在人工智能技术飞速发展的今天,模型训练与部署之间的"鸿沟"始终是行业痛点------训练好的模型往往因框架差异、硬件限制等问题难以高效落地。而ONNX Runtime的出现,为这一难题提供了强有力的解决方案。作为微软开源的跨平台推理引擎,ONNX Runtime凭借其跨框架兼容性、全硬件加速能力和极致的性能优化,已成为AI模型部署领域的关键基础设施。本文将深入解析ONNX Runtime的核心价值、技术原理与应用场景,带你领略它如何为AI落地"加速"。
1、什么是ONNX Runtime?
ONNX Runtime全称为Open Neural Network Exchange Runtime,是微软于2018年开源的一款高性能推理引擎,旨在解决AI模型部署中的"碎片化"问题。它基于ONNX(Open Neural Network Exchange,开放神经网络交换格式)标准构建------ONNX作为跨框架的模型中间格式,能够将PyTorch、TensorFlow、TensorRT等主流训练框架的模型统一转换为标准格式,而ONNX Runtime则负责对这些标准化模型进行高效推理。
简单来说,ONNX Runtime扮演了"翻译官"与"加速器"的双重角色:一方面,它消除了不同框架模型之间的兼容性壁垒;另一方面,它通过软硬件协同优化,让模型在从云端到边缘端的各种设备上都能高效运行。截至2025年,ONNX Runtime已成为GitHub上星标超1.5万的热门项目,被微软、亚马逊、百度等众多企业广泛应用于生产环境。
2、ONNX Runtime的核心优势
ONNX Runtime之所以能成为AI部署的优选引擎,源于其四大核心优势,这些优势共同构成了它在性能、兼容性和灵活性上的竞争力。
1. 跨框架与跨平台兼容性
作为ONNX生态的核心推理引擎,ONNX Runtime天然支持所有符合ONNX标准的模型。目前,PyTorch、TensorFlow、MXNet、Scikit-learn等主流训练框架均已支持将模型导出为ONNX格式,这意味着用户无需重构模型,即可将不同框架训练的模型无缝迁移至ONNX Runtime进行推理。同时,ONNX Runtime支持Windows、Linux、macOS、Android、iOS等全平台系统,以及x86、ARM、RISC-V等多种芯片架构,真正实现了"一次转换,多端部署"。
2. 全硬件加速能力
ONNX Runtime深度整合了各类硬件的加速能力,通过"自适应硬件调度"机制,自动为不同设备选择最优的推理路径:
- CPU加速:通过Intel oneDNN、AMD MIOpen等库优化x86/ARM CPU的计算效率,尤其在低算力设备上表现突出;
- GPU加速:支持NVIDIA CUDA、TensorRT,AMD ROCm,以及Intel Arc GPU等,充分利用GPU的并行计算能力;
- 边缘端加速:针对FPGA、ASIC(如华为昇腾、寒武纪思元)等专用硬件提供定制化适配,满足工业物联网、自动驾驶等场景的低延迟需求;
- 移动端优化:通过轻量化推理引擎(ONNX Runtime Mobile)和模型量化技术,在手机、嵌入式设备上实现高效推理。
3. 极致的性能优化策略
ONNX Runtime通过多层次的优化策略,将模型推理性能提升至极致,主要包括:
- 计算图优化:对模型计算图进行算子融合(如Conv+BN+Relu融合)、常量折叠、死代码消除等,减少计算开销;
- 量化与剪枝:支持INT8、FP16等低精度量化,在精度损失可控的前提下大幅提升推理速度、降低内存占用;
- 动态批处理与并行推理:支持动态调整批处理大小,并通过多线程、多流并行计算进一步提升吞吐量;
- kernel自动选择:针对不同硬件自动选择最优的计算内核(Kernel),避免用户手动调优的繁琐。
根据微软官方测试数据,在ResNet-50、BERT等典型模型上,ONNX Runtime相比原生框架推理速度平均提升2-5倍,在GPU上甚至可达到10倍以上的性能增益。
4. 低门槛与高扩展性
ONNX Runtime提供了Python、C++、C#、Java等多语言API,开发者只需几行代码即可完成模型加载与推理,极大降低了使用门槛。同时,它支持自定义算子扩展------当模型中包含ONNX标准未定义的算子时,用户可通过注册自定义算子的方式实现兼容,满足特殊场景的需求。此外,ONNX Runtime还与TensorFlow Lite、ML.NET等框架深度集成,进一步拓展了其应用生态。
3、ONNX Runtime的技术架构
ONNX Runtime的高性能得益于其模块化、分层化的技术架构,各层职责明确且协同高效,从硬件交互到用户接口形成完整链路。这种架构设计既保证了对不同硬件的兼容性,又能通过层间优化实现极致推理性能。以下是各层的详细解析及数据流向流程图:
1. 架构分层详细解析
ONNX Runtime从下至上分为四层,每层承担特定功能,共同支撑模型的高效推理:
- 硬件适配层(Hardware Abstraction Layer) :作为架构的"地基",负责屏蔽不同硬件的底层差异。它封装了CPU(Intel oneDNN/AMD MIOpen)、GPU(NVIDIA CUDA/TensorRT、AMD ROCm)、FPGA、ASIC等硬件的加速库,向上提供统一的硬件访问接口。无论底层是x86服务器还是ARM嵌入式设备,上层模块都能通过该层获得一致的硬件操作体验。
- 计算内核层(Kernel Layer) :提供模型推理所需的"计算单元"。该层包含大量经过硬件针对性优化的算子内核(如卷积、矩阵乘法、激活函数等),覆盖ONNX标准定义的全部算子。同时支持自定义算子注册机制,当模型中存在非标准算子时,开发者可通过接口注册自定义内核,确保特殊模型的兼容性。
- 优化与执行层(Optimization & Execution Layer) :架构的"大脑",负责模型推理的全局调度与优化。核心功能包括: - 计算图优化:对输入的ONNX模型进行算子融合(如Conv+BN+Relu合并为单一算子)、常量折叠(将计算结果为常量的节点替换为具体数值)、死代码消除(删除无用计算节点)等操作,减少冗余计算; - 执行计划生成:根据硬件类型(如CPU/GPU)和模型结构,将优化后的计算图拆分为可并行执行的任务片段; - 资源调度:通过线程池、流处理等机制,将任务分配到对应的硬件核心,实现计算资源的高效利用。
- API接口层(API Layer) :面向开发者的"交互窗口"。提供Python、C++、C#、Java、JavaScript等多语言API,封装了模型加载、输入预处理、推理执行、输出后处理等全流程功能。开发者无需关注底层硬件细节,仅需调用简单接口即可完成模型部署,极大降低了使用门槛。
2. 架构数据流向流程图
以下流程图直观展示了ONNX模型从输入到输出的全链路数据流向,以及各架构层的交互关系:
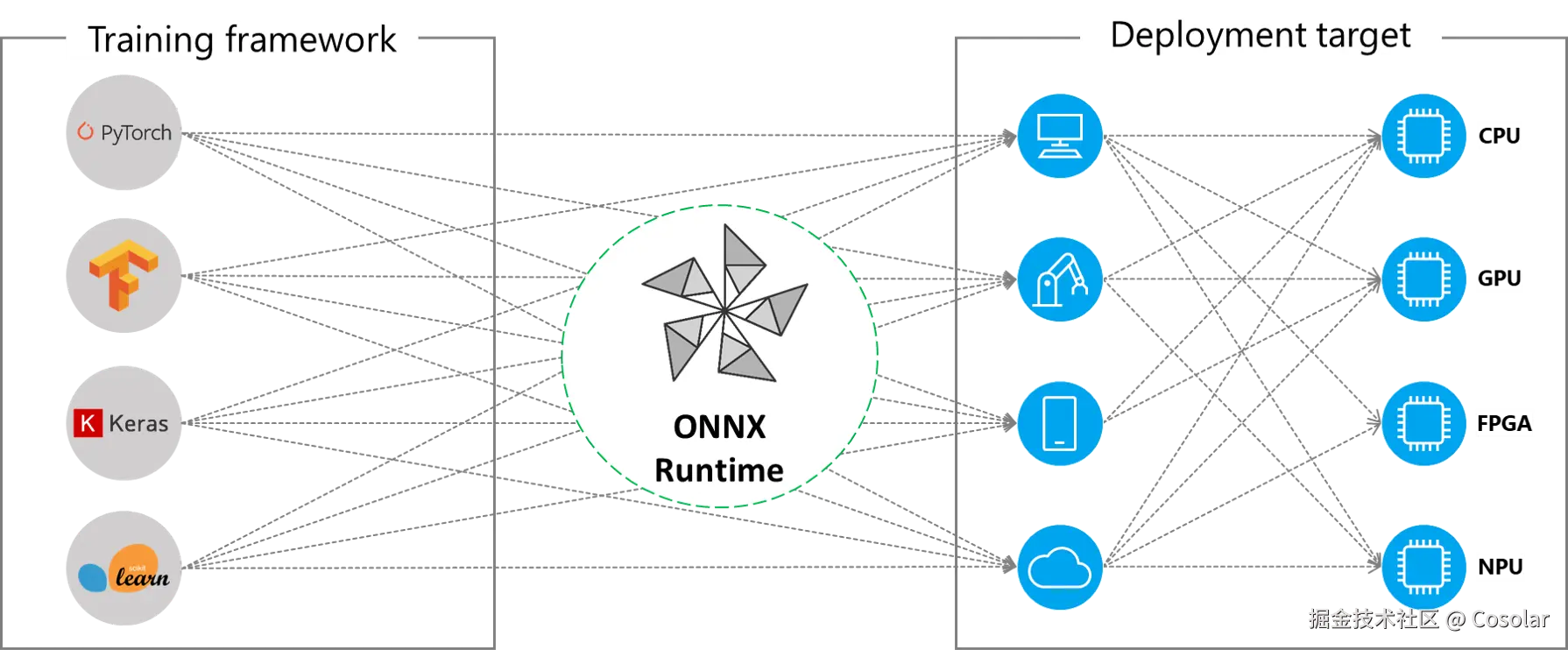 ONNX Runtime的高性能离不开其模块化的技术架构,主要分为四层,从下至上形成了"硬件抽象-优化-执行-接口"的完整链路:
ONNX Runtime的高性能离不开其模块化的技术架构,主要分为四层,从下至上形成了"硬件抽象-优化-执行-接口"的完整链路:
- 硬件适配层(Hardware Abstraction Layer):作为最底层,负责与CPU、GPU、FPGA等硬件交互,封装不同硬件的加速库(如CUDA、oneDNN),为上层提供统一的硬件访问接口;
- 计算内核层(Kernel Layer):包含大量优化后的计算内核,覆盖卷积、矩阵乘法、激活函数等常用算子,同时支持自定义算子注册;
- 优化与执行层(Optimization & Execution Layer):核心层之一,负责模型的计算图优化、执行计划生成和资源调度。它会根据硬件类型自动选择优化策略,并将计算图拆分为可并行执行的任务;
- API接口层(API Layer):最上层,提供多语言API接口,支持开发者快速集成模型推理功能,同时包含模型加载、输入输出处理等工具函数。