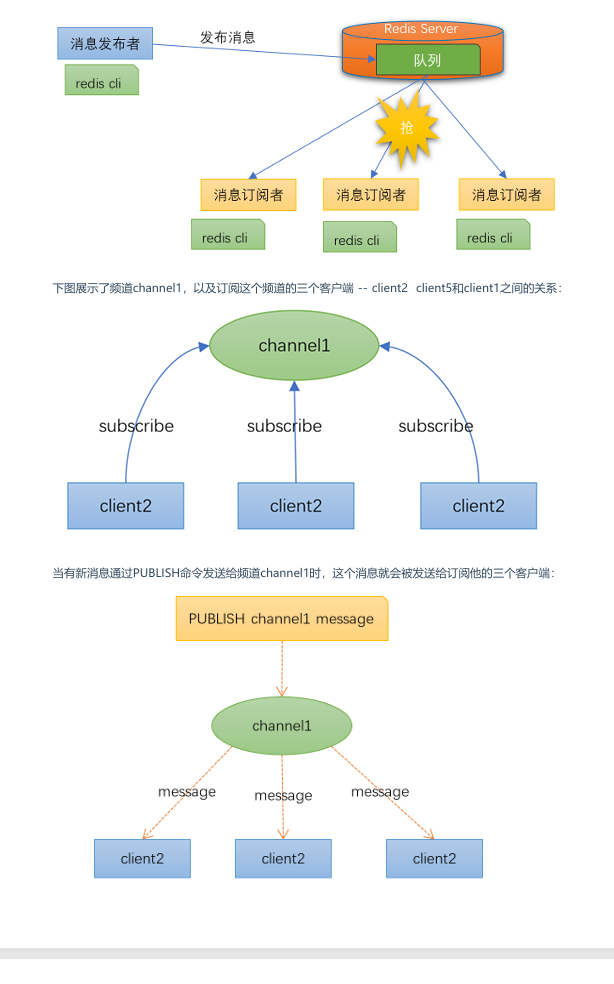
redis发布订阅
Redis发布订阅(pub/sub)是一种消息通信模式 :发布者(pub)发送消息,订阅者(sub)接受消息。
模型:

redis主从复制
概念:
主从复制:
指的是将一个Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower)。
数据的复制是单向的,只能从主节点到从节点。Master以写为主,Slave以读为主。
默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或者没有从节点),但一个从节点只能有一个主节点
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务冗余
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过从节点分担读负载,可以大大提供 Redis 服务器的并发量。
- 高可用 (集群) 基石:除了上述作用以外,主从复制还是哨兵和集群能够实现的基础,因此说主从复制是 Redis 高可用的基础。
一般来说,用将 Redis 运用于工程项目中,只使用一台 Redis 是万万不可能的,原因如下:
- 从结构上,单个 Redis 服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
- 从容量上,单个 Redis 服务器内存容量有限,就算一台 Redis 服务器内存容量为 256G,也不能将所有内存用作 Redis 存储内存,一般来说,单台 Redis 最大使用内存不应该超过 20G。
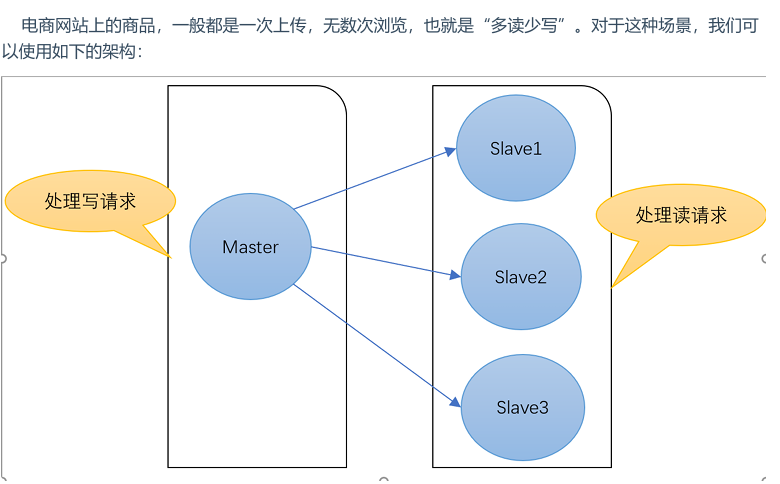
环境配置

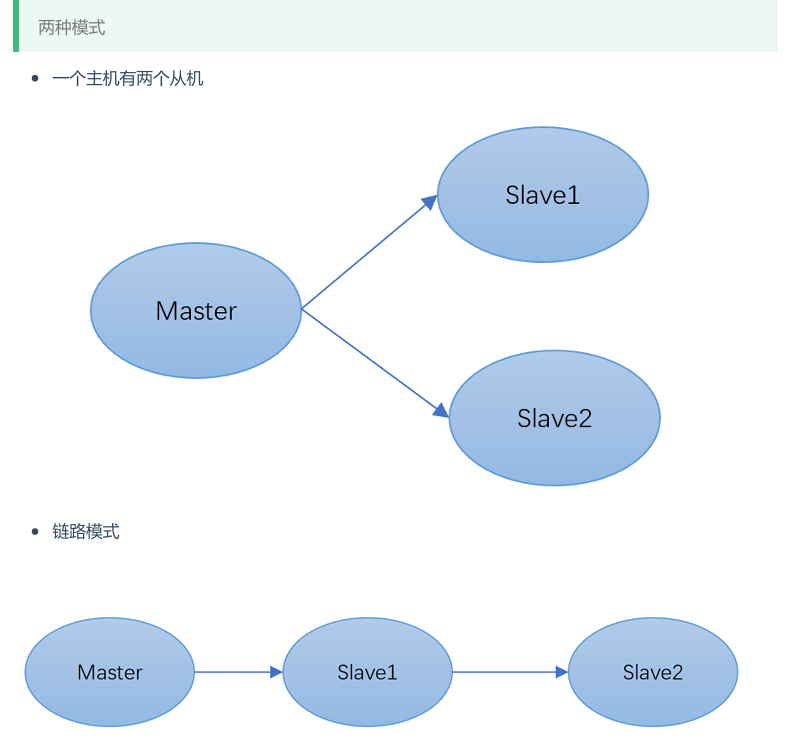
一主二从
默认情况下,每台Redis服务器都是主节点,主需要配置从机就行

真实的主从配置应该在配置文件中配置,这样的话是永久的,我们通过命令配置的是临时的!
主机可以写,从机不能写只能读!主机中的所有信息和数据,都会自动保存到从机中!
主机断开连接,从机依旧连接到主机的,但是没有写操作,这个时候,主机如果回来了,从机依旧可以直接获取到主机写的信息。
如果使用命令行配置的从机,重启后,就会变回主机!只要在把他重新配成原来主机的从机,数据依旧可以获取到。
复制原理:
Slave启动成功连接到Master后会向Master发送一个sync同步命令
Master接受到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,Master将传送整个数据文件(全量复制)到Slave,并完成一次完全同步。
全量复制 :Slave服务在接受到数据库文件数据后,将其存盘并加载到内存中
增量复制 :Master继续将新的所有收集到的修改命令一次传给Slave,完成同步
但是只要是重新连接Master,一次完全同步(全量复制)将被自动执行!
从机恢复主机:从机执行SLAVEOF no one 可以重新恢复为主机
哨兵模式
自动选举老大的模式
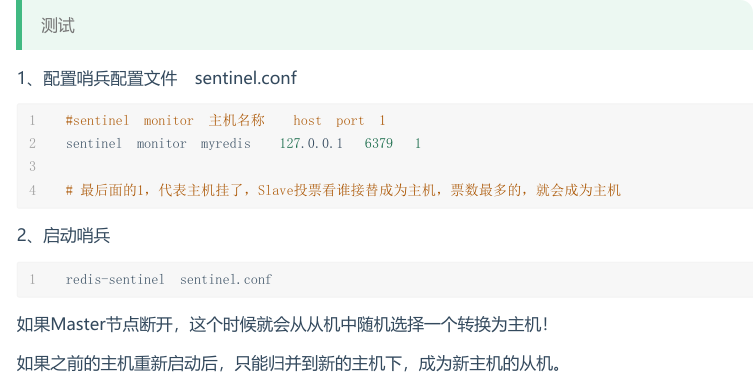
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。
某草篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个单独的进程,作为进程,他会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
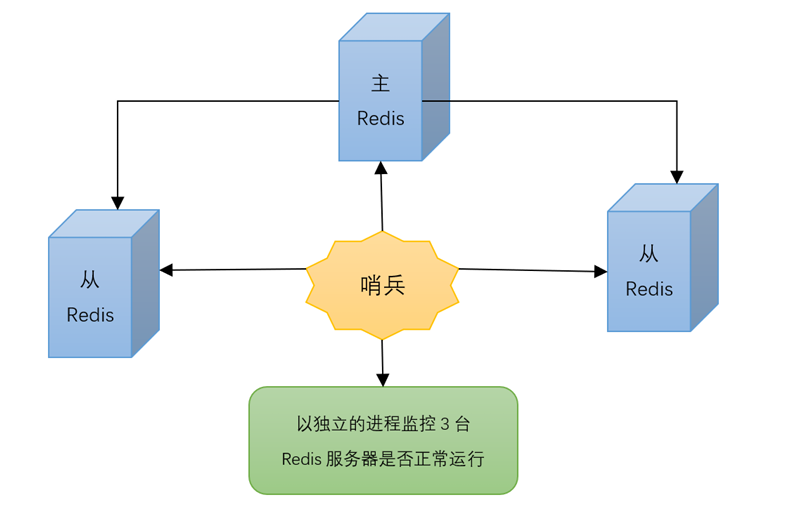
哨兵的作用:
通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
当哨兵监测到Master宕机,会自动将Slave切换成Master,然后通过发布/订阅模式通知其他的从服务器,修改配置文件,让它切换主机。
多哨兵模式:(哨兵互相监控,主管下线后投票实现客观下线 )
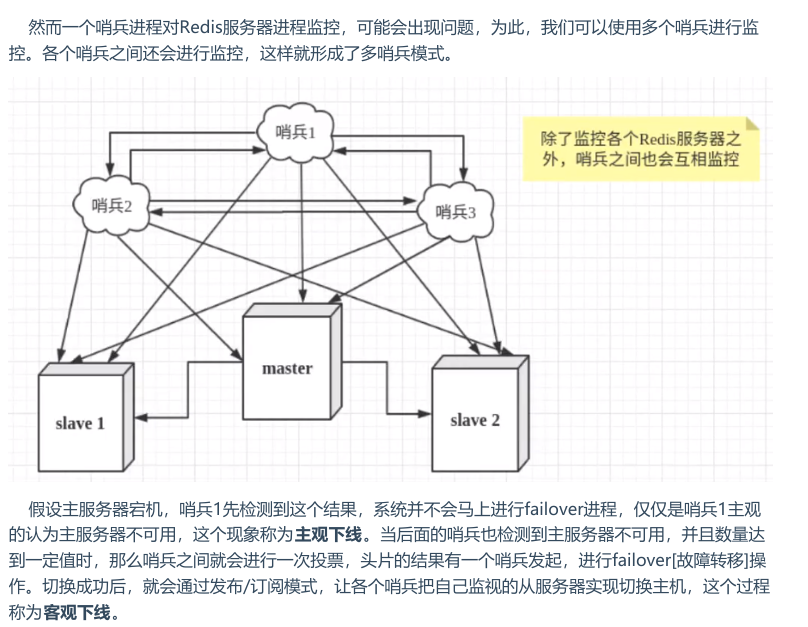
哨兵模式的优点
哨兵集群,基于主从复制模式,所有的主从复制优点,它全有
主从可以切换,故障可以转移,系统的可用性会更好
哨兵模式就是主从模式的升级,手动转自动,更加健壮
哨兵模式的缺点
Redis不好在线扩展,集群容量一旦到达上限,在线扩容十分麻烦
实现哨兵模式的配置很麻烦,里面有很多选择
Redis缓存穿透和雪崩
Redis缓存的使用,极大的提高了应用程序的性能和效率,特别是数据查询等。但同时,它也带来了一些问题。其中,最主要的问题就是数据一致性,从严格意义上来讲,这个问题是无解的。如果对数据一致性要求很高,那么就不能使用缓存。
1、缓存穿透 - 查不到
缓存穿透的就是用户想要查询一个数据,发现Redis中没有,也就是缓存没有命中,于是向持久层数据库发起查询,发现也没有这个数据,于是本次查询失败。当用户很多的情况下,缓存都没有命中,又都去请求持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于缓存穿透。
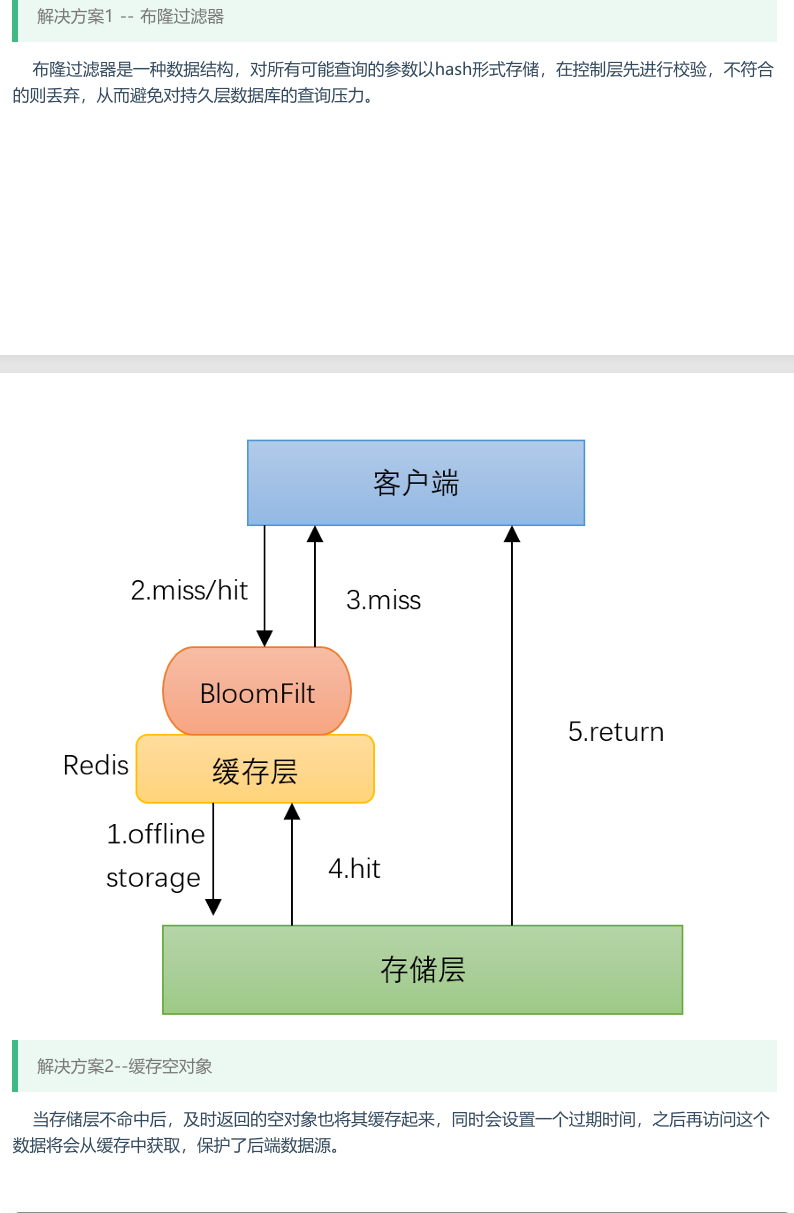
2、缓存击穿 - 量太大,缓存过期
这里需要注意和缓存穿透的区别,缓存击穿,是指一个key非常热点。在不停的扛着大量并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在也给屏蔽上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且写会缓存,会导致数据库瞬间压力过大

3.缓存雪崩
缓存雪崩指的是在某一时间段,缓存集中过期失效,或者Redis宕机。
比如:在写文本的时候,马上要到双十一零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就过期了。从而对这批商品的访问查询,都落到了后台数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会宕机的情况
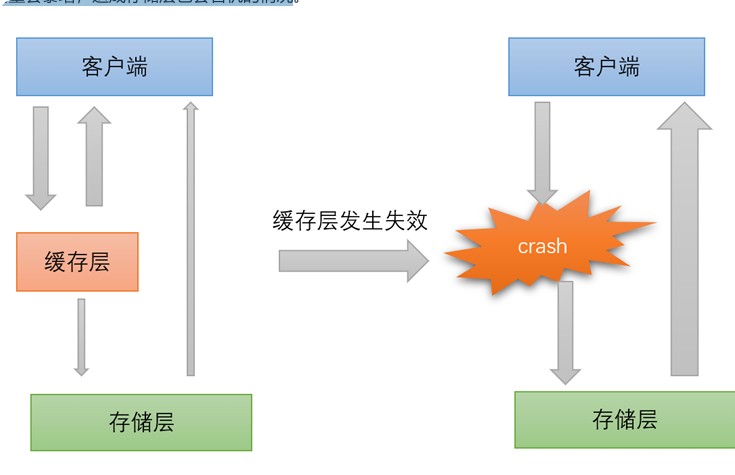
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务器节点的宕机,对数据服务器造成的压力是不可预估的,很可能瞬间就把数据库压宕机。

完整事务示例
示例1:用户注册事务
# 用户注册:检查用户名是否存在,然后创建用户
127.0.0.1:6379> WATCH user:username:张三 # 监视用户名
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> EXISTS user:username:张三 # 检查用户名是否已存在
QUEUED
127.0.0.1:6379> INCR user:id_counter # 获取新用户ID
QUEUED
127.0.0.1:6379> SET user:1001:name "张三" # 创建用户信息
QUEUED
127.0.0.1:6379> SET user:username:张三 1001 # 设置用户名索引
QUEUED
127.0.0.1:6379> EXEC
# 如果在执行期间其他客户端创建了"张三"用户,则事务失败示例2:库存扣减事务
127.0.0.1:6379> WATCH product:1001:stock
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> GET product:1001:stock
QUEUED
127.0.0.1:6379> DECR product:1001:stock
QUEUED
127.0.0.1:6379> LPUSH orders "order123,product1001"
QUEUED
127.0.0.1:6379> EXEC事务的局限性
不支持回滚
# 如果事务中部分命令失败,不会自动回滚已成功的命令
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET key1 "value1" # 会成功
QUEUED
127.0.0.1:6379> INCR key1 # 会失败
QUEUED
127.0.0.1:6379> SET key2 "value2" # 会成功
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) (error) ERR value is not an integer or out of range
3) OK # key2仍然被设置了!不支持条件判断
不能在事务中根据前一个命令的结果决定是否执行后续命令:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> GET balance
QUEUED
# 这里无法判断balance是否足够,然后决定是否执行DECR
127.0.0.1:6379> DECR balance
QUEUED
127.0.0.1:6379> EXECLua 脚本 - 更好的选择
由于事务的局限性,Redis 推荐使用 Lua 脚本来实现复杂的原子操作:
Lua 脚本示例:
# 扣减库存的Lua脚本
EVAL "local stock = redis.call('GET', KEYS[1])
if stock and tonumber(stock) >= tonumber(ARGV[1]) then
redis.call('DECRBY', KEYS[1], ARGV[1])
redis.call('LPUSH', KEYS[2], ARGV[2])
return 'SUCCESS'
else
return 'INSUFFICIENT_STOCK'
end" 2 product:1001:stock orders 1 "order123"Lua 脚本的优势:
- ✅ 真正的原子性
- ✅ 支持复杂逻辑
- ✅ 减少网络开销
- ✅ 避免竞态条件
实际应用建议
适合使用事务的场景:
- 需要一次性执行多个相关命令
- 对一致性要求不是极端严格
- 命令之间没有复杂的条件依赖
不适合使用事务的场景:
- 需要真正的回滚机制
- 命令执行依赖于前一个命令的结果
- 对一致性要求极高
最佳实践:
# 1. 简单操作使用事务
MULTI
SET key1 value1
SET key2 value2
EXEC
# 2. 需要条件判断的使用Lua脚本
EVAL "if redis.call('GET', KEYS[1]) then ... end" 1 key
# 3. 需要乐观锁的使用 WATCH
WATCH key
MULTI
# ... 命令
EXEC总结
Redis 事务的核心特点:
- 🎯 批量执行:一次性执行多个命令
- 🔒 串行化:执行期间不会被其他命令打断
- ⚠️ 无回滚:遇到错误继续执行,不会回滚
- 👀 乐观锁:通过 WATCH 实现简单的并发控制
记住关键点:
- Redis 事务不是真正的ACID事务
- 主要用途是批量执行 和简单乐观锁
- 复杂场景推荐使用 Lua 脚本
- WATCH + 事务 可以实现简单的并发控制
理解了这些,你就能正确地使用 Redis 事务了!