点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月29日更新到: Java-136 深入浅出 MySQL Spring Boot @Transactional 使用指南:事务传播、隔离级别与异常回滚策略 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节完成了如下的内容:
- Flink 重要角色
- TaskManager
- ResourceManager
- 各个组件之间的关系
- Sink Task SubTask 等等内容

安装模式
Flink支持多种安装模式:
1. Local(本地)模式
- 定义:单机运行模式,适合开发和调试
- 特点 :
- 无需额外配置,开箱即用
- 只能在单个JVM进程中运行
- 支持本地IDE调试(如IntelliJ IDEA)
- 适用场景 :
- 本地开发测试
- 小规模数据验证
- 学习Flink基础功能
- 示例 :通过
bin/start-local.sh启动本地环境
2. Standalone独立模式
- 定义:Flink自带的集群管理方式
- 特点 :
- 需要手动部署和管理集群
- 包含JobManager和TaskManager
- 资源分配由Flink自身完成
- 优势 :
- 不依赖外部资源管理器
- 部署相对简单
- 适用场景 :
- 中小规模生产环境
- 对Hadoop生态依赖较少的场景
- 需要快速搭建Flink集群的情况
- 配置要点 :
- 需配置
flink-conf.yaml中的集群参数 - 需要设置TaskManager数量及资源分配
- 需配置
3. YARN模式
- 定义:基于Hadoop YARN的资源管理模式
- 特点 :
- 计算资源由YARN统一调度
- 支持动态资源分配
- 可与其他YARN应用共存
- 运行模式 :
- Session模式(长期运行集群)
- Per-Job模式(按作业分配资源)
- 优势 :
- 资源利用率高
- 与Hadoop生态无缝集成
- 适合大规模生产环境
- 适用场景 :
- 企业级大数据平台
- 需要与其他Hadoop组件协同工作的场景
- 资源需求波动的应用
- 配置要求 :
- 需要正确配置Hadoop环境
- 需设置YARN相关参数
- 通常需要配置高可用(HA)## Flink支持多种安装模式:
基础环境
基于我们之前的大数据的环境:
- JAVA_HOME 之前已经配好了
- SSH 免密登录 三台节点之间 之前也配置好了
集群规划
 我们对应的机器是:
我们对应的机器是:
- h121 2C4G
- h122 2C4G
- h123 2C2G
下载安装
选择的版本是:Flink 1.11.1 版本
shell
https://www.apache.org/dyn/closer.lua/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.12.tgz你也可以直接使用 wget 下载,目前我们登录到服务器 h121 节点上
shell
cd /opt/software/
wget https://archive.apache.org/dist/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.12.tgz等待下载完毕:  解压配置:
解压配置:
shell
tar -zxvf flink-1.11.1-bin-scala_2.12.tgz处理过程如下:  解压完成之后,移动到目录下:
解压完成之后,移动到目录下:
shell
mv flink-1.11.1 ../servers/
cd ../servers/
lsStandalone模式部署
上述我们已经完成了 h121 服务器节点的配置安装,接下来我们修改配置文件。 Standalone 模式是一种相对简单的 Flink 集群部署方式,适合在拥有固定资源的环境中运行 Flink 应用程序。与 YARN 或 Kubernetes 等资源管理平台不同,Standalone 模式完全由用户自行管理集群资源。
在这种模式下,所有的 Flink 组件(如 JobManager 和 TaskManager)都是手动配置和启动的:
- JobManager 作为集群的主节点,负责协调分布式执行、调度任务和故障恢复
- TaskManager 作为工作节点,负责执行具体的数据处理任务
- 用户需要手动配置每个节点的资源分配(如内存、CPU等)
典型的使用场景包括:
- 开发和测试环境
- 小规模生产环境
- 资源需求稳定的长期运行作业
优势在于部署简单,不需要额外的资源管理框架;但缺点是缺乏动态资源分配能力,当作业需求变化时需要人工干预调整资源配置。用户可以通过修改 conf/flink-conf.yaml 文件来配置集群参数,如并行度、内存分配等。
启动与配置
- 手动启动:在 Standalone 模式下,JobManager 和 TaskManager 需要通过脚本手动启动。可以通过 Flink 提供的启动脚本(如 start-cluster.sh)来启动整个集群,或者单独启动每个组件。
- 配置文件:Standalone 模式的配置主要通过 flink-conf.yaml 文件进行,配置内容包括 JobManager 和 TaskManager 的数量、内存和 CPU 资源、网络设置等。
flink-conf.yaml
shell
cd /opt/servers/flink-1.11.1/conf
vim flink-conf.yaml我们修改的内容有这么两处:
shell
jobmanager.rpc.address: h121.wzk.icu
taskmanager.numberOfTaskSlots: 2修改内容如下所示: 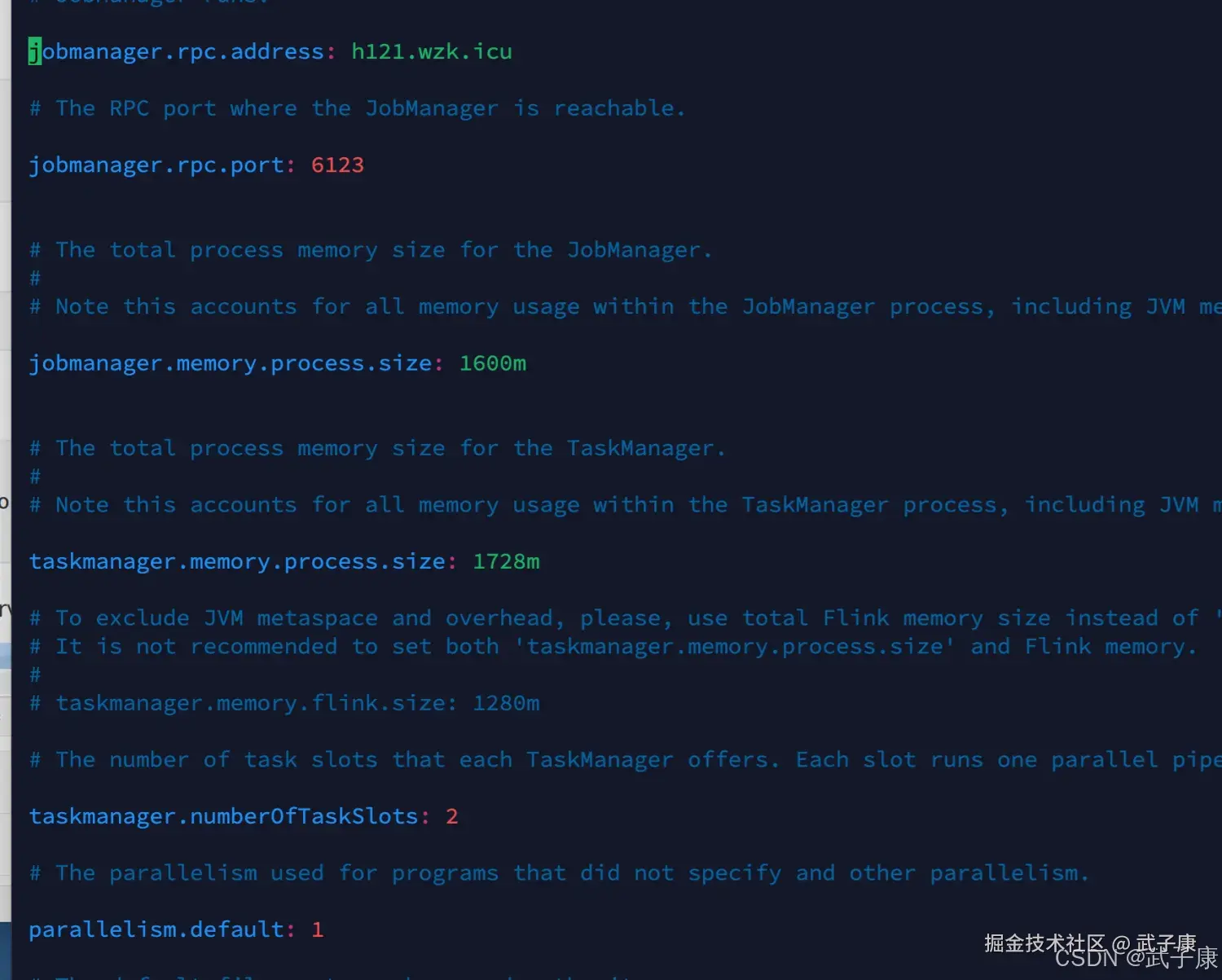
Works
不同的版本可能叫不同的名字,我这里是 works
shell
cd /opt/servers/flink-1.11.1/conf
vim workers写入如下的内容,我们有三台云节点:
shell
h121.wzk.icu
h122.wzk.icu
h123.wzk.icu写入的结果如下图所示: 
Master
shell
cd /opt/servers/flink-1.11.1/conf
vim masters写入如下的内容:
shell
h121.wzk.icu:8081写入的结果如下图: 
服务启动
暂时就可以先启动进行测试了:
shell
cd /opt/servers/flink-1.11.1/bin/
./start-cluster.sh启动过程如下所示: 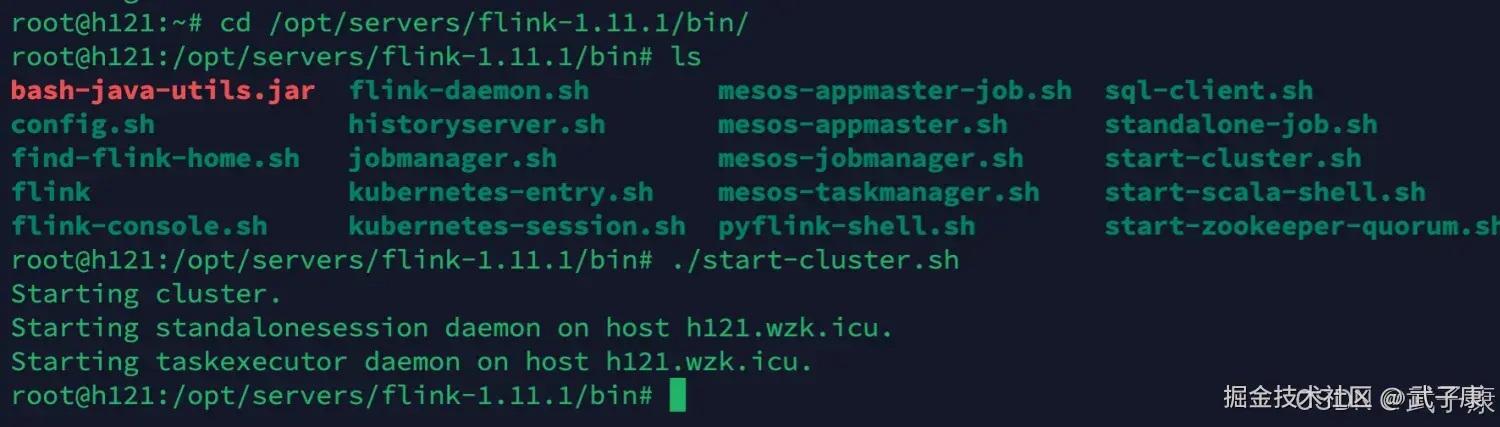
启动结果
这里要注意,由于我们之前配置过Spark环境,Spark的Web也是8081端口。 记得把Spark的服务停掉(暂时用不到Spark相关的内容了)。 启动后,我们访问:
shell
http://h121.wzk.icu:8081/#/overview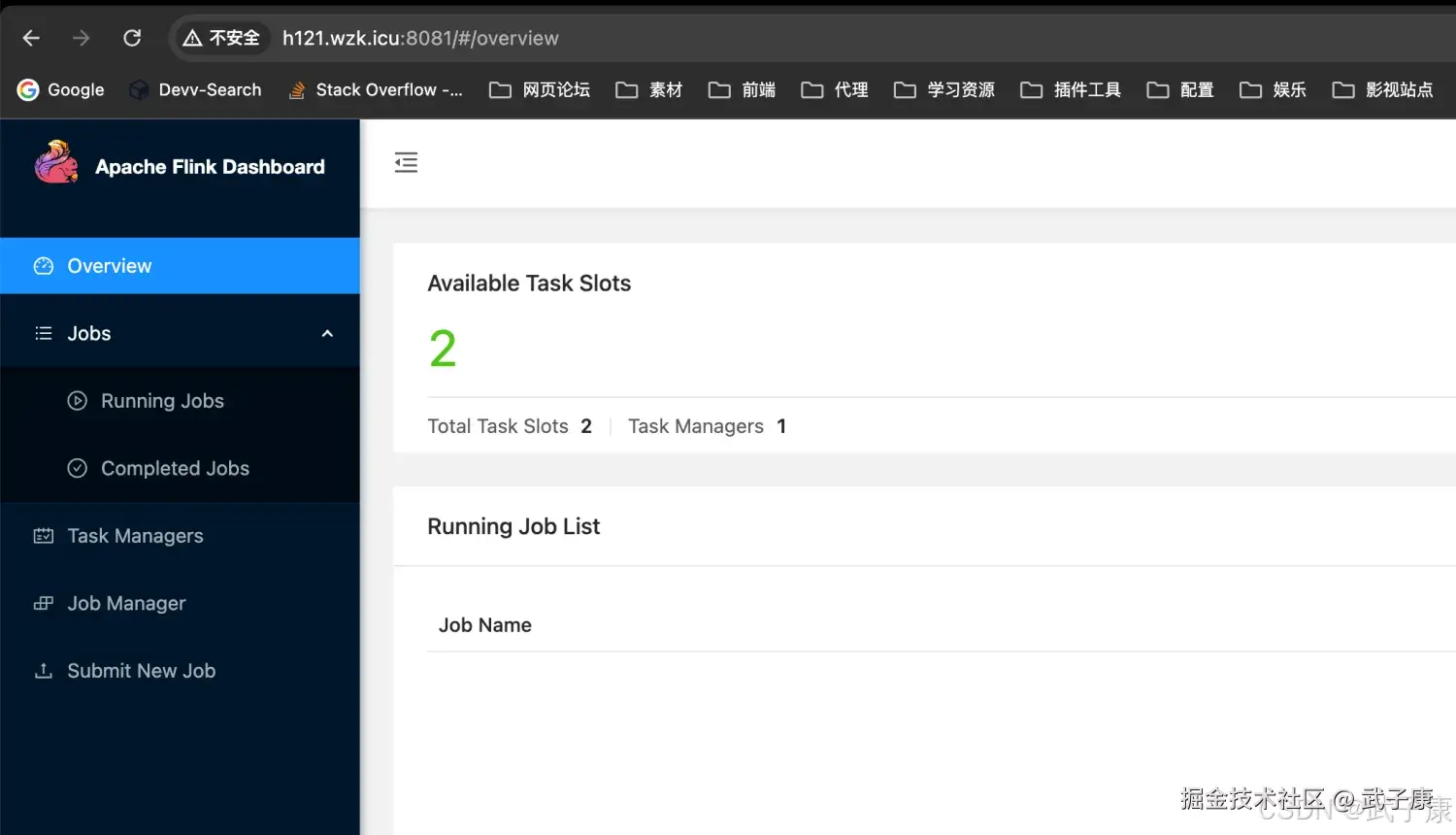 可以通过 JPS 命令查看主机当前的状态:(不需要的你可以停掉)
可以通过 JPS 命令查看主机当前的状态:(不需要的你可以停掉)
- Hadoop
- HDFS
- Flink
- 等等
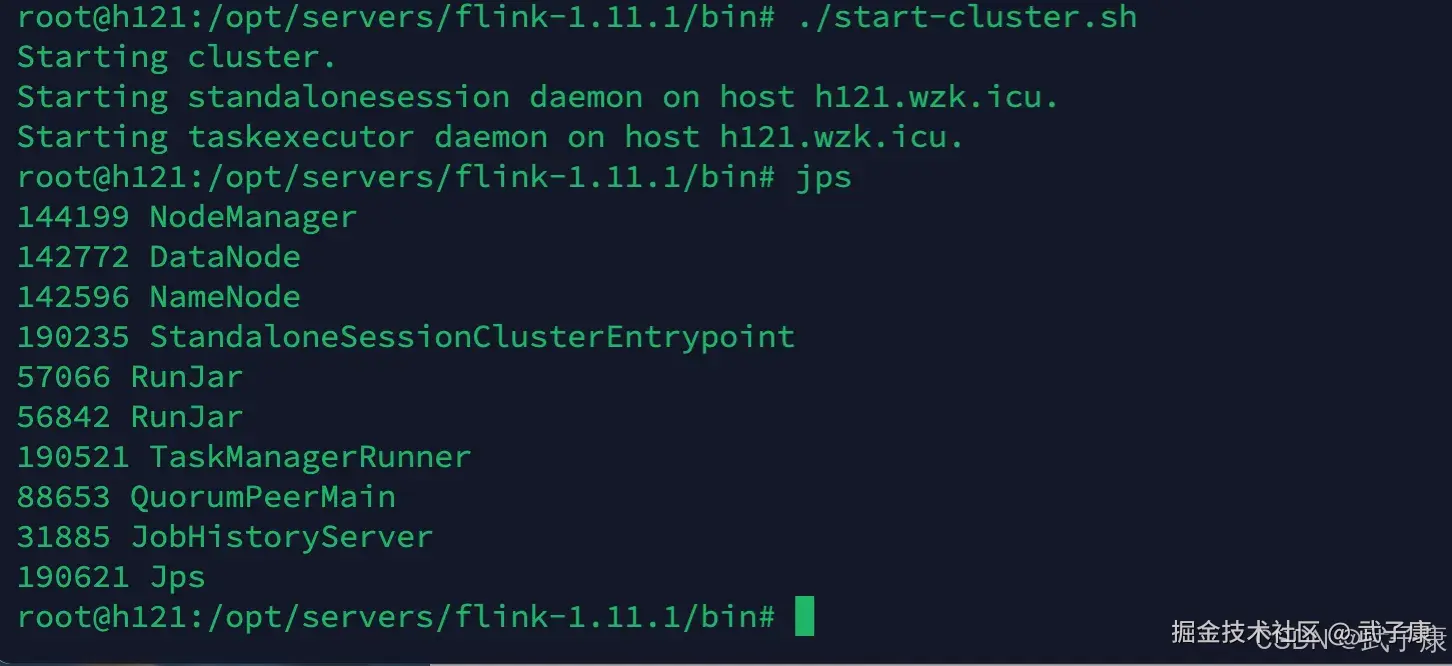
测试效果
官方提供的Demo,可以运行测试一下是否正常
shell
cd /opt/servers/flink-1.11.1/bin
./flink run ../examples/streaming/WordCount.jar执行结果如下图: 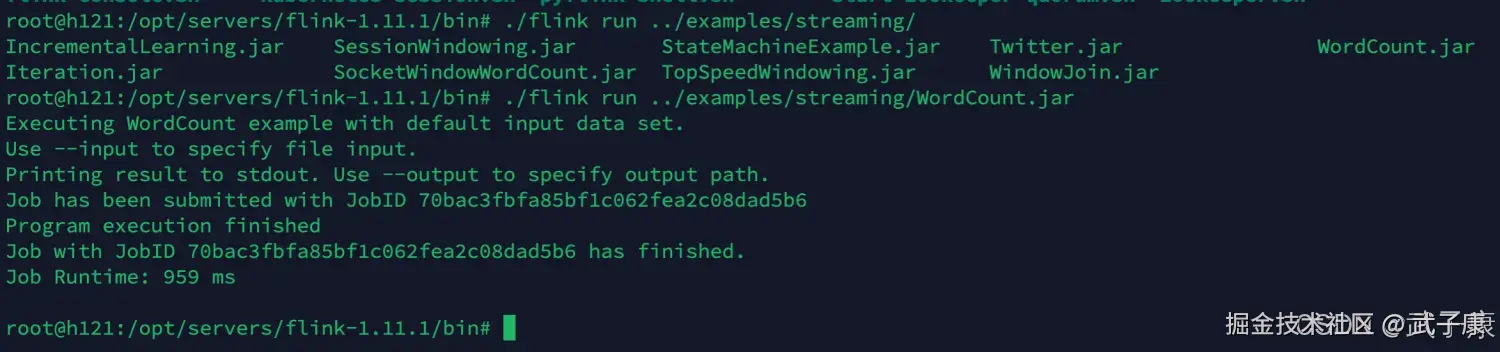 可视化的页面也可以看到:
可视化的页面也可以看到: 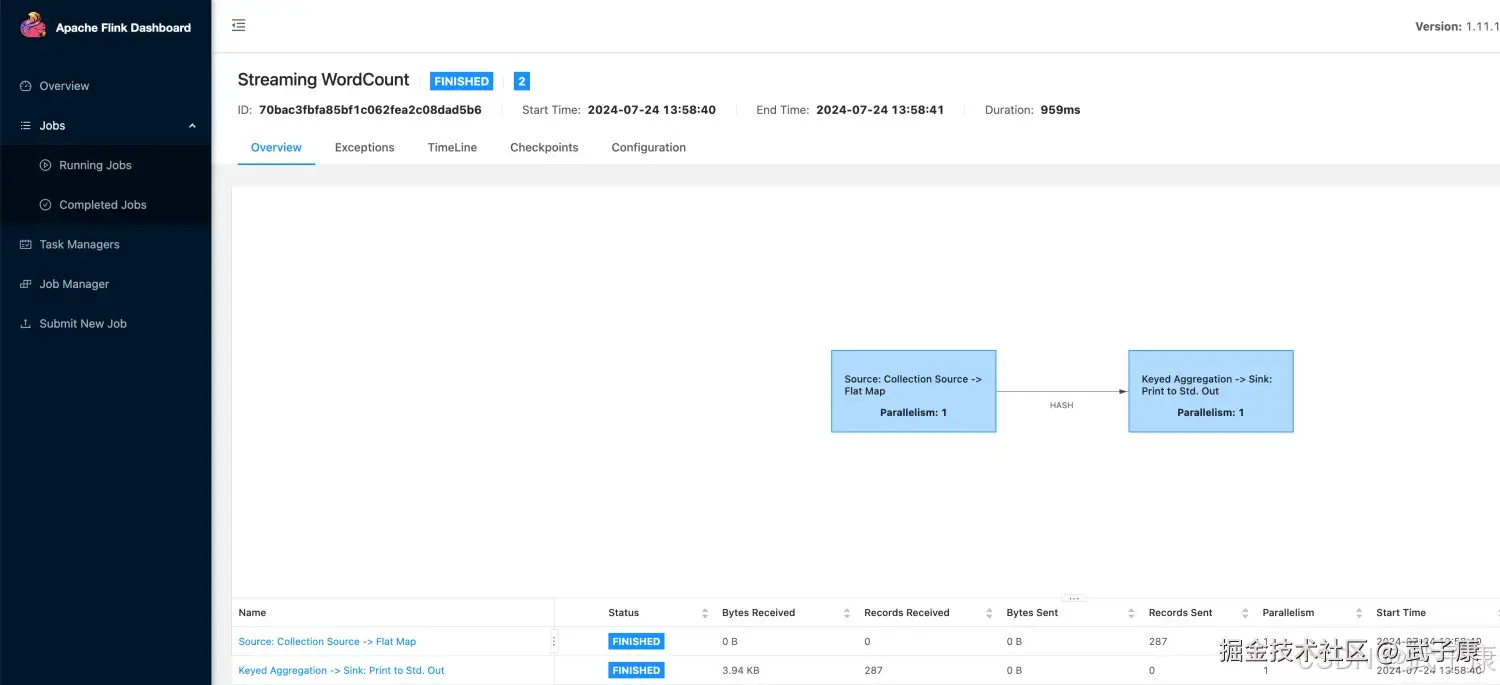
特点与优缺点
优点
- 简洁易用:Standalone 模式不需要额外的资源管理系统,配置相对简单,特别适合在资源固定的小型集群中运行。
- 独立性强:这种模式下,Flink 集群不依赖于外部系统,可以在没有 Yarn、Kubernetes 等资源管理平台的环境中独立运行。
- 低延迟:由于不涉及外部资源调度系统,Standalone 模式在资源调度上的延迟相对较低,适合需要低延迟任务调度的场景。
缺点
- 资源弹性差:由于没有集成外部资源管理系统,Standalone 模式的资源调度和管理相对固定,不支持动态扩展或缩减资源。这在面对变化的工作负载时,可能会导致资源浪费或不足。
- 管理复杂:在大规模集群中,手动管理多个 JobManager 和 TaskManager 可能变得复杂,特别是在需要高可用性和故障恢复的情况下。
- 缺乏高级特性:相比于集成 Yarn 或 Kubernetes 的部署模式,Standalone 模式缺乏一些高级的资源管理特性,如自动化资源分配、动态扩展、集群隔离等。
使用场景
-
开发与测试:Standalone 模式是 Flink 应用开发与测试阶段的理想选择。开发者无需配置复杂的集群管理工具(如 YARN 或 Kubernetes),只需在单机或少量机器上快速启动 Flink 进程即可运行作业。例如,开发者可以在本地笔记本电脑上运行 Standalone 模式,验证数据处理逻辑的正确性,或通过 IDE 直接调试代码。此外,Standalone 模式支持快速重启和日志查看,便于排查问题,显著提升开发效率。
-
小型集群 :对于资源固定且规模较小的生产环境(如 10 台以下节点的集群),Standalone 模式能够提供足够的灵活性和控制力。用户可以通过手动配置
flink-conf.yaml文件定义 TaskManager 和 JobManager 的资源分配,无需依赖外部资源调度系统。例如,一个数据分析团队可能使用 5 台物理服务器组成 Standalone 集群,长期运行批处理报表作业,既避免了管理复杂集群的开销,又能保证稳定的资源隔离和作业优先级控制。 -
边缘计算:在资源受限的边缘计算场景(如工业物联网网关、车载设备或远程传感器节点)中,Standalone 模式可作为轻量级的分布式计算解决方案。其优势包括:
- 低开销:无需部署 Kubernetes 等容器化平台,减少内存和 CPU 占用;
- 快速部署:通过预编译的 Flink 二进制包即可在 ARM 等边缘设备架构上运行;
- 离线支持 :适应边缘网络不稳定的环境,独立完成本地数据处理。
例如,在风力发电机监测系统中,边缘设备可通过 Standalone 模式实时分析振动传感器数据,仅将异常结果上传至云端,大幅降低带宽消耗。
扩展性与限制
- 扩展性有限:虽然 Standalone 模式允许在固定资源下进行扩展,但由于缺乏动态资源管理,扩展能力有限,难以应对大规模或动态变化的工作负载。
- 适应性:对于需要频繁调整资源的场景,Standalone 模式可能不太适用,但在资源固定且作业负载相对稳定的情况下,它可以提供稳定可靠的服务。
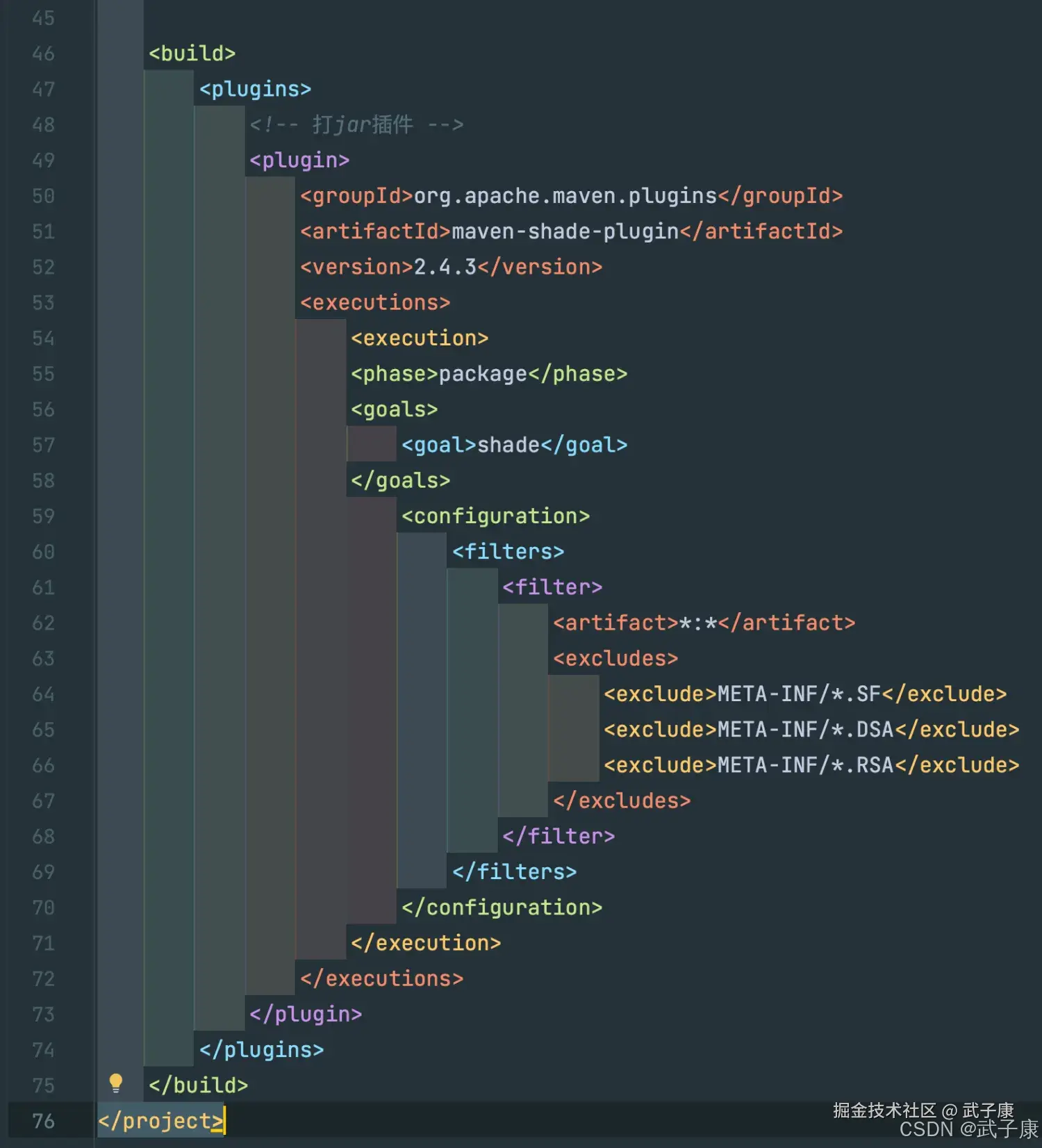
添加依赖
xml
<build>
<plugins>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>pom结构如下所示: