既然你的智能体已经具备一套可用工具,下一步就是将它们编排起来 以解决真实任务。编排不只是决定调用哪些工具、何时调用 ;还需要为每次模型调用构建恰当的上下文 ,以确保行动有效且有依据。简单任务也许只需一个工具与极少上下文;但更复杂的工作流则需要周密规划、记忆检索与动态上下文拼装 ,才能在每一步都准确执行。本章将介绍编排策略、上下文工程、工具选择与执行、以及规划拓扑 ,以打造能够高效、可靠地处理真实多步骤任务的智能体。正如图 5-1 所示,编排就是系统如何利用手边资源来有效回应用户查询的核心机制。
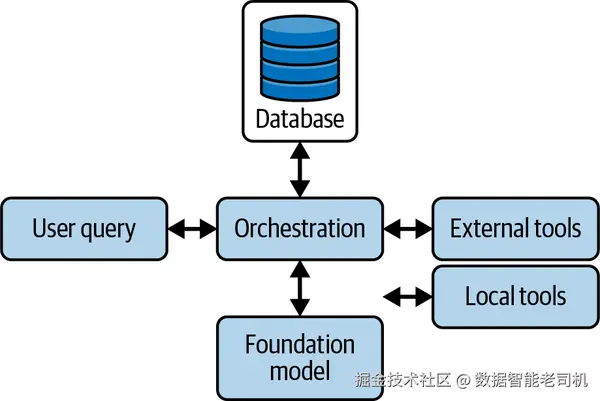
图 5-1. 编排作为核心逻辑:处理用户查询并协调对基础模型、外部与本地工具的调用,同时访问各类数据库以检索补充信息。
智能体类型(Agent Types)
在深入具体编排策略之前,先理解可构建的不同智能体类型 很重要。每种类型在推理、规划与行动 上都有独特取径,决定了任务如何被拆解与执行。有的智能体通过预设映射瞬时响应;有的则迭代推理与反思,以处理复杂的开放式目标。你的选择将直接影响系统的性能、成本与能力 。本节将介绍一个光谱:从反应迅捷的反射型智能体 ,到能以自适应计划与综合能力处理多阶段研究的深度研究型智能体 。理解这些原型,有助于将编排模式、工具选择与上下文构建与应用需求相匹配,从而实现有效、可靠的结果。
反射型智能体(Reflex Agents)
反射型智能体将输入直接映射为动作 ,不保留内部推理轨迹。简单的反射智能体遵循"若满足条件,则执行动作 "的规则:一旦检测到预定义触发器,就立刻调用相应工具。由于跳过中间思考步骤,它们具备极低时延与可预测性能 ,适合关键词路由、单步数据查询或基础自动化 (如"若 X,则调用工具 Y")。其局限是表达力有限,无法应对需要多步推理或超出即时输入上下文的任务。
ReAct 智能体(ReAct Agents)
ReAct 智能体在推理(Reasoning)与 行动(Action)之间交替循环 :模型生成想法 → 选择并调用工具 → 观察结果 → 视需要重复。该模式使智能体能把复杂任务拆成若干可管理步骤,并基于中间观察动态更新计划:
- ZERO_SHOT_REACT_DESCRIPTION(LangChain) :在单条提示中呈现工具与指令,依赖 LLM 的先验推理来选择/调用工具,无需示例轨迹。
- CHAT_ZERO_SHOT_REACT_DESCRIPTION:在此基础上纳入会话历史,让智能体在决策下一步动作时利用过往对话。
ReAct 智能体擅长探索性场景 ------动态数据分析、多源聚合、故障排查等------在这些场景中,中途自适应比额外时延与算力开销更重要。其循环结构也带来一定可观测性(如"思维链"),便于调试与审计,但可能增加 API 成本与响应时间。
规划-执行型智能体(Planner-Executor Agents)
此类智能体将任务分为两个明确阶段:规划 (由模型生成多步计划)与执行 (按计划调用工具完成各步)。这种分离让规划器 专注长程推理,而执行器 只调用必要工具,减少冗余 LLM 调用。由于计划是显式 的,调试与监控更直接:你可以检查生成的计划、定位失败步骤并在必要时重新规划。优势包括:
- 清晰拆解:复杂任务被划分为可管理的子任务。
- 易于调试:显式计划揭示错误发生的地点与原因。
- 成本效率:执行阶段可由更小的模型或更少的调用承担,把大模型留给规划。
询问分解型智能体(Query-Decomposition Agents)
该类智能体通过迭代地把复杂问题拆解为子问题 来求解:对每个子问题调用搜索或其他工具,最后再综合 答案。这一模式常被称为"self-ask with search ",流程为:
"我还需要什么后续问题?"→ 调用搜索 →"下一个问题是什么?"→ ... →"最终答案是什么?"
示例:SELF_ASK_WITH_SEARCH
问:"X 和 Y 谁活得更久?"
自问:"X 的生卒年是多少?"→ 搜索工具
自问:"Y 的生卒年是多少?"→ 搜索工具
综合:"X 活了 85 岁,Y 活了 90 岁,所以 Y 更久。"
当需要外部知识检索 以确保每条事实有据可依时,这种方法尤为有效。
反思型智能体(Reflection Agents)
反思与元推理智能体在 ReAct 的基础上更进一步:不仅交替"思考---行动",还会回顾既往步骤 ,在继续前识别并纠正错误 。以近期提出的 ReflAct 框架为例,智能体持续以目标状态反思 来校准推理:衡量当前状态与目标之间的差距,并在偏离时调整计划。反思提示 鼓励模型自我批注思维链、修正逻辑错误并强化成功策略,在复杂问题求解中模拟人类式的自我评估。
该模式适合高风险工作流 ,因为早期错误可能级联成高成本失败------如金融交易编排、医疗诊断支持或重大事件响应 。通过在每次行动后配套反思步骤 ,智能体能在工具输出偏离预期时及时检测并重规划或回滚 ,避免在不可逆操作前犯错。虽然额外的元推理会带来时延与算力开销,但在正确性与可靠性重于速度的任务中,反思型智能体提供了强有力的"防错护栏",帮助持续对齐总体目标。
深度研究型智能体(Deep Research Agents)
深度研究型智能体专长于应对开放式、高复杂度 的研究任务,这类任务需要广泛的外部信息收集、假设检验与综合 ------如文献综述、科学发现或战略市场分析。它们组合多种模式:用规划---执行 阶段制定研究工作流;用查询分解 将大问题拆成有针对性的检索;再用 ReAct 循环依据新发现迭代完善假设。在一个典型循环中,深度研究型智能体会:
- 规划整体研究议程(如识别关键子主题或数据来源)。
- 分解每个子主题为具体查询(通过 SELF_ASK 等方法)。
- 调用工具 ------从学术搜索 API 到领域数据库------并反思每条结果的相关性与可靠性。
- 综合 洞见为不断演进的报告或建议集,并在每一步使用 LLM 驱动的摘要与评议。
优势(Strengths)
- 能力(Capability)
可处理高度复杂、分阶段的研究,依托专业数据库与跨学科来源。 - 自适应(Adaptive)
随着新证据出现持续调整研究方向。 - 透明(Transparent)
显式的计划与分解步骤便于审计方法论。
劣势(Weaknesses)
- 高成本(High cost)
大量基础模型调用与多次 API 访问推高计算与 Token 开销。 - 时延(Latency)
规划、分解与反思的各层都会增加延迟。 - 脆弱性(Fragility)
严重依赖外部数据源的质量与可用性,需谨慎的错误处理与回退策略。
最佳用例 是长篇、专家级 任务------如学术文献调研、技术尽职调查、竞争情报------在这些场景下,深度与严谨比速度更重要。
表 5-1 概览了当前常见的智能体原型------各自在速度、灵活性与复杂度 间有不同取舍。不过,这一版图正以惊人速度演化:新的混合模式、元推理框架与规划策略层出不穷,类型划分也会愈发细化。将下表视为起点而非终点 :随着研究与工具成熟,请保持好奇、频繁试验,并准备好调整你的编排策略。
表 5-1. 常见智能体原型
| 智能体类型 | 优势 | 劣势 | 最佳用例 |
|---|---|---|---|
| Reflex(反射) | 毫秒级响应 | 无多步推理 | 关键词路由、简单查找 |
| ReAct | 灵活、可即时自适应 | 更高的时延与成本 | 探索型流程、故障排查 |
| Plan-execute(规划---执行) | 任务拆解清晰 | 规划开销 | 复杂的多步骤流程 |
| Query-decomposition(查询分解) | 基于检索、事实更扎实 | 多次工具调用 | 研究、基于事实的问答 |
| Reflection(反思) | 及早发现错误 | 增加计算与时延 | 高风险、对安全敏感的任务 |
| Deep research(深度研究) | 管理多阶段、可自适应的研究 | 计算成本高、时延极高 | 长篇文献综述 |
工具选择(Tool Selection)
在谈"编排"之前,先从工具选择开始,因为它是更高级规划的基础。不同的工具选择方法各有优劣,适用于不同的需求与环境。这里默认你已经有一套可用工具;若需回顾,请返回第 4 章。
表 5-2. 工具选择策略
| 技术 | 优点 | 缺点 |
|---|---|---|
| 标准工具选择 | 实现简单 | 当工具数量很大时扩展性差 |
| 语义工具选择 | 对大量工具非常可扩展;通常实现时延低 | 由于语义"碰撞",选择准确率往往更差 |
| 分层工具选择 | 对大量工具非常可扩展 | 需要多次顺序的大模型调用,速度更慢 |
标准工具选择(Standard Tool Selection)
最简单的方法是标准工具选择 :把工具、其定义与描述提供给基础模型,请模型在给定上下文中选择最合适的工具。随后将模型输出与工具集合比对,选取最接近的工具。该方法易于实现 ,无需额外训练、嵌入或工具层级。但主要缺点是时延 :需要额外的一次模型调用,可能给总体响应增加数秒。它也可受益于上下文学习(few-shot 示例),无需训练/微调即可提升预测准确率。
有效的工具选择高度依赖你如何描述每项能力:
- 为每个工具起简洁、准确 的名字(如
calculate_sum而非process_numbers)。 - 用一句话突出其独特用途(例:"返回两个数的和")。
- 在描述中加入调用示例(典型输入/输出),让模型基于具体而非抽象语言理解。
- 明确输入约束(类型与范围,如"x 与 y 必须是 0--1000 的整数"),以减少歧义并帮助模型排除无关工具。
随着注册工具数量增长,描述重叠会变得常见并引发误选。下面定义一个能计算数学表达式、评估公式的工具------这是基础模型常见的薄弱环节:
python
from langchain_core.tools import tool
import requests
@tool
def query_wolfram_alpha(expression: str) -> str:
"""
Query Wolfram Alpha to compute expressions or retrieve information.
Args: expression (str): The mathematical expression or query to evaluate.
Returns: str: The result of the computation or the retrieved information.
"""
api_url = f'''https://api.wolframalpha.com/v1/result?
i={requests.utils.quote(expression)}&
appid=YOUR_WOLFRAM_ALPHA_APP_ID'''
try:
response = requests.get(api_url)
if response.status_code == 200:
return response.text
else: raise ValueError(f"Wolfram Alpha API Error:
{response.status_code} - {response.text}")
except requests.exceptions.RequestException as e:
raise ValueError(f"Failed to query Wolfram Alpha: {e}")
@tool
def trigger_zapier_webhook(zap_id: str, payload: dict) -> str:
""" Trigger a Zapier webhook to execute a predefined Zap.
Args:
zap_id (str): The unique identifier for the Zap to be triggered.
payload (dict): The data to send to the Zapier webhook.
Returns:
str: Confirmation message upon successful triggering of the Zap.
Raises: ValueError: If the API request fails or returns an error.
"""
zapier_webhook_url = f"https://hooks.zapier.com/hooks/catch/{zap_id}/"
try:
response = requests.post(zapier_webhook_url, json=payload)
if response.status_code == 200:
return f"Zapier webhook '{zap_id}' successfully triggered."
else:
raise ValueError(f'''Zapier API Error: {response.status_code} -
{response.text}''')
except requests.exceptions.RequestException as e:
raise ValueError(f"Failed to trigger Zapier webhook '{zap_id}': {e}")另一个你可能注册的工具:在任务完成或需人工介入时通知某个 Slack 频道(human-in-the-loop 模式):
python
@tool
def send_slack_message(channel: str, message: str) -> str:
""" Send a message to a specified Slack channel.
Args:
channel (str): The Slack channel ID or name where the message will be sent.
message (str): The content of the message to send.
Returns:
str: Confirmation message upon successful sending of the Slack message.
Raises: ValueError: If the API request fails or returns an error.
"""
api_url = "https://slack.com/api/chat.postMessage"
headers = { "Authorization": "Bearer YOUR_SLACK_BOT_TOKEN",
"Content-Type": "application/json" }
payload = { "channel": channel, "text": message }
try:
response = requests.post(api_url, headers=headers, json=payload)
response_data = response.json()
if response.status_code == 200 and response_data.get("ok"):
return f"Message successfully sent to Slack channel '{channel}'."
else:
error_msg = response_data.get("error", "Unknown error")
raise ValueError(f"Slack API Error: {error_msg}")
except requests.exceptions.RequestException as e:
raise ValueError(f'''Failed to send message to Slack channel
"{channel}": {e}''')将工具绑定到模型端,让模型选择最合适的工具来处理输入:
ini
# Initialize the LLM with GPT-4o and bind the tools
llm = ChatOpenAI(model_name="gpt-4o")
llm_with_tools = llm.bind_tools([get_stock_price,
send_slack_message, query_wolfram_alpha])
messages = [HumanMessage("What is the stock price of Apple?")]
ai_msg = llm_with_tools.invoke(messages)
messages.append(ai_msg)
for tool_call in ai_msg.tool_calls:
tool_msg = get_stock_price.invoke(tool_call)
final_response = llm_with_tools.invoke(messages)
print(final_response.content)小结 :标准工具选择能在无额外基础设施或训练 的情况下,快速直觉地把工具接入智能体系统。对于小规模工具集很合适;当库规模扩大时,必须通过精心的描述工程 维持准确性并避免误选。结合精炼的描述与迭代提示测试 ,你能以这一简单而强大的方法获得稳健表现。
语义工具选择(Semantic Tool Selection)
另一种方法是语义工具选择 :用语义表示 为所有可用工具建索引,并用语义搜索 检索最相关的工具。这样先把候选集合缩小,再让基础模型从更小的集合中选择正确的工具与参数。预先,使用仅编码模型 (如 OpenAI 的 Ada、Amazon Titan、Cohere Embed、ModernBERT 等)对每个工具的定义与描述进行嵌入,把工具名与描述表示为向量。
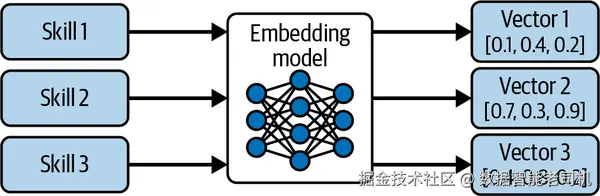
图 5-2. 语义工具嵌入用于基于检索的选择。 每个工具/技能被编码为稠密向量,存入库中以便按任务语义相似度进行高效检索。
随后,把这些工具向量索引到轻量级向量数据库 。运行时,用相同嵌入模型对当前上下文向量化,在数据库中搜索,取回Top K 工具。再把这些工具传给基础模型,由其决定是否调用与如何设参;调用完成后用返回结果组装最终答复。
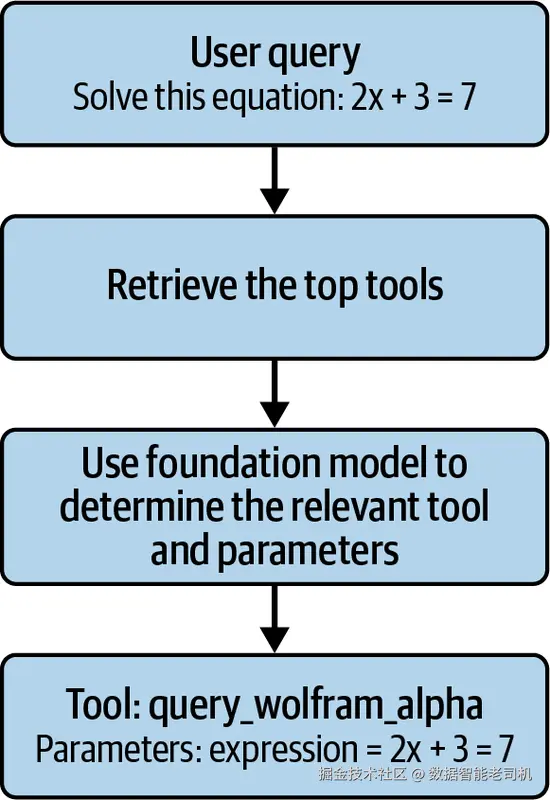
图 5-3. 语义工具检索与调用流程。 运行时将用户查询嵌入→检索最相关工具→由基础模型选择工具并确定参数→调用工具→融合输出生成最终响应。
这是最常见、且推荐用于多数场景的模式:通常比标准选择更快、性能稳健且可扩展。先对工具描述进行嵌入:
python
import os
import requests
import logging
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
from langchain.vectorstores import FAISS
import faiss
import numpy as np
# Initialize OpenAI embeddings
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# Tool descriptions
tool_descriptions = {
"query_wolfram_alpha": '''Use Wolfram Alpha to compute mathematical
expressions or retrieve information.''',
"trigger_zapier_webhook": '''Trigger a Zapier webhook to execute
predefined automated workflows.''',
"send_slack_message": '''Send messages to specific Slack channels to
communicate with team members.'''
}
# Create embeddings for each tool description
tool_embeddings = []
tool_names = []
for tool_name, description in tool_descriptions.items():
embedding = embeddings.embed_text(description)
tool_embeddings.append(embedding)
tool_names.append(tool_name)
# Initialize FAISS vector store
dimension = len(tool_embeddings[0])
index = faiss.IndexFlatL2(dimension)
# Normalize embeddings for cosine similarity
faiss.normalize_L2(np.array(tool_embeddings).astype('float32'))
# Convert list to FAISS-compatible format
tool_embeddings_np = np.array(tool_embeddings).astype('float32')
index.add(tool_embeddings_np)
# Map index to tool functions
index_to_tool = {
0: query_wolfram_alpha,
1: trigger_zapier_webhook,
2: send_slack_message
}这些向量只需计算一次,之后即可快速检索。选择工具时,对查询做同样的嵌入,进行数据库查找,选参并调用:
python
def select_tool(query: str, top_k: int = 1) -> list:
"""
Select the most relevant tool(s) based on the user's query using
vector-based retrieval.
Args:
query (str): The user's input query.
top_k (int): Number of top tools to retrieve.
Returns:
list: List of selected tool functions.
"""
query_embedding = embeddings.embed_text(query).astype('float32')
faiss.normalize_L2(query_embedding.reshape(1, -1))
D, I = index.search(query_embedding.reshape(1, -1), top_k)
selected_tools = [index_to_tool[idx] for idx in I[0] if idx in index_to_tool]
return selected_tools
def determine_parameters(query: str, tool_name: str) -> dict:
"""
Use the LLM to analyze the query and determine the parameters for the tool
to be invoked.
Args:
query (str): The user's input query.
tool_name (str): The selected tool name.
Returns:
dict: Parameters for the tool.
"""
messages = [
HumanMessage(content=f'''Based on the user's query: '{query}', what
parameters should be used for the tool '{tool_name}'?''')
]
# Call the LLM to extract parameters
response = llm(messages)
# Example logic to parse response from LLM
parameters = {}
if tool_name == "query_wolfram_alpha":
parameters["expression"] = response['expression']
# Extract mathematical expression
elif tool_name == "trigger_zapier_webhook":
parameters["zap_id"] = response.get('zap_id', "123456")
parameters["payload"] = response.get('payload', {"data": query})
elif tool_name == "send_slack_message":
parameters["channel"] = response.get('channel', "#general")
parameters["message"] = response.get('message', query)
return parameters
# Example user query
user_query = "Solve this equation: 2x + 3 = 7"
# Select the top tool
selected_tools = select_tool(user_query, top_k=1)
tool_name = selected_tools[0] if selected_tools else None
if tool_name:
# Use LLM to determine the parameters based on the query and the selected tool
args = determine_parameters(user_query, tool_name)
# Invoke the selected tool
try:
# Assuming each tool has an `invoke` method to execute it
tool_result = globals()[tool_name].invoke(args)
print(f"Tool '{tool_name}' Result: {tool_result}")
except ValueError as e:
print(f"Error invoking tool '{tool_name}': {e}")
else:
print("No tool was selected.")分层工具选择(Hierarchical Tool Selection)
当你的场景涉及大量工具 ,尤其是许多工具语义相近 且你愿意用更高的时延与复杂度换取更好的选择准确率时,可考虑分层工具选择 。该模式中,你将工具分组 并为每组提供描述。工具选择(生成式或语义式)先选组 ,再在该组内进行二次检索选出具体工具。
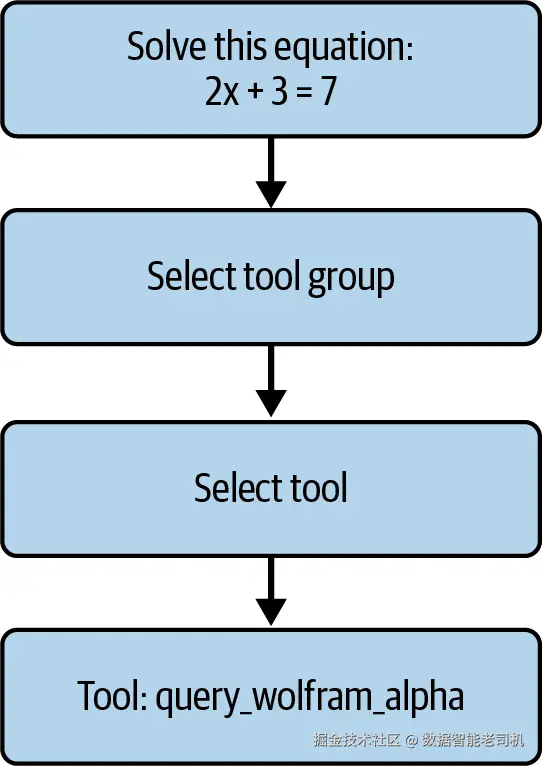
图 5-4. 分层工具选择流程。 查询先路由至最相关的工具组,再在组内细化到单个工具------示例中把数学问题路由到"计算"组,最终调用 query_wolfram_alpha。
这种方法更慢、并且并行化成本高,但它把复杂选择任务拆成两段,经常能带来更高的总体准确率 。不过,构建与维护 这些工具组需要额外时间与精力,因此除非你确有大量工具,否则不建议使用。
python
import os
import requests
import logging
import numpy as np
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
# Initialize the LLM
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
# Define tool groups with descriptions
tool_groups = {
"Computation": {
"description": '''Tools related to mathematical computations and
data analysis.''',
"tools": []
},
"Automation": {
"description": '''Tools that automate workflows and integrate
different services.''',
"tools": []
},
"Communication": {
"description": "Tools that facilitate communication and messaging.",
"tools": []
}
}
# Define Tools
@tool
def query_wolfram_alpha(expression: str) -> str:
api_url = f'''https://api.wolframalpha.com/v1/result?i=
{requests.utils.quote(expression)}&appid={WOLFRAM_ALPHA_APP_ID}'''
try:
response = requests.get(api_url)
if response.status_code == 200:
return response.text
else:
raise ValueError(f'''Wolfram Alpha API Error: {response.status_code}
- {response.text}''')
except requests.exceptions.RequestException as e:
raise ValueError(f"Failed to query Wolfram Alpha: {e}")
@tool
def trigger_zapier_webhook(zap_id: str, payload: dict) -> str:
zapier_webhook_url = f"https://hooks.zapier.com/hooks/catch/{zap_id}/"
try:
response = requests.post(zapier_webhook_url, json=payload)
if response.status_code == 200:
return f"Zapier webhook '{zap_id}' successfully triggered."
else:
raise ValueError(f'''Zapier API Error: {response.status_code} -
{response.text}''')
except requests.exceptions.RequestException as e:
raise ValueError(f"Failed to trigger Zapier webhook '{zap_id}': {e}")
@tool
def send_slack_message(channel: str, message: str) -> str:
api_url = "https://slack.com/api/chat.postMessage"
headers = {
"Authorization": f"Bearer {SLACK_BOT_TOKEN}",
"Content-Type": "application/json"
}
payload = {
"channel": channel,
"text": message
}
try:
response = requests.post(api_url, headers=headers, json=payload)
response_data = response.json()
if response.status_code == 200 and response_data.get("ok"):
return f"Message successfully sent to Slack channel '{channel}'."
else:
error_msg = response_data.get("error", "Unknown error")
raise ValueError(f"Slack API Error: {error_msg}")
except requests.exceptions.RequestException as e:
raise ValueError(f'''Failed to send message to Slack channel
'{channel}': {e}''')
# Assign tools to their respective groups
tool_groups["Computation"]["tools"].append(query_wolfram_alpha)
tool_groups["Automation"]["tools"].append(trigger_zapier_webhook)
tool_groups["Communication"]["tools"].append(send_slack_message)
# -------------------------------
# LLM-Based Hierarchical Tool Selection
# -------------------------------
def select_group_llm(query: str) -> str:
"""
Use the LLM to determine the most appropriate tool group based on the
user's query.
Args:
query (str): The user's input query.
Returns:
str: The name of the selected group.
"""
prompt = f'''Select the most appropriate tool group for the following query:
'{query}'.\nOptions are: Computation, Automation, Communication.'''
response = llm([HumanMessage(content=prompt)])
return response.content.strip()
def select_tool_llm(query: str, group_name: str) -> str:
"""
Use the LLM to determine the most appropriate tool within a group based
on the user's query.
Args:
query (str): The user's input query.
group_name (str): The name of the selected tool group.
Returns:
str: The name of the selected tool function.
"""
prompt = f'''Based on the query: '{query}', select the most appropriate
tool from the group '{group_name}'.'''
response = llm([HumanMessage(content=prompt)])
return response.content.strip()
# Example user query
user_query = "Solve this equation: 2x + 3 = 7"
# Step 1: Select the most relevant tool group using LLM
selected_group_name = select_group_llm(user_query)
if not selected_group_name:
print("No relevant tool group found for your query.")
else:
logging.info(f"Selected Group: {selected_group_name}")
print(f"Selected Tool Group: {selected_group_name}")
# Step 2: Select the most relevant tool within the group using LLM
selected_tool_name = select_tool_llm(user_query, selected_group_name)
selected_tool = globals().get(selected_tool_name, None)
if not selected_tool:
print("No relevant tool found within the selected group.")
else:
logging.info(f"Selected Tool: {selected_tool.__name__}")
print(f"Selected Tool: {selected_tool.__name__}")
# Prepare arguments based on the tool
args = {}
if selected_tool == query_wolfram_alpha:
# Assume the entire query is the expression
args["expression"] = user_query
elif selected_tool == trigger_zapier_webhook:
# Use placeholders for demo
args["zap_id"] = "123456"
args["payload"] = {"message": user_query}
elif selected_tool == send_slack_message:
# Use placeholders for demo
args["channel"] = "#general"
args["message"] = user_query
else:
print("Selected tool is not recognized.")
# Invoke the selected tool
try:
tool_result = selected_tool.invoke(args)
print(f"Tool '{selected_tool.__name__}' Result: {tool_result}")
except ValueError as e:
print(f"Error: {e}")结论 :分层选择虽更慢且并行代价高,但把问题拆成两段往往能带来更高的总体准确率 。然而,分组的设计与维护有成本,除非工具数量庞大,否则不建议采用。
工具执行(Tool Execution)
参数化(Parametrization)是为将由语言模型执行的工具定义并设置参数 的过程。这一步至关重要,它决定了模型如何理解任务,并如何据此定制响应以满足具体需求。参数由工具定义(第 4 章已详细讨论)所规定。智能体的当前状态 (包括已完成的进度)会作为额外上下文 一并提供给模型,并指示基础模型用合适的数据类型 填充调用该函数所需的参数。对于需要此类信息的函数,还可以将当前时间、用户位置 等额外上下文 注入到上下文窗口中以提供指引。建议使用基本的解析器 对输入做类型与格式校验;若未通过校验,应在提示中指示基础模型自行更正参数格式。
一旦参数就绪,就进入工具执行阶段 。有些工具可以本地 直接执行,另一些将通过 API 远程 执行。执行期间,模型可能会与各类 API、数据库或其他工具交互,以收集信息、进行计算或执行完成任务所需的操作。整合外部数据源与工具能显著提升智能体输出的实用性与准确性 。需要根据场景的时延与性能 要求,调整超时与重试策略。
工具拓扑(Tool Topologies)
当下多数聊天机器人系统依赖无规划的单工具执行 。这很合理:实现简单、时延更低。若你团队在做第一套基于智能体的系统,或该模式已能满足需求,那么看完下一节"单工具执行 "即可止步。
但在许多场景,我们希望智能体能完成需要多个工具 的复杂任务。只要为智能体提供足够丰富的工具,就可以让它灵活编排 并按正确顺序应用这些工具,以解决更广泛的问题。传统软件工程中,设计者必须手写 步骤的控制流与顺序;如今,我们实现好工具并定义智能体可运行的拓扑 ,再让具体的组合 随上下文与任务动态生成。本节将讨论这些工具拓扑及其取舍。
单工具执行(Single Tool Execution)
先看只需一个工具 的任务。此时的"规划"就是选出最适合的一个工具 。选定后,依据工具定义正确参数化 ,执行工具,并将其输出作为拼装最终用户响应 的输入(见图 5-5)。这虽然是极简的计划定义,但也是我们构建更复杂模式的地基。
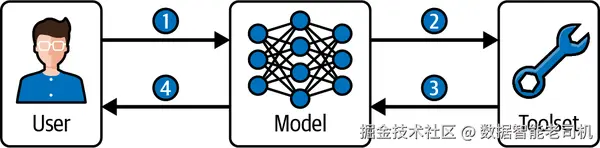
图 5-5. 单工具执行流程。 用户查询传给模型(步骤 1);模型从工具集中选择合适工具(步骤 2);接收工具输出(步骤 3);据此生成最终答复(步骤 4)。
为了更具体,图 5-6 展示了相同流程在查询纽约市天气场景下的应用。

图 5-6. 天气查询的单工具执行示例。 用户询问纽约天气;模型选择并参数化天气工具;以 JSON 载荷取回温度与天气状况;据此用自然语言回复用户。
这一简单模式构成了高级智能体系统中多步规划与工具编排 的基础。下一节我们将看看如何增加工具数量 而不牺牲时延。
并行工具执行(Parallel Tool Execution)
第一层复杂化来自工具并行 。在某些情况下,对同一输入并行采取多个动作 是有价值的。比如查询某位病人的记录:若你的工具集中包含访问多个数据源 的工具,就需要并行执行 多个动作以分别取回各源的数据。难点在于不确定需要执行多少个工具。
常见做法是:先用语义工具选择 检索出最多 K 个可能需要执行的工具(例如 5 个)。接着,针对这最多 5 个工具再调用一次基础模型,让它在其中筛选出真正必要 的子集;或反复调用基础模型,并将"已选工具"的上下文传入,直到模型不再添加新工具。选定后,这些工具独立参数化并并行执行 。待所有工具完成后,再把它们的结果一并交给基础模型起草最终回复(见图 5-7)。
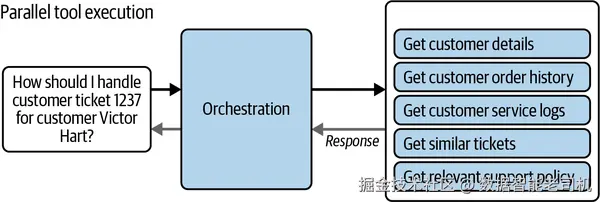
图 5-7. 并行工具执行模式。 例:用户询问如何处理客户工单。编排过程并行选择多种工具------检索客户详情、订单历史、服务日志、相似工单、相关政策------在整合输出后生成最终答复。
这种模式让智能体能在单个步骤 里高效地从多源收集完整信息 ;在生成回复前整合这些结果,可在尽量不增加总时延的前提下,给出更丰富、更有依据的输出。
链(Chains)
进一步的复杂化是链式 执行。链 指按照固定顺序逐步执行 的一系列动作,且每一步依赖 前一步的成功结果。规划链的要点是:确定动作顺序,使每步都能顺畅衔接 到下一步,直至达成目标。链常见于需要分步流程或线性工作流的任务。
幸运的是,LangChain 提供了声明式语法 LCEL(LangChain Expression Language) ,可通过组合现有 Runnable 来构建链,而非手动装配 Chain 对象。LCEL 将每条链视作实现统一接口的 Runnable,因此你可以像对待其他 Runnable 一样对任意 LCEL 链执行 invoke()、batch() 或 stream():
ini
from langchain_core.runnables import RunnableLambda
from langchain.chat_models import ChatOpenAI
from langchain_core.prompts import PromptTemplate
# Wrap a function or model call as a Runnable
llm = RunnableLambda.from_callable(ChatOpenAI(model_name="gpt-4",
temperature=0).generate)
prompt = RunnableLambda.from_callable(lambda text:
PromptTemplate.from_template(text).format_prompt({"input": text}
).to_messages())
# Traditional chain equivalent:
# chain = LLMChain(prompt=prompt, llm=llm)
# LCEL chain using pipes:
chain = prompt | llm
# Invoke the chain
result = chain.invoke("What is the capital of France?")切换到 LCEL 可减少样板代码,获得更强的执行特性,并保持链简洁可维护 。图 5-8 展示了许多 LCEL 工作流背后的通用代理式链模式。

图 5-8. 代理式链执行模式。 用户提示传入模型;模型推理并调用工具与环境交互;结果作为观察回灌模型,继续推理,直至任务完成。
规划链时,应仔细评估各动作之间的依赖关系 ,力求形成面向目标的连贯流程。强烈建议为链设置最大长度 ,因为错误会沿链条逐步放大 。只要任务不需要分裂成多分支子任务,链 在"多工具 + 有依赖"与"控制复杂度"之间提供了很好的折衷。
图(Graphs)
在包含多个决策点 的支持类场景中,图拓扑 比链或树更能表达复杂、非层级 的流程。不同于线性链或严格分叉的树,图结构允许定义条件边 与合并边 ,从而让并行路径在下游汇合到共享节点。
图中的每个节点 代表一次独立的工具调用(或逻辑步骤);边 (包括 add_conditional_edges)声明了智能体在何种条件下可以从一个步骤转移 到下一个。通过把多个分支的输出合并到单一的下游节点(如 summarize_response),你可以把分散处理的结果缝合为统一回复。
需要注意,完整的图执行通常比链需要更多的大模型调用 ------增加时延与成本 。因此必须限制图的深度 与分支因子 。同时,环路 、不可达节点 或冲突的状态合并 会引入新的错误类型,需通过严格的校验与测试管理。下面是用 LangGraph 实现图的示例(代码保持原样):
python
from langgraph.graph import StateGraph, START, END
from langchain.chat_models import ChatOpenAI
# Initialize LLM
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
# 1. Node definitions
def categorize_issue(state: dict) -> dict:
prompt = (
f"Classify this support request as 'billing' or 'technical'.\n\n"
f"Message: {state['user_message']}"
)
generations = llm.generate([{"role":"user","content":prompt}]).generations
kind = generations[0][0].text.strip().lower()
return {**state, "issue_type": kind}
def handle_invoice(state: dict) -> dict:
# Fetch invoice details...
return {**state, "step_result": f"Invoice details for {state['user_id']}"}
def handle_refund(state: dict) -> dict:
# Initiate refund workflow...
return {**state, "step_result": "Refund process initiated"}
def handle_login(state: dict) -> dict:
# Troubleshoot login...
return {**state, "step_result": "Password reset link sent"}
def handle_performance(state: dict) -> dict:
# Check performance metrics...
return {**state, "step_result": "Performance metrics analyzed"}
def summarize_response(state: dict) -> dict:
# Consolidate previous step_result into a user-facing message
details = state.get("step_result", "")
summary = llm.generate([{"role":"user","content":
f"Write a concise customer reply based on: {details}"
}]).generations[0][0].text.strip()
return {**state, "response": summary}接下来把各节点的逻辑连线 成真正的执行图。创建 StateGraph 后,从 START → categorize_issue 起步,确保每个请求先经过分类。然后用 add_conditional_edges 编码业务规则:分类后,仅 账单问题进入发票/退款处理,仅 技术问题进入登录/性能处理。每个路由函数检查状态 并返回下个节点名称,映射则保证运行时只允许合法后继 。这样能让决策逻辑显式化,强制正确的工具调用顺序,并在执行前就阻止非法跳转:
perl
# 2. Build the graph
graph = StateGraph()
# Start → categorize_issue
graph.add_edge(START, categorize_issue)
# categorize_issue → billing or technical
def top_router(state):
return "billing" if state["issue_type"] == "billing" else "technical"
graph.add_conditional_edges(
categorize_issue,
top_router,
mapping={"billing": handle_invoice, "technical": handle_login}
)
# Billing sub-branches: invoice vs. refund
def billing_router(state):
msg = state["user_message"].lower()
return "invoice" if "invoice" in msg else "refund"
graph.add_conditional_edges(
handle_invoice,
billing_router,
mapping={"invoice": handle_invoice, "refund": handle_refund}
)
# Technical sub-branches: login vs. performance
def tech_router(state):
msg = state["user_message"].lower()
return "login" if "login" in msg else "performance"
graph.add_conditional_edges(
handle_login,
tech_router,
mapping={"login": handle_login, "performance": handle_performance}
)最后补齐合并边 :无论路径走到退款、性能、发票还是登录,其结果都汇入 summarize_response,再链接到 END ,确保每条执行路径在结束前收敛为一条完善的回复:
makefile
# Consolidation: both refund and performance (and invoice/login) lead here
graph.add_edge(handle_refund, summarize_response)
graph.add_edge(handle_performance, summarize_response)
# Also cover paths where invoice or login directly go to summary
graph.add_edge(handle_invoice, summarize_response)
graph.add_edge(handle_login, summarize_response)
# Final: summary → END
graph.add_edge(summarize_response, END)
# 3. Execute the graph
initial_state = {
"user_message": "Hi, I need help with my invoice and possibly a refund.",
"user_id": "U1234"
}
result = graph.run(initial_state, max_depth=5)
print(result["response"])总结 :图为建模复杂、非线性的工作流提供了最高的表达力 ------可分支、可合并,并将多次工具执行整合为统一流程。但这种表达力带来额外开销 :更多的 LLM 调用、更深的路由逻辑,以及潜在的环路/死路。落地时,请始终以具体用例为锚,避免不必要的复杂化。
- 若任务严格线性 (如 prompt → model → parser),先用链,更易理解与调试。
- 只有当你既需要分支,又需要在下游合并 多路信息时,才上图。
实践建议:先在纸上勾勒拓扑,标注每个节点与允许的转移,并强调分支何处汇合 。再增量实现 :限制深度与分支数、为每个路由写单测,并用 LangGraph 的追踪工具验证每条路径都能走到终止节点 。最重要的是:保持尽可能简单 。每多一个节点或边,潜在执行路径与错误模式都会激增。若更简单的链或树就够用,就把图留给真正复杂 的场景。通过从简入手、按需迭代 ,你将获得健壮、可维护、可扩展的编排。
上下文工程(Context Engineering)
上下文工程 是编排(orchestration)的核心组成部分。它确保智能体计划中的每一步都拥有恰当的信息与指令 以高效执行。与专注于撰写有效指令的提示工程(prompt engineering)不同,上下文工程关注动态装配 所有输入------用户消息、检索到的知识、工作流状态与系统提示------并将其组织成结构化、节省 token 的上下文窗口,从而最大化任务表现。
例如,规划---执行型 智能体依赖干净的"计划输出"被传递给执行步骤作为上下文;ReAct 智能体则需要把相关的工具结果清晰地嵌入到提示中,以指导其下一轮推理。由此可见,上下文工程在规划与执行之间搭桥,让智能体工作流保持连贯、扎实并与用户目标一致。
从本质上说,上下文工程要解决三个问题:包含什么信息 、如何为清晰与相关性来组织 、以及如何在 token 限额内高效装配 。这通常包括:当前用户输入、从记忆或外部知识库检索到的相关片段、过往对话的摘要、定义智能体角色的系统指令,以及完成当下任务所需的任何工作流状态 。在简单系统里,上下文可能只有系统提示和最近一次用户查询;但当智能体需要处理更复杂的任务------如编排多步工作流 或基于历史交互进行个性化推荐 ------就必须进行动态上下文构建,以维持连贯性、准确性与实用性。
举例来说,一个处理电商客服的智能体,可能会把以下内容组合成上下文:限定其允许动作的系统提示、用户当前消息、检索到的订单记录摘要,以及相关政策条款摘录。在更高级的系统中,上下文还会包含关联对话的摘要 ,或工作流早期工具调用的结果 。每加入一项元素都可能 提升任务表现,但前提是经过审慎挑选与结构化;无关或组织混乱的内容只会分散模型注意力、徒增 token 成本而无益。
要实现有效的上下文工程,建议遵循以下实践:
- 相关性优先 :从记忆或知识库只检索最有用的信息,避免无差别拼接大段文本。
- 保持结构化 :采用清晰的格式或模式/架构(schema) (如 MCP,Model Context Protocol )来传递状态与检索知识,使模型能可预测、可解释地消费上下文。
- 摘要压缩 :对较长的历史进行摘要,保留关键信息,节省 token。
- 动态装配 :在每一步推理 时根据当前目标、工作流阶段与用户输入,重新组装上下文,确保信息及时、对齐。
上下文工程位于记忆、知识与编排的交汇处 :编排决定要走哪些步骤;上下文工程确保每一步拥有正确的信息 以有效执行。随着基础模型不断进步,智能体系统设计的前沿正从模型架构 转向我们提供的上下文质量 。本质上,良好工程化的上下文能释放哪怕相对小型模型的全部潜力;而糟糕的上下文则会拖累最先进的模型。
掌握上下文工程,开发者就能构建既技术强大 又可靠、扎实、对环境与用户需求高度响应 的智能体。未来几年,随着记忆系统、检索架构与编排框架的演化,上下文工程将继续充当把这些组件粘合成无缝、有效体验的关键。
结论(Conclusion)
智能体的成功高度依赖 所采用的编排方法,因此任何希望构建智能体系统的组织,都应投入精力为其用例设计合适的规划策略。以下是设计规划系统的一些最佳实践:
- 平衡时延与准确率:两者存在明确权衡,请结合你的系统目标与约束做出取舍。
- 评估典型动作数:你的用例通常需要多少步动作?动作越多,规划方法往往需要越复杂。
- 评估对结果的适应需求 :如果后续步骤需根据前序结果显著调整 ,请选择支持增量调整计划的技术。
- 建立代表性测试集:用一组贴近真实的测试用例评估不同规划方案,找到最契合的。
- 从最简单可行的方案开始:满足需求即可,避免过度设计。
在为你的场景选定合适的编排方法后,我们将进入工作流的下一部分:记忆(Memory) 。建议小步起步 :从设计良好的场景与更简单的编排方式开始,随后按需逐步提升 复杂度。下一章将探讨记忆如何进一步增强智能体的能力------帮助其回忆知识 、在交互间保持上下文 ,并以更高的智能性与个性化完成任务。