目录
[2.1 开源之前:一个封闭的"黑盒"](#2.1 开源之前:一个封闭的“黑盒”)
[2.2 开源之后:一个开放的"工具箱"](#2.2 开源之后:一个开放的“工具箱”)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 NVIDIA开源Audio2Face模型与SDK
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
引言:我们都见过的"假"数字人
你肯定有过这样的经历:在玩一款游戏或看一段动画时,一个数字角色的配音充满感情,但他的脸却像个不动声色的木偶,嘴巴一张一合,却总感觉和声音对不上拍。这种"声画分离"的尴尬,是通往真实数字世界道路上一个顽固的"拦路虎",也是许多观众和玩家口中的"出戏"瞬间。
长久以来,要制作一套逼真、自然的面部动画,尤其是与口型精准同步的动画,是一项极其耗时耗力的"手艺活"。动画师需要对着音频,一帧一帧地精雕细琢,成本高昂,周期漫长。
而现在,NVIDIA(英伟达)投下了一颗重磅炸弹,决心要让这种"木偶嘴"成为历史。**他们正式将其AI驱动的面部动画技术------Audio2Face------完全开源。**这意味着,从今往后,创造一张会说话、有表情、有灵魂的"脸",门槛被前所未有地拉低了。这不仅仅是送给开发者的一份大礼,更可能是一个新时代的开端。
一、Audio2Face究竟是什么"黑科技"?
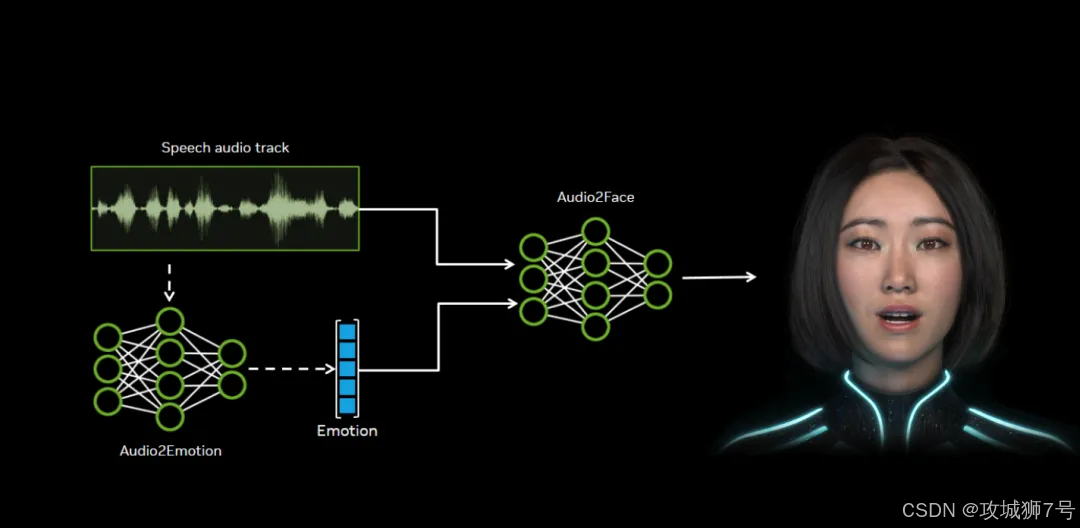
简单来说,Audio2Face是一个"听声识面"的AI。你给它一段音频,它就能自动为你的3D模型生成一套栩栩如生的面部动画。但它的高明之处,远不止"对口型"那么简单。
它的工作原理可以分为两个层面:
(1)科学的口型同步: AI会深度分析音频中的音素(构成语音的最小单位)。比如,当你说出"你好"(nǐ hǎo)时,模型知道你的嘴唇应该如何从发"n"音的舌尖抵住上颚,过渡到发"i"音的咧开,再到发"h"音的送气和发"ǎo"音的圆唇。它能精准捕捉这些微小的肌肉运动,生成与任何语言(无论是中文、英文还是法语)都高度匹配的口型。
(2)艺术的情感表达: 更进一步,Audio2Face还能听出声音里的"戏"。**它会分析音频的语调、节奏和音量,并从中推断出说话者的情感。**当声音高昂兴奋时,角色的眉毛可能会上扬,眼睛会睁大;当语气低沉悲伤时,嘴角则会自然下垂。它驱动的是一整套面部肌肉的联动,而不仅仅是嘴巴。
最终,这些分析结果被转换成动画数据,可以驱动3D模型的网格、骨骼或融合形状(BlendShape),让角色真正"活"起来。

二、"免费"与"开源":一字之差,天壤之别
在这次官宣之前,很多开发者其实已经通过NVIDIA的Omniverse平台免费用上了Audio2Face。这让不少人感到困惑:"既然我一直在用,那这次开源到底有什么不同?"
这里的区别,是"使用权"和"所有权"的区别,也是"黑盒"与"工具箱"的区别。
2.1 开源之前:一个封闭的"黑盒"
在此之前,你得到的是一个预编译好的软件。它功能强大,但你无法看到其内部的源代码、模型结构和训练方法。你只能在NVIDIA为你划定的框架内使用它,就像使用一台功能固定的微波炉,能加热食物,但你无法改造它让它学会制冷。对于想脱离Omniverse平台,或想根据特定需求(比如一种独特的方言、一种非人类角色的口型)定制模型的开发者来说,这扇门是紧闭的。
2.2 开源之后:一个开放的"工具箱"
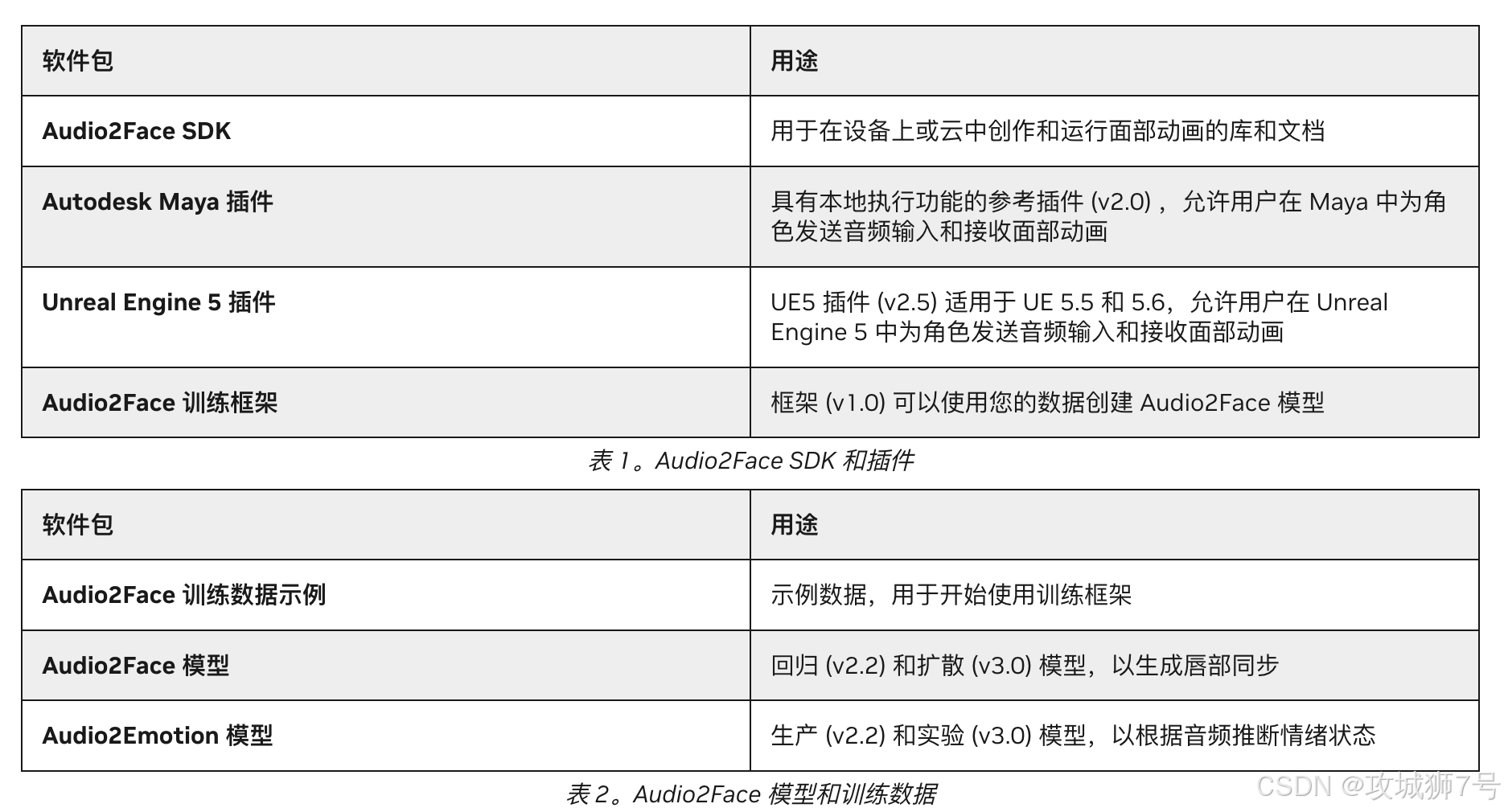
现在,NVIDIA把整个"微波炉"的设计图纸、核心零件和组装说明书(即模型、SDK和训练框架)全部公之于众,并采用了极其宽松的MIT许可。这意味着:
**(1)你可以"魔改":**你可以直接修改它的核心代码,优化算法,或者为它添加全新的功能。
**(2)你可以"另起炉灶":**你可以用自己的数据(比如特定演员的面部数据或一种罕见的语言)来重新训练或微调模型,打造一个专属的、更符合你项目风格的Audio2Face。
**(3)你可以"随处安家":**你不再被绑定在Omniverse生态系统里。开发者可以轻松地将Audio2Face的核心技术集成到任何他们想去的地方,比如主流的游戏引擎Unreal Engine、Unity,或者其他3D软件中。
从一个封闭的工具,到一个开放的、可被社区共同建设的平台,这才是本次开源最核心的价值。
三、为不同需求的开发者,提供不同的"利器"
考虑到不同开发者的使用场景,开源后的Audio2Face生态提供了两种主要的集成方式:
(1)Audio2Face-3D SDK:为"动手派"准备的核心引擎
这是一个强大的C++库,适合那些希望将Audio2Face的实时推理能力深度集成到自己软件中的开发者。你可以把它看作是汽车的"发动机"。如果你正在构建自己的游戏引擎、渲染器或自定义的动画工具,这个SDK能让你直接把Audio2Face的核心功能无缝植入其中,实现最高的性能和最灵活的控制。
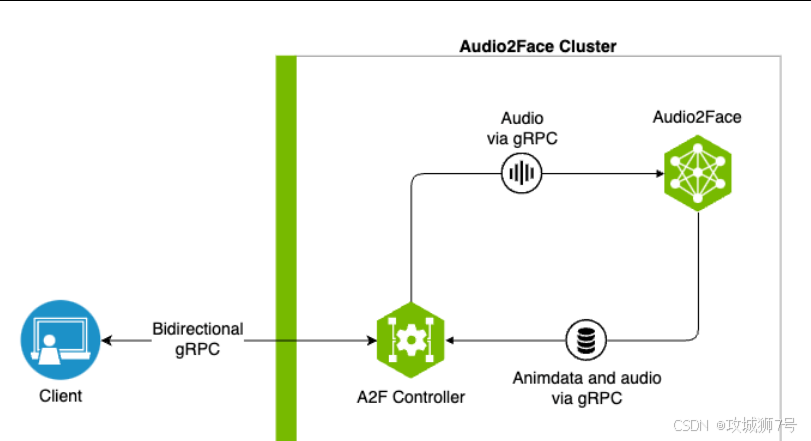
(2)Audio2Face NIM:为"效率派"打造的共享服务中心
NIM全称是NVIDIA Inference Microservice,它是一个容器化的、可扩展的微服务。你可以把它想象成一个工作室的"中央厨房"。你只需在一台强大的服务器上部署好NIM,团队里的所有动画师或开发者,无论用的是什么客户端电脑,都可以通过网络同时连接到这个服务,实时生成面部动画。它非常适合多用户协作的大型项目、云应用或为整个工作室提供统一的动画解决方案,极大地提高了资源利用效率。
四、一场席卷数字内容创作的效率革命
Audio2Face的全面开源,其影响将迅速渗透到数字内容创作的各个角落。
**(1)对于游戏行业:**这意味着制作成千上万句NPC对话的口型动画,成本和时间将被压缩到原来的几分之一。开发者可以把更多精力投入到玩法和故事本身,同时为玩家带来更具沉浸感的互动体验。像《F1 25》、《切尔诺贝利人2》等游戏已经从中受益。
**(2)对于影视和虚拟制作:**导演可以在拍摄现场实时看到由配音驱动的虚拟角色表演,大大加快了创意的迭代速度。过去需要数周的动画预览,现在可能几分钟就能完成。
**(3)对于数字人和虚拟主播:**实时互动的真实感将达到新的高度。虚拟客服的声音将拥有与之匹配的、更富人情味的表情;虚拟主播可以与观众进行更自然、更有感染力的实时交流。
**(4)对于个人创作者和小团队:**这无疑是最大的福音。过去,高质量的面部动画是只有大型工作室才能负担的奢侈品。现在,任何一个有创意的独立开发者,都能利用这项技术,创造出具有专业水准的角色动画,真正实现了技术的"民主化"。
结语:当技术退后,创意向前
NVIDIA将Audio2Face开源,并非一时兴起,而是其推动"AI重塑各行各业"战略的一部分。通过开放核心技术,NVIDIA正在构建一个良性循环:开发者社区的参与会为其增添更多功能、修复问题、拓展应用场景,而这又会进一步加速AI驱动的虚拟形象在各领域的普及,最终扩大整个市场的蛋糕。
当创造一张会说话、有表情的脸,变得像用美图秀秀处理一张照片一样简单时,技术的壁垒便悄然消融。创作者们终于可以从繁琐的技术实现中解放出来,将全部的精力倾注于故事、角色和情感的表达上。
一个更加鲜活、更具表现力的数字世界,正随着这样的技术开放,加速向我们走来。而这一次,数字角色的脸上,将真正拥有"灵魂"。
开源地址: https://github.com/NVIDIA/Audio2Face-3D
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!