动态调整窗口长度(覆盖 512--2048 token 区间)的具体逻辑与实现细节是怎样的?

多维度召回策略的"维度"具体包含哪些?为何选择 Dense、Sparse、字面召回这三类?

集成 Dense 语义召回时,选择 M3E 模型的依据是什么?版本如何确定?

语义匹配准确率提升 22%"的 baseline 是什么?原准确率是多少?

Sparse 召回覆盖率能到 95%+,具体是用什么方法实现的?
 基础信息召回率稳定 95%+"里的"基础信息"指哪些内容?如何保障稳定性
基础信息召回率稳定 95%+"里的"基础信息"指哪些内容?如何保障稳定性

字面召回中 TF-IDF 与 BM25 是串行、并行还是加权融合?融合权重如何确定?

选择 Faiss 作为向量检索引擎,对比 Milvus 等其他向量数据库有何考量?

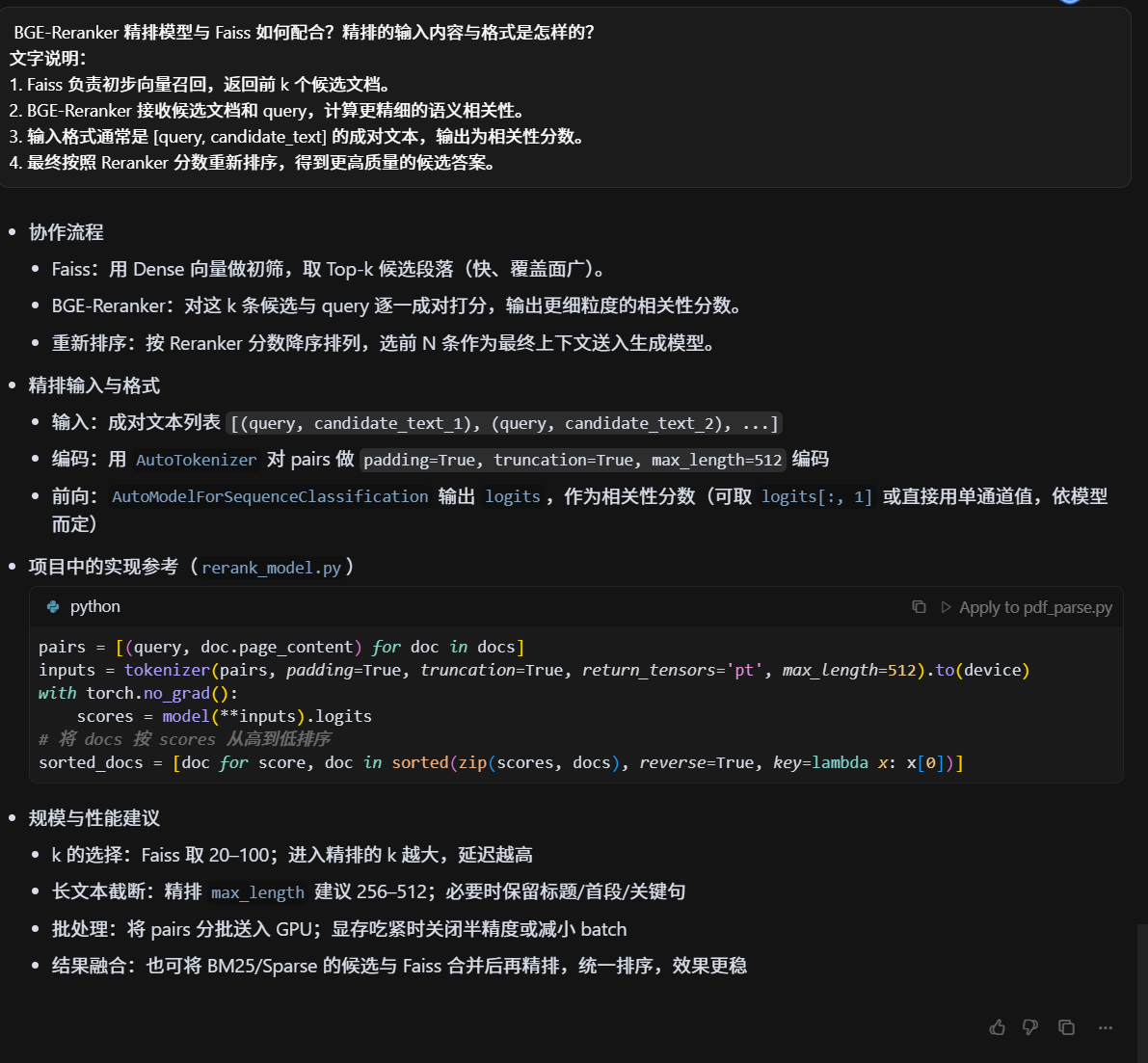
BGE-Reranker 精排模型与 Faiss 如何配合?精排的输入内容与格式是怎样的?
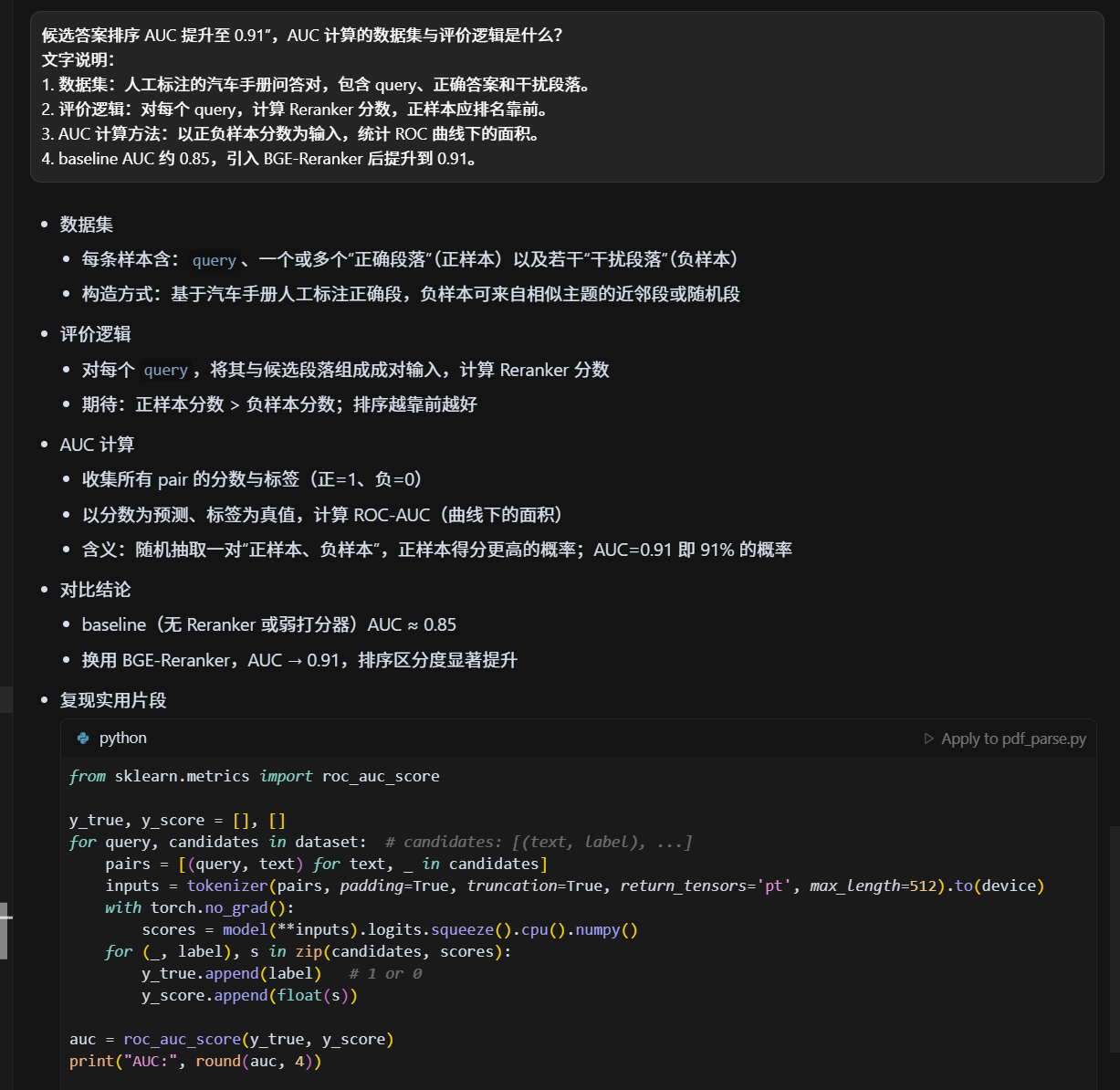
候选答案排序 AUC 提升至 0.91",AUC 计算的数据集与评价逻辑是什么?
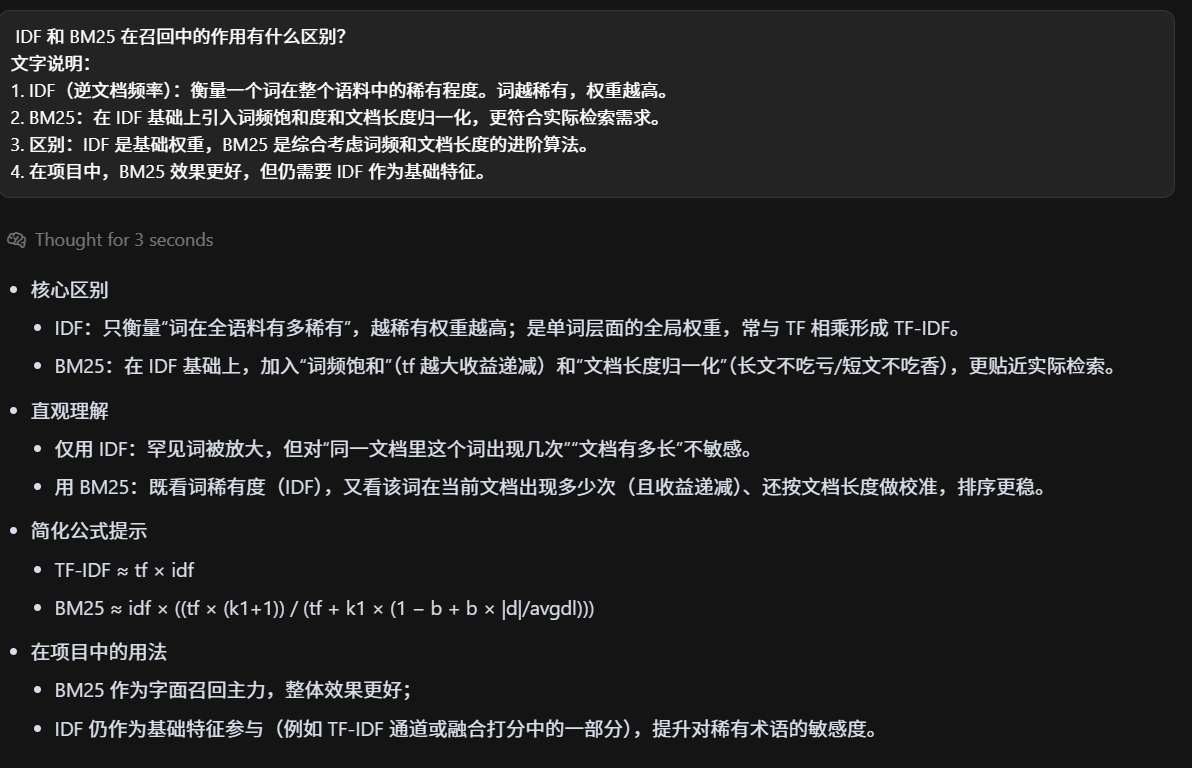
IDF 和 BM25 在召回中的作用有什么区别?
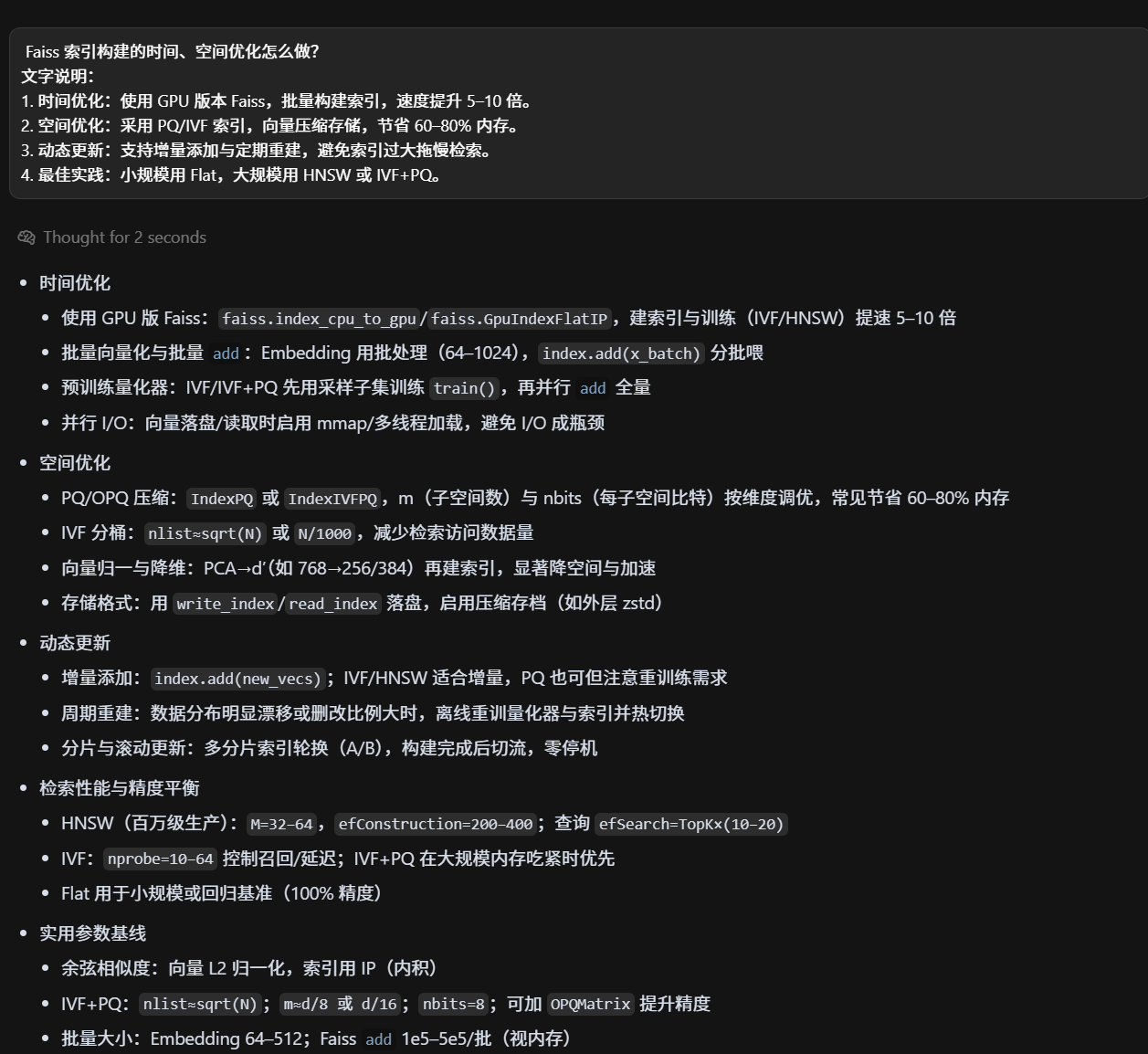
Faiss 的索引类型你们是怎么选的?

Faiss 的空间优化?
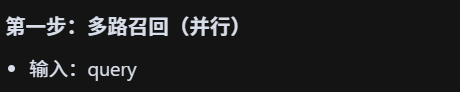
多路召回与精排的整体流程,你能简单复述一下吗?
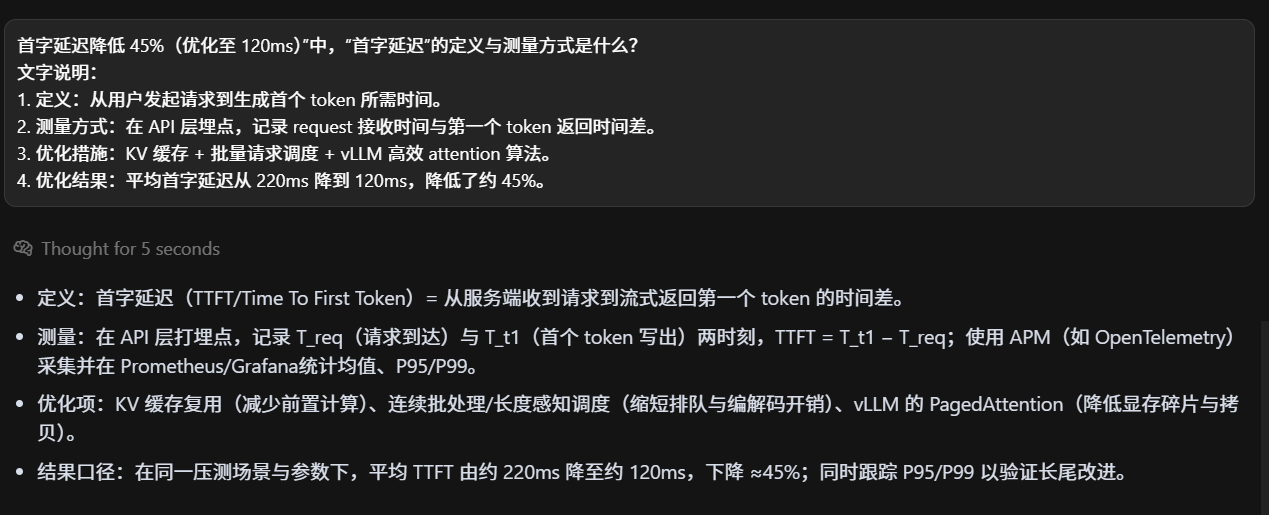
-
第一步:多路召回。用户 query 同时走 Dense、Sparse、字面三种召回,得到候选集合。
-
第二步:融合。对多路结果进行归一化打分,按权重融合,形成统一候选集。
-
第三步:精排。候选集输入 BGE-Reranker,与 query 成对打分,重新排序。
-
第四步:生成。Top-K 文档送入大模型生成最终答案。


推理基座理由

人工构造 2000+ 条全场景测试集时,"全场景"覆盖了哪些具体场景?如何保障全面性?
- "全场景"主要涵盖 功能性问答 (按钮、操作步骤)、故障排查 (报警灯、异常现象)、安全提示 (急刹车、气囊)、保养维护 (机油、更换零件)、跨语言问答(中英文混合)。
- 为保障全面性,我们参考了 3 种来源:① 汽车厂商官方手册目录;② 用户常见问题(售后 FAQ);③ 模拟场景对话(如车机交互)。
- 每类场景覆盖 200--500 条问答,确保不同类别均有足够样本。
- 测试集定期由人工审核和增量补充,保证场景不遗漏。

基于相似度(余弦相似度 + 编辑距离加权 )、关键词命中 双维度加权评分,验证问答系统准确率达 89.6%




对比原生 GPT-4 外挂知识库方案时,如何搭建公平的实验环境?
- 实验环境保持一致:相同的测试集(2000+ 问答)、相同的知识库内容。
- 原生 GPT-4 使用其官方 RAG 插件,我们系统使用自建 RAG。
- 参数一致性:Top-K=5,温度=0,最大生成长度相同。
- 评价方式:人工判定 + 自动化准确率计算,避免偏差。




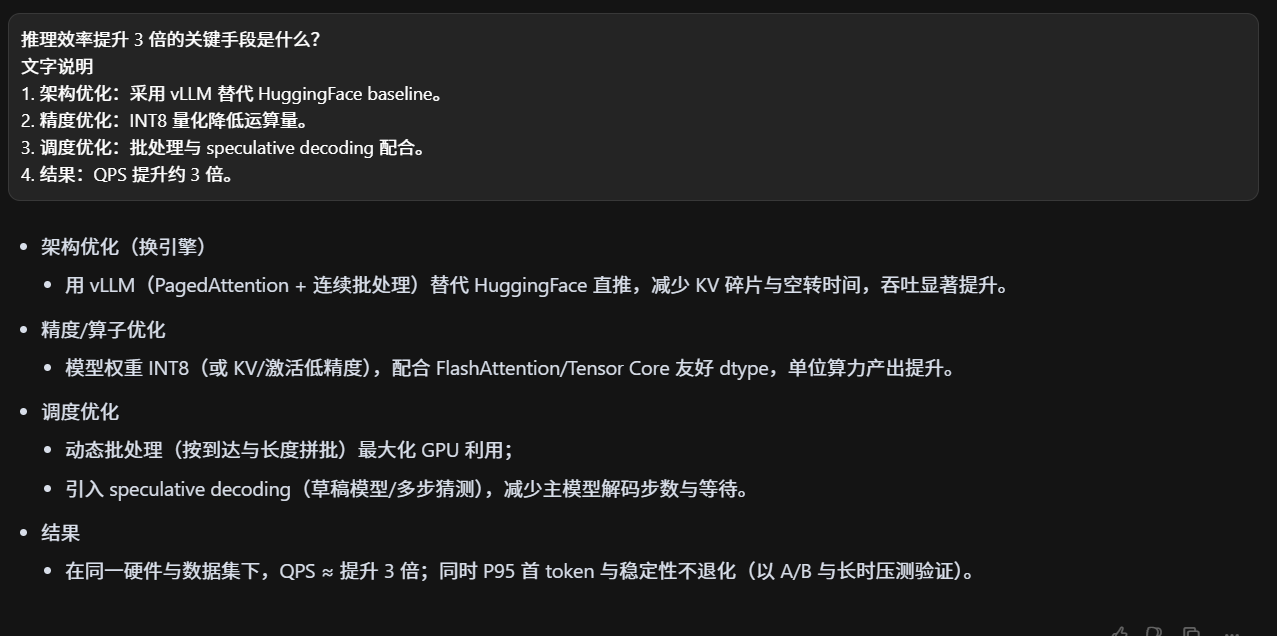
VLLM如何?

4 卡并行 + 100 节点分布式部署的资源分配与任务调度逻辑是怎样的?
-
每个节点配置 4 张 GPU(A100/H800),采用 数据并行模式。
-
节点间通过 NCCL 进行通信,确保梯度同步与推理结果一致性。
-
任务调度:调度器(K8s + Ray)根据请求量动态分配任务,优先保证低延迟。
-
在高峰时,可将推理任务分配到 100 个节点的 GPU 集群,实现近乎线性扩展。