Project Go-Big:互联网规模的拟人机器人预训练 + 直接从人类视频到机器人的迁移
(发布日期:2025 年 9 月 18 日)
Figure AI单个模型自主导航和惊喜动作
摘要
一个重大进展
要让机器人在家庭环境中达到人类水平的智能,需要这些机器人能从大规模的现实世界中学习。今天,我们宣布在 Helix(Figure 的视觉-语言-动作模型,用于通用型拟人机器人控制)上的两个关键进展:
-
Project Go-Big:互联网规模的拟人预训练。Figure 正在构建世界上最大、最多样化的拟人机器人预训练数据集,该项目将通过与 Brookfield 的前所未有合作来加速推进,Brookfield 在全球拥有超过 100,000 个住宅单位。
-
零样本人类视频 → 机器人迁移 。Helix 已经达成一个新的学习里程碑:仅通过以第一视角拍摄的人类视频训练,Figure 的机器人现在能够从**"去冰箱"**这样的自然语言命令出发,在杂乱的真实环境中导航 ------ 这是拟人机器人领域的一个首次突破。
演示人类视频采集如何有效覆盖现实空间,并捕获可被迁移到 Helix 的行为技巧。
人类视角 数据采集

转化后

互联网规模的拟人预训练
机器学习的最大突破通常来自对大规模、多样化数据集的大规模预训练:例如,ImageNet 对视觉模型的推动;Wikipedia 对语言模型的推动;YouTube 对生成视频模型的推动。
但在机器人领域,缺乏等同于"机器人行为的 YouTube"那样规模的数据集。
传统上,教机器人新技能通常需要昂贵的示范(人操作机器人)、手工编程、或在高度受控的环境下训练,但这些方式难以捕捉现实世界的杂乱性。拟人机器人(humanoid robots) 具有一个独特优势:它们的视角和运动学结构与人类类似,因此理论上可以把日常人类视频中的知识直接迁移给机器人。

Project Go-Big 正是基于这一愿景 ------ 这是 Figure 发起的一个大规模拟人机器人预训练数据采集计划。
昨天,Figure 宣布已与 Brookfield 资产管理公司达成合作。Brookfield 拥有 1 万亿美元的全球资产基础 ------ 包括超过 100,000 个住宅单元、5 亿 平方英尺的写字楼空间、1.6 亿 平方英尺的物流空间 ------ 这将帮助加速 Go-Big 计划,通过在这些环境中捕获人类有目标行为的大规模、多样化现实数据。

直接从人类视频到机器人迁移
此前,Helix 的工作主要侧重于上半身操作任务,例如折叠衣服、洗碗机装载、包裹重定位等。
但除了操作之外,拟人机器人还必须具备智能导航能力 ------ 在家中找到路径、为任务重新定位、在人或物体之间流畅移动。
我们很高兴地分享:Project Go-Big 已经为 Helix 带来了一个初步的学习成果 ------ 从纯粹的人类视频直接迁移到机器人行为 。使用 100% 的第一视角(egocentric)人类视频数据,这些视频是在 Brookfield 的真实家庭环境中被动采集的,Helix 被训练将人类的导航策略 直接转化为机器人的控制。令人惊讶的是,这一方法不需要任何机器人演示数据。
结果包括:
-
语音到导航 (Speech-to-Nav):Helix 现在能对类似 "走到厨房桌子那边" 或 "去给植物浇水" 的对话式命令作出反应,从像素输入到自主导航,在复杂、杂乱的家居环境中生成闭环控制。
-
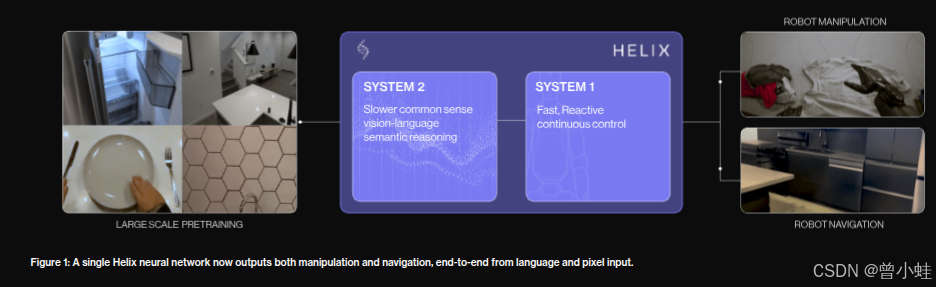
单一统一模型 :一个 Helix 网络模型现在能够同时输出高频率的精细操作和导航命令 ------ 无需为不同任务或不同数据源使用分离的子系统。
-
零样本人类 → 机器人迁移:据我们所知,这是第一次有拟人机器人能够端到端地学习 ------ 从图像 (pixels) + 语言 (language) 到低层的 SE(2) 速度命令输出 ------ 而仅用人类视频,无需任何机器人特定的数据或训练。
结语
我们正快速逼近一个未来:拟人机器人以根本"人性化"的方式理解和互动家庭环境 ------ 它们能导航、操作物体,并在复杂环境中用自然语言作为主要接口来推理与行动。
我们与 Brookfield 的合作使我们有机会探索用于运动(locomotion)和操作 (manipulation) 的互联网规模体现式 (embodied) 数据集的全部潜力。
我们已经看到了初步益处:首次实现从人类视频到机器人导航的交叉形体 (cross-embodiment) 零样本迁移。
技术解析:这一代机器人采用了什么技术思路 / 核心创新
从这篇官方文章来看,Figure 在这一代 Helix 系统里引入/强化了以下几个关键技术思路和创新方向:
| 技术方向 / 创新 | 具体内容 / 特点 | 意义 / 挑战 |
|---|---|---|
| 互联网规模的拟人预训练(Humanoid Pretraining) | 构建大规模、多样化、现实世界中的拟人行为数据集(尤其是人类第一视角视频),用于预训练机器人模型 | 类比于语言模型或视觉模型用大数据预训练的做法,将"机器人行为"纳入到预训练范式之中,是机器人领域少有的尝试。挑战在于采集、标注、对齐(人类动作 → 机器人动作)等方面。 |
| 跨形体迁移 / 零样本迁移 (Zero-shot human → robot transfer) | 用纯人类视频(无机器人演示)训练机器人行为模型,从人类导航策略、动作模式、行为直观映射到机器人控制 | 这是一种极具野心的路径:如果成功,可大幅降低机器人训练成本和环境依赖性。但核心难点在于 "对齐" ------ 如何把人类的运动学 / 视角 /身体限制差异映射到机器人的能力范围,以及如何保证机器人在现实环境中稳定执行。 |
| 统一端到端模型 (Unified model for navigation + manipulation) | 不再为导航 vs 操作分割模型,而是让同一个 Helix 网络模型从像素、语言输入,一并输出导航控制和操作控制 | 这简化了系统架构,提高通用性与协同能力。但对模型容量、稳定性、任务冲突、训练策略都提出了较高要求。 |
| 从语言 + 像素输入直接输出速度控制 (SE(2) 速度命令) | 模型的输入是图像 (pixels) + 语言 (natural language command),输出是控制命令(例如机器人在地面平面上的速度指令) | 这种端到端路径省去了中间手工规划或路径规划模块,但训练难度更高,尤其是在复杂/未知环境下需要鲁棒性和安全性。 |
| 现实环境数据采集与场景多样性 | 与 Brookfield 合作,在大量真实住宅 /商业 /物流环境中采集行为数据,覆盖各种杂乱、生活化场景 | 通过这种策略,Helix 模型能见到更多复杂环境下的人类行为,从而更具泛化能力。但采集、隐私、数据处理、同步、覆盖性都是挑战。 |
总的来说,这一代 Helix 机器人系统更倾向于一种"数据驱动 + 端到端学习 + 跨形体迁移"的路径,而不是传统的模块化、硬编码规划 + 强化学习单个任务的方式。