PyTorch实战(8)------图像描述生成
-
- [0. 前言](#0. 前言)
- [1. 使用 CNN 和 LSTM 构建神经网络](#1. 使用 CNN 和 LSTM 构建神经网络)
-
- [1.1 文本编码示例](#1.1 文本编码示例)
- [2. 数据集处理](#2. 数据集处理)
-
- [2.1 下载图像描述数据集](#2.1 下载图像描述数据集)
- [2.2 文本标注数据预处理](#2.2 文本标注数据预处理)
- [2.3 图像数据预处理](#2.3 图像数据预处理)
- [2.4 定义数据加载器](#2.4 定义数据加载器)
- [3. 构建图像描述生成模型](#3. 构建图像描述生成模型)
-
- [3.1 定义 CNN-LSTM 模型](#3.1 定义 CNN-LSTM 模型)
- [3.2 训练 CNN-LSTM 模型](#3.2 训练 CNN-LSTM 模型)
- [3.3 使用训练好的模型生成图像描述](#3.3 使用训练好的模型生成图像描述)
- 小结
- 系列链接
0. 前言
卷积神经网络 (Convolutional Neural Network, CNN)作为一种重要的深度学习模型,在图像分类、目标检测、语音识别等涉及视觉和听觉的机器学习任务中表现卓越。其核心优势在于采用了具有参数共享特性的卷积层,参数共享基于图像特征(如边缘轮廓)与像素位置无关的假设。与之相对应,长短期记忆网络 (Long Short-Term Memory, LSTM)作为循环神经网络 (Recurrent Neural Network, RNN) 的变体,在处理文本等序列数据时展现出独特优势,能够有效建模词语间的时序依赖关系。
将这两种网络结构有机结合,可构建出能够实现图像到文本转换的多模态模型。这种混合模型的一个典型应用是图像描述生成,模型接收图像输入后,自动生成符合图像内容的文字描述。虽然机器学习应用于执行图像描述生成任务可追溯至 2010 年,但神经网络直到 2015 年左右才首次成功应用于这一任务。随着技术的不断改进,这一深度学习应用已切实在实际应用中发挥作用。本节将讨论这种多模态模型的架构及 PyTorch 实现细节,使用 PyTorch 从零开始构建一个图像描述生成模型。
1. 使用 CNN 和 LSTM 构建神经网络
CNN-LSTM 网络架构由卷积层(用于从输入图像数据中提取特征)和 LSTM 层(用于执行序列预测)组成,兼具空间深度 (CNN) 与时间深度 (LSTM) 双重特性。模型的卷积部分通常作为编码器,接收输入图像并输出高维特征或嵌入。
在实际应用中,CNN 部分通常采用预训练模型(如图像分类网络),然后,预训练 CNN 模型的最后一个隐藏层作为输入传递给 LSTM 部分,LSTM 作为解码器用于生成文本。
处理文本数据时,需要将单词和标点符号、标识符等符号(统称为词元,token )转化为数字,通过为文本中的每个词元分配一个唯一的数字来实现。接下来,我们将通过一个文本编码示例说明编码过程。
1.1 文本编码示例
假设我们正在构建一个机器学习模型来处理文本数据,原始文本为:
shell
<start> PyTorch is a deep learning library. <end>然后,将每个词元映射为数字:
shell
<start> : 0
PyTorch : 1
is : 2
a : 3
deep : 4
learning : 5
library : 6
. : 7
<end> : 8利用这个映射,可以将这个句子表示为数字序列:
shell
<start> PyTorch is a deep learning library. <end> -> [0, 1, 2, 3, 4, 5, 6, 7, 8]例如,<start> PyTorch is deep. <end> 被编码为 [0, 1, 2, 4, 7, 8]。这个映射通常称为词汇表,构建词汇表是大多数与文本相关的机器学习问题中的一个关键步骤。
在图像描述任务中,LSTM 模型作为解码器,在时间步 t=0 时接收 CNN 嵌入作为输入。然后,每个 LSTM 单元在每个时间步预测一个 token,并将其作为输入传递给下一个 LSTM 单元。最终整体架构如下所示。
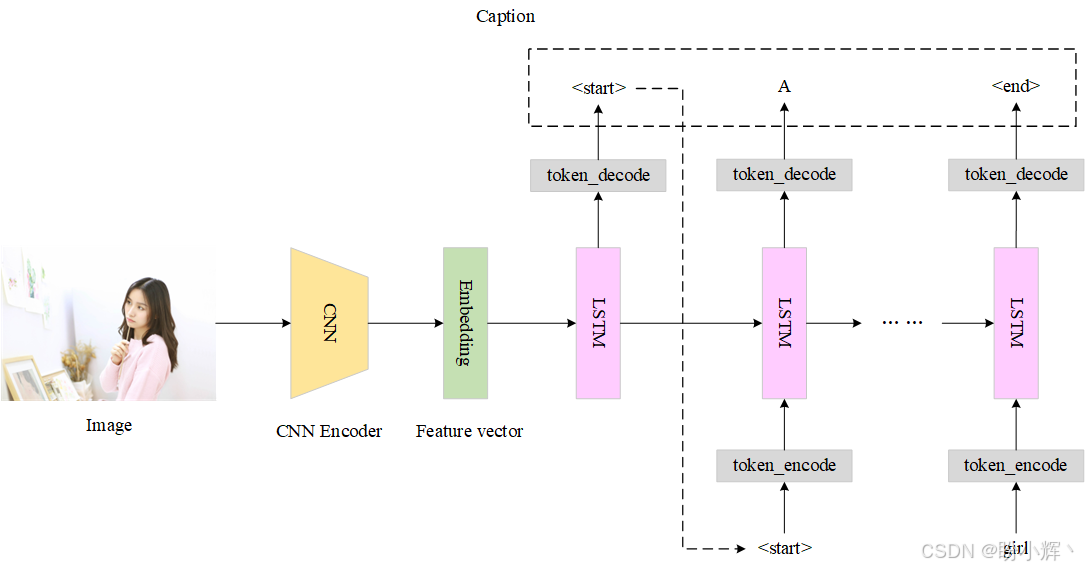
如果输入不是一张图像,而是一系列图像(比如视频),则需在每个时间步都注入 CNN 编码特征,而不仅仅是在 t=0 时输入。
接下来,我们将使用 PyTorch 实现一个图像描述生成系统,涵盖混合模型构建、数据加载预处理、训练评估全流程。
2. 数据集处理
在本节中,我们将使用 COCO (Common Objects in Context) 数据集,这是一个大规模的物体检测、分割和描述数据集。COCO 数据集包含超过 200000 张带标签的图像,每张图像有五个描述,极大推动了计算机视觉领域的发展,现已成为物体检测、实例分割及图像描述等基准测试中最常用的数据集之一。在本节中,我们将使用 PyTorch 在 COCO 数据集上训练一个 CNN-LSTM 模型,并用于生成新图像的描述文本。
2.1 下载图像描述数据集
在构建图像描述系统之前,需要下载所需的数据集。训练数据集和验证数据集的大小分别为 13 GB 和 6 GB。下载并解压数据集文件:
shell
# linux
!apt-get install wget
# mac
# !brew install wget
!mkdir data_dir
!wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip -P ./data_dir/
!wget http://images.cocodataset.org/zips/train2014.zip -P ./data_dir/
!wget http://images.cocodataset.org/zips/val2014.zip -P ./data_dir/
!unzip ./data_dir/annotations_trainval2014.zip -d ./data_dir/
!rm ./data_dir/annotations_trainval2014.zip
!unzip ./data_dir/train2014.zip -d ./data_dir/
!rm ./data_dir/train2014.zip
!unzip ./data_dir/val2014.zip -d ./data_dir/
!rm ./data_dir/val2014.zip输出结果如下所示:
该步骤会创建 ./data_dir 目录,自动下载压缩的图像文件与标注文件并解压至该目录。
2.2 文本标注数据预处理
数据集包含图像与文本描述两部分,在本节中,我们将对文本数据进行预处理,以便可以用于 CNN-LSTM 模型。
(1) 首先导入所需模块:
python
import os
import nltk
import pickle
import numpy as np
from PIL import Image
from collections import Counter
from pycocotools.coco import COCO
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.utils.data as data
from torchvision import transforms
import torchvision.models as models
import torchvision.transforms as transforms
from torch.nn.utils.rnn import pack_padded_sequencenltk 是自然语言工具包,在构建词汇表时非常有用,而 pycocotools 是一个用于处理 COCO 数据集的辅助工具。pack_padded_sequence 函数可将不同长度(单词数量)的句子通过填充转换为固定长度格式。
(2) 下载 nltk 库的 punkt 分词器模型,用于将给定的文本分解为其组成单词:
python
nltk.download('punkt')(3) 接下来,构建词汇表 ------ 即一个可以将实际词元(如单词)转换为数字索引的字典,这一步骤对于大多数与文本相关的任务都是必不可少的。
首先,在词汇表构建函数中加载 JSON 格式的文本描述,并对描述中的单个单词进行分词转换成数字,并将其存储在计数器 counter 中:
python
class Vocab(object):
def __init__(self):
self.w2i = {}
self.i2w = {}
self.index = 0
def __call__(self, token):
if not token in self.w2i:
return self.w2i['<unk>']
return self.w2i[token]
def __len__(self):
return len(self.w2i)
def add_token(self, token):
if not token in self.w2i:
self.w2i[token] = self.index
self.i2w[self.index] = token
self.index += 1
def build_vocabulary(json, threshold):
coco = COCO(json)
counter = Counter()
ids = coco.anns.keys()
for i, id in enumerate(ids):
caption = str(coco.anns[id]['caption'])
tokens = nltk.tokenize.word_tokenize(caption.lower())
counter.update(tokens)
if (i+1) % 1000 == 0:
print("[{}/{}] Tokenized the captions.".format(i+1, len(ids)))然后,删除出现次数少于某个阈值的词元,其余的词元添加到词汇表对象中,同时加入一些特殊词元 ------ 句子开始 (start)、结束 (end)、未知单词 (unknown_word) 和填充 (padding) 词元:
python
tokens = [token for token, cnt in counter.items() if cnt >= threshold]
vocab = Vocab()
vocab.add_token('<pad>')
vocab.add_token('<start>')
vocab.add_token('<end>')
vocab.add_token('<unk>')
for i, token in enumerate(tokens):
vocab.add_token(token)
return vocab最后,使用词汇表构建函数,创建一个词汇表对象 vocab 并将其保存在本地,以便后续使用:
python
vocab = build_vocabulary(json='data_dir/annotations/captions_train2014.json', threshold=4)
vocab_path = './data_dir/vocabulary.pkl'
with open(vocab_path, 'wb') as f:
pickle.dump(vocab, f)
print("Total vocabulary size: {}".format(len(vocab)))
print("Saved the vocabulary wrapper to '{}'".format(vocab_path))输出结果如下所示:
完成词汇表构建后,即可在运行时将文本数据动态转换为数字序列。
2.3 图像数据预处理
在下载数据并为文本描述构建词汇表之后,我们还需要对图像数据进行一些预处理。由于数据集中的图像尺寸不一,需要将所有图像调整为固定形状以适应 CNN 模型输入要求:
python
def reshape_image(image, shape):
return image.resize(shape, Image.LANCZOS)
def reshape_images(image_path, output_path, shape):
if not os.path.exists(output_path):
os.makedirs(output_path)
images = os.listdir(image_path)
num_im = len(images)
for i, im in enumerate(images):
with open(os.path.join(image_path, im), 'r+b') as f:
with Image.open(f) as image:
image = reshape_image(image, shape)
image.save(os.path.join(output_path, im), image.format)
if (i+1) % 100 == 0:
print ("[{}/{}] Resized the images and saved into '{}'."
.format(i+1, num_im, output_path))
image_path = './data_dir/train2014/'
output_path = './data_dir/resized_images/'
image_shape = [256, 256]
reshape_images(image_path, output_path, image_shape)输出结果如下:
经过图像尺寸统一标准化处理(调整为 256×256 像素),所有输入图像均已适配 CNN 模型架构要求。
2.4 定义数据加载器
在完成数据下载与预处理后,需将数据封装为 PyTorch 数据集对象,进而构建可用于训练循环的数据加载器。
(1) 实现自定义数据加载器:
python
class CustomCocoDataset(data.Dataset):
def __init__(self, data_path, coco_json_path, vocabulary, transform=None):
self.root = data_path
self.coco_data = COCO(coco_json_path)
self.indices = list(self.coco_data.anns.keys())
self.vocabulary = vocabulary
self.transform = transform
def __getitem__(self, idx):
coco_data = self.coco_data
vocabulary = self.vocabulary
annotation_id = self.indices[idx]
caption = coco_data.anns[annotation_id]['caption']
image_id = coco_data.anns[annotation_id]['image_id']
image_path = coco_data.loadImgs(image_id)[0]['file_name']
image = Image.open(os.path.join(self.root, image_path)).convert('RGB')
if self.transform is not None:
image = self.transform(image)
word_tokens = nltk.tokenize.word_tokenize(str(caption).lower())
caption = []
caption.append(vocabulary('<start>'))
caption.extend([vocabulary(token) for token in word_tokens])
caption.append(vocabulary('<end>'))
ground_truth = torch.Tensor(caption)
return image, ground_truth
def __len__(self):
return len(self.indices)自定义 PyTorch Dataset 对象,为实例化、获取数据样本和返回数据集大小分别定义了 __init__、__getitem__ 和 __len__ 方法。
(2) 定义 collate_fn,该函数以 X 和 y 的形式返回数据批次:
python
def collate_function(data_batch):
data_batch.sort(key=lambda d: len(d[1]), reverse=True)
imgs, caps = zip(*data_batch)
imgs = torch.stack(imgs, 0)
cap_lens = [len(cap) for cap in caps]
tgts = torch.zeros(len(caps), max(cap_lens)).long()
for i, cap in enumerate(caps):
end = cap_lens[i]
tgts[i, :end] = cap[:end]
return imgs, tgts, cap_lens通常,我们不需要编写 collate_fn 函数,这里定义 collate_fn 为了处理可变长度的句子。这样,当句子的长度 k 小于固定长度 n 时,需要使用 pack_padded_sequence 函数用 <pad> 词元进行填充。
(3) 最后,实现 get_loader 函数,该函数返回一个用于 COCO 数据集的自定义数据加载器:
python
def get_loader(data_path, coco_json_path, vocabulary, transform, batch_size, shuffle):
coco_dataser = CustomCocoDataset(data_path=data_path,
coco_json_path=coco_json_path,
vocabulary=vocabulary,
transform=transform)
custom_data_loader = torch.utils.data.DataLoader(dataset=coco_dataser,
batch_size=batch_size,
shuffle=shuffle,
collate_fn=collate_function)
return custom_data_loader完成数据管道构建后,开始着手定义模型。
3. 构建图像描述生成模型
3.1 定义 CNN-LSTM 模型
(1) 构建模型,定义两个子模型,包括 CNN 模型和 LSTM 模型:
python
class CNNModel(nn.Module):
def __init__(self, embedding_size):
super(CNNModel, self).__init__()
resnet = models.resnet152(weights=models.ResNet152_Weights.DEFAULT)
module_list = list(resnet.children())[:-1] # delete the last fc layer.
self.resnet_module = nn.Sequential(*module_list)
self.linear_layer = nn.Linear(resnet.fc.in_features, embedding_size)
self.batch_norm = nn.BatchNorm1d(embedding_size, momentum=0.01)
def forward(self, input_images):
with torch.no_grad():
resnet_features = self.resnet_module(input_images)
resnet_features = resnet_features.reshape(resnet_features.size(0), -1)
final_features = self.batch_norm(self.linear_layer(resnet_features))
return final_features对于 CNN 部分,使用了一个预训练的 CNN 模型ResNet 152。移除预训练的 ResNet 模型的最后一层,替换为全连接层+批归一化层组合。
神经网络可以被看作是一系列的权重矩阵,一个预训练的模型则可以被看作是一系列经过精心调整的权重矩阵。通过替换最后一层,实际上是在将最后一个权重矩阵(假设倒数第二层有 K 个神经元,那么是一个 K x 1000 维的矩阵)替换为一个新的随机初始化的权重矩阵( K x 256 维的矩阵,其中 256 是新的输出大小)。
批归一化层 (Batch Normalization Layer) 会对全连接层的输出进行标准化处理,使得整个批次的输出数据均值为 0、标准差为 1。这类似于使用 torch.transforms 进行输入数据归一化的方式,批归一化有助于限制隐藏层输出值的波动范围,通常也能加速模型学习过程。由于优化超平面变得更加均匀(均值为 0,标准差为 1),我们可以采用更高的学习率。
批归一化能够有效隔离 CNN 可能引发的数据偏移,保护 LSTM 子模型不受影响。如果不使用批归一化,那么在最坏情况下,CNN 最后一层可能会在训练时输出均值大于 0.5 且标准差为 1 的值(假设训练数据的分布有限)。但在推理阶段,如果某张图像的 CNN 输出均值小于 0.5 且标准差为 1,那么 LSTM 子模型就会很难在这种新的数据分布上正常工作。因此,我们需要通过批归一化来标准化 CNN 输出(即 LSTM 的输入),从而确保 LSTM 不会产生异常输出。
使用自定义全连接层,因为我们不需要 ResNet 模型输出的 1000 个类别概率,而是希望生成每个图像的嵌入向量。这个嵌入向量可以视为输入图像的一维数值编码表示,随后将被输入到 LSTM 模型中。
(2) LSTM 层接收这些嵌入向量作为输入,并输出一个单词序列------这个序列理想情况下应该能准确描述生成该嵌入向量的图像:
python
class LSTMModel(nn.Module):
def __init__(self, embedding_size, hidden_layer_size, vocabulary_size, num_layers, max_seq_len=20):
super(LSTMModel, self).__init__()
self.embedding_layer = nn.Embedding(vocabulary_size, embedding_size)
self.lstm_layer = nn.LSTM(embedding_size, hidden_layer_size, num_layers, batch_first=True)
self.linear_layer = nn.Linear(hidden_layer_size, vocabulary_size)
self.max_seq_len = max_seq_len
def forward(self, input_features, capts, lens):
embeddings = self.embedding_layer(capts)
embeddings = torch.cat((input_features.unsqueeze(1), embeddings), 1)
lstm_input = pack_padded_sequence(embeddings, lens, batch_first=True)
hidden_variables, _ = self.lstm_layer(lstm_input)
model_outputs = self.linear_layer(hidden_variables[0])
return model_outputsLSTM 模型由 LSTM 层和全连接层组成。在本节中,这些 LSTM 单元将在每个时间步输出单词预测概率,最终将概率最高的单词逐步拼接成完整句子。在每个时间步的 LSTM 单元除了输出预测结果外,还会生成内部单元状态 (cell state),这个状态会作为下一个时间步 LSTM 单元的输入。该过程持续循环,直到某个 LSTM 单元输出 <end> 结束词元。<end> 词元附加到输出句子后,就得到了最终的图像描述文本。
需要注意的是,我们通过 max_seq_len 参数将最大序列长度设定为 20 个单词。这意味着不足 20 个单词的句子,都会在结尾处填充空词元,超过 20 词的则截断保留前 20 词。
理论上,如果我们希望 LSTM 处理任意长度的句子,可以将该值设为极大值(如 9999)。但基于两点考量:首先,现实中极少有图像描述需要这么多词汇;更重要的是,过长的异常序列会导致 LSTM 难以有效学习跨时间步的时序模式。虽然 LSTM 比传统 RNN 在处理较长序列时更有效,但在超长序列上保持记忆仍然困难。考虑到常见图像描述的长度分布,我们选择 20 作为平衡值。
(3) 以上 LSTM 层和线性层对象都继承自 nn.Module,我们通过 __init__ 方法构建模型结构,forward 方法实现前向传播。对于 LSTM 模型,额外实现了一个 sample 方法,该方法采用贪心搜索策略生成句子,即始终选择整体概率最高的单词序列,这对后续图像描述生成非常有用:
python
def sample(self, input_features, lstm_states=None):
sampled_indices = []
lstm_inputs = input_features.unsqueeze(1)
for i in range(self.max_seq_len):
hidden_variables, lstm_states = self.lstm_layer(lstm_inputs, lstm_states) # hiddens: (batch_size, 1, hidden_size)
model_outputs = self.linear_layer(hidden_variables.squeeze(1)) # outputs: (batch_size, vocab_size)
_, predicted_outputs = model_outputs.max(1) # predicted: (batch_size)
sampled_indices.append(predicted_outputs)
lstm_inputs = self.embedding_layer(predicted_outputs) # inputs: (batch_size, embed_size)
lstm_inputs = lstm_inputs.unsqueeze(1) # inputs: (batch_size, 1, embed_size)
sampled_indices = torch.stack(sampled_indices, 1) # sampled_ids: (batch_size, max_seq_length)
return sampled_indices完成了图像描述模型的架构定义后,接下来进入模型训练阶段。
3.2 训练 CNN-LSTM 模型
在完成模型架构定义后,开始训练 CNN-LSTM 模型。
(1) 首先,定义设备:
python
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')(2) 虽然所有图像尺寸都已统一调整为 256×256,但我们仍然需要对数据进行归一化。归一化至关重要,因为不同的数据维度可能存在分布差异,这会导致优化空间扭曲,导致梯度下降效率低下。使用 PyTorch 的 transform 模块归一化输入图像的像素值:
python
if not os.path.exists('models_dir/'):
os.makedirs('models_dir/')
transform = transforms.Compose([
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))])此外,还需要对数据集进行数据增强。数据增强不仅能扩充训练数据规模,更能提升模型对输入数据变化的鲁棒性。使用 PyTorch 的 transform 模块,本节中我们实现了两种数据增强技术:
- 随机裁剪,将图像大小从
(256, 256)缩小到(224, 224)。通过截取图像不同区域,实现了单张图像生成多张样本的效果。这也使得模型能够学习到更具鲁棒性的图像表示,而不仅仅专注于训练数据集中原始的(256, 256)大小的图像 - 图像的水平翻转。这种方法可使数据量翻倍,更多的数据通常意味着更好的效果。对于本节所用的数据集,水平翻转不会改变图像本质语义(翻转后的狗图像依然是狗),因此增强效果显著。但需注意应用场景的适用性,如果我们在做数字识别任务,那么将数字
5的图像水平翻转并继续训练模型去识别它为5会导致模型混淆,因为翻转后的图像看起来更像数字2,而不是5
(3) 加载构建的词汇表,并使用 get_loader() 函数来初始化数据加载器:
python
with open('data_dir/vocabulary.pkl', 'rb') as f:
vocabulary = pickle.load(f)
custom_data_loader = get_loader('data_dir/resized_images', 'data_dir/annotations/captions_train2014.json', vocabulary,
transform, 128,
shuffle=True) (4) 实例化 CNN 和 LSTM 模型,分别作为编码器 (encoder) 和解码器 (decoder),同时定义交叉熵损失函数和 Adam 优化器:
python
encoder_model = CNNModel(256).to(device)
decoder_model = LSTMModel(256, 512, len(vocabulary), 1).to(device)
loss_criterion = nn.CrossEntropyLoss()
parameters = list(decoder_model.parameters()) + list(encoder_model.linear_layer.parameters()) + list(encoder_model.batch_norm.parameters())
optimizer = torch.optim.Adam(parameters, lr=0.001)Adam 优化器在处理稀疏数据时是最佳选择。当前任务同时涉及图像和文本,这两类数据的稀疏性特征明显:图像中并非所有像素都携带有效信息,而数值化/向量化的文本本身就是稀疏矩阵。
(5) 最后执行训练循环,在循环中,使用数据加载器获取 COCO 数据集的小批量数据,先后通过编码器和解码器网络进行前向传播,并最终通过反向传播调整 CNN-LSTM 模型参数:
python
total_num_steps = len(custom_data_loader)
for epoch in range(5):
for i, (imgs, caps, lens) in enumerate(custom_data_loader):
imgs = imgs.to(device)
caps = caps.to(device)
tgts = pack_padded_sequence(caps, lens, batch_first=True)[0]
feats = encoder_model(imgs)
outputs = decoder_model(feats, caps, lens)
loss = loss_criterion(outputs, tgts)
decoder_model.zero_grad()
encoder_model.zero_grad()
loss.backward()
optimizer.step()每完成 1000 次训练迭代,保存一次模型检查点:
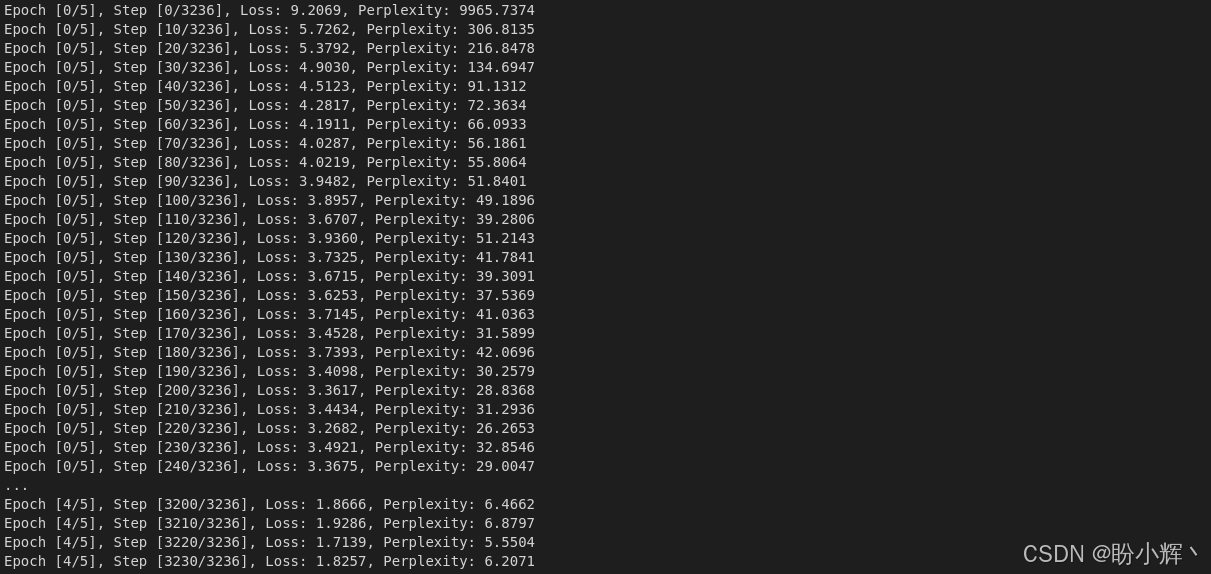
python
if i % 10 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}, Perplexity: {:5.4f}'
.format(epoch, 5, i, total_num_steps, loss.item(), np.exp(loss.item())))
if (i+1) % 1000 == 0:
torch.save(decoder_model.state_dict(), os.path.join(
'models_dir/', 'decoder-{}-{}.ckpt'.format(epoch+1, i+1)))
torch.save(encoder_model.state_dict(), os.path.join(
'models_dir/', 'encoder-{}-{}.ckpt'.format(epoch+1, i+1)))输出结果如下所示:
3.3 使用训练好的模型生成图像描述
在完成图像描述模型的训练后。在本节中,我们将使用训练好的模型为之前未见过的图像生成描述文字。
(1) 准备测试样本 sample.jpg 并定义预处理函数。该函数会加载图像并将其调整为 224×224 像素,随后通过转换模块对像素值进行归一化处理:
python
image_file_path = 'sample.jpg'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def load_image(image_file_path, transform=None):
img = Image.open(image_file_path).convert('RGB')
img = img.resize([224, 224], Image.LANCZOS)
if transform is not None:
img = transform(img).unsqueeze(0)
return img
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))])(2) 加载词汇表并实例化编码器-解码器模型:
python
with open('data_dir/vocabulary.pkl', 'rb') as f:
vocabulary = pickle.load(f)
encoder_model = CNNModel(256).eval() # eval mode (batchnorm uses moving mean/variance)
decoder_model = LSTMModel(256, 512, len(vocabulary), 1)
encoder_model = encoder_model.to(device)
decoder_model = decoder_model.to(device)(3) 准备好模型框架后,使用训练过程中保存的检查点设置模型参数:
python
encoder_model.load_state_dict(torch.load('models_dir/encoder-2-3000.ckpt'))
decoder_model.load_state_dict(torch.load('models_dir/decoder-2-3000.ckpt'))(4) 接下来,加载图像并执行模型推理------也就是说,首先使用编码器生成图像嵌入向量,随后将嵌入向量输入解码器生成序列:
python
img = load_image(image_file_path, transform)
img_tensor = img.to(device)
feat = encoder_model(img_tensor)
sampled_indices = decoder_model.sample(feat)
sampled_indices = sampled_indices[0].cpu().numpy() # (1, max_seq_length) -> (max_seq_length)(5) 此时生成的描述仍为数值词元 (token) 形式,需利用词汇表进行反向转换,将数值词元转换为实际文本:
python
predicted_caption = []
for token_index in sampled_indices:
word = vocabulary.i2w[token_index]
predicted_caption.append(word)
if word == '<end>':
break
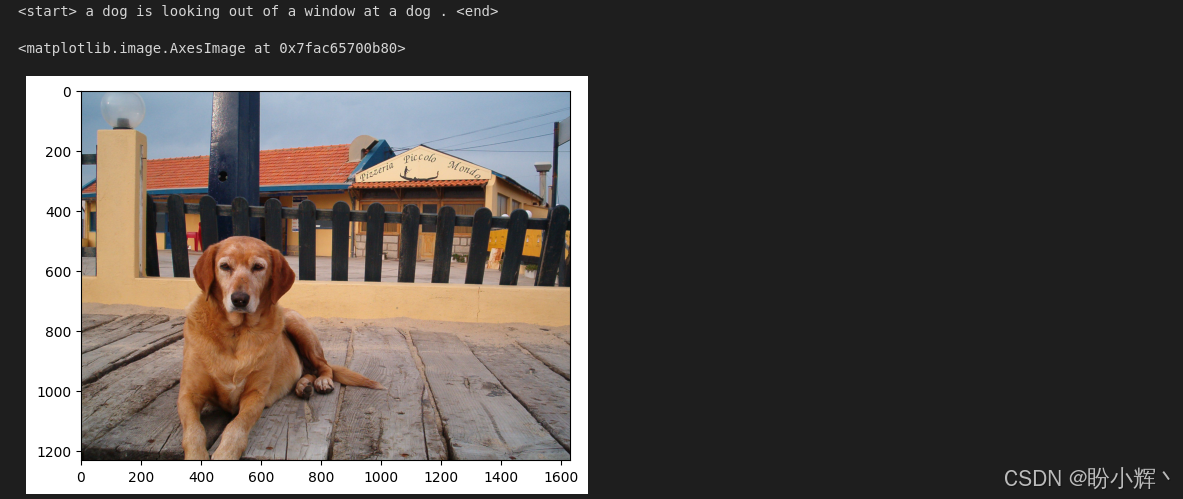
predicted_sentence = ' '.join(predicted_caption)(6) 完成文本转换后,可视化图像及其生成描述:
python
print (predicted_sentence)
img = Image.open(image_file_path)
plt.imshow(np.asarray(img))输出结果如下所示,模型已能生成合理的图像描述:
小结
本节重点探讨了卷积神经网络 (Convolutional Neural Network, CNN) 与长短期记忆网络 (Long Short-Term Memory, LSTM) 在编码器-解码器框架中的协同应用,包括:两种模型的联合训练方法,以及组合模型在图像描述生成中的应用。
系列链接
PyTorch实战(1)------深度学习概述
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络