问题
需要将数据定时每天从Aurora搬数据到S3中。
步骤
准备数据库只读账号
这里用的Aurora实际上是Mysql,所以,这里创建一个Mysql账号,然后,在Secrets Manager
设置好自动轮转即可。具体如下:
bash
# 登录跳板机后,使用mysql cli登录数据库集群
mysql -h dev.cluster-xxxx.rds.cn-north-1.amazonaws.com.cn -u admin --ssl -p
# 输入密码登录成功后,开始创建mysql只读用户
CREATE USER '{用户名}'@'%' IDENTIFIED BY '{密码}';
# 设置只读权限
GRANT SELECT, SHOW VIEW ON {数据库名}.* TO '{用户名}'@'%';
# 强制刷新权限
FLUSH PRIVILEGES;在数据库段创建好只读用户后,再到Secrets Manager设置用户自动轮转:
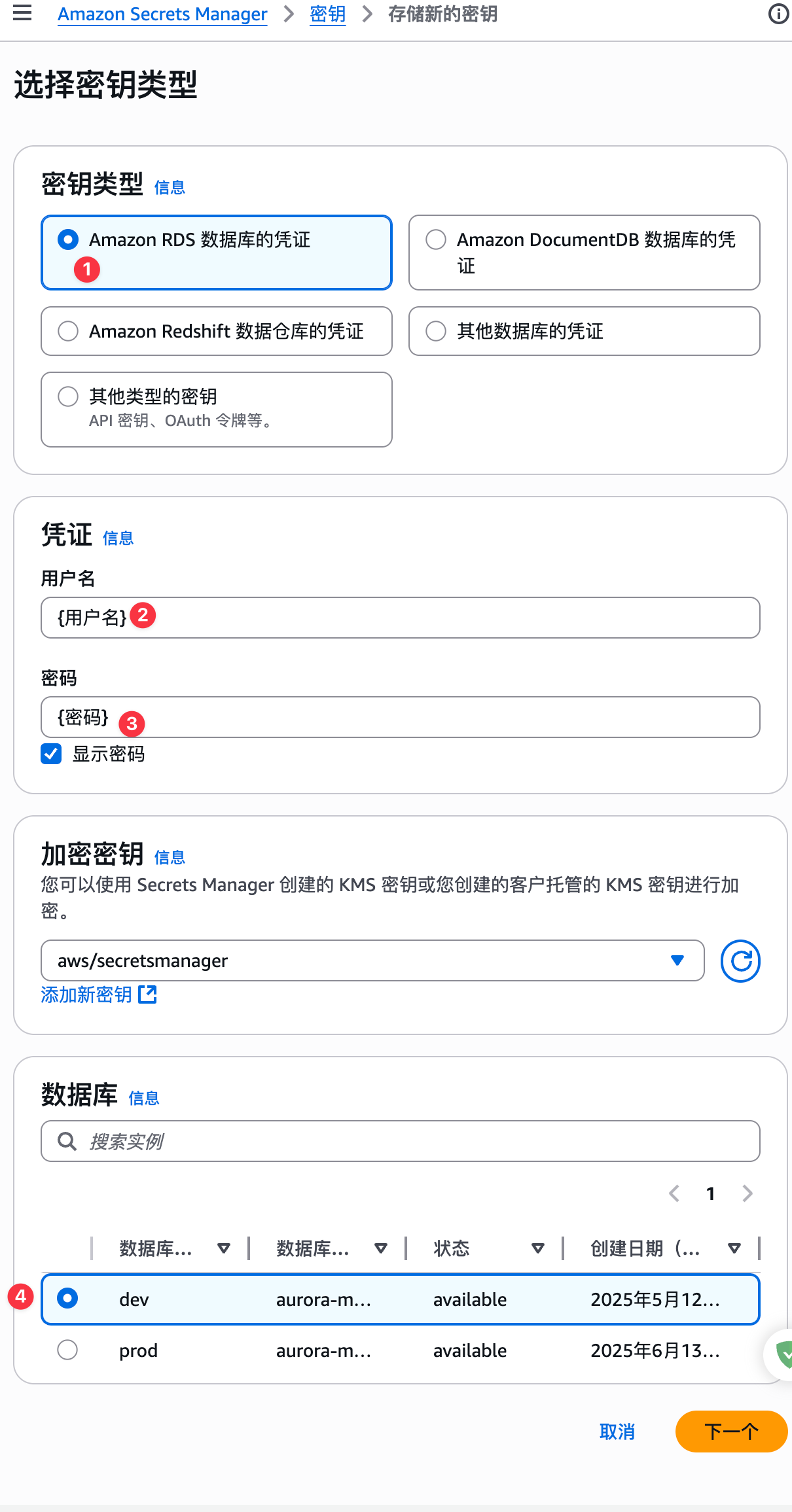
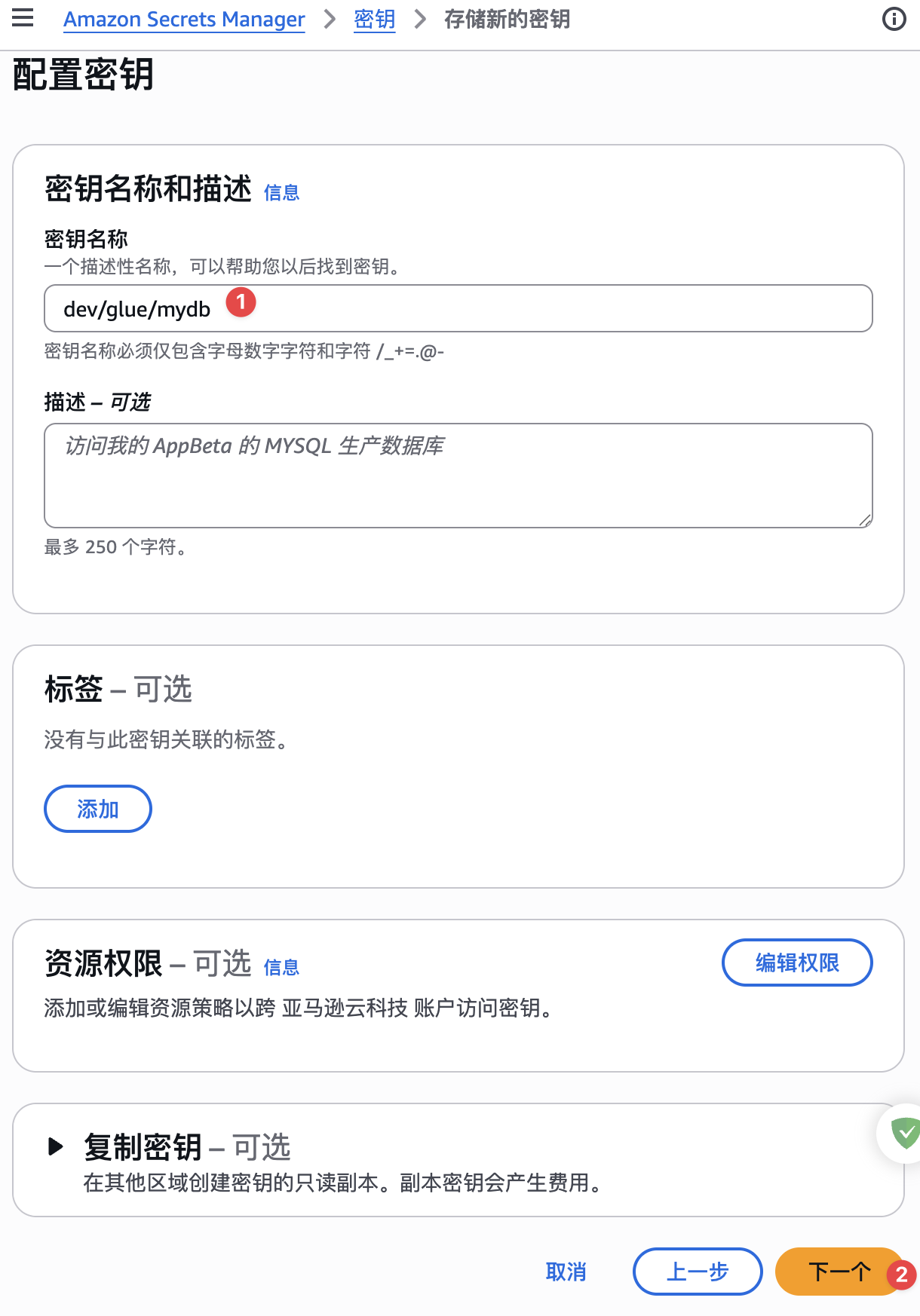
设置密钥名称:
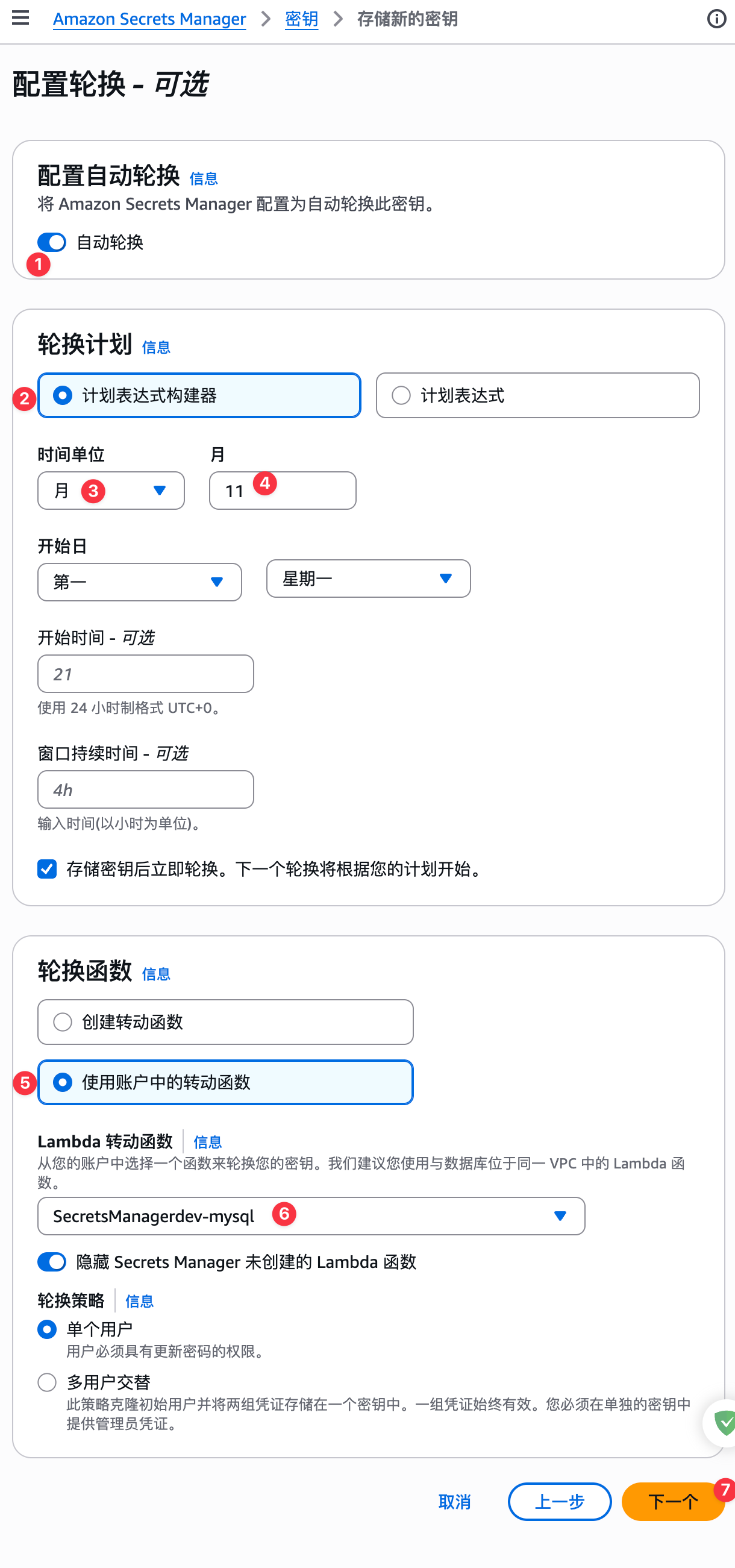
设置自动轮转密钥,如下图:
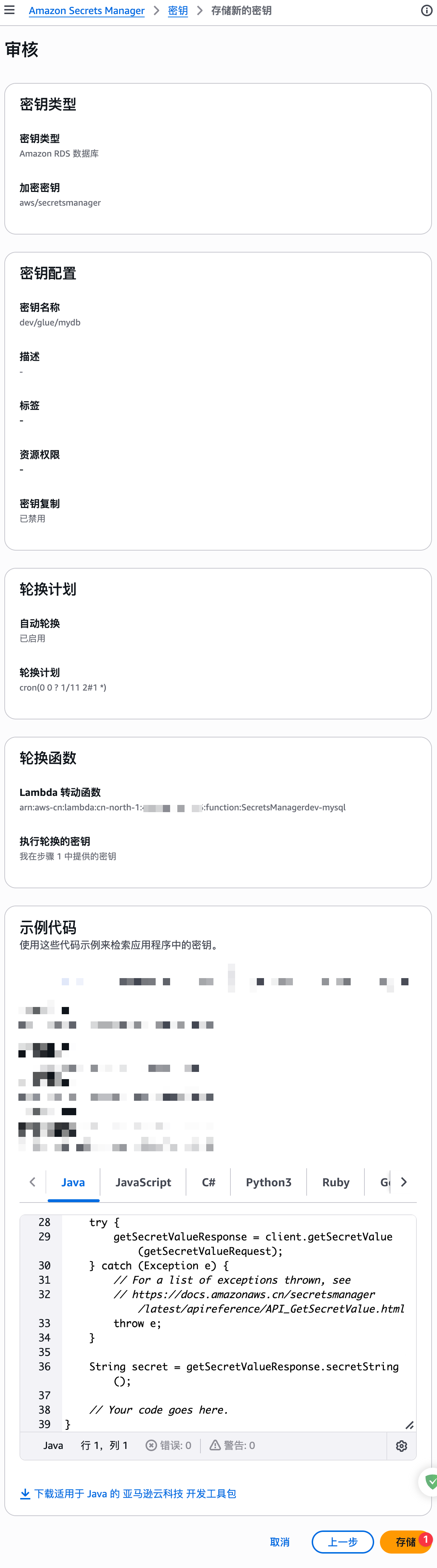
创建自动轮转密钥:
创建Glue JDBC连接器
开始创建Glue的JDBC连接器,如下图:
选择Amazon Aurora数据库进行连接,如下图:
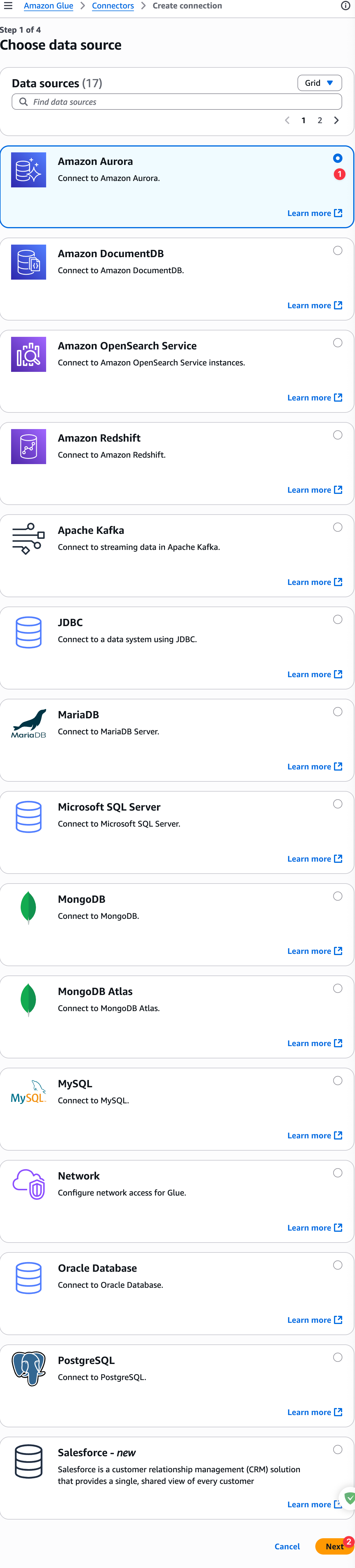
配置连接如下图:
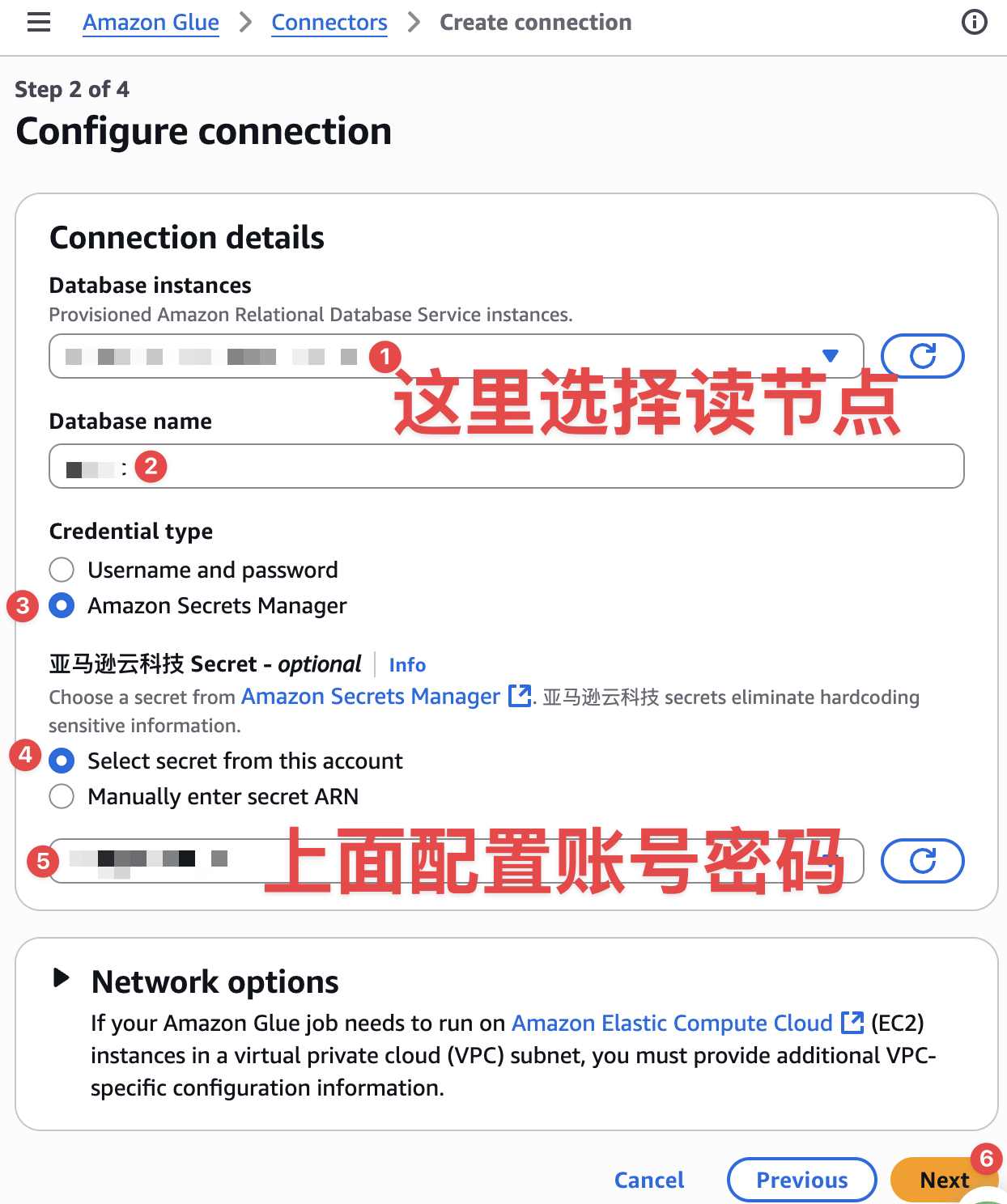
设置连接器名称,如下图:
创建JDBC连接器,如下图:
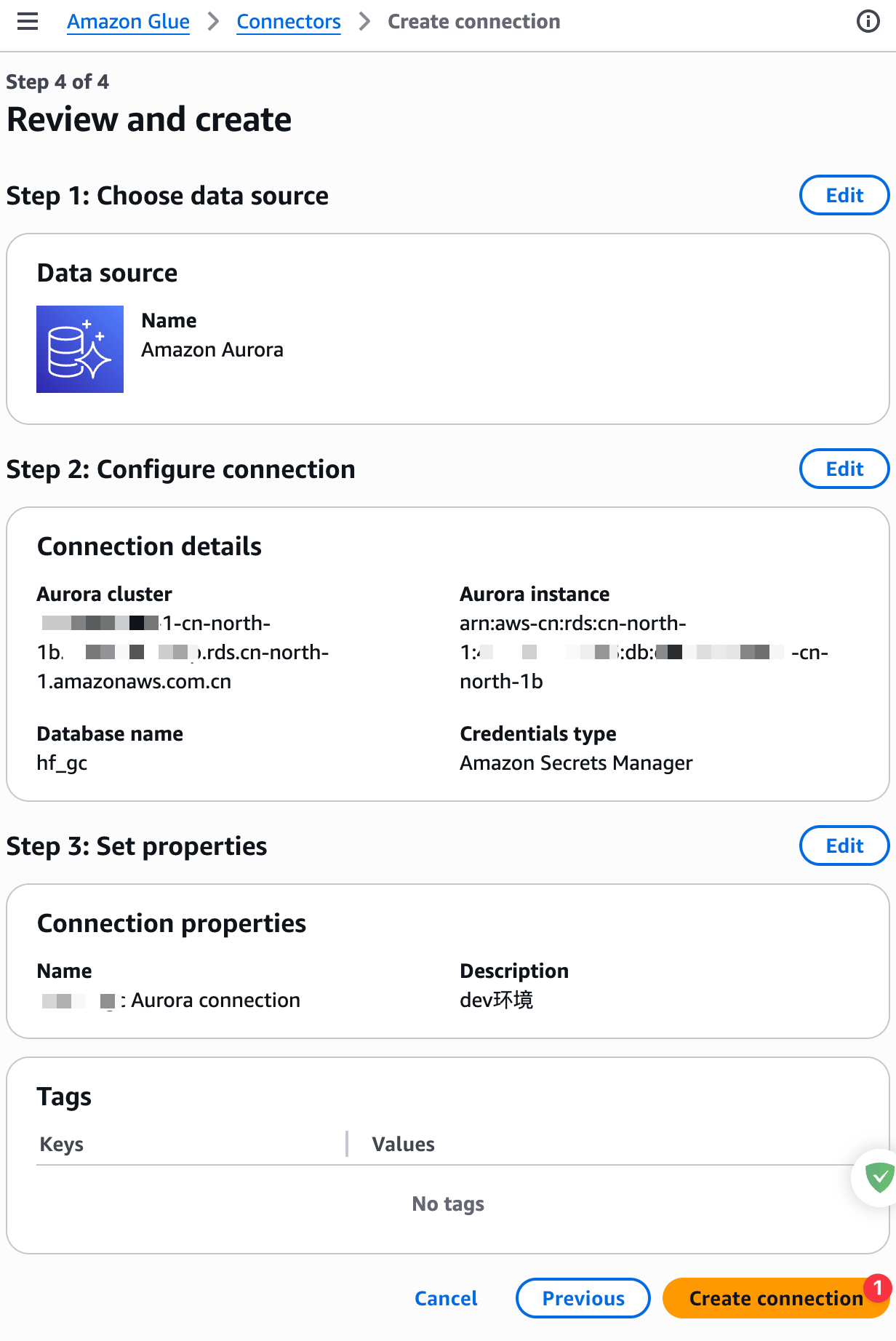
创建完成后,手动编辑一下JDBC连接,添加如下JDBC参数:
bash
jdbc:mysql://xxx-cn-north-1b.{数据库集群ID}.rds.cn-north-1.amazonaws.com.cn:3306/{数据库名}?sslMode=REQUIRED&characterEncoding=UTF-8&connectionTimeZone=GMT%2B8&forceConnectionTimeZoneToSession=true这里强制启用SSL方式连接,并使用UTF-8编码,设置时区为东八区,并且强制设置使用这个时区设置。
创建Glue任务运行角色
创建一个角色名为AWSGlueServiceRole角色,注意这个角色名必须以AWSGlueServiceRoleDefault*开头,才能被AWS Glue任务选择到。这个角色配置如下3种权限策略:
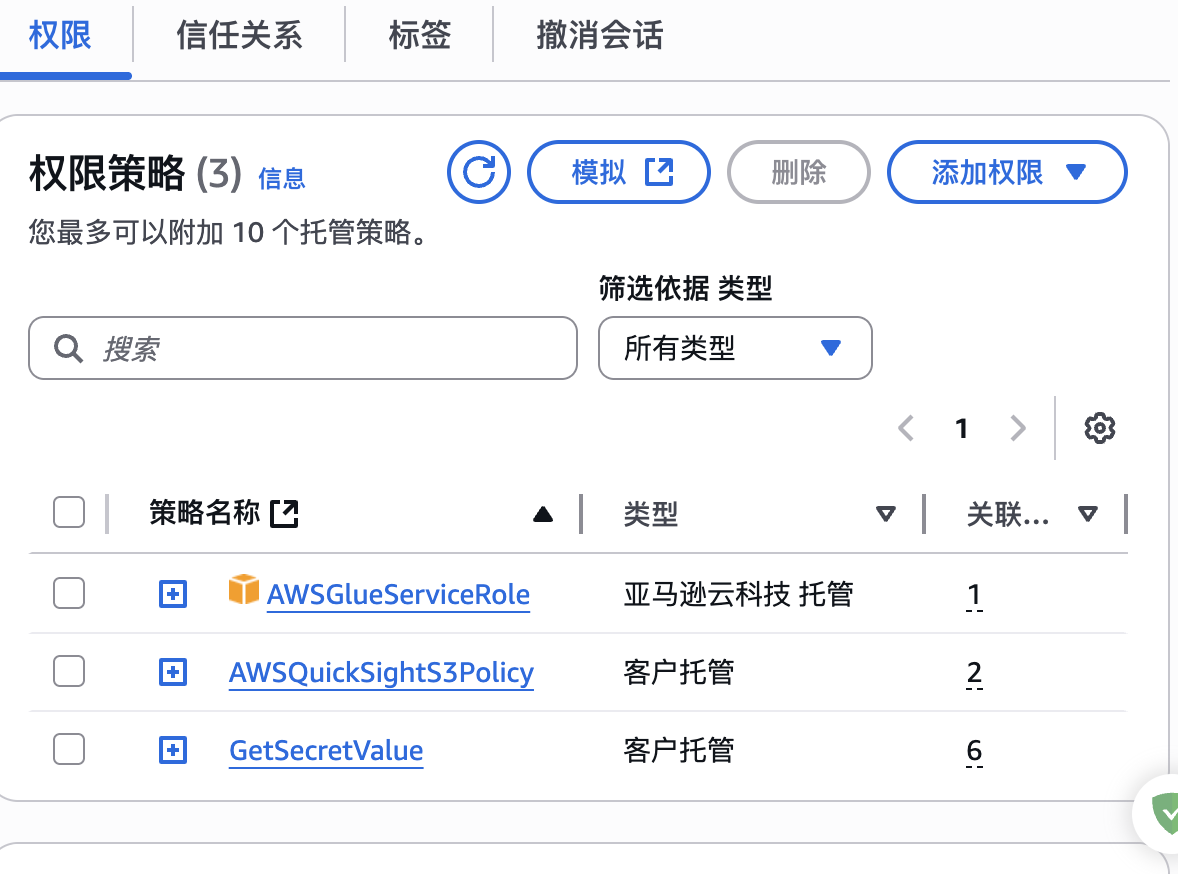
- AWSGlueServiceRole:为AWS托管策略,这个策略许可定时任务操作包含
aws-glue-路径的s3桶或s3目录; - AWSQuickSightS3Policy:是自定义对s3桶的设置,可以不用配置作用不是很大,这里忽略了;
- GetSecretValue:是许可定时任务对secretsmanager密钥只读访问权限。
GetSecretValue策略
json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
],
"Resource": "arn:aws-cn:secretsmanager:*:{账号ID}:secret:*"
}
]
}创建Glue定时任务
找到Glue入口管理页面。开始创建Glue任务,如下图:
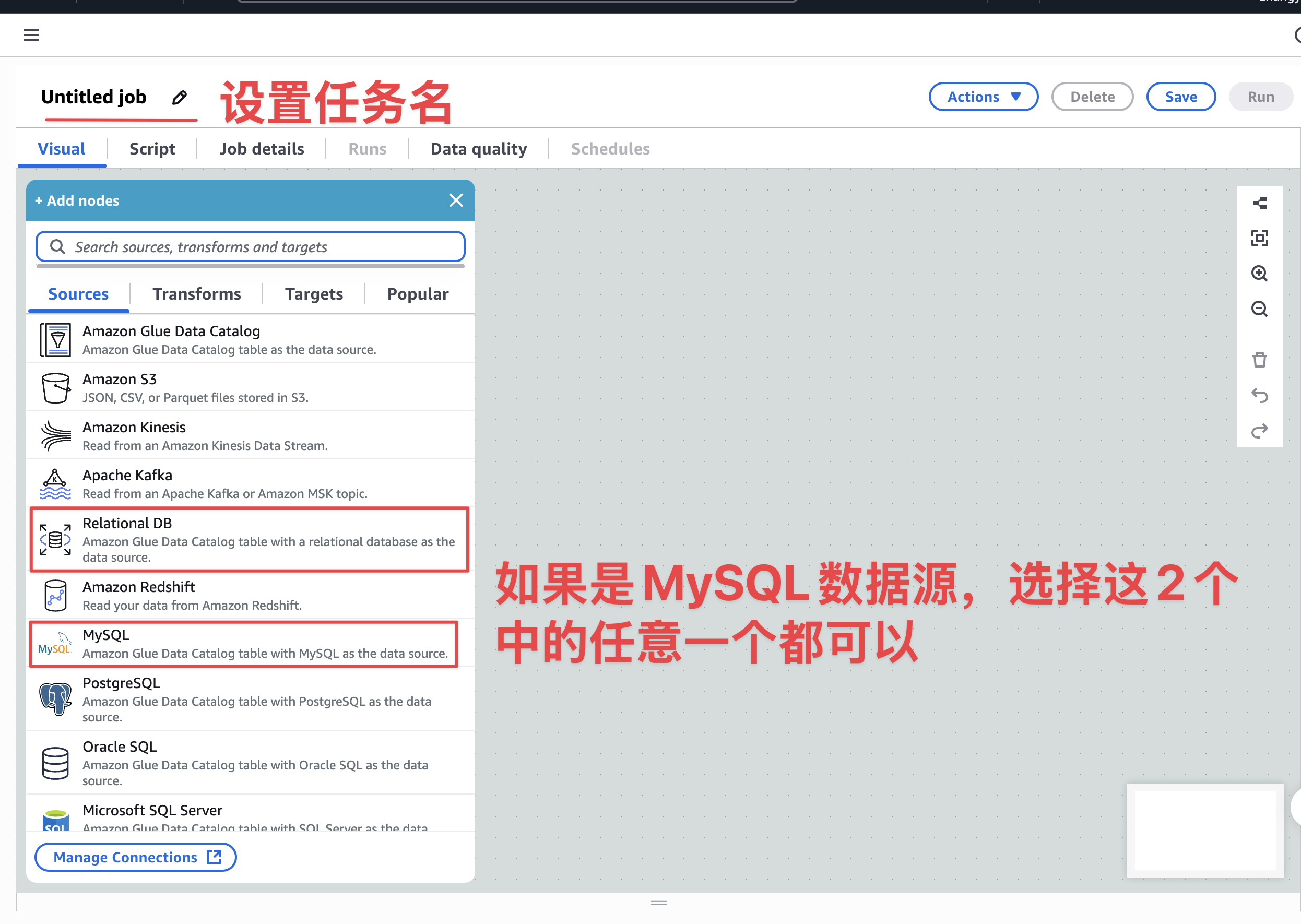
设置数据读取源------MySQL
设置数据源,因为我们使用的Aurora是Mysql,所以这里直接设置数据源为MySQL或者关系型数据也可以。如下图:
接下来,配置数据库连接,配置需要查询的表和任务执行的角色,如下图:
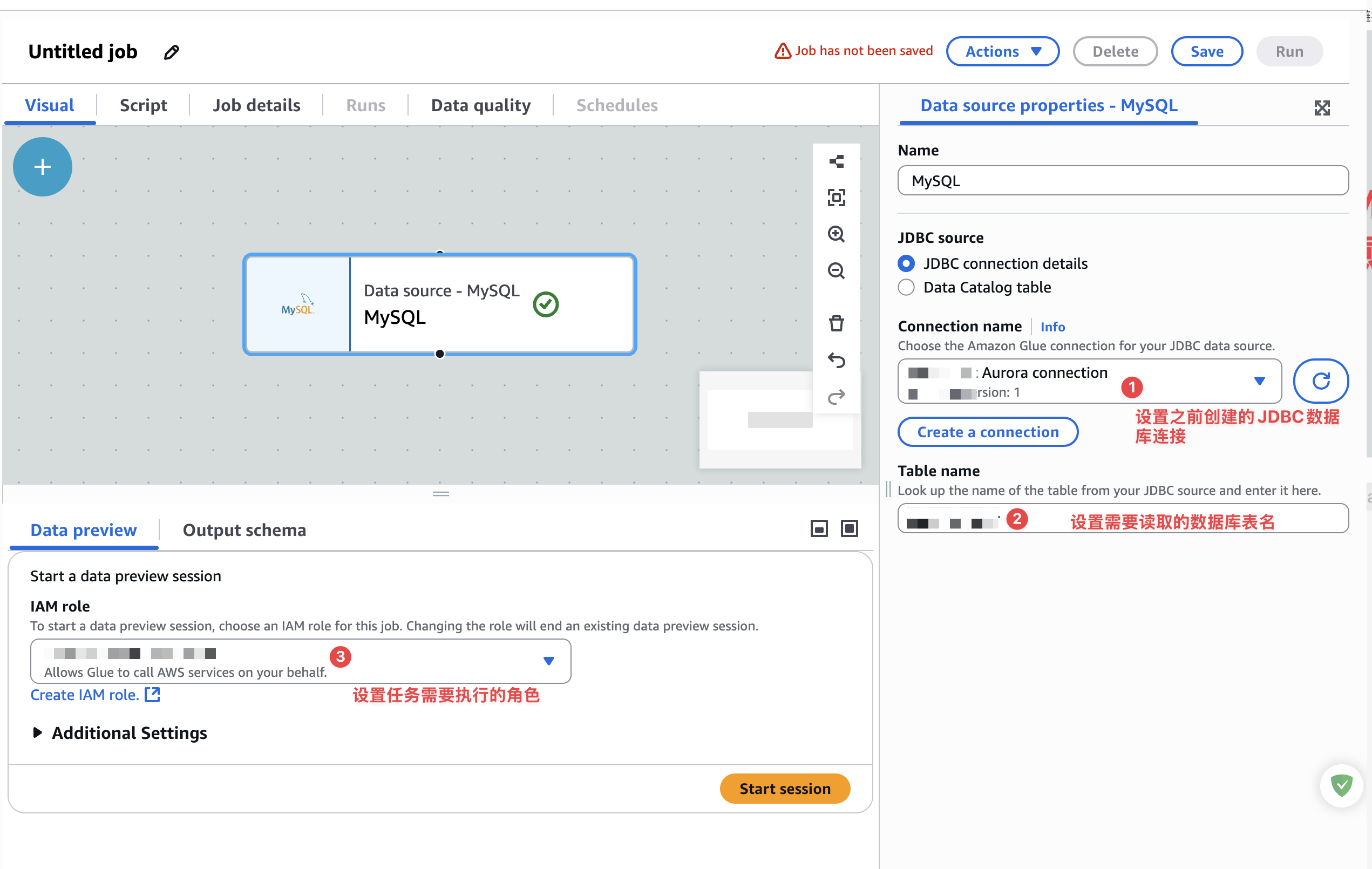
最后点击start session,看数据预查询效果,如果出现安全组错误,一定要找到之前配置JDBC连接时与数据库RDS共用的安全组,需要配置如下入站规则:
安全组入站规则
| 类型 | 协议 | 端口范围 | 源 |
|---|---|---|---|
| All TCP | TCP | 0-65535 | database-sg-id |
注意这里的database-sg-id就是安全组自身的id。
安全组的出站规则保存默认即可,即放行所有流量出站。
设置SQL查询
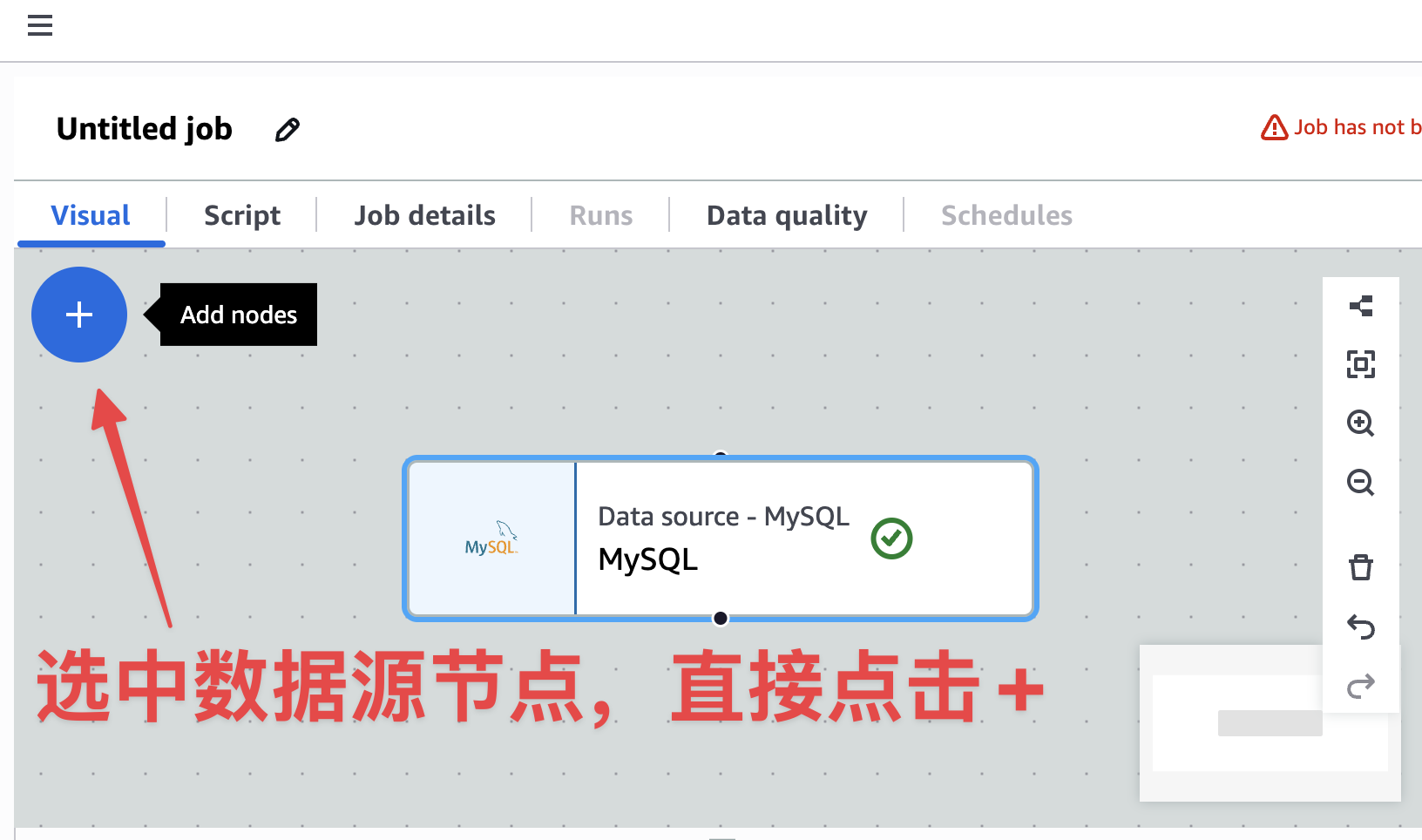
完成上面数据源配置后,就可以下一步,查询需要的数据了。开始添加下一步,如下图:
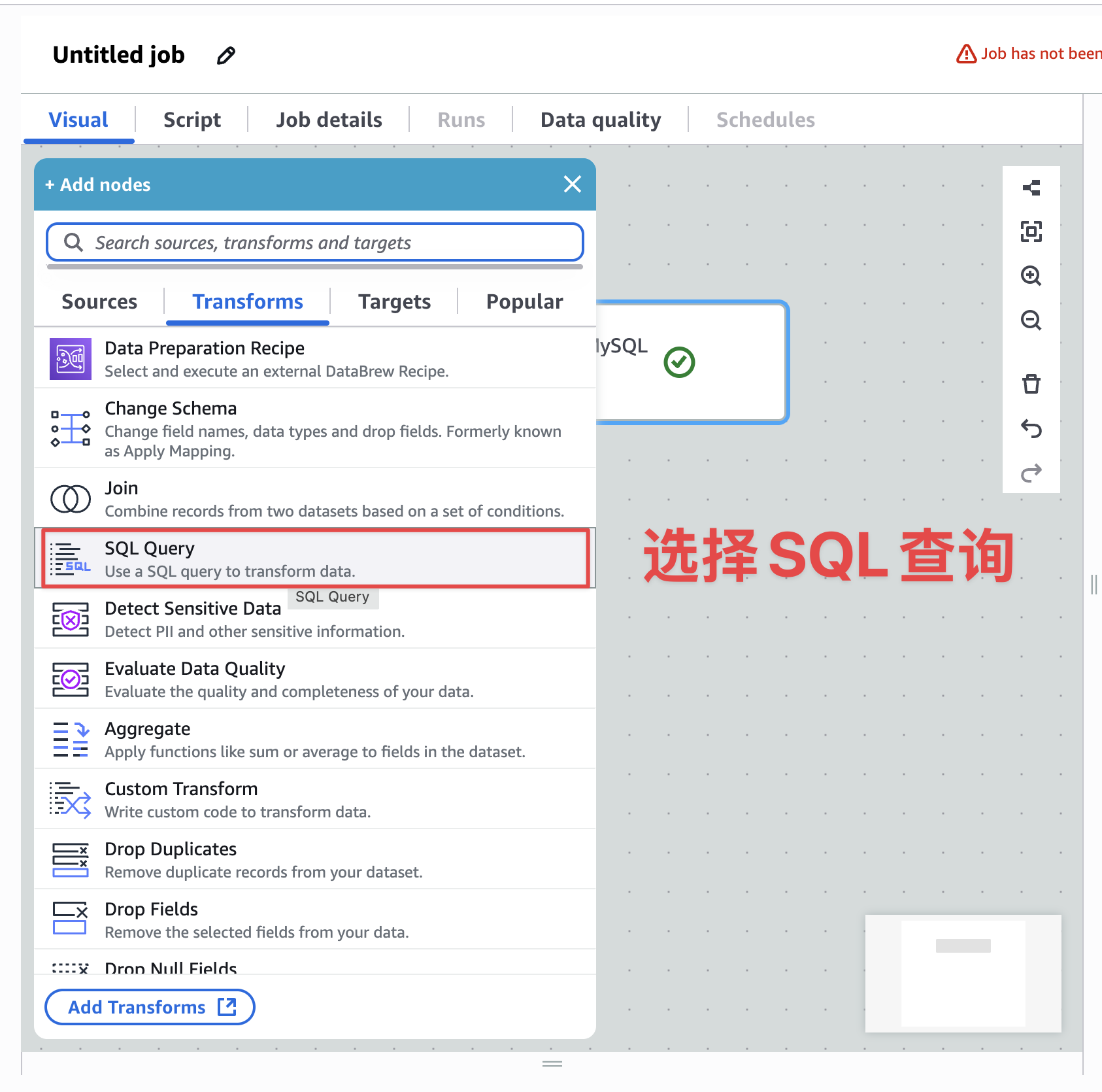
下一步转化步骤,选择SQL查询,如下图:
配置SQL查询,如下图:
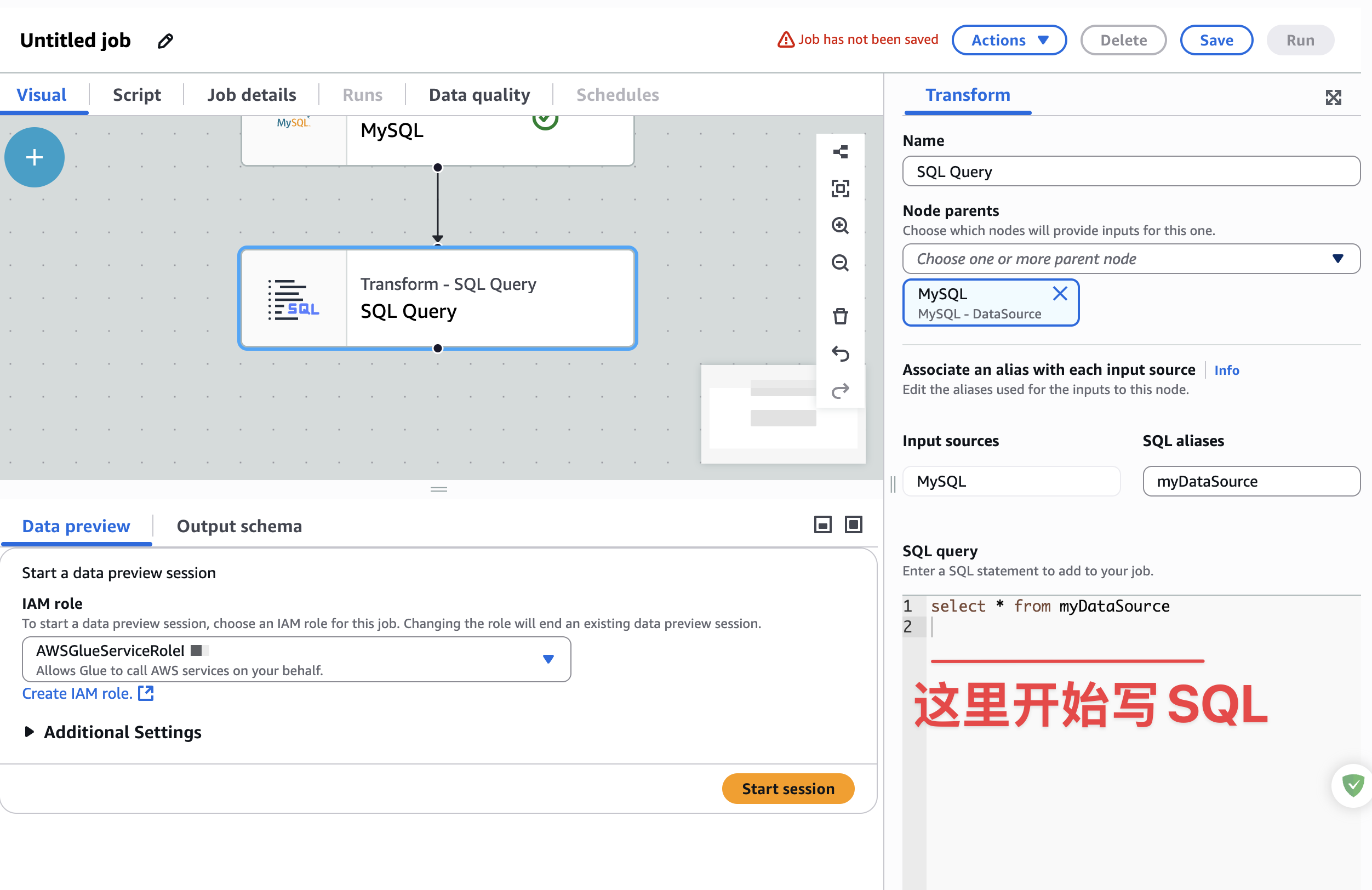
这里写好业务需要查询SQL即可,其他东西,根据情况,进行配置即可。这里有一个需要注意的地方,就是S3桶中的数据,需要按年月日进行分区保存,而且保存的数据格式是hadoop格式,这里需要根据某些字段来进行数据分区,一般是年月日。英文里面把这个过程叫------partition。数据分区后,在s3里面类似如下:
s3://my_bucket/logs/year=2018/month=01/day=23/
如果你的数据里面有年月日三个字段的话,可以直接在下一步里面设置分区key即可。如果没有,又需要按当前时间任务运行时间来推断的话,就需要在SELECT子句里面另外加字段即可。类似查询SQL如下:
sql
select *,
YEAR(CURDATE() - INTERVAL 1 DAY) AS year,
MONTH(CURDATE() - INTERVAL 1 DAY) AS month,
DAY(CURDATE() - INTERVAL 1 DAY) AS day
from xxxx;注意,这里不要直接写SELECT *,实际情况是要写出现表所有字段的,这里推断出昨天的年月日数据,记住这里的3个字段,在下一步S3分区配置中还需要使用。
这里还需要,手动添加年月日字段,如下图
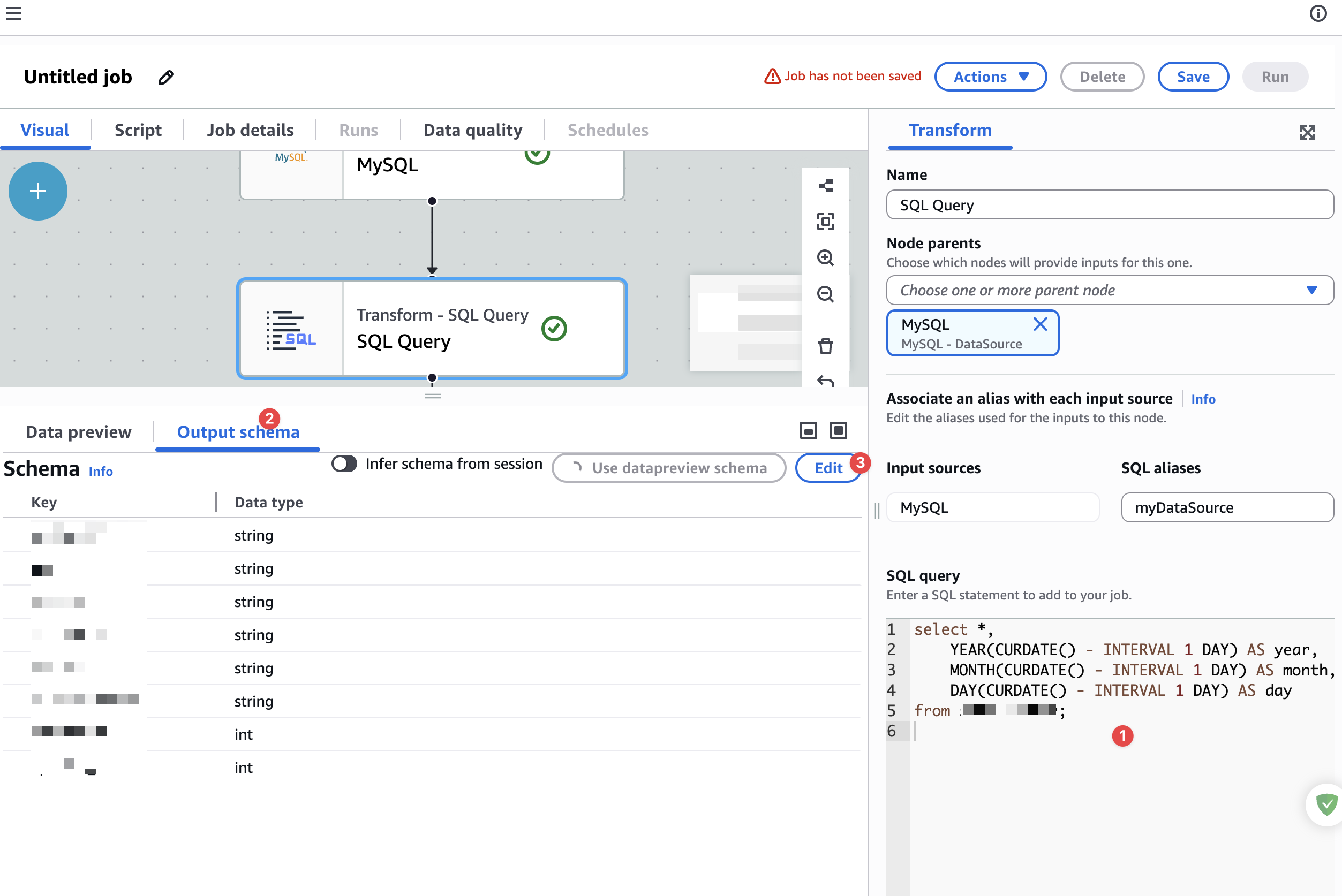
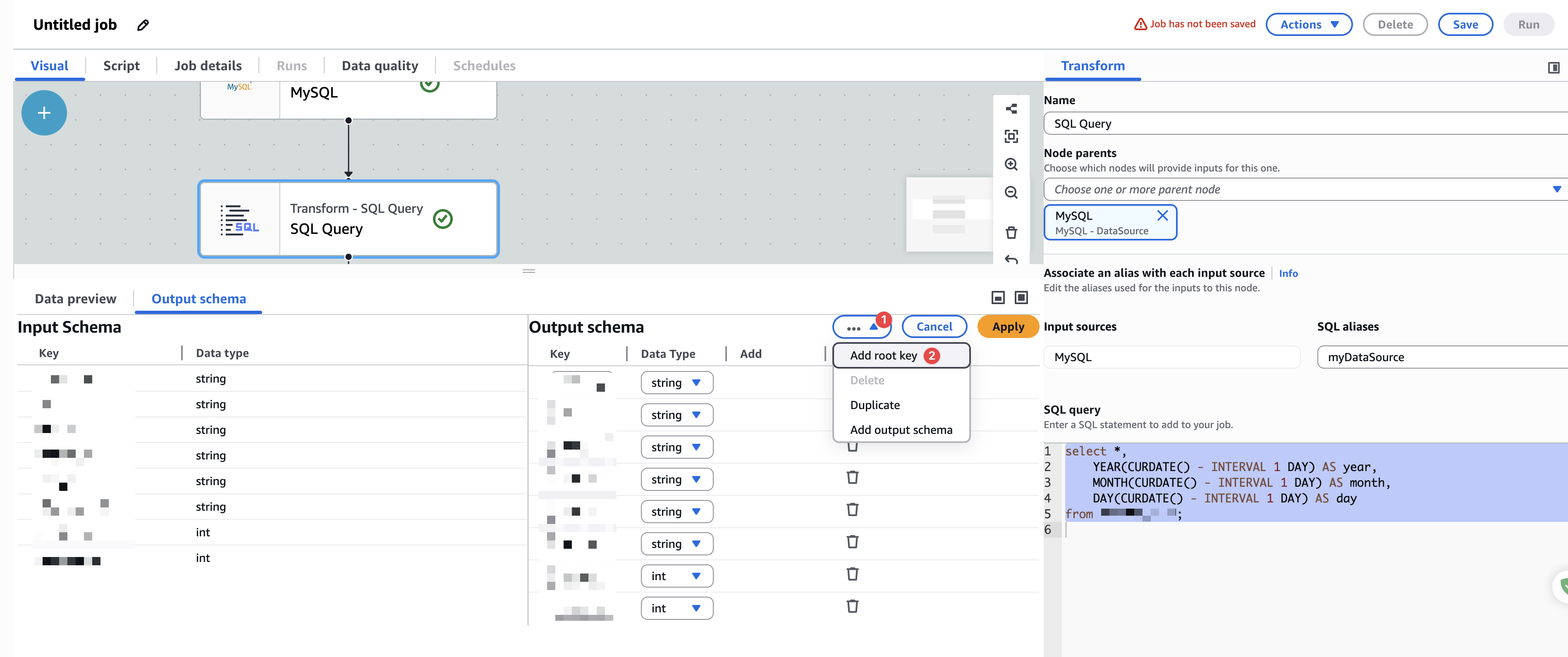
开始手动添加字段,如下图:
添加完成3个字段后,如下图:
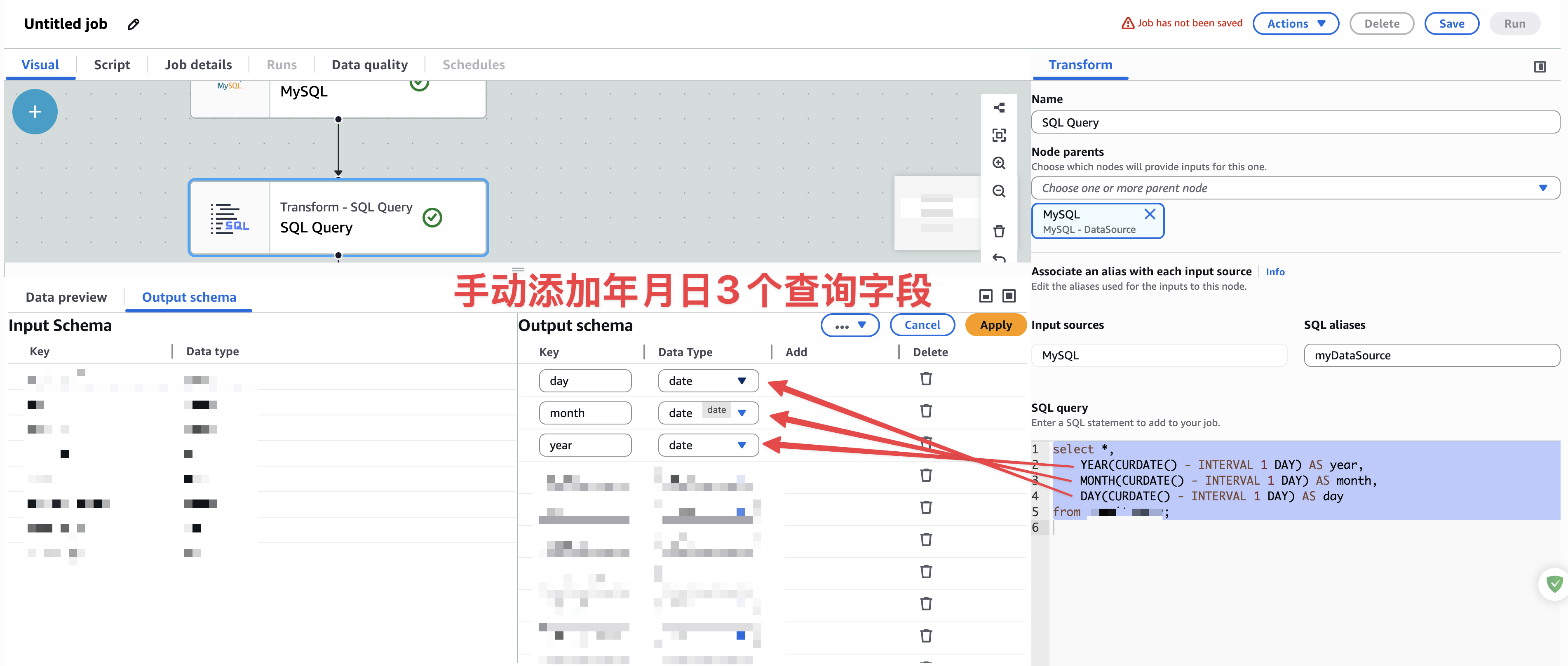
最后点击Apply即可。
设置数据写入目标------S3
选中转化步骤,添加下一步目标S3桶步骤,如下图:
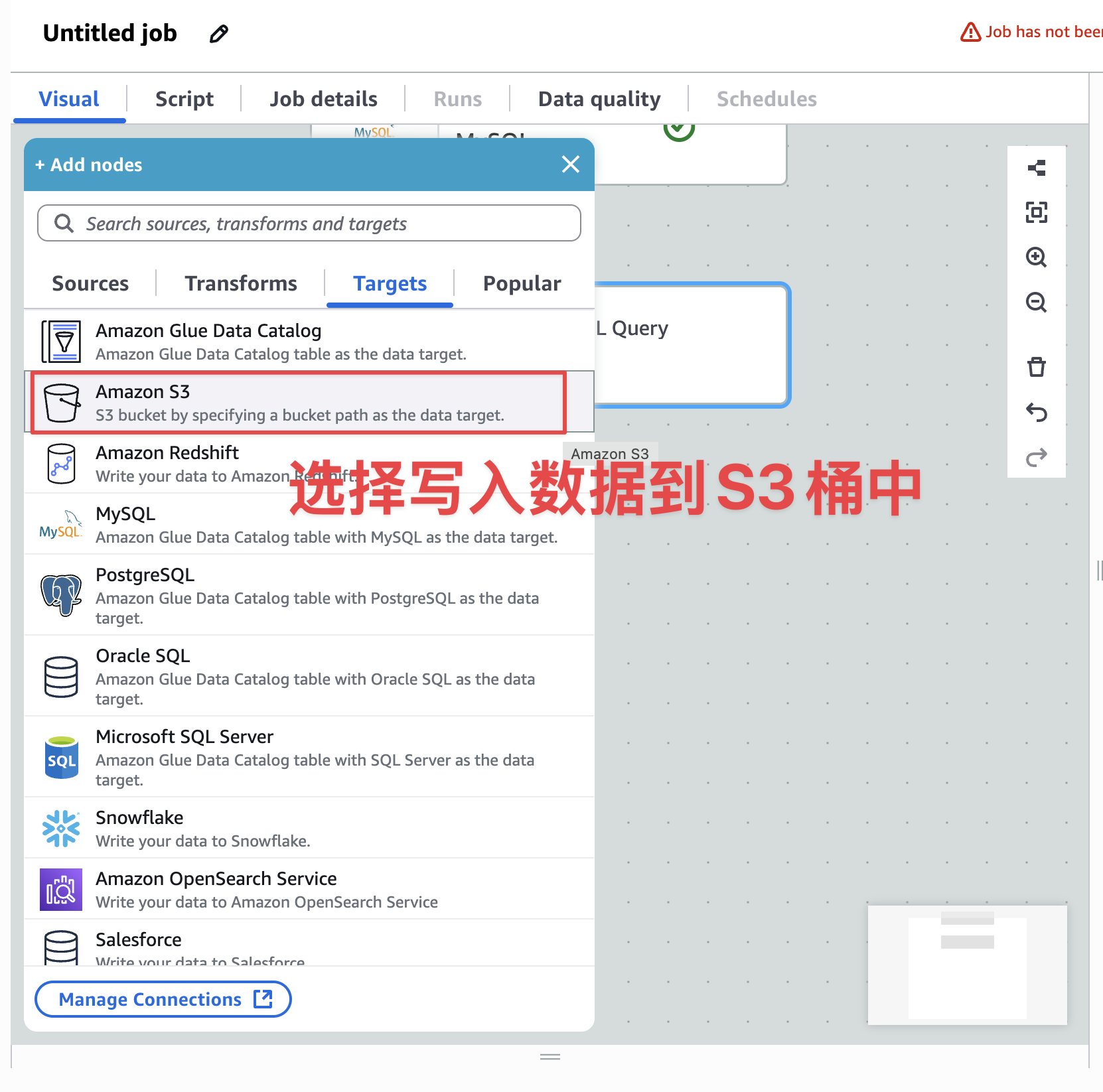
开始配置目标S3位置和分区key,如下图:
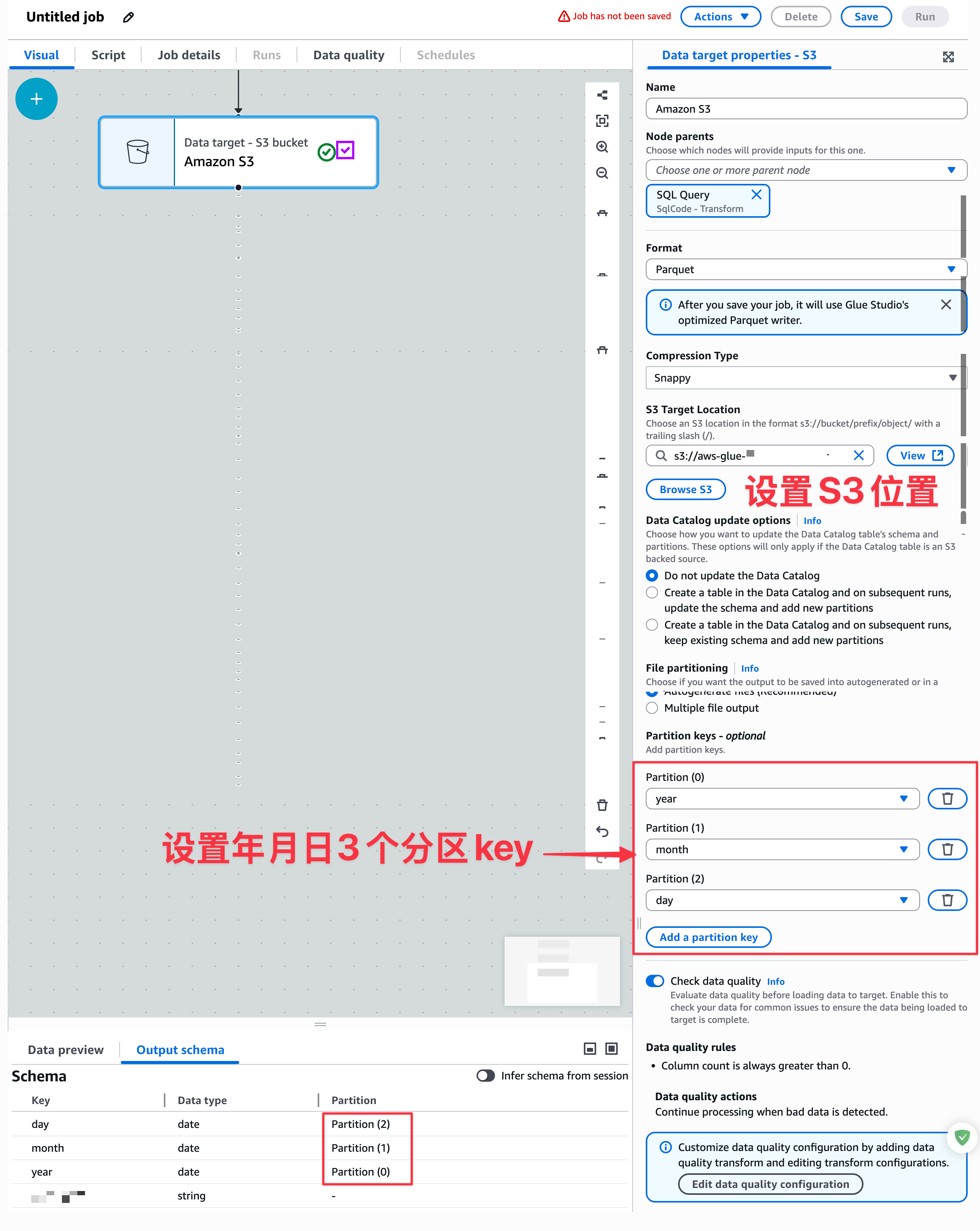
这里最关键的就是hadoop分区key设置。这里保存的就是hadoop的压缩格式Parquet,而且,按年月日进行数据分区。最后点击保存后。在Schedules标签也配置定时任务触发器即可。注意定时任务触发器是用零时区的。
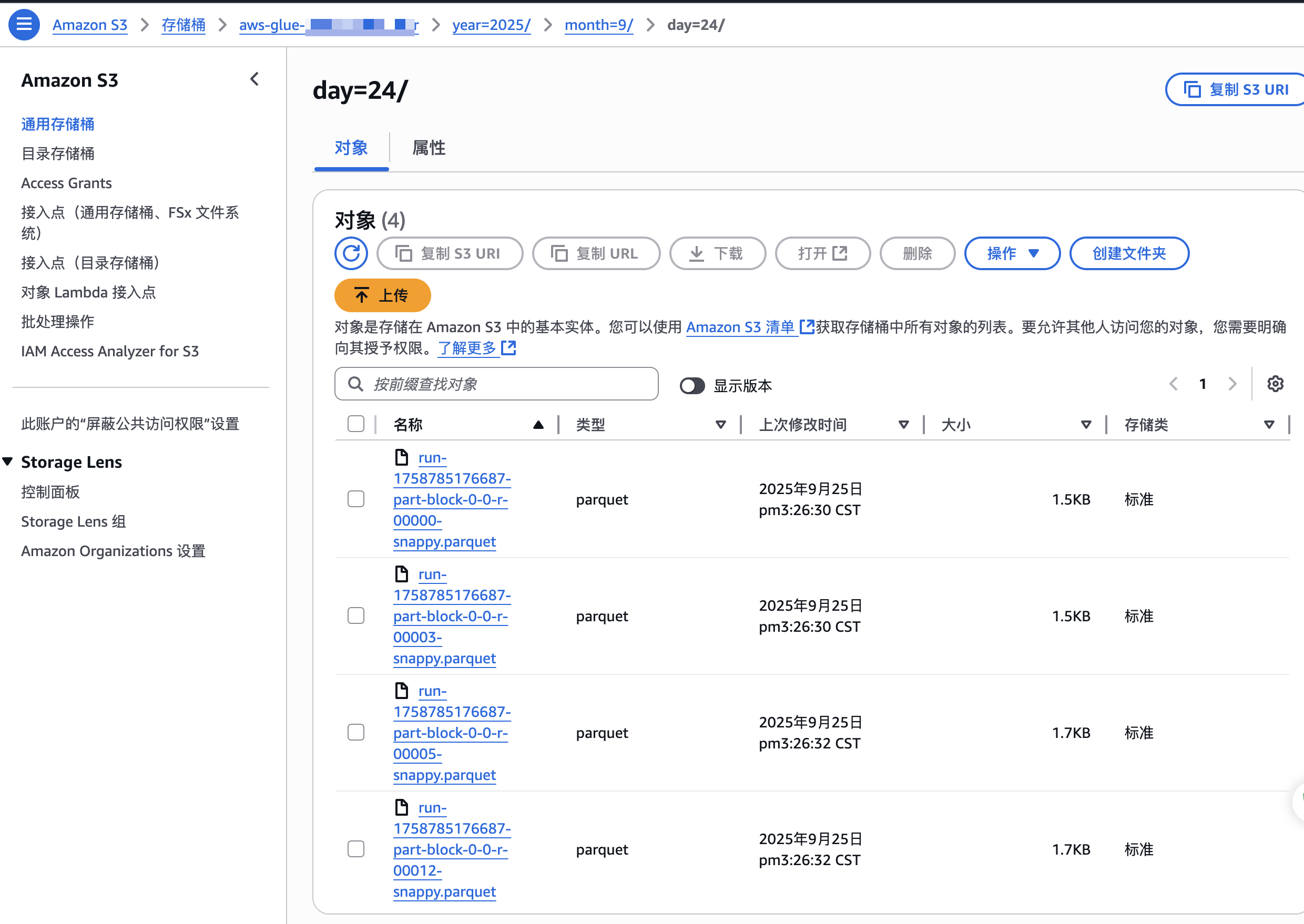
测试效果
S3文件效果如下:
总结
这里的AWS Glue任务,其实就是Spark+Hadoop完成了从MySQL到HDFS的数据写入。Spark在大数据的生态是真的强。这里比较难以理解的就是在Hadoop中的partition设计,具体数据分区远离,我借用了AWS文档里面图了,如下图:
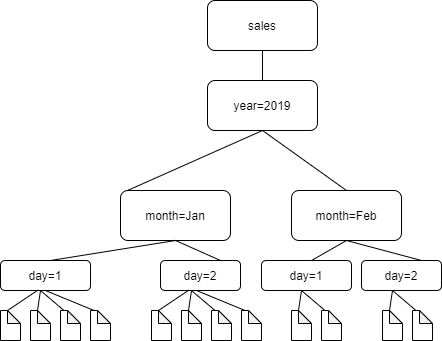
这种按年月日,在这个领域,还是比较常见的。到这里就是AWS ETL的简单搬运任务了。
参考
- A Guide to Store Data from Amazon Aurora RDS on an Incremental Basis using AWS Glue
- Setting up Amazon VPC for JDBC connections to Amazon RDS data stores from AWS Glue
- Step 2: Create an IAM role for AWS Glue
- 东八区
- 时差换算器
- AWS Tutorials - Partition Data in S3 using AWS Glue Job
- Managing partitions for ETL output in AWS Glue
- Using crawlers to populate the Data Catalog