摘要:在机器学习领域,有一句名言:"Garbage in, garbage out." (垃圾进,垃圾出)。本文将带你深入机器学习项目中价值最高的部分------数据预处理与特征工程。你将学会如何清洗"生"数据,并从中提炼出能让模型"吃得更好、学得更快"的"黄金特征"。掌握这些,你对模型效果的掌控力将远超那些只关心算法的人。
前言:你不是算法工程师,你是"数据大厨"
在上一篇 【手撕机器学习 02】 中,我们已经掌握了NumPy和Pandas这两把锋利的"厨刀"。现在,是时候处理真正的"食材"了。
想象一下,再厉害的米其林大厨(机器学习算法),如果拿到的是一堆发霉、未经清洗的食材(原始数据),也做不出美味佳肴。
💡 在实际的机器学习项目中,超过70%的时间都花在了数据准备上。这一步的质量,直接决定了你模型性能的上限。算法和调参,只是在逼近这个上限而已。
本篇,我们将扮演一位"数据大厨",学习两项核心技艺:
- 数据预处理 (Data Preprocessing):就像"洗菜、择菜、切菜"。它是数据准备的基础,目的是处理数据中的噪声和不一致性。
- 特征工程 (Feature Engineering):就像"配菜、调味、腌制"。它是一门艺术,目的是从原始数据中创造出更能体现问题本质的、对模型更有用的新特征。
准备好,让我们开始处理我们的"食材"吧。
一、数据预处理:把"脏数据"变"干净"的三步清洗法
我们将使用Pandas来完成大部分预处理工作。
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, MinMaxScaler, LabelEncoder
# 创建一个包含各种问题的模拟DataFrame
data = {
'age': [25, 30, np.nan, 35, 40],
'gender': ['Male', 'Female', 'Male', 'Female', 'Male'],
'city': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago'],
'income': [50000, 120000, 80000, 60000, 90000]
}
df = pd.DataFrame(data)
print("--- 原始数据 ---")
print(df)第一步:处理缺失值
这是我们在上一篇中接触过的,也是最常见的任务。
python
# 用年龄的平均值填充缺失的年龄
mean_age = df['age'].mean()
df['age'].fillna(mean_age, inplace=True) # inplace=True 表示直接在原始DataFrame上修改
print("\n--- 1. 处理缺失值后 ---")
print(df)第二步:处理类别特征
机器学习算法只能理解数字。我们需要将像'Male', 'New York'这样的文本转换成数值。
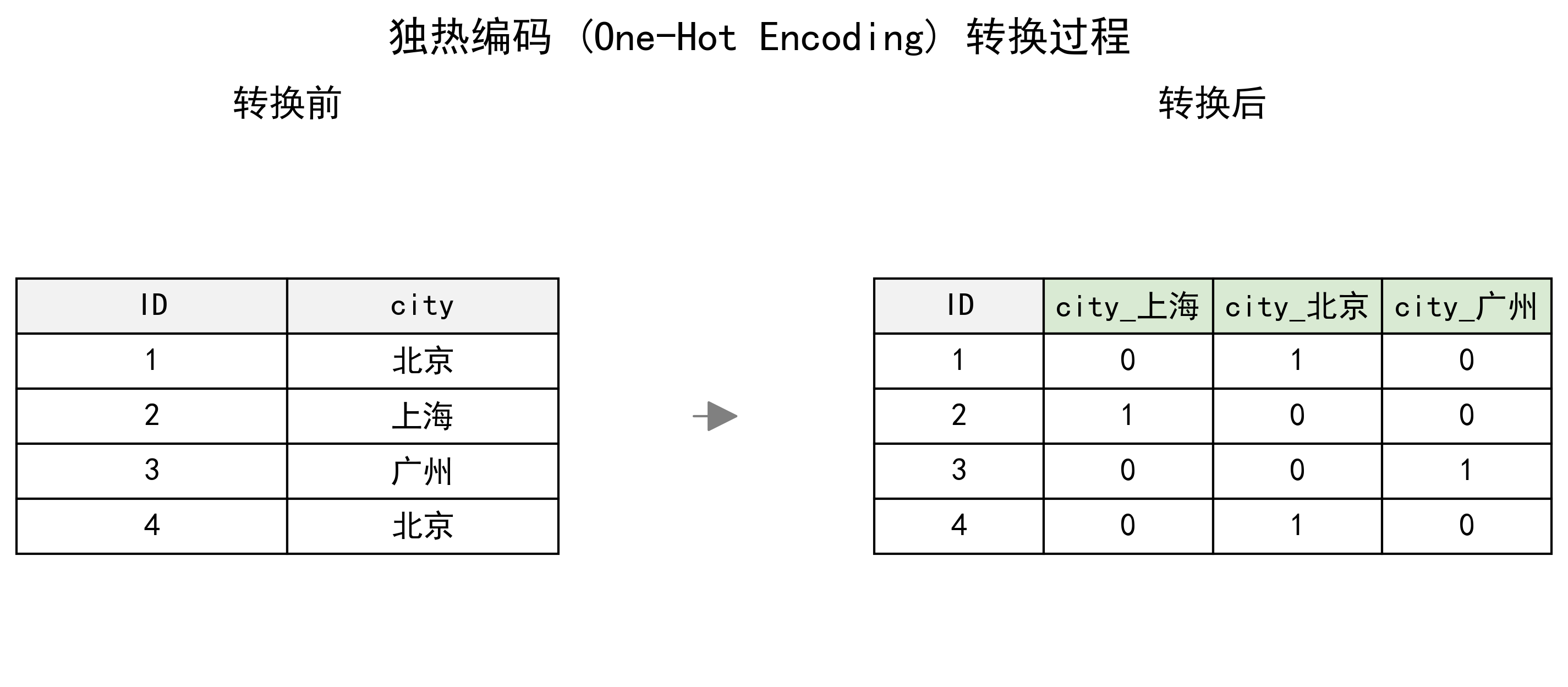
方法一:独热编码 (One-Hot Encoding)
这是最常用的方法,它为每个类别创建一个新的二进制(0/1)列,避免了类别间不存在的大小关系。
python
# 使用Pandas的get_dummies函数
df_onehot = pd.get_dummies(df, columns=['gender', 'city'])
print("\n--- 2. 独热编码后 ---")
print(df_onehot)方法二:标签编码 (Label Encoding)
将每个类别映射到一个整数。
python
# 标签编码只适用于有序类别,或某些树模型
# 这里我们仅作演示
label_encoder = LabelEncoder()
df_label = df.copy()
df_label['gender'] = label_encoder.fit_transform(df_label['gender'])
# df_label -> 'Male'会变成1, 'Female'会变成0⚠️ 注意 :标签编码会引入
0 < 1 < 2这样的人为大小关系。它只适用于本身就有序的类别(如"学士"<"硕士"<"博士"),或者一些对数值大小不敏感的树模型。通常情况下,优先使用独热编码。
第三步:特征缩放 (Feature Scaling)
如果不同特征的数值范围相差巨大(比如年龄是几十,收入是几万),很多算法(如线性回归、KNN、SVM)的表现会变差。我们需要将所有特征"拉"到同一个尺度上。
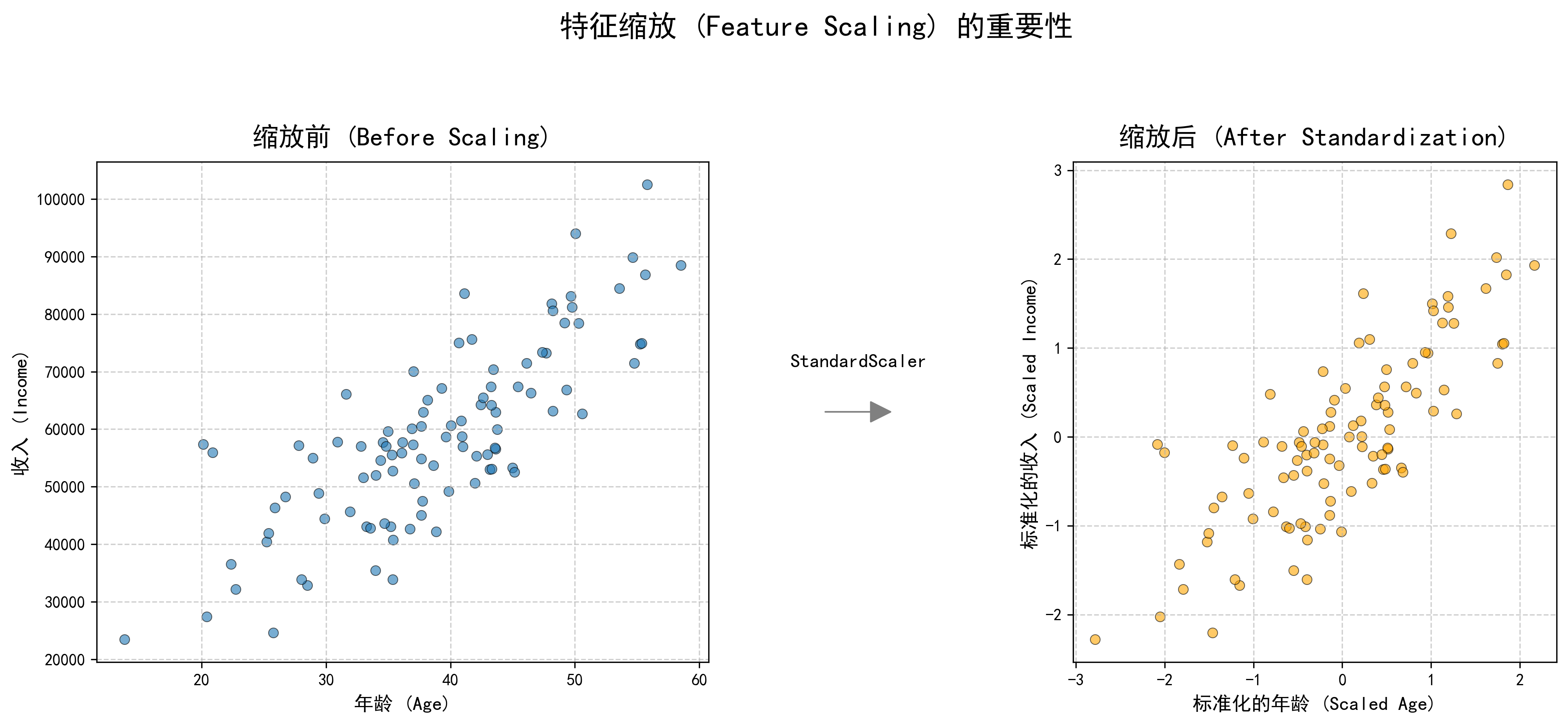
- 标准化 (Standardization) :将数据缩放到均值为0,方差为1 。它保留了数据的原始分布形状,是最常用的缩放方法。
python
scaler = StandardScaler()
# 我们对经过独热编码后的DataFrame进行操作
df_scaled = df_onehot.copy()
df_scaled[['age', 'income']] = scaler.fit_transform(df_scaled[['age', 'income']])
print("\n--- 3. 特征标准化后 ---")
print(df_scaled)- 归一化 (Normalization):将数据缩放到一个固定的区间,通常是****。适用于数据分布有明显边界的情况。
二、特征工程:从数据中"榨取"信息的两招提炼术
特征工程更依赖于你对业务的理解,是真正体现"人工"智能的地方。
第一招:特征创造 (Feature Creation)
从现有特征中组合出新的、更有意义的特征。
python
# 假设我们有一个电商数据集
sales_df = pd.DataFrame({'price': [100, 50, 200], 'quantity': [2, 5, 1]})
# 创造一个新特征 'total_price'
sales_df['total_price'] = sales_df['price'] * sales_df['quantity']
print("\n--- 特征创造 ---")
print(sales_df)```
#### **第二招:特征提取 (Feature Extraction)**
从复杂数据中提取出关键信息。
```python
# 假设我们有时间戳数据
time_df = pd.DataFrame({'timestamp': ['2023-10-27 10:00:00']})
time_df['timestamp'] = pd.to_datetime(time_df['timestamp'])
# 从时间戳中提取出小时和星期几
time_df['hour'] = time_df['timestamp'].dt.hour
time_df['day_of_week'] = time_df['timestamp'].dt.dayofweek # Monday=0
print("\n--- 特征提取 ---")
print(time_df)三、最后一步:划分训练集与测试集
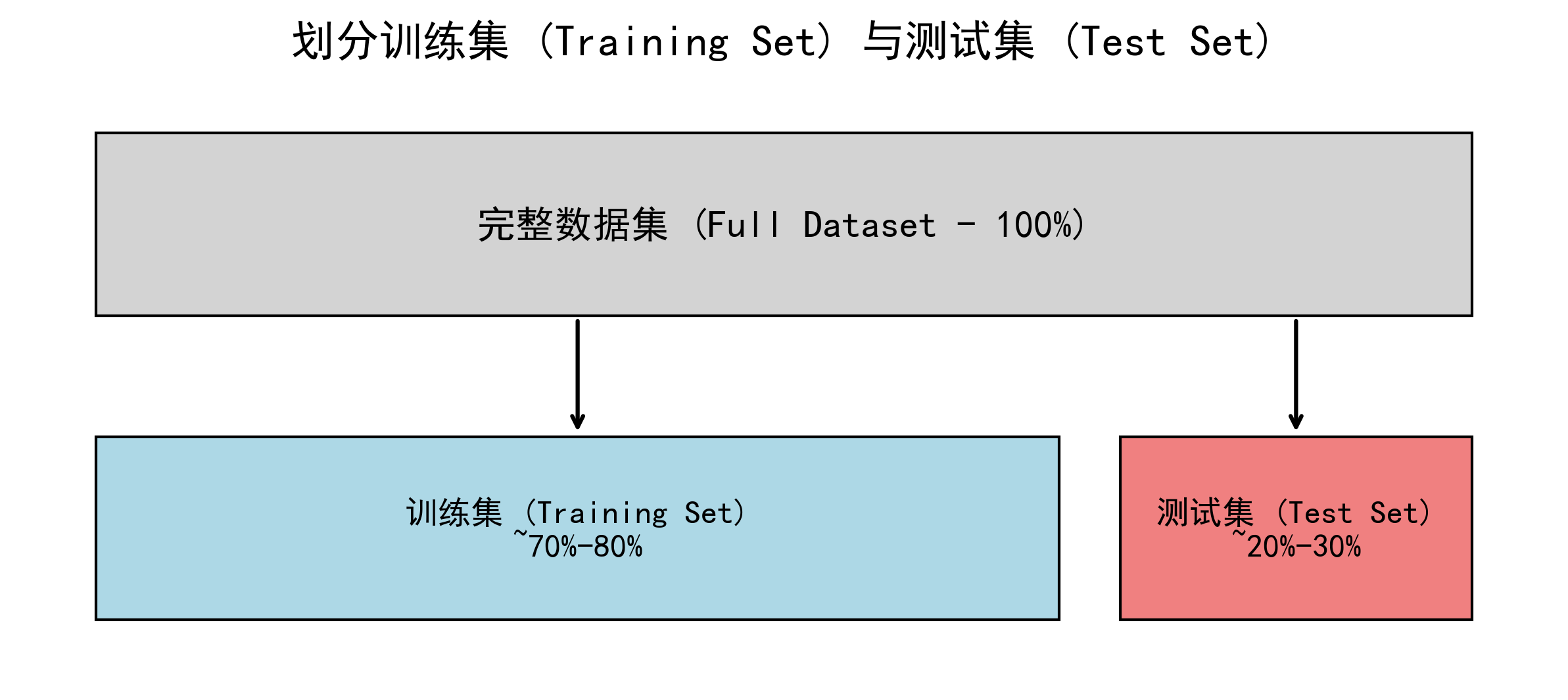
这是模型训练前的"分班"仪式,也是保证我们能客观评价模型的关键。
💡 为什么要划分?
我们必须用模型从未见过的数据来评估它,就像用一张全新的"期末考试卷"来检验学生是否真的学会了,而不是"死记硬背"了练习册。
- 训练集 (Training Set):用于训练模型,就像给学生的"练习册"。
- 测试集 (Test Set):用于最终评估模型性能,就像"期末考试卷"。
python
from sklearn.model_selection import train_test_split
# 假设df_scaled是我们的最终特征矩阵
# 我们想预测收入,所以'income'是目标y
X = df_scaled.drop('income', axis=1) # 特征 (除了目标以外的所有列)
y = df_scaled['income'] # 目标
# random_state保证每次划分的结果都一样,便于复现
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
print("\n--- 划分数据集 ---")
print(f"训练集特征形状: {X_train.shape}")
print(f"测试集特征形状: {X_test.shape}")总结:准备好你的"黄金"食粮
在本篇中,我们扮演了一位"数据大厨",学习了机器学习项目中最关键的准备工作:
- 数据预处理 :掌握了处理缺失值 、类别特征 (独热编码vs标签编码)和进行特征缩放的三步清洗法。
- 特征工程 :学习了特征创造 和特征提取的两招提炼术。
- 数据集划分 :理解了为何必须划分训练集 与测试集,并学会了如何操作。
现在,我们的"食材"已经处理干净、调味完毕,变成了能让模型大快朵颐的"黄金特征"。从下一篇开始,我们将正式开火,把这些食粮喂给我们亲手实现的第一个机器学习模型!
如果觉得这篇文章让你对数据预处理有了质的飞跃,请一定记得 👍 点赞、⭐ 收藏、💬 评论,你的支持是"大厨"更新的全部动力!
预告:【手撕机器学习 04】手撕线性回归:从"蒙眼下山"彻底理解梯度下降