前言
再三考虑强化学习和足式机器人算法两个系列之间的关系后,我目前决定专门的强化学习算法知识还是放到强化学习系列中,而足式机器人算法系列可能会以其相关的论文和项目为主介绍更多应用层面的内容。而为了以足式机器人为最终导向,本系列将不再以萨顿的《强化学习》为参考教材,博主将自行探索学习方向,但不影响前七篇的内容的基础地位,可以接续学习,本章将依赖于系列第五篇时序差分学习。本章开始将进入深度强化学习领域,深度学习相关知识已在【动手学深度学习】系列笔记中整理,故不再赘述。
DQN
DQN(deep Q-network,深度Q网络)将深度神经网络应用于Q-learning(Q学习)算法,是深度强化学习的开山之作。
Q网络
回顾一下时序差分学习一篇中的知识,Q-learning是一种直接以对最优动作价值函数q∗q_*q∗的估计为目标的时序差分控制
Q(St,At)←Q(St,At)+αRt+1+γmaxaQ(St+1,a)−Q(St,At) Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alphaR_{t+1}+\\gamma\\underset a\\max Q(S_{t+1},a)-Q(S_t,A_t) Q(St,At)←Q(St,At)+αRt+1+γamaxQ(St+1,a)−Q(St,At)
当该更新公式收敛时,有
Q(St,At)=Rt+1+γmaxaQ(St+1,a) Q(S_t,A_t)=R_{t+1}+\gamma\underset a\max Q(S_{t+1},a) Q(St,At)=Rt+1+γamaxQ(St+1,a)
Q-learning算法使用表格存储每个状态sss下采取动作aaa的动作价值函数Q(s,a)Q(s,a)Q(s,a),然而现实中很多情况下,强化学习任务所面临的状态空间是连续的、无穷大的,此时我们无法再使用表格进行存储。
为此,我们可以用一个线性函数Q(s,a;θ)Q(s,a;\theta)Q(s,a;θ)来近似Q(s,a)Q(s,a)Q(s,a),称为价值函数近似 ,并使用线性神经网络来拟合这个函数Q(s,a;θ)Q(s,a;\theta)Q(s,a;θ),称为Q网络。
- 输入与输出 :一个标准的Q网络的输入为状态sss,输出为所有动作aaa的QQQ值,因此只需要一次前向传播即可找出最优动作价值。相应地,其输入神经元数量为状态空间的维数(在此之前状态空间也可经过其他神经网络处理),输出神经元数量为动作空间的大小。
- 标签与损失函数 :Q网络的标签即其收敛的目标yt=rt+γ⋅maxaQ(st+1,a;θ)y_t=r_t+\gamma\cdot\max_aQ(s_{t+1},a;\theta)yt=rt+γ⋅maxaQ(st+1,a;θ),损失函数可采用均方损失L=12yt−Q(s,a;θ)2L=\displaystyle\frac12y_t-Q(s,a;\\theta)^2L=21yt−Q(s,a;θ)2。
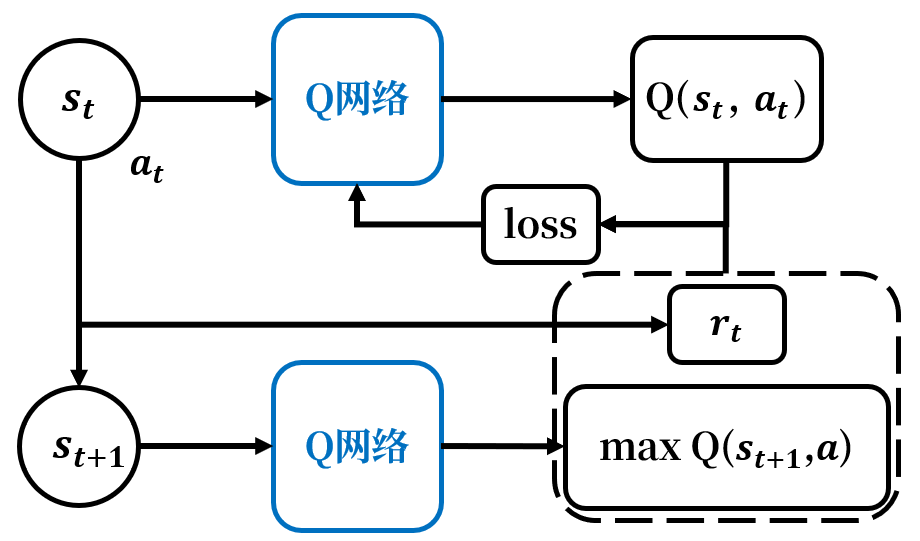
目前,我们可以得到DQN的算法流程如下
- 初始化Q网络,输入状态sts_tst,输出sts_tst下所有动作的QQQ值;
- 利用行动策略(例如ε\varepsilonε-贪心)选择一个动作aaa,将ata_tat输入到环境中,获得新状态st+1s_{t+1}st+1和rtr_trt;
- 将状态st+1s_{t+1}st+1输入Q网络,从输出中选择最优动作价值maxaQ(st+1,a;θ)\max_aQ(s_{t+1},a;\theta)maxaQ(st+1,a;θ);
- 计算标签yt=rt+γ⋅maxaQ(st+1,a;θ)y_t=r_t+\gamma\cdot\max_aQ(s_{t+1},a;\theta)yt=rt+γ⋅maxaQ(st+1,a;θ);
- 计算损失函数L=12yt−Q(s,a;θ)2L=\displaystyle\frac12y_t-Q(s,a;\\theta)^2L=21yt−Q(s,a;θ)2;
- 使用梯度下降更新Q网络中的参数;
- 丢弃四元组(st,at,rt,st+1)(s_t,a_t,r_t,s_{t+1})(st,at,rt,st+1),输入新状态st+1s_{t+1}st+1,重复更新工作。
经验回放
原始的DQN算法具有如下缺点:
- 数据相关:在序贯决策下,按顺序获得的经验之间具有相关性,不满足独立同分布;
- 经验浪费:每个状态转移四元组用完即弃,数据利用率低。
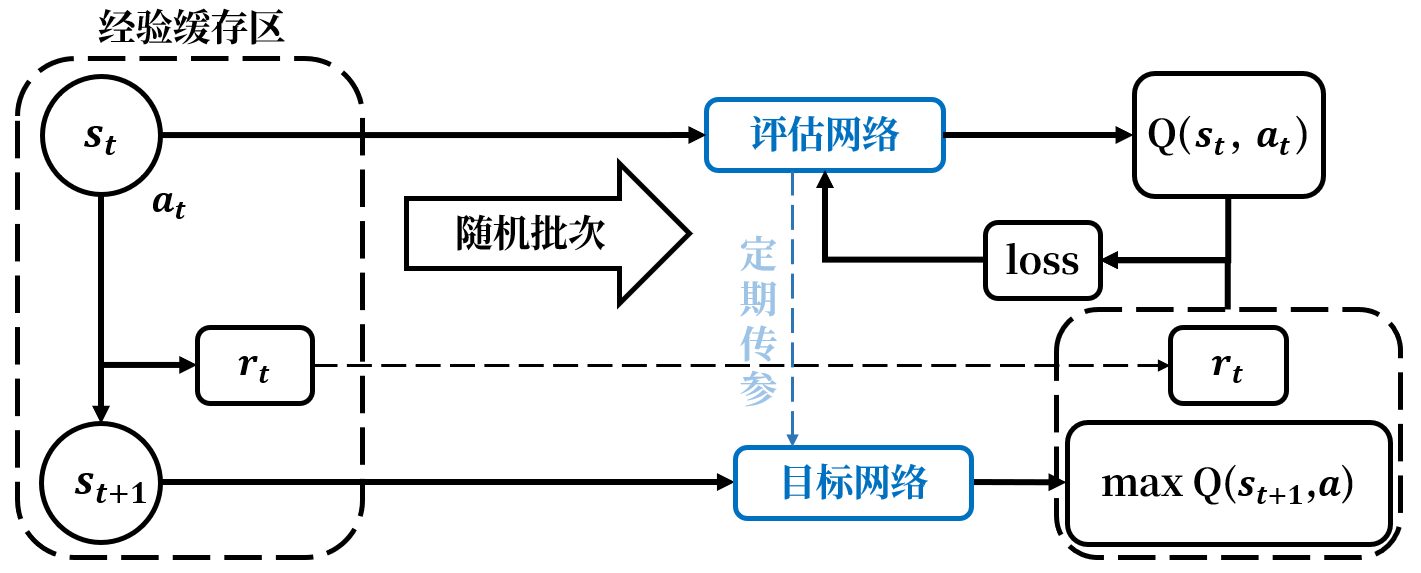
经验回放 可以克服上面两个缺点,它将经验(st,at,rt,st+1)(s_t,a_t,r_t,s_{t+1})(st,at,rt,st+1)存储在一个固定大小的回放缓冲区 中。在训练前,先让智能体采用某个行动策略π\piπ与环境持续交互,收集多条经验直至回放缓冲区存满。随后利用该回放缓冲区对Q网络进行训练,训练过程的每一轮等概率随机从缓冲区中抽取一个batch大小的经验训练网络,算出每个经验的梯度后使用梯度的平均更新参数。
在上述基础之上,经验回放还可作出如下改进:
- 分布式回放:多个智能体同时在多个环境中运行,将经验统一存储在一个缓冲区中,可以利用更多的资源更快地收集经验。
- 优先回放:为缓冲区中每条经验制定一个优先级,在采样经验时更倾向于选择优先级高的经验。
目标网络
原始的DQN算法使用一个Q网络,其在被训练的同时还用于给出自己的训练标签,这使得网络的更新总是在追逐一个不断变化的目标,在复杂的环境中极易产生振荡和发散,难以收敛。其次,仅依赖于单个Q估计存在最大化偏差问题(也称"高估")。
为了避免上述问题,DQN引入了第二个网络目标网络 Q(s,a;θ−)Q(s,a;\theta^-)Q(s,a;θ−),而原来的网络称为评估网络 。目标网络和评估网络的结构一样,只是参数不同,即θ−≠θ\theta^-\neq\thetaθ−=θ。
目标网络和评估网络将动作评估与标签计算的过程解耦。其中评估网络负责控制智能体,收集经验;目标网络用于计算标签yt=rt+γ⋅maxaQ(st+1,a;θ−)y_t=r_t+\gamma\cdot\max_aQ(s_{t+1},a;\theta^-)yt=rt+γ⋅maxaQ(st+1,a;θ−)。在每一批更新中,只有评估网络的权重θ\thetaθ会得到持续的更新,目标网络的权重θ−\theta^-θ−保持不变以稳定训练目标。评估网络更新一定次数后,其权重更新结果才会复制给目标网络,让目标网络也能得到更新,随后进行下一批更新。
经过经验回放和目标网络两大技术的引入,DQN算法的流程图如下
Double DQN
目标网络的引入确实在一定程度上减轻了高估问题,其通过在一定时间内固定目标网络避免了评估网络的高估立刻反映到自身的更新当中,延缓了高估的传播速度。但目标网络并没有触及高估问题的根源,即最大化操作。
与双Q学习改进Q学习的思想一脉相承,Double DQN也对DQN做出了相应的改进。Double DQN解耦了选择和评估动作的过程,即在计算下一个状态的信息时,由主网络θ\thetaθ(也就是原来的评估网络)而非目标网络来选出它认为最好的动作
a∗=argmaxaQ(st,a;θ) a^*=\underset{a}{\mathrm{argmax}}Q(s_t,a;\theta) a∗=aargmaxQ(st,a;θ)
而标签仍由目标网络给出,只是用于计算的最优动作不再由它独断
yt=rt+γ⋅Q(st+1,a∗;θ−) y_t=r_t+\gamma\cdot Q(s_{t+1},a^*;\theta^-) yt=rt+γ⋅Q(st+1,a∗;θ−)
由于
Q(st+1,a∗;θ−)⩽maxaQ(st+1,a;θ−) Q(s_{t+1},a^*;\theta^-)\leqslant\max_aQ(s_{t+1},a;\theta^-) Q(st+1,a∗;θ−)⩽amaxQ(st+1,a;θ−)
所以Double DQN进一步减缓了最大化带来的高估问题。这不会影响网络最终收敛到真正的最优动作,因为即时收益rtr_trt对更新的影响不断积累后终究会克服对真正最优动作价值的估计误差带来的影响,只要收集到足够多的经验,和动作价值相关的统计分布一定会收敛到其真实概率分布。