背景意义
研究背景与意义
随着全球对高效、可持续农业生产的需求日益增加,家禽养殖业在满足人类食品需求方面扮演着重要角色。尤其是鸡只养殖,因其生长周期短、饲养成本低而受到广泛关注。然而,传统的鸡只养殖管理方式往往依赖人工监测,效率低下且容易受到人为因素的影响,导致资源浪费和生产效率低下。因此,如何通过先进的技术手段提升鸡只养殖的管理水平,成为了当前农业科技研究的重要课题。
近年来,计算机视觉技术的迅猛发展为农业领域带来了新的机遇。特别是基于深度学习的图像分割技术,能够有效地识别和分离图像中的不同对象,为智能养殖提供了重要的技术支持。YOLO(You Only Look Once)系列模型因其高效的实时目标检测能力而受到广泛应用,YOLOv8作为该系列的最新版本,进一步提升了检测精度和速度。基于YOLOv8的图像分割系统,能够在复杂的养殖环境中,准确识别鸡只及其周围环境中的各种物品,为养殖管理提供了可靠的数据支持。
本研究旨在构建一个基于改进YOLOv8的鸡只与养殖场环境物品图像分割系统,利用丰富的数据集进行训练和测试。该数据集包含8700张图像,涵盖了六个类别:鸡只、饲料容器、出入口、产卵巢、栖木和水容器。这些类别不仅包括了鸡只本身,还涵盖了养殖过程中必不可少的环境物品,能够全面反映养殖场的实际情况。通过对这些图像的分析与处理,系统能够实现对鸡只及其周围环境的精准识别和分割,为后续的智能化管理提供基础。
该研究的意义在于,首先,通过实现鸡只与养殖环境物品的高效分割,能够为养殖场提供实时监测与管理的能力,帮助养殖者及时发现潜在问题,如饲料不足、水源缺乏等,从而提高养殖效率和动物福利。其次,系统的建立将为相关领域的研究提供数据支持和技术参考,推动计算机视觉技术在农业中的应用发展。此外,随着数据集的不断丰富和模型的持续优化,未来该系统还可以扩展到其他家禽或养殖动物的管理中,具有广泛的应用前景。
综上所述,基于改进YOLOv8的鸡只与养殖场环境物品图像分割系统,不仅具有重要的学术价值,也为实际养殖管理提供了切实可行的解决方案。通过本研究的开展,期望能够为智能农业的发展贡献一份力量,推动家禽养殖业向更高效、可持续的方向迈进。
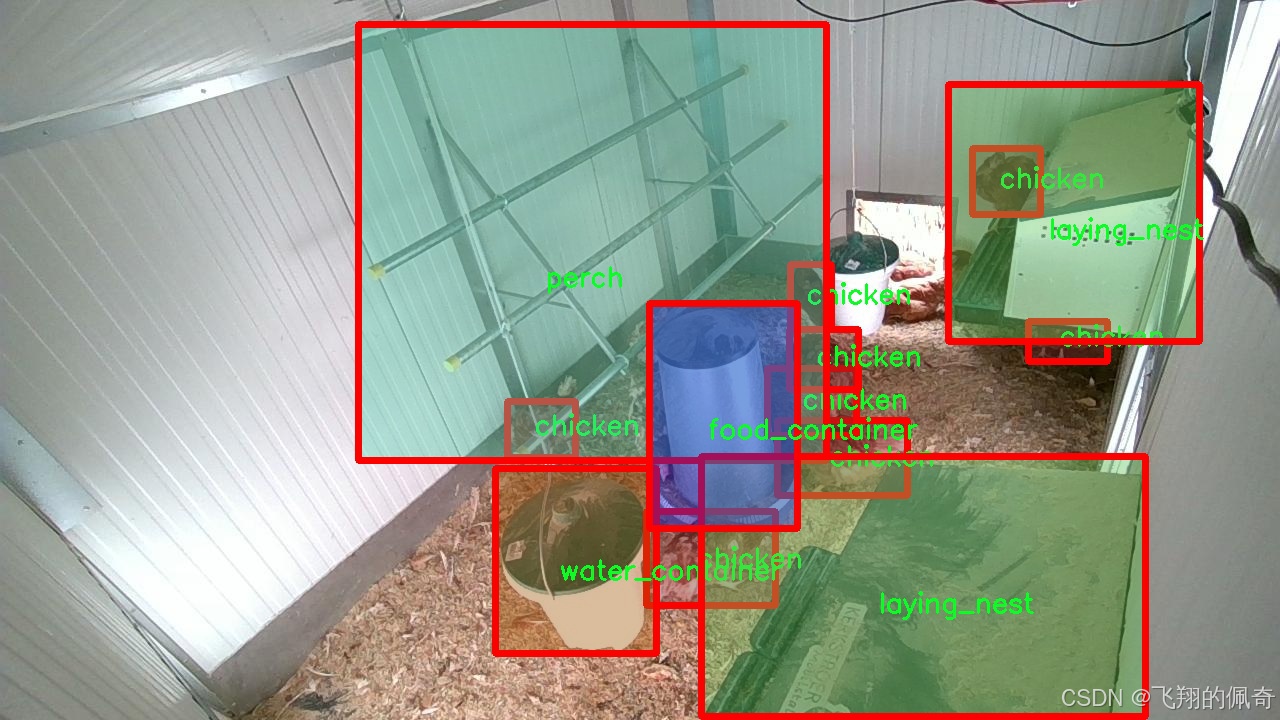
图片效果
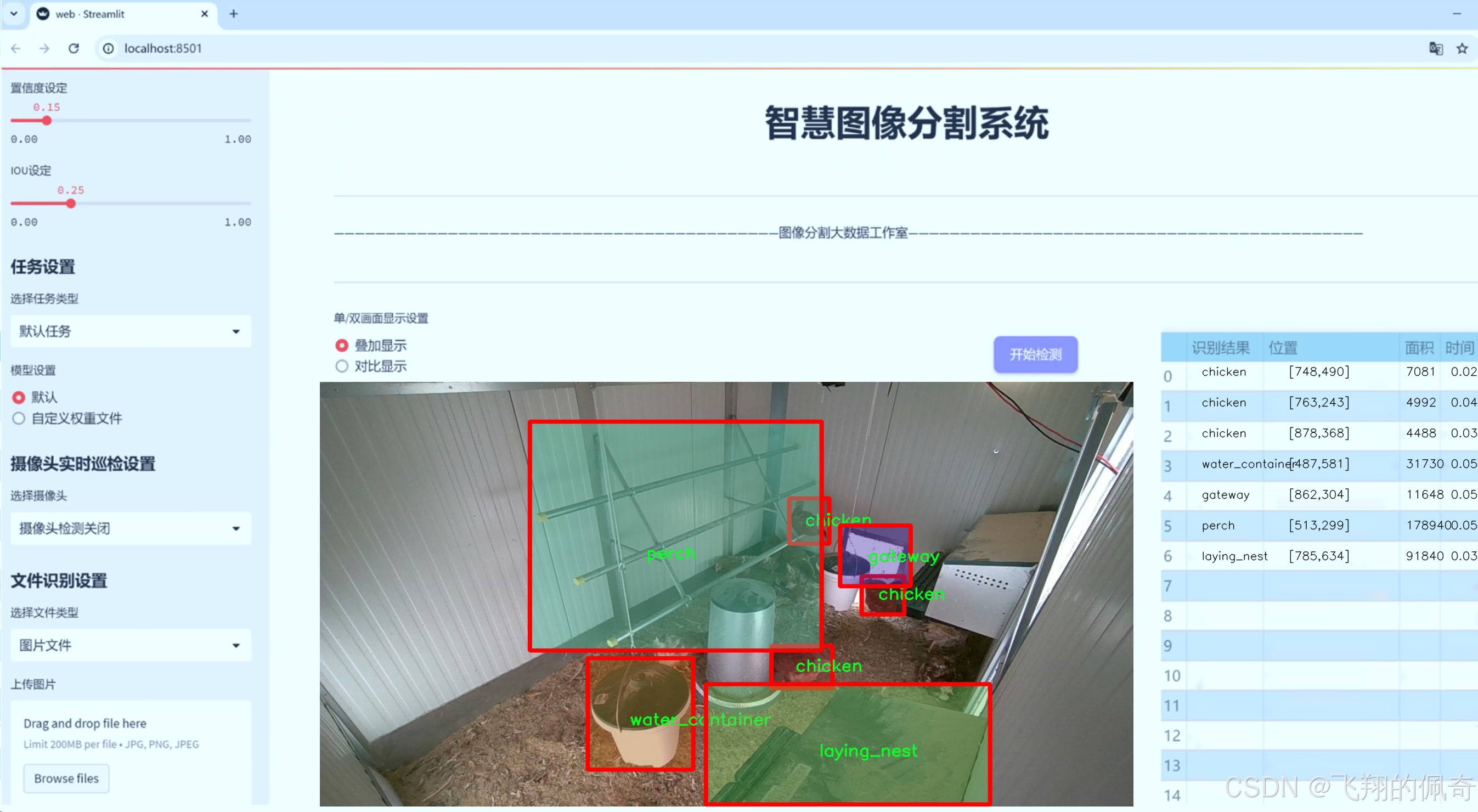
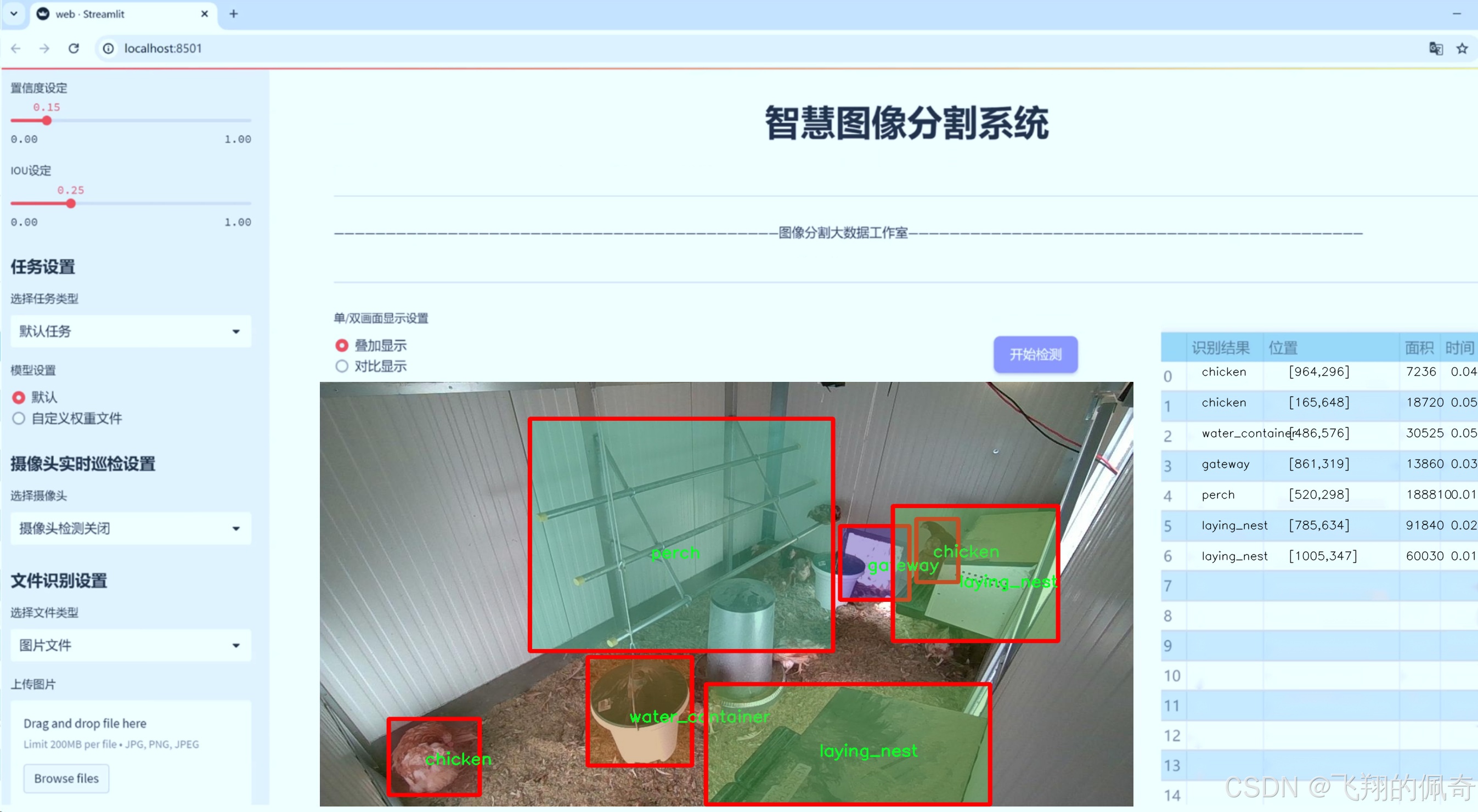
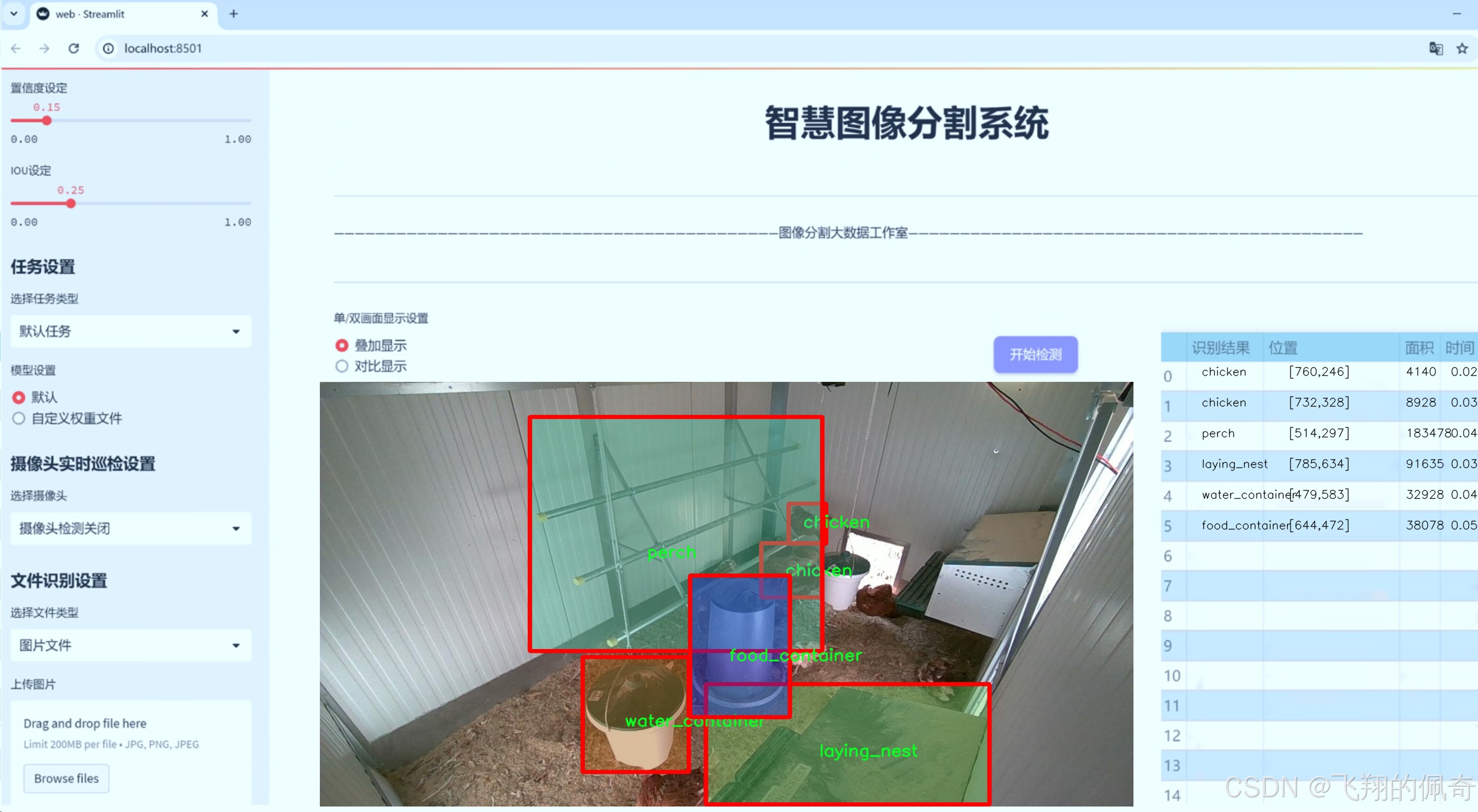
数据集信息
在本研究中,我们使用了名为"chicken_2_groundDINO_6labels_bb"的数据集,旨在改进YOLOv8-seg模型,以实现对鸡只及其养殖场环境物品的高效图像分割。该数据集专门设计用于训练深度学习模型,提供了丰富的标注信息,涵盖了六个主要类别,分别是"chicken"(鸡只)、"food_container"(饲料容器)、"gateway"(通道)、"laying_nest"(产卵巢)、"perch"(栖木)和"water_container"(水容器)。这些类别不仅代表了养殖场中常见的物品和动物,还为模型的训练提供了多样化的视觉信息,有助于提高其在实际应用中的识别和分割能力。
数据集的构建过程充分考虑了养殖场的实际环境,确保了图像的多样性和代表性。每个类别的图像均来自于不同的养殖场,涵盖了不同的光照条件、角度和背景。这种多样性使得模型在训练过程中能够学习到更加丰富的特征,从而提高其在不同环境下的泛化能力。例如,鸡只的图像不仅包括在笼子内的状态,还包括在开放空间中的活动场景,这样的设计使得模型能够更好地适应实际养殖场的复杂情况。
在数据集的标注方面,采用了高精度的边界框和分割掩码,使得每个类别的物体都得到了准确的定位和分割。这种精细的标注方式为YOLOv8-seg模型的训练提供了可靠的基础,确保了模型能够有效地识别和分割出每个类别的物体。尤其是在处理鸡只与环境物品的重叠区域时,精确的分割信息能够显著提高模型的性能,减少误检和漏检的情况。
此外,数据集还包含了丰富的背景信息,这对于训练模型理解不同物体之间的关系至关重要。例如,饲料容器和水容器通常位于鸡只活动的区域,而产卵巢和栖木则是鸡只栖息和产卵的重要场所。通过学习这些物体之间的空间关系,模型不仅能够识别单个物体,还能够理解它们在养殖场中的功能和作用,从而实现更为智能的图像分割。
在训练过程中,我们将数据集划分为训练集和验证集,以确保模型的训练效果和评估的准确性。通过不断调整模型参数和优化算法,我们期望能够提升YOLOv8-seg在鸡只及养殖场环境物品图像分割任务中的表现。最终,经过多轮的训练和验证,我们希望能够实现一个高效、准确的图像分割系统,为养殖业的智能化管理提供有力支持。
综上所述,"chicken_2_groundDINO_6labels_bb"数据集不仅为本研究提供了丰富的训练素材,也为改进YOLOv8-seg模型的性能奠定了坚实的基础。通过对鸡只及其养殖环境物品的深入分析和研究,我们期望能够推动养殖业的数字化转型,提升其生产效率和管理水平。



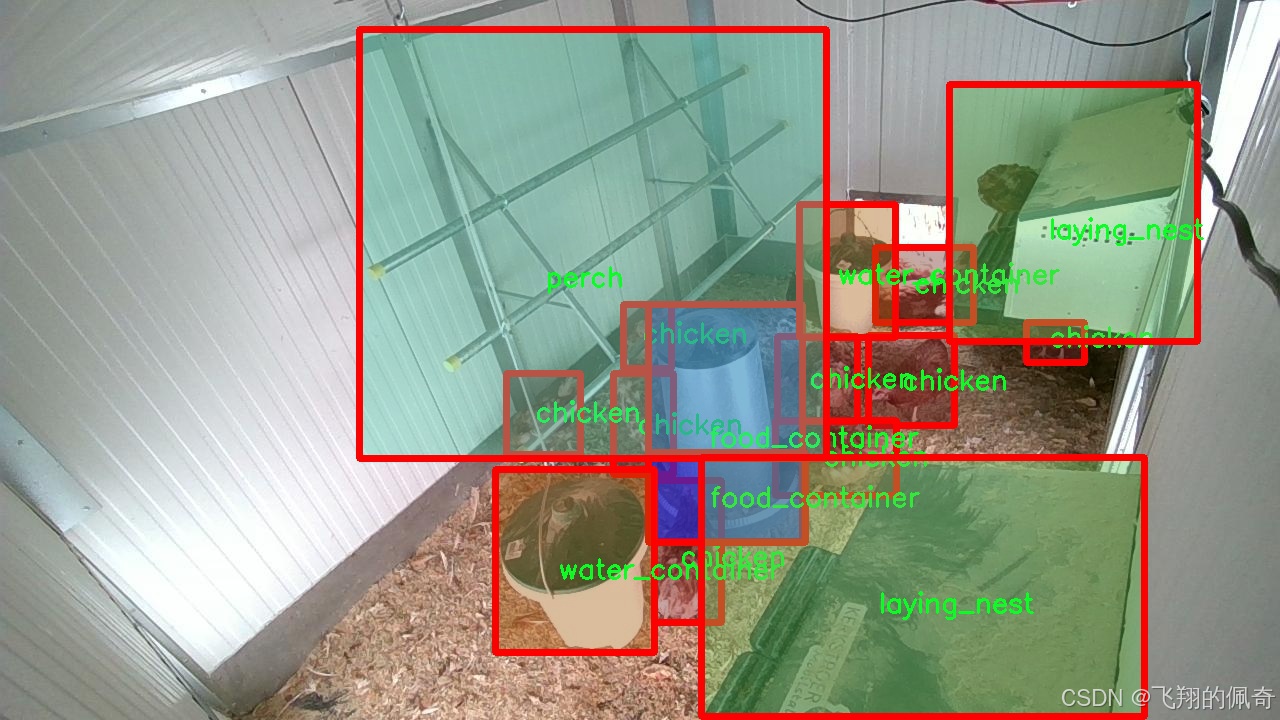
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
```python
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
def calculate_polygon_area(points):
"""
计算多边形的面积,输入应为一个 Nx2 的numpy数组,表示多边形的顶点坐标
"""
if len(points) < 3: # 多边形至少需要3个顶点
return 0
return cv2.contourArea(points)
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
"""
在OpenCV图像上绘制中文文字
"""
# 将图像从 OpenCV 格式(BGR)转换为 PIL 格式(RGB)
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
# 使用指定的字体
font = ImageFont.truetype("simsun.ttc", font_size, encoding="unic")
draw.text(position, text, font=font, fill=color)
# 将图像从 PIL 格式(RGB)转换回 OpenCV 格式(BGR)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
def generate_color_based_on_name(name):
"""
使用哈希函数生成稳定的颜色
"""
hash_object = md5(name.encode())
hex_color = hash_object.hexdigest()[:6] # 取前6位16进制数
r, g, b = int(hex_color[0:2], 16), int(hex_color[2:4], 16), int(hex_color[4:6], 16)
return (b, g, r) # OpenCV 使用BGR格式
def draw_detections(image, info, alpha=0.2):
"""
在图像上绘制检测结果,包括边界框和类别名称
"""
name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']
x1, y1, x2, y2 = bbox
# 绘制边界框
cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=3)
# 在边界框上方绘制类别名称
image = draw_with_chinese(image, name, (x1, y1 - 10), font_size=20)
return image
def frame_process(image, model, conf_threshold=0.15, iou_threshold=0.5):
"""
处理并预测单个图像帧的内容。
Args:
image (numpy.ndarray): 输入的图像。
model: 预测模型。
conf_threshold (float): 置信度阈值。
iou_threshold (float): IOU阈值。
Returns:
tuple: 处理后的图像,检测信息。
"""
pre_img = model.preprocess(image) # 对图像进行预处理
params = {'conf': conf_threshold, 'iou': iou_threshold}
model.set_param(params) # 更新模型参数
pred = model.predict(pre_img) # 使用模型进行预测
detInfo = [] # 存储检测信息
if pred is not None and len(pred):
for info in pred: # 遍历检测到的对象
image = draw_detections(image, info) # 绘制检测结果
detInfo.append(info) # 记录检测信息
return image, detInfo
# 示例用法
if __name__ == "__main__":
# 假设我们有一个模型和一张图像
model = ... # 加载或创建模型
image = cv2.imread("example.jpg") # 读取图像
# 处理图像并获取检测结果
processed_image, detections = frame_process(image, model)
# 显示处理后的图像
cv2.imshow("Detections", processed_image)
cv2.waitKey(0)
cv2.destroyAllWindows()代码说明:
- calculate_polygon_area: 计算多边形的面积,输入为多边形的顶点坐标。
- draw_with_chinese: 在图像上绘制中文文本,使用PIL库处理字体。
- generate_color_based_on_name: 根据类别名称生成稳定的颜色,使用MD5哈希函数。
- draw_detections: 在图像上绘制检测结果,包括边界框和类别名称。
- frame_process: 处理输入图像,进行模型预测,并返回处理后的图像和检测信息。
这段代码展示了如何在图像上进行目标检测,并将检测结果可视化。```
这个程序文件web.py是一个基于Streamlit的图像分割和目标检测应用,主要用于实时处理摄像头输入或上传的图像和视频。以下是对代码的详细说明。
首先,程序导入了必要的库,包括随机数生成、临时文件处理、时间处理、OpenCV、NumPy、Streamlit等。它还导入了一些自定义模块,如路径处理、绘制矩形框的工具、日志记录器、模型加载和处理工具等。
程序定义了一些辅助函数,包括计算多边形面积、在图像上绘制中文文本、根据名称生成颜色、调整参数、绘制检测结果等。这些函数的主要作用是为后续的图像处理和检测提供支持。
Detection_UI类是程序的核心,负责初始化应用的各个部分。构造函数中,初始化了一些属性,包括类别标签、颜色、模型参数、摄像头和文件相关变量、检测结果相关变量、UI显示相关变量等。它还设置了页面标题和侧边栏布局,并加载了模型和日志表格。
在setup_sidebar方法中,设置了Streamlit的侧边栏,包括置信度和IOU阈值的滑动条、模型类型选择、摄像头选择和文件上传器等。用户可以通过这些控件来配置检测任务。
process_camera_or_file方法处理用户选择的输入源(摄像头或文件),并进行相应的检测。如果选择了摄像头,它会使用OpenCV捕获视频流,并对每一帧进行处理。如果选择了上传的文件(图片或视频),则会读取文件并进行处理。
frame_process方法是对单个图像帧进行处理的核心函数。它首先对图像进行预处理,然后使用模型进行预测,最后将检测结果绘制到图像上,并返回处理后的图像和检测信息。
程序的主循环在setupMainWindow方法中运行,创建了用户界面并处理用户的输入。用户可以选择显示模式(叠加显示或对比显示),并通过按钮启动检测。检测结果会实时更新,并在表格中显示。
整个程序通过Streamlit提供的交互式界面,使得用户能够方便地进行图像分割和目标检测,实时查看结果并导出检测数据。
以下是经过简化并注释的核心代码部分,主要包含了TinyViT模型的基本结构和功能。
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class Conv2d_BN(nn.Sequential):
"""执行2D卷积并随后进行批量归一化的序列容器。"""
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0):
"""初始化卷积层和批量归一化层。"""
super().__init__()
self.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False))
self.add_module('bn', nn.BatchNorm2d(out_channels))
class PatchEmbed(nn.Module):
"""将图像嵌入为补丁并投影到指定的嵌入维度。"""
def __init__(self, in_chans, embed_dim, resolution):
"""初始化PatchEmbed类。"""
super().__init__()
self.patches_resolution = (resolution // 4, resolution // 4) # 计算补丁的分辨率
self.seq = nn.Sequential(
Conv2d_BN(in_chans, embed_dim // 2, kernel_size=3, stride=2, padding=1),
nn.GELU(), # 激活函数
Conv2d_BN(embed_dim // 2, embed_dim, kernel_size=3, stride=2, padding=1),
)
def forward(self, x):
"""通过补丁嵌入模型的序列操作运行输入张量。"""
return self.seq(x)
class TinyViTBlock(nn.Module):
"""TinyViT块,应用自注意力和局部卷积。"""
def __init__(self, dim, num_heads, window_size=7):
"""初始化TinyViTBlock。"""
super().__init__()
self.attn = Attention(dim, num_heads) # 注意力机制
self.local_conv = Conv2d_BN(dim, dim, kernel_size=3, stride=1, padding=1) # 局部卷积
def forward(self, x):
"""对输入进行自注意力变换和局部卷积。"""
x = self.attn(x) # 应用注意力
x = self.local_conv(x) # 应用局部卷积
return x
class TinyViT(nn.Module):
"""TinyViT架构,用于视觉任务。"""
def __init__(self, img_size=224, in_chans=3, num_classes=1000):
"""初始化TinyViT模型。"""
super().__init__()
self.patch_embed = PatchEmbed(in_chans, embed_dim=96, resolution=img_size) # 初始化补丁嵌入
self.layers = nn.ModuleList([
TinyViTBlock(dim=96, num_heads=3), # 添加TinyViT块
TinyViTBlock(dim=192, num_heads=6),
TinyViTBlock(dim=384, num_heads=12),
])
self.head = nn.Linear(384, num_classes) # 分类头
def forward(self, x):
"""执行前向传播,返回分类结果。"""
x = self.patch_embed(x) # 嵌入补丁
for layer in self.layers:
x = layer(x) # 通过每个层
return self.head(x) # 返回分类结果代码说明:
- Conv2d_BN: 该类定义了一个卷积层后接批量归一化的结构。
- PatchEmbed: 将输入图像分割成补丁并通过卷积层进行嵌入,生成固定维度的特征表示。
- TinyViTBlock: 该模块包含自注意力机制和局部卷积操作,用于处理输入特征。
- TinyViT: 这是整个模型的主类,负责初始化补丁嵌入、多个TinyViT块和分类头,并定义前向传播过程。
通过这种结构,TinyViT模型能够有效地处理视觉任务,并利用自注意力机制和卷积操作来提取特征。```
这个程序文件 tiny_encoder.py 实现了一个名为 TinyViT 的视觉模型架构,主要用于图像分类等视觉任务。该模型是基于小型视觉变换器(ViT)设计的,结合了卷积神经网络(CNN)和自注意力机制。文件中包含多个类,每个类负责模型的不同部分。
首先,Conv2d_BN 类是一个简单的模块,执行二维卷积操作并随后进行批量归一化。这种结构在许多深度学习模型中都很常见,因为它有助于加速训练并提高模型的稳定性。
接下来,PatchEmbed 类负责将输入图像分割成小块(patches),并将这些小块映射到指定的嵌入维度。这是变换器模型的一个关键步骤,因为它将图像数据转换为适合后续处理的格式。
MBConv 类实现了移动反向瓶颈卷积层,这是一种高效的卷积结构,常用于轻量级网络。它通过扩展和压缩通道来提高特征提取的能力,同时保持计算效率。
PatchMerging 类则负责将相邻的特征块合并,并将其投影到新的维度,这有助于在模型的不同层之间传递信息。
ConvLayer 类包含多个 MBConv 层,并可选择性地对输出进行下采样。它还支持梯度检查点,以节省内存。
Mlp 类实现了多层感知机(MLP),用于对特征进行进一步处理,通常在自注意力机制之后使用。
Attention 类实现了多头自注意力机制,允许模型在处理输入时关注不同的特征部分。它还支持空间偏置,使得模型能够更好地理解输入的空间结构。
TinyViTBlock 类结合了自注意力和局部卷积,形成了 TinyViT 的基本构建块。它通过局部卷积增强了模型对局部特征的捕捉能力。
BasicLayer 类则是一个基本的 TinyViT 层,包含多个 TinyViTBlock,并可选择性地进行下采样。
LayerNorm2d 类实现了二维层归一化,通常用于稳定训练过程。
最后,TinyViT 类是整个模型的核心,负责初始化各个层并定义前向传播的逻辑。它接受多个参数,如输入图像的大小、通道数、类别数、嵌入维度等,允许用户根据需求灵活配置模型。
总体而言,这个文件实现了一个结构化的视觉模型,结合了卷积和变换器的优点,适用于各种视觉任务。通过模块化设计,代码的可读性和可维护性得到了增强。
程序整体功能和构架概括
该程序是一个基于Ultralytics YOLO和相关深度学习模型的计算机视觉框架,主要用于目标检测和图像分割任务。程序的整体架构分为多个模块,每个模块负责特定的功能,以便于管理和扩展。以下是各个模块的主要功能:
- 回调模块:通过与外部工具(如Weights & Biases和ClearML)集成,记录和可视化训练过程中的性能指标,帮助开发者监控模型的训练状态。
- 注意力机制模块:实现了多种注意力机制,以增强模型在特征提取和表示学习方面的能力。这些模块可以灵活组合,以适应不同的视觉任务。
- Web应用模块:提供了一个用户友好的界面,允许用户通过摄像头或上传文件进行实时目标检测和图像分割,方便用户进行实验和结果查看。
- TinyViT模型模块:实现了一种轻量级的视觉变换器架构,结合了卷积和自注意力机制,适用于高效的图像分类和其他视觉任务。
文件功能整理表
| 文件路径 | 功能描述 |
|---|---|
ultralytics/utils/callbacks/wb.py |
集成Weights & Biases,记录和可视化训练过程中的性能指标,支持自定义图表和曲线的记录。 |
ultralytics/utils/callbacks/clearml.py |
集成ClearML,记录训练过程中的实验日志和结果,支持调试样本和验证结果的记录。 |
ultralytics/nn/extra_modules/attention.py |
实现多种注意力机制模块(如SimAM、CoordAtt等),用于增强模型的特征提取能力和性能。 |
web.py |
提供基于Streamlit的用户界面,允许用户进行实时目标检测和图像分割,支持摄像头和文件输入。 |
ultralytics/models/sam/modules/tiny_encoder.py |
实现TinyViT模型架构,结合卷积和自注意力机制,适用于高效的图像分类和视觉任务。 |
通过这种模块化的设计,程序能够灵活地适应不同的需求,并为用户提供强大的功能和易用的界面。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻