作者:SkyXZ
CSDN:SkyXZ~-CSDN博客
博客园:SkyXZ - 博客园
PS:网页端用不明白...还是SDK方便...
一、SageMaker介绍
Amazon SageMaker 是 AWS 提供的全托管机器学习平台,它覆盖了从数据准备、模型训练、超参数调优到模型部署的完整流程,我们可以通过 SageMaker,轻松创建 Notebook 实例进行数据探索和实验,也可以使用AWS的计算资源在云端快速训练大规模模型,无需管理底层服务器或集群。同时SageMaker 默认支持多种框架(如 TensorFlow、PyTorch、MXNet)和自定义容器,方便我们在熟悉的环境中进行深度学习开发,甚至对于需要快速验证模型或进行端到端部署的场景,SageMaker 提供了托管推理服务,让训练好的模型可以立即通过 API 被应用调用,虽然 SageMaker 提供了全流程可视化的网页开发,但是作为资深"调库码农",让我一下子使用网页反而有点不习惯,因此我们今天主要介绍AWS的boto3这个库,使用这个库提供的接口来完成训练全流程,以下是boto3库的官方文档:
- boto3文档:https://boto3.amazonaws.com/v1/documentation/api/latest/guide/quickstart.html#installation
- AWS SageMaker:https://us-west-2.console.aws.amazon.com/sagemaker/

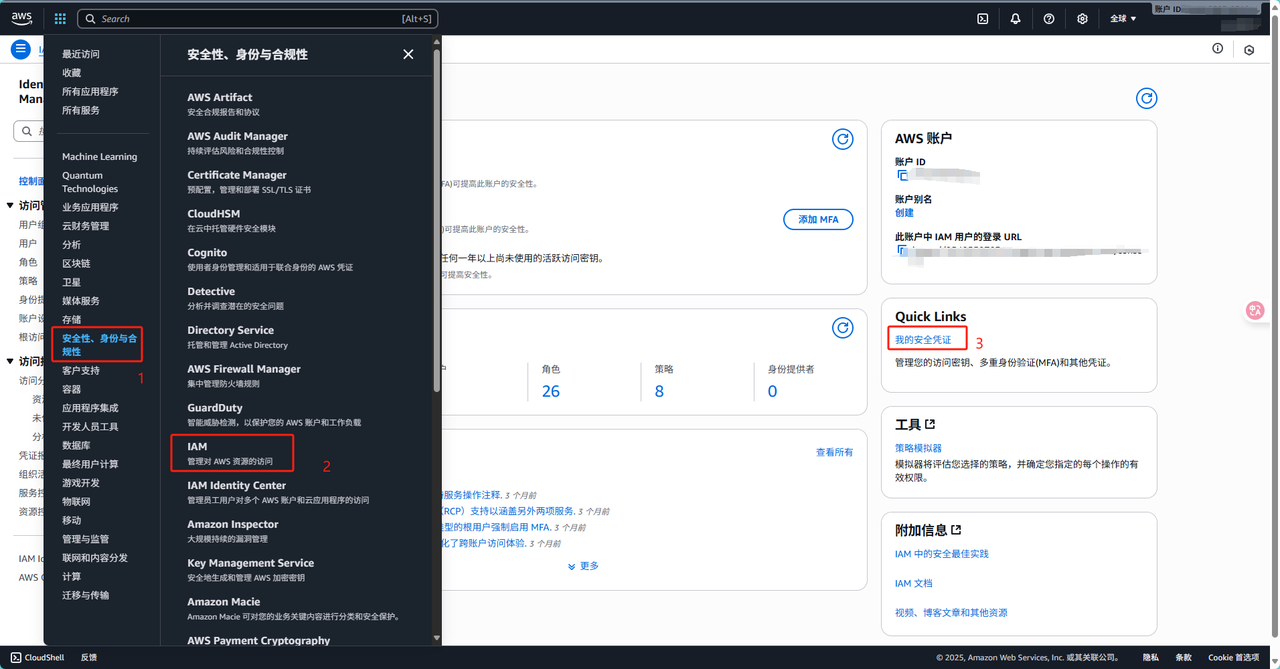
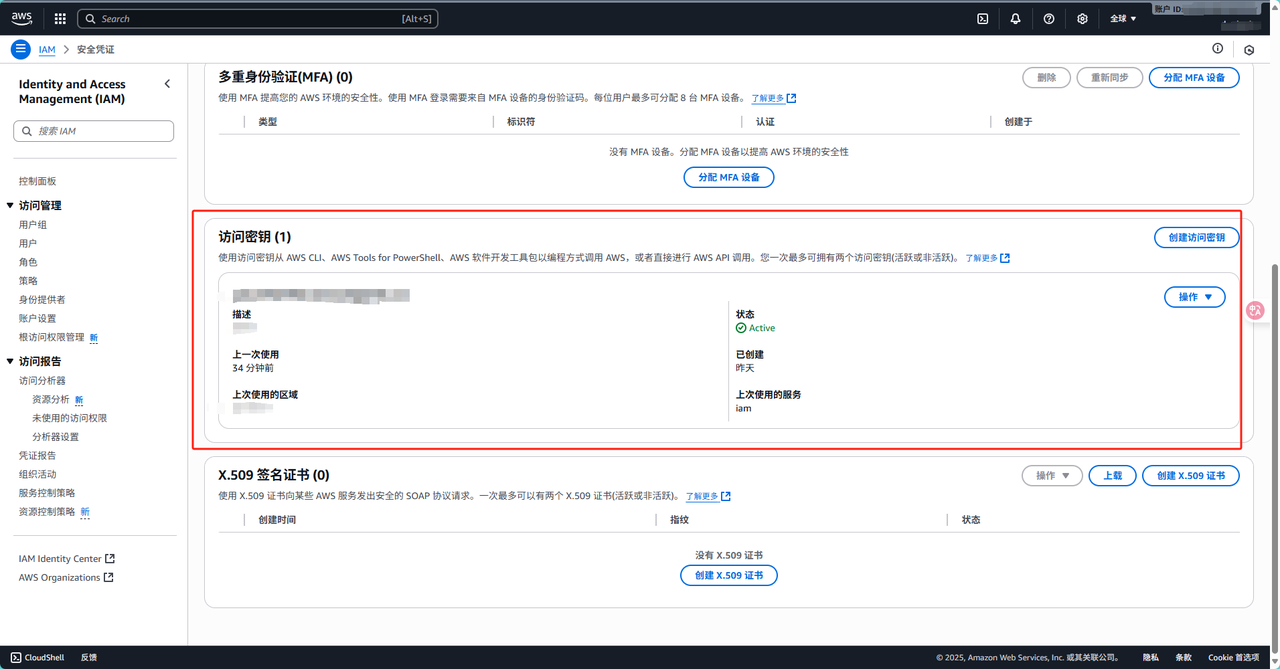
在动手介绍 SageMaker 的接口之前,咱们先得把本地的 AWS CLI 配置好,通过 AWS CLI,我们能安全地管理 AWS 账号的访问权限、设置默认区域w和输出格式,同时让 boto3 能顺利地访问 SageMaker、S3 等服务,我们首先在AWS的控制台左上角服务里面找到"安全性、身份与合规性",再进入IAM的服务控制台,点击进入后找到右边的"我的安全凭证"申请一个访问凭证即可
然后我们再环境中下载AWS CLI,具体命令如下,Mac上的HomeBrew下载可以参考我的另一篇文章:Mac上HomeBrew安装及换源教程
bash
# MacOS
brew install awscli
# Ubuntu
sudo apt install awscli -y接着我们在终端中输入aws configure后按照提示配置好即可

二、SageMaker-API用例
AWS 的 boto3 库功能非常强大,它不仅提供了 SageMaker、S3 Bucket 的接口,还涵盖了 AWS 上几乎所有服务的底层接口和高层封装,为 SageMaker 提供了完整的 API 支持。因此,今天我们将聚焦几个在实际使用中最常用的 API 接口,通过示例演示如何快速完成从数据上传、训练启动,到模型部署与推理的基本流程,让你能够用 Python 脚本高效管理整个机器学习任务,而在 boto3 中,每一个 AWS 服务都会对应一个独立的 客户端(client) ,这些客户端就是我们与 AWS 服务交互的入口,所有的 API 调用(比如上传文件到 S3、启动 SageMaker 训练任务、创建 IAM 角色等)都需要通过对应的客户端来完成,相比于 AWS 控制台点点点的操作方式,使用 boto3 让整个流程变得可编程和自动化:
- 数据层 :使用
s3客户端上传训练数据或下载模型结果; - 权限层 :通过
iam客户端管理角色和策略,保证任务安全合规; - 训练层 :用
sagemaker客户端一键启动训练任务,指定镜像、参数和算力资源; - 部署层 :调用
sagemaker的 API 部署模型,生成 Endpoint 并完成在线推理。
Role角色
AWS的SageMarker进行训练需要用到一个Role的概念,这个Role(角色) 是一种临时授权机制,由于我们在训练的时候数据集一般储存在AWS的S3Bucket中也有可能需要训练时附加EC2服务,而使用角色可以赋予SageMaker访问其他 AWS 服务(如 S3、CloudWatch)的权限,当SageMaker运行训练任务时,它会以这个角色的身份去读取数据集、写入模型输出等操作,因此我们首先需要在IAM中创建一个SageMaker执行角色(Execution Role),并授予我们创建的这个角色AmazonS3FullAccess 以及 AmazonSageMakerFullAccess 等必要策略,有关Role的几个常见API如下:
查询当前账号下的所有Role
在 IAM 中,最直接的查询方式是调用 list_roles API,它可以返回当前账号下的角色信息。不过需要注意的是,list_roles 单次调用返回的结果数量有限,如果账号下的角色很多,就必须通过翻页机制才能拿到完整列表,因此我们更多的是使用boto3 提供的 get_paginator,这个API能够自动处理分页请求,帮我们逐页取回所有结果,而不需要手动拼接 Marker 或 NextToken 参数。通过 for page in paginator.paginate(),我们就能方便地遍历账号内的所有角色信息,非常适合在需要完整列出资源的场景下使用。
python
import boto3
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
iam = boto_sess.client('iam')
paginator = iam.get_paginator('list_roles')
for page in paginator.paginate():
for role in page['Roles']:
print(f"Role Name: {role['RoleName']}")
print(f" ARN: {role['Arn']}")
print(f" Create Date: {role['CreateDate']}")
print("-" * 60)
创建一个Role并附加策略
创建Role的时候我们更多可以通过 create_role API 在 IAM 中创建,在创建时我们需要指定 信任策略(Trust Policy) ,用于定义 SageMaker 等服务是否能够扮演该角色。随后,通过 attach_role_policy 为我们创建的角色附加访问其他服务的权限,例如 AmazonSageMakerFullAccess 和 AmazonS3FullAccess,以确保 SageMaker 在训练任务中能够正常读取 S3 数据、写入模型输出并调用相关服务;如果指定的角色已存在,可以使用 get_role 获取其信息,避免重复创建,最终,该脚本会返回角色的 ARN,供后续的 SageMaker 训练任务使用,常见的训练任务中我们可以附加的权限有:
-
AmazonS3FullAccess:允许读取和写入 S3 数据集、模型文件等;
-
AmazonSageMakerFullAccess:允许创建和管理 SageMaker 训练任务、模型和端点;
-
CloudWatchFullAccess:允许 SageMaker 将日志和指标写入 CloudWatch,方便监控与调试;
-
AmazonEC2ContainerRegistryFullAccess:允许 SageMaker 从 ECR 拉取自定义镜像;
-
AmazonDynamoDBFullAccess:在需要持久化实验元数据时提供数据库访问能力。
python
import boto3
import json
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
iam = boto_sess.client("iam")
role_name = "SkyXZ-Test-Role"
trust_policy = {
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "sagemaker.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}
try:
role = iam.create_role(
RoleName=role_name,
AssumeRolePolicyDocument=json.dumps(trust_policy),
Description="SageMaker execution role"
)
except iam.exceptions.EntityAlreadyExistsException:
role = iam.get_role(RoleName=role_name)
policies = [
"arn:aws:iam::aws:policy/AmazonSageMakerFullAccess",
"arn:aws:iam::aws:policy/AmazonS3FullAccess"
]
for p in policies:
iam.attach_role_policy(RoleName=role_name, PolicyArn=p)
print(f"Role Created: {role['Role']['Arn']}")
为已有的Role角色添加/删除策略
有时候我们会遇到之前创建 Role 时赋予的权限不足,如果再重新创建新的 Role 就显得有些冗余。此时,更推荐的方式是直接在现有的 Role 上 添加或移除策略 ,在 boto3 中,我们可以使用 attach_role_policy 来为指定的角色附加新的托管策略,也可以通过 detach_role_policy 将不需要的策略移除。这样不仅避免了重复创建角色的麻烦,还能在保持最小权限原则的同时,灵活调整 SageMaker 的访问范围。
python
import boto3
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
iam = boto_sess.client("iam")
role_name = "SkyXZ-Test-Role"
# 添加策略
iam.attach_role_policy(
RoleName=role_name,
PolicyArn="arn:aws:iam::aws:policy/CloudWatchFullAccess"
)
# 删除策略
iam.detach_role_policy(
RoleName=role_name,
PolicyArn="arn:aws:iam::aws:policy/AmazonS3FullAccess"
)
print(f"Updated policies for role: {role_name}")删除已有的Role角色
当我们需要删除一个Role角色的时候我们调用 delete_role API删除该角色,但是在删除Role角色前我们需要保证这个Role下面没有附加的策略,否则删除操作会失败,因此我们首先需要通过 get_role 检查指定的角色是否存在;如果存在,则使用 list_attached_role_policies 获取该角色上所有已附加的策略,并逐一调用 detach_role_policy 将它们移除;在策略全部解绑后,再调用 delete_role 删除该角色
python
import boto3
import json
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
iam = boto_sess.client("iam")
role_name = "SkyXZ-Test-Role"
try:
role = iam.get_role(RoleName=role_name)
print(f"Role Found: {role_name}")
print(f" ARN: {role['Role']['Arn']}")
attached_policies = iam.list_attached_role_policies(RoleName=role_name)
print(f"Found {len(attached_policies['AttachedPolicies'])} attached policies")
for policy in attached_policies['AttachedPolicies']:
policy_arn = policy['PolicyArn']
policy_name = policy['PolicyName']
print(f"Detaching policy: {policy_name}")
iam.detach_role_policy(RoleName=role_name, PolicyArn=policy_arn)
print(f"Deleting role: {role_name}")
iam.delete_role(RoleName=role_name)
print(f"Role {role_name} deleted successfully")
except iam.exceptions.NoSuchEntityException:
print(f"Role {role_name} does not exist")
except Exception as e:
print(f"Error: {e}")
S3Bucket
S3Bucket 是 AWS 提供的一种高可用、可扩展的对象存储服务,主要用于存放训练数据、模型文件以及其他资源。在使用 SageMaker 训练模型时,我们通常可以将本地的数据集上传到 S3,这样之后训练任务就可以直接从云端读取数据,实现端到端的云端训练流程。同时,S3 还支持版本管理、权限控制和跨区域复制等功能,使我们在管理数据和模型文件时更加灵活和安全,有关S3Bucket的几个常见API如下:
查询当前账号下的所有Bucket
在 AWS 中,我们可以通过 boto3 提供的 list_buckets API 查询当前账号下所有的 S3 Bucket,并结合 get_bucket_location 可以获取每个 Bucket 所在的区域信息,而通过 S3 Resource 对象遍历 Bucket 内的对象即可统计其存储大小,这样不仅可以快速查看账号下有哪些 Bucket,还能了解它们的区域分布和占用空间,方便在上传训练数据或管理模型文件时做出合理规划。
Python
import boto3
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
s3 = boto_sess.client('s3')
s3_res = boto_sess.resource('s3')
for bucket in s3.list_buckets()['Buckets']:
name = bucket['Name']
region = s3.get_bucket_location(Bucket=name).get('LocationConstraint')
size_mb = sum(obj.size for obj in s3_res.Bucket(name).objects.all()) / (1024*1024)
print(f"{name} | Region: {region} | Size: {size_mb:.2f} MB")

创建一个新的Bucket
如果当前账号下没有可用的存储桶,我们可以使用 create_bucket API 创建一个新的 S3 Bucket,在创建时需要指定 Bucket 的名称以及所在的区域(Region),以确保数据存储在预期的位置,创建完成后,这个 Bucket 就可以用来上传训练数据、存放模型文件或保存其他资源,为 SageMaker 的训练和推理任务提供云端存储支持。
Python
import boto3
import os
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = 'skyxz-test-bucket-2025'
s3.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={'LocationConstraint': 'Region'}
)
print(f"S3 Bucket {bucket_name} Created")上传文件到Bucket
创建好 S3 Bucket 后,我们就可以将本地的数据集或资源上传到云端,以便 SageMaker 训练任务直接读取,在下述示例中,我们使用 os.walk 遍历本地目录下的所有文件,并通过 upload_file 将每个文件上传到指定的 Bucket 和路径(Key)下,在这段代码中我还通过设置了一个合适的前缀(Prefix),来在 S3 中组织文件结构,使数据管理更清晰
Python
import boto3, os
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = 'your-bucket'
local_dir = './my_local_dataset'
s3_prefix = 'lerobot-data/'
for root, dirs, files in os.walk(local_dir):
for file in files:
local_path = os.path.join(root, file)
relative_path = os.path.relpath(local_path, local_dir)
s3_key = os.path.join(s3_prefix, relative_path).replace("\\", "/")
s3.upload_file(local_path, bucket_name, s3_key)
print(f"Success: {local_path} → s3://{bucket_name}/{s3_key}")
列出Bucket中的所有文件
仅知道 S3 中有哪些 Bucket 并不足以管理数据,我们通常还需要查看每个 Bucket 内具体存放了哪些文件,我们可以通过 list_objects_v2 API 列出指定 Bucket 下符合前缀(Prefix)的所有对象,返回结果中包含每个对象的 Key(路径)、大小和最后修改时间,方便我们了解数据的结构和存储情况:
Python
import boto3
boto_sess = boto3.Session(
aws_access_key_id="AccessKeyId",
aws_secret_access_key="AccessKeySecret",
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = "skyxz-test-bucket-2025"
s3_prefix = "training-data"
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=s3_prefix)
if "Contents" in response:
for obj in response["Contents"]:
print(obj["Key"], obj["Size"], obj["LastModified"])
else:
print("No Found Files")
删除Bucket中的文件
在管理 S3 数据时,如果发现某个文件或文件夹不再需要,我们可以使用 delete_object API 将其删除,通过指定 Bucket 名称和文件的 Key,即可删除指定对象,这种方式适用于单个文件的删除,如果需要批量删除文件,则可以结合 list_objects_v2 获取 Key 列表后循环调用 delete_object 或使用 delete_objects 批量删除。
Python
import boto3
boto_sess = boto3.Session(
aws_access_key_id="AccessKeyId",
aws_secret_access_key="AccessKeySecret",
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = "skyxz-test-bucket-2025"
key_to_delete = "training-data/example.txt"
s3.delete_object(Bucket=bucket_name, Key=key_to_delete)
print(f"{key_to_delete} have been {bucket_name} deleted")删除S3Bucket存储桶
如果需要直接删除整个 Bucket,我们必须先清空桶内的所有文件,否则删除操作会失败,我们首先需要使用 list_objects_v2 列出 Bucket 内的所有对象,然后循环调用 delete_object 删除每个文件,最后再调用 delete_bucket 删除整个存储桶,这样可以安全、完整地移除不再使用的存储桶及其内容:
Python
import boto3
boto_sess = boto3.Session(
aws_access_key_id="AccessKeyId",
aws_secret_access_key="AccessKeySecret",
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = "skyxz-test-bucket-2025"
objects = s3.list_objects_v2(Bucket=bucket_name)
if 'Contents' in objects:
for obj in objects['Contents']:
s3.delete_object(Bucket=bucket_name, Key=obj['Key'])
s3.delete_bucket(Bucket=bucket_name)
print(f"{bucket_name} have been deleted")从Bucket中下载文件
在训练完成之后,我们通常需要将训练结果或模型文件下载到本地进行验证或部署,我们可以通过 list_objects_v2 获取指定前缀下的所有对象,然后使用 download_file 将每个文件下载到本地指定目录:
Python
import boto3, os
boto_sess = boto3.Session(
aws_access_key_id="AccessKeyId",
aws_secret_access_key="AccessKeySecret",
region_name="Region"
)
bucket = ""
prefix = ""
local_dir = "./output"
s3 = boto_sess.client("s3")
resp = s3.list_objects_v2(Bucket=bucket, Prefix=prefix)
for obj in resp.get("Contents", []):
key = obj["Key"]
if key.endswith("/"):
continue
local_path = os.path.join(local_dir, os.path.relpath(key, prefix))
os.makedirs(os.path.dirname(local_path), exist_ok=True)
s3.download_file(bucket, key, local_path)
print(f"Downloaded: {key} -> {local_path}")Notebook-Instance
我们也可以使用create_notebook_instance 来创建一个Notebook实例,同时等待实例创建完成之后获取这个示例的Url以及目前账户下的所有Notebook Instance实例,我们可以直接复制这个Url到浏览器即可直接打开创建的实例:
Python
import boto3
import time
role_arn = "arn:aws:iam::your-account-id:role/your-role-name"
boto_sess = boto3.Session(
aws_access_key_id="AccessKey",
aws_secret_access_key="SecretKey",
region_name="Region"
)
sagemaker_client = boto_sess.client("sagemaker")
notebook_name = "MyNotebookInstance-demo"
# 1. 创建 Notebook Instance
print(f"=== Create Notebook Instance: {notebook_name} ===")
try:
response = sagemaker_client.create_notebook_instance(
NotebookInstanceName=notebook_name,
InstanceType="ml.t3.medium",
RoleArn=role_arn,
DirectInternetAccess="Enabled",
VolumeSizeInGB=10,
Tags=[{"Key": "Project", "Value": "Demo"}],
)
print("Notebook Create Request Sent:", response["NotebookInstanceArn"])
except sagemaker_client.exceptions.ResourceInUse:
print("Notebook Already Exists, Skipping Creation.")
# 2. 等待 Notebook 启动
print("=== Waiting for Notebook to Start... ===")
while True:
desc = sagemaker_client.describe_notebook_instance(NotebookInstanceName=notebook_name)
status = desc["NotebookInstanceStatus"]
print(f"Current Status: {status}")
if status == "InService":
print("Notebook Started Successfully!")
break
elif status in ["Failed", "Deleting", "Stopped"]:
raise RuntimeError(f"Notebook Start Failed, Status: {status}")
time.sleep(30)
# 3. 获取 Notebook 的访问 URL
url = sagemaker_client.create_presigned_notebook_instance_url(
NotebookInstanceName=notebook_name
)
print("=== Notebook Access URL ===")
print(url["AuthorizedUrl"])
# 4. 列出当前所有 Notebook
print("\n=== Current Account's Notebook Instances ===")
instances = sagemaker_client.list_notebook_instances(MaxResults=20)
for nb in instances["NotebookInstances"]:
print(f"- {nb['NotebookInstanceName']} | Status: {nb['NotebookInstanceStatus']}")
三、SageMaker训练配置流程
AWS的训练可以直接由SageMaker的高级封装的SDKsagemaker发起并管理,在 sagemaker 库中,对于深度学习任务,我们通常使用 from sagemaker.pytorch import PyTorch 来快速启动 PyTorch 训练作业。这个模块提供了对 PyTorch 框架的封装,使我们可以直接指定训练脚本、超参数、实例类型和训练数据位置,SageMaker 会自动创建训练环境并执行训练,同时配合 from sagemaker.inputs import TrainingInput,我们可以灵活地定义训练数据的来源和格式,例如,可以指定 S3 路径、输入数据类型(如 File 或 Pipe)、是否使用分布式训练以及数据增强配置等。TrainingInput 使数据输入配置变得直观且可编程,能够无缝连接 S3 数据与训练作业,实现训练数据的高效管理。
这里展示了一个最基础的 SageMaker PyTorch 训练流程:我们用 TrainingInput 指定 S3 上的训练数据,用 boto3 创建 AWS 会话并通过 sagemaker.Session 管理交互,然后用 PyTorch Estimator 配置训练脚本、依赖、实例类型和角色,最后一行 estimator.fit 就能发起训练,SageMaker 会帮你自动处理环境搭建、资源调度和日志管理,让从数据准备到模型训练的整个流程变得简单又高效,同时还支持分布式训练和自动保存检查点,非常适合快速迭代和管理大规模训练任务。
Python
from sagemaker.pytorch import PyTorch
from sagemaker.inputs import TrainingInput
import boto3, sagemaker
# === 数据集路径 ===
dataset_input = TrainingInput(
"s3://your-bucket-name/",
distribution="FullyReplicated"
)
# === 创建 boto3 会话 ===
boto_sess = boto3.Session(
aws_access_key_id="AccessKeyId",
aws_secret_access_key="AccessKeySecret",
region_name="Region"
)
# === SageMaker 会话 ===
sess = sagemaker.Session(boto_session=boto_sess)
# === PyTorch 训练任务 ===
estimator = PyTorch(
entry_point="lerobot/train.py",
source_dir="/your-source-dir/",
dependencies=["lerobot/requirements.txt"],
role="your-role-arn",
instance_count=1,
instance_type="ml.m5.large",
framework_version="2.1",
py_version="py310",
sagemaker_session=sess,
)
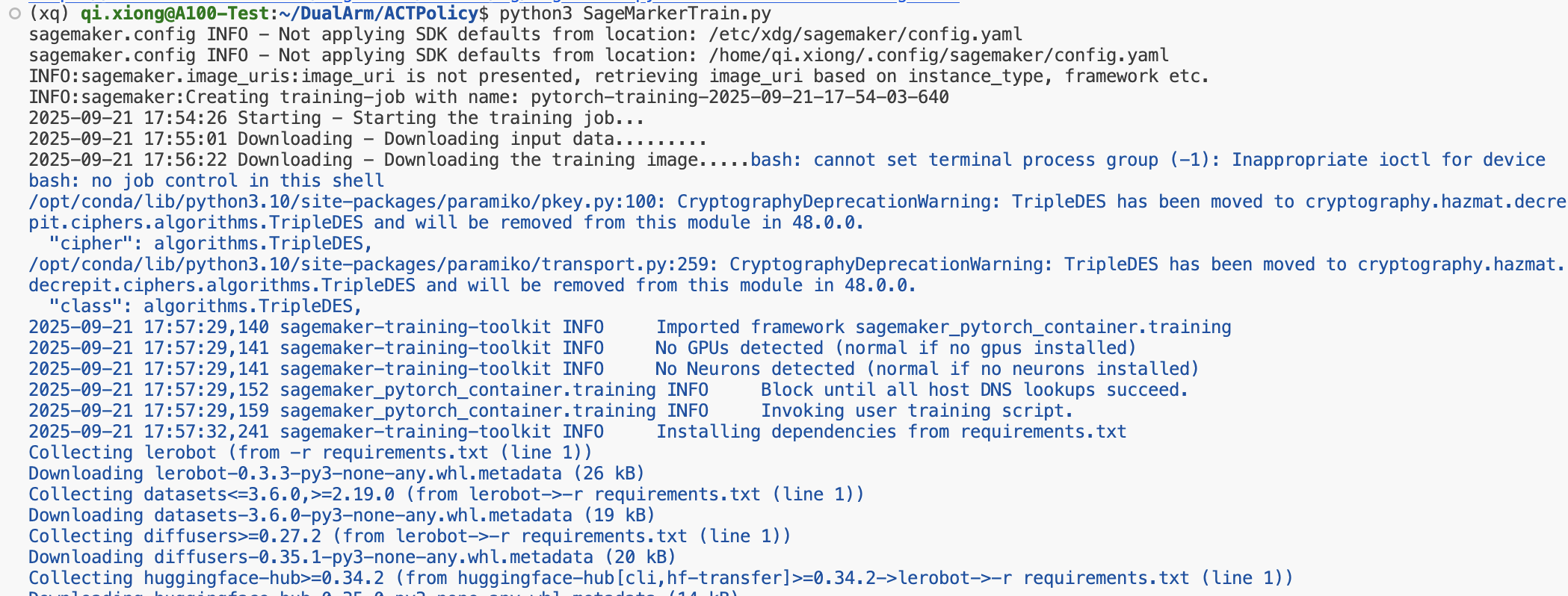
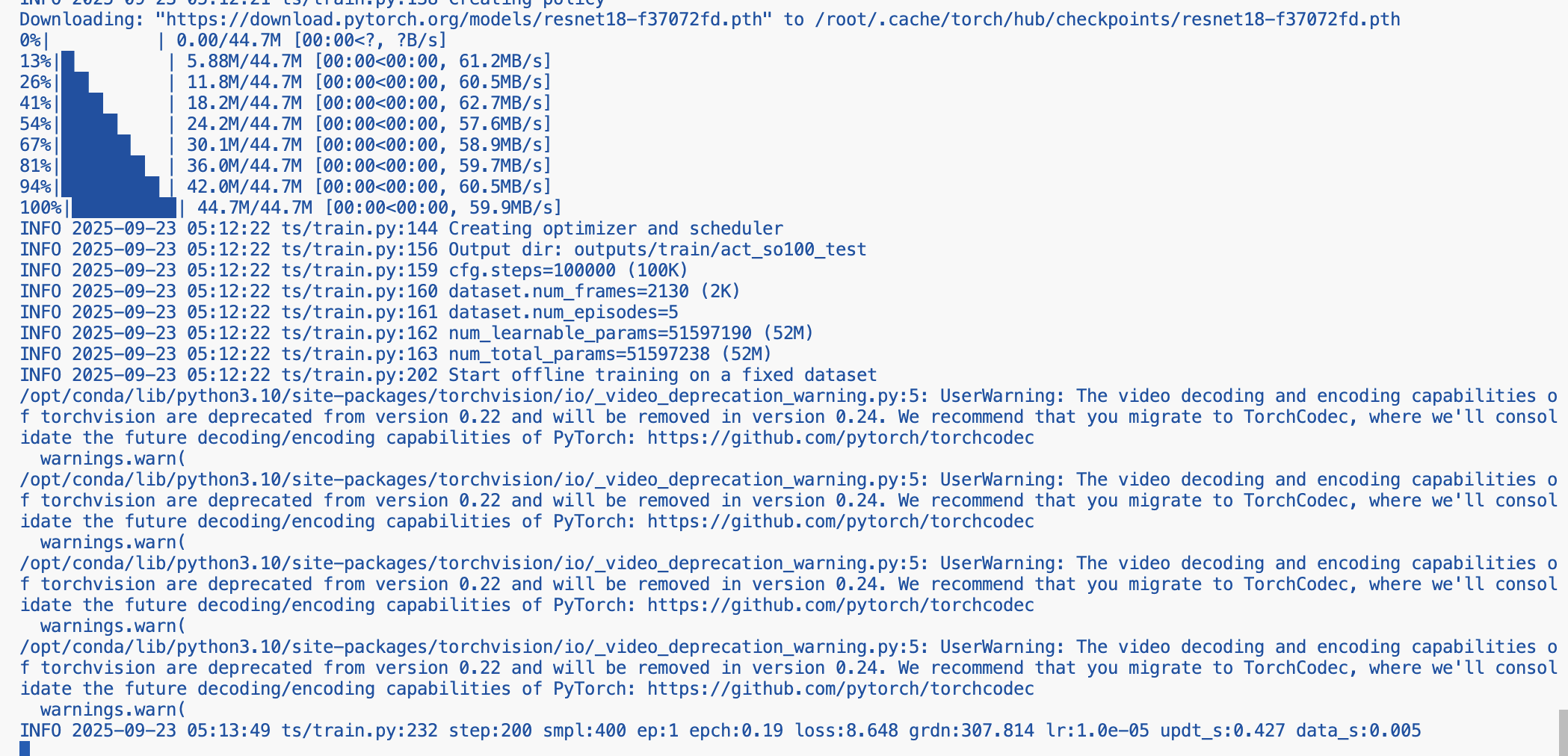
# === 发起训练 ===
estimator.fit({"dataset": dataset_input})需要注意的是,在 estimator = PyTorch() 中的 entry_point 只需要指向我们的训练脚本即可,而挂载的 S3 Bucket 会被 SageMaker 自动映射到训练实例上的 /opt/ml/input/data/dataset/ 目录下,这样训练脚本就可以直接读取数据,无需手动下载或配置路径,大大简化了训练环境的管理,出现以下输出即代表我们的配置没有问题,SageMaker正在帮我们托管训练ing.