标题:Matten: Video Generation with Mamba-Attention
作者:Yu Gao, Jiancheng Huang, Xiaopeng Sun, Zequn Jie, Yujie Zhong, Lin Ma(Zequn Jie 为通讯作者)
单位:Meituan Inc.(美团公司)
发表:arXiv preprint arXiv:2405.03025v2 cs.CV
论文链接 :https://arxiv.org/pdf/2405.03025
代码链接:暂无
关键词:视频生成(Video Generation)、 latent diffusion 模型(Latent Diffusion Model)、Mamba 架构(Mamba Architecture)、注意力机制(Attention Mechanism)、状态空间模型(State Space Model)、计算效率(Computational Efficiency)、时空建模(Spatio-Temporal Modeling)
在视频生成领域,如何在保证生成质量的前提下提升模型效率、捕捉全局与局部时空关联,一直是研究者们面临的核心挑战。美团团队提出的 Matten 模型,创新性地将 Mamba 架构与 Attention 机制结合,构建了一种高效的 latent diffusion 模型,为解决这一挑战提供了新思路。
一、研究背景与动机
1.1 视频生成技术的发展现状
近年来,扩散模型在视频生成领域展现出卓越能力,当前主流技术路线主要分为两类:
- CNN-based U-Net 架构:如 LVDM 等模型,依托卷积操作处理空间信息,但在捕捉长序列时空依赖时存在局限。
- Transformer-based 框架 :如 Latte 等模型,通过自注意力机制建模全局关联,然而自注意力的二次复杂度(
,其中J为序列长度,D为隐藏层维度)导致计算成本高昂,难以高效处理长视频序列。
此外,早期的 GAN-based 方法易出现模式崩溃问题,生成视频的多样性和真实性受限;autoregressive 模型虽能生成高质量视频,但同样面临计算量大的困境。因此,寻找兼顾效率与质量、能同时处理局部与全局时空信息的架构,成为视频生成技术突破的关键方向。
1.2 Mamba 架构的潜力与挑战
State Space Models(SSMs,状态空间模型)凭借对长序列数据的高效建模能力,在 NLP、计算机视觉等领域逐渐兴起。其中,Mamba 作为 SSM 的代表性模型,通过动态参数设计和硬件友好型算法,实现了线性复杂度(,N为 SSM 维度)的序列建模,在长文本处理、图像生成等任务中表现出色。
然而,Mamba 在视频生成领域的应用面临两大挑战:
- 局部模式捕捉能力弱:Mamba 的扫描操作本质上不直接计算 token 间的依赖关系,难以有效捕捉视频中的局部时空细节,这与 Attention 机制在局部建模上的优势形成互补。
- 时空建模适配性:原始 Mamba 为 1D 序列设计,直接应用于 3D 视频数据(帧序列 + 空间维度)时,需解决时空维度的适配问题,如何合理组织视频的时空 token 序列,成为发挥 Mamba 优势的关键。
1.3 研究动机
基于上述现状,Matten 的核心研究动机可概括为三点:
- 融合优势:结合 Mamba 的全局长序列高效建模能力与 Attention 的局部细节捕捉能力,构建 "全局 - 局部" 协同的时空建模架构。
- 降低成本:通过 Mamba 的线性复杂度替代部分 Transformer 的自注意力模块,在保证生成质量的前提下,降低模型的计算量与参数规模。
- 验证扩展性:探索模型复杂度与视频生成质量的关系,验证融合架构的可扩展性,为后续更大规模模型的设计提供依据。
1.4 传统时空建模方法的局限与对比
为更直观理解视频时空建模的核心痛点,文中展示了四种主流的时空建模方式(图1),清晰揭示了现有方法的优势与短板,也为 Matten 的 "Mamba-Attention 融合架构" 提供了设计依据。

-
(a) Spatial-Attention(空间注意力) 仅计算 "单帧内图像 token 间的自注意力",例如同一帧中不同
-
(b) Local Temporal-Attention(局部时间注意力) 仅计算 "不同帧间相同空间位置 token 的注意力",例如第 1 帧
-
(c) Global-Attention(全局注意力) 计算 "所有时空位置 token 间的注意力",既覆盖帧内跨空间位置,也覆盖跨帧关联,理论上能完整建模全局时空依赖。但由于自注意力的二次复杂度,当视频帧数(
-
(d) Global-Mamba(全局 Mamba) 采用 Mamba 的扫描操作建模全局关联,通过 "空间优先扫描"(先按
二、核心方法:Matten 模型设计
Matten 的整体框架基于 latent diffusion 模型,核心创新在于将 Mamba 与 Attention 机制以多种方式融合,形成不同的模型变体,并通过自适应归一化等技术优化条件信息注入。
2.1 背景知识:Latent Diffusion 与 Mamba 基础
在深入模型设计前,需先明确两个核心基础组件:
2.1.1 Latent Diffusion Model(LDM)
LDM 通过预训练 VAE/VQ-VAE 将视频数据映射到低维 latent 空间,在 latent 空间中进行扩散与去噪过程,有效降低计算成本。其核心流程包括:
- 编码阶段 :输入视频
- 扩散阶段 :向z中逐步添加噪声,生成含噪 latent 序列
- 去噪阶段 :训练去噪网络
2.1.2 Mamba 的离散化与双向扩展
原始 Mamba 为 1D 连续时间 SSM,需通过离散化适配深度学习任务。其核心公式如下:
- 连续时间 SSM:
其中为 latent 状态,
为状态转移参数。
- 离散化(零阶保持法,ZOH) :通过时间尺度参数
为适配视频的空间建模需求,Matten借鉴Vision Mamba的设计,采用双向Mamba块:通过同时执行前向与后向SSM扫描,捕捉空间维度上的双向依赖关系,解决了原始1D Mamba空间感知能力弱的问题,结构如下图(图2)所示。
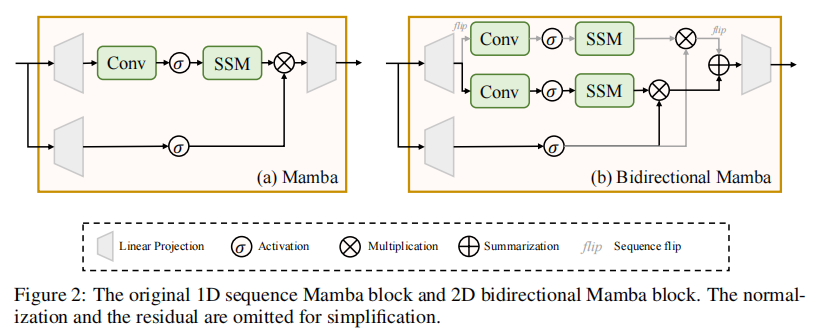
2.2 视频Latent表示与Token化
Matten首先对视频的 latent 表示进行处理,将其转换为适合Mamba与Attention处理的token序列:
- Latent 输入 :视频的 latent 表示为
- Token化 :将
- 位置嵌入 :添加时空位置嵌入
2.3 四种Matten模型变体
为探索Mamba与Attention的最优融合方式,Matten设计了四种模型变体,每种变体针对不同的时空建模需求,具体结构如图3所示:
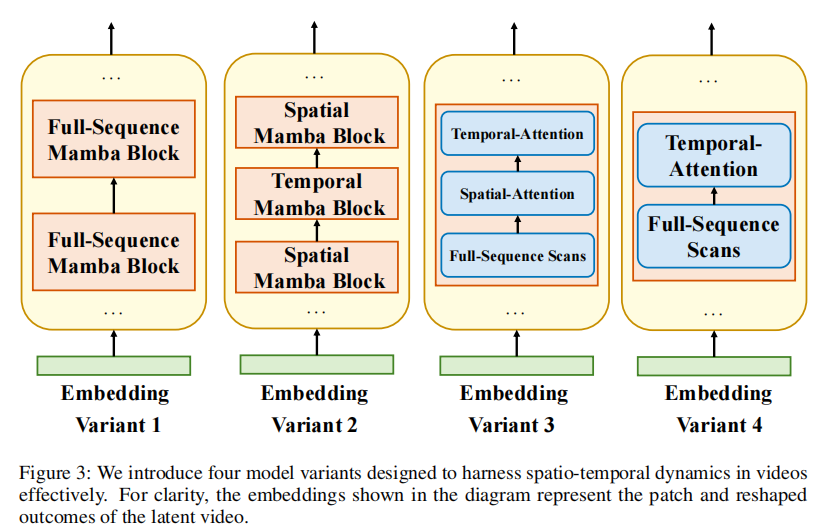
变体1:Global-Sequence Mamba Block(全局序列Mamba块)
- 核心设计:对整个时空token序列执行3D Mamba扫描,采用"空间优先"(Spatial-First)的扫描顺序(先按空间位置排列token,再按帧堆叠);
- 输入处理 :将
- 特点:专注于捕捉全局时空依赖,但缺乏局部细节建模能力,易忽略帧内或相邻帧的局部关联。
变体2:Spatial and Temporal Mamba Blocks Interleaved(时空Mamba块交错)
- 核心设计:用Mamba块替代Transformer中的Attention模块,分为空间Mamba块与时间Mamba块两类;
- 空间Mamba块 :处理相同时间索引的token(即单帧内的空间token),输入重塑为
- 时间Mamba块 :处理相同空间坐标的token(即跨帧的同一空间位置),输入重塑为
- 特点:分别建模空间与时间维度的依赖,但未引入Attention机制,局部细节捕捉能力仍受限。
变体3:Global-Sequence Mamba + Spatial-Temporal Attention Interleaved(全局Mamba+时空Attention交错)
- 核心设计:每个块按"空间Attention→时间Attention→全局Mamba扫描"的顺序串联,同时利用Attention的局部建模与Mamba的全局建模优势;
- 空间Attention:计算单帧内token的自注意力,捕捉帧内局部空间关联;
- 时间Attention:计算相同空间位置跨帧token的自注意力,捕捉局部时间关联;
- 全局Mamba扫描:对整个序列执行Mamba扫描,捕捉全局时空依赖;
- 特点:兼顾局部细节与全局关联,是Matten最终验证的最优变体,在实验中表现出最佳性能。
变体4:Global-Sequence Mamba + Temporal Attention Interleaved(全局Mamba+时间Attention交错)
- 核心设计:在变体3的基础上去除空间Attention模块,仅保留时间Attention与全局Mamba扫描;
- 动机:考虑到Mamba的空间优先扫描已能部分捕捉空间依赖,尝试通过移除空间Attention降低计算成本;
- 特点:计算量低于变体3,但空间局部细节建模能力减弱,在空间复杂度高的场景(如人脸视频)中表现不佳。
2.4 条件信息注入:M-AdaN(Mamba Adaptive Normalization)
视频生成常需引入时间步(timestep)或类别(class)等条件信息,Matten对比了两种注入方式,并提出M-AdaN优化条件融合效果:
两种基础注入方式
- 条件Token(Conditional Tokens):将条件信息转换为token,直接添加到输入token序列中(借鉴DiS模型);
- 缺点:易导致Mamba扫描中的"空间脱节",条件信息无法均匀传递到所有视频token。
- 自适应归一化(AdaN) :通过MLP层从条件信息C中计算归一化参数
M-AdaN的优化设计
Matten在AdaN的基础上,结合Mamba块的残差连接,提出M-AdaN:
其中为残差权重,MambaScans为双向Mamba扫描操作。M-AdaN将条件信息通过归一化与残差连接深度融入Mamba块,确保条件信息均匀传递到所有token,实验证明其效果显著优于条件Token方式(图8b)。
2.5 理论分析:Mamba与Attention的复杂度对比
为量化验证Mamba的效率优势,论文对自注意力(SA)、前馈网络(FFN)与Mamba(SSM)的计算复杂度进行了理论分析,假设序列长度为J,隐藏层维度为D,SSM维度为N(固定为16),扩展维度为E=2:
| 模块 | 计算复杂度公式 | 复杂度类型 | 关键结论 |
|---|---|---|---|
| 自注意力(SA) | 二次复杂度 | 序列长度J增大时,计算量急剧上升,不适用于长序列 | |
| 前馈网络(FFN) | 线性复杂度 | 计算量随J线性增长,但受 |
|
| Mamba(SSM) | 线性复杂度 | 当 |
理论分析表明:
- 对于长序列(如视频的全局时空序列,J通常远大于256),Mamba的计算效率显著高于自注意力;
- 对于短序列(如单帧的空间token序列,J较小),Attention的计算成本更低,更适合局部建模。
这一结论为Matten的"局部Attention+全局Mamba"融合设计提供了理论支撑,也解释了为何变体3能在效率与质量间取得平衡。
三、实验验证与结果分析
为全面评估Matten的性能,论文在4个主流视频生成数据集上进行了大量实验,包括无条件/条件生成任务、消融实验与SOTA对比实验。
3.1 实验设置
3.1.1 数据集与预处理
实验采用4个常用视频生成数据集,统一预处理为16帧、256×256分辨率,采样间隔为3:
- FaceForensics:人脸视频数据集,专注于面部表情与动作生成;
- SkyTimelapse:天空延时视频数据集,包含云、日出日落等缓慢动态场景;
- UCF101:人类动作视频数据集,包含跑步、跳舞等复杂动作;
- Taichi-HD:太极动作视频数据集,需捕捉连贯的肢体动作。
3.1.2 评估指标
采用Fréchet Video Distance(FVD) 作为核心指标,FVD值越低,表明生成视频与真实视频的分布差异越小,质量越高。此外,通过FLOPs(浮点运算次数)评估模型效率。
3.1.3 基线模型
对比当前主流视频生成模型,涵盖GAN-based、Transformer-based、Diffusion-based等类型:
- GAN-based:MoCoGAN、MoCoGAN-HD、DIGAN、StyleGAN-V、MoStGAN-V;
- Transformer-based:VideoGPT、Latte;
- Diffusion-based:PVDM、LVDM。
除非明确重新说明,所有相关数据均来自最新相关研究:Latte、StyleGAN-V、PVDM 或原始论文。
3.1.4 模型配置
Matten设计了4种不同规模的模型(遵循ViT/DiT的配置策略),用于验证扩展性:
| 模型规模 | 层数L | 隐藏层维度D | SSM维度N | 参数数量(M) |
|---|---|---|---|---|
| Matten-S | 12 | 384 | 16 | 35 |
| Matten-B | 12 | 768 | 16 | 164 |
| Matten-L | 24 | 1024 | 16 | 579 |
| Matten-XL | 28 | 1152 | 16 | 853 |
训练细节:采用AdamW优化器(学习率1e-4),仅使用水平翻转作为数据增强,前50k步与后100步分别采用0.99衰减率的EMA(指数移动平均),VAE编码器采用Stable Diffusion v1-4的预训练模型。
3.2 消融实验:关键设计的有效性验证
消融实验在SkyTimelapse数据集上进行,重点验证模型变体、条件注入方式与模型规模的影响。
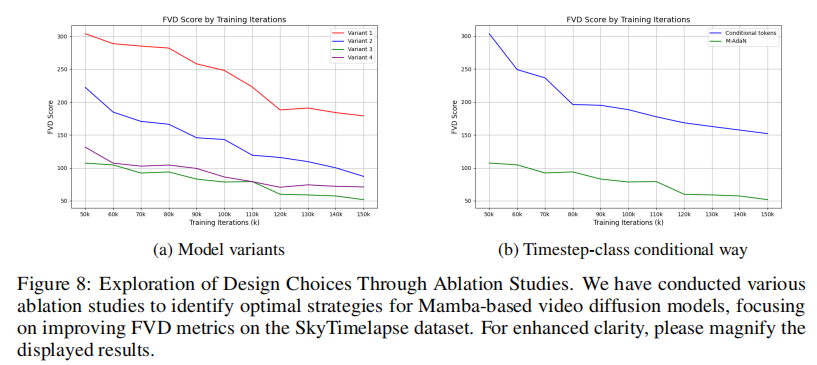
3.2.1 模型变体对比(图8a)
实验保持各变体参数数量一致,对比FVD随训练迭代的变化:
- 变体3表现最优:由于同时结合了Attention的局部建模与Mamba的全局建模,FVD值最低且收敛稳定;
- 变体1/2表现较差:变体1仅依赖全局Mamba,忽略局部细节;变体2仅用Mamba替代Attention,缺乏全局关联捕捉;
- 变体4略逊于变体3:移除空间Attention后,空间局部细节建模能力下降,导致FVD值上升。
这一结果验证了"局部Attention+全局Mamba"融合设计的必要性,也确定了变体3为后续实验的基准模型。
3.2.2 条件注入方式对比(图8b)
对比"条件Token"与"M-AdaN"两种条件注入方式:
- M-AdaN显著更优:FVD值低于条件Token方式,且收敛速度更快;
- 原因分析:M-AdaN通过归一化与残差连接,将条件信息均匀融入Mamba块,避免了条件Token导致的"空间脱节"问题,确保条件信息有效传递到所有时空token。
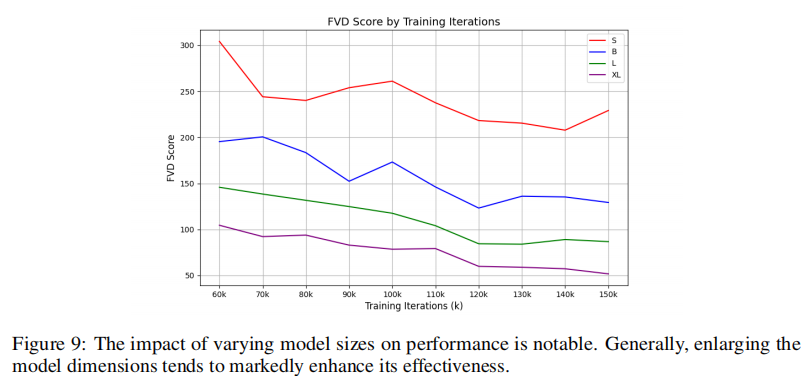
3.2.3 模型规模对性能的影响(图9)
对比4种规模模型的FVD变化:
- 规模越大,性能越好:Matten-XL(853M参数)的FVD值最低,Matten-S(35M参数)最高,且随着训练迭代增加,差距逐渐扩大;
- 扩展性验证:模型复杂度与生成质量呈直接正相关,证明Matten具有优秀的扩展性,为后续更大规模模型的设计提供了依据。
3.3 SOTA对比实验:性能与效率双优
3.3.1 定量结果
在4个数据集上,Matten(变体3,Matten-XL)与SOTA模型的FVD及FLOPs对比如下(FVD值越低越好,FLOPs越低越高效):

关键结论:
-
性能竞争力:
- 在SkyTimelapse(53.56 vs 59.82)、UCF101(210.61 vs 477.97)、Taichi-HD(158.56 vs 159.60)数据集上,Matten的FVD值优于或接近Transformer-based的Latte;
- 在FaceForensics数据集上,Matten(45.01)略逊于Latte(34.00),但需注意Latte使用了图像预训练权重,而Matten因缺乏Mamba-based图像预训练模型,需从头训练(论文指出,若有预训练模型,性能可进一步提升)。
-
效率优势:
- Matten的FLOPs为4008G,较Latte(5572G)降低约25%,较LVDM(5718G)降低约30%;
- 在同等性能下,Matten的计算成本显著低于Transformer-based模型,验证了Mamba架构的效率优势。
3.3.2 定性结果(图4-7,因图片较多,这里仅放了图4,其他图片可以去原文中查看)

定性结果展示了Matten与其他模型在4个数据集上的生成视频质量:
- FaceForensics:Matten能准确捕捉面部表情变化(如微笑、眨眼),生成的人脸轮廓清晰,无明显模糊或变形;
- SkyTimelapse:Matten生成的云层运动连贯自然,日出日落的光线变化平滑,无帧间跳跃;
- UCF101:在跑步、跳舞等复杂动作场景中,Matten能保持人体姿态的连贯性,避免肢体扭曲或动作断裂;
- Taichi-HD:Matten生成的太极动作舒展连贯,招式过渡自然,优于多数基线模型。
特别值得注意的是,在UCF101数据集上,Matten的FVD值(210.61)远低于Latte(477.97),定性结果也显示其在复杂动作建模上的优势,这得益于Mamba对长序列全局依赖的高效捕捉。
四、研究结论与未来展望
4.1 核心结论
- 架构有效性:融合Mamba与Attention的"局部-全局"协同架构(变体3)能有效平衡视频生成的质量与效率,Mamba负责全局时空依赖建模,Attention负责局部细节捕捉,二者互补提升性能。
- 效率优势:Matten在保证SOTA级生成质量的前提下,计算成本(FLOPs)较Transformer-based模型降低约25%,验证了Mamba架构在视频生成领域的效率潜力。
- 扩展性优秀:模型复杂度与生成质量呈直接正相关,更大规模的Matten模型(如Matten-XL)表现出更优性能,为后续模型缩放提供了明确方向。
- 条件注入优化:M-AdaN通过深度融合条件信息与Mamba块,显著提升条件生成性能,优于传统的条件Token方式。
4.2 局限性与未来方向
- 缺乏预训练模型:当前无公开的Mamba-based图像预训练模型,Matten需从头训练;未来若能利用Mamba图像预训练权重,可进一步提升视频生成质量与训练效率。
- 高分辨率扩展:实验主要集中在256×256分辨率,如何将Matten扩展到更高分辨率(如512×512)仍需探索,可能需要结合分层扩散或多尺度建模策略。
- 文本条件生成:论文未涉及文本到视频的生成任务;未来可将M-AdaN扩展为文本条件注入,结合CLIP等文本-图像对齐模型,实现文本驱动的视频生成。
- Mamba扫描策略优化:当前采用"空间优先"的扫描顺序,未来可探索更优的时空扫描策略(如"时间优先"或动态扫描顺序),进一步提升时空依赖建模能力。
五、总结
Matten作为融合Mamba与Attention的视频生成模型,创新性地解决了传统Transformer-based模型计算成本高、Mamba局部建模能力弱的问题。通过四种模型变体的探索,确定了"局部Attention+全局Mamba"的最优架构,并提出M-AdaN优化条件信息注入。实验结果表明,Matten在4个主流数据集上表现出SOTA级的生成质量,同时计算效率提升约25%,为视频生成领域提供了一种高效且可扩展的新范式。
未来,随着Mamba-based预训练模型的发展、高分辨率建模技术的突破以及文本条件生成的扩展,Matten架构有望在更广泛的视频生成场景中发挥作用,推动视频生成技术向更高质量、更高效率、更多样化的方向发展。