩列表:
键值对数量较少:默认阈值由配置 hash-max-ziplist-entries 控制(默认值为 512);
键和值的长度较短:默认阈值由配置 hash-max-ziplist-value 控制(默认值为 64 字节)。
结构特点:
压缩列表是一种连续内存的紧凑结构,Hash 的键值对按「key1 + value1 + key2 + value2 + ...」的顺序依次存储;
无需额外指针维护结构,通过编码长度和偏移量定位键值对,内存利用率极高;
但修改(插入 / 删除)时可能需要移动大量数据,适合小规模数据。 2. 哈希表(hashtable)
当 Hash 中的键值对数量或键 / 值长度超过上述阈值时,底层会自动转换为哈希表(类似 Java HashMap 中的 HashMap)。
结构特点:
由「数组 + 链表」组成(Redis 6.0+ 中链表过长时会转为红黑树);
通过哈希函数计算键的哈希值,映射到数组下标,解决哈希冲突时使用链表(或红黑树);
支持动态扩容(负载因子 > 1 时翻倍),适合大规模数据,插入、查询、删除的平均时间复杂度为 O (1)。3. hsetCommand
c
void hsetCommand(client *c){//hset user1 name jack age 21
int i, created=0
robj *o;
//判断hash的key是否存在,不存在创建一个新的,默认采用ziplist编码
if((o=hashTypeLookupWriteOrCreate(c,c->argv[1]))==NULL)return
//判断是否需要把ziplist转为dict
hashTypeConversion(o,c->argv,2,c->argc-1)
//循环遍历每一对field和value,并执行hset命令
for(i=2;2<c->argc;i+=2)
create+=!hashTypeSet()...
}