
半桔 :个人主页
🔥 个人专栏 : 《Linux手册》《手撕面试算法》《网络编程》
🔖有些鸟儿注定是不会被关在牢笼里的,因为它们的每一片羽毛都闪耀着自由的光辉。
文章目录
- [一. 前言](#一. 前言)
- [二. 基础知识](#二. 基础知识)
-
- [2.1 URL](#2.1 URL)
- [三. 请求报文](#三. 请求报文)
- [四. 响应报文](#四. 响应报文)
- [五. 实现HTTP服务器](#五. 实现HTTP服务器)
- [六. HTTP的细节字段](#六. HTTP的细节字段)
-
- [6.1 请求方法](#6.1 请求方法)
- [6.2 状态码](#6.2 状态码)
- [6.3 常见的报头](#6.3 常见的报头)
- [6.4 Cookie和Session ID](#6.4 Cookie和Session ID)
一. 前言
在如今的数字时代,我们每天打开浏览器浏览新闻、刷社交媒体、在线购物、观看视频时,背后都有一套默默运转的 "通信规则" 在支撑 ------ 这就是超文本传输协议(HyperText Transfer Protocol,简称 HTTP)。作为 TCP/IP 协议栈中应用层的核心协议之一,HTTP 如同互联网世界的 "信使",负责在客户端(如电脑、手机浏览器)与服务器之间传递数据,让文本、图片、音频、视频等各类资源得以跨越网络顺畅流转。
然而,对于多数使用者而言,HTTP 协议更像是 "隐形的基础设施",其运作原理、核心特性与演进逻辑往往被忽略。本文将从 HTTP 协议的基本概念入手,深入剖析其工作机制。
本文将分为4大板块:
- 基础知识;
- http请求和响应的报文结构;
- 实现http服务器;
- http的细节字段。
二. 基础知识
2.1 URL
在构建http服务器之前我们需要学习一些关于http的基础知识。
URL:在网络上的所有资源都可以使用一个唯一的"字符串"标识,该字符串被称为URL。
以下是完全符合标准格式的 URL,以及对应的各个字段标识的含义:

| 组成部分 | 示例内容 | 作用 |
|---|---|---|
| 协议方案 | http |
指定通信协议(如 http、https、ftp 等,决定客户端如何与服务器交互) |
| 认证信息 | user:pass@ |
(可选)早期用于 HTTP Basic 认证,现在少用(安全风险高) |
| 主机名 | www.example.jp |
服务器的域名(或 IP 地址),定位网络中的服务器 |
| 端口号 | :80 |
(可选)指定服务器监听的端口,http 默认 80、https 默认 443,可省略 |
| 路径 | /dir/index.htm |
服务器上资源的具体位置(类似文件系统路径) |
| 查询参数 | ?uid=1 |
(可选)键值对形式,向服务器传递额外参数(如筛选、分页) |
| 片段(锚点) | #ch1 |
(可选)浏览器内部使用,定位页面内的锚点(不传给服务器) |
根据上面的表格,一个最简单的URL至少包含三个部分:协议方案 + 主机名(IP号) + 路径。
因为IP地址是一串数字难以记忆,所以一般采用域名来替代IP号,像bandu.com,bilibili.com都是域名,通过域名能够解析出IP地址,让用户更容易记忆。
http://hcl.baidu.com/:这就是一个最简单的URL,其中http是协议方案,hcl.bandu.com是域名标识IP地址,而最后的/类似于根目录标识路径。
可以看到上面的URL中各个部分要进行划分,采用了不同的分隔符,像\,?等;
我们可以在URL上带上自己要查询的参数,其中内容可以自定义,那当内容中含有URL的分隔符的时候,URL会不会解析失败???
此时就需要服务端和客户端对信息进行编码和解码:
- 如果用户或客户端输入的内容中包含了URL的特殊分割符,就需要对内容进行编码和解码,也就是对特殊字符进行转义。
转义原则:将需要转码的字符转为 16 进制,然后从右到左,取 4 位(不足 4 位直接处理),每2 位做一位,前面加上%,编码成%XY格式。比如对于?会被转义为%3F.
三. 请求报文
Http协议已经定制好了,学习Http协议是非常有必要的,对于我们后续使用http协议,以及进行抓包都有很大帮助。
此处我们先学习一下http的请求报文的组成。
一下是请求的报文结构:
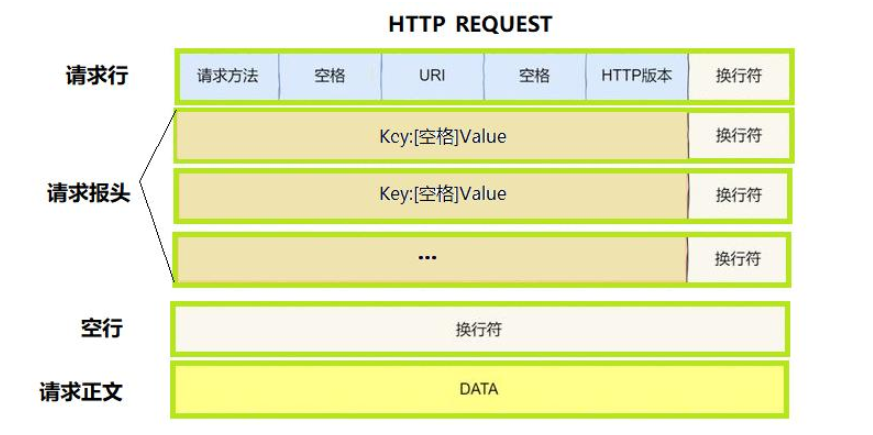
首先请求行分为3个部分:
- 请求方法:参加的就是Get获取资源,POST上传资源,关于其他请求在文章结尾会详细介绍;
- URL:用来标识请求的资源位置;
- HTTP版本:保证双方使用统一协议进行交互。
其中每一行通过\n\r作为换行符进行分割。
- 请求报头 :请求报头中存放的是
key-value形式的数据,内部有各种不同的字段来标识请求者,报文的各种信息,我们也会在结尾处详细介绍; - 请求正文:请求正文就是我们先服务区发送的请求字段信息。
在报头和正文中间,用一个空行 的进行分割,来报文能够区分一个http报头的结尾位置。
在报头中存放了请求正文的行数或正文的大小 ,像Content-Length字段就表示请求正文的字节数,来保证服务端也能知道请求正文的结束位置。
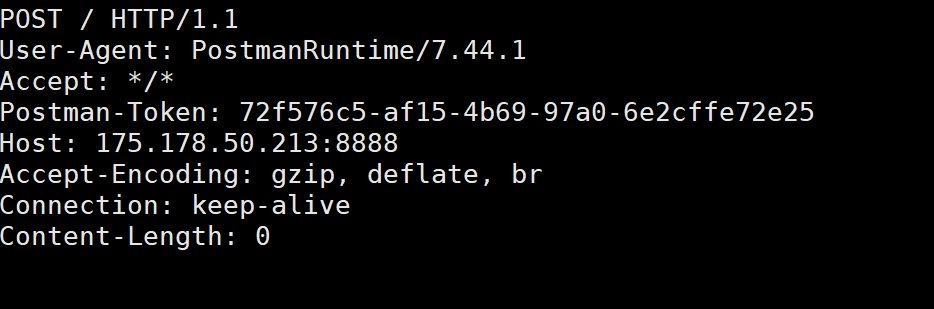
上面这是一个普通的请求报文的内容。
- 其中的请求方法是Get,标识该请求是用来获取资源的,在HTTP中Get方法不允许携带请求正文 ,因此我们并没有在报头中看到关于描述正文大小的字段;另一个POST的方法中确实有
Content-Length字段。 - 在请求报文的第二个参数URL有一点问题,为什么只有一个路径,既没有协议也没有IP地址。
第二个URL这么写,有两个原因:
- HTTP 请求的 传输层协议 (HTTP 还是 HTTPS),是在 建立 TCP 连接时就确定的 : 如果客户端用 80 端口 发起 TCP 连接,默认是 HTTP 协议 ;如果用 443 端口 发起 SSL/TLS 加密连接,默认是 HTTPS 协议。依次在URL中并没有直接写协议方案。
- HTTP 协议客户端通过
Host请求头 明确指定目标域名,保证同一个IP下可以用多个域名,也就是说IP信息保存在请求报头的Host中,所以也并不用显示的在URL中写出来。
通过这两种方式只保留路径和查询参数,提升传输效率。
四. 响应报文
响应报文与请求报文结构一致,只不过其中的字段信心不一样,下面是响应报文的结构:

请求行的结构:
- HTTP版本:与请求行的作用一样,保证使用统一协议进行通信;
- 状态码 :服务器对客户端 HTTP 请求的 "结果反馈码" ,核心作用是 用标准化的数字,清晰告知请求的处理状态,关于请求码有很多,在最后一部分来统一讲解;
- 状态码描述:用来描述状态码标识的含义。
报头和响应正文与请求报头一样,就不再赘述了。
下一步先实现一下HTTP服务器,再实现的过程中进行更多的介绍。
五. 实现HTTP服务器
HTTP服务器的实现与TCP是完全一样的,只不过我们使用HTTP现成的协议,而不需要自己再定制了。所以在之前编写的TCP服务器上对Service的行为进行修改即可。
因此我们只需要对接收到的HTTP请求进行响应就行了,此处先进行简单演示,我们对于所有请求都返回HELLO WORLD:
cpp
void Response(int fd_)
{
// 构建响应报文
std::string response_line = "HTTP/1.1 200 OK\r\n"; // 请求行
std::string text = "HELLO WORLD"; // 请求正文
std::string repsonse_heaeder = "Content-Length:" + std::to_string(text.size()) + "\r\n" + "\r\n"; // 请求报头
std::string response = response_line + repsonse_heaeder + text;
std::cout << response << std::endl;
write(fd_ , response.c_str() , response.size());
}
void Service(int fd_)
{
char buffer[1024*10];
while (1)
{
memset(buffer, 0, sizeof(buffer));
int n = read(fd_, buffer, sizeof(buffer) - 1);
if(n > 0)
{
buffer[n] = 0;
std::cout << buffer << std::endl;
Response(fd_);
}
}
}此时用浏览器再进行访问就会打印出HELLO WORLD的字段:

以上仅仅是一个简单的实现,我们也可以将用户要进行访问的所有数据都进行整理,到一个目录中,该目录被称为\:web根目录。
我们可以根据用户的请求,解析出用户要进行访问的路径 ,通过该路径找到文件,将文件的内容传递给用户,即使用write接口将文件内容发送给用户。此处就不再进行拓展了,有兴趣的可以自己试一试。
六. HTTP的细节字段
下面将详细介绍HTTP报头中的各个字段。
6.1 请求方法
| 方法 | 核心语义 | 主要用途 |
|---|---|---|
| GET | 读取资源 | 查询数据、获取静态资源 |
| POST | 提交 / 创建资源 | 表单提交、创建数据 |
| PUT | 全量更新资源 | 替换完整资源 |
| PATCH | 部分更新资源 | 修改资源部分字段 |
| DELETE | 删除资源 | 删除指定资源 |
| HEAD | 读取资源头 | 检查资源存在性、获取元信息 |
| OPTIONS | 查询支持的方法 | 跨域预检、调试 |
数据是通过表单进行提交的,即我们通常所使用的搜索框。如果我们想要提交信息一般使用POST,但是也可以通过Get来进行提交:
- 使用POST提交的数据将被放到请求的正文部分;
- 实际上使用Get也可以进行数据的提交,只不过Get默认请求正文为空,因此通过Get方法提交的参数信息将被放到URL中。
6.2 状态码
在HTTP中在状态码有很多,一下通过一张表格进行展示:
| 分类(首位数字) | 含义 | 典型场景 & 状态码示例 |
|---|---|---|
| 1xx(信息类) | 服务器已接收请求,需客户端配合 | 100 Continue:客户端要发大文件,服务器先回应 "可以继续发"(避免浪费流量); 101 Switching Protocols:升级协议(如 HTTP→WebSocket)。 |
| 2xx(成功类) | 请求被成功处理 | 200 OK:最常见,如浏览器访问网页成功; 201 Created:新建资源成功(如注册用户、上传文件); 204 No Content:请求成功,但无内容返回(如删除资源后)。 |
| 3xx(重定向类) | 需客户端跳转到新地址 | 301 永久重定向:旧网址失效,永久跳新地址(如域名更换); 302 临时重定向:临时跳转到其他页面(如商品缺货引导登记); 304 未修改:资源没变化,客户端直接用缓存(省流量)。 |
| 4xx(客户端错误类) | 客户端请求有问题,服务器无法处理 | 400 错误请求:参数格式错(如 API 传了无效 JSON); 401 未授权:需要登录但没登录; 403 禁止访问:权限不够(如普通用户访问管理员页面); 404 资源不存在:网址打错,或资源被删除。 |
| 5xx(服务器错误类) | 服务器处理请求时出错 | 500 内部服务器错误:服务器代码崩溃(如程序 bug); 503 服务不可用:服务器过载或维护(如双 11 期间服务器忙); 504 网关超时:服务器调用其他服务超时(如调用支付接口卡住)。 |
以上几种状态码都比较容易理解,此处重点解释一下3xx的状态码:
- 因为某些原因,你要访问的服务器无法再向你提供访问,所以服务器响应时,以3开头,并在报头中会添加一个Location字段 ,通过这一字段来告诉浏览器哪一个位置可以访问到该资源,浏览器会根据该地址,进行二次跳转。
6.3 常见的报头
因为报头中的字段有很多,此处我们只介绍一些最常见的。
Content_Length:正文的大小;Host:请求客户端的端口号和IP;User-agent:客户端的软件信息,比如用户的操作系统,浏览器版本信息等;referer:用户要访问的网页是从哪一个网页跳转过来的;Connect:keep-alive通信双方,采用长连接进行通信;
此处不同一下什么是长连接,以及对应的短链接又是什么意思:
在访问一个网址的时候,该网址内可能有很多元素,像视频,图片,文本等等;每一个元素都是资源,访问这些资源的时候都需要发送请求;
短链接:一次请求响应一个资源,相应完成后就关闭连接;
长连接:建立TCP连接,发送并返回多个HTTP请求和响应。
长连接可以满足只建立一次连接就能拿到多个资源。
Connect-Type:正文部分数据类型,如html,png,image...
以上就是一些常见的报头字段的含义。
6.4 Cookie和Session ID
HTTP请求是独立的,服务器会认为每一次请求都不一样,因此服务器并不能通过HTTP请求来看是不是同一个用户在进行访问,我们在浏览器上登录一个网站后,当关闭浏览器后,为什么不需要在此重复的登录???
此时就需要使用到Cookie了,Cookie相当于一张身份标识,当浏览器向服务端发送请求的时候,如果有一个身份标识,服务端就能认出来要访问的用户是谁了,通过这种方式就很好的解决了HTTP相互独立的问题。
浏览器获取Cookie的具体流程如下:
- 首次登录 :服务器验证账号密码后,在响应报头中通过
Set-Cookie响应头 下发 Cookie给浏览器(如user_id=123; password=abcdef)。 - 存储 Cookie:浏览器将 Cookie 存在内存(临时,浏览器关闭则删)或硬盘(长期,按过期时间留存)。
- 后续请求 :浏览器自动在 请求头的
Cookie字段 中携带 Cookie,服务器读取后识别用户。
当服务端向客户端发送响应的时候,如果对应的响应被中间人获取,此时他就可以通过对应的Cookies字段,拿到用户的账号和密码了。
此时为了防止这一种情况,需要使用Session ID.
- 服务器会为每个用户生成唯一 Session ID,并将用户数据(如登录信息、权限)与 ID 关联,保存在服务器中。
这样服务器就不需要将用户的账号和密码放到Cookie中,而是将Session ID放到Cookies中,当浏览器再次访问时,就只需要携带该Session ID即可。
通过这种方式,如果中间人拿到了报文,他也只能获取Session ID,而用户的账号和密码并不会被泄露,个人隐私得以保证。