我自己的原文哦~ https://blog.51cto.com/whaosoft/12270131
#2024自动驾驶世界模型大观~
"整体上来说,完全地理解这个世界是世界模型要干的事。"------任少卿在接受采访中说到。
那么何谓世界模型呢?按照最初wayve展示的demo,世界模型依赖实车采集的海量数据,基于生成模型去生成未来场景来和真实的未来时刻数据,进而进行监督,这是典型的无监督训练。其最巧妙的地方则在于要想成功预测未来时刻的场景,你必须对现在时刻场景的语义信息以及世界演化的规律有着深刻的了解。当下自动驾驶方向的世界模型可以分成两大类:生成式和端到端。
RenderWorld: World Model with Self-Supervised 3D Label
上海科技大学的工作:仅使用视觉的端到端自动驾驶不仅比LiDAR视觉融合更具成本效益,而且比传统方法更可靠。为了实现经济且稳健的纯视觉自动驾驶系统,我们提出了RenderWorld,这是一种仅支持视觉的端到端自动驾驶框架,它使用基于自监督高斯的Img2Occ模块生成3D占用标签,然后通过AM-VAE对标签进行编码,并使用世界模型进行预测和规划。RenderWorld采用高斯散射来表示3D场景和渲染2D图像,与基于NeRF的方法相比,大大提高了分割精度并降低了GPU内存消耗。通过应用AM-VAE分别对空气和非空气进行编码,RenderWorld实现了更细粒度的场景元素表示,从而在自回归世界模型的4D占用预测和运动规划方面取得了最先进的性能。
OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
复旦和清华等团队的工作:多模态大语言模型(MLLM)的兴起刺激了它们在自动驾驶中的应用。最近基于MLLM的方法通过学习从感知到行动的直接映射来实现最终控制,忽略了世界的动态以及行动与世界动态之间的关系。相比之下,人类拥有世界模型,使他们能够基于3D内部视觉表示来模拟未来的状态,并相应地计划行动。为此,我们提出了OccLLaMA,这是一种占用语言动作生成世界模型,它使用语义占用作为一般的视觉表示,并通过自回归模型统一视觉语言动作(VLA)模式。具体来说,我们引入了一种新的类似VQVAE的场景标记器,以有效地离散和重建语义占用场景,同时考虑到其稀疏性和类不平衡性。然后,我们为视觉、语言和动作构建了一个统一的多模态词汇表。此外,我们增强了LLM,特别是LLaMA,以对统一词汇表执行下一个令牌/场景预测,从而完成自动驾驶中的多项任务。大量实验表明,OccLLaMA在多个任务中都取得了具有竞争力的性能,包括4D占用预测、运动规划和视觉问答,展示了其作为自动驾驶基础模型的潜力。
Mitigating Covariate Shift in Imitation Learning for Autonomous Vehicles Using Latent Space Generative World Models
英伟达的工作:我们建议使用潜在空间生成世界模型来解决自动驾驶中的协变量转换问题。世界模型是一种神经网络,能够根据过去的状态和动作预测代理的下一个状态。通过在训练过程中利用世界模型,驾驶策略有效地缓解了协变量变化,而不需要过多的训练数据。在端到端训练期间,我们的策略通过与人类演示中观察到的状态对齐来学习如何从错误中恢复,以便在运行时可以从训练分布之外的扰动中恢复。此外我们介绍了一种基于Transformer的感知编码器,该编码器采用多视图交叉注意力和学习场景查询。我们呈现了定性和定量结果,展示了在CARLA模拟器闭环测试方面对现有技术的显著改进,并展示了CARLA和NVIDIA DRIVE Sim处理扰动的能力。
Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
浙大&华为团队的工作:世界模型基于各种自车行为设想了潜在的未来状态。它们嵌入了关于驾驶环境的广泛知识,促进了安全和可扩展的自动驾驶。大多数现有方法主要关注数据生成或世界模型的预训练范式。与上述先前的工作不同,我们提出了Drive OccWorld,它将以视觉为中心的4D预测世界模型应用于自动驾驶的端到端规划。具体来说,我们首先在内存模块中引入语义和运动条件规范化,该模块从历史BEV嵌入中积累语义和动态信息。然后将这些BEV特征传送到世界解码器,以进行未来的占用和流量预测,同时考虑几何和时空建模。此外,我们建议在世界模型中注入灵活的动作条件,如速度、转向角、轨迹和命令,以实现可控生成,并促进更广泛的下游应用。此外,我们探索将4D世界模型的生成能力与端到端规划相结合,从而能够使用基于占用的成本函数对未来状态进行连续预测并选择最佳轨迹。对nuScenes数据集的广泛实验表明,我们的方法可以生成合理可控的4D占用率,为推动世界生成和端到端规划开辟了新途径。
BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space
百度的工作:世界模型因其预测潜在未来情景的能力而在自动驾驶领域受到越来越多的关注。在本文中,我们提出了BEVWorld,这是一种将多模态传感器输入标记为统一紧凑的鸟瞰图(BEV)潜在空间以进行环境建模的新方法。世界模型由两部分组成:多模态标记器和潜在BEV序列扩散模型。多模态标记器首先对多模态信息进行编码,解码器能够以自监督的方式通过光线投射渲染将潜在的BEV标记重建为LiDAR和图像观测。然后,潜在的BEV序列扩散模型在给定动作标记作为条件的情况下预测未来的情景。实验证明了BEVWorld在自动驾驶任务中的有效性,展示了其生成未来场景的能力,并使感知和运动预测等下游任务受益。
Planning with Adaptive World Models for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2406.10714v2
- 项目主页:https://arunbalajeev.github.io/world_models_planning/world_model_paper.html
卡内基梅隆大学的工作:运动规划对于复杂城市环境中的安全导航至关重要。从历史上看,运动规划器(MP)已经用程序生成的模拟器(如CARLA)进行了评估。然而,这种合成基准并不能捕捉到现实世界中的多智能体交互。nuPlan是最近发布的MP基准测试,它通过用闭环仿真逻辑增强现实世界的驾驶日志来解决这一局限性,有效地将固定数据集转化为反应式模拟器。我们分析了nuPlan记录日志的特征,发现每个城市都有自己独特的驾驶行为,这表明稳健的规划者必须适应不同的环境。我们学习使用BehaviorNet对这种独特的行为进行建模,BehaviorNet是一种图卷积神经网络(GCNN),它使用最近观察到的代理历史中得出的特征来预测反应性代理行为;直觉上,一些激进的特工可能会尾随领先的车辆,而另一些则可能不会。为了模拟这种现象,BehaviorNet预测代理运动控制器的参数,而不是直接预测其时空轨迹(就像大多数预测者那样)。最后,我们提出了AdaptiveDriver,这是一种基于模型预测控制(MPC)的规划器,可以展开基于BehaviorNet预测的不同世界模型。我们广泛的实验表明,AdaptiveDriver在nuPlan闭环规划基准上取得了最先进的结果,在Test-14 Hard R-CLS上比之前的工作提高了2%,即使在从未见过的城市进行评估时也具有普遍性。
Enhancing End-to-End Autonomous Driving with Latent World Model
中科院和中科院自动化研究所等团队的工作:端到端自动驾驶引起了广泛关注。当前的端到端方法在很大程度上依赖于感知任务的监督,如检测、跟踪和地图分割,以帮助学习场景表示。然而,这些方法需要大量的标注,阻碍了数据的可扩展性。为了应对这一挑战,我们提出了一种新的自监督方法来增强端到端的驱动,而不需要昂贵的标签。具体来说,我们的框架LAW使用LAtent World model,根据预测的自车行为和当前框架的潜在特征来预测未来的潜在特征。预测的潜在特征由未来实际观察到的特征进行监督。这种监督联合优化了潜在特征学习和动作预测,大大提高了驾驶性能。因此,我们的方法在开环和闭环基准测试中都实现了最先进的性能,而无需昂贵的标注。
Probing Multimodal LLMs as World Models for Driving
MIT等团队的工作:我们冷静地看待了多模态大语言模型(MLLM)在自动驾驶领域的应用,并挑战/验证了一些常见的假设,重点是它们在闭环控制环境中通过图像/帧序列推理和解释动态驾驶场景的能力。尽管GPT-4V等MLLM取得了重大进展,但它们在复杂、动态驾驶环境中的性能在很大程度上仍未经过测试,这是一个广泛的探索领域。我们进行了一项全面的实验研究,从固定车载摄像头的角度评估各种MLLM作为世界驾驶模型的能力。我们的研究结果表明,虽然这些模型能够熟练地解释单个图像,但它们在跨描述动态行为的框架合成连贯的叙事或逻辑序列方面存在很大困难。实验表明,在预测(i)基本车辆动力学(前进/后退、加速/减速、右转或左转)、(ii)与其他道路参与者的相互作用(例如,识别超速行驶的汽车或繁忙的交通)、(iii)轨迹规划和(iv)开放集动态场景推理方面存在相当大的不准确性,这表明模型训练数据中存在偏差。为了实现这项实验研究,我们引入了一个专门的模拟器DriveSim,旨在生成各种驾驶场景,为评估驾驶领域的MLLM提供平台。此外,我们还贡献了完整的开源代码和一个新的数据集"Eval LLM Drive",用于评估驾驶中的MLLM。我们的研究结果突显了当前最先进MLLM能力的一个关键差距,强调了增强基础模型的必要性,以提高其在现实世界动态环境中的适用性。
OccSora: 4D Occupancy Generation Models as World Simulators for Autonomous Driving
北航&UC Berkeley等团队的工作:了解3D场景的演变对于有效的自动驾驶非常重要。虽然传统方法将场景开发与单个实例的运动相结合,但世界模型作为一个生成框架出现,用于描述一般的场景动态。然而大多数现有方法采用自回归框架来执行下一个令牌预测,这在建模长期时间演化方面效率低下。为了解决这个问题,我们提出了一种基于扩散的4D占用生成模型OccSora,来模拟自动驾驶3D世界的发展。我们采用4D场景标记器来获得4D占用输入的紧凑离散时空表示,并实现长序列占用视频的高质量重建。然后,我们学习时空表示上的扩散Transformer,并根据轨迹提示生成4D占用率。我们对广泛使用的具有Occ3D占用注释的nuScenes数据集进行了广泛的实验。OccSora可以生成具有真实3D布局和时间一致性的16秒视频,展示了其理解驾驶场景的空间和时间分布的能力。通过轨迹感知4D生成,OccSora有可能成为自动驾驶决策的世界模拟器。
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
中科院自动化研究所&GigaAI团队的工作:世界模型在自动驾驶方面表现出了优势,特别是在生成多视图驾驶视频方面。然而,在生成定制的驾驶视频方面仍然存在重大挑战。在本文中,我们提出了DriveDreamer-2,它基于DriveDreamer的框架,并结合了一个大型语言模型(LLM)来生成用户定义的驾驶视频。具体来说,最初结合了LLM接口,将用户的查询转换为代理轨迹。随后,根据轨迹生成符合交通规则的HDMap。最终,我们提出了统一多视图模型来增强生成的驾驶视频中的时间和空间连贯性。DriveDreamer-2是世界上第一款生成定制驾驶视频的车型,它可以以用户友好的方式生成不常见的驾驶视频(例如,突然切入的车辆)。此外,实验结果表明,生成的视频增强了驾驶感知方法(如3D检测和跟踪)的训练。此外,DriveDreamer-2的视频生成质量超越了其他最先进的方法,显示FID和FVD得分分别为11.2和55.7,相对提高了30%和50%。
WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
GigaAI和清华团队的工作:世界模型在理解和预测世界动态方面发挥着至关重要的作用,这对视频生成至关重要。然而,现有的世界模型仅限于游戏或驾驶等特定场景,限制了它们捕捉一般世界动态环境复杂性的能力。因此,我们介绍WorldDreamer,这是一个开创性的世界模型,旨在培养对一般世界物理和运动的全面理解,从而显著增强视频生成的能力。WorldDreamer从大型语言模型的成功中汲取灵感,将世界建模定义为无监督的视觉序列建模挑战。这是通过将视觉输入映射到离散的令牌并预测掩码来实现的。在此过程中,我们结合了多模式提示,以促进世界模型内的交互。我们的实验表明,WorldDreamer在生成不同场景的视频方面表现出色,包括自然场景和驾驶环境。WorldDreamer展示了在执行文本到视频转换、图像到视频合成和视频编辑等任务方面的多功能性。这些结果突显了WorldDreamer在捕捉不同一般世界环境中的动态元素方面的有效性。
Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2)
上交的工作:现实世界中的自动驾驶(AD),尤其是城市驾驶,涉及许多弯道情况。最近发布的AD模拟器CARLA v2在驾驶场景中增加了39个常见事件,与CARLA v1相比提供了更逼真的测试平台。它给社区带来了新的挑战,到目前为止,还没有文献报道V2中的新场景取得了任何成功,因为现有的工作大多必须依赖于特定的规划规则,但它们无法涵盖CARLA V2中更复杂的案例。在这项工作中,我们主动直接训练一个规划者,希望灵活有效地处理极端情况,我们认为这也是AD的未来。据我们所知,我们开发了第一个基于模型的RL方法,名为Think2Drive for AD,使用世界模型来学习环境的转变,然后它充当神经模拟器来训练规划者。由于低维状态空间和世界模型中张量的并行计算,这种范式显著提高了训练效率。因此,Think2Drive能够在单个A6000 GPU上训练3天内以专家级熟练程度运行CARLA v2,据我们所知,到目前为止,CARLA v2上还没有成功的报告(100%的路线完成)。我们还提出了CornerCase Repository,这是一个支持按场景评估驾驶模型的基准。此外,我们提出了一种新的平衡指标,通过路线完成情况、违规次数和场景密度来评估性能,以便驾驶分数可以提供更多关于实际驾驶性能的信息。
OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving
清华团队的工作:了解3D场景如何演变对于自动驾驶决策至关重要。大多数现有方法通过预测对象框的运动来实现这一点,这无法捕获更细粒度的场景信息。本文探索了一种在3D占用空间中学习世界模型OccWorld的新框架,以同时预测自车的运动和周围场景的演变。我们建议基于3D占用而不是3D边界框和分割图来学习世界模型,原因有三:1)表现力:3D占用可以描述场景的更细粒度的3D结构;2)效率:获得3D占用率更经济(例如,从稀疏的LiDAR点)。3)多功能性:3D占用可以适应视觉和激光雷达。为了便于对世界演化进行建模,我们学习了一种基于重建的3D占用场景标记器,以获得离散的场景标记来描述周围的场景。然后,我们采用类似GPT的时空生成Transformer来生成后续场景和自车令牌,以解码未来的占用和自车轨迹。在广泛使用的nuScenes基准上进行的广泛实验证明了OccWorld有效模拟驾驶场景演变的能力。OccWorld还可以在不使用实例和地图监督的情况下生成具有竞争力的规划结果。
从这些工作中我们可以总结出以下几点:
- 基于世界模型的端到端方法还在持续发展,未来能否落地还需观望;
- Occ任务可以无缝地同世界模型相结合,引入VLM和3D GS也是未来可以进一步扩展研究的方向;
- 世界模型的核心是生成。基于生成的框架,可以添加很多模块,以进一步增强可是解释性和提升性能。
- 当下世界模型对运动规律、物理规则的建模能力还有限。
....
#完整的自动驾驶仿真工具链
为了要保证安全性,自动驾驶算法在真正大规模应用之前,就需要经历大量的道路测试。但自动驾驶系统的测试非常"贵":时间和资金成本巨大,所以人们就希望将尽量多的测试搬到计算机系统中去做,用仿真暴露自动驾驶系统中的大部分问题,减少实地路测的需求,因此,我们的饭碗就出现了。
目前自动驾驶行业常用的仿真工具有哪些**?**
在自动驾驶技术的开发与验证过程中,仿真平台已经成为一个至关重要的工具。基于仿真平台,开发者可以快速构建复杂的交通场景,涵盖多种道路条件、天气状况、以及车辆和行人的动态交互。这不仅能够加速算法迭代,同时也能在没有风险的前提下,测试极端情况下的车辆行为。
目前,行业内有多个广受使用的自动驾驶仿真平台,各自具备独特的功能与优势。例如,SUMO专注于交通仿真,能够模拟大规模城市中的交通动态,非常适合研究车流、交通管理系统和道路网络的优化;PreScan是一款侧重于传感器建模的仿真工具,常用于自动驾驶车辆的传感器在环测试,其对雷达、激光雷达、毫米波雷达、摄像头等传感器建模有较强的表现;而工业级的VTD作为最早支持ASAM OpenX系列标准之一的仿真平台,早就成为了众多主机厂的主流方案。它提供高保真车辆动力学仿真,非常适合进行精确的车辆控制与动态测试。
除此之外,Apollo是由百度开发的自动驾驶仿真平台,与百度Apollo自动驾驶栈紧密结合,能够实现全栈自动驾驶功能的测试与验证,非常适合大型企业使用。但在众多仿真平台中,CARLA作为为数不多的开源平台,以其灵活性和强大的功能在研究界和工业界都获得了广泛的应用和认可。
为什么用Carla进行仿真?
Carla是一个开源的自动驾驶仿真平台,与其他开源平台相比,它的优势在于支持高精度的地图和多种传感器模拟,如相机、激光雷达和雷达。此外,Carla 还提供了通过Python API进行编程控制的功能,使用起来更加便捷,学习曲线较为平缓,因此在科研界得到了广泛应用这也使得工业界在将最新的研究成果转化为实际应用时更加高效。whaoの开发板商城物联网测试设备~
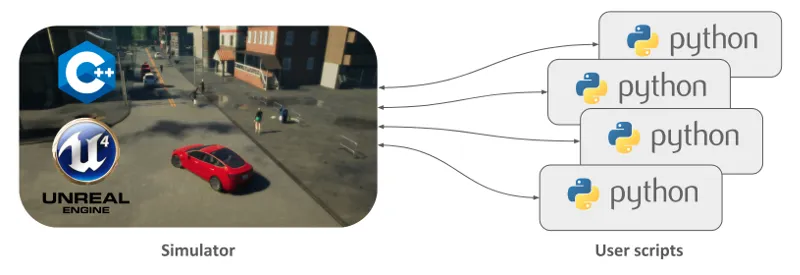
通过高精度传感器模拟和逼真的虚拟场景,它支持感知模块、路径规划、行为决策、强化学习等的开发和测试。无论是仿真极端环境还是大规模并行测试,CARLA 都能帮助研究人员在没有真实世界风险的前提下,快速迭代和优化自动驾驶算法。这是推动自动驾驶技术前进的核心工具。

入门难,门槛高?
在各种自动驾驶社区和技术讨论群中,关于CARLA的问题经常被提起。这反映出,尽管仿真是自动驾驶开发中的关键环节,然而,由于其涉及的知识面广泛、内容复杂,许多开发者,尤其是初学者,常常感到无从下手。除了需要理解各类仿真工具的使用,还要掌握传感器模拟、UE渲染引擎、高精地图应用等多领域的知识。
.....
#Gen-Drive
英伟达&斯坦福打破陈规!生成-评估的全新规划范式,直接SOTA!
在复杂环境中导航需要自动驾驶代理能够熟练地预测未来场景(比如其他代理的行为),同时做出明智的决策。一般而言,传统的预测性和确定性规划方法通常将预测和规划过程分开,从而将自车与社会环境信息隔离开来,并常常导致不符合社会驾驶规范的行为。尽管目前工业界和学术界已经提出了集成预测和规划框架的算法模型来解决这一问题,但这类算法仍然依赖于确定性规划,这对解决代理行为的不确定性、多模态性和相互作用的动态性提出了挑战。
为了克服上述提到的这些挑战,我们建议在规划任务中采用生成-评估的方法。这个方法的关键是将自车代理集成到社会互动环境中,为整个场景中的所有代理生成一系列可能的结果,并使用学习场景评估器来指导决策过程。同时,我们考虑到生成模型在自动驾驶的仿真和预测任务中得到了广泛的应用,但它们在决策任务中的应用相对有限。我们认为是两个主要限制阻碍了生成模型在规划任务中的应用。
评估生成的场景并选择符合人类期望和价值观的最佳决策场景非常复杂。为了解决这个问题,我们引入了一个场景评估(奖励)模型,该模型基于从 VLM 反馈中得出的偏好数据进行训练,从而实现更好的决策;
与受益于样本多样性的仿真或者场景生成任务不同,使用生成模型进行规划需要用更少的样本生成更可能的未来场景,以最大限度地减少计算开销和运行时延迟。我们通过引入强化学习 (RL) 微调框架来解决这个问题,该框架基于获得的奖励模型来提高扩散生成的质量;
考虑到上述提到的主要限制阻碍以及相应的解决措施,我们提出了Gen-Drive算法模型,一种扩散生成驱动策略以及相应的训练框架。我们设计的基础模型使用 nuPlan数据集进行训练,并在nuPlan闭环规划基准上进行评估。结果表明,我们的扩散驱动策略取得了良好的性能。
完整的Gen-Drive算法框架以及训练过程如下图所示。
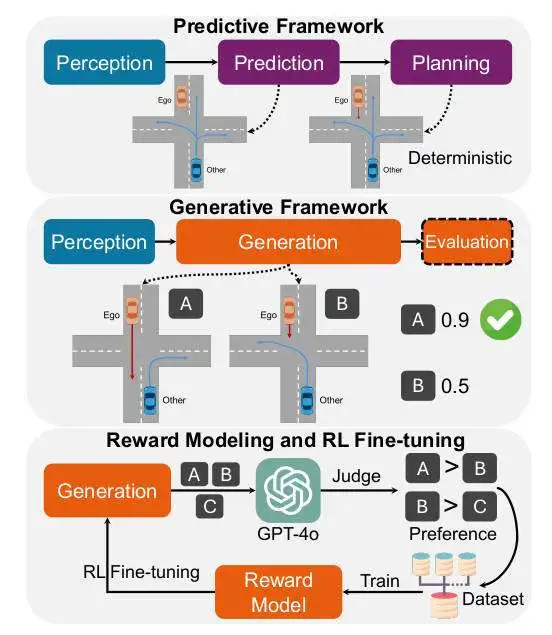
Gen-Drive算法模型整体训练框架图
网络模型的整体架构&细节梳理
在详细介绍我们提出的Gen-Drive算法模型细节之前,下图展示了我们提出的Gen-Drive算法模型的整体架构。
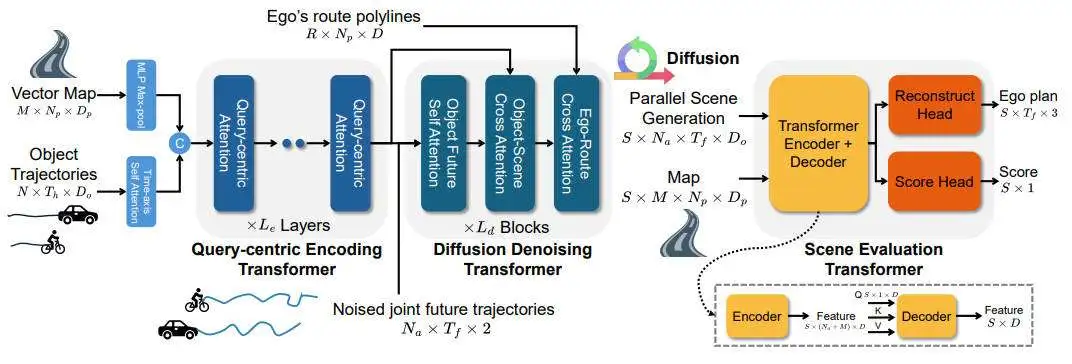
提出的Gen-Drive框架的整体结构图
通过上图可以看出,整体而言,我们采用生成(扩散)模型来取代传统范式中的预测规划模型。二者之间的关键的区别在于,自车代理并不是孤立于场景之外的;相反,它被视为场景中不可或缺的一部分,所有代理的行为都相互依赖。为了利用该生成模型进行规划,我们设计了一个场景评估(奖励)模型。该模型使用精选的成对人类偏好数据集进行训练,使其能够直接对生成的场景(规划)进行评分,并促进选择最佳且符合上下文的决策。此外,我们利用奖励模型来微调扩散生成过程,使其朝着生成高回报计划的方向发展。RL微调步骤可以增强整体规划性能并减少大量采样的需要。
场景生成器
对于当前时间戳的初始驾驶场景,我们考虑N个目标(包括自车)和M个地图元素,追踪这些目标在个时间步内的历史轨迹。当前的场景输入到编码器中的包括目标的轨迹以及地图线。其中,是路径点的个数,和是每个点的特征维度。
- 编码器部分:当前场景输入最初通过时间轴自注意力Transformer层对目标轨的迹进行编码,得到,然后通过多层感知机对地图数据进行最大池化,得到。他们被拼接起来形成初始的编码。我们采用以查询为中心的Transformer编码器来融合场景元素的特征并生成全面的场景条件编码。
- 去噪器部分:扩散过程在所有感兴趣目标的联合动作空间中进行,动作由加速度和偏航角比率组成。噪声直接添加到动作序列中。给定噪声输入,其中是噪声等级,是未来时间戳,此外场景条件为,我们采用具有自注意力和交叉注意力层的去噪Transformer来预测去噪后的动作序列。对于自车代理,额外的路线信息被提供,并采用了额外的交叉注意层来模拟自车的路线关系。
- 生成:未来场景(联合目标动作)是从随机高斯噪声开始生成的,随后,每个扩散步骤k涉及从下面指定的过程进行采样。其中,以及是根据预先确定的噪声得到的。通过迭代地反转扩散步骤,我们获得最终的去噪联合动作输出。随后,通过使用动态模型将目标动作转换为状态。该状态包括目标的坐标、朝向和速度。
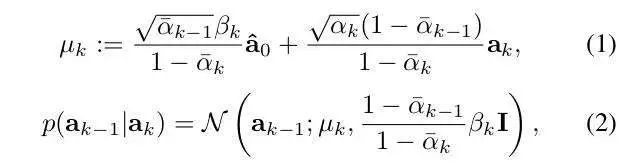
场景评估器
场景评估器将扩散生成器生成的个未来场景作为输入,这些场景可以通过从一批高斯噪声开始并行生成。这些生成的场景结构化为,评估器的另外一个输入是矢量地图。这些未来场景使用以查询为中心的Transformer编码器进行编码,类似于历史场景的编码,从而产生场景特征表示。随后,我们利用从场景编码中提取的自车代理的未来或规划编码,以及将场景编码作为Transformer解码器中的键和值,得出未来场景中以规划为中心的特征。需要注意的是,Transformer解码器分别关注每个场景中的个元素。两个多层感知机头模块附加到这个特征张量用于分别重建自车代理的规划轨迹并输出不同生成场景的分数。自车规划重建的头模块作为辅助任务来增强稳定性和有效性。
基于扩散模型的训练
基础的扩散模型经过训练,可以在各种噪声水平和场景条件下从带噪声的轨迹输入中恢复干净的轨迹。在每个训练步骤中,我们都会从噪声级别和高斯噪声中进行采样来扰乱原始的动作轨迹。由于该模型预测场景级的轨迹,因此所有目标轨迹都受到相同噪声水平的影响。基础扩散模型的训练损失函数可以表示为:
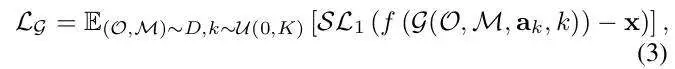
其中,代表数据集,代表Smooth L1损失函数,是动态模型,是目标的未来真值状态。
训练奖励模型
- 成对偏好数据收集:为了构建一个有效的奖励模型,整理全面的数据集是非常有必要的。一种方法是利用人为设计的指标,例如PDM分数。但是,依赖此类指标存在很大的局限性,因为它们可能无法准确反映不同场景中的实际人类价值观。此外,即使对于人类评估者来说,准确地用奖励值标记场景也是一项挑战。或者,我们可以让人类标注员进行成对的比较,确定哪些场景更符合人类偏好。然而,整理大规模奖励数据集会给人类标注员带来巨大的工作量。为了解决这个问题,我们使用VLM来提高流程的效率和可扩展性。VLM辅助奖励标记流程如下图所示。为了增加规划轨迹的多样性,我们首先利用K-means聚类算法从数据中提取32个5秒锚定目标,并采用引导扩散策略为自车代理生成32条不同的规划轨迹,以及模型对场景中其他物体的反应行为。随后,我们对这些场景进行成对采样。我们首先计算规划轨迹之间的差异,然后检查碰撞和过滤掉明显的失败情况。如果这些措施不足以区分,我们将使用GPT-4o提供结论性评估。如下图所示,GPT-4o根据当前场景上下文对两个生成的场景进行了合理的评估。

使用VLM收集规划偏好数据的整体流程
- 训练过程:在每个训练步骤中,我们从相同的初始条件中采样一批成对比较结果,即接受的场景和拒绝的场景。训练场景评估模型的损失函数如下,其中,是成对偏好奖励数据集,表示预测生成场景得分的奖励模型。
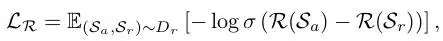
下图显示了一些奖励模型输出的示例,结果表明,我们训练的奖励模型为生成的计划和场景产生了合理的分数。
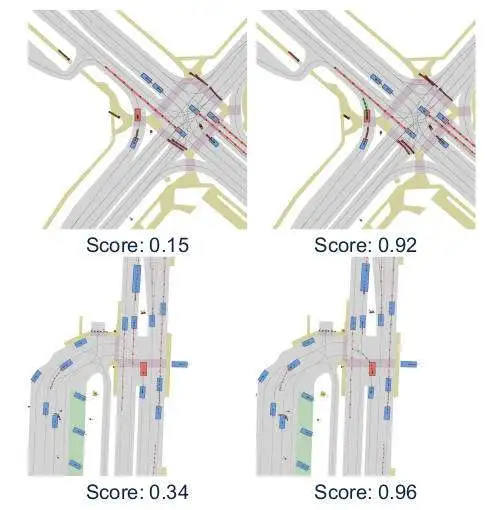
场景评估输出的示例
微调生成模型
为了提高扩散生成在规划任务中的效率,我们建议使用训练好的奖励模型和RL对扩散模型进行微调。我们可以将扩散去噪过程公式化为多步骤的MDP,其中去噪器函数作为以每一步的噪声输入为条件的策略。轨迹包含K个时间戳,在扩散过程结束时发出奖励信号。RL目标是最大化沿轨迹的累积奖励,我们可以利用去噪扩散策略优化来改进生成策略。微调损失公式如下,其中,是所有目标的去噪状态轨迹,是真实轨迹。
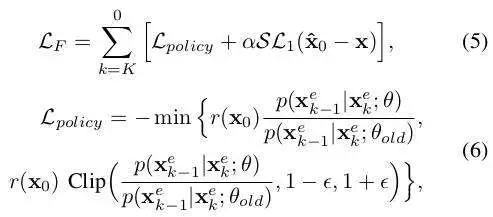
需要注意的是,微调损失会在整个扩散轨迹上累积,并且只有去噪器是可学习的,而编码器在微调期间是固定的。下图展示了使用DDPO的RL微调算法流程。

实验结果&评价指标整体实验结果分析
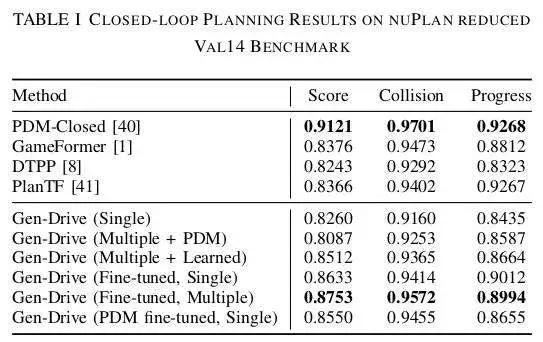
为了验证我们提出的算法模型的有效性,我们实施了不同模型的闭环规划实验,结果如下表所示。
此外,为了更加直观的展示生成过程中的一些典型场景,微调后的策略表现出更好的规划性能,我们也进行了相关的可视化。
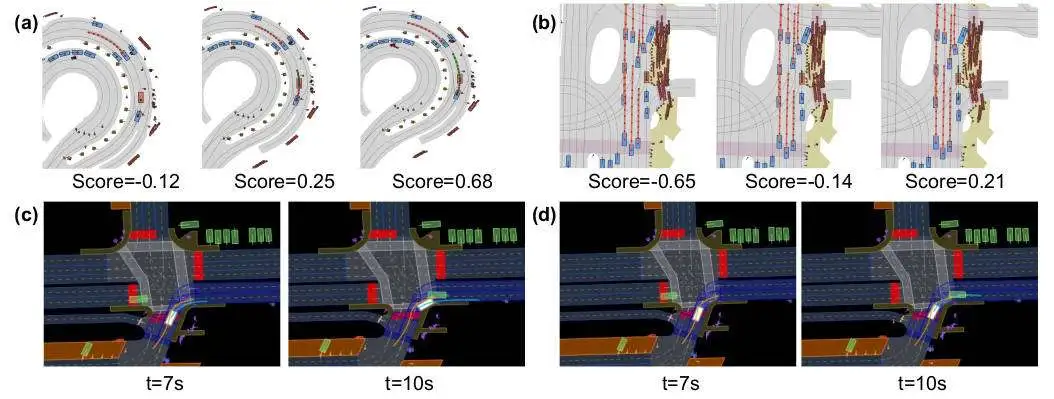
规划过程示意图
通过相应的实验和可视化结果可以看出,生成和评估优于单样本推理。多样本规划方法通过批处理并行生成 16 个场景,并使用学习到的奖励模型选择最佳场景。该方法增强了生成计划的多样性,从而提高了整体规划得分。此外,具有我们学习到的奖励模型的生成规划器在规划方面优于基于 PDM 分数的评估器。此外,微调可提高性能。规划效率仍然在很大程度上取决于生成质量,我们证明 RL 微调可以显著提高质量和性能。值得注意的是,即使使用单样本方法,微调策略的整体规划得分也优于没有微调的多样本方法。此外,使用我们学习到的奖励模型进行微调比使用基于 PDM 的评分器效果更好。我们也注意到,与基于学习的预测规划器相比,我们的模型通过使用先生成后评估的方法表现出卓越的性能。然而,使用基于规则的轨迹生成器和评分器的PDM-Closed规划器获得了最高分。值得注意的是,它针对 nuPlan 指标进行了优化,这可能缺乏人类相似性和对现实世界场景的适应性。
消融实验结果分析
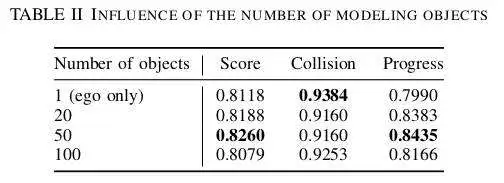
首先,我们先分析了建模目标数量的影响。数量范围从 1到 100,相关的实验结果下表所示。我们在模型训练中调整建模目标的数量,并在测试中使用单样本生成。结果表明,仅生成自车的规划会导致性能较差,主要是因为在某些情况下缺乏运动。相反,过多的建模目标(例如 100)也会导致性能和运行效率下降。因此,在保持运行效率的同时,对 50 个自车和周围对象进行建模表现最佳。
此外,我们也对RL微调阶段训练步骤对结果的影响进行了实验,并在测试中采用了多样本生成和评分方法,相关实验结果如下表所示。结果表明,1000 个微调步骤可实现最佳规划指标,超过此指标,微调策略的性能就会下降。这是 RLHF 框架中的一个常见问题,因为策略可能会利用奖励函数并产生不合理的行为。因此,我们将 RL 微调阶段限制为 1000 个步骤,以防止性能下降。
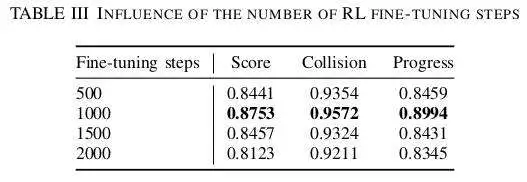
结论
在本文中,我们提出了Gen-Drive算法框架,标志着自动驾驶的决策向生成-评估的方式进行转变。实验结果表明,与其他基于学习的规划方法相比,我们的模型通过适当的奖励建模表现出更优异的性能,并且通过 RL 微调得到了进一步的增强。
....
#xxx
.....
#深入分析NeRF及3DGS的原理
一场对3D Gaussian Splatting的祛魅
(本文是作者在公司内部分享的整理,力求简明扼要的向大家介绍清楚 Nerf 技术的发展脉络,以及个人对于 3D Gaussian Splatting 技术的看法,其中原理推导的部分设计较多的数学原理,如果感到枯燥可以直接跳过看结论,对于 Nerf 感兴趣的同学,欢迎积极留言,大家一起学习讨论~)
NeRF 介绍
NeRF 是什么
传统计算机图形学
在传统的计算机图形学技术中,我们通过将场景数据,通过渲染算法,生成在特定视角下的渲染画面。
场景数据包括:
- 几何数据(点云、三角网格、体素等)
- 纹理数据(PBR、Normal、AO等)
- 光照数据(光源类型、阴影、全局光照等)
渲染算法包括:
- 光栅化方法
- 光线投射方法
为了达成更加逼真的画面,需要人工参与创建、估算各种场景参数,带来大量的人工成本(美术、引擎、图程)。
NeRF Rendering
NeRF,全称是 Neural Radiance Fields (神经辐射场)技术,滥觞于 2019 年发表的《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》这篇论文,文中通过结合机器学习的方法,使用可微分的渲染损失,来从观测中重建这样的场景数据。
相比于传统的计算机图形学技术,从人工建模与调参,得到场景数据,最后渲染出逼真的画面, Nerf 技术可以直接从参考图像中,运用机器学习的方法,自动得到场景数据,而无需人工手动参与,从而大大降低了场景建模的成本。
NeRF 的原理
NeRF 中三大关键的技术点:
- 5D 的隐式场景表示函数;
- 位置编码;
- 分层体渲染;
三维场景的显示表达与隐式表达
在传统的计算机图形学技术中,用来表示场景的数据通常可以分为以下几类:
- 点云:由一维的点组成,本身没有封闭的面,所以没有办法表达拓扑结构;
- 三角网格:由二维的平面组成,可以描述绝大部分的拓扑结构,游戏中最常用的方式;
- 体素:体素描述的是三维体积中的数据,可以描述各种拓扑结构
这些场景数据都是显示表达的数据,可以直接读取出场景中某个位置的属性,也因此,这些数据是对连续的真实场景的离散化的采样。
另一种表达场景的方式,是通过高维函数直接对场景建模,需要获取场景中某个位置的属性的时候,传入位置信息作为参数,计算出该点的属性,这种方式并不直接保存数据,我们一般把这种方式成为场景数据的隐式表达。
比如,我们可以通过下面的方程求得场景中任意一点,到原点的距离:
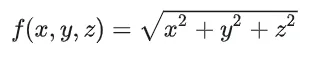
这就是一种隐式的场景表达方式,在 NeRF 技术中,我们也采用类似的方式,用来表达场景
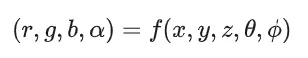
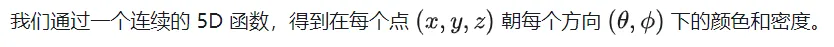
这里需要说明一下,为什么要使用 5D 的参数:
- 对于颜色数据来说,尤其是高光反射的部分,虽然在场景中的位置相同,但是从不同的角度观察时,会得到不同的结果,所以本身除了和位置相关,也和观察角度相关;
- 对于密度数据来说,其表示的是观察的视线能够通过该点的概率,所以只和位置相关。
神经网络结构
当我们把整个场景表示成一个连续的 5D 函数之后,就可以通过 MLP 全连接层来对这个函数建模,首先对位置进行位置编码,再通过 8 层 256 维的全链接 ReLU 层,输出体素密度
和 256 维的特征向量,然后把特征向量和经过位置编码后的方向参数串联,最后经过一个 128 维的全连接层,得到与位置和方向都相关的一个颜色预测。
当我们把场景函数通过神经网络表示之后,就可以用梯度下降的方式来进行优化,通过不断的最小化每个观察图像和对应视图之间的误差,最终得到我们需要的场景函数,具体步骤如下:
- 从相机的位置出发,沿着相机的视线,一步步采样 5D 坐标(位置和角度)下场景的属性;
- 将 5D 坐标输入 MLP 全连接神经网络,得到该位置的颜色和密度;
- 利用体渲染技术,将得到的颜色和密度,合成为 2D 的图像;
- 通过最小化合成的图像与参考图像之间的差值,来优化我们的 MLP 全连接神经网络;
- 不断重复上面的过程,最终得到一个足够优化的场景表示函数;
体渲染技术
体渲染技术在计算机图形学中由来已久,对大气散射、体积雾等没有清晰边界的物体,体渲染技术能够很好的表现其体积感与层次感,由于 NeRF 中采用的表示场景的方法,是一个连续的隐函数,故而可以认为其本身充满了整个空间,所以可以采用体渲染的方式,来得到图像。
计算机算机图形学中的体渲染,模拟了光在空间中的散射、吸收等现象,NeRF 中对此进行了简化,使用了(t)表示碰撞概率,即视线通过此处的概率。下面会详细说明下(t):
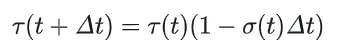
改写上述公式可以得到:
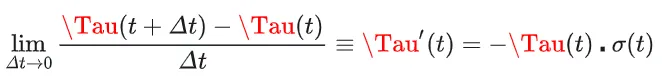
求解该微分方程
我们得到了两点之间碰撞概率之比。
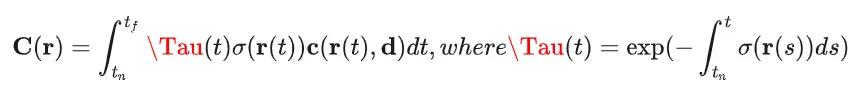
得到了上述连续形式的积分方程之后,我们还需要进一步对其进行离散化。

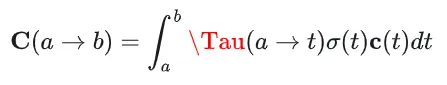

把整个射线上的N段进行累加:

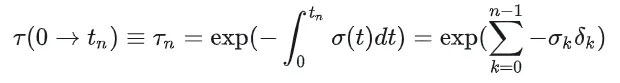
结合上面的公式,可以得到最终的离散化的形式:
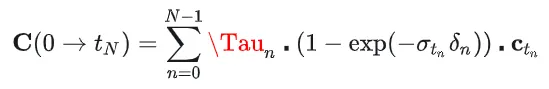
得到了如何计算一条视线所得到的颜色,就可以从相机位置发出多条视线,组成画面,NeRF 的算法里面是通过 1024 条射线,来得到一幅完整的画面
重建三维场景
有了表示场景的神经网络,和能够得到图像的体渲染技术后,我们就可以开始训练神经网络,具体步骤如下:
- 数据准备:准备一组包含二维图片和相应相机参数的训练数据。每张图片是从不同角度捕获的场景快照。每个训练样本由一张图片和对应的相机参数组成;
- 视线的生成:对于每张图片,根据相机参数生成视线,这些视线起始于相机位置,穿过图像平面上的每个像素,并延伸到场景中;
- 输出颜色:对于每条视线,将视线的起始点传入体积函数(通常是一个多层感知器)。体积函数沿着视线逐点采样神经网络,得到该点的颜色和密度值,带入体渲染公式,得到最终的颜色;
- 损失计算:将体积函数输出的颜色与实际图像中对应像素的颜色进行比较,计算损失,损失衡量了预测图像与真实图像之间的差异;
- 反向传播和优化:使用反向传播算法,将损失反向传播到神经网络中,计算梯度并进行权重更新,这个过程采用优化算法(如随机梯度下降)来逐步调整神经网络的权重,以最小化损失函数;
- 迭代训练:重复以上步骤,逐渐迭代训练神经网络。每次迭代都会使用不同的训练样本,以便网络能够从各个角度和视角学习场景的三维表示;
- 收敛与模型保存:训练过程会持续一段时间,直到模型达到一定的收敛程度,即损失足够小,在训练完成后,可以保存训练好的体积函数模型,之后就可以直接利用该体积函数新的视角下的输出。
总的来说,场景重建就是通过在多个视角下的输入图像和相机参数,让神经网络学习到一个能够将三维空间点映射到颜色和密度值的隐式函数。这个过程实际上是在从输入图像中学习场景的三维结构和属性,并将其表示为神经网络的权重,这使得网络在渲染阶段能够根据相机参数和光线来生成场景的虚拟图像。
位置编码
解决这个问题的办法,是通过编码将输入的维度进行提升,这样低频的连续输入经过升维后,就有足够的维度去描述更高频的信息了,具体采用的方式如下:
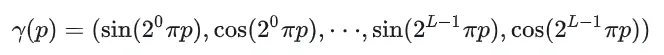
经过编码后,三维的位置信息,会变为 63 维的输入信息(3 维原来的信息,加上32 10维升维后的信息),同时,我们用三维的向量来描述视角信息,经过编码后,得到 27维的视角信息(3 维原来的信息,加上324维升维后的信息)
如图所示,可以看到完全没有位置编码的情况下,整个场景会偏向模糊,阴影细节无法很好表示;而只对位置进行编码,而对视角没有编码的情况下,则对于像高光反射这种现象,无法很好表示;在对位置和视角都进行了编码后,场景对于高频信息的表现能力大大增强。
分层采样
故 NeRF 中采用了多层级体素采样(Hierarchical volume sampling)的技术,该方案可以根据场景密度,自适应分布场景中的采样点,具体步骤如下:
- 准备神经网络:我们需要准备两个神经网络,分别称为粗网络(coarse net)和精网络(fine net);
- 训练粗网络:在训练粗网络时,我们采用均匀采样,加随机偏移的方式,如下图所示:

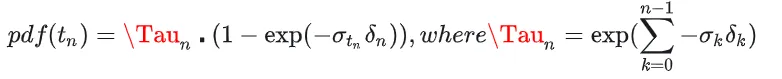
通过处的pdf,我们可以积分得到cdf,对cdf进行均匀采样,就可以反向得到应该采样的位置。
- 训练精网络:通过采样上一步得到的位置,来对精网络进行训练,最后我们保存下来,用来进行预测输出的就是精网络。
NeRF 的发展历程
在 2019 年《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》这篇论文横空出世之后,凭借其震撼的合成效果获得了 2020 年 ECCV 的最佳论文,之后沿着 NeRF 打开的大门,人们开始不懈的探索,到 2023 年为止这篇论文已经被引用了 3000+ 次。
但是 NeRF 本身也存在很多问题,其中最大的两个问题就是:训练慢 和 渲染慢,NeRF 对于单一物体的训练时间平均达到了一到两天,渲染更是连 1 FPS 都达不到,完全无法实时交互,这两个问题极大的限制了 NeRF 的应用场景。
我们可以看下 NeRF 为什么会存在训练慢和渲染慢的问题:训练慢:NeRF 中采用的 MLP 网络是从零开始进行训练,需要在训练中一点点学习到场景的空间结构;渲染慢:体渲染技术中,会对空白区域进行采样,浪费了大量的算力;
有问题,就会有解决问题的探索,下面就介绍几种尝试解决以上两个问题的方案:
Mip-NeRF(视锥追踪)
《Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields》中提出了一种方法,在体渲染的采样中,不再发射一条射线,而是换成了发射一条圆锥,然后把圆锥进行分段,每段通过 3D Gaussian 函数进行建模,采样的时候输入的不再是位置和视角,而是高斯的均值、方差和视角。
采用这种方法,可以减少采样光线的数量,从而提高了渲染速度,同时能降低训练图片与渲染画面分辨率不一致时的锯齿和模糊感。
PlenOctrees(MLP 转 八叉树)
《PlenOctrees for Real-time Rendering of Neural Radiance Fields》中提出了一种方法,先根据场景,预训练一个 NeRF 的神经网路,然后稠密采样这个 NeRF 网络,用八叉树来存储采样的结果,再对八叉树存储的结果进行优化,最终保存八叉树用来渲染。
DVGO(显式表达+隐式表达)
《Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction》中提出了一种新的思路,既然我们可以用八叉树来加速渲染,那我们可不可以用类似的方式来加速训练呢?这篇文章就是从这个角度,进行的探索。
在这篇文章提出的方法中,不仅用到了 MLP 神经网络来存储颜色,还用到了体素网格来表达整个场景,每个体素里会存储密度和颜色特征值,然后用三线性插值的方式,保证了这些值是连续平滑变化的,从而可以进行可微渲染,反向传播优化。为了用低密度网格表示高频信息,在密度值插值之后,会加上一个非线性的激活函数。而颜色特征值会和位置与视角一起作为输入,传入到 MLP 神经网络中,获取到颜色值。在训练中会不断对体素网格进行优化,这样就可以利用体素网格,来快速跳过大部分空白的区域,从而提高训练和渲染的速度。
Point-NeRF(显式表达+隐式表达)
《Point-NeRF: Point-based Neural Radiance Fields》中提出了另一个思路,上文中的体素毕竟是均匀分布,还是会有空洞,那是不是可以有更加适应场景密度的形式?
答案是肯定的,我们可以使用 deep MVS 或者 COLMAP 等方法,对参考图片进行处理,从而得到用来表示整个场景的点云分布,然后在体渲染采样时,通过采样周围点,插值融合点上的特征,再传入 MLP 神经网络中,得到颜色与密度。
这种方法可以在一开始就通过预训练的方法,得到场景的点云表示,场景中的空洞部分直接就可以得到,不需要像上一篇文章中,需要不断训练得到。
Plenoxels(显式表达)
《Plenoxels:Radiance Fileds without Neural Network》中完全放弃了 MLP 神经网络,仅使用体素网格来表达整个场景,渲染时采用和 NeRF 同样的体渲染技术,通过三线性插值,得到采样点的密度和球谐函数的参数,之后通过反向传播进行优化。
采用这种方式,整体的训练时间缩短了百倍以上,达到 NeRF 同样的效果只需要平均 15 分钟的训练时间,而 NeRF 的训练时间通常需要一到两天。这证明了一件事情,在场景重建的技术中,MLP 神经网络并不是必要的,可微渲染与反向传播才是关键。这为后续的研究指明了一条道路,我们可以引入了更多 CG 领域的方法,来对场景进行表示,或许会得到更好的结果。
3D Gaussian Splatting 介绍
困扰 NeRF 的两个问题:训练慢和渲染慢,3D Gaussian Splatting 都基本解决了,因此 NeRF 技术大规模应用到商业实践中的进程,被大大的推进了一步。而这种进步,并不是凭空发生的,是建立在之前各种实践探索上的,尤其是沿袭了 Plenoxels 的思路,完全抛弃了 MLP 神经网络,在此之上又抛弃了光线追踪的体渲染方法,利用了基于光栅化的 3D Gaussian Splatting 的渲染方式。
下面详细分析下 3D Gaussian Splatting 方法中是如何解决训练慢和渲染慢的问题的:
- 采用点云结合 3D Gaussian 的方式,作为显式的场景表达:从 Plenoxels 我们可以得知,MLP 隐式表达并不是 NeRF 的关键,可微渲染才是关键,所以采用 3D Gaussian 来表示点云中的每个点的性质,就是利用了 3D Gaussian 函数可微的性质,同时,使用点云表达空间结构,避免了对于空场景的训练,大大提高了训练速度;
- 使用的 3D Gaussian Splatting 的渲染方式是一种基于光栅化的方式,避免了体渲染中光线追踪的方式:利用了 3D Gaussian 函数的轴向积分等同于 2D Gaussian 函数的性质,可以直接用 2D Gaussian 函数替换掉体渲染中沿着视线积分的过程,从数学层面摆脱了采样量的限制,并且可以直接使用光栅化管线进行渲染,在保证渲染效果的同时,把渲染速度提升到了 1080 分辨率下 60 FPS 的程度,已经达到了 Real-Time 的程度;
3D Gaussian Splatting 的原理
下图是 3D Gaussian Splatting 技术合成后的画面:
下图是 3D Gaussian Splatting 技术中,将每个 3D Gaussian 透明度设置为 1 后的画面,可以看到画面是由半透明的小椭圆叠加而成:
3D Gaussian Splatting 的点云中的每个点,都采用以下参数,显式描述场景:
3D Gaussian Splatting 整体的流程如上图:
- 使用运动结构恢复(SfM:Structure from Motion)方法从一组图像中估计点云的位置和颜色,作为初始化的参数(SfM 是一种从一组 2D 图像估计 3D 点云的方法,可以通过 COLMAP 库来完成);
- 点云中的每个点会表达成 3D Gaussian 的形式,之后通过投影与可微光栅化后,得到合成的图像;
- 和参考图像对比计算损失函数,进行反向传播,调整 3D Gaussian 的参数;
- 在此过程中,会进行自适应的密度调整:
- 如果对于给定的高斯梯度很大,则分割或者克隆一个新的高斯;
- 如果高斯很小,则克隆一个新的高斯;
- 如果高斯很大,则将其分割;
- 如果高斯的 alpha 太低,则将其删除;
3D Gaussian Splatting 的关键技术
3D高斯函数沿某一轴进行积分后等同于2D高斯函数,这是由于高斯函数的一些性质决定的。
首先,高斯函数是可以分离的,即多维高斯函数可以表示为各个维度上的一维高斯函数的乘积。这意味着,多维高斯函数沿某一维度进行积分,就相当于将这一维度的一维高斯函数积分到1,剩下的就是其他维度的高斯函数,即一个低一维的高斯函数。
其次,高斯函数的边缘分布也是高斯的。多维高斯函数的边缘分布就是将某一维度积掉,得到的结果仍然是高斯的。这再次证明了3D高斯函数沿某一轴进行积分后等同于2D高斯函数。
这个性质在图形学中有很重要的应用,例如在3D Gaussian Splatting中,将3D高斯投影到投影平面后得到的2D图形称为Splat,然后通过计算待求解像素和椭圆中心的距离,可以得到不透明度。由于3D高斯的轴向积分等同于2D高斯,可以用2D高斯直接替换积分过程,从数学层面摆脱了采样量的限制,计算量由高斯数量决定,而高斯又可以使用光栅化管线快速并行渲染。
如今的 CG 界,三角图元已经一统江湖啊,而在 CG 刚刚起步的年代,其实人尝试了多种表达场景的方式,比如 1994 年发售的魔城迷踪 ecstatica,就是以椭球为基础元素的游戏。
为什么选择 3D Gaussian 这种表达方式?主要优点有两个:
- 3D Gaussian 是连续可微的;
- 3D Gaussian 可以用光栅化渲染;
单个的 3D Gaussian 可以作为小型可微空间进行优化,不同的 3D Gaussian 则能够像三角形一样并行光栅化渲染,从而在可微和离散之间做了一个微妙平衡。
3D Gaussian 的数学表达

- 均值为 0;
- 方差为 1;
- 概率密度的积分为 1;
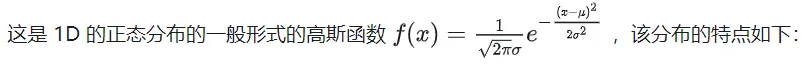
根据联合概率密度公式
把转化为二次型的形式
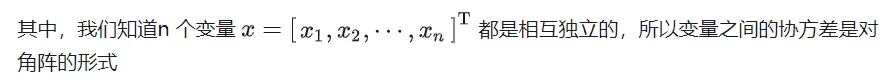
根据对角阵的性质可知,其逆矩阵是
由于对角阵的行列式等于对角上元素的乘积,所以我们可以得到
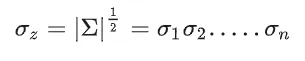
综合上述公式可得
由此,我们得到了独立多元高斯函数的公式。
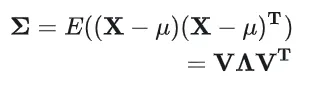

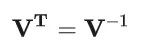
结合上述两个公式可得

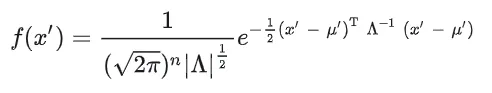

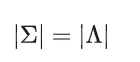
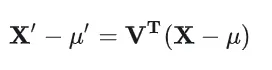
综合上述公式可得
由此,我们得到了相关多元高斯函数的公式。
3D Gaussian 的参数构成
回顾《3D Gaussian Splatting 的原理》一节,我们使用 3D Gaussian 描述空间中的一个椭球,结合上述公式可知,3D Gaussian 中最重要的两个参数是期望值和协方差矩阵,那我们如何获得这两个参数呢?
结合几何意义可知,期望值就是椭球的圆心,所以可以用点云的位置P(x,y,z)来表示。


3D Gaussian 的投影
我们已经知道了如何通过 3D Gaussian 表示空间中的椭球,那么又该如何对其进行光栅化渲染出来呢?
对于传统的三角形图元,光栅化的过程如下:
- 世界空间中的点,转换到视图空间;
- 视图空间中的点,转换到裁剪空间;
- 裁剪空间中的点,转换到 NDC 空间;
- 在 NDC 空间的xy平面使用扫描线算法进行填充;
3D Gaussian 的投影过程与之类似,该过程我们称之为 Splatting。我们也需要将 3D Gaussian 代表的椭球,从世界空间转换到 NDC 空间,然后沿着z轴进行投影,再对投影在xy平面上的椭圆进行扫描线填充。
不同于三角形图元的光栅化过程,对于 3D Gaussian 的变换需要保证变换完成后,依然保持是高斯函数,这样才可以利用多元高斯函数的投影依然是高斯函数的性质,来快速得到投影后的图像。
我们知道确定一个 3D Gaussian 的参数包括期望值和协方差:
- 对于期望值,表示的是椭球的圆心,可以通过类似三角图元的变换过程得到在投影空间里的坐标;
- 对于协方差,表示的是椭球的缩放和旋转,如果直接使用三角图元的变换过程,由于投影变换不是线性的,会导致变换后不再保持高斯函数的性质;

可以看到,一阶导的泰勒展开满足线性变换的条件,同时当x在附近时,
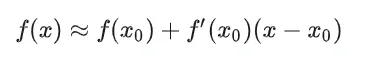
可以表示为处一阶导数的展开形式。
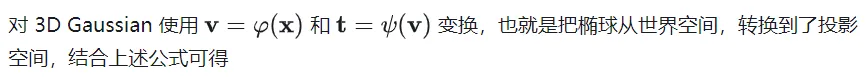
我们假设变换前的 3D Gaussian 的协方差为,对于变换后的 3D Gaussian 求协方差
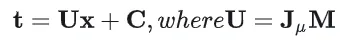
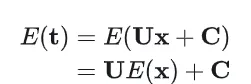
所以变换后的协方差为
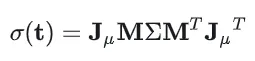

投影到平面后的 2D Gaussian 函数为
3D Gaussian 的渲染
在得到每个 3D Gaussian 投影到平面的公式后,我们可以开始着手将其渲染出来,但是投影后的 2D Gaussian 函数的函数值,并不能直接得到颜色和透明度,其值表示的是相对于中心处的颜色和透明度的百分比。其中,透明度可以直接和百分比值相乘,而颜色则需要通过球谐函数计算才能得到,这里需要简单介绍一下球谐函数,简单来说球谐函数是一组正交基函数,可以对分布在球面上的实函数进行方便的展开。之所以用球谐函数表示颜色,正是为了能够表示从不同的角度观察,得到不同颜色的现象,比如像光滑的金属表面,对于同一个位置,从不同的角度观察,就能得到不同的反射影像,而球谐函数只需要存储几个简单的参数,就能模拟出这种现象,如下图,可以看到左边的桌面随着不同的观察视角,会有明显的明暗变化:
与傅里叶级数展开类似,傅里叶级数是把任何的周期函数都表示成一组正余弦函数的和的形式,如下:
其中:
而分布在球面上的任意函数,都可以像上面展开傅里叶级数那样,通过一组球谐函数进行展开
其中是展开式中不同球谐函数的系数,其值可以通过和球谐函数进行积分得到

前三阶的球谐基函数的可视化如下
在实际操作中,我们通过球谐函数进行展开的时候,不可能展开成无穷多项,一般会选取前 3 阶或者 2 阶,这样就会把原来函数中的高频部分过滤掉,如下图可以看到,球谐展开的阶数越高,保留的高频信息就越多,还原的函数细节就越丰富

了解了如何求得颜色和透明度,我们就可以采用的是分 tile 的渲染方式来得到最终图像,具体步骤如下:
- 将屏幕划分为 16x16 大小的 tiles;
- 将每个 3D Gaussian 点投影到视平面后,根据中心点的位置,计算出该点所处的 tile 和相对视平面的深度;
- 对每个 tile 中的所有 3D Gaussian 点,根据相对视平面的深度进行排序;
- 排序完成后,每个 tile 都可以得到一个按照从近到远记录了该 tile 中所有 3D Gaussian 点的 list;
- 对应每个 tile,运行一个 16x16 的 thread block,并将 tile 对应的 list 加载进 block 的 shared memory 里;
- thread block 中的每个 thread 对应 tile 中的一个像素,从 list 中依次取出 3D Gaussian 点,根据投影后的 2D Gaussian 公式,可以计算出该像素位置处的百分比,然后通过球谐函数得到 3D Gaussian 点中心出的颜色和透明度,乘以百分比后,按照以下规则进行累加:
- 将颜色与 frame buffer 中的颜色按照 frame buffer 中的透明度混合;
- 将透明度与 frame buffer 中的透明度相加;
- 如果透明度的值大于阈值则退出计算;
- 每个像素的颜色都计算完成后,也就渲染出了整个画面。
3D Gaussian Splatting 的未来展望
Animatable 3D Gaussian
《Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars》中提出了一种可动画化的 3D Gaussian 技术,从输入图像和姿势中学习人类的形象。我们通过在正则空间中建模一组蒙皮的 3D Gaussian 模型和相应的骨架,并根据输入姿态将 3D Gaussian 模型变形到姿态空间,从而将 3D Gaussian 扩展到动态人类场景。
HUGS: Human Gaussian Splats
《HUGS: Human Gaussian Splats》中提出了一种使用 3D Gaussian 来表示可动画化的人体和场景的方法,该方法只需要一个具有少量(50-100)帧的单眼视频,就能在 30 分钟内,通过机器学习自动将静态场景和完全可动画化的人体分开,并且可以使用全新的姿势与场景进行融合。如下视频所示:
- 左上,是用来训练的视频;
- 右上,是训练出来的可动画化的人体表示;
- 左下,是训练出来的静态场景;
- 右下,是使用全新的姿势驱动人体,并且和静态场景结合,可以通过各种视角进行观察;
....
#RoadLib
开源的轻量级道路建图与定位系统!
端到端的自动驾驶系统目前已经成为行业的一个趋势。通过将感知、规划、控制等模块整合到统一的端到端网络体系下,一定程度上可以克服单一模块的信息损失,有望用数据驱动的方式解决传统算法在corner case方面遇到的挑战。
在这样的背景下,基于特定特征的轻量级道路地图依然有其应用价值。通过低成本终端或者众包的方式对地图进行构建和维护,可以在用户端作为额外的信息源,增强其高精度定位或者超视距感知的能力,从而提升系统的稳健性和高效性。
在此介绍RoadLib,一个开源的基于道路标识的增量式建图与定位系统 ,通过对单目图像中的道路标识(实线、虚线、指示标识、停车线等)进行实例级建模并充分考虑其空间不确定性,高效构建大尺度范围内具备一致性的轻量级语义地图,并支持多地图融合和高精度的地图匹配定位。本开源项目主要基于本团队之前的工作1;在此基础上,本项目增强了道路标识几何建模、增量式建图、地理注册方面的功能,提高了其实用性。该系统具有以下的特性:
- 通过二维语义分割与逆透视变换(IPM)提取三维道路标识并进行矢量化的实例级建模。
- 考虑道路标识实例的空间不确定性进行概率融合,实现一致性的局部地图构建。
- 使用绝对位置对局部地图进行地理注册,并支持多地图的概率融合。
- 使用滑动窗口和迭代的实例级匹配进行用户端的地图定位。
图1.RoadLib:开源的基于道路标识的增量式建图与定位系统
尽管在轻量级道路地图方面已经有很多发表的工作2-5,但是目前缺少比较完整的开源解决方案。本项目提供了一个开源的轻量级道路建图与定位系统,支持了感知-建图-定位的pipeline和一些基本的算法实现,希望可以给大家的研究提供一个参考。区别于端到端的在线矢量地图生成方法6-7,本系统聚焦于以定位为导向的道路特征地图,并提供了相对更加完整的流程。
工作实现
算法说明
算法部分的主要原理和框架可以参考我们发表的论文1;同时,我们在在原有算法上进行了一定的改进,在此加以说明。
算法部分主要包括道路标识提取与建模 、局部增量式建图 、地图管理 与地图匹配定位等模块。
道路标识提取与建模
首先,使用二维语义分割网络,生成车载相机的道路标识语义分割图像 。在此基础上,使用逆透视变换(IPM)将语义图像转换到鸟瞰视角。IPM的使用基于已知的相机-地面几何(相机高度、相机与地面的夹角),需要加以预先标定8-10。
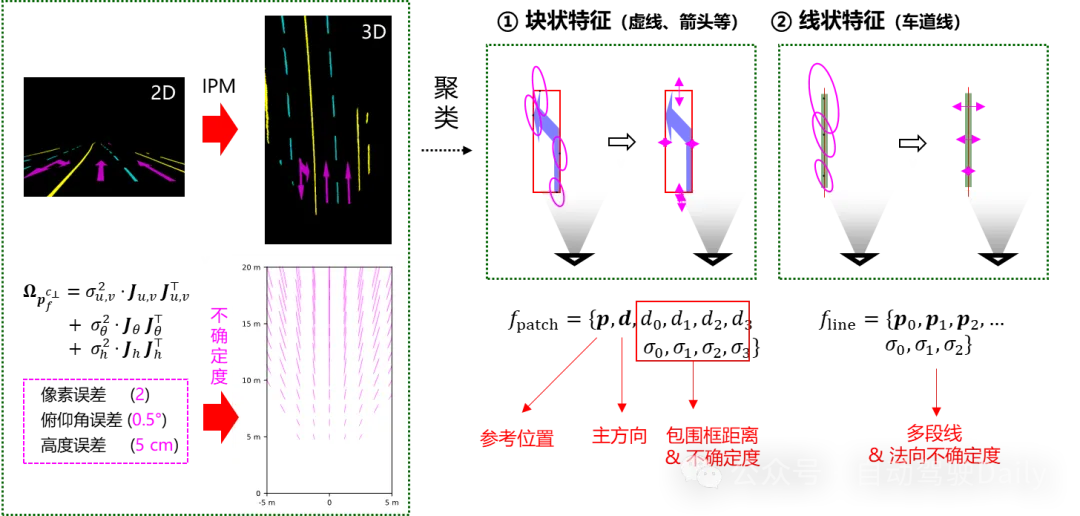
图2.道路标识提取与建模示意图
注意到,由于语义分割以及IPM条件的限制,鸟瞰图上的要素其实并不完全精确,而是具有一定的空间不确定性。造成空间不确定性/几何误差的因素包括:1)图像本身/语义分割造成的像素误差;2)相机俯仰角造成的IPM误差;2)相机距离地面高度造成的IPM误差。针对这些因素,我们假定了典型情况下的误差量级,并通过误差传播得到鸟瞰图上任意位置的空间不确定度。此外,针对于车辆颠簸、道路坡度显著变化等情况,算法会采取IMU姿态高频补偿、坡度变化检测与粗差剔除等方式,尽可能获取精确的空间几何要素。
基于变换后的鸟瞰视角语义图像,对不同类别的道路标识进行像素聚类,并对聚类后的像素块进一步参数化。根据其语义类别,我们将道路标识特征分为块状特征(虚线、箭头等) 与线状特征(实线、停车线等):对于块状特征,我们将其建模为一个参考点,一个主方向,一个包围框,以及四根框线距离的不确定度;对于线状特征,我们将其建模为多段线,以及多段线端点的不确定度。至此,语义像素图转化为了一系列离散的轻量级道路特征实例,大大减小了数据量,便于后续的处理。
局部增量式建图
基于载体的相对位姿估计(由VIO、轮式里程计等获取),我们可以将提取出的道路特征实例根据位姿投影到局部地图坐标系中。在此过程中,对于道路标识的多帧观测将会在空间中叠加起来。为了保持地图要素的一致性并提高其几何精度,我们将道路标识实例进行聚类并加以融合。
具体来说,对块状特征而言,使用线框的交集检查对其进行聚类,并进行基于不确定性线框集合的优化。需要特别注意的是,语义分割的结果受到物体或者视野遮挡的影响,可能会导致不完整的块状特征观测,在融合优化的过程中需要考虑这部分错误信息并加以剔除。
对于线状特征而言,使用邻近点的绝对距离、垂向距离以及局部方向对多帧的线状特征进行聚类,根据聚类的空间范围对融合后线状特征的端点进行扩展,并最小化多帧观测到的三维采样点到线状特征的距离,得到优化后的新线状特征。为了维持线状特征的基本形态并抵抗粗差观测的影响,我们在上述的优化中对线状特征施加一个曲线平滑性的约束。
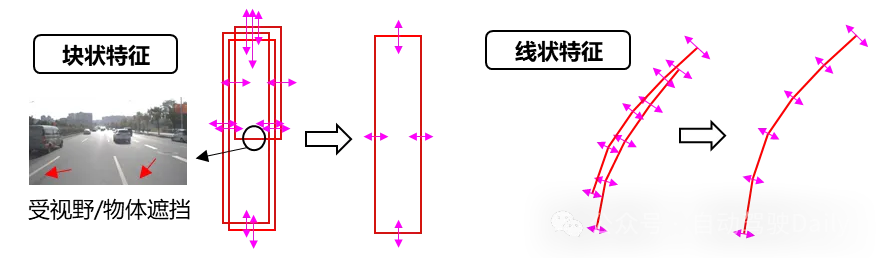
图3.道路标识特征的融合优化示意图(左:块状特征,右:线状特征)
地图管理
局部建图基于里程计位姿进行构建,其结果存在不可避免的漂移,并且没有绝对位置信息,无法进行多地图融合或提供给用户端使用。为了满足实用需求,需要对地图进行地理注册,纠正地图的偏移并将其放置到绝对坐标系下。
地理注册的过程需要使用到高精度的GNSS信息,但是对于实时性没有很高的要求。基于间断可用的高精度GNSS位置,我们可以将其与车辆里程计提供的相对位姿构建全局位姿图,优化得到全局一致的相对高精度的绝对位姿。利用这个无漂移的绝对位姿信息,我们可以在局部地图中对每一个位姿关联的道路特征进行纠正,并将其自然地转换到绝对坐标系下。
图4.地图管理示意图
完成地理注册后,局部构建的地图到了统一的地理坐标系下;我们也可以将多个时段、多个载体采集的地图进行基于不确定性的融合,融合的过程与局部增量式建图中的聚类/融合方式基本是一致的,但在聚类条件方面略有差别。
地图匹配定位
一旦建立了轻量级的道路特征地图之后,用户可以从云端获取地图并用它来进行匹配定位。
基于道路特征地图的匹配定位分两步,第一步是建立正确的匹配关系 。在此,初始位置的确定和初始匹配的建立是难点,也较为重要。(在此次开源的项目中,我们没有考虑这部分内容,直接用初始时刻的近似位姿进行初始化。)一种可行的方案是,由GNSS来提供粗略的初始位置与航向,并结合空间分布模式搜索来实现初始定位。具体来说,在10m左右的初始定位误差下,观测到箭头这种分布相对分散的特征,基本上就可以实现亚米级的初始定位,如下图所示。在位置初值较好的情况下,对用户观测到的特征进行空间最邻近搜索,综合考虑线状特征方向/距离、块状特征尺寸/方向/类别等方面的因素,实现实例级的数据关联。
图5.位置误差下的初始匹配1示意图
一旦建立了匹配关系之后,我们使用滑动窗口的因子图进行用户端的位姿优化 。因子图中主要包含里程计因子和地图匹配因子。其中,里程计因子提供相对位姿约束;地图匹配因子统一构建为点到线的距离------对于线状特征而言,优化用户端特征采样点到地图中线状特征局部线段的距离;对于块状特征而言,优化用户端观测到的包围框采样点到地图中块状特征四条框线的距离。总的来说,车道线实线通常提供横向的位置约束,而车道线虚线、停车线、箭头等道路标识提供纵向的位置约束。
考虑到道路特征检测以及匹配过程中可能存在的粗差,我们维护一个较长的滑动窗口(如10秒)联合多帧的观测进行位姿估计,并使用Cauchy鲁棒核对地图匹配因子进行处理;在优化过程中,会迭代地更新道路特征的数据关联,以实现较为精确和鲁棒的位姿估计。
图6.基于滑动窗口因子图的地图匹配示意图
数据采集
在数据采集方面,我们搭建了自己的数据自动化采集平台,通过GNSS接收机产生的秒脉冲(PPS)触发/同步各种传感器的数据,储存下来的数据记录打上GPS时间系统的时间戳;采集平台可集成GNSS、相机、激光雷达、惯导、毫米波雷达等多种传感器,适用于小车、乘用车等多种平台。
在参考真值方面,我们会在数据采集开始前在开阔环境架设参考基站,用于进行差分GNSS处理;在数据采集完成后,我们使用商用GNSS/INS后处理软件Inertial Explorer(IE)对GNSS与战术级惯导数据进行双向平滑的PPK/INS紧组合解,从而获取相对精确可靠的高频参考位姿。
图7.多传感器数据采集平台
数据标注与训练
本系统的感知模块依赖于道路标识的二维语义分割;目前开源数据集中,带有道路标识语义标注的数据较少,具有代表性的是Apolloscape。
为了实现武汉市区典型道路场景的建图,我们在多时段、不同终端采集的车载图像中,选取600张使用labelme进行了语义标注。在语义分割网络方面,我们使用了MMSeg提供的SegFormer实现。(如果对于实时性有更高的要求,可以考虑使用PP-LiteSeg等轻量级网络,效果都能满足需求)。
图8.道路标识语义分割数据标注示例(Labelme)
本仓库提供了SegFormer的模型文件和运行脚本;如果需要获取数据集进行自行训练,可以联系我的邮箱(yuxuanzhou@whu.edu.cn)。
效果展示
本系统的建图模块运行效果如下图所示。
,时长00:04
定位模块运行效果如下图所示。
,时长00:11
将地图匹配定位的结果与单点定位(SPP)进行对比,结果如下图所示。可以看到,通过融合VIO提供的相对位姿以及地图匹配信息,可以实现稳定的分米级定位。
图9.水平定位误差(单位:米,左:基于rtklib的SPP,右:VIO+10秒窗口地图匹配)
开源仓库
RoadLib的仓库链接如下:https://github.com/GREAT-WHU/RoadLib
视频展示
我们在Bilibili上传了关于本开源项目的预览视频,传送门如下:
https://www.bilibili.com/video/BV1bp42117N1
https://www.bilibili.com/video/BV1dS421d71n
团队实验室介绍
武汉大学GREAT(GNSS+ REsearch, Application and Teaching)团队 长期从事卫星精密定位定轨与多源融合导航方面的研究与教学工作。团队成员有李星星教授,李昕、袁勇强、张柯柯、郑玉新、冯绍权、廖健驰等青年教师,以及三十余名博士和硕士研究生。
主要研究方向及成果包括:1)以PPP-RTK为代表的实时精密定位,可生成并提供多频多系统实时精密轨道、实时钟差、实时UPD以及实时精密大气产品,支持星地一体化增强的快速精密定位;2)基于因子图和滤波的GNSS、视觉、激光、惯性以及高精地图等多源信息紧融合算法,以及相应的软硬件一体化终端设备;3)低轨导航增强以及在观测值层面的多种空间大地测量技术(GNSS/SLR/VLBI)联合解算。
近年来,团队在国际大地测量与地球科学、智能交通、机器人等领域权威期刊发表高水平 SCI 论文 170 篇,Google Scholar 总被引 8300余次。入选爱思唯尔中国高被引学者和全球2%顶尖科学家榜单。承担国际合作、国家级、省部级以及产学研合作项目三十余项,相关成果获得广泛的应用。先后荣获湖北省自然科学奖一等奖、教育部科技进步奖一等奖、国际大地测量和地球物理学联合会(IUGG)青年科学家奖等奖项。
....
#CrossFormer
一个模型同时控制单双臂/四足等机器人
现代机器学习系统依赖于大型数据集来实现广泛的泛化能力,这在机器人学习中往往构成挑战,因为每个机器人平台和任务可能只有小型数据集。通过在多种不同类型的机器人上训练单一策略,机器人学习方法可以利用更广泛且更多样化的数据集,这反过来又能提高泛化能力和鲁棒性。然而,在多机器人数据上训练单一策略具有挑战性,因为机器人的传感器、执行器和控制频率可能差异很大。本文提出了CrossFormer,这是一种可扩展且灵活的基于Transformer的策略,能够利用来自任何实体的数据。我们在迄今为止规模最大、最多样化的数据集上训练CrossFormer,该数据集包含20种不同机器人实体的90万条轨迹。论文证明,相同的网络权重可以控制截然不同的机器人,包括单臂和双臂操控系统、轮式机器人、四旋翼无人机和四足机器人。与以往的工作不同,我们的模型无需手动对齐观测或动作空间。在现实世界中进行的大量实验表明,我们的方法性能与为每个实体量身定制的专业策略相当,同时显著优于以往跨实体学习的最先进技术。
一些介绍
近年来,机器学习领域的许多成功都得益于在越来越多样化和多任务的数据上训练通用模型。例如,曾经由特定任务方法处理的视觉和语言任务,现在由能够跨任务迁移知识的通用视觉语言模型更有效地执行。同样,在机器人领域,近期的数据聚合工作使得能够在跨多个实体、任务和环境收集的机器人数据上训练通用策略成为可能。这些通用策略通过迁移视觉表征和技能,其性能超过了仅使用目标机器人和任务数据训练的专用策略。除了正向迁移带来的好处外,训练通用跨实体策略还最大限度地减少了为每个机器人设计和调整策略架构所需的工程量。然而,训练通用机器人策略具有独特的挑战性,因为机器人系统在相机视角、本体感受输入、关节配置、动作输出和控制频率等方面可能存在很大差异。在训练大规模跨实体策略的初步尝试中,通常仅限于单个机械臂或地面导航机器人,这些机器人可以通过单个相机视角和相对于基座或末端执行器的相对路径点动作来控制。要进一步提高这些策略能够控制的实体的多样性,需要一个支持根据任意数量的相机视角或本体感受观测进行条件设置,并预测任意维度动作的模型架构。
遵循先前的工作,我们采用序列建模方法来进行跨实体模仿学习。提出了一个基于Transformer的策略,通过将输入和输出转换为序列来支持可变观测和动作。我们将这种方法扩展到用单个策略控制迄今为止最多样化的实体集合,包括单臂和双臂机器人、地面导航机器人、四旋翼无人机和四足机器人。
使用提出的Transformer策略,只需将观测值标记化并排列成序列,就可以在具有任意数量相机视角或感知传感器的机器人数据上进行训练。同时,可以预测任意维度的动作,关键是不需要手动对齐不同实体的动作空间。对于每种动作类型,我们将一组动作读出tokens插入到输入tokens序列中。然后,将相应的输出嵌入传递到特定于动作空间的头部,以生成正确维度的向量。我们的策略可以接受以语言指令或目标图像形式的任务,从而允许用户为给定实体选择最自然的任务模态。
本文主要贡献是在迄今为止规模最大、最多样化的机器人数据集上训练的跨实体机器人策略,该数据集包含90万条轨迹和20个不同的实体。我们的策略可以控制具有不同观测和动作类型的机器人,从具有本体感受传感器和12个关节的四足机器人到具有3个相机和14个关节的双臂机器人。在大量的现实世界实验中,发现我们的策略与仅在目标机器人数据上训练的相同架构的性能相当,同时也优于每个设置中的最佳先前方法,这表明我们的架构能够吸收异构机器人数据而不会发生负迁移,同时性能与为每个机器人量身定制的最先进专业方法相当。此外,我们还发现我们的方法在跨实体学习方面优于最先进的方法,同时减轻了手动对齐观测和动作空间的需求。
相关工作
早期关于跨实体机器人策略学习的研究已经探索了多种技术,包括基于实体明确或学习到的表示进行条件设定、领域随机化和适应、模块化策略或基于模型的强化学习。通常,这些先前的研究项目规模较小,仅在模拟环境中进行评估,或仅使用少量机器人数据训练策略以控制少数机器人完成几项任务。
一些先前的工作试图通过使用来自单个机器人实体的大量数据来扩大机器人学习的规模,这些数据是自主收集的,或通过人类远程操作收集的。我们解决了在包含多种不同类型机器人的更广泛机器人数据上训练策略所面临的挑战。其他先前的工作使用来自多个机器人的数据进行训练,但要求每个机器人具有相同的观测和动作空间。例如,Shah等人使用以ego为中心的相机视角和二维路径点动作,在多个导航机器人上训练了一个策略,而RT-X模型则使用第三人称相机视角和7自由度末端执行器位置动作,在单个机械臂上进行了训练。本文的方法不需要数据具有共同的观测和动作空间,因此可以同时控制具有不相交传感器和执行器集合的机器人,例如机械臂和四足机器人。
已经有一些大规模的研究尝试在具有不同观测和动作空间的机器人数据上训练单一策略。Octo可以在具有与预训练期间所见不同的观测和动作的机器人上进行微调。然而,Octo仅使用来自单个机械臂的数据进行预训练,并未探索在更多异构数据上的联合训练。Reed等人和Bousmalis等人提出了一种灵活的基于Transformer的策略,该策略可以处理预训练期间不同的观测和动作空间。他们证明了他们的策略可以控制具有不同动作空间的机械臂,包括4自由度(4-DoF)、6自由度(6-DoF)、7自由度(7-DoF)和14自由度(使用三指手)。
本文探索了增加单个策略可以操作的实体和环境多样性的挑战。除了增加我们可以控制的机械臂实体的数量(例如高频双臂机械臂)之外,还展示了导航和四足行走,并在广泛的真实世界环境中进行了评估,而他们将评估限制在标准化的笼子中。我们还通过比较有无跨实体联合训练的策略来明确评估跨实体的迁移能力,而他们的重点是自主ego改进。
与我们的工作最相关的是Yang等人的研究,他们研究了操控和导航数据之间的迁移。然而,他们的重点是利用这样一个事实:导航中的以自我为中心的运动看起来与操控中来自手腕相机的以ego为中心的运动相似,并且他们手动对这两个实体中的动作进行了对齐。相反,我们的重点是训练一种可以控制超出机械臂和地面导航机器人的实体的策略,包括那些其观测和动作空间无法转换为通用格式的实体。CrossFormer是第一个在四个不同的动作空间(单臂操控、地面导航、双臂操控和四足行走)上进行联合训练的方法,同时没有任何观测空间限制或动作空间对齐,同时在每个机器人上保持最先进的性能。
训练通用、跨实体的策略需要多机器人数据集,并且已有一些工作致力于收集此类大规模跨实体数据集。特别是,Open Cross-Embodiment数据集(OXE)汇集了150万集机器人数据,而我们则在90万轨迹的子集上进行了训练。这里注意到,Octo和RT-X模型也在OXE数据集上进行了训练,但它们仅使用了包含单个机械臂的子集。此外,本文还使用了GNM导航数据集和DROID(大规模Franka机器人操控)数据集,以及为本项目收集的Go1四足机器人和ALOHA双臂数据。
设计跨实体策略
在多实体机器人学习中,主要挑战在于处理广泛变化的观测空间和动作空间,以及机器人系统在控制频率和其他方面的差异。机器人系统可能具有不同数量的相机视图或本体感受传感器,并且它们可能由各种不同的动作表示来控制,包括关节角度、笛卡尔位置和电机扭矩。为了将数据标准化为通用格式,一些先前关于训练跨实体策略的工作忽略了某些观测类型(例如在操控中的手腕视图或第三人称视图)或跨机器人对齐动作空间。相反,我们遵循其他先前的工作9, 10, 6,将跨实体模仿学习视为序列到序列问题,并选择基于Transformer的策略架构,该架构可以处理不同长度的序列输入和输出。
由于其序列性质,Transformer策略能够通过将它们序列化为平面序列来编码来自每个实体的所有可用观测类型。同样,我们可以解码可变长度的动作,这使我们能够为每个实体使用最佳动作类型。使用这种灵活的输出,我们还可以预测大小可变的动作块。动作分块提高了动作的时间一致性,并减少了累积误差,这对于高频精细操控尤为重要。综上所述,Transformer主干网络和动作分块使我们的策略能够控制从具有20Hz关节位置控制的双臂ALOHA系统,到具有5Hz二维航点控制的地面和空中导航机器人等各种机器人。
从高层次来看,本文的Transformer策略遵循了先前在多模态数据上训练Transformer的工作。观测和任务规范通过特定模态的分词器进行分词,组装成词序列,并输入到所有实体共享的因果、仅解码器的Transformer主干网络中。然后,将输出嵌入分别输入到每个实体类别的独立动作Head中,以生成相应维度的动作。架构概述如图2所示。
1)Training data
训练数据混合涵盖了20种不同的机器人实体,这些实体在观测空间、动作空间和控制频率上差异很大。我们从Octo使用的Open Cross-Embodiment数据集中的单臂操控子集开始。然后,添加了DROID Franka操控数据集、在两个机构收集的7000条ALOHA数据(称为ALOHA-multi-task)、来自GNM数据集的60小时导航数据、Go1四足机器人25分钟的行走数据(称为Go1-walk),以及在我们自己实验室收集的200条额外Franka数据(称为Franka-tabletop)。将与每个评估设置最相关的数据集分类为目标数据集,并在训练期间相对于其他数据集对其赋予更高的权重。目标数据集包括用于WidowX评估的BridgeData、用于ALOHA评估的ALOHA-multi-task、用于导航评估的GNM、用于四足机器人评估的Go1-walk,以及用于Franka评估的Franka-tabletop。我们通过在模拟中训练RL专家策略来收集Go1数据。有关训练数据混合,请参见图3;
2)对可变观测类型和任务规范进行分词
训练跨实体策略的第一步是创建输入序列。机器人训练数据中的轨迹是由一系列时间步组成的,每个时间步包含图像观测I、本体感受观测P和一个动作。来自每个实体的数据可能每个时间步的相机视角数量不同,并且可能包含或不包含本体感受观测。为了创建输入序列,首先定义一个观测历史长度k,并将每条轨迹分割成长度为k的段,。然后,根据观测的模态对其进行分词。图像通过ResNet-26编码器处理,生成一个特征图,该特征图沿空间维度展平并投影到词嵌入大小。本体感受观测则直接投影到词嵌入大小。除了观测序列外,策略还接受任务规范。对于跨实体控制而言,重要的是,我们的策略可以接受以语言指令l或目标图像g形式的任务规范。在某些设置下,如导航,任务更自然地以图像目标的形式指定,而在其他设置下,如操控,任务则更容易用语言指定。语言指令与图像观测一起使用FiLM进行处理。目标图像在与当前图像沿通道维度堆叠后,再输入到图像编码器中。
由于训练数据包含单臂操纵器、双臂操纵器、四足机器人和地面导航机器人的数据,因此本文的策略支持以下观测类型的任何子集的调节:(1)工作空间图像:在操纵设置中采用第三人称相机视角。(2)导航图像:在导航设置中采用第一人称相机视角。(3)手腕图像:在操纵设置中采用手腕安装的相机视角。(4)四足本体感受:四足机器人的关节位置和速度估计。(5)双臂本体感受:双臂操纵设置中的关节位置。
为了最大化跨实体的迁移,我们对相同类型的相机视角共享图像编码器权重。因此,例如,在单臂和双臂操纵设置中,工作空间图像都由相同的ResNet图像编码器处理。总共使用了四个图像编码器:一个用于操纵设置中的工作空间视角,一个用于地面导航机器人的第一人称视角,两个用于操纵设置中的手腕相机视角。在输入分词后,我们得到一个观测词序列,其中L和M分别表示图像和本体感受观测的词数量。
3)预测可变长度的动作
在创建输入序列后,下一步是使用Transformer处理输入序列,以预测每个实体合适维度的动作。我们采用带有block级因果注意力掩码的Transformer,使得观测词只能关注同一或先前时间步t的观测词。遵循先前的工作,在输入词序列中每个时间步的观测词之后插入特殊的读出词R。这些读出词只能关注先前的观测词,因此它们作为预测动作的便捷表示。最终的输入序列为,其中N表示读出词的数量。将输入词序列传递给Transformer以获得嵌入序列,然后对与读出词对应的嵌入应用动作Head以产生动作。动作Head有几种可能性,过去的工作已经探索了使用L1或L2损失的回归、使用交叉熵损失的分类或扩散。这选择预测连续动作并使用L1作为损失,因为这在先前的高频双臂操纵工作中取得了成功。因此,动作Head简单地将读出词嵌入投影到动作维度。对于一些实体,我们预测一系列顺序动作。先前的工作表明,动作分块可以改善策略性能,这对于控制频率较高的实体至关重要,因为累积误差会迅速增加。由于我们的动作Head将读出词投影到动作维度大小,因此为每个实体的读出词数量与动作分块大小相匹配。本文的策略有4个动作Head,产生以下类型的分块动作:(1)单臂笛卡尔位置:一个7维动作,表示末端执行器和夹爪驱动的笛卡尔位置相对变化。预测4个动作的分块,并在5-15Hz的频率下在单臂机器人上执行。(2)导航路径点:一个2维动作,表示相对于机器人当前位置的路径点。预测4个动作的分块,并在4Hz的频率下在导航机器人上执行。(3)双臂关节位置:一个14维动作,表示双臂的关节位置。预测100个动作的分块,并在20Hz的频率下在双臂机器人上执行。(4)四足关节位置:一个12维动作,无分块预测,表示腿的关节位置。仅预测1个动作,并在20Hz的频率下在四足机器人上执行。动作分块大小取自每个机器人设置中的先前工作。
4)训练技巧
在实际操作中,我们会对某个具体实例中缺失的观测值进行掩码处理,以确保每个批次元素都包含所有类型的观测值和所有读出词组,并且这些词组在上下文窗口中占据固定位置。或者,为了提高内存效率,观测词和读出词可以紧密排列,以去除填充并适应观测类型较少的实例所需的更多上下文时间步。这是先前工作中采用的一种策略。然而,如果不将观测词和读出词类型固定在上下文窗口中的特定位置,模型将需要仅根据观测值来推断实例,以预测正确类型的动作(而不是依赖于读出词的位置嵌入)。对于一些实例,其观测值可能看起来相似(例如,仅使用手腕摄像头的导航和操纵),因此这种设计可能需要向词序列添加前缀以指示实例。
本文的Transformer主干网络具有12层、8个注意力头、2048维的多层感知机(MLP)以及512的词嵌入大小。总的来说,加上ResNet-26图像编码器和动作Head,模型共有1.3亿个参数。使用在ImageNet上预训练的权重来初始化ResNet-26编码器。使用的context窗口大小为2135个词,这可以容纳5个时间step的context,同时包含所有观测词组和读出词组。我们发现,在导航任务上取得良好性能需要5个时间step的观测历史,并且使用此context长度不会对其他实例的性能产生负面影响。以512的bs大小训练了30万个iter,在TPU V5e-256 pod上耗时47小时。使用了AdamW优化器、逆平方根衰减学习率计划、0.1的权重衰减和1.0的梯度裁剪。应用了标准的图像增强技术。
实验与评测
将CrossFormer与仅在目标机器人数据上训练的相同架构以及目标机器人数据上表现最佳的先前方法进行了比较。
与Yang等人8的比较。我们将CrossFormer与Yang等人8的方法进行了比较,后者对导航和操作动作进行了对齐,并且每次仅使用一个摄像头视图。无论是在第三人称摄像头视角下的桌面操作任务上,还是在常见的导航任务上,CrossFormer的整体性能都比Yang等人8的方法高出3倍。
总结下
CrossFormer是一种可扩展且灵活的Transformer策略,它是在迄今为止最大且最多样化的数据集上训练的,该数据集包含20种不同机器人实体的90万条轨迹。本文展示了一种原则性方法,来学习一种单一策略,该策略可以控制截然不同的实体,包括单臂和双臂操纵系统、轮式机器人、四旋翼无人机和四足机器人。结果表明,CrossFormer的性能与为单个实体量身定制的专业策略相当,同时在跨实体学习方面显著优于当前最先进的技术。然而,本文的工作也存在局限性,结果尚未显示出实体之间的显著正向迁移。我们预计,随着在包含更多实体的更大机器人数据集上进行训练,将看到更大的正向迁移。另一个局限性是,我们的数据混合使用了手工挑选的采样权重,以避免在包含许多重复片段的数据集上过度训练,以及在与我们评估设置最相关的数据上训练不足。原则上,随着模型规模的扩大,策略应该能够同样良好地适应所有数据,而无需任何数据加权。最后,由于需要大模型来适应大型多机器人数据集,模型的推理速度可能成为限制因素。在这项工作中,我们成功地将策略应用于高频、细粒度的双手操纵任务,但随着模型规模的扩大,可能无法控制这些更高频率的实体。未来的硬件改进将有助于缓解这一问题,但还需要进一步研究使用大型模型控制高频机器人的技术。未来的工作还可以包括探索使实体之间实现更大正向迁移的同时保持我们架构灵活性的技术、数据整理技术,以及纳入更多样化的数据源,如次优机器人数据或无动作的人类视频。希望这项工作能够为更高效地从不同机器人实体的经验中学习和迁移知识的通用且灵活的机器人策略打开大门。
....
#特斯拉种出的"萝卜"对我们影响有多大?
10月11日,特斯拉We Robot大会上发布了Robotaxi产品------Cybercap,完全去掉了方向盘和踏板,仅仅依靠中控屏幕完成乘客和车的指令交互。马斯克宣布未来的自动驾驶成本将会降低5倍到0.2美元每英里,而车本身的价格将不超过3万美元。

一起回顾下特斯拉的Robotaxi产品相关信息:

这个不得不提到FSD v12的升级,端到端的全新架构,让全自动驾驶和Robotaxi得到一种阶跃式改善。主要的更新如下:
- 算法端:采用全新端到端架构,优化了30万行C++代码,实现了数据收集、处理、规划到反应的自动化,成功避免了数据损失等风险。
- 硬件端:公司采用自研FSD2.0芯片构建HW4.0平台,实现纯视觉化解决方案。
- 数据端:公司构建自动标注下的数据训练闭环,目前拥有超过180万辆车辆和13亿英里的驾驶数据,实现训练数据上的遥遥领先。
- 算力端:公司采用自研Dojo集群,算力大幅提升,预计24年10月可达100E FLOPS。
FSD版本迭代一览:
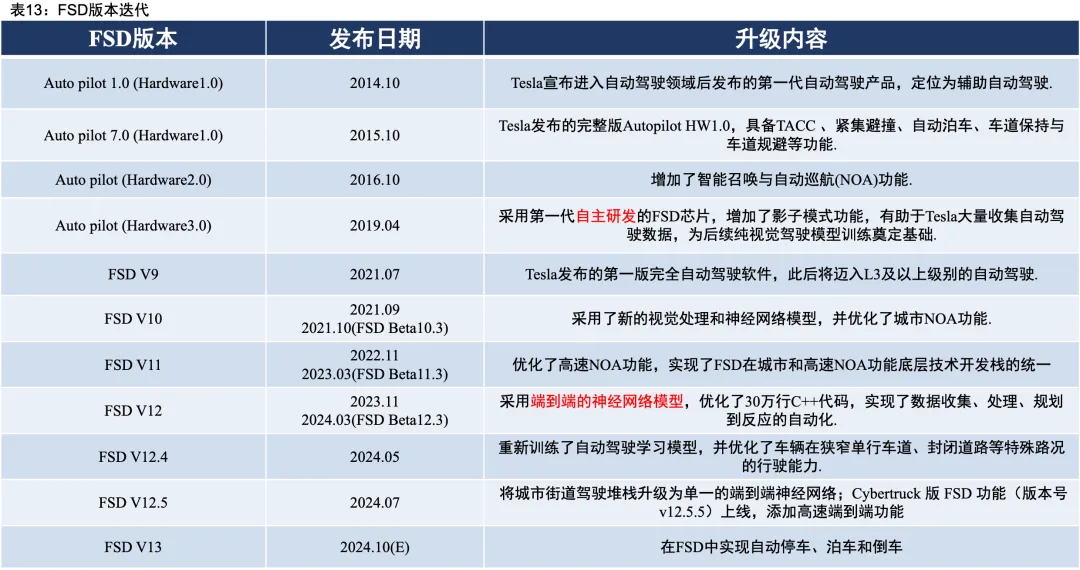
前几年,特斯拉AI Day上透漏的技术方案,引领了整个自动驾驶行业的发展(包括BEV、OCC、数据闭环、无图、端到端等)。近两年,国内厂商的自动驾驶技术飞速发展,现在已经达到领先阶段。
据统计,新能源汽车的销售仍是特斯拉利润的最主要来源,2024年第二季度的财务显示,公司实现了总收入255亿美元,其中汽车销售收入199亿美元。中国是特斯拉model 3 和model Y的销售大国,特斯拉9月5日在X平台上发布路线图,预计2025年第一季度在中国和欧洲推出全自动驾驶(Full Self-Driving,FSD)系统,但仍有待监管批准。
中国的监管环境相对复杂,特别是在高精度地图和数据安全方面,中国政府对自动驾驶技术的要求非常严格。特斯拉需要与中国的本土企业合作,确保其自动驾驶系统符合中国的法规要求。为此,特斯拉已经与百度合作,获得了车道级的导航地图,以支持其FSD在中国的落地。随着FSD系统进入中国市场,预计将推动国内智能驾驶技术与产业链的快速发展,而地大华魔百将遇到强劲对手,从智驾算法到Robotaxi产品。
百度的萝卜快跑已经在武汉等地运营起来,在政策、技术和运营的多方努力下,将会越来越有竞争力。特斯拉也将受益于国内的政策和运营经验,进入国内的进程将会加快。
我们自动驾驶从业者,在技术深度上耕耘,更要在广度和前瞻上有所关注,这样一是可以根据大方向尽快更新自己的技术栈,避免陷入过时的技术陷阱;二是市场变化快,更换工作的频率将会大大提升,都会遇到"面试造火箭"的情况,所以"火箭"技术还是得时刻关注下,不能长期陷入现有项目的"杂事"上。
.....
#盘一盘那些活跃于自动驾驶的"华为天才少年"如今都怎么样了?
金九银十的热潮即将过去,这一年的秋招有人欢喜有人愁。
堪称毕业生的前端人才的"华为天才少年"们,似乎也已低调地在华为就位。
早在今年7月末,华为官方就宣布要开启2024年的"华为天才少年"计划,这次将招募的重点放在了人工智能和智能驾驶等领域。
众所周知,今年华为汽车在智能驾驶方案上的更新速度飞快,其中搭载纯视觉方案的问界M7 Pro更是卖出了一个让余承东喜笑颜开的销售额。
华为对智能车BU的人才需求,让我们不禁回想曾经辉煌的天才少年前辈,那些深耕智驾,或者说曾活跃于自动驾驶领域的"华为天才少年"们,如今都高就何处呢?

姚婷1993年出生于湖南,2015年本科毕业于西北大学信息科学与技术学院的物联网工程专业;同年她免试攻读华中科技大学的计算系统结构专业,并成功直博。2017-2018年期间,姚婷在美国天普大学访学;2019年10月至2020年1月,在西部数据日本研究院实习,任高级研究员。2020年8月,她当选"华为天才少年",目前在华为就任SFS Turbo领域的架构师一职。
她的研究方向为新型存储介质(NVM, SMR)、数据库和键值存储系统。在CCF A类会议FAST、ATC,CCF B类会议IPDPS、MSST,CCF A期刊TPDS、TOS等以第一作者发表多篇科研成果。2019年9月,姚婷参加了NCIS 2019优秀博士生论坛,并获CCF存储专委会卓越论文奖。
姚婷在华为负责全NVM键值存储以及基于NVM的混合存储系统研究,并在自动驾驶、EDA、语音训练、大语言模型训练和推理等多场景进行攻关。入职的第一年,她便独立负责MDS Turbo(极致弹性分布式元数据管理系统)项目,团队实现了千万级元数据IOPS,为自动驾驶、EDA等场景储备了关键能力。
她是一位非常优秀的女性。

黄青虬2012年以692分、全省第40名的成绩考入清华大学自动化系;2020年7月博士毕业于香港中文大学多媒体实验室,该实验室被誉为计算机视觉界的"黄埔军校"。读期间,他发表了十多篇顶级会议论文。同年,他和姚婷一同被选为当时的"华为天才少年",目前是华为智能汽车解决方案事业群激光感知团队的负责人。
他的研究兴趣包括但不限于计算机视觉、深度学习和自动驾驶,他读书和工作期间都在多家顶会顶刊上发表过文章,例如入选ECCV2018的《Person Search in Videos with One Portrait Through Visual and Temporal Links》、入选 ECCV2020的《MovieNet: A Holistic Dataset for Movie Understanding》等。
作为华为自动驾驶激光感知算法团队的负责人,黄青虬带领团队解决了多个技术难题。特别是在极狐项目中,他带领团队在短时间内将激光感知算法模块性能提升了一大截。

丁文超于2015年6月本科毕业于华中科技大学的电子信息工程专业,同年9月他前往香港科技大学深造,2020年8月,博士毕业于香港科技大学电子与计算机工程系沈劭颉教授的课题组,研究自主导航、机器人、计算机视觉,并以"人工智能+机器人"为重心,主攻智能驾驶方向。同年9月丁文超加入华为,成为华为"天才少年"项目的一员,并在华为智能驾驶解决方案BU(Business Unit)担任技术专家。2023年1月,丁文超离开华为加入复旦大学工程与应用技术研究院,担任青年研究员。在复旦,他担任集群机器人系统实验室(MagicLab)负责人,致力于打造面向机器人和智能驾驶的通用人工智能,并探索自动驾驶的大模型、自动驾驶的感知和决策优化。他的研究方向主要为自动驾驶预测决策、机器人智能感知和决策等。
丁文超以第一/通讯作者身份,在TRO、JFR、RAL、ICRA等机器人领域顶级期刊和会议上发表高质量论文十余篇。代表性论文包括:"EPSILON: An Efficient Planning System for Automated Vehicles in Highly Interactive Environments"、"An Efficient B-spline-Based Kinodynamic Replanning Framework for Quadrotors"等。
在华为工作期间,他作为核心贡献者参与了华为ADS1.0以及ADS2.0智能驾驶系统的研发,并贡献了业界领先的智能驾驶预测方案。该方案已成功应用于北汽极狐、长安阿维塔以及问界2023智驾版等多款车型上。

秦通2015年本科毕业于浙江大学控制科学与工程专业,2014年9月,秦通就被香港科技大学录取为硕博连读生,并于2019年获得香港科技大学电子及计算机系博士学位。在香港科技大学,他师从机器人和无人机领域的大牛沈劭劼教授,研究领域包括机器视觉SLAM、视觉惯导融合、多传感器定位等。博士毕业的同年,秦通入选"华为天才少年计划",并成为智能汽车BU的SLAM算法专家。2023年,秦通离开华为回归科研,担任上海交通大学溥渊未来技术学院的副教授,继续从事智能驾驶相关领域的研究和教学工作。
秦通在机器视觉和SLAM领域有着深入的研究,并开源了VINS这一重要算法;他曾在多个国际顶级期刊和会议上发表论文,包括IEEE Transactions on Robotics (T-RO)、IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)等。2018年,秦通获得了IEEE Transaction on Robotics (T-RO)最佳论文提名奖和机器人国际旗舰会议IROS最佳学生论文奖。

*严格意义上来说,稚晖君并不算智驾行列的人,但他作为up主期间最火的一支视频就是关于自制"自动驾驶单车"的,而如今作为智元的创始人之一,他的主攻阵地均在人形机器人上,其所包含的部分算法技术也与自动驾驶略有重叠,因此,小编对他也做介绍。
彭志辉1993年出生于江西吉安,2011年他本科考入电子科技大学生命科学与技术学院;2015年硕士就读于电子科技大学信息与通信工程学院,并于2018年毕业。同年,彭志辉加入了OPPO研究院院I实验室,担任算法工程师一职,并在这里工作了两年时间。2020年,彭志辉通过华为"天才少年计划"加入华为,负责华为昇腾计算产品线的全栈研发;2022年12月,彭志辉从华为离职,选择创业,专注于机器人领域的研究。2023年,他成立了智元机器人公司,并担任联合创始人兼首席技术官。
除了诸多科研及资本title之外,彭志辉还曾有过一个近乎家喻户晓的昵称**@稚晖君**,他在2017年11月26日开始用这个账号在B站上传视频,其视频主要以技术类为主,给观众呈现了一系列自制科技作品,其中最出名的当属他自制的「自动驾驶自行车」:他利用四个月的时间将一辆普通的自行车升级为具备自动驾驶功能的自行车,这辆自行车具备平衡站立、自动避障、路径识别等自动驾驶功能。稚晖君通过CAD建模、3D打印、手工制作、AI算法调教等一系列步骤,成功地将这辆自行车打造成了自动驾驶的"黑科技"产品。
在华为期间,彭志辉负责华为昇腾计算产品线的全栈研发,特别是在人工智能边缘计算领域展现出卓越才能。参与了自研昇腾NPU芯片体系的全栈开发,为华为的技术创新做出了重要贡献。
如今,彭志辉牵头创办的智元机器人在人形机器人领域也取得了显著成果,推出了远征系列等多款人形机器人产品。
....
#WorldSplat
最新世界模型!用于自动驾驶的高斯中心前馈4D场景生成(小米&南开)
让我们先来看两段视频:


世界模型自提出以来,一直被视为理解世界更本质的一种方式,因此获得了非常广泛的研究。世界模型是一种生成式的方法,但在自动驾驶的场景理解中,纯生成的方法一直没有得到广泛的应用。
现有生成的方法主要聚焦于生成多样化、真实的的驾驶视频;然而由于3D一致性有限且视角覆盖稀疏,这些方法难以支持便捷、高质量的新视角合成。与之相反,近年来的3D/4D重建方法虽大幅提升了真实驾驶场景的重建效果,却天生缺乏生成新视角能力。

**所以一种可能的方式是利用生成+重建结合的形式,来建模自动驾驶场景。**3DGS用于重建原始场景,生成方法用于优化新视角,两者强强联合以构建自动驾驶中的世界模型。
为解决场景生成与重建之间的这一困境,南开大学&小米汽车的团队提出了WorldSplat------一种用于4D驾驶场景生成的全新前馈式框架。该方法通过两个关键步骤高效生成具有一致性的多轨迹视频:(1)引入融合多模态信息的4D感知潜在扩散模型,以前馈方式生成像素对齐的4D高斯分布;(2)利用增强型视频扩散模型,对基于这些高斯分布渲染的新视角视频进行优化。在基准数据集上开展的大量实验表明,WorldSplat能够有效生成高保真、具备时空一致性的多轨迹新视角驾驶视频。
一、背景回顾
生成视角可控的真实驾驶场景视频是自动驾驶与计算机视觉领域的核心挑战,对实现可扩展训练与闭环评估至关重要。近年来的生成模型在高保真、用户自定义视频生成方面取得了进展,降低了对昂贵真实数据的依赖。与此同时,城市场景重建方法也优化了3D表示与一致性新视角合成效果。
尽管技术不断进步,生成方法与重建方法仍面临"未知环境创建"与"新视角合成"之间的困境。现有视频生成模型在2D图像域工作,往往缺乏3D一致性和新视角可控性:从某个角度看可能合理,但从新视角生成时却无法保持连贯性。而场景重建方法虽能从已记录的驾驶日志中实现高精度3D一致性与照片级真实感的新视角合成,却缺乏生成灵活性,无法对超出已捕获数据范围的场景进行想象式生成。尽管"先视频生成、后重建"的思路具有可行性,但最终新视角的质量仍会受到两个过程的双重制约。因此,如何将"生成式想象"与"忠实的4D重建"相结合,仍是一个待解决的挑战。
为应对上述挑战,本文提出WorldSplat------一种将生成式扩散与显式3D重建相融合的前馈式框架,用于4D驾驶场景合成。该框架构建动态4D高斯表示,并能沿任意用户定义的相机轨迹渲染新视角,无需进行逐场景优化。通过在扩散模型中嵌入3D感知能力,并采用以高斯分布为核心的显式世界表示,本文方法确保了跨新轨迹视角的时空一致性。如图1所示,以往的驾驶世界模型虽能生成真实视频,但由于其随机性,在合成新视角序列时往往会失去连贯性;与之相反,WorldSplat通过单次前向传播直接输出4D高斯场,能够实现稳定、一致的新视角渲染。为实现灵活的生成控制,该框架支持丰富的条件输入------包括道路草图、文本描述、动态目标放置与自车轨迹,使其成为适用于多样化驾驶场景的高可控性模拟器。
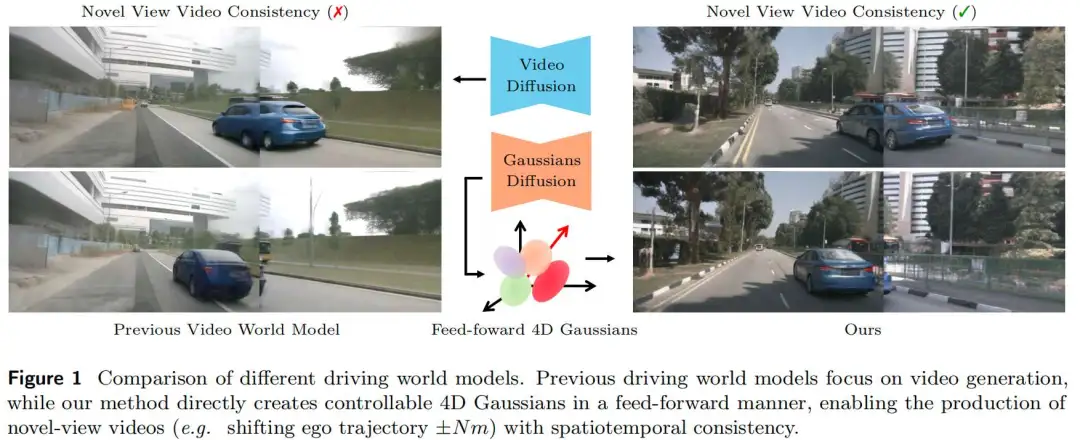
具体而言,WorldSplat的工作流程分为三个阶段:首先,不依赖真实图像或激光雷达(LiDAR)数据,仅基于灵活的用户定义控制条件,4D感知潜在扩散模型生成多视角、时间连贯的潜变量,该潜变量天生包含RGB、度量深度与语义通道,可提供兼具视觉外观与场景几何信息的视角感知3D数据。其次,潜在高斯解码器将这些潜变量转换为显式的4D高斯场景表示;具体而言,该解码器预测一组像素对齐的3D高斯分布,并将其划分为静态背景与动态目标,再聚合为统一的4D表示,从而对动态驾驶世界进行显式建模。为清晰说明,我们在图7中可视化了该表示,并认为相较于点云图,该表示为一致性新视角视频生成提供了更合适的基础。随后,我们采用快速高斯泼溅(Gaussian splatting)技术,将高斯分布投影到新的相机视角,实现具备真实几何一致性的新轨迹视频合成。最后,对渲染帧应用增强型扩散优化模型,通过修正伪影与增强细节(如纹理、光照)进一步提升真实感,最终得到高保真新视角视频。
综上,本文的主要贡献包括:
- 4D场景生成框架:提出WorldSplat------一种前馈式4D生成框架,将驾驶场景视频生成与显式动态场景重建相统一;
- 前馈式高斯解码器:设计动态感知高斯解码器,能从多模态潜变量中直接推断出精确的像素对齐3D高斯分布,并通过静-动态分解将其聚合为4D高斯表示;
- 全面评估:大量实验表明,本文框架能生成具备时空一致性的自由视角视频,在驾驶视频生成任务中实现当前最优性能,并为下游驾驶任务提供显著增益。
二、算法详解概述
如图2所示,我们的框架包含三个关键模块:用于多模态潜变量生成的4D感知潜在扩散模型、用于前馈式4D高斯预测及实时轨迹渲染的潜在高斯解码器,以及用于视频质量优化的增强型扩散模型。这三个模块独立训练,其架构与训练流程将后续章节中详细说明。最后阐述如何整合这些模块,以生成高保真、具备时空一致性的视频。
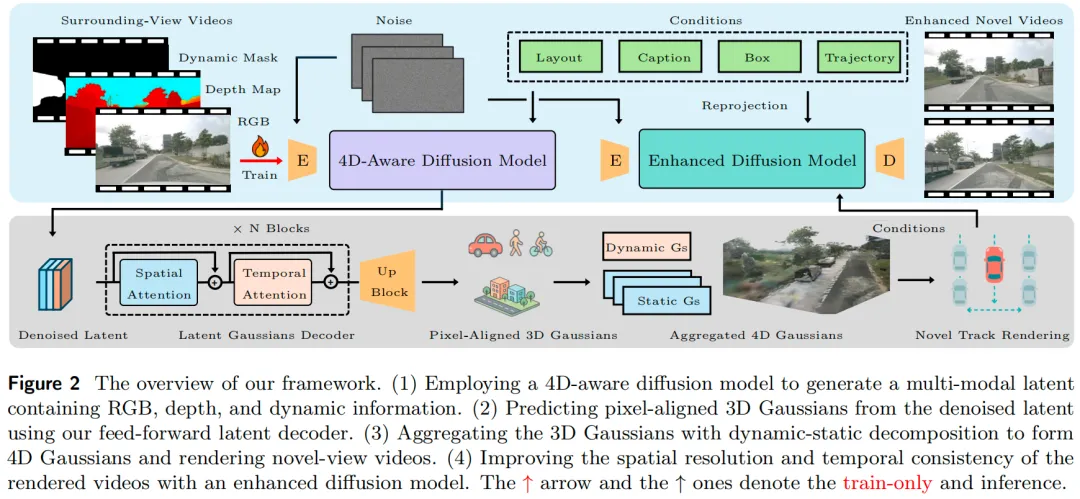
4D感知潜在扩散模型
给定噪声潜变量与细粒度条件(即边界框、道路草图、文本描述及自车轨迹),4D感知潜在扩散模型通过去噪生成包含RGB、深度与动态目标信息的多模态潜变量,这些潜变量随后用于4D高斯预测。下文将详细阐述潜变量、控制条件、模型架构及训练策略。
多模态潜变量融合
对于一段包含T帧的K视角驾驶视频片段,我们首先利用预训练变分自编码器(VAE)编码器提取多视角图像潜变量。接着,通过基础深度估计器(Hu et al., 2024)生成度量深度图D,将其归一化至范围并复制到三个通道,再编码为深度潜变量。已有研究表明,融入深度潜变量可同时提升3D重建与生成质量。为进一步分离静态与动态目标以实现4D场景重建,我们从动态类别目标的二值分割掩码中,利用SegFormer提取语义掩码潜变量。最终,将这三个潜变量在通道维度上拼接,形成解码器输入。
多条件控制
扩散Transformer以结构化线索为条件,包括鸟瞰图(BEV)布局、实例边界框、自车轨迹与文本描述,统一表示为。借鉴MagicDrive的方法,我们获取布局、边界框与轨迹输入。为实现细粒度文本描述控制,我们引入DataCrafter工具:将K视角视频分割为片段,使用视觉语言模型(VLM)评估器为片段评分,生成单视角文本描述,再通过一致性模块融合这些描述。最终得到的结构化文本描述既包含场景上下文(天气、时间、布局),也涵盖目标细节(类别、边界框、描述信息),可确保跨视角的时间连贯性与空间一致性。
架构
4D感知扩散模型的架构基于ControlNet,以OpenSora v1.2为基础构建Transformer。具体而言,我们为OpenSora扩展了双分支扩散Transformer:主分支为DiT流,用于处理时空视频潜变量L;多块ControlNet分支用于处理条件C。为确保多视角连贯性,我们将标准自注意力替换为跨视角注意力。
每个ControlNet块整合两部分信息:通过预训练VAE编码的道路草图潜变量,以及通过T5编码器生成的文本嵌入。3D边界框、自车轨迹与文本特征通过跨注意力进一步融合为统一的场景级信号,为跨时间与跨视角的一致性视频合成提供细粒度引导。
训练
训练阶段,我们用Rectified Flow模型替代标准IDDPM调度器,以提升稳定性并减少推理步数。设为干净潜变量L的真实样本,为噪声样本,引入连续混合参数并定义插值状态:
随后,我们训练一个以C为条件的神经场,通过最小化以下损失函数恢复目标向量:
测试阶段,我们将(其中)离散化,并通过以下公式反向迭代:
推理时,我们不使用VAE解码器从去噪潜变量中重建视频帧,而是采用q后文介绍的潜在4D高斯解码器,直接预测4D高斯分布以用于新视角视频渲染。
潜在4D高斯解码器
我们的高斯解码器从多模态潜变量L中预测像素对齐的3D高斯分布,随后利用潜变量中的语义信息区分动态与静态目标,并基于3D高斯分布重建4D场景。
架构
基于Transformer的解码器包含多个跨视角注意力块与跨帧时间注意力层,后续接层级式上采样块,用于预测逐像素高斯参数。如图2所示,该设计可捕捉4D场景的时空动态特征,并从多模态潜变量输入L中直接输出像素对齐的3D高斯分布。为进一步增强3D空间线索,我们融入普吕克射线图P,该射线图编码了由相机内参与外参推导的像素级射线原点与射线方向。
每个3D高斯分布的参数定义如下:、(四元数旋转)、(尺度)、(不透明度)、(颜色)。解码器最后一层预测逐像素偏移量δ、旋转参数r、尺度参数s、不透明度α、颜色c、深度d,以及用于静-动态分类的对数概率m。高斯中心通过以下公式计算:,其中为学习得到的偏移量。该过程生成一系列高斯集合G与指示动态类别目标的掩码M(随时间变化),可简洁表示为:
与现有前馈式场景重建模型相比,我们的解码器支持多达48个同时输入视角,能够更全面地重建复杂场景。
4D高斯聚合
通过融合各帧的3D高斯估计结果,我们构建出时间对齐且连贯的场景模型。我们采用一种简洁的4D重建方案:已知自车轨迹T的情况下,通过自车坐标变换将所有3D高斯分布转换到统一坐标系中。在每个时间步,将所有帧的静态高斯分布与当前帧的动态高斯分布进行融合,公式如下:
通过整合多时间步数据,解码器能够捕捉场景完整的几何结构、外观与运动信息,支持从新空间视角与不同时间点进行渲染。
监督与损失函数
需注意,高斯解码器同时预测像素对齐的3D高斯分布与用于区分动态/静态区域的语义掩码。预测的语义掩码以SegFormer生成的掩码为监督,采用二元交叉熵损失训练。将所有观测时间步的预测掩码与4D高斯分布组装后,我们将其投影到一组目标渲染时间步上。训练过程中,随机选择一个基准时间步t,采样T个目标时间步,并提取对应的干净潜变量L作为输入。对于每个,渲染RGB图像R与深度图像,并以对应的真实信号(RGB输入I与度量深度图为监督:RGB重建采用 photometric 损失与感知LPIPS损失联合引导,深度预测则在度量空间中采用损失监督。整体训练目标定义为这些损失的加权和:
推理时,预训练高斯解码器生成的4D高斯分布用于沿自定义自车轨迹渲染新视角视频。
增强型扩散模型
增强型扩散模型对基于4D高斯分布渲染的RGB视频进行优化,生成过程同时以原始输入C与渲染视频为条件。该优化过程可丰富空间细节并增强时间连贯性,最终输出高保真新视角序列。
基于恢复的重建
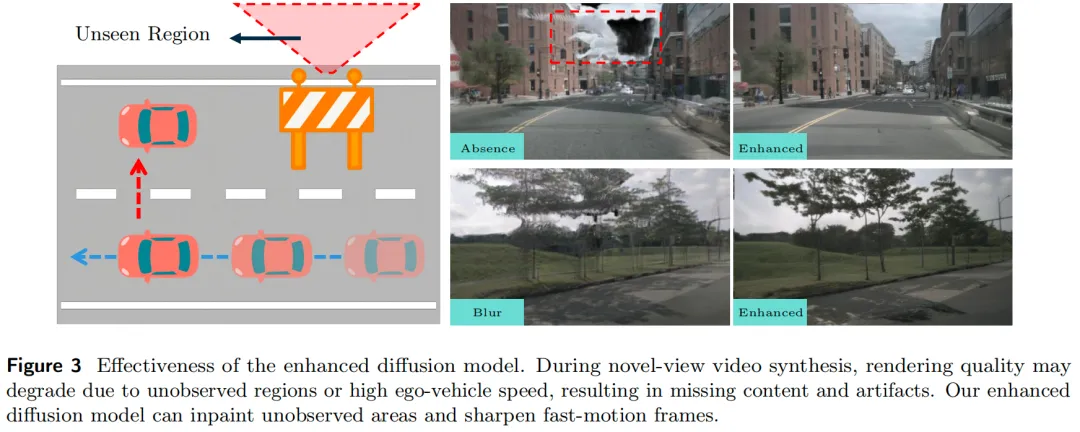
潜在高斯解码器以前馈方式重建4D场景,但Gaussian splatting技术存在固有局限:未观测区域的渲染质量较低;且无需逐场景优化时,强自车运动下的新视角重建可能出现模糊。为解决这些问题,我们设计增强型扩散模型以提升渲染质量。
如图3所示(为便于理解),左上角新视角渲染因遮挡缺失天空区域,左下角渲染因强自车运动出现模糊;相比之下,我们的模型显著提升了最终渲染结果的保真度与清晰度。
架构与训练
增强型扩散模型的整体架构与训练策略与4D感知扩散模型保持一致。其目标是在潜变量空间中优化渲染结果R,以为真实值,因此回归目标为图像潜变量------这与常见的潜在扩散模型一致。训练流程与4D感知扩散模型相同,仅在控制条件与回归目标上存在差异。
受高斯喷绘技术局限,推理阶段的新视角渲染质量往往低于训练所用的源视角质量。ReconDreamer通过退化渲染样本训练缩小这一差距,但仅依赖退化输入会削弱条件与输出间的对齐性。我们采用混合条件策略,融合退化视角与高质量视角,同时提升可控性与生成保真度。
框架推理流程
推理时,4D感知扩散模型以噪声潜变量与控制条件C为输入,输出去噪潜变量;高斯解码器从中预测4D高斯分布,再基于自定义自车轨迹渲染新视角视频。随后,将草图与边界框重投影为与,形成新控制条件。增强型扩散模型以噪声潜变量与为输入,对进行优化,最终生成高保真新视角视频。
自定义轨迹选择
基于FreeVS的自车姿态扰动策略,我们通过横向偏移车辆路径生成一组新轨迹。具体而言,给定原始自车轨迹,沿车辆y轴施加的偏移量,生成6条扰动轨迹。对于每条扰动路径,聚合后的4D高斯分布可渲染出高保真新视角视频。
此外,从真实驾驶视频重建场景时,可绕过4D感知扩散模型,高斯解码器直接以干净潜变量为输入。
实验结果
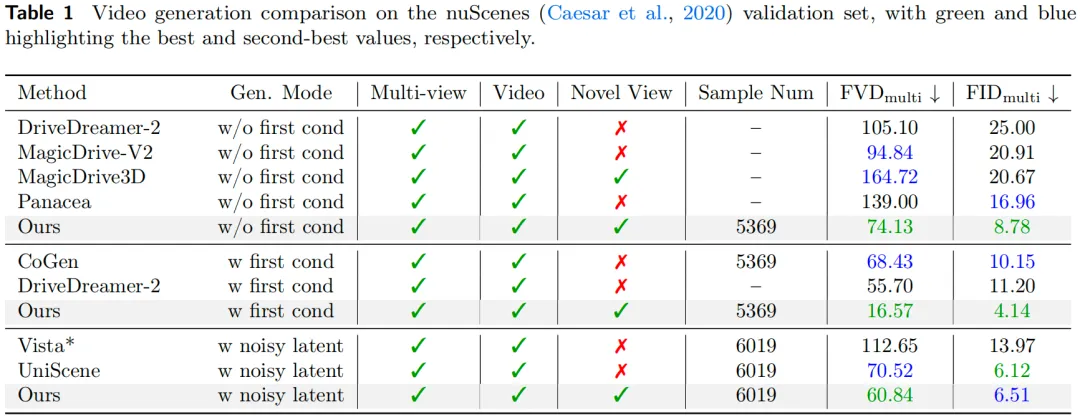
主实验结果对比:
可视化结果:
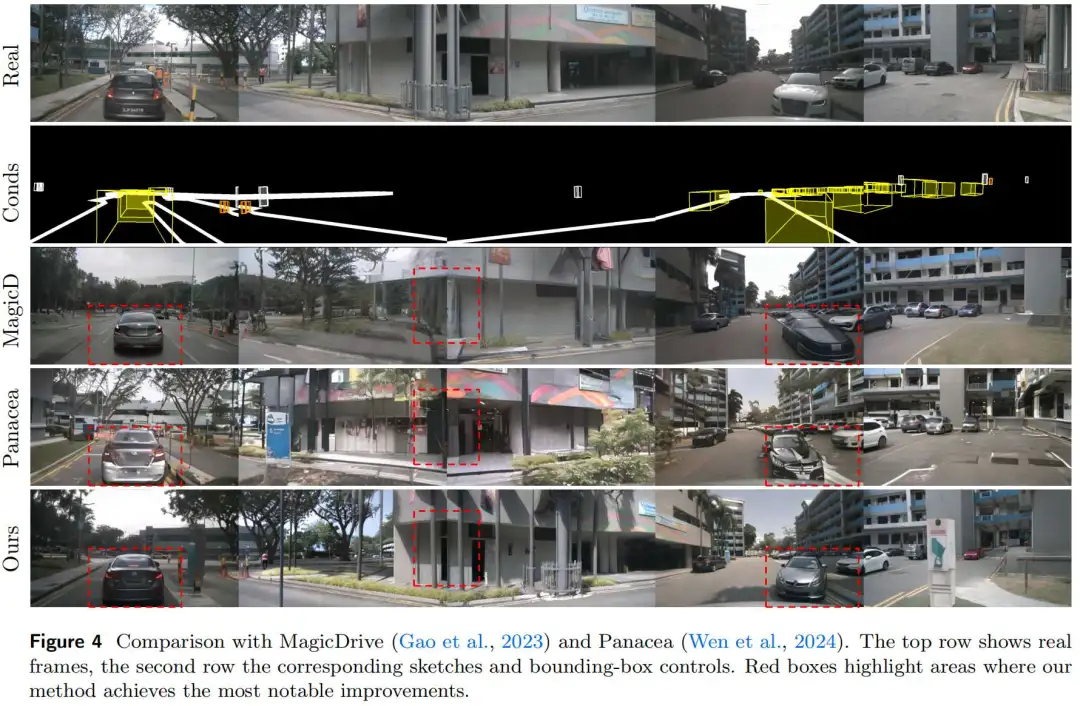
新视角合成对比:
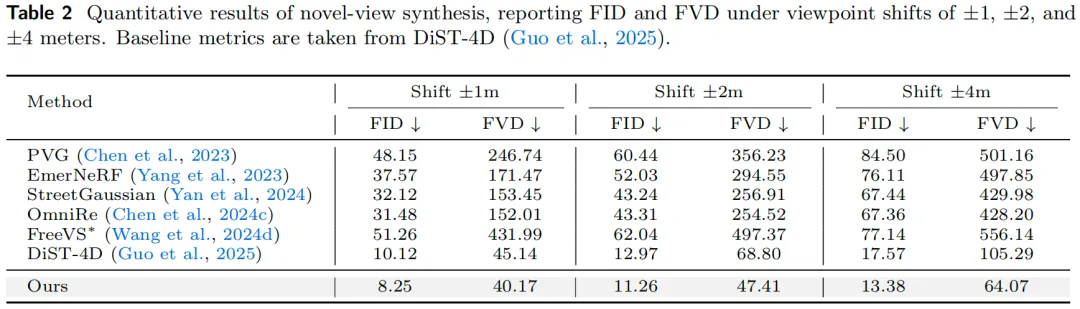
新视角可视化:

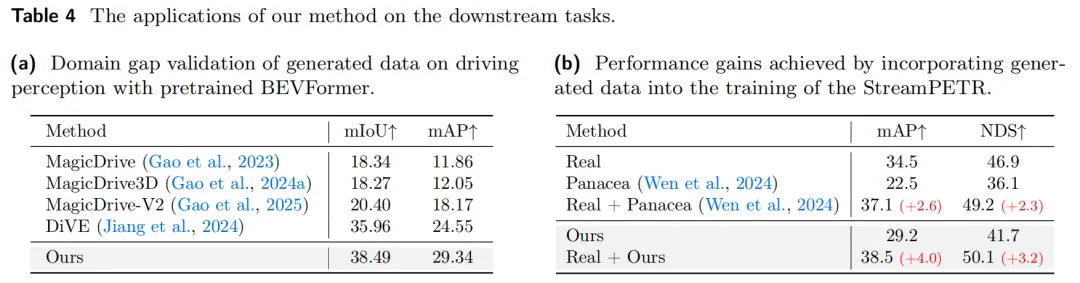
消融实验结果:

四、结论
在本研究中,我们提出了WorldSplat------一种全新的前馈式框架,该框架整合了生成式方法与重建式方法的优势,用于4D驾驶场景合成。通过将4D感知潜在扩散模型与增强型扩散网络相结合,我们的方法能够生成显式4D高斯分布,并将其优化为高保真、具备时间与空间一致性的多轨迹驾驶视频。在标准基准数据集上开展的大量实验证实,WorldSplat在真实感与新视角质量方面均优于现有的生成技术与重建技术。
....
#DriveDPO
模仿学习无法真正端到端!Safety DPO打破模仿学习固有缺陷(中科院最新)
想象一下,你正在教一个模型学习开车。你给它看了一堆人类司机的驾驶录像,希望它能模仿得一模一样。听起来很合理对吧?但问题来了------人类司机偶尔也会犯错,或者做出一些在特定情况下很危险的操作!
这就是当前端到端自动驾驶面临的最大挑战:模仿学习虽然能让模型开车像人类,但不能保证它开得安全。针对这个现象,中科院的团队认为模仿学习主要有两个大问题:
- 几何距离不等于安全距离:模仿学习通常使用均方误差等对称损失函数,只关心预测轨迹与人类轨迹的几何相似度。但现实中,即使轨迹看起来很像,安全性可能天差地别;
- 对称损失忽略风险不对称性:在紧急刹车时,超越人类轨迹可能导致追尾,而滞后于人类轨迹通常更安全。但对称损失函数对两个方向的偏差给予同等惩罚,完全无法反映驾驶风险的不对称性。
为了解决上述的问题,中科院的团队提出了DriveDPO - 一种基于safety DPO的策略学习框架。首先从人类模仿相似度和基于规则的安全分数中提炼出统一的策略分布,用于直接的策略优化;其次,引入迭代式DPO,将其构建为轨迹级别的偏好对齐任务。在NAVSIM基准数据集上的大量实验表明,DriveDPO实现了90.0的最新最优PDMS。此外在多种复杂场景下的定性结果进一步证明,DriveDPO能够生成更安全、更可靠的驾驶行为。
- 论文链接:https://arxiv.org/abs/2509.17940
- 论文标题:DriveDPO: Policy Learning via Safety DPO For End-to-End Autonomous Driving
背景回顾
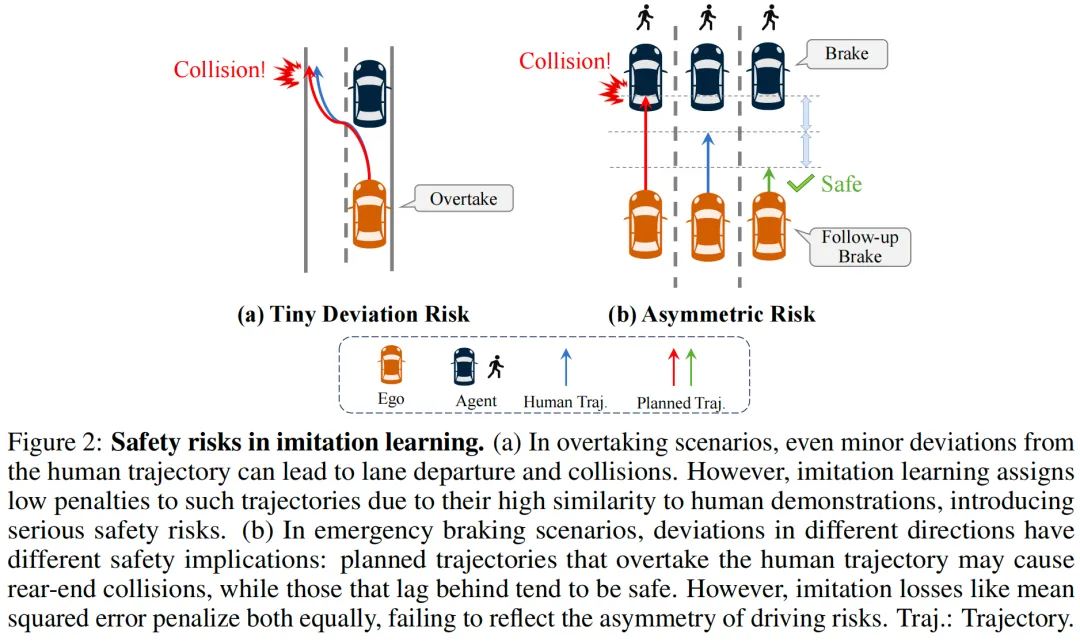
近年来端到端自动驾驶发展很快。与传统的模块化流程不同,端到端方法直接从原始传感器输入预测未来轨迹,既避免了模块间的误差累积,又简化了整个系统的流程。如图1a所示,主流端到端方法通过模仿学习优化。尽管模仿学习能生成符合人类驾驶习惯的行为,但它存在两个关键的安全性问题:
- 第一,模仿学习的核心是最小化预测轨迹与人类轨迹之间的几何距离。然而即使与人类轨迹的差距很小也可能导致危险结果;
- 第二,模仿学习中常用的对称损失(如均方误差)会对两个方向的偏差施加同等的惩罚,但不同方向的偏差对安全性的影响差异极大(见图2b)。因此仅通过模仿学习训练的策略往往会生成看似合理、但在实际驾驶场景中存在安全风险的行为。
为解决安全性问题,一些引入了基于规则的指导模型,并采用多目标蒸馏技术,将多个规则驱动的指标作为监督信号进行回归,具体如图1b所示。尽管此类设计在安全性上优于纯模仿学习,但它们会为每条锚定轨迹独立学习单独的评分函数,而未直接优化底层的策略分布,最终导致驾驶性能欠佳。
受模仿学习的安全性问题以及基于分数的方法在优化间接性上的局限所启发,本文提出DriveDPO------一种基于安全直接偏好优化(Safety DPO)的策略学习框架。具体而言:
针对基于分数的方法仅优化单条锚定轨迹的分数、而非整体策略分布的问题,本文提出统一策略蒸馏方法:将人类模仿相似度与基于规则的安全分数融合为单一监督信号,用于策略模型的训练。与基于分数的方法为每个候选轨迹构建独立评分头不同,本文方法直接对所有锚定轨迹的策略分布进行监督,从而实现更连贯的端到端策略优化。
然而将模仿监督与安全监督直接融合为单一训练目标会引发多目标优化问题。为解决这一问题,本文引入迭代式DPO,提出"安全直接偏好优化(Safety DPO)"------将监督信号重构为轨迹级别的偏好对齐任务。该方法通过更稳定、更具针对性的优化,增强策略对安全导向偏好的响应能力。通过对轨迹对进行偏好学习,Safety DPO能优先选择"符合人类驾驶习惯且安全"的轨迹,而非"符合人类驾驶习惯但不安全"的轨迹,从而在策略学习中实现更精准的安全偏好对齐。
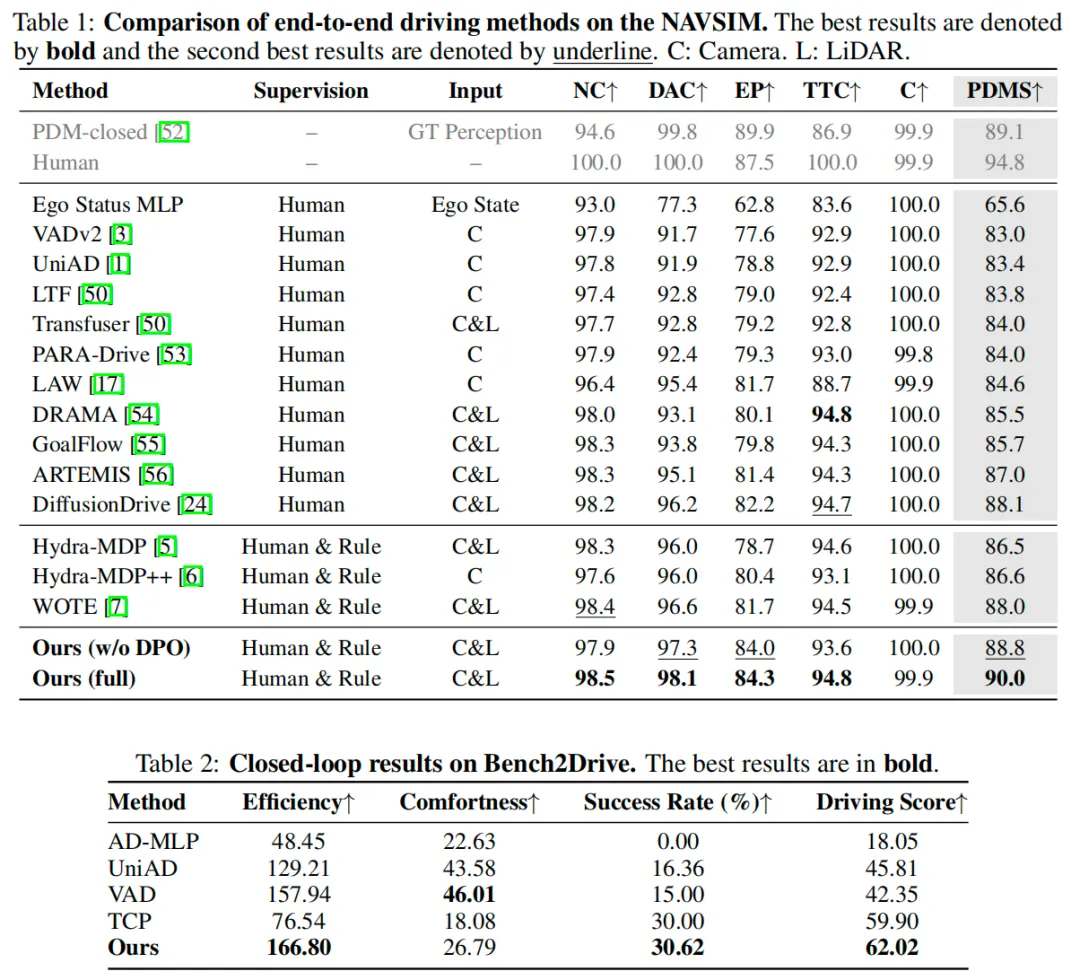
本文在NAVSIM基准数据集和Bench2Drive基准数据集上对所提框架进行了评估。在使用ResNet-34 backbone的统一实验设置下,实现了90.0的最新最优PDMS,相较于基于模仿学习PDMS提升了1.9;相较于基于分数的最新最优方法PDMS提升了2.0。此外,定性结果还表明,本文方法在复杂场景中显著提升了所学策略的安全性。
本文的贡献可总结如下:
- 明确了现有模仿学习方法与基于分数的方法的核心挑战:纯模仿学习无法区分"看似符合人类驾驶习惯但存在安全隐患"的轨迹;而基于分数的方法将分数预测与直接策略优化相分离,导致性能不佳。
- 为应对上述挑战,提出DriveDPO(基于Safety DPO的策略学习框架):首先从人类模仿信号与基于规则的安全分数中提炼统一的策略分布,随后通过DPO的微调阶段进一步优化策略。
- 在NAVSIM基准数据集上开展了全面实验,实现了90.0的最新最优PDMS,在多个安全关键指标上均取得显著提升。通过有效抑制不安全行为,本文方法为安全关键型端到端自动驾驶应用展现出巨大潜力。
DriveDPO算法详解
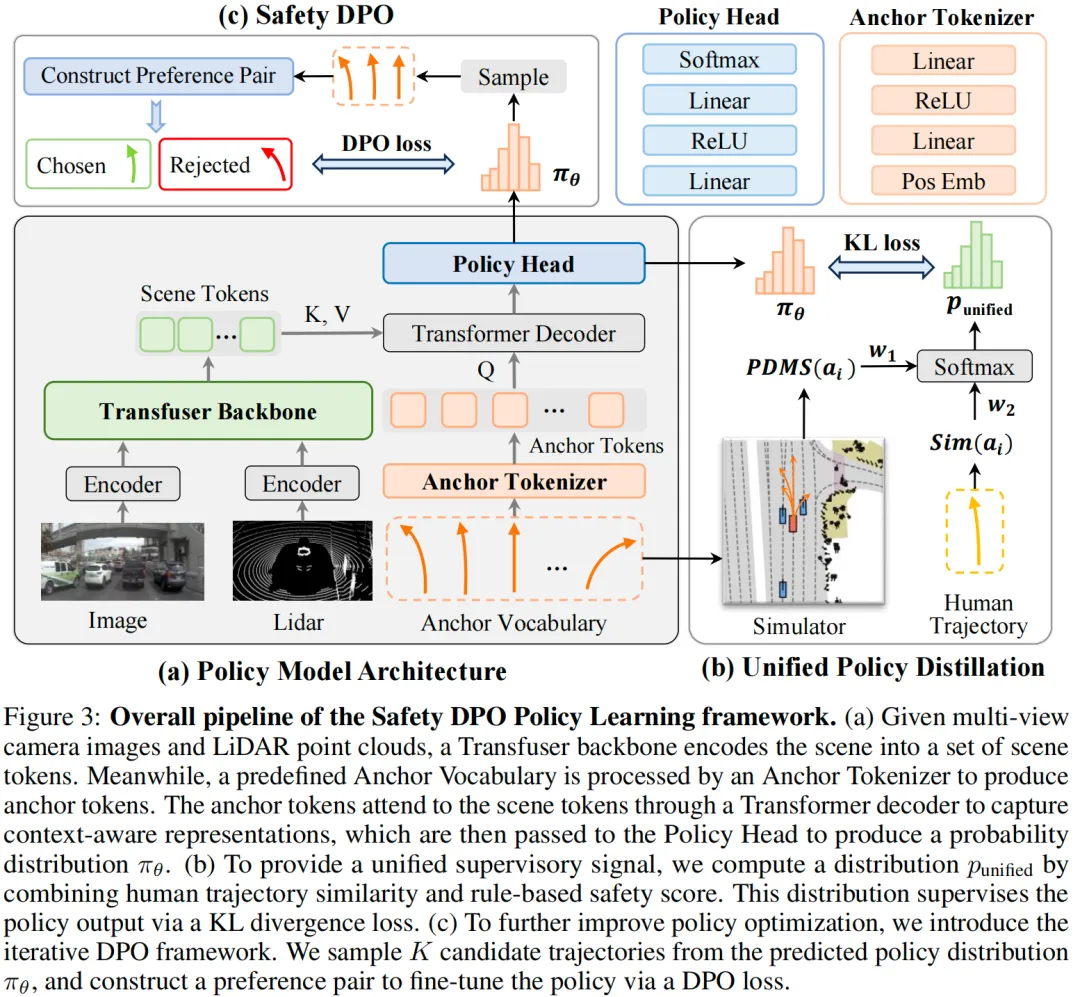
策略模型架构
模型的输入包括多视图相机图像、激光雷达(LiDAR)点云、当前自车状态(ego state)与导航指令,输出为预定义的个离散候选轨迹上的概率分布,具体如图3a所示。首先,本文构建离散的锚点轨迹集合以定义策略网络的输出空间:通过对NAVSIM数据集Navtrain子集中的人类驾驶轨迹进行-均值聚类,得到个具有代表性的锚点轨迹,记为(其中)。每个锚点轨迹包含个未来时间步的信息,每个时间步均由()表示位置与航向。
这些锚点会输入至"锚点Tokenizer(Anchor Tokenizer)"进行处理:首先采用神经辐射场(NeRF)风格的傅里叶位置编码捕捉空间结构,其数学表达式为:
其中,为位置编码维度。随后,编码后的轨迹会输入至多层感知机(MLP),生成最终的锚点token表示:
其中,为嵌入维度(embedding dimension)。
在感知模块方面,本文采用Transfuser作为backbone,实现相机图像与激光雷达点云的融合。该模型首先分别对图像与激光雷达输入进行编码,再通过多个Transformer模块进行融合,得到统一的场景表示,即"场景Tokens(Scene Tokens)",其定义为:
其中,为场景token的数量。
在最终决策阶段,使用基于Cross-Attention的Transformer解码器,实现锚点token与场景上下文的对齐。每个锚点token作为查询(query),对场景token进行注意力计算,得到融合上下文信息的表示:
其中,表示融合场景语义信息后的锚点表示。最后,策略网络对每个融合上下文的锚点token应用MLP,再通过softmax函数得到锚点轨迹上的最终策略分布:
统一策略蒸馏
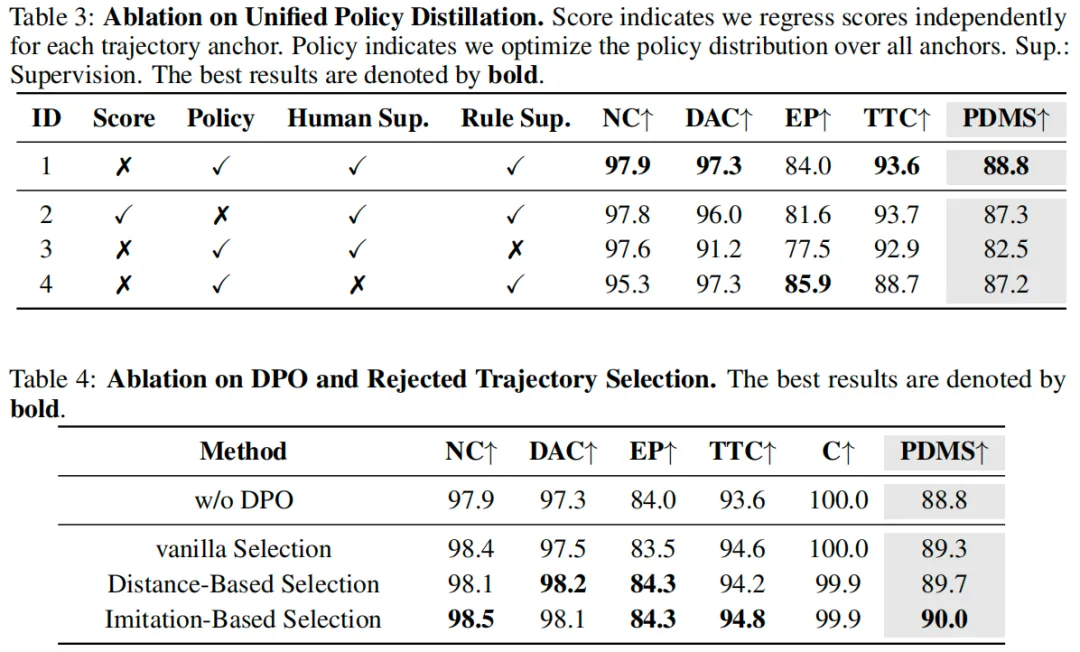
基于分数的学习方法通常为每个轨迹锚点构建独立的评分头(score head),仅预测单锚点分数而不直接优化策略分布。为解决该问题,本文提出"统一策略蒸馏"方法:将所有监督信号压缩为单一策略分布目标,实现策略输出的端到端一致性优化。具体而言,本文将"人类模仿相似度"与"基于规则的安全分数"整合,作为输出概率分布的监督信号。
对于锚点词汇表中的每个候选轨迹,首先定义候选轨迹与人类参考轨迹之间的"模仿相似度"为"负欧氏距离"。为确保不同场景间的可比性,通过softmax函数对所有锚点的相似度进行归一化,得到相对相似度:
为获取每个锚点轨迹的"基于规则的安全分数",本文使用NAVSIM仿真器:该仿真器可对每条轨迹进行前向仿真(forward simulation),并输出多个规则化指标,包括"无责任碰撞(No At-Fault Collision, NC)"、"可行驶区域合规性(Drivable Area Compliance, DAC)"、"自车进度(Ego Progress, EP)"、"碰撞时间(Time-to-Collision, TTC)"与"舒适性(Comfort, C)"。这些指标会被整合为单一标量分数------PDMS(轨迹决策度量分数),其计算公式为:
通过NAVSIM仿真器对每条锚点轨迹进行前向仿真,即可计算其对应的PDMS:
在构建策略学习的统一监督分布时,本文引入"对数变换",将模仿相似度与安全分数从区间映射至区间------该变换可放大数值较小时的差异:若某一锚点的安全分数较低,其变换后的值会显著低于安全锚点,从而有效区分安全与不安全轨迹。相比之下,基于分数的方法仅对每个锚点独立回归分数,无法捕捉安全与不安全轨迹间的显著差异。此外,对数变换可保留模仿相似度的相对差异,引导策略优先选择"既安全又符合人类驾驶行为"的轨迹。
最后,通过softmax函数构建软目标分布(soft-target distribution),在候选锚点间引入竞争机制。最终的"统一监督分布"计算公式为:
其中,与为权重系数。策略模型的训练目标为"最小化预测分布与统一监督分布之间的KL散度",损失函数定义为: \\mathcal{L}*{unified}=KL\\left(p*{unified} \| \\pi_{\\theta}\\right)
Safety DPO
通过"统一策略蒸馏"得到预训练策略后,由于同时存在模仿与安全信号的联合监督,会引发多目标优化问题。为缓解该问题,本文采用迭代式DPO框架,提出"安全直接偏好优化(Safety DPO)":通过明确优先选择"既符合人类驾驶习惯又安全"的轨迹、抑制"看似符合人类驾驶习惯但存在风险"的轨迹,进一步优化策略。
具体流程如下:首先从当前策略分布中采样个候选轨迹。若采用"朴素方法",会将中分数最高的轨迹作为优选轨迹、分数最低的作为拒绝轨迹,但这种方式构建的偏好对过于简单,限制了基于偏好优化的效果。为此,本文保留"选择分数最高的轨迹作为优选轨迹"的逻辑,但设计两种"拒绝轨迹选择策略":
(1)基于模仿的拒绝轨迹选择
该策略用于识别"空间上接近人类参考轨迹但安全性能较差"的轨迹。具体而言,在满足"PDMS低于预定义安全阈值"的前提下,选择与人类轨迹空间距离最近的轨迹作为拒绝轨迹,其数学表达式为:
其中,为预定义安全阈值,表示人类参考轨迹。
(2)基于距离的拒绝轨迹选择
该策略用于识别"空间上接近优选轨迹但不安全"的候选轨迹。具体而言,在满足"PDMS低于阈值"的前提下,选择与优选轨迹空间距离最近的轨迹作为拒绝轨迹,其数学表达式为:
实验表明,两种策略均能显著提升策略的安全性能,且第一种策略(基于模仿的选择)效果略优。因此,本文实验默认采用第一种策略构建偏好对。
最终,给定构建的偏好对,采用标准DPO损失函数进行策略微调,损失公式为:
其中,为Sigmoid函数,为温度参数,为参考策略。
实验结果
NAVSIM和Bench2Drive上的结果:
消融实验:
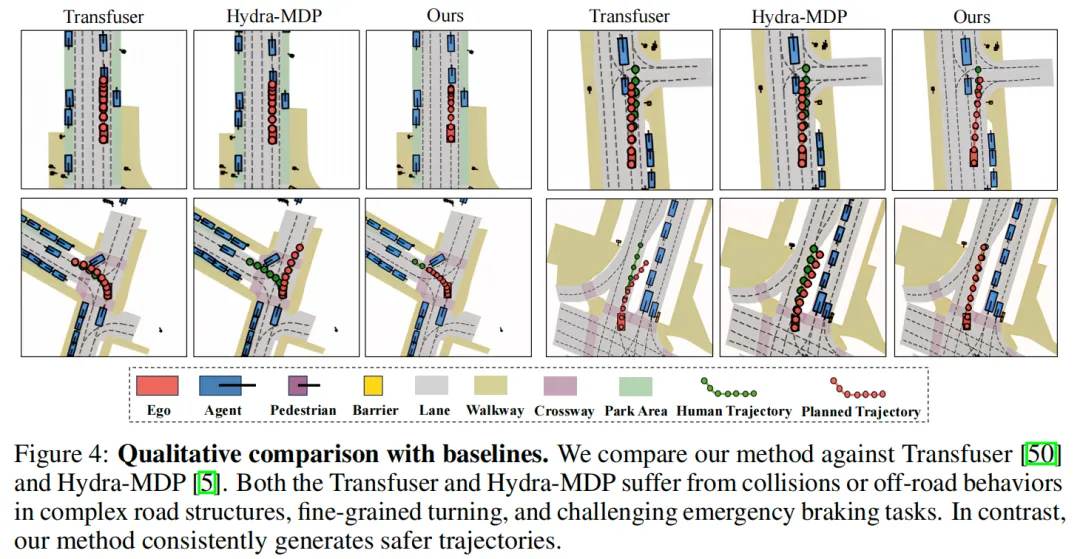
可视化:
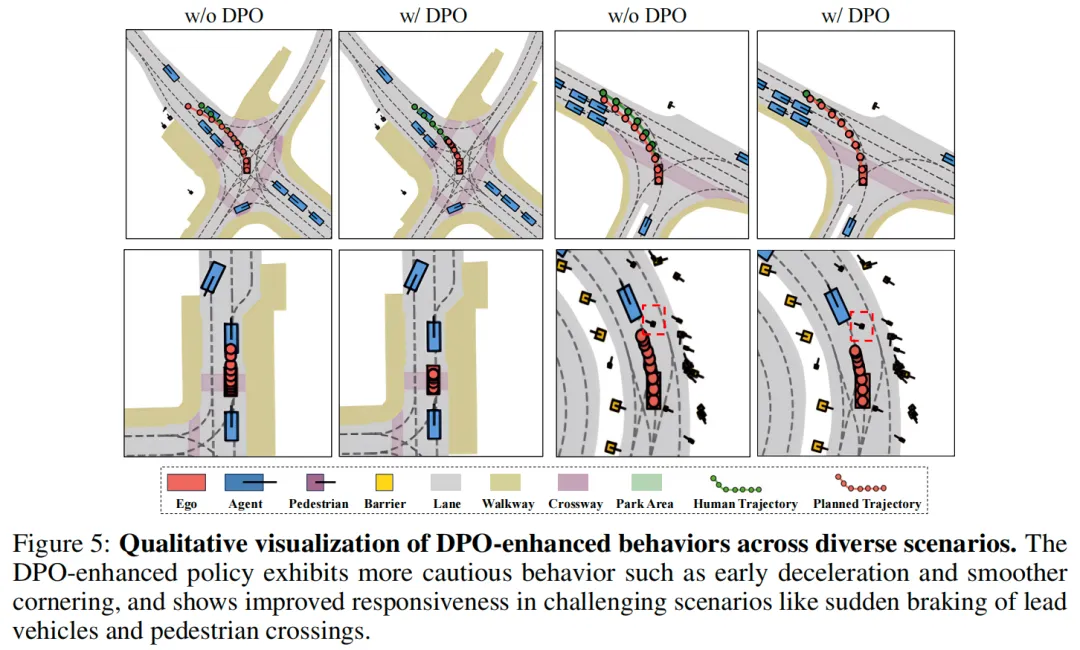
局限性与未来工作
尽管本文提出的方法在提升端到端驾驶策略的安全性方面取得了显著进展,但仍存在若干局限性,有待进一步研究。
首先,本文方法依赖PDMS指标作为安全评估的核心标准。虽然PDMS整合了多个维度的评估内容(包括避撞、可行驶区域合规性、自车进度、碰撞时间和舒适性),但它本质上仍是一种预定义的加权复合指标,无法完全捕捉复杂驾驶场景中所有潜在的风险因素。未来的研究可探索更具表达性和灵活性的轨迹评估指标,以构建更全面的安全评估机制。
其次本文的规则化监督依赖高保真仿真器提供规则驱动的评估分数。这类方法虽能发挥作用,但由仿真得出的偏好会受到规则设计和仿真器精度的固有限制;此外,高保真仿真器的获取难度较大,这在一定程度上制约了可用数据的规模与多样性。因此,未来的研究应探索不依赖感知真值标签的偏好优化方法,通过从历史轨迹数据中自动挖掘潜在偏好结构,推动弱监督甚至完全自监督安全对齐策略的发展。
结论
本文指出了端到端自动驾驶领域中模仿学习存在的关键安全挑战------此类模型往往会生成看似符合人类驾驶习惯、但实则存在安全隐患的轨迹。同时,本文还强调了现有基于分数的方法存在的局限性:这类方法将监督信号与策略学习相分离,无法实现对策略分布的直接优化。
为应对上述挑战,本文提出了DriveDPO(一种基于安全直接偏好优化的策略学习框架)。该框架通过结合统一策略蒸馏与安全DPO微调,实现了对策略分布的直接且高效的优化。在NAVSIM数据集上开展的全面实验与定性比较表明,DriveDPO显著提升了驾驶策略的安全性与合规性,证明其在安全关键型驾驶系统中具有部署潜力。
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....