文章目录
- 前言
- 一、问题背景与数据集:MNIST
- 二、常规训练流程总览
- 三、详细步骤与代码实现(PyTorch)
-
- [1. 环境准备](#1. 环境准备)
- [2. 数据准备:从原始数据到可训练格式](#2. 数据准备:从原始数据到可训练格式)
-
- [2.1 加载MNIST数据集](#2.1 加载MNIST数据集)
- [2.2 划分训练集与验证集](#2.2 划分训练集与验证集)
- [2.3 创建DataLoader(批量加载数据并进行数据增强处理)](#2.3 创建DataLoader(批量加载数据并进行数据增强处理))
- [3. 模型构建:三层全连接神经网络](#3. 模型构建:三层全连接神经网络)
- [4. 训练配置:损失函数与优化器](#4. 训练配置:损失函数与优化器)
-
- [4.1 损失函数:交叉熵(Cross Entropy)](#4.1 损失函数:交叉熵(Cross Entropy))
- [4.2 优化器:Adam](#4.2 优化器:Adam)
- [5. 训练循环:迭代优化模型](#5. 训练循环:迭代优化模型)
- [6. 模型评估:看性能到底怎么样?](#6. 模型评估:看性能到底怎么样?)
- [7. 模型预测:对新手写数字做推断](#7. 模型预测:对新手写数字做推断)
- 四、更加现代的深度学习项目规范
- 五、训练
- 六、常规训练过程的核心要点总结
- 总结
前言
很多同学对机器学习和深度学习训练的整体概念不清晰,实际上任意一个模型的训练都会经历共同的步骤。这篇文章以手写数字识别带你理解模型训练。
手写数字识别是机器学习的"Hello World" ,也是理解神经网络训练流程的最佳切入点。本文将从数据准备→模型构建→训练循环→评估预测 ,完整复现用三层全连接神经网络解决MNIST手写数字分类问题的过程。每一步都会解释"为什么这么做",并附可运行的代码示例。
一、问题背景与数据集:MNIST
MNIST是LeCun等人整理的手写数字数据集,包含:
- 6万张训练图(28×28像素灰度图,0-9数字)
- 1万张测试图
- 每张图对应一个数字标签(如"3""7")
目标:训练一个模型,输入手写数字图片,输出对应的数字(多分类问题)。
二、常规训练流程总览
无论用什么模型,机器学习的常规训练流程都是:
- 数据准备:加载、预处理、划分数据集
- 模型定义:搭建神经网络结构
- 训练配置:选择损失函数、优化器
- 训练循环:迭代优化模型权重
- 模型评估:验证性能(准确率、混淆矩阵)
- 模型预测:对新数据做推断
三、详细步骤与代码实现(PyTorch)
1. 环境准备
确保安装了PyTorch和必要库(用cpu版本即可实现,给大家准备的数据集量是微缩版的,量并不大,不需要追求卓越使用GPU哦):
2. 数据准备:从原始数据到可训练格式
2.1 加载MNIST数据集
PyTorch的torchvision.datasets.MNIST已封装好MNIST的下载与加载:
python
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 数据预处理:转Tensor + 归一化(像素值从[0,255]→[0,1]→[-1,1])
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor格式(C×H×W)
transforms.Normalize((0.1307,), (0.3081,)) # MNIST的均值和标准差
])
# 加载训练集和测试集
train_dataset = datasets.MNIST(
root='./data', # 数据存储路径
train=True, # 训练集
download=True, # 自动下载
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False, # 测试集
download=True,
transform=transform
)下载数据集这种事情,肯定得我们自己来。自动下载可能因为网络原因而下载不下来哦
MNIST数据集通常包含四个文件:
- train-images-idx3-ubyte: 训练集图像
- train-labels-idx1-ubyte: 训练集标签
- t10k-images-idx3-ubyte: 测试集图像
- t10k-images-idx1-ubyte: 测试集标签
为什么MNIST使用.ubyte格式而不是图像格式嘞?
MNIST数据集使用特殊的二进制格式,而不是常见的图像格式(如PNG、JPEG),主要原因如下:
每个MNIST文件包含:
- 魔数(Magic Number):标识文件类型
- 项目数量:图像或标签的数量
- 维度信息:图像的尺寸信息
- 数据部分:实际的像素值或标签
图像文件 (train-images-idx3-ubyte):
[偏移量] [类型] [值] [描述]
0000 32位整数 0x00000803 魔数 (2051)
0004 32位整数 60000 图像数量
0008 32位整数 28 行数
0012 32位整数 28 列数
0016 无符号字节 像素值 图像数据开始...标签文件 (train-labels-idx1-ubyte):
[偏移量] [类型] [值] [描述]
0000 32位整数 0x00000801 魔数 (2049)
0004 32位整数 60000 标签数量
0008 无符号字节 标签值 标签数据开始...| 特性 | .ubyte格式 | 图像格式 (PNG/JPG) |
|---|---|---|
| 读取速度 | ⭐⭐⭐⭐⭐ (直接二进制) | ⭐⭐ (需解码) |
| 存储效率 | ⭐⭐⭐⭐⭐ (无压缩损失) | ⭐⭐⭐ (有损/无损压缩) |
| 处理复杂度 | ⭐⭐ (需解析头文件) | ⭐⭐⭐⭐ (标准库支持) |
| 元数据 | ⭐⭐⭐⭐⭐ (内置维度信息) | ⭐⭐ (需额外文件) |
| 标准化 | ⭐⭐⭐⭐⭐ (MNIST标准) | ⭐⭐⭐ (多种格式) |
具体原因
-
性能优化
- 二进制格式直接读取,无需图像解码
- 适合大规模机器学习训练
- 内存映射支持,可处理超大数据集
-
数据完整性
- 无压缩损失,保持原始像素精度
- 固定格式,避免格式兼容性问题
-
学术传统
- MNIST自1998年发布就使用此格式
- 成为机器学习领域的标准基准
ubyte解析器
python
import struct
import numpy as np
import matplotlib.pyplot as plt
from pathlib import Path
class MNISTParser:
"""完整的MNIST .ubyte文件解析器"""
@staticmethod
def parse_images(filename):
"""
解析MNIST图像文件
返回: (数量, 高度, 宽度)的numpy数组
"""
with open(filename, 'rb') as f:
# 读取文件头
magic, num, rows, cols = struct.unpack('>IIII', f.read(16))
if magic != 2051:
raise ValueError(f'无效的图像文件魔数: {magic}')
print(f"解析图像文件: {filename}")
print(f"图像数量: {num}, 尺寸: {rows}x{cols}")
# 读取所有图像数据
buffer = f.read()
images = np.frombuffer(buffer, dtype=np.uint8)
images = images.reshape(num, rows, cols)
return images
@staticmethod
def parse_labels(filename):
"""
解析MNIST标签文件
返回: (数量,)的numpy数组
"""
with open(filename, 'rb') as f:
# 读取文件头
magic, num = struct.unpack('>II', f.read(8))
if magic != 2049:
raise ValueError(f'无效的标签文件魔数: {magic}')
print(f"解析标签文件: {filename}")
print(f"标签数量: {num}")
# 读取所有标签数据
buffer = f.read()
labels = np.frombuffer(buffer, dtype=np.uint8)
return labels
@staticmethod
def save_as_images(images, labels, output_dir, max_images=100):
"""
将.ubyte数据保存为图像文件(用于可视化)
"""
output_dir = Path(output_dir)
output_dir.mkdir(exist_ok=True)
for i in range(min(max_images, len(images))):
# 创建图像
plt.figure(figsize=(2, 2))
plt.imshow(images[i], cmap='gray')
plt.title(f'Label: {labels[i]}')
plt.axis('off')
# 保存为PNG
filename = output_dir / f'{i:05d}_label{labels[i]}.png'
plt.savefig(filename, bbox_inches='tight', pad_inches=0)
plt.close()
print(f"已保存 {min(max_images, len(images))} 张图像到 {output_dir}")
@staticmethod
def analyze_dataset(images, labels):
"""分析数据集统计信息"""
print("\n" + "="*50)
print("数据集分析报告")
print("="*50)
# 基本统计
print(f"数据集大小: {len(images)} 个样本")
print(f"图像尺寸: {images[0].shape}")
print(f"像素值范围: [{images.min()}, {images.max()}]")
# 标签分布
unique, counts = np.unique(labels, return_counts=True)
print("\n标签分布:")
for label, count in zip(unique, counts):
percentage = 100 * count / len(labels)
print(f" 数字 {label}: {count:5d} 张 ({percentage:5.1f}%)")
# 图像统计
print(f"\n图像统计:")
print(f" 平均亮度: {images.mean():.1f}")
print(f" 标准差: {images.std():.1f}")
return unique, counts
@staticmethod
def visualize_samples(images, labels, num_samples=10):
"""可视化样本数据"""
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
axes = axes.ravel()
for i in range(num_samples):
axes[i].imshow(images[i], cmap='gray')
axes[i].set_title(f'Label: {labels[i]}')
axes[i].axis('off')
plt.suptitle('MNIST手写数字样本', fontsize=16)
plt.tight_layout()
plt.show()
# 使用示例
def demonstrate_ubyte_format():
"""演示.ubyte格式的完整解析过程"""
# 假设文件路径(请根据实际情况修改)
train_images_file = './data/train-images-idx3-ubyte'
train_labels_file = './data/train-labels-idx1-ubyte'
try:
# 1. 解析文件
print("步骤1: 解析.ubyte文件")
train_images = MNISTParser.parse_images(train_images_file)
train_labels = MNISTParser.parse_labels(train_labels_file)
# 2. 数据分析
print("\n步骤2: 数据分析")
unique, counts = MNISTParser.analyze_dataset(train_images, train_labels)
# 3. 可视化样本
print("\n步骤3: 可视化样本")
MNISTParser.visualize_samples(train_images, train_labels)
# 4. 保存为图像格式(可选)
print("\n步骤4: 转换为图像格式(演示用)")
MNISTParser.save_as_images(train_images[:100], train_labels[:100],
'./mnist_images')
return train_images, train_labels
except FileNotFoundError as e:
print(f"文件未找到: {e}")
print("请确保MNIST .ubyte文件存在于指定路径")
return None, None
except Exception as e:
print(f"解析错误: {e}")
return None, None
# 运行演示
if __name__ == "__main__":
images, labels = demonstrate_ubyte_format()格式转换工具
python
class FormatConverter:
"""格式转换工具类"""
@staticmethod
def ubyte_to_numpy(images_file, labels_file):
""".ubyte转换为numpy数组"""
images = MNISTParser.parse_images(images_file)
labels = MNISTParser.parse_labels(labels_file)
return images, labels
@staticmethod
def numpy_to_ubyte(images, labels, images_file, labels_file):
"""numpy数组转换为.ubyte格式"""
# 图像文件
with open(images_file, 'wb') as f:
# 写入文件头
magic = 2051
num, rows, cols = images.shape
f.write(struct.pack('>IIII', magic, num, rows, cols))
# 写入数据
images.flatten().tofile(f)
# 标签文件
with open(labels_file, 'wb') as f:
# 写入文件头
magic = 2049
num = len(labels)
f.write(struct.pack('>II', magic, num))
# 写入数据
labels.tofile(f)
@staticmethod
def image_folder_to_ubyte(image_folder, output_prefix, image_size=(28, 28)):
"""图像文件夹转换为.ubyte格式"""
import glob
from PIL import Image
image_files = glob.glob(f"{image_folder}/*.png") + glob.glob(f"{image_folder}/*.jpg")
images = []
labels = []
for file in sorted(image_files):
# 从文件名提取标签(假设格式: 00001_5.png)
filename = Path(file).stem
try:
label = int(filename.split('_')[-1]) # 提取最后一部分作为标签
except:
label = 0 # 默认标签
# 加载并预处理图像
img = Image.open(file).convert('L') # 转灰度
img = img.resize(image_size)
img_array = np.array(img)
images.append(img_array)
labels.append(label)
images = np.array(images)
labels = np.array(labels)
# 保存为.ubyte格式
FormatConverter.numpy_to_ubyte(images, labels,
f"{output_prefix}-images-idx3-ubyte",
f"{output_prefix}-labels-idx1-ubyte")
print(f"转换完成: {len(images)} 张图像")
return images, labels本地加载数据集
python
class MNISTLoader:
"""MNIST数据加载器 - 直接从.ubyte文件加载"""
@staticmethod
def load_mnist_images(filename):
"""加载MNIST图像文件"""
with open(filename, 'rb') as f:
magic, num, rows, cols = struct.unpack(">IIII", f.read(16))
images = np.fromfile(f, dtype=np.uint8).reshape(num, rows, cols)
return images
@staticmethod
def load_mnist_labels(filename):
"""加载MNIST标签文件"""
with open(filename, 'rb') as f:
magic, num = struct.unpack(">II", f.read(8))
labels = np.fromfile(f, dtype=np.uint8)
return labels
@staticmethod
def load_dataset(data_dir='./data'):
"""加载完整的MNIST数据集"""
print("从本地文件加载MNIST数据集...")
# 训练集
train_images = MNISTLoader.load_mnist_images(os.path.join(data_dir, 'train-images-idx3-ubyte'))
train_labels = MNISTLoader.load_mnist_labels(os.path.join(data_dir, 'train-labels-idx1-ubyte'))
# 测试集
test_images = MNISTLoader.load_mnist_images(os.path.join(data_dir, 't10k-images-idx3-ubyte'))
test_labels = MNISTLoader.load_mnist_labels(os.path.join(data_dir, 't10k-labels-idx1-ubyte'))
print(f"训练集: {train_images.shape} images, {train_labels.shape} labels")
print(f"测试集: {test_images.shape} images, {test_labels.shape} labels")
return (train_images, train_labels), (test_images, test_labels)2.2 划分训练集与验证集
为了避免模型"死记硬背"训练数据(过拟合),需要从训练集中拆分出验证集(比如20%)下面给出划分数据集的示例,我准备的数据集已经给出了训练集和验证集,并不需要再单独进行划分喽,当然你也可以将给出的较大的数据集进行划分为训练集和验证集,另一个作为验证集,这样更符合规范:
python
from torch.utils.data import random_split
# 拆分训练集:80%训练,20%验证
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])2.3 创建DataLoader(批量加载数据并进行数据增强处理)
DataLoader负责将数据分成小批量(batch)加载,加速训练:
python
def setup_data(self, data_dir='./data', batch_size=64, val_ratio=0.2):
"""设置训练数据"""
print("正在加载数据集...")
if not os.path.exists(data_dir):
raise FileNotFoundError(f"数据目录不存在: {data_dir}")
# 检查必要文件
required_files = ['train-images-idx3-ubyte', 'train-labels-idx1-ubyte',
't10k-images-idx3-ubyte', 't10k-labels-idx1-ubyte']
for f in required_files:
if not os.path.exists(os.path.join(data_dir, f)):
raise FileNotFoundError(f"缺少文件: {f}")
# 加载数据
(train_img, train_lbl), (test_img, test_lbl) = MNISTLoader.load_dataset(data_dir)
# 数据预处理
def preprocess(images, labels):
images = images.astype(np.float32) / 255.0
images = np.expand_dims(images, 1) # 添加通道维度
return torch.from_numpy(images), torch.from_numpy(labels).long()
train_X, train_y = preprocess(train_img, train_lbl)
test_X, test_y = preprocess(test_img, test_lbl)
# 创建数据集
train_dataset = TensorDataset(train_X, train_y)
test_dataset = TensorDataset(test_X, test_y)
# 分割训练集和验证集
val_size = int(val_ratio * len(train_dataset))
train_size = len(train_dataset) - val_size
train_subset, val_subset = random_split(train_dataset, [train_size, val_size])
# 创建数据加载器
self.train_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True)
self.val_loader = DataLoader(val_subset, batch_size=batch_size, shuffle=False)
self.test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
print(f"数据集加载完成:")
print(f" 训练集: {train_size} 样本")
print(f" 验证集: {val_size} 样本")
print(f" 测试集: {len(test_dataset)} 样本")
return train_size, val_size, len(test_dataset)3. 模型构建:三层全连接神经网络
我们定义一个输入层→隐藏层→输出层的三层网络:
输入(1×28×28) → 卷积层1 → 池化 → 卷积层2 → 池化 → 全连接层1 → 全连接层2 → 输出输入层
- 输入是28×28的灰度图像(1个通道)
- 批量大小:
x.size(0)
第一次卷积操作
python
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
x = self.relu(self.conv1(x)) # 输出: (batch, 32, 28, 28)- 输入:1通道 → 输出:32个特征图
- 尺寸变化:28×28 → 28×28(padding=1保持尺寸)
第一次池化
python
x = self.pool(x) # 输出: (batch, 32, 14, 14)- 最大池化,2×2窗口,步长2
- 尺寸减半:28×28 → 14×14
第二次卷积操作
python
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
x = self.relu(self.conv2(x)) # 输出: (batch, 64, 14, 14)- 输入:32通道 → 输出:64个特征图
- 尺寸保持不变(padding=1)
第二次池化
python
x = self.pool(x) # 输出: (batch, 64, 7, 7)- 尺寸再次减半:14×14 → 7×7
展平操作
python
x = x.view(x.size(0), -1) # 输出: (batch, 64×7×7=3136)- 将三维特征图展平为一维向量
全连接层1
python
self.fc1 = nn.Linear(64 * 7 * 7, 128)
x = self.relu(self.fc1(x)) # 输出: (batch, 128)- 3136维 → 128维特征向量
全连接层2(输出层)
python
self.fc2 = nn.Linear(128, num_classes) # 输出: (batch, num_classes)- 128维 → num_classes维(分类得分)
Dropout正则化
python
self.dropout1 = nn.Dropout(0.25) # 25%神经元随机失活
self.dropout2 = nn.Dropout(0.5) # 50%神经元随机失活- 防止过拟合,提高泛化能力
- 第一个Dropout在特征展平后,第二个在全连接层后
ReLU激活函数
python
self.relu = nn.ReLU()- 公式: f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x)
- 解决梯度消失问题,加速收敛
python
class CNN(nn.Module):
"""卷积神经网络模型"""
def __init__(self, num_classes=10):
super(CNN, self).__init__()
# 第一次卷积:输入通道1(灰度图)→输出通道32,卷积核3×3,边缘填充1像素
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
# 第二次卷积:32通道→64通道,同样3×3核+填充
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
# 最大池化:2×2窗口,步长2,宽高减半
self.pool = nn.MaxPool2d(2, 2)
# Dropout层:训练时随机"丢弃"部分神经元,防止过拟合
self.dropout1 = nn.Dropout(0.25) # 第一个丢弃率25%
self.dropout2 = nn.Dropout(0.5) # 第二个丢弃率50%
# 全连接层:将卷积特征展平后映射到128维向量
# 64通道×7×7像素 = 3136输入特征
self.fc1 = nn.Linear(64 * 7 * 7, 128)
# 输出层:128维→num_classes维(默认10类)
self.fc2 = nn.Linear(128, num_classes)
# ReLU激活函数:负数置0,保持非线性
self.relu = nn.ReLU()
def forward(self, x):
# 卷积层1:28×28→28×28(填充保持尺寸)
x = self.relu(self.conv1(x))
# 池化:28×28→14×14
x = self.pool(x)
# 卷积层2:14×14→14×14
x = self.relu(self.conv2(x))
# 池化:14×14→7×7
x = self.pool(x)
# 展平:把(batch, 64, 7, 7)拉成(batch, 3136)
x = x.view(x.size(0), -1)
# 全连接阶段
x = self.dropout1(x) # 随机丢弃25%
x = self.relu(self.fc1(x)) # 全连接+ReLU
x = self.dropout2(x) # 再丢弃50%
x = self.fc2(x) # 输出logits(无softmax)
return x4. 训练配置:损失函数与优化器
4.1 损失函数:交叉熵(Cross Entropy)
多分类问题的经典损失函数,衡量模型输出概率与真实标签的差异:
python
criterion = nn.CrossEntropyLoss() # 包含Softmax,无需手动加4.2 优化器:Adam
Adam是自适应学习率的优化器,比SGD更稳定,收敛更快:
python
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # lr是学习率5. 训练循环:迭代优化模型
训练的核心是**"前向传播→计算损失→反向传播→更新权重"**,重复这个过程直到模型收敛:
python
num_epochs = 10 # 训练10轮(遍历整个训练集10次)
for epoch in range(num_epochs):
# ------------------- 训练阶段 -------------------
model.train() # 开启训练模式(如Dropout生效,这里没用Dropout可忽略)
train_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
# 前向传播:输入数据→模型输出
output = model(data)
# 计算损失:输出与真实标签的差异
loss = criterion(output, target)
# 反向传播:计算梯度
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 计算当前梯度
optimizer.step() # 更新模型权重
# 累计损失
train_loss += loss.item()
# 每100批打印一次进度
if batch_idx % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Batch [{batch_idx}/{len(train_loader)}], Loss: {loss.item():.4f}')
# 计算平均训练损失
avg_train_loss = train_loss / len(train_loader)
# ------------------- 验证阶段 -------------------
model.eval() # 开启评估模式(关闭Dropout等)
val_correct = 0
val_total = 0
with torch.no_grad(): # 不计算梯度,节省内存
for data, target in val_loader:
output = model(data)
# 预测类别:取输出概率最大的那个
_, predicted = torch.max(output.data, 1)
val_total += target.size(0)
val_correct += (predicted == target).sum().item()
# 计算验证准确率
val_acc = 100 * val_correct / val_total
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {avg_train_loss:.4f}, Val Acc: {val_acc:.2f}%')关键解释:
model.train()/model.eval():切换模型的训练/评估模式(如Dropout层在训练时随机失活神经元,评估时关闭)。torch.no_grad():关闭梯度计算,减少内存消耗,加速验证。torch.max(output.data, 1):取输出层的最大值及其索引(索引对应数字类别)。
6. 模型评估:看性能到底怎么样?
训练完成后,我们需要用测试集评估模型的泛化能力(对未见过的数据的表现):
python
def evaluate(model, test_loader):
model.eval()
test_correct = 0
test_total = 0
all_preds = []
all_targets = []
with torch.no_grad():
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1)
test_total += target.size(0)
test_correct += (predicted == target).sum().item()
# 保存预测和真实标签,用于混淆矩阵
all_preds.extend(predicted.cpu().numpy())
all_targets.extend(target.cpu().numpy())
# 计算准确率
test_acc = 100 * test_correct / test_total
print(f'Test Accuracy: {test_acc:.2f}%')
# 绘制混淆矩阵(可选,需安装seaborn)
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(all_targets, all_preds)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
# 调用评估函数
evaluate(model, test_loader)结果解读:
- 测试准确率通常能达到97%以上(三层网络的极限)。
- 混淆矩阵中,对角线越深表示该数字的分类越准确;非对角线越深表示容易混淆的数字(比如"4"和"9"、"7"和"1")。
7. 模型预测:对新手写数字做推断
训练好的模型可以用来预测新的手写数字图片。假设我们有一张手写的"5":
python
from PIL import Image
def predict_image(model, image_path):
# 加载图片并预处理
image = Image.open(image_path).convert('L') # 转灰度图
image = transform(image) # 应用之前的预处理(ToTensor + Normalize)
image = image.unsqueeze(0)
# 前向传播
output = model(image)
# 预测类别
_, predicted = torch.max(output.data, 1)
print(f'Predicted Digit: {predicted.item()}')
# 使用示例:预测图片中的数字
predict_image(model, 'handwritten_5.png')四、更加现代的深度学习项目规范
现在我们已经完成了几乎所有代码的实现,但是在现代深度学习项目中,往往是多人同时进行代码的实现,我们不能将所有的实现代码全部放在同一个文件中,而是分不同的工具和模块使用脚本工具进行调用。
data 文件夹:存放我们的训练数据
dataloader 文件夹:存放我们读取数据集的工具
python
"""
基础数据加载器boase_loader.py,机器学习正常的数据加载过程,我们会用设计的mnist数据加载进行重载
"""
import os
from abc import ABC, abstractmethod
from typing import Tuple, Any
import numpy as np
class BaseDataLoader(ABC):
"""抽象基础数据加载器"""
@abstractmethod
def load_dataset(self, data_dir: str) -> Tuple[Any, Any]:
"""加载数据集"""
pass
@abstractmethod
def preprocess_data(self, data: Any) -> Any:
"""预处理数据"""
pass
def validate_data_dir(self, data_dir: str, required_files: list) -> bool:
"""验证数据目录"""
if not os.path.exists(data_dir):
raise FileNotFoundError(f"数据目录不存在: {data_dir}")
for file in required_files:
if not os.path.exists(os.path.join(data_dir, file)):
raise FileNotFoundError(f"缺少文件: {file}")
return True
python
#真正实现
class MNISTLoader(BaseDataLoader):
"""MNIST数据加载器"""
@staticmethod
def load_dataset(data_dir: str) -> Tuple[Tuple[np.ndarray, np.ndarray],
Tuple[np.ndarray, np.ndarray]]:
"""加载MNIST数据集"""
required_files = [
'train-images-idx3-ubyte', 'train-labels-idx1-ubyte',
't10k-images-idx3-ubyte', 't10k-labels-idx1-ubyte'
]
# 验证文件存在性(简化版,实际需要完整实现)
for f in required_files:
if not os.path.exists(os.path.join(data_dir, f)):
raise FileNotFoundError(f"缺少文件: {f}")
# 这里应该是实际的MNIST文件解析代码
# 简化实现,假设文件已正确解析
def load_mnist_images(filename):
with open(filename, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
return data.reshape(-1, 28, 28)
def load_mnist_labels(filename):
with open(filename, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=8)
return data
train_images = load_mnist_images(os.path.join(data_dir, 'train-images-idx3-ubyte'))
train_labels = load_mnist_labels(os.path.join(data_dir, 'train-labels-idx1-ubyte'))
test_images = load_mnist_images(os.path.join(data_dir, 't10k-images-idx3-ubyte'))
test_labels = load_mnist_labels(os.path.join(data_dir, 't10k-labels-idx1-ubyte'))
return (train_images, train_labels), (test_images, test_labels)
@staticmethod
def create_data_loaders(data_dir: str, batch_size: int = 64,
val_ratio: float = 0.2, num_workers: int = 4
) -> Tuple[DataLoader, DataLoader, DataLoader]:
"""创建数据加载器"""
# 加载数据
(train_img, train_lbl), (test_img, test_lbl) = MNISTLoader.load_dataset(data_dir)
# 预处理
def preprocess(images, labels):
images = images.astype(np.float32) / 255.0
images = np.expand_dims(images, 1) # 添加通道维度
return torch.from_numpy(images), torch.from_numpy(labels).long()
train_X, train_y = preprocess(train_img, train_lbl)
test_X, test_y = preprocess(test_img, test_lbl)
# 创建数据集
train_dataset = TensorDataset(train_X, train_y)
test_dataset = TensorDataset(test_X, test_y)
# 分割验证集
val_size = int(val_ratio * len(train_dataset))
train_size = len(train_dataset) - val_size
train_subset, val_subset = random_split(train_dataset, [train_size, val_size])
# 创建数据加载器
train_loader = DataLoader(train_subset, batch_size=batch_size,
shuffle=True, num_workers=num_workers)
val_loader = DataLoader(val_subset, batch_size=batch_size,
shuffle=False, num_workers=num_workers)
test_loader = DataLoader(test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers)
print(f"数据加载完成:")
print(f" 训练集: {train_size} 样本")
print(f" 验证集: {val_size} 样本")
print(f" 测试集: {len(test_dataset)} 样本")
return train_loader, val_loader, test_loadermodels 文件夹:存放我们设计的网络,如果你不想使用cnn也可以使用其他网络。这种模块化方式可以快速进行网络的替换实现
results 文件夹:存放我们的训练结果和保存权重
utils 文件夹:存放我们的训练
工具帮助我们更好观察训练过程,如日志文件,保存权重等一些列辅助训练工具
python
#config.py保存我们的训练配置,有些大型项目会单独设置一个config类的文件专门存放配置文件yaml,这样可以实现快速选择优化器设备配置等
class TrainingConfig:
"""训练配置数据类"""
# 数据配置
data_dir: str = './data'
batch_size: int = 128
val_ratio: float = 0.2
num_workers: int = 4
# 模型配置
num_classes: int = 10
model_type: str = 'CNN'
# 训练配置
epochs: int = 15
learning_rate: float = 0.001
weight_decay: float = 0.0
momentum: float = 0.9
# 优化器配置
optimizer: str = 'Adam'
scheduler: str = 'StepLR'
scheduler_step_size: int = 5
scheduler_gamma: float = 0.7
# 设备配置
device: str = 'auto'
# 结果保存配置
results_base_dir: str = 'results'
save_interval: int = 5
def to_dict(self) -> Dict[str, Any]:
"""转换为字典"""
return asdict(self)
def save(self, filepath: str):
"""保存配置到JSON文件"""
config_dict = self.to_dict()
config_dict['save_time'] = datetime.now().isoformat()
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(config_dict, f, indent=2, ensure_ascii=False)
@classmethod
def load(cls, filepath: str) -> 'TrainingConfig':
"""从JSON文件加载配置"""
with open(filepath, 'r', encoding='utf-8') as f:
config_dict = json.load(f)
# 移除时间戳等元数据
config_dict = {k: v for k, v in config_dict.items()
if not k.endswith('_time') and k != 'save_time'}
return cls(**config_dict)
def setup_device(device_preference='auto'):
"""
设置训练设备
Args:
device_preference: 设备偏好 ('auto', 'cuda', 'cpu')
Returns:
torch.device: 训练设备
"""
if device_preference == 'auto':
if torch.cuda.is_available():
device = torch.device('cuda')
print(f"✅ 使用GPU: {torch.cuda.get_device_name()}")
else:
device = torch.device('cpu')
print("⚠️ CUDA不可用,使用CPU")
else:
device = torch.device(device_preference)
print(f"使用设备: {device}")
return device
python
#日志文件设置,非常关键,是我们得到可视化训练过程的关键
class ResultLogger:
"""训练结果日志记录器"""
def __init__(self, base_dir='results'):
self.base_dir = base_dir
self.run_dir = None
self.start_time = None
def create_run_directory(self, run_name: Optional[str] = None):
"""创建按时间戳命名的运行目录"""
os.makedirs(self.base_dir, exist_ok=True)
if run_name is None:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
run_name = f"training_{timestamp}"
self.run_dir = os.path.join(self.base_dir, run_name)
# 创建子目录结构
subdirs = ['models', 'plots', 'configs', 'logs', 'checkpoints']
for subdir in subdirs:
os.makedirs(os.path.join(self.run_dir, subdir), exist_ok=True)
self.start_time = datetime.now()
print(f"✅ 创建结果目录: {self.run_dir}")
return self.run_dir
def save_config(self, config: Dict[str, Any], filename='training_config.json'):
"""保存训练配置"""
if self.run_dir is None:
raise ValueError("请先创建运行目录")
config_file = os.path.join(self.run_dir, 'configs', filename)
config_data = config.copy()
config_data['start_time'] = self.start_time.isoformat()
with open(config_file, 'w', encoding='utf-8') as f:
json.dump(config_data, f, indent=2, ensure_ascii=False)
print(f"✅ 训练配置已保存: {config_file}")
return config_file
def save_model(self, model_state, filename: str, is_best: bool = False):
"""保存模型权重"""
if self.run_dir is None:
raise ValueError("请先创建运行目录")
model_path = os.path.join(self.run_dir, 'models', filename)
torch.save(model_state, model_path)
if is_best:
best_path = os.path.join(self.run_dir, 'models', 'best_model.pth')
shutil.copy2(model_path, best_path)
print(f"✅ 最佳模型已保存: {best_path}")
print(f"✅ 模型已保存: {model_path}")
return model_path
def save_plot(self, fig, filename: str, dpi=300, bbox_inches='tight'):
"""保存图表"""
if self.run_dir is None:
raise ValueError("请先创建运行目录")
plot_path = os.path.join(self.run_dir, 'plots', filename)
fig.savefig(plot_path, dpi=dpi, bbox_inches=bbox_inches)
plt.close(fig)
print(f"✅ 图表已保存: {plot_path}")
return plot_path
def save_training_log(self, history: Dict[str, Any], filename='training_log.json'):
"""保存训练日志为JSON"""
if self.run_dir is None:
raise ValueError("请先创建运行目录")
log_file = os.path.join(self.run_dir, 'logs', filename)
log_data = {
'start_time': self.start_time.isoformat(),
'end_time': datetime.now().isoformat(),
'total_duration': (datetime.now() - self.start_time).total_seconds(),
'training_history': history
}
with open(log_file, 'w', encoding='utf-8') as f:
json.dump(log_data, f, indent=2, ensure_ascii=False)
print(f"✅ 训练日志已保存: {log_file}")
return log_file
def save_text_report(self, content: str, filename: str):
"""保存文本报告"""
if self.run_dir is None:
raise ValueError("请先创建运行目录")
report_file = os.path.join(self.run_dir, 'logs', filename)
with open(report_file, 'w', encoding='utf-8') as f:
f.write(content)
print(f"✅ 文本报告已保存: {report_file}")
return report_file
def setup_chinese_font():
"""设置中文字体"""
font_candidates = [
'SimHei', 'Microsoft YaHei', 'Noto Sans CJK SC',
'WenQuanYi Micro Hei', 'PingFang SC', 'Arial Unicode MS',
'DejaVu Sans'
]
for font_name in font_candidates:
if any(font_name in f.name for f in fm.fontManager.ttflist):
plt.rcParams['font.sans-serif'] = [font_name]
plt.rcParams['axes.unicode_minus'] = False
print(f"已设置中文字体:{font_name}")
return font_name
print("警告:未找到中文字体,使用默认")
return None
python
#训练辅助工具
class ModelBuilder:
"""模型构建器"""
@staticmethod
def build_model(model_type: str, num_classes: int = 10, device: str = 'cpu') -> nn.Module:
"""构建模型"""
device = torch.device(device)
if model_type.lower() == 'cnn':
model = CNN(num_classes=num_classes)
else:
raise ValueError(f"不支持的模型类型: {model_type}")
model = model.to(device)
# 计算参数数量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"模型参数统计:")
print(f" 总参数: {total_params:,}")
print(f" 可训练参数: {trainable_params:,}")
return model
@staticmethod
def setup_optimizer(model: nn.Module, optimizer_type: str = 'Adam',
lr: float = 0.001, weight_decay: float = 0.0) -> optim.Optimizer:
"""设置优化器"""
if optimizer_type.lower() == 'adam':
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
elif optimizer_type.lower() == 'sgd':
optimizer = optim.SGD(model.parameters(), lr=lr, weight_decay=weight_decay)
else:
raise ValueError(f"不支持的优化器: {optimizer_type}")
return optimizer
@staticmethod
def setup_scheduler(optimizer: optim.Optimizer, scheduler_type: str = 'StepLR',
step_size: int = 5, gamma: float = 0.7) -> optim.lr_scheduler._LRScheduler:
"""设置学习率调度器"""
if scheduler_type.lower() == 'steplr':
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma)
elif scheduler_type.lower() == 'reduceonplateau':
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=5, factor=0.5)
else:
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma)
return scheduler
class TrainingMetrics:
"""训练指标计算器"""
def __init__(self):
self.reset()
def reset(self):
"""重置指标"""
self.loss = 0.0
self.correct = 0
self.total = 0
self.batch_count = 0
def update(self, loss: float, outputs: torch.Tensor, labels: torch.Tensor):
"""更新指标"""
self.loss += loss
self.batch_count += 1
_, predicted = outputs.max(1)
self.total += labels.size(0)
self.correct += predicted.eq(labels).sum().item()
def get_metrics(self) -> Dict[str, float]:
"""获取当前指标"""
if self.batch_count == 0:
return {'loss': 0.0, 'accuracy': 0.0}
avg_loss = self.loss / self.batch_count
accuracy = 100. * self.correct / self.total if self.total > 0 else 0.0
return {
'loss': avg_loss,
'accuracy': accuracy,
'correct': self.correct,
'total': self.total
}utils工具特别多就不一一列举了,大家慢慢理解。这些都是为了帮助我们更好的完成训练都东西。
这里可以优化的地方有很多。
比如可以单独设置损失函数,激活函数等脚本,比如训练监视器脚本等,在大型项目中都是可以找到的。
test.py 测试脚本,或者叫预测脚本等等,有些项目用predict.py命名,目的是使用已经训练好的模型对测试集进行验证。有些训练脚本中往往也集成着检测函数。
train.py 训练脚本,我们真正使用的训练代码。在大多数模块已经存放到其他文件时,我们的训练脚本关注的是机器学习中正常的训练抽象过程,通过调用我们自己写的各种模型实现自己模型的训练实现
有些项目还会单独有一个使用验证集验证模型的val.py,用于对模型进行测评
同样的一个好的项目要尽量让大家简单进行复现,还会有类似的.md说明文件帮助大家复现项目等等。
五、训练
直接运行训练代码就可实现运行,训练前会打印你使用的训练设备、数据集信息、进度条等等(学有余力的同学可以进一步去优化代码,学长能力有限)
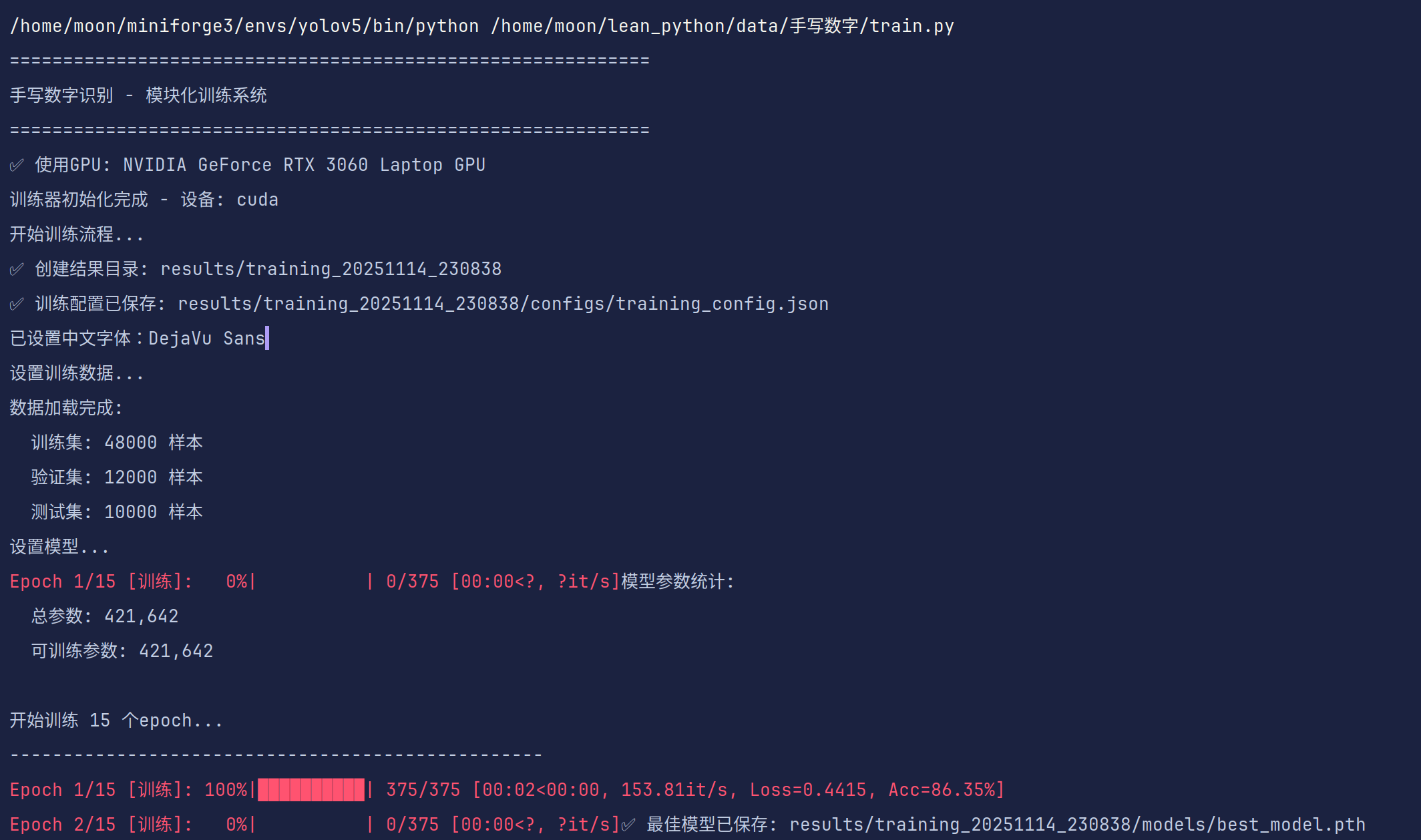
每一轮训练会加载损失函数值和准确度,并保存最佳模型(可以优化为每次训练完对当前模型进行测评并与最优模型进行比较,只保留最近训练的模型和最好的模型,这样就不会产生大量的模型文件,试着改进一下吧)
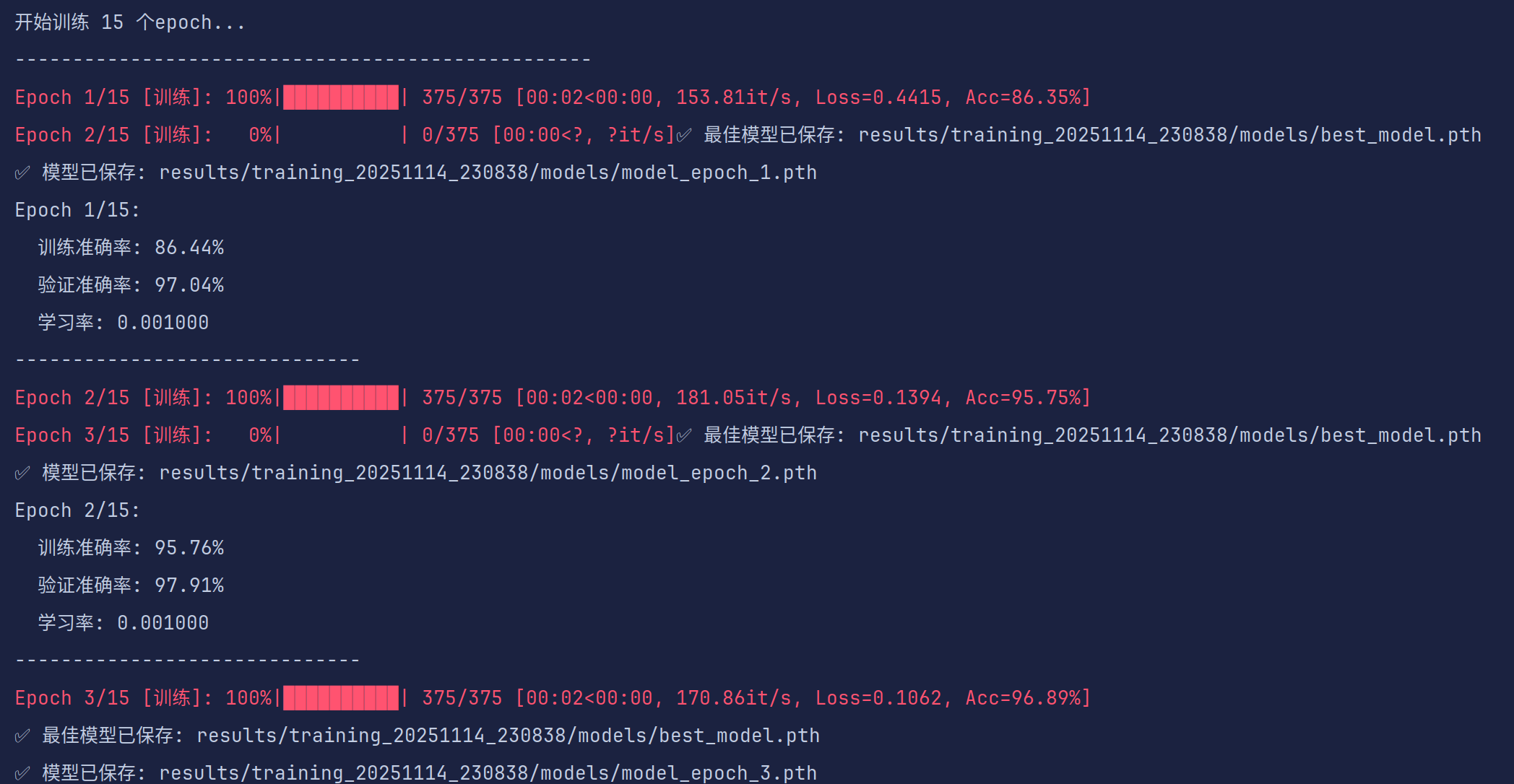
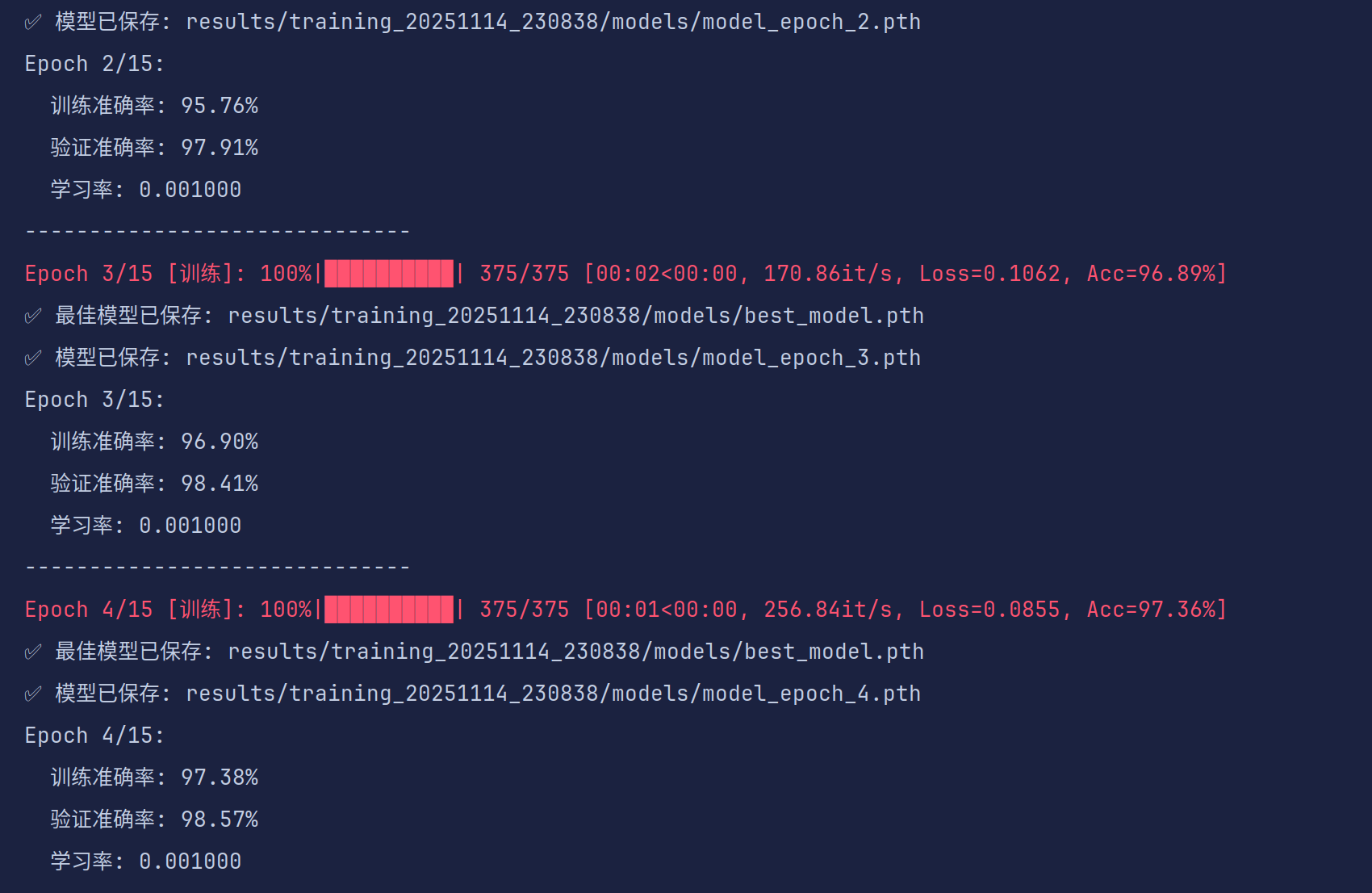
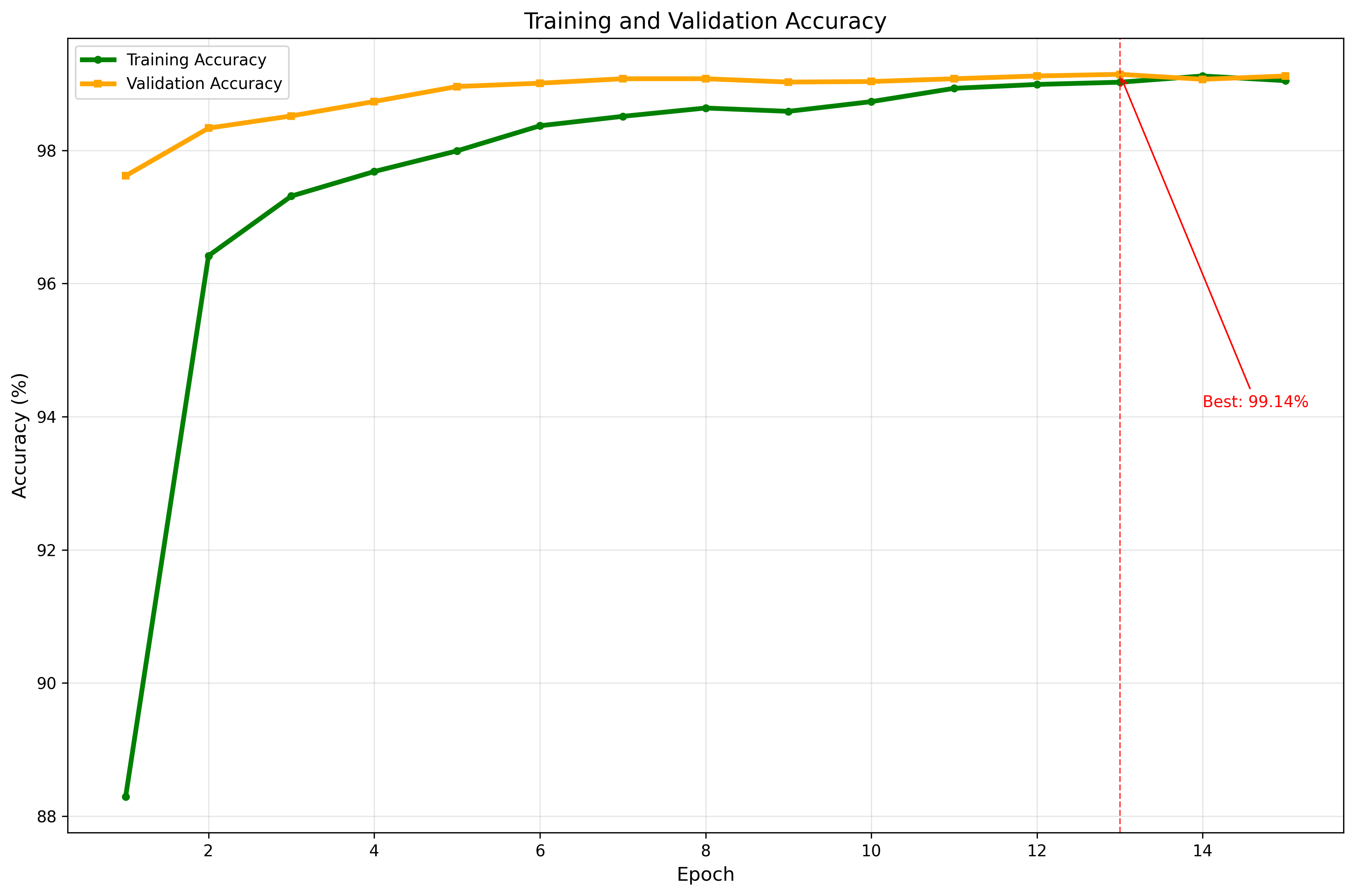
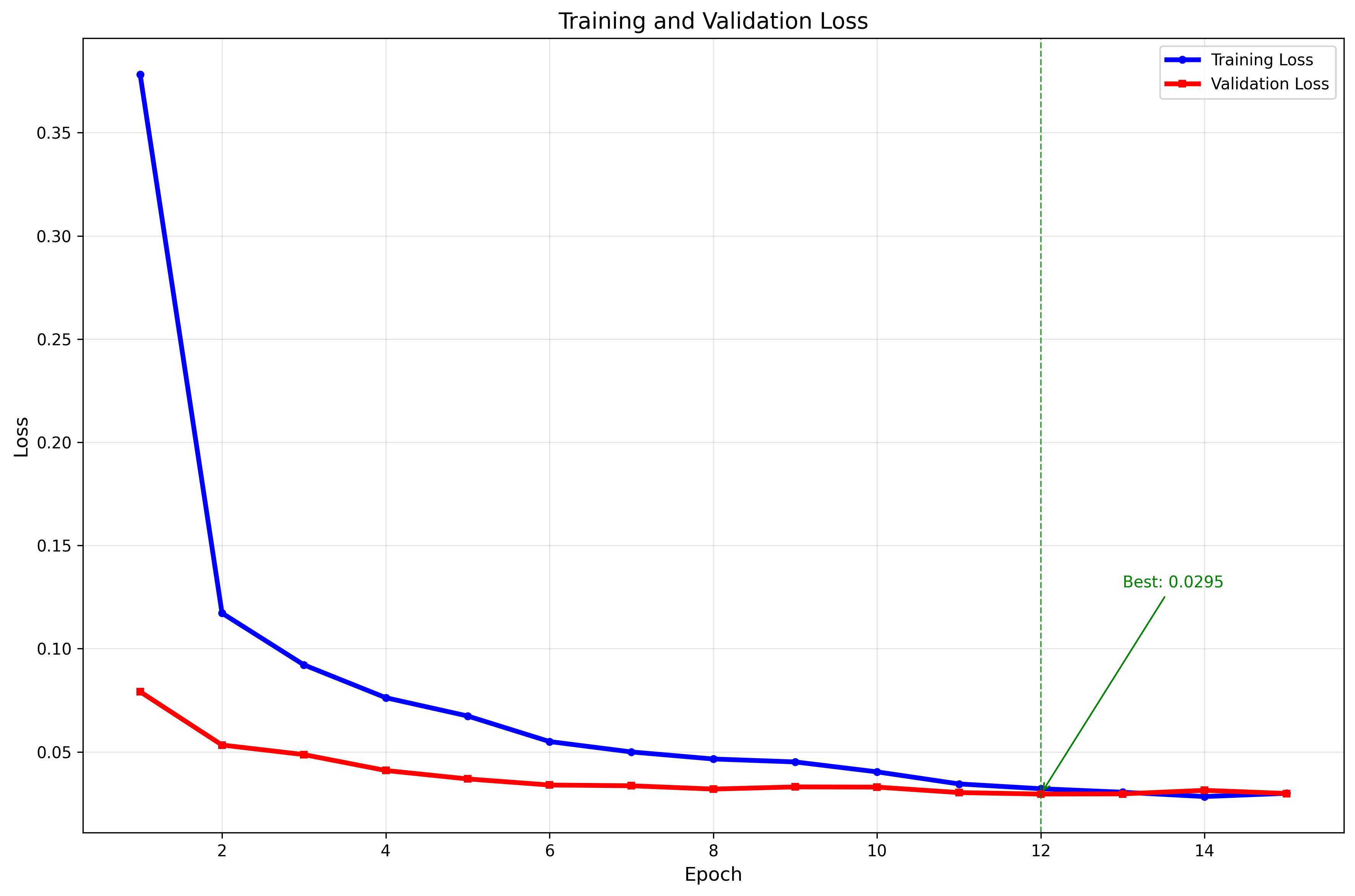
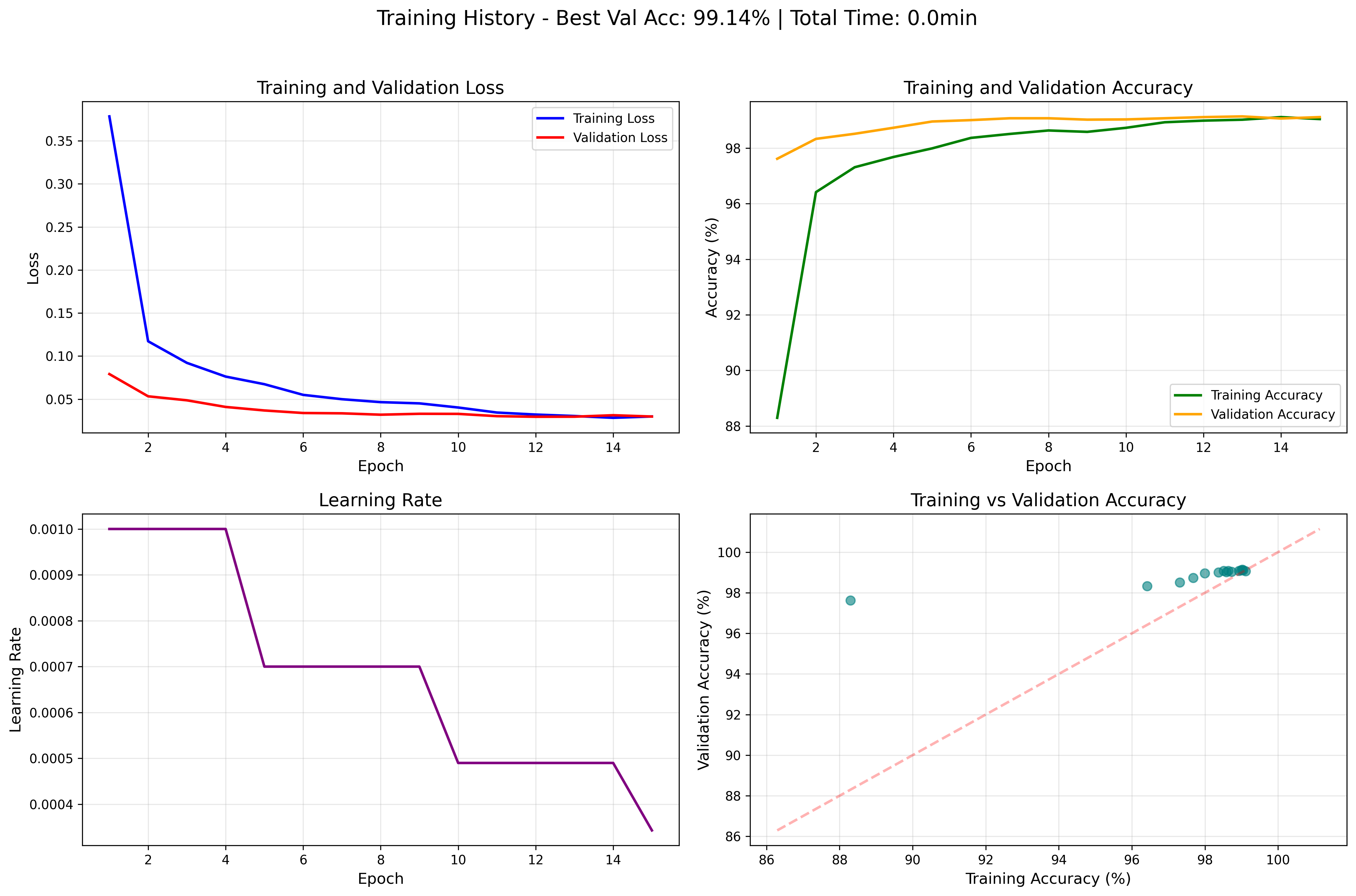
训练开始时会在results文件夹下创建当前训练时间命名的文件,训练结束后会保存相关模型和log已经各种评价指标可视化。
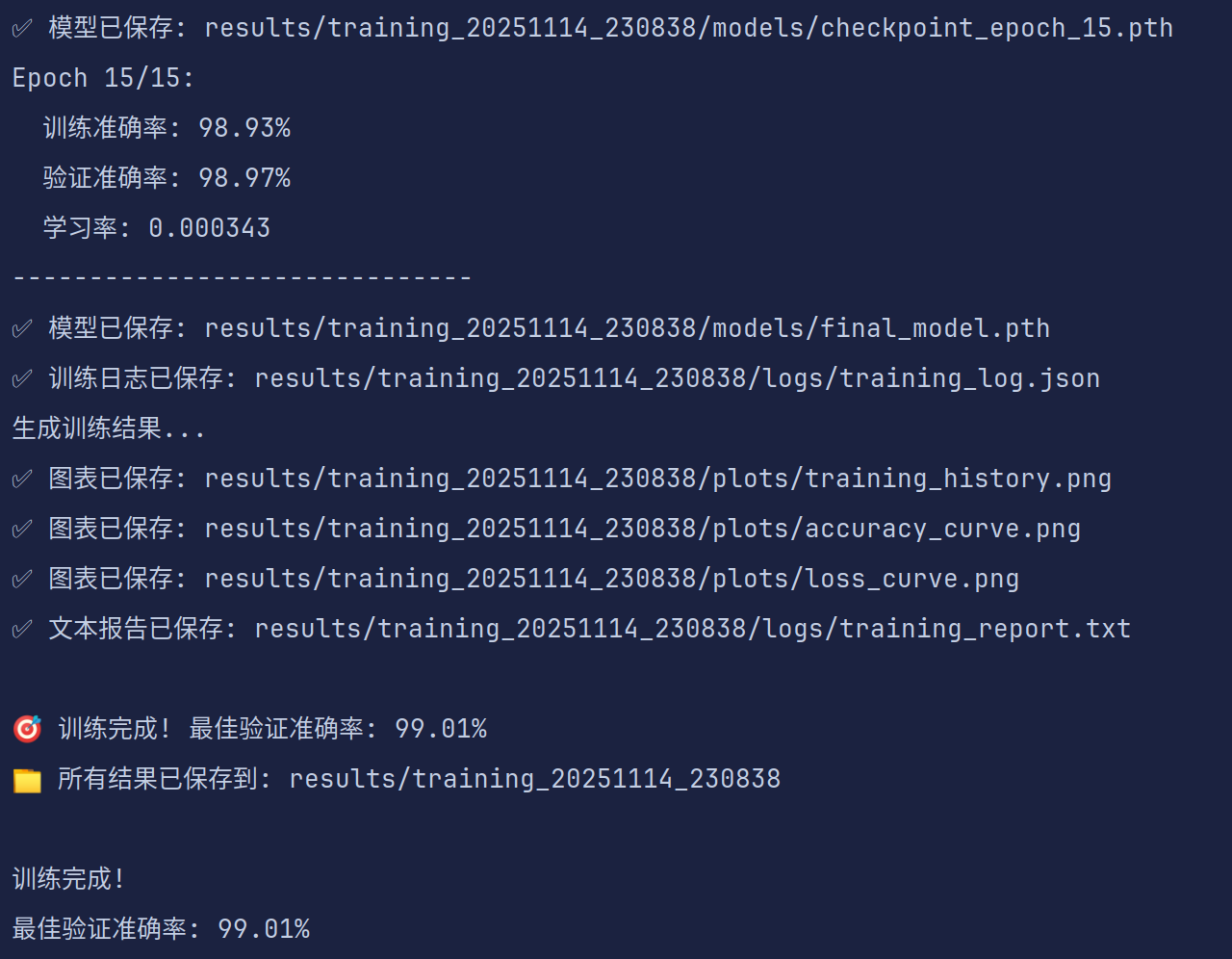
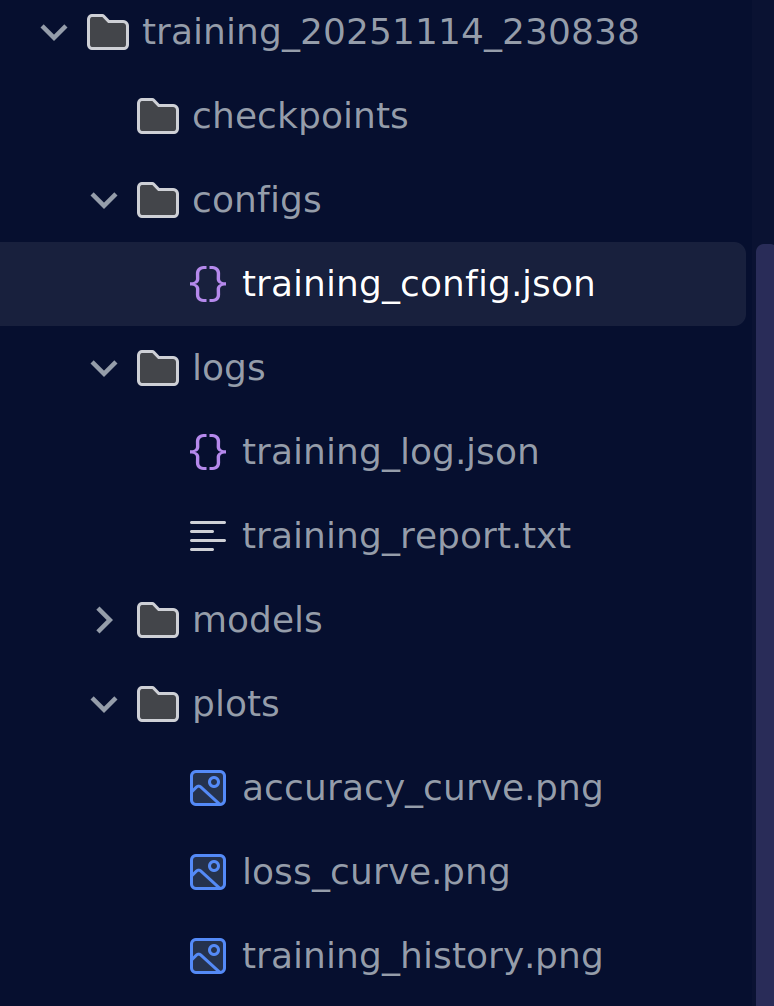
config.json存放训练配置参数
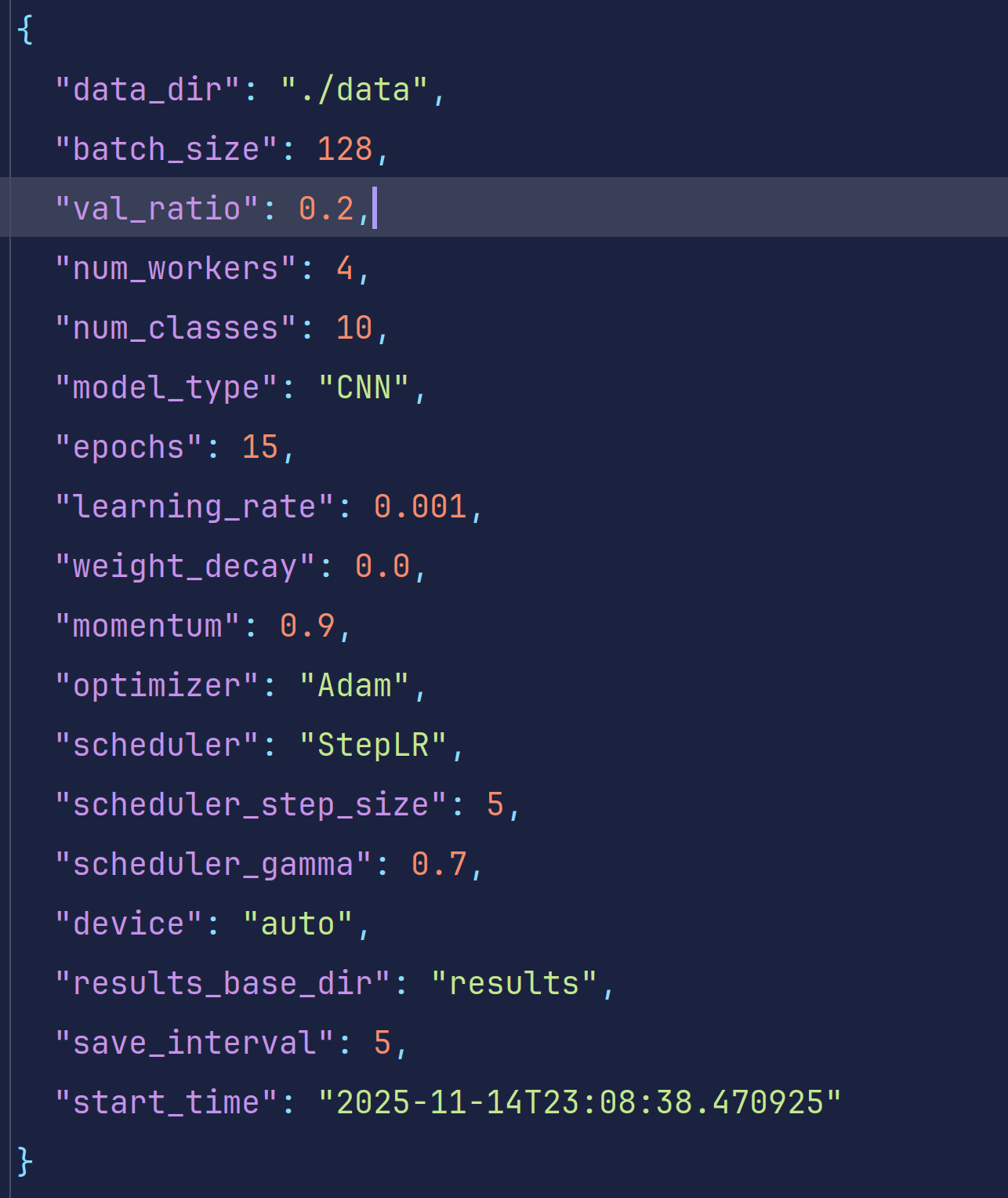
log 文件夹存放着训练日志和训练关键结果参数
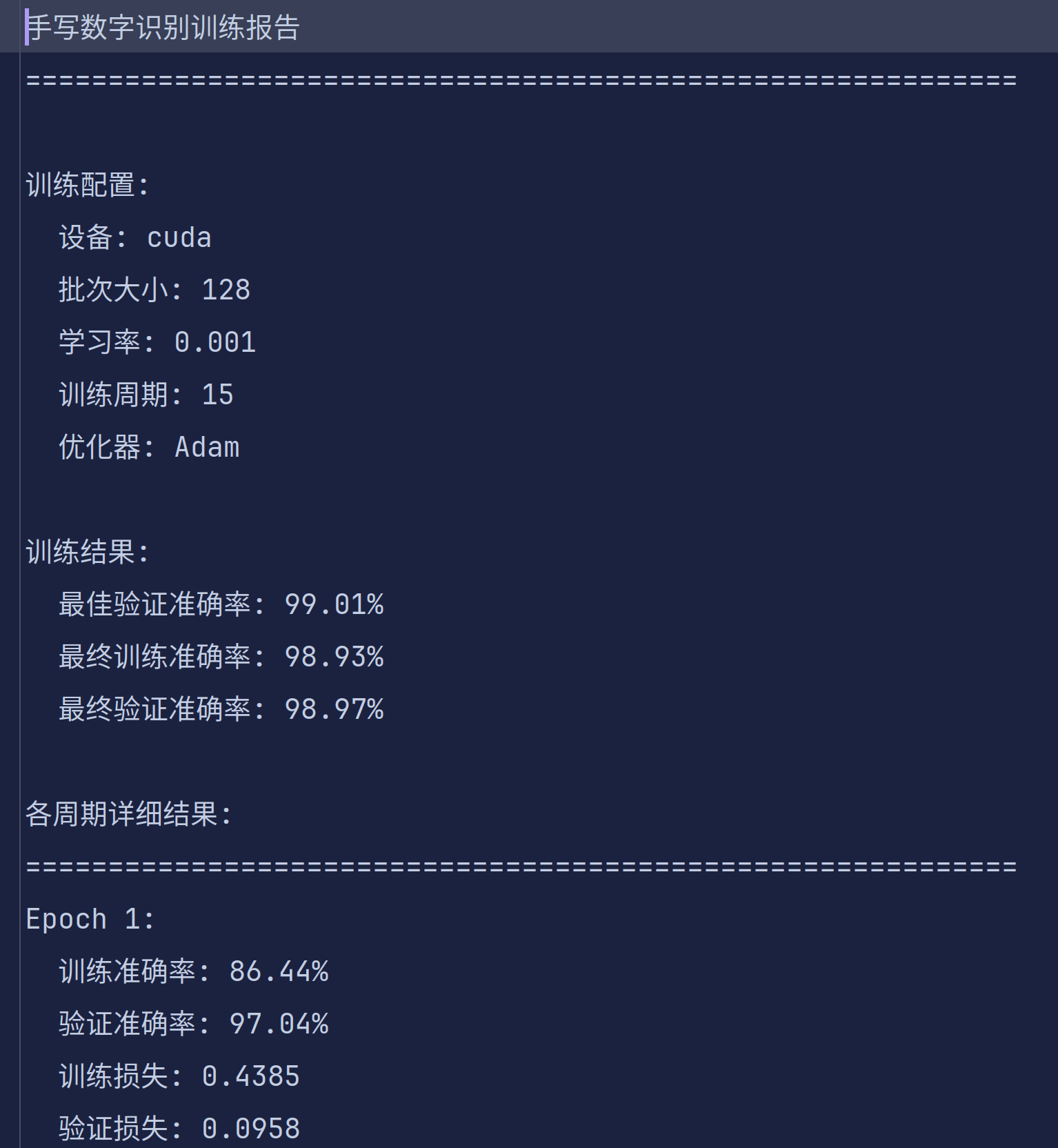
models 文件夹存放训练保存的模型
plots 存放着各种可视化结果,loss曲线,准确度曲线等等(学有余力的同学可以添加更多的评价指标可视化结果并解决一下文字可视化,我懒得搞了)
test.py 用法
自动检测输入类型:单张图片、文件夹路径或随机样本测试
模式1:单张图像测试
python test.py --model_path model.pth --input_path my_digit.png
模式2:文件夹批量测试
python test.py --model_path model.pth --input_path my_digits_folder/
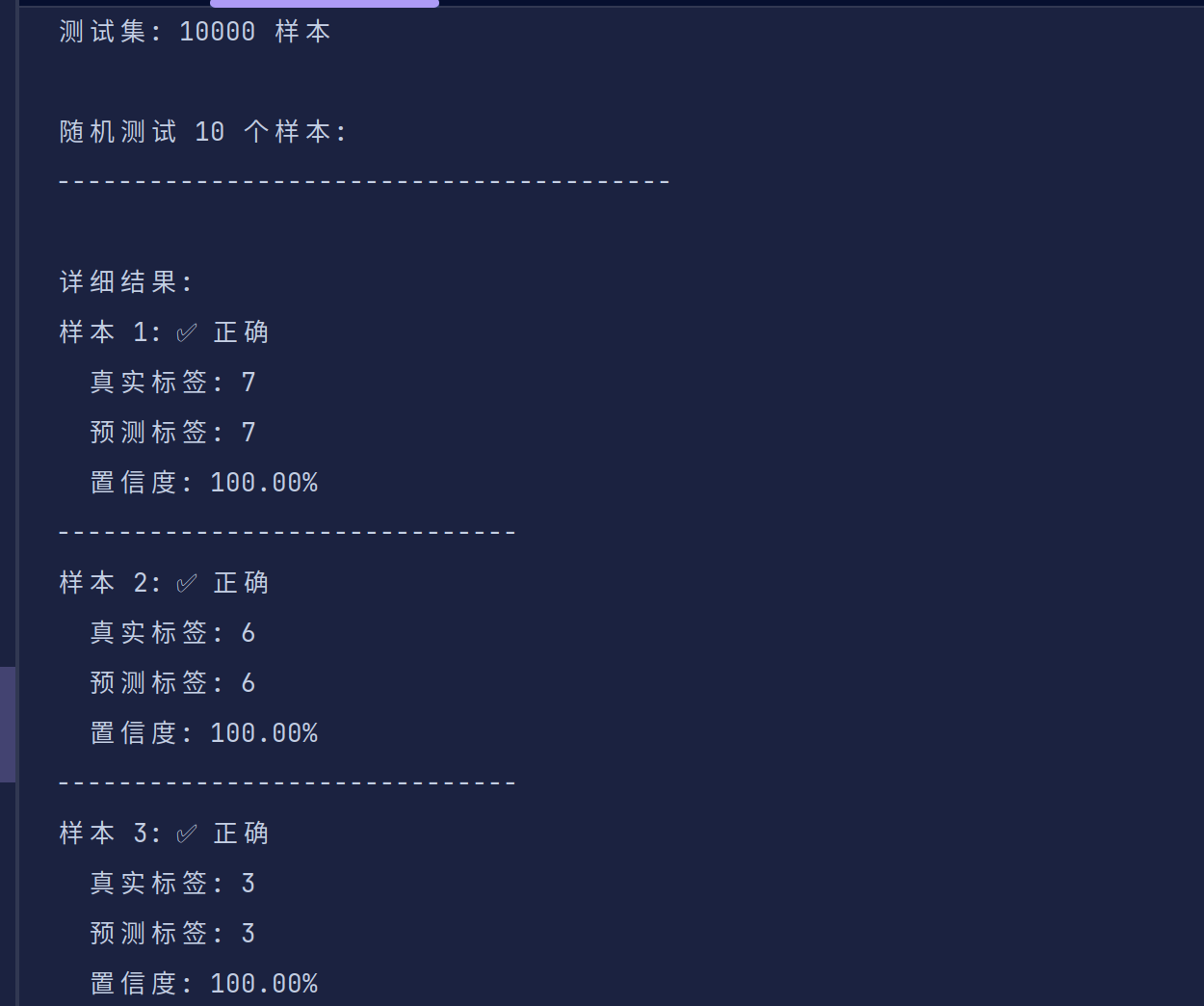
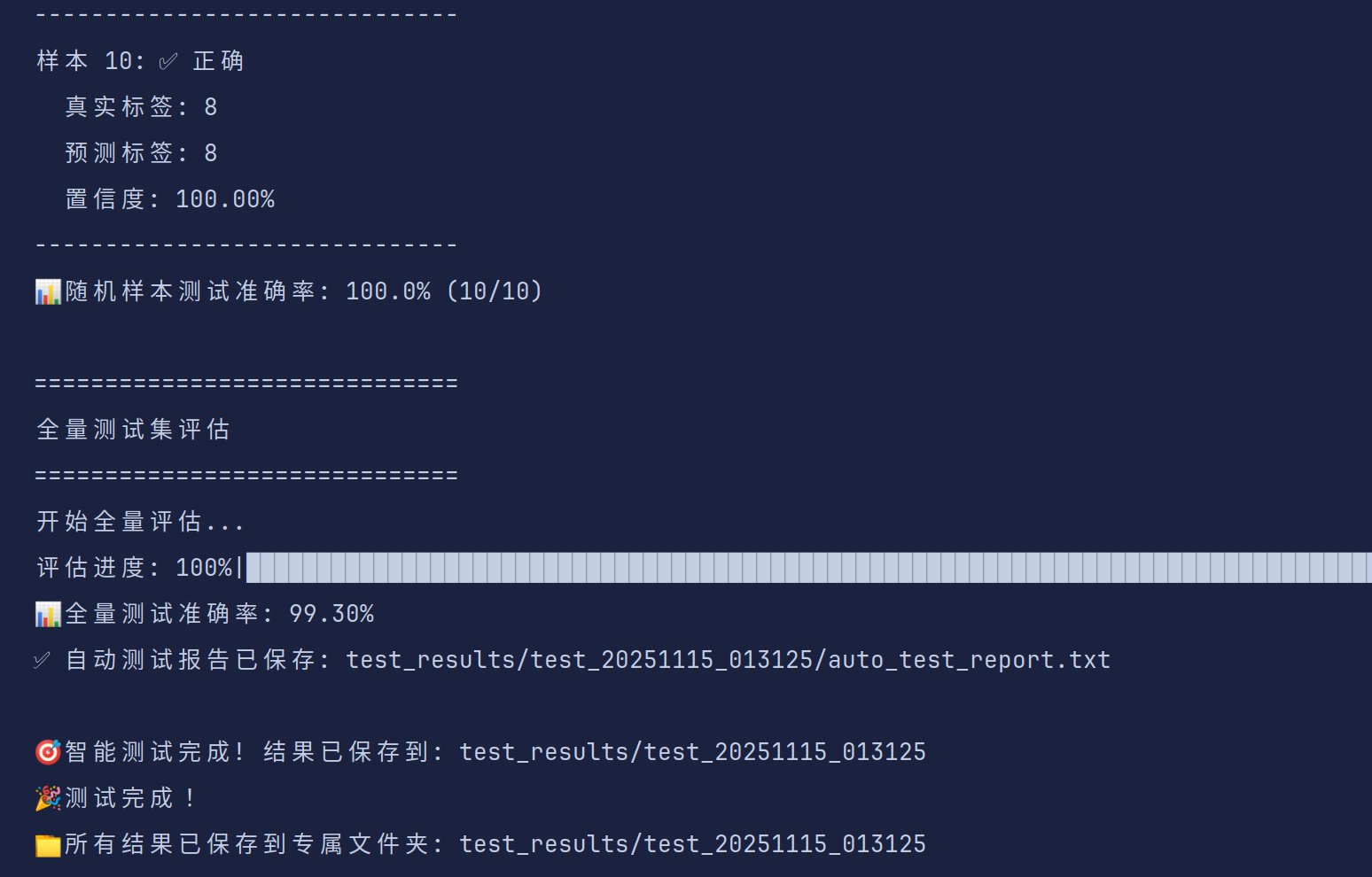
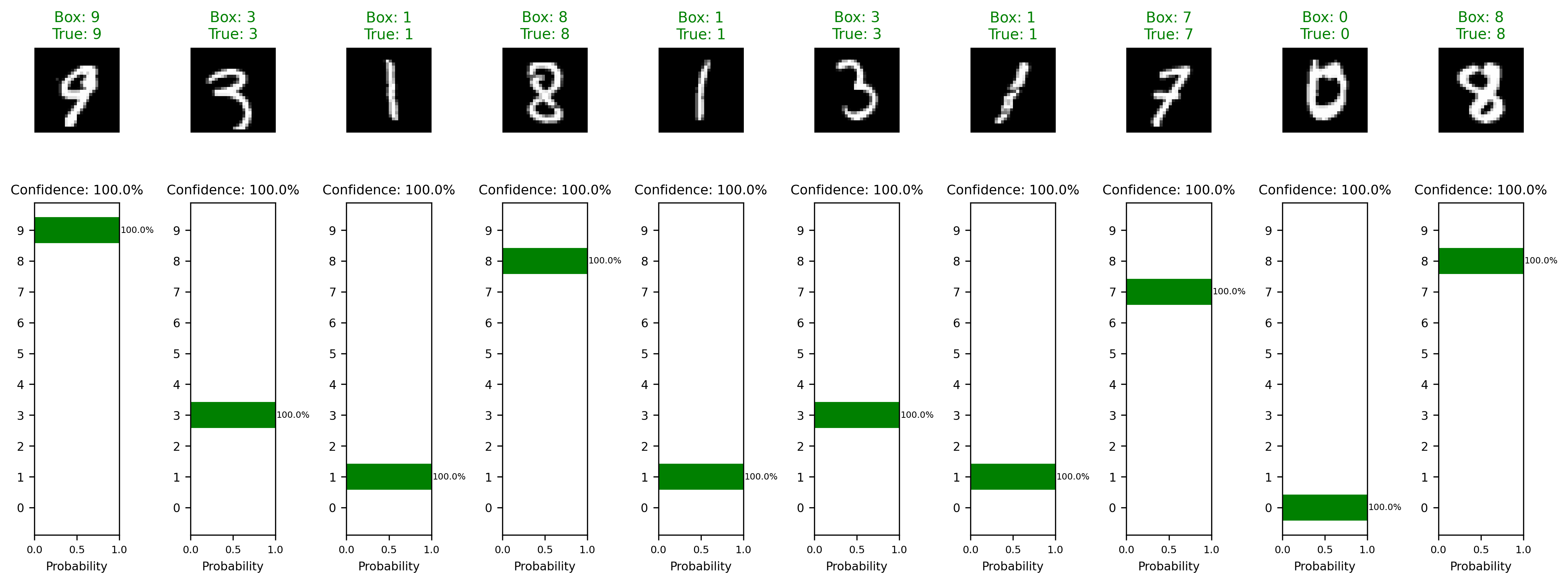
模式3:随机样本测试(默认,随机抽取测试集中的图片进行检测)
python test.py --model_path model.pth --num_samples 10
检测结果会保存在test_results
项目我已经上传到我的github主页了大家可以自行拉取
https://github.com/in-moonshadow/mnist_pytorch
六、常规训练过程的核心要点总结
无论用什么模型,常规训练流程的本质是"优化模型权重,最小化损失函数",关键要点包括:
- 数据是基础:预处理(归一化、展平)直接影响模型性能。
- 模型结构要适配问题:三层网络适合简单分类,复杂问题需CNN/RNN等。
- 损失函数选对:多分类用交叉熵,回归用MSE。
- 优化器影响收敛:Adam比SGD更稳定,适合大多数场景。
- 验证集防过拟合:监控验证集性能,避免模型"死记硬背"。
总结
通过本文的实战,你已经掌握了机器学习常规训练流程的每一个细节,并且了解了项目级机器学习代码的组成,准备去攻克yolov5吧