- 作者: Sheng Fan, Rui Liu, Wenguan Wang, Yi Yang
- 单位:浙江大学
- 论文标题: Scene Map-based Prompt Tuning for Navigation Instruction Generation
- 论文链接:https://openaccess.thecvf.com/content/CVPR2025/papers/Fan_Scene_Map-based_Prompt_Tuning_for_Navigation_Instruction_Generation_CVPR_2025_paper.pdf
- 代码链接:https://github.com/FanScy/MAPInstructor (Coming soon)
主要贡献
- 提出了基于场景图提示调整的导航指令生成框架 MAPINSTRUCTOR,通过将地图上下文纳入大语言模型(LLM)中,以参数高效的方式更新 LLM,从而提高了导航指令生成的质量。
- 设计了三个关键组件:场景表示编码 、地图提示调整 和地标不确定性评估,分别用于细粒度场景理解、整合全局地图信息以及减少地标预测中的幻觉现象,增强了指令生成的可靠性和连贯性。
- 在 R2R、REVERIE、RxR 三个导航数据集上的广泛实验表明,该算法具有良好的泛化能力和有效性,与现有方法相比取得了显著的性能提升。
研究背景
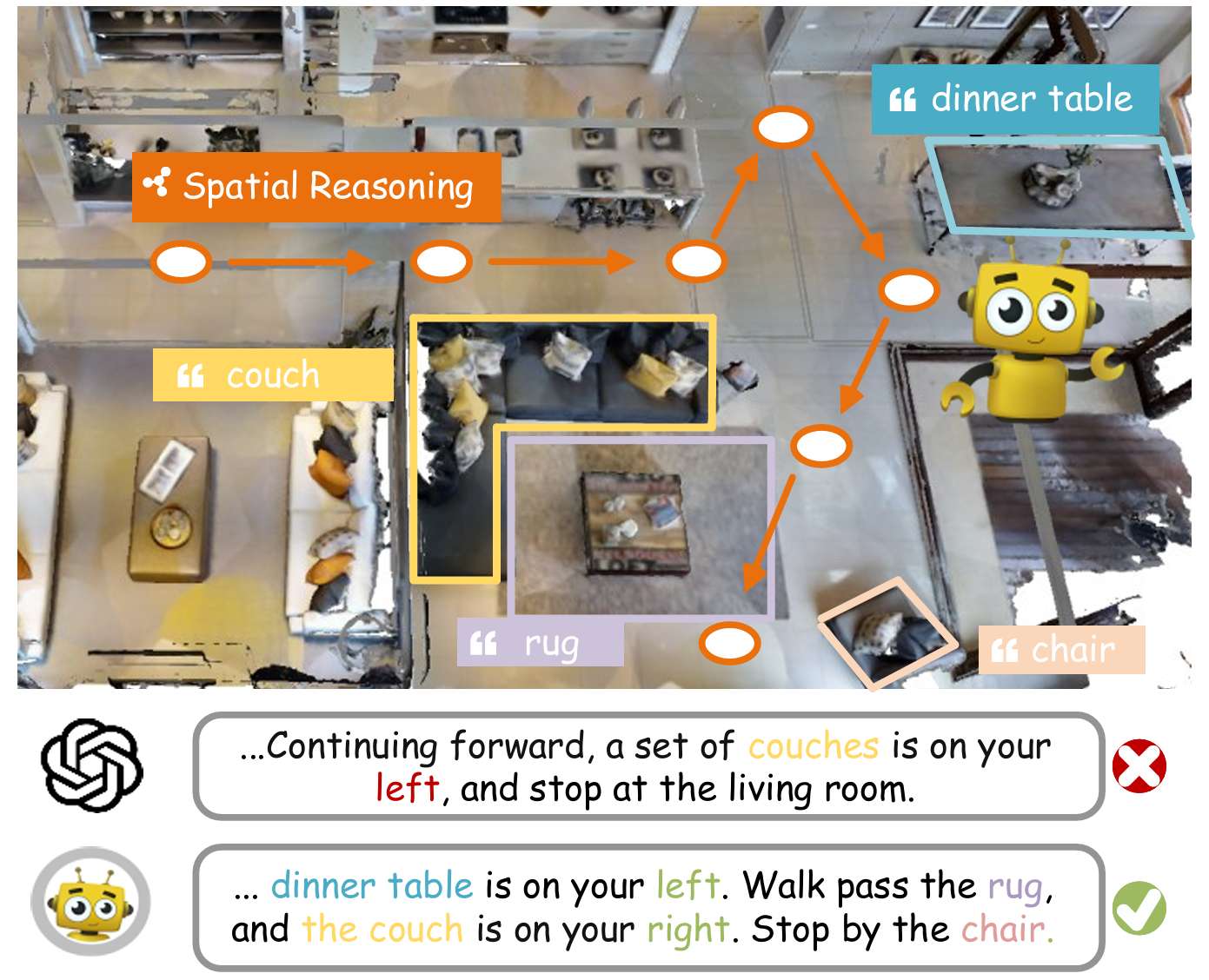
- 导航指令生成(Navigation Instruction Generation, NIG)是具身智能中的一个重要任务,它要求具身智能体(embodied agent)使用自然语言提供导航轨迹的详细描述,对于实现人机通过自然语言进行沟通和协作的具身智能体至关重要。
- 早期的数据驱动方法直接将过去的观测序列映射到有限数据集上的轨迹描述,缺乏对复杂 3D 环境中空间关系的理解。近期的研究虽然利用大语言模型(LLM)来提升 NIG 的性能,但往往忽略了导航中的全局空间上下文,例如地图中固有的空间离散化。
- 现有的 NIG 方法存在一些挑战,如将高度感知特征压缩到 BEV(鸟瞰图)平面上会损失 3D 环境的整体结构,导致关键空间信息的丢失;此外,通过文本描述将地图信息整合到 LLM 中的方法需要大量的数据标注和模型训练,并且在零样本或少样本设置中难以捕捉到细粒度的场景细节,从而遗漏关键地标。
方法
问题定义
- 任务描述 :导航指令生成(NIG)任务要求根据一系列导航动作和对应的全景视图生成自然语言指令。具体来说,给定一系列的全景视图 O={Ot}t=1TO = \{O_t\}{t=1}^TO={Ot}t=1T 和动作 A={at}t=1TA = \{a_t\}{t=1}^TA={at}t=1T,模型需要生成一个由 LLL 个单词组成的指令 X={xl}l=1LX = \{x_l\}_{l=1}^LX={xl}l=1L。
- 数学表达 :模型的目标是最大化以下条件概率:
maxΘ∑l=1LlogPΘ(xl∣x<l,O,A) \max_{\Theta} \sum_{l=1}^L \log P_{\Theta}(x_l | x_{\lt l}, O, A) Θmaxl=1∑LlogPΘ(xl∣x<l,O,A)
其中,Θ\ThetaΘ 表示模型参数,x<lx_{\lt l}x<l 表示已经生成的单词序列。
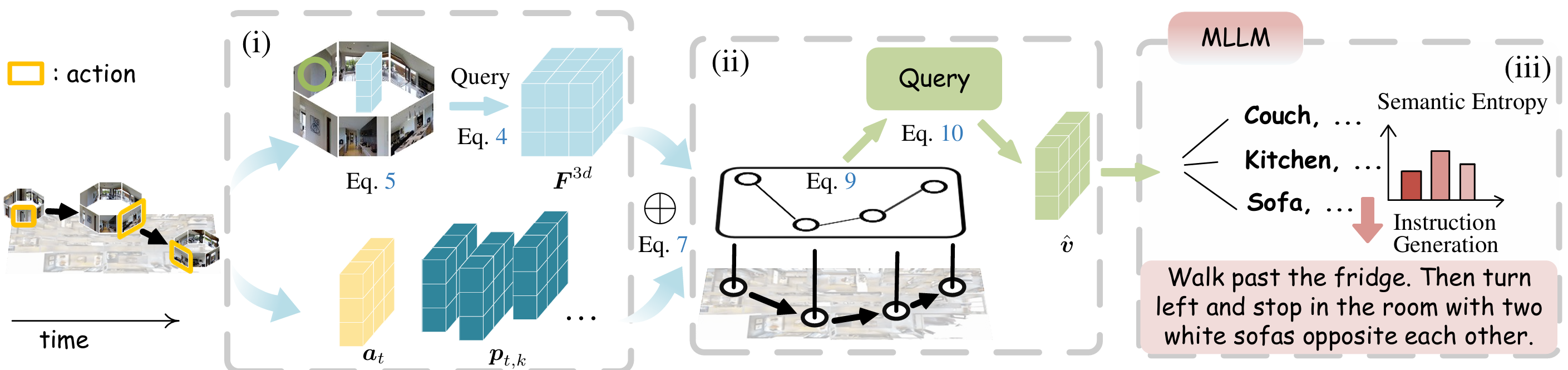
场景表示编码
-
视角-动作嵌入:
- 从全景视图中提取密集的语义表示,结合视角嵌入和动作嵌入。
- 视角嵌入计算公式为:
pt,k=Ep(F2dt,k)+Eδ(rt,k)+Et+Eo p_{t,k} = E_p(F_{2d}^{t,k}) + E_{\delta}(r_{t,k}) + E_t + E_o pt,k=Ep(F2dt,k)+Eδ(rt,k)+Et+Eo
其中,EpE_pEp 和 EδE_{\delta}Eδ 是线性嵌入层,EtE_tEt 和 EoE_oEo 是可学习的步长嵌入和全景观察标记类型嵌入。 - 动作嵌入与视角嵌入类似,计算公式为:
at=Ea(F2dt,a)+Eδ(rt,a)+Et+Ea a_t = E_a(F_{2d}^{t,a}) + E_{\delta}(r_{t,a}) + E_t + E_a at=Ea(F2dt,a)+Eδ(rt,a)+Et+Ea
其中,EaE_aEa 是线性层,EaE_aEa 是可学习的动作标记类型嵌入。
-
视角-3D变换:
- 使用 CrossView Attention(CVA)将视角特征融合到统一的 3D 表示中,通过一组可学习的 3D 查询 QQQ 从周围 KKK 个视角特征中采样信息。
- 3D 特征计算公式为:
F3d=1K∑k=1KFcva(Q,Pk,F2dk) F_{3d} = \frac{1}{K} \sum_{k=1}^K F_{cva}(Q, P_k, F_{2d}^k) F3d=K1k=1∑KFcva(Q,Pk,F2dk)
其中,FcvaF_{cva}Fcva 使用可变形注意力(deformable attention)聚合信息。
-
多尺度场景预测:
- 将视角-3D变换分解为多个尺度,使用不同层次的 3D 可变形注意力层提取多尺度 3D 特征。
- 通过上采样函数 F↑F_{\uparrow}F↑ 将低尺度特征上采样到高尺度,得到最终的 3D 特征。
-
场景表示:
- 将视角-3D特征对连接起来,映射到统一的表示 vtv_tvt 中:
vt=Fs(F3dt⊕pt⊕at) v_t = F_s(F_{3d}\^t \\oplus p_t \\oplus a_t) vt=Fs(F3dt⊕pt⊕at)
其中,⊕\oplus⊕ 表示广播和加法操作,FsF_sFs 是由多个线性层组成的嵌入模块。
- 将视角-3D特征对连接起来,映射到统一的表示 vtv_tvt 中:
地图提示调整
-
拓扑地图构建:
- 将导航轨迹表示为有向图 G=(V,E)G = (V, E)G=(V,E),每个节点 v∈Vv \in Vv∈V 表示一个观测点,包含位置编码和导航步长编码。
- 节点表示的更新公式为:
v~t=vt+vloct \tilde{v}t = v_t + v{loc}^t v~t=vt+vloct
其中,vloctv_{loc}^tvloct 是从欧几里得距离 ddd 中派生的位置编码。 - 使用图神经网络(GNN)对节点间的交互进行建模,通过消息传递更新节点表示。
-
地图提示调整:
- 将全局场景理解整合到基于 LLM 的智能体中,使用轻量级的 Transformer 解码器架构将场景图作为提示特征整合到 LLM 中。
- 通过单个查询 QvQ_vQv 将节点特征 v~′\tilde{v}'v~′ 映射到固定长度的张量 v^\hat{v}v^:
v^=Fdecoder(Qv,v~′) \hat{v} = F_{decoder}(Q_v, \tilde{v}') v^=Fdecoder(Qv,v~′) - 使用 v^\hat{v}v^ 逐步生成指令:
xl=FLLM(v^;xl−1) x_l = F_{LLM}(\hat{v}; x_{l-1}) xl=FLLM(v^;xl−1)
地标不确定性评估
-
地标预测和指令完成:
- 将指令生成过程分解为地标预测和指令完成两个阶段。
- 在地标预测阶段,生成 MMM 个关键地标序列 {s1,...,sM}\{s_1, \ldots, s_M\}{s1,...,sM}:
sml=FLLM(v^;sml−1),m=1,...,M s_m^l = F_{LLM}(\hat{v}; s_m^{l-1}), \quad m = 1, \ldots, M sml=FLLM(v^;sml−1),m=1,...,M
-
地标语义熵:
- 使用地标语义熵来评估地标预测的语义一致性,通过 Deberta-large 模型评估地标列表的语义相似性。
- 计算地标语义熵公式为:
LE(v)=−∑cp(c∣v^)logp(c∣v^) LE(v) = -\sum_{c} p(c | \hat{v}) \log p(c | \hat{v}) LE(v)=−c∑p(c∣v^)logp(c∣v^)
其中,ccc 表示地标列表的语义聚类。 - 如果 LE(v)≤τLE(v) \leq \tauLE(v)≤τ,则认为地标预测是语义确定的,否则需要重新采样地标。
实现细节
- 网络架构:基于 Llama-7B 模型构建,使用 2D 和 3D 特征分辨率分别为 (14,14) 和 (7,7,7)。
- 训练:采用两阶段训练策略,先进行地标预测,再进行指令完成。使用 GPT-4 提取训练集中的真实地标作为标签。
- 推理 :在推理阶段,进行 3 轮地标预测,评估地标语义熵。如果 LE(v)>τLE(v) > \tauLE(v)>τ,则随机采样地标预测以创建新的地标提示。
- 可复现性:使用 PyTorch 框架实现,在单机上使用 2 个 NVIDIA A40 GPU 进行训练。
实验
实验设置
-
数据集:
- R2R:VLN任务的经典数据集,包含从Matterport3D环境中收集的导航路径和对应的自然语言指令。
- REVERIE:以物体为中心的数据集,强调物体检测能力。
- RxR:更具挑战性的多语言VLN数据集,包含更复杂的指令和路径。
-
评估指标:
- 使用BLEU、CIDEr、METEOR、ROUGE和SPICE等评估指标来衡量生成导航指令的质量。这些指标从不同角度评估生成指令的准确性、多样性和语义相关性。
定量结果
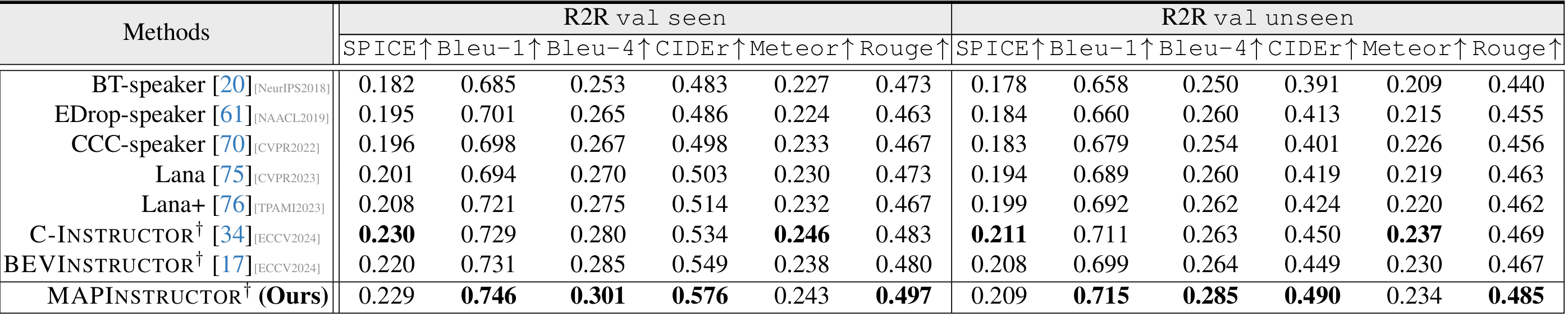
- R2R数据集上的性能:MAPINSTRUCTOR在val seen和unseen分割上的大多数评估指标上均优于其他方法,特别是在CIDEr指标上,分别比其他方法高出2.7%和4.0%,这表明了MAPINSTRUCTOR在指令生成质量和泛化能力上的优势。
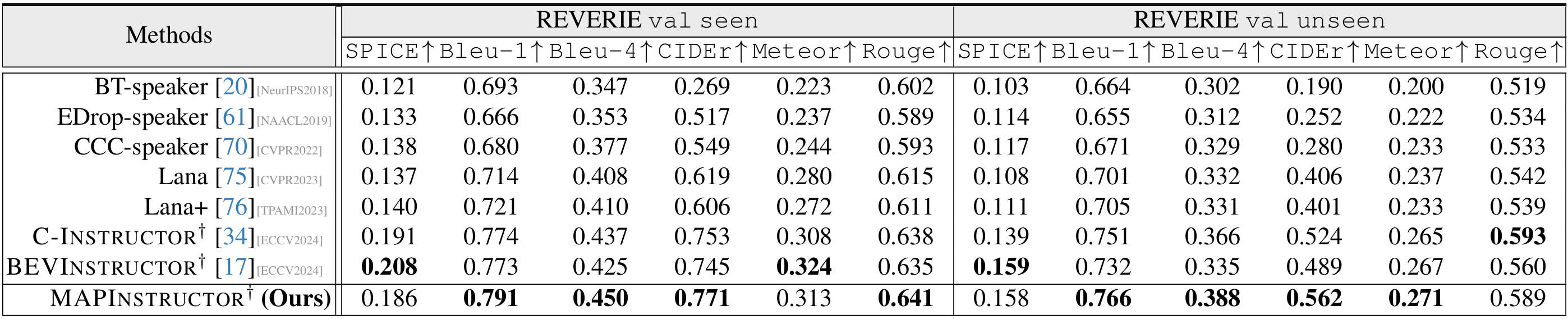
- REVERIE数据集上的性能:尽管REVERIE数据集更注重物体检测能力,MAPINSTRUCTOR仍然表现出色,在大多数评估指标上领先于其他方法。与BEVInstructor相比,MAPINSTRUCTOR在seen和unseen分割上的CIDEr指标分别高出1.8%和3.8%,这进一步证明了MAPINSTRUCTOR在场景理解方面的优势。
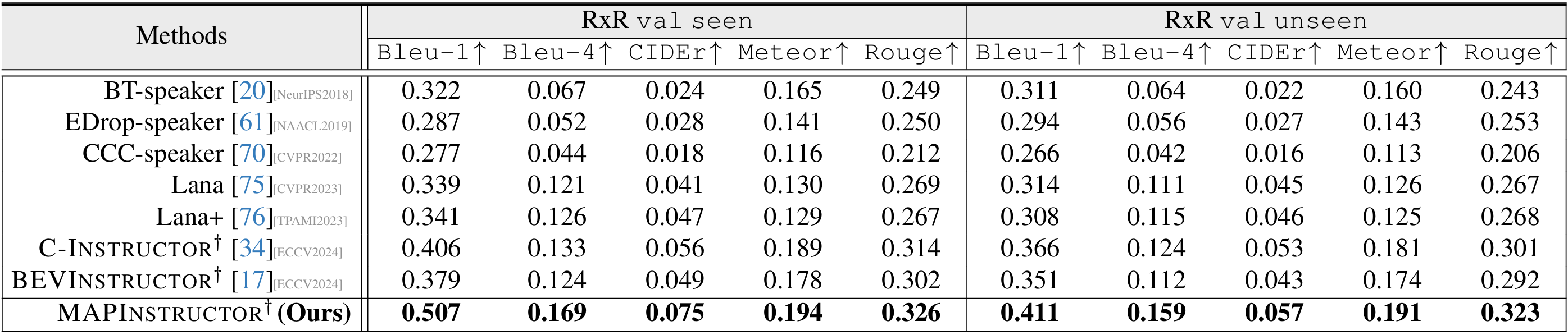
- RxR数据集上的性能:MAPINSTRUCTOR在所有评估指标上均取得了最佳性能,尤其是在val unseen分割上,分别比其他方法高出4.5%、3.5%、0.4%、1.0%和2.2%。这表明MAPINSTRUCTOR在处理更灵活的指令形式时具有更高的有效性。
定性结果
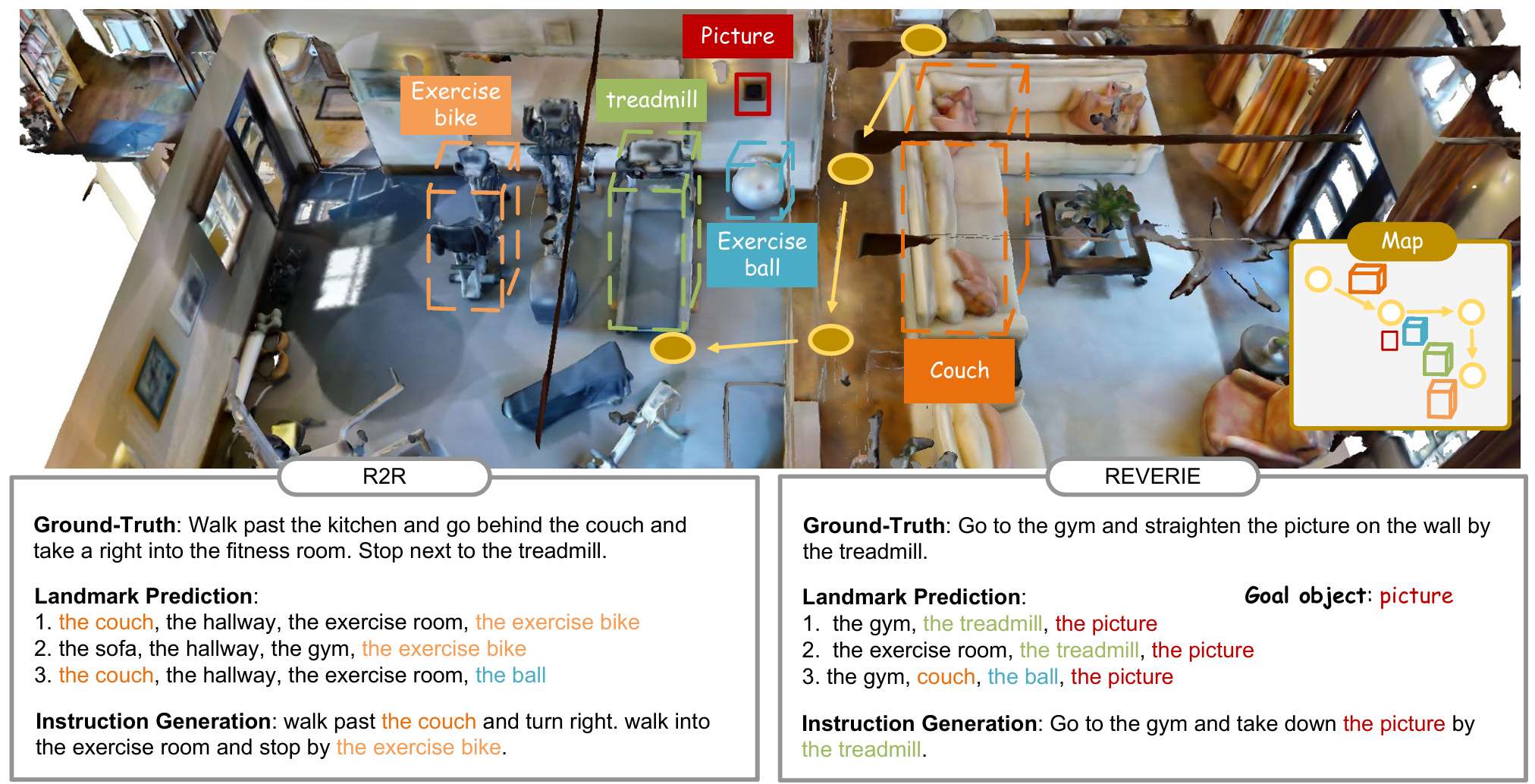
- MAPINSTRUCTOR能够有效地捕捉轨迹中的细粒度地标,例如在REVERIE数据集中的目标物体"picture"。这得益于场景表示编码模块,它能够提供更准确的地标检测。
- 地图提示调整提供了重要的空间线索,使得MAPINSTRUCTOR能够生成更准确的动作预测指令,例如"turn right"。
- 通过地标不确定性评估,MAPINSTRUCTOR能够生成多轮地标序列,过滤掉潜在的错误地标,从而提高指令的准确性和可靠性。
诊断实验
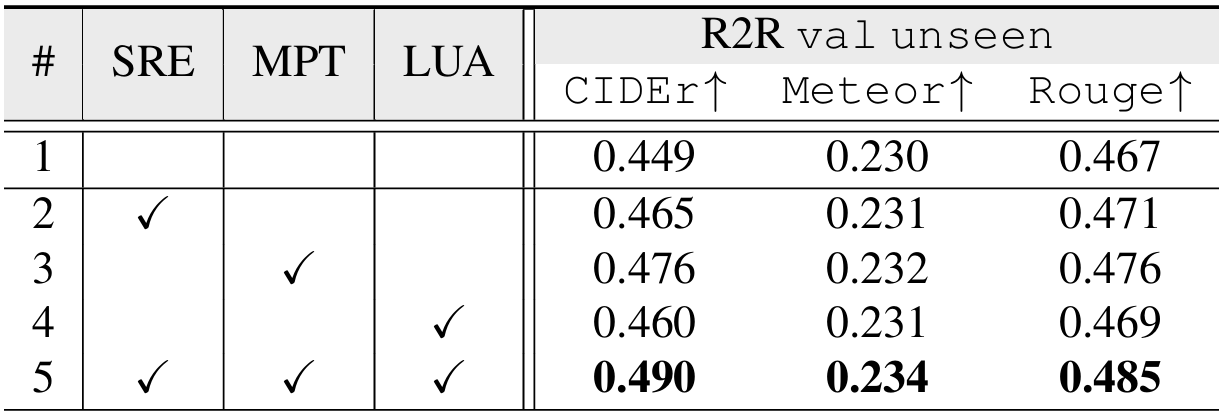
- 关键组件分析:上表展示了MAPINSTRUCTOR中三个核心组件(场景表示编码、地图提示调整和地标不确定性评估)的消融研究结果。实验表明,每个组件都对性能提升有显著贡献。结合所有组件后,MAPINSTRUCTOR在R2R数据集的val unseen分割上取得了最佳性能。

- 场景构建方法比较:上表比较了不同的场景构建方法,包括BEV特征和MAPINSTRUCTOR中使用的3D表示。结果表明,3D表示在目标级检测方面更有优势,因为它能够提供更细粒度的场景理解。
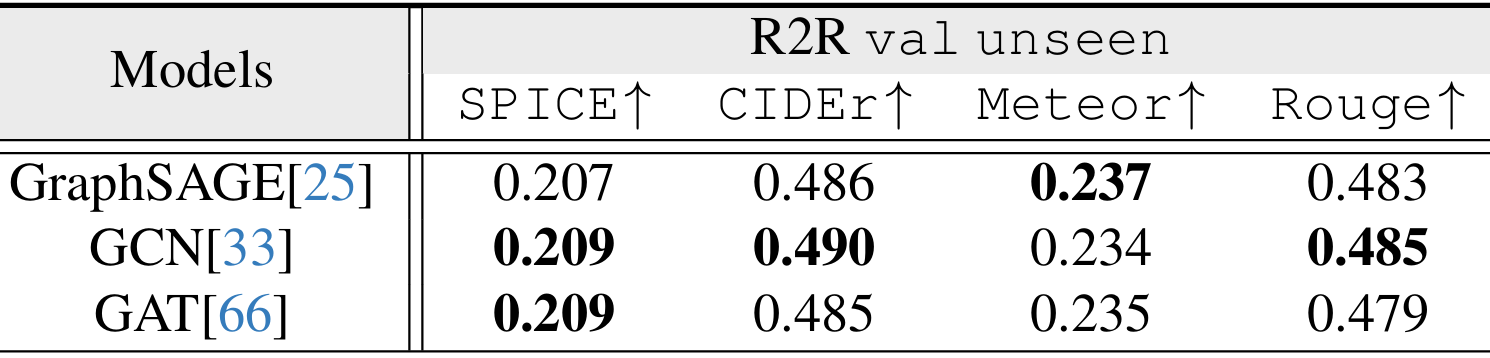
- 映射架构比较:上表比较了不同的图神经网络方法,如GraphSAGE、GCN和GAT。这些方法在指令生成性能上表现出相似的效果,表明在静态几何地图导航中,基于消息传递的方法能够实现可比的性能。
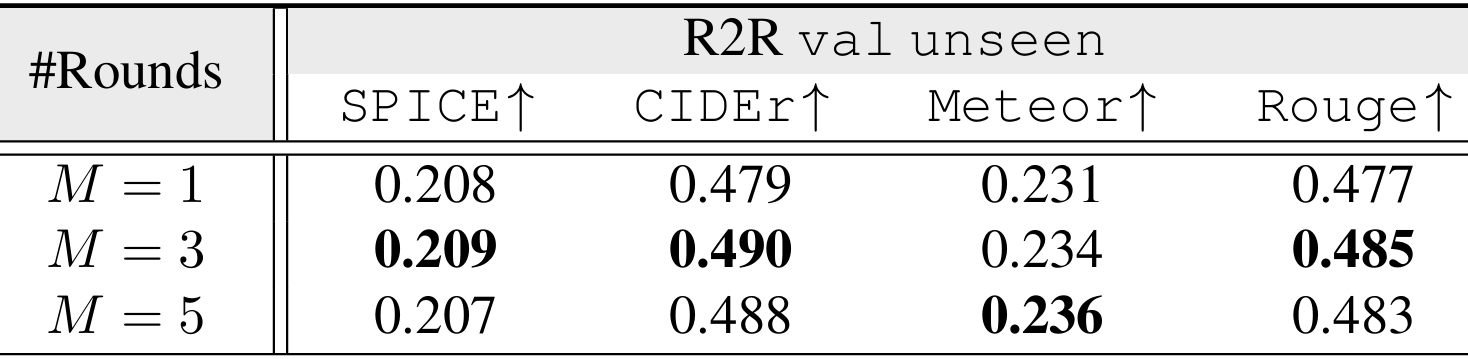
- 地标不确定性评估轮次分析:上表分析了不同轮次的地标不确定性评估对性能的影响。结果表明,与单轮地标预测相比,多轮评估能够提升性能,但随着轮次增加,性能提升逐渐趋于平稳。
指令质量分析
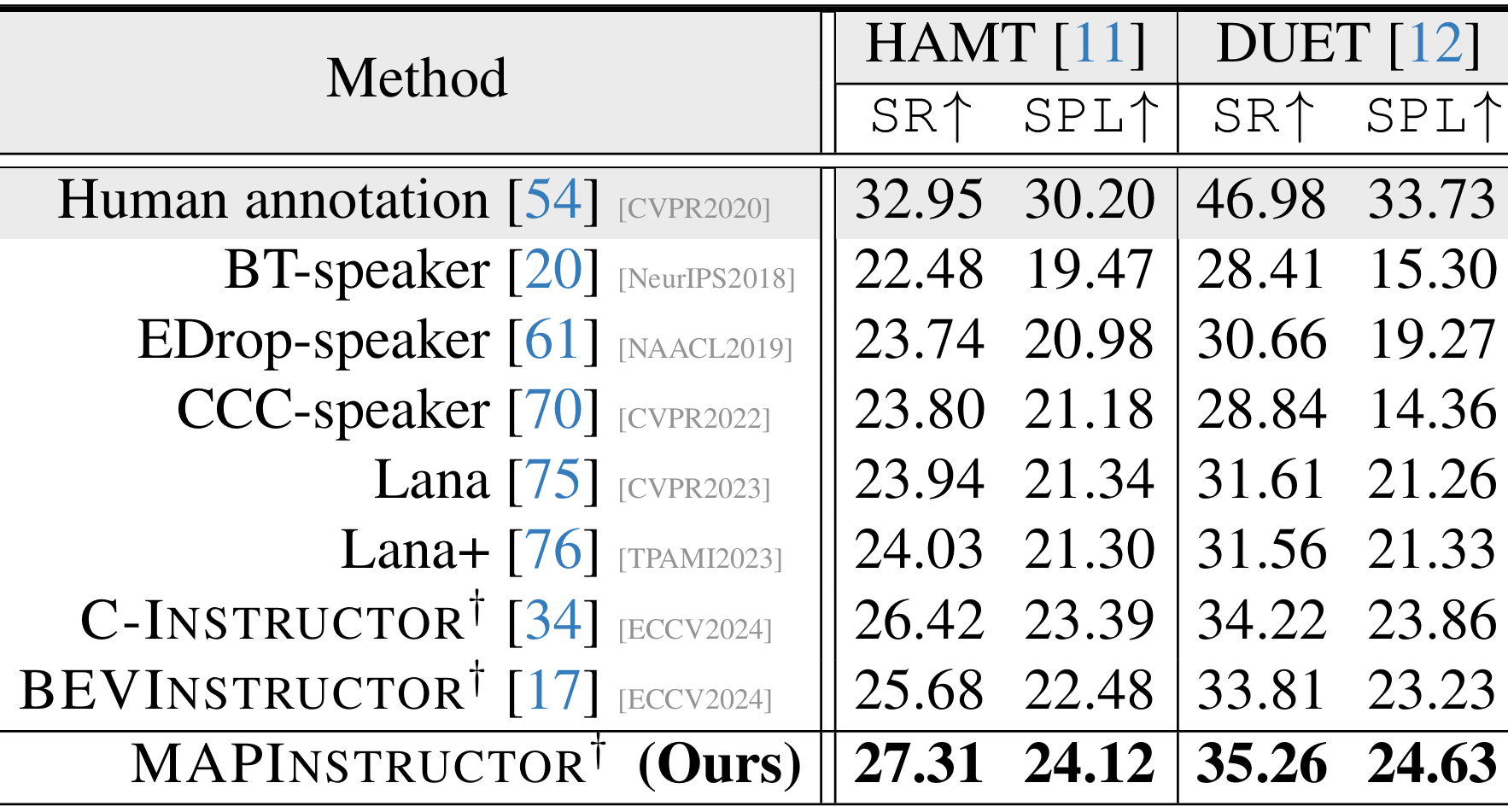
- 路径引导能力:上表展示了使用不同NIG模型生成的指令来引导VLN模型(如HAMT和DUET)进行导航的性能。MAPINSTRUCTOR生成的指令在成功率(SR)和路径长度加权成功率(SPL)上表现出色,接近人类标注的指令。
-
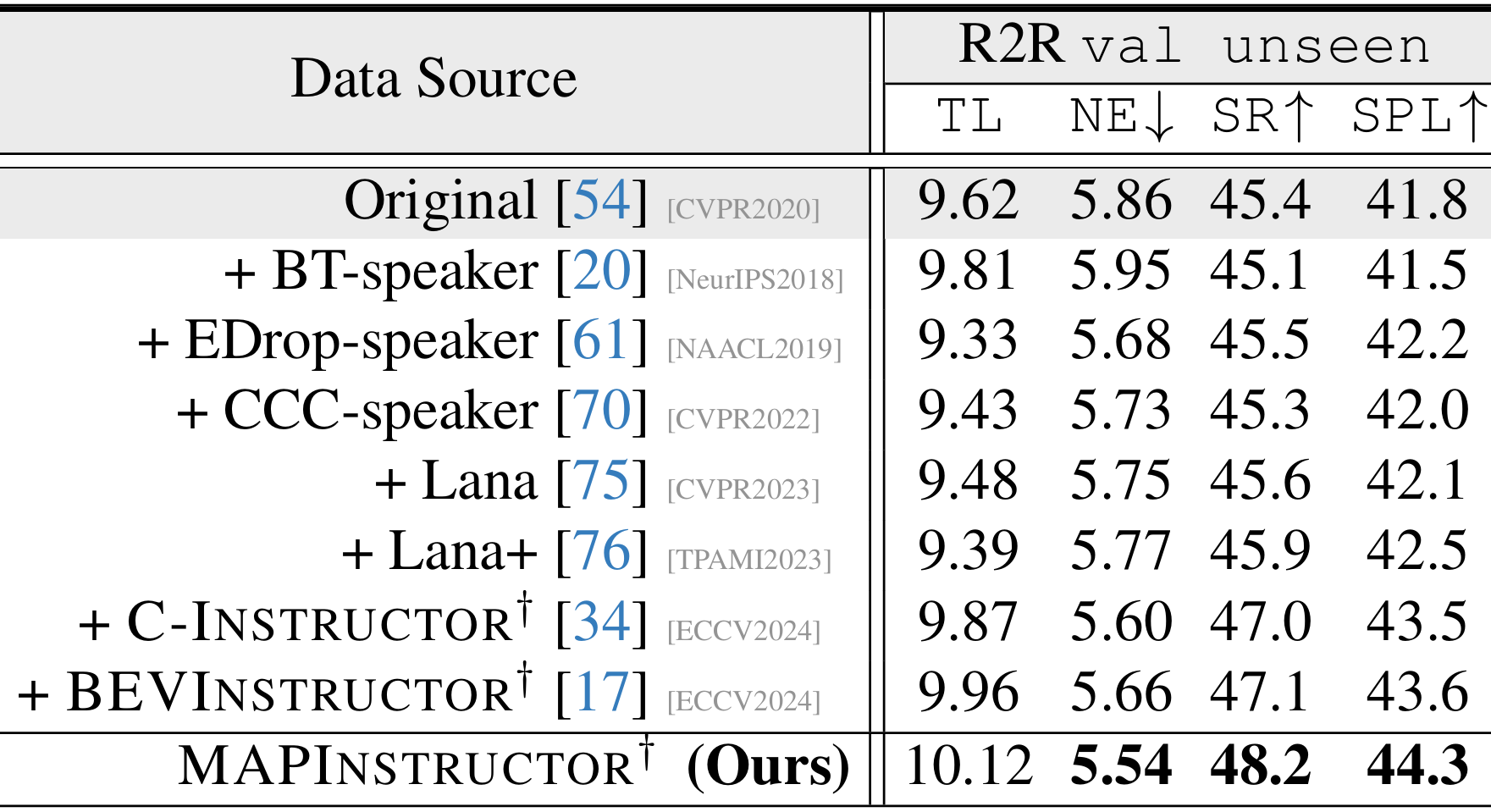
数据增强:上表展示了使用MAPINSTRUCTOR生成的指令作为数据增强,用于训练EDropfollower模型的结果。MAPINSTRUCTOR在R2R数据集的val unseen分割上显著提升了SR和SPL指标,表明其生成的指令具有高质量。
-
用户研究:通过邀请30名大学生对不同模型生成的100条指令进行评分,MAPINSTRUCTOR在指令的多样性和语义一致性方面得分最高,平均得分为4.11,优于其他模型。这进一步证明了MAPINSTRUCTOR生成指令的质量和泛化能力。
结论与未来工作
- 结论 :
- MAPINSTRUCTOR 通过将拓扑地图连接作为提示特征整合到 LLM 中,有效地解决了 NIG 中的空间场景理解问题,在复杂室内环境中取得了令人满意的性能。
- 该框架在局部场景表示上采用了 3D 体素表示,以实现更细粒度的对象级检测,并引入了地标不确定性评估流程,以减少地标预测中的幻觉现象。
- 在多个导航数据集上的实验结果验证了其优于现有方法的性能。
- 未来工作 :
- 将探索更多基于 LLM 的 NIG 框架,以增强空间智能。
