论文标题 :Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
作者 :Qi Fan, Wei Zhuo, Chi-Keung Tang, Yu-Wing Tai
发表会议 :CVPR 2020
论文链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Fan_Few-Shot_Object_Detection_With_Attention-RPN_and_Multi-Relation_Detector_CVPR_2020_paper.pdf
代码与数据集:https://github.com/fanq15/Few-Shot-Object-Detection-Dataset关键词:小样本目标检测(Few-Shot Object Detection, FSOD)、注意力机制(Attention Mechanism)、区域建议网络(Region Proposal Network, RPN)、多关系检测器(Multi-Relation Detector)、对比训练(Contrastive Training)、支持集与查询集(Support-Query Pair)、特征匹配(Feature Matching)、跨域泛化(Cross-Domain Generalization)
一、文章背景:从"数据饥渴"到"小样本学习"
传统的目标检测模型(如Faster R-CNN、YOLO、SSD等)依赖于大量高质量标注数据进行训练。然而,在现实世界中,获取大量标注数据不仅成本高昂,而且在某些特定领域(如罕见动物、医疗影像、工业缺陷检测)几乎不可行。因此,如何让模型在仅提供少量样本(Few-Shot)的情况下,快速识别并定位新类别的目标,成为计算机视觉领域的重要研究方向。
本文提出了一种全新的小样本目标检测(Few-Shot Object Detection, FSOD)框架,旨在仅用几个标注样本,就能检测出图像中从未见过的物体类别。该方法的核心创新在于:
- Attention-RPN:基于注意力机制的区域建议网络,能够根据支持图像(Support Image)动态筛选候选区域;
- Multi-Relation Detector:多关系检测器,通过多种匹配关系增强模型对正负样本的区分能力;
- Contrastive Training Strategy:对比式训练策略,使模型在训练阶段就学会区分"同类"与"异类";
- FSOD数据集:作者构建了一个包含1000个类别的高质量小样本检测数据集,为后续研究提供了重要基准。
二、问题定义:什么是小样本目标检测?
小样本目标检测的任务可以形式化为:给定一个支持图像 ,其中包含某个目标类别的清晰示例(通常是一个带标注框的局部图像),以及一个查询图像
,该图像可能包含多个属于支持类别 c 的目标实例,模型需要在查询图像中准确地定位所有同类目标。
如果支持集中包含 N 个类别,每个类别有 K 个样本,则该任务被称为 N-way K-shot detection。例如,5-way 1-shot 表示模型需要同时识别5个新类别,每个类别仅提供1个样本。
这一任务的关键挑战在于:
- 如何在没有类别先验知识的情况下,定位新类别的目标?
- 如何在复杂背景中抑制误检?
- 如何从极少量样本中提取具有泛化能力的特征?
三、核心方法:Attention-RPN + Multi-Relation Detector
3.1 整体架构
论文提出的网络架构如图所示:
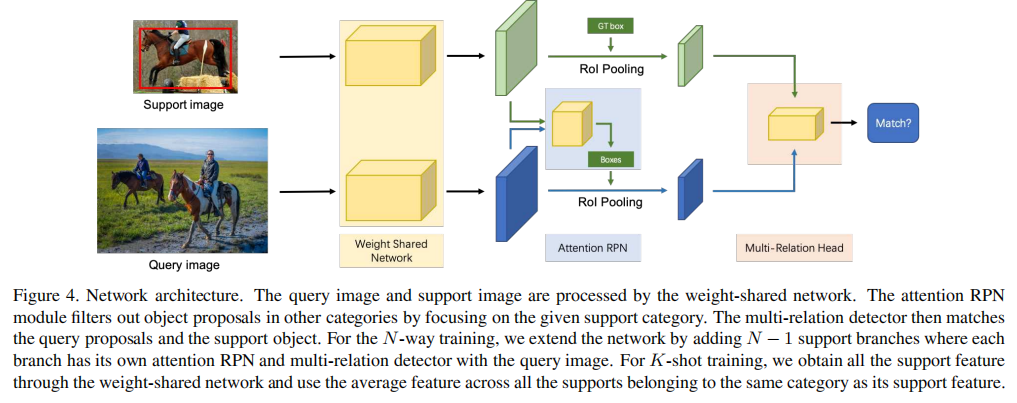
该网络架构中查询图像和支持图像通过权重共享的骨干网络处理。Attention-RPN模块根据支持类别过滤候选区域。Multi-Relation Detector模块进一步匹配查询候选框与支持目标。对于N-way训练,网络扩展为多个支持分支。
整个系统基于Faster R-CNN框架,但引入了两个关键模块:
- Attention-RPN:改进区域建议网络(RPN),使其能根据支持图像动态调整候选框生成;
- Multi-Relation Detector:替换原Faster R-CNN的分类头,通过多关系匹配机制进行类别判别。
网络采用权重共享结构,查询图像和支持图像通过同一个骨干网络(如ResNet-50)提取特征,确保特征空间对齐。
3.2 Attention-RPN:让RPN"看见"支持图像
传统RPN是类别无关的(class-agnostic),它只能判断某个区域是否为"物体",但无法区分属于哪个类别。在小样本场景下,这会导致大量无关候选框被送入检测器,增加误检风险。
为此,作者提出 Attention-RPN,其结构如图所示:
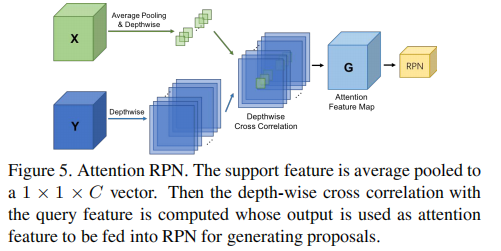
该结构支持特征经平均池化后得到1×1×C向量,与查询特征进行逐通道相关运算,生成注意力图,用于指导RPN生成候选框。
工作原理:
- 支持图像特征
经过全局平均池化,得到 1×1×C 的向量;
- 该向量作为"核",在查询图像特征图
- 得到的注意力图 G 被送入RPN,用于生成候选框。
公式表示:
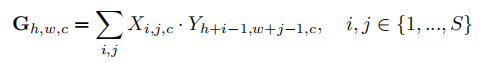
该机制使得RPN在生成候选框时,优先关注与支持图像特征相似的区域,从而显著提升候选框质量。
实验验证:
- Recall@100 IoU=0.5 :Attention-RPN 达到 0.9130 ,优于传统RPN的 0.8804;
- ABO(Average Best Overlap) :Attention-RPN 为 0.7282 ,优于传统RPN的 0.7127。
这表明Attention-RPN能生成更多高质量候选框,为后续检测奠定基础。
3.3 Multi-Relation Detector:多维度匹配机制
即使RPN生成了高质量候选框,检测器仍需判断这些候选框是否真正属于支持类别。为此,作者设计了 Multi-Relation Detector,如图所示:
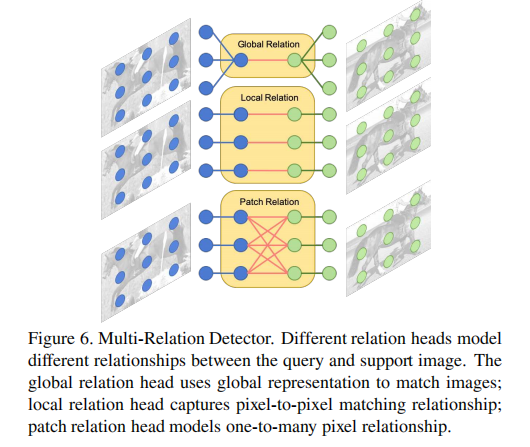
该检测器包含三个并行的"关系头"(Relation Heads),分别从不同粒度建模查询候选框与支持图像之间的相似性:
| 关系头 | 作用 | 特点 |
|---|---|---|
| Global Relation Head | 全局特征匹配 | 使用全局平均池化后的特征进行匹配,适合整体外观相似的目标 |
| Local Relation Head | 像素级匹配 | 计算支持图像与候选区域之间的逐像素相关性,对局部细节敏感 |
| Patch Relation Head | 块状匹配 | 将图像划分为多个patch,建模"一对多"匹配关系,适合纹理复杂的目标 |
消融实验结果:
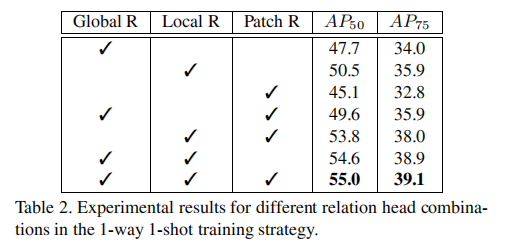
实验表明,Local Relation Head 单独表现最好,但三者联合使用 能获得最佳性能,说明不同关系头具有互补性。
3.4 对比式训练策略:2-Way Contrastive Training
传统训练方式仅匹配"同类"样本对(如 ),但忽略了"异类"样本的区分能力。为此,作者提出 2-Way Contrastive Training 策略。
训练三元组构建:
随机选择:
- 一个查询图像
- 一个正支持图像
- 一个负支持图像
构成三元组 。
匹配对设计:
- 正匹配对 :前景候选框 + 正支持图像
- 负匹配对 :背景候选框 + 正支持图像
- 负匹配对 :任意候选框 + 负支持图像
训练时,按 1:2:1 的比例采样这三类匹配对,计算二元交叉熵损失。
实验效果:
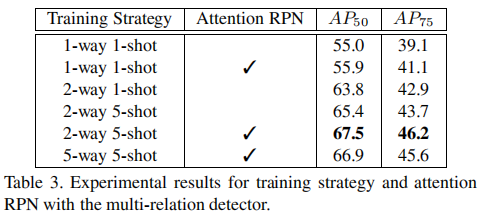
结果表明,①. 2-way 1-shot对比训练与传统的1-way 1-shot训练相比,使AP50提升了 7.9%,验证了对比式训练策略的有效性。②. 不同的训练策略中,2-way 5-shot对比训练获得最佳性能。③. 5-way并没有比2-way训练策略产生更好的性能,表明在训练模型以区分不同类别时,仅一个负支持类别就可以。
四、FSOD数据集:首个大规模小样本检测基准
为推动小样本目标检测研究,作者构建了 FSOD(Few-Shot Object Detection)数据集。
4.1 数据集构建流程
- 数据来源:整合 MS COCO、ImageNet、Open Images 等数据集;
- 标签统一:合并语义相同的类别(如"polar bear"与"ice bear");
- 质量筛选:去除标注错误、边界框过小(<0.05%图像面积)的样本;
- 划分策略 :训练集800类,测试集200类,类别完全不重叠,确保评估模型泛化能力。

FSOD标签树如上图所示。ImageNet类别(红圈)与Open Images类别(绿圈)融合,形成统一的层级结构。
文中将来自不同数据集的类别进行语义对齐,从而构建一个统一的、无歧义的标签体系,为跨数据集融合奠定基础。
4.2 数据集统计
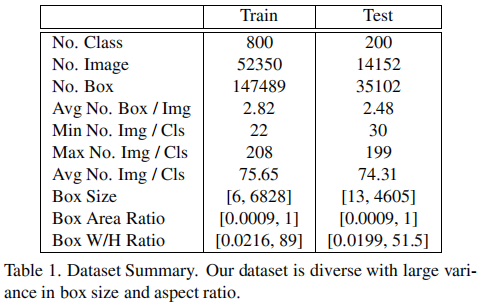
FSOD数据集共1000类,66,502张图像,182,591个标注框。
4.3 数据集特点
- 高多样性:涵盖83个父类(如哺乳动物、服装、武器等);
- 挑战性强:测试集中26.5%的图像包含≥3个目标;
- 类别不重叠:训练与测试类别完全分离,真正考验泛化能力。
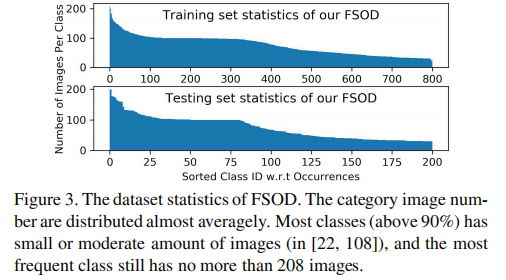
FSOD数据集中大多数类别样本数在22~108之间,符合小样本设定。
五、实验结果:SOTA性能
5.1 定性结果展示

可以直观看到模型的强大泛化能力:仅凭一个支持样本,模型就能在复杂场景中准确检测出多个同类目标,且几乎没有误检。
5.2 与SOTA方法对比

本文方法无需进一步的训练和微调,即可获得SOTA性能。
5.3 与SOTA方法对比(ImageNet Detection数据集)
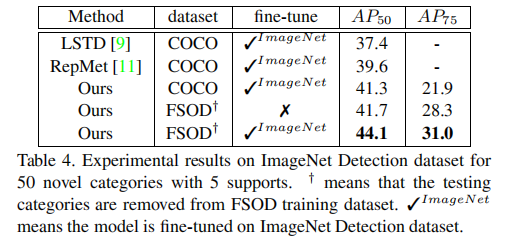
本文方法提升超过30个百分点,达到新的SOTA水平。
5.4 与SOTA方法对比(MS COCO数据集)
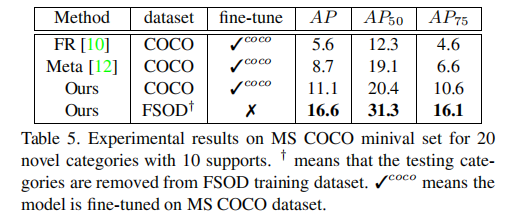
在MS COCO数据集上的性能对比显示,本方法在未针对COCO微调的情况下,仍取得优异表现。
Tips :本文方法不仅在自建FSOD数据集上表现优异,还能无缝迁移到其他主流检测数据集,展现出强大的跨域泛化能力。
5.5 消融实验总结
- Attention-RPN 提升AP50约2.0%;
- Multi-Relation Detector 提升AP50约5.0%;
- 对比训练策略提升AP50约7.9%;
- 三者结合实现端到端无需微调的小样本检测。
六、总结与启示
核心贡献
- 提出 Attention-RPN,首次将支持信息引入RPN,提升候选框质量;
- 设计 Multi-Relation Detector,通过多粒度匹配增强判别能力;
- 引入 对比训练策略,使模型学会区分"同类"与"异类";
- 构建 FSOD数据集,为小样本检测提供新基准。
意义与影响
- 本文是首个无需微调的小样本目标检测框架;
- 开启了"匹配式检测"新范式,后续许多工作(如FSCE、Dense Teacher)均受其启发;
- 所提数据集成为小样本检测领域的重要基准。
主要参考文献
1 Snell et al., Prototypical Networks for Few-shot Learning , NeurIPS 2017
9 Ren et al., LSTD: A Low-Shot Transfer Detector , CVPR 2018
13 Lin et al., Microsoft COCO: Common Objects in Context , ECCV 2014
25 Ren et al., Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks , NeurIPS 2015
37 Vinyals et al., Matching Networks for One Shot Learning , NeurIPS 2016
61 Rosenberg et al., Incremental Few-Shot Object Detection, CVPR 2019