✨作者主页 :IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍
本系统是一个基于大数据技术的全球产品库存数据分析与可视化系统,采用Hadoop+Spark大数据框架作为核心数据处理引擎,结合Python/Java语言开发模式,构建了完整的数据分析生态。系统后端采用Django/Spring Boot双框架支撑,前端运用Vue+ElementUI+Echarts技术栈实现交互式数据可视化。通过HDFS分布式存储海量库存数据,利用Spark SQL进行高效的数据查询和计算,结合Pandas、NumPy进行深度数据分析。系统核心功能涵盖产品时效性分析、库存价格结构分析、销售风险评估和仓储优化分析四大模块,能够实时监控全球范围内的产品库存状态,预警临期产品风险,识别滞销商品,优化仓储空间配置。系统通过MySQL数据库存储结构化数据,配合大数据平台处理非结构化数据,实现了从数据采集、清洗、分析到可视化展示的全流程自动化处理,为企业库存管理决策提供了科学的数据支撑和直观的可视化界面。
选题背景
随着全球贸易一体化进程的加速和电子商务的蓬勃发展,现代企业面临着前所未有的库存管理挑战。全球化供应链使得产品种类急剧增加,库存数据呈现出海量化、多样化和实时性的特点,传统的库存管理方式已经难以满足现代企业精细化运营的需求。许多企业在库存管理中普遍存在库存积压、资金占用过多、产品过期损失等问题,这些问题不仅影响企业的运营效率,还直接关系到企业的盈利能力和市场竞争力。与此同时,大数据技术的快速发展为解决这些问题提供了新的技术路径,Hadoop、Spark等大数据处理框架能够高效处理海量库存数据,而机器学习和数据挖掘技术则能够从复杂的数据中发现有价值的规律和趋势。在这样的背景下,构建一个基于大数据技术的库存分析系统,能够帮助企业更好地理解和管理其全球库存资源。
选题意义
本课题的研究具有重要的理论价值和实践意义。从理论角度来看,通过将大数据技术与库存管理理论相结合,探索了新的数据分析方法在供应链管理中的应用,丰富了库存管理的理论体系。从实践角度来看,本系统能够帮助企业实现库存数据的智能化分析,通过产品时效性分析功能,企业可以及时发现临期产品并制定相应的处理策略,有效减少过期损失;通过销售风险分析,能够识别滞销产品和畅销缺货风险,指导企业调整采购和销售策略;通过仓储优化分析,可以提升仓库空间利用效率,降低仓储成本。系统的可视化功能使得复杂的数据分析结果能够直观地展示给管理者,提高了决策效率。虽然本系统作为毕业设计在功能和规模上有一定局限性,但它为中小企业提供了一个可行的库存管理解决方案,对推动传统库存管理向智能化转型具有一定的参考价值和示范意义。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的全球产品库存数据分析与可视化系统界面展示:
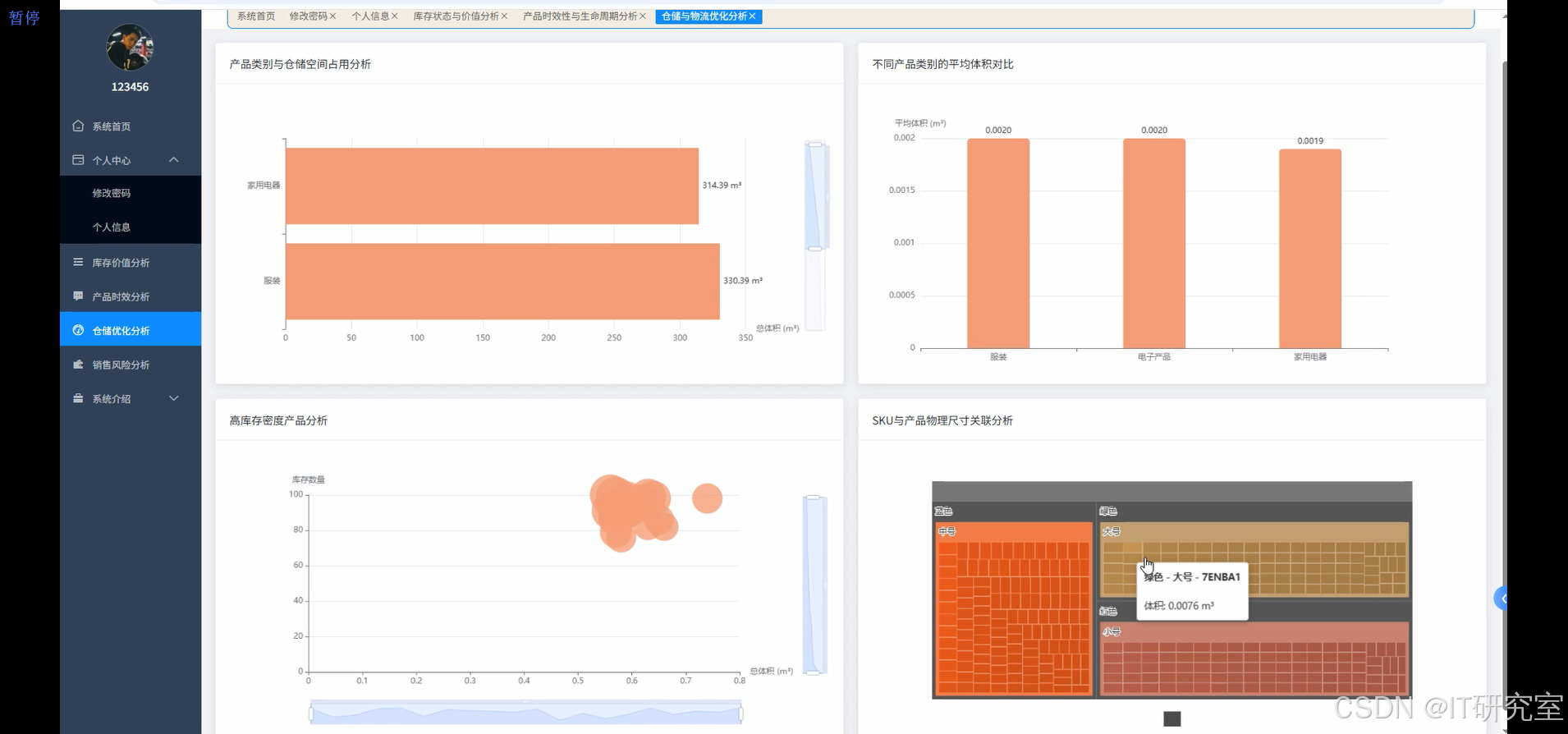
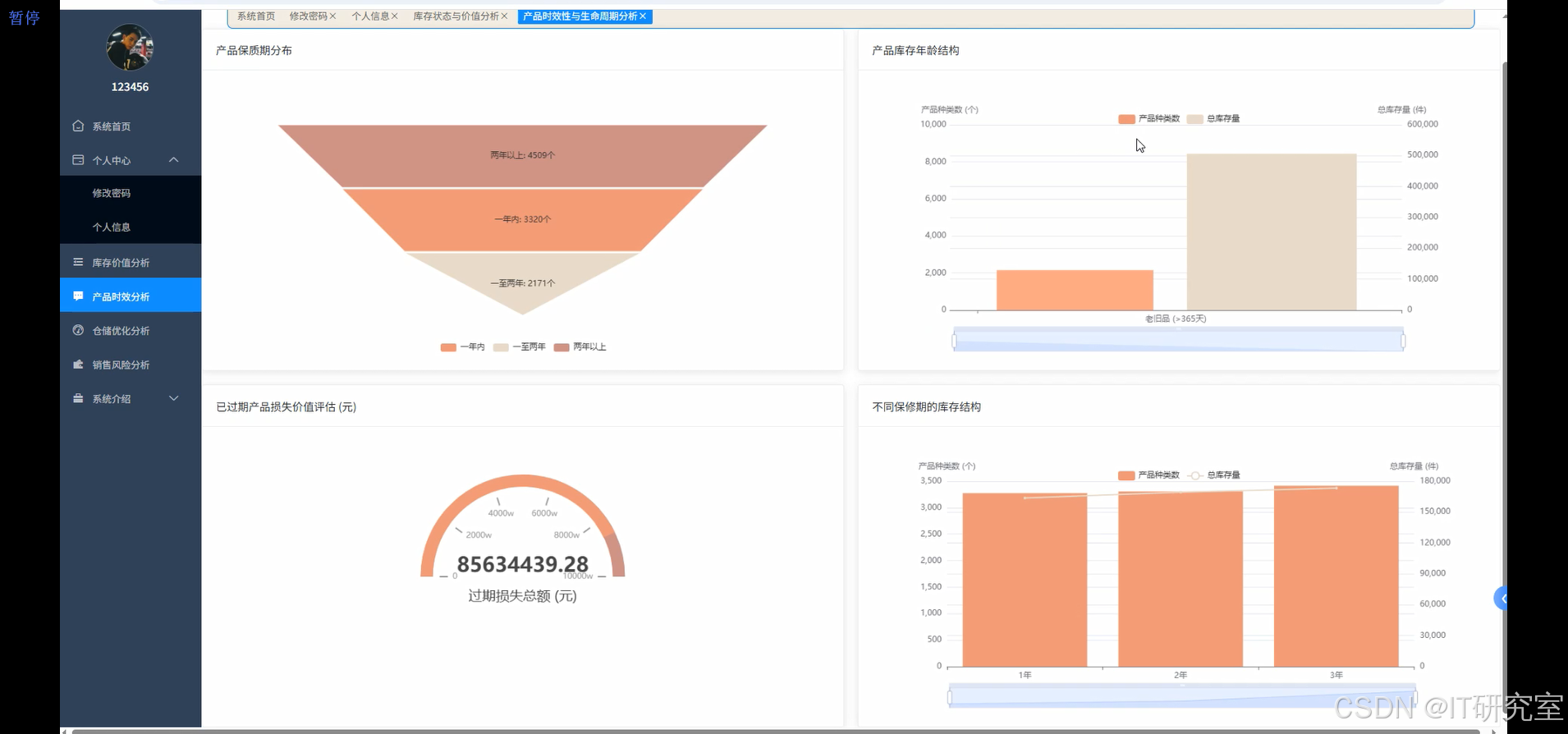
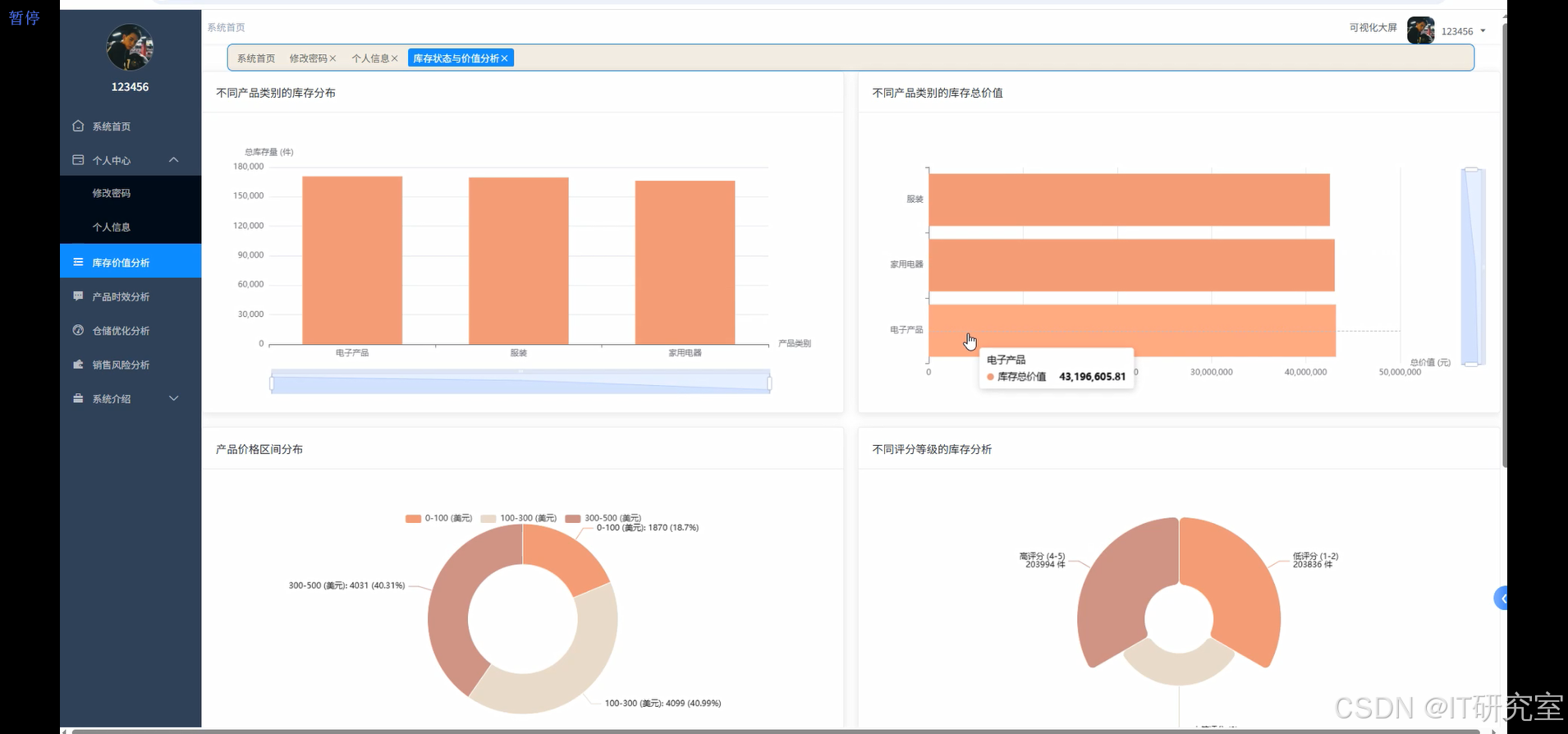
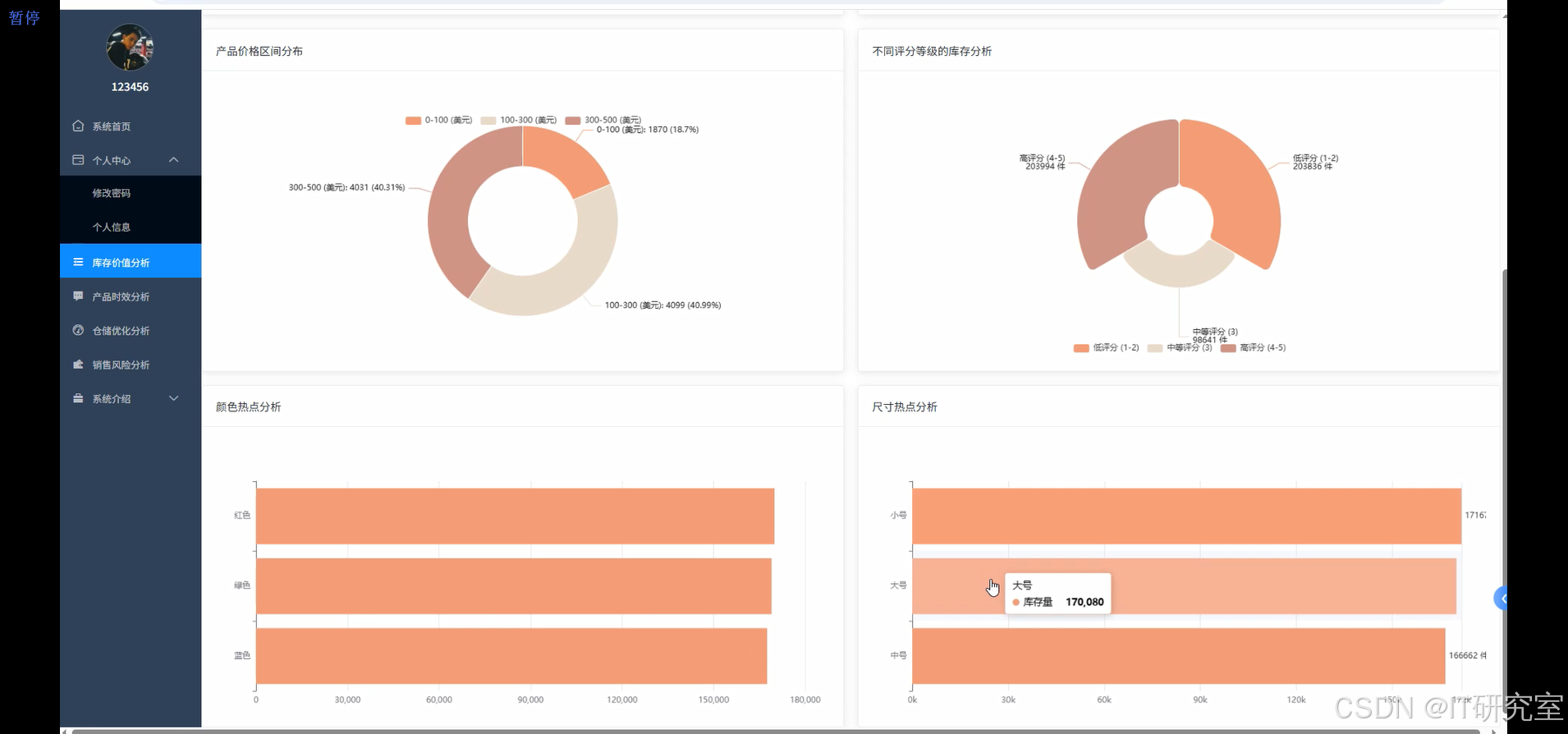
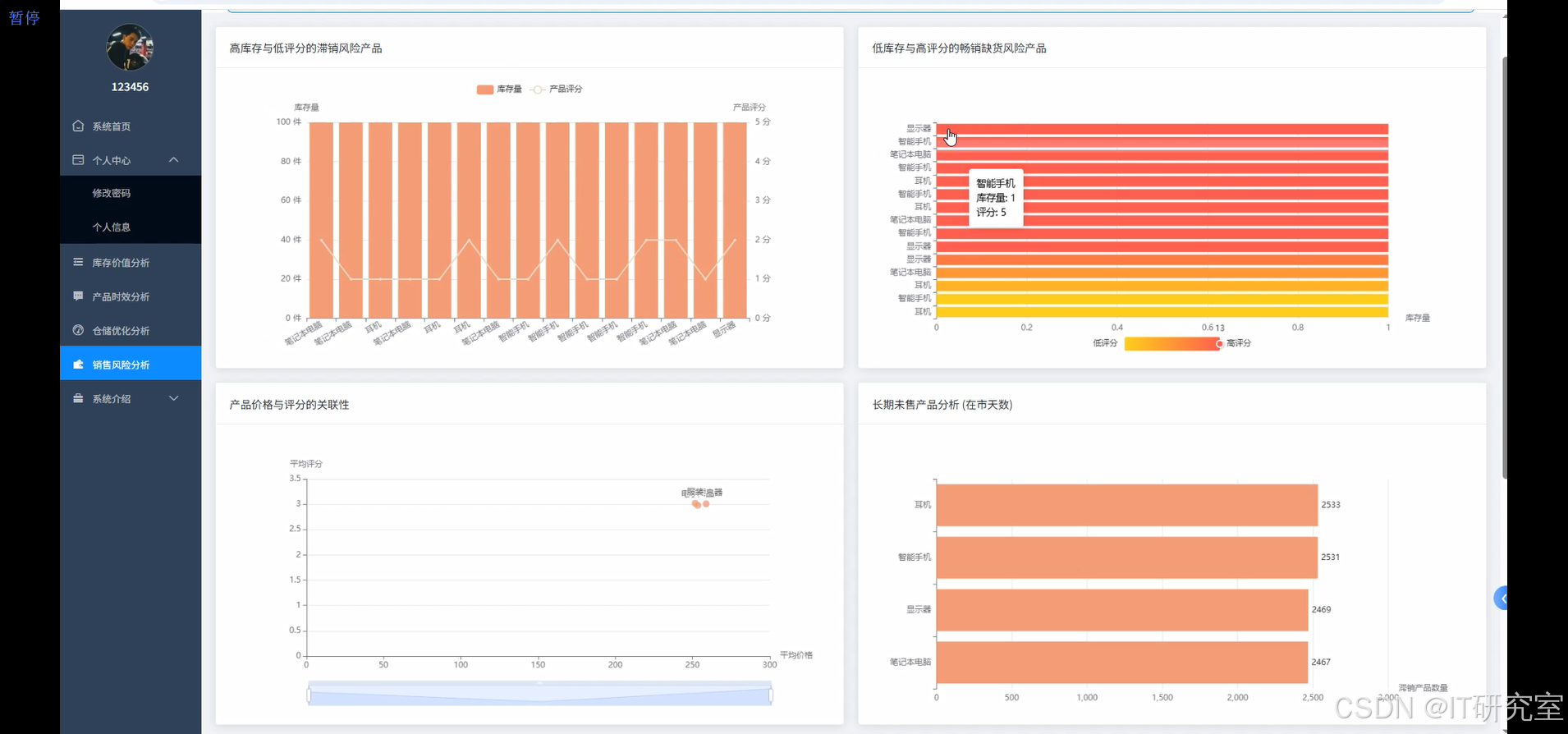
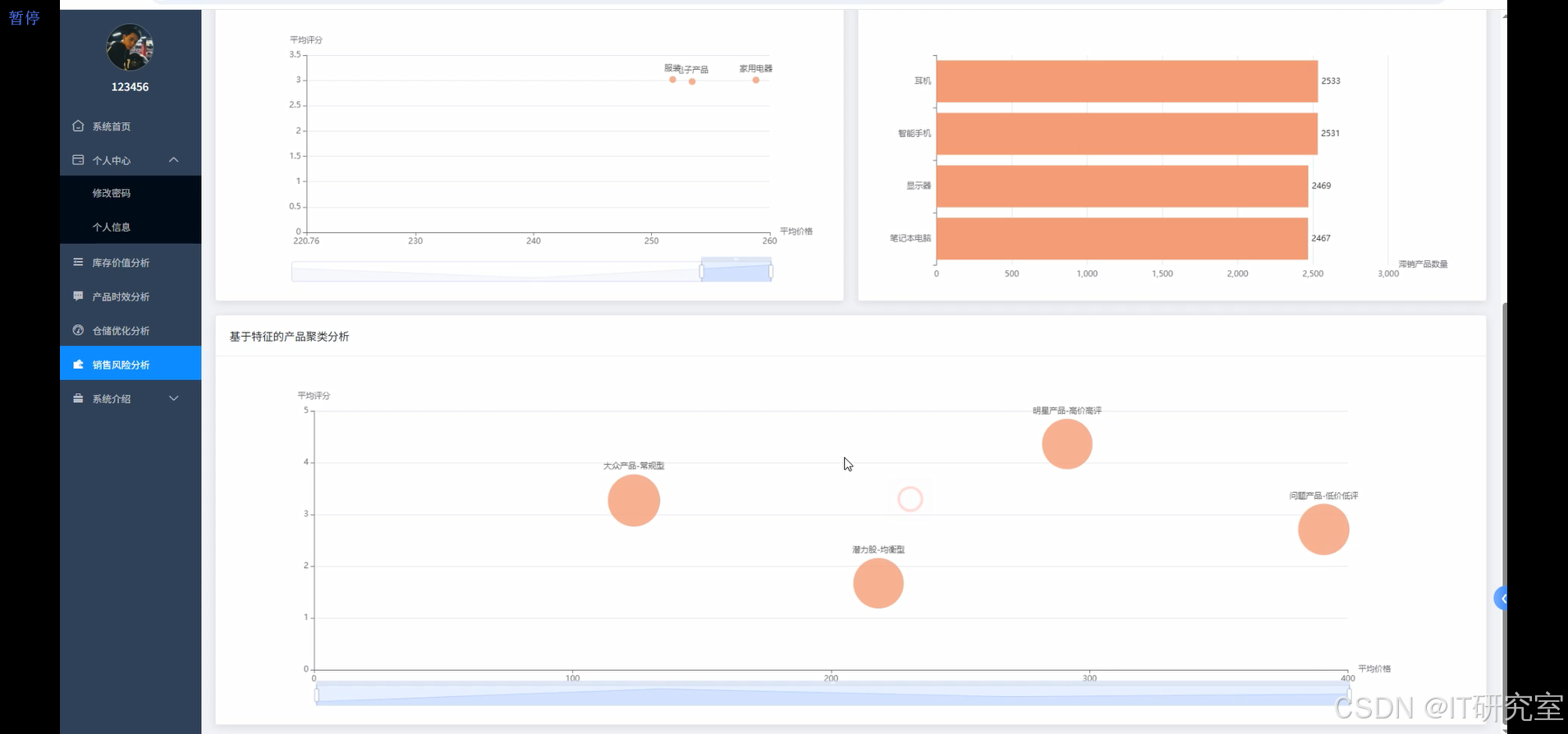
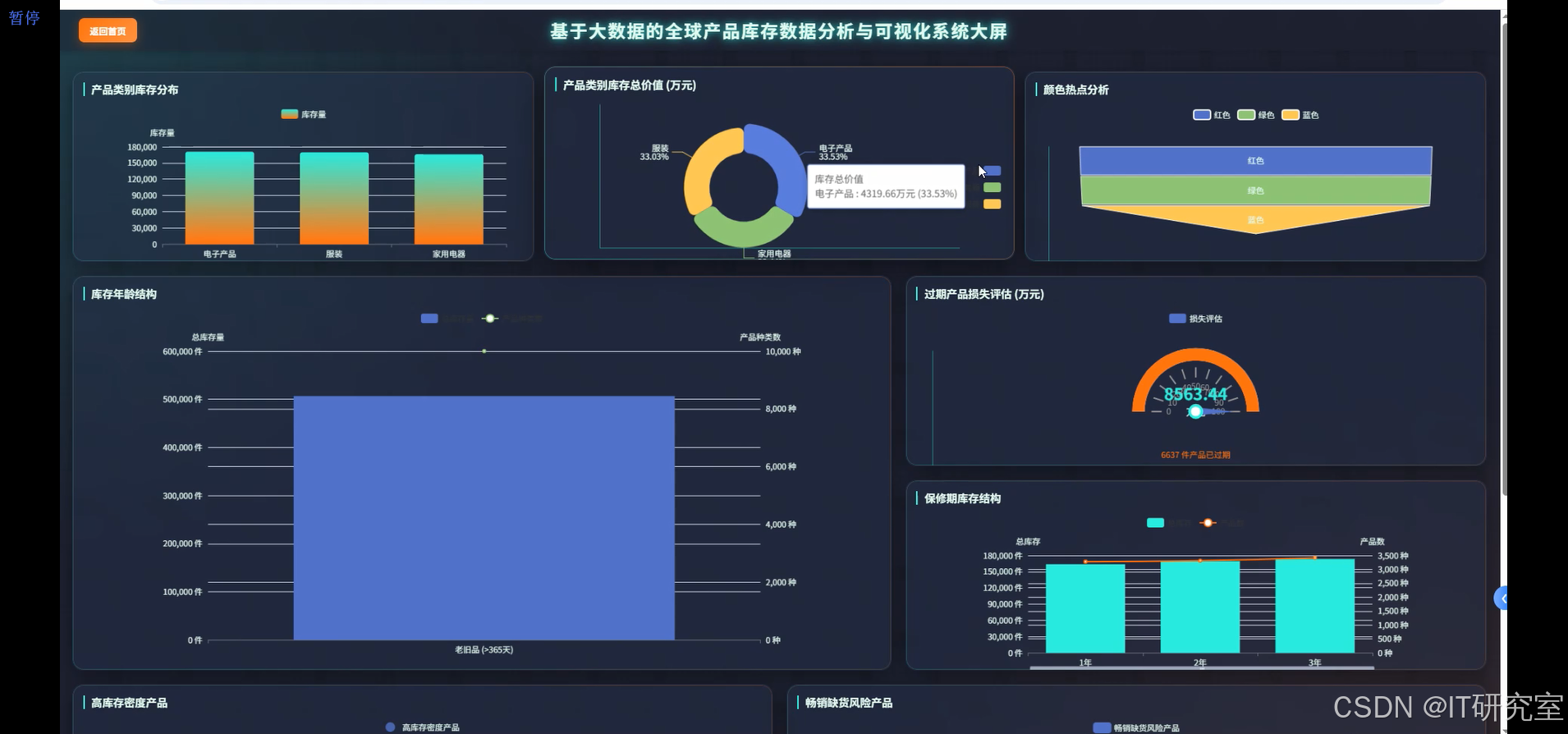
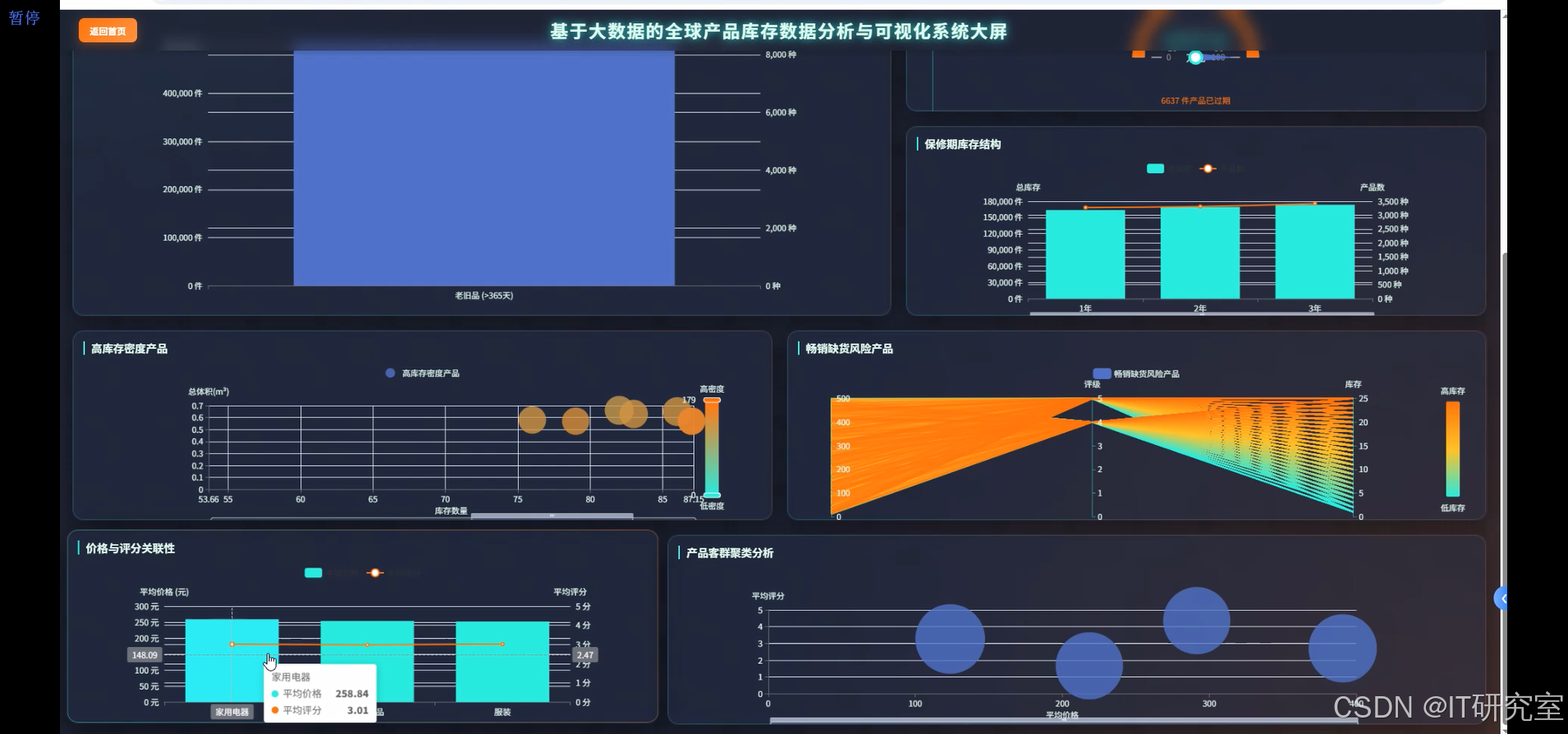
四、代码参考
- 项目实战代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from sklearn.cluster import KMeans
spark = SparkSession.builder.appName("InventoryAnalysisSystem").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def expiry_risk_analysis(df):
current_date = datetime.now()
df = df.withColumn("expiry_date_parsed", to_date(col("expiration_date"), "yyyy-MM-dd"))
df = df.withColumn("manufacturing_date_parsed", to_date(col("manufacturing_date"), "yyyy-MM-dd"))
df = df.withColumn("days_to_expiry", datediff(col("expiry_date_parsed"), lit(current_date)))
df = df.withColumn("shelf_life_days", datediff(col("expiry_date_parsed"), col("manufacturing_date_parsed")))
df = df.withColumn("total_value", col("price") * col("stock_quantity"))
risk_products = df.filter(col("days_to_expiry") <= 30).filter(col("days_to_expiry") >= 0)
expired_products = df.filter(col("days_to_expiry") < 0)
expired_loss = expired_products.agg(sum("total_value").alias("total_expired_loss")).collect()[0]["total_expired_loss"]
risk_summary = risk_products.groupBy("product_category").agg(
count("*").alias("risk_product_count"),
sum("stock_quantity").alias("total_risk_quantity"),
sum("total_value").alias("total_risk_value"),
avg("days_to_expiry").alias("avg_days_to_expiry")
).orderBy(desc("total_risk_value"))
shelf_life_analysis = df.groupBy("product_category").agg(
avg("shelf_life_days").alias("avg_shelf_life"),
min("shelf_life_days").alias("min_shelf_life"),
max("shelf_life_days").alias("max_shelf_life")
)
urgent_products = risk_products.filter(col("days_to_expiry") <= 7).select(
"product_name", "product_category", "days_to_expiry", "stock_quantity", "total_value"
).orderBy("days_to_expiry")
expiry_trend = df.withColumn("expiry_month", date_format(col("expiry_date_parsed"), "yyyy-MM")).groupBy("expiry_month").agg(
count("*").alias("products_expiring"),
sum("total_value").alias("value_at_risk")
).orderBy("expiry_month")
result_dict = {
"expired_loss": expired_loss if expired_loss else 0,
"risk_summary": risk_summary.toPandas().to_dict('records'),
"shelf_life_analysis": shelf_life_analysis.toPandas().to_dict('records'),
"urgent_products": urgent_products.toPandas().to_dict('records'),
"expiry_trend": expiry_trend.toPandas().to_dict('records')
}
return result_dict
def sales_risk_analysis(df):
df = df.withColumn("total_value", col("price") * col("stock_quantity"))
avg_stock = df.agg(avg("stock_quantity")).collect()[0][0]
avg_rating = df.agg(avg("product_ratings")).collect()[0][0]
high_risk_products = df.filter((col("stock_quantity") > avg_stock) & (col("product_ratings") < avg_rating))
high_opportunity_products = df.filter((col("stock_quantity") < avg_stock * 0.5) & (col("product_ratings") > avg_rating))
manufacturing_df = df.withColumn("manufacturing_date_parsed", to_date(col("manufacturing_date"), "yyyy-MM-dd"))
manufacturing_df = manufacturing_df.withColumn("days_since_manufacturing", datediff(lit(datetime.now()), col("manufacturing_date_parsed")))
stagnant_products = manufacturing_df.filter(col("days_since_manufacturing") > 180).filter(col("stock_quantity") > avg_stock)
price_rating_correlation = df.groupBy("product_category").agg(
corr("price", "product_ratings").alias("price_rating_correlation"),
avg("price").alias("avg_price"),
avg("product_ratings").alias("avg_rating"),
count("*").alias("product_count")
)
risk_matrix = df.withColumn(
"risk_score",
when((col("stock_quantity") > avg_stock) & (col("product_ratings") < 3), 5)
.when((col("stock_quantity") > avg_stock) & (col("product_ratings") < avg_rating), 4)
.when(col("stock_quantity") > avg_stock, 3)
.when(col("product_ratings") < 3, 3)
.otherwise(1)
).withColumn(
"opportunity_score",
when((col("stock_quantity") < avg_stock * 0.3) & (col("product_ratings") > 4), 5)
.when((col("stock_quantity") < avg_stock * 0.5) & (col("product_ratings") > avg_rating), 4)
.when(col("product_ratings") > 4, 3)
.otherwise(1)
)
features_df = df.select("price", "stock_quantity", "product_ratings", "warranty_period").fillna(0)
pandas_features = features_df.toPandas()
feature_matrix = pandas_features[['price', 'stock_quantity', 'product_ratings', 'warranty_period']].values
normalized_features = (feature_matrix - feature_matrix.mean(axis=0)) / feature_matrix.std(axis=0)
kmeans = KMeans(n_clusters=4, random_state=42, n_init=10)
clusters = kmeans.fit_predict(normalized_features)
df_with_clusters = df.withColumn("row_id", monotonically_increasing_id())
cluster_df = spark.createDataFrame([(int(i), int(cluster)) for i, cluster in enumerate(clusters)], ["row_id", "cluster"])
clustered_df = df_with_clusters.join(cluster_df, "row_id")
cluster_analysis = clustered_df.groupBy("cluster").agg(
count("*").alias("product_count"),
avg("price").alias("avg_price"),
avg("stock_quantity").alias("avg_stock"),
avg("product_ratings").alias("avg_rating"),
sum("total_value").alias("total_cluster_value")
)
result_dict = {
"high_risk_products": high_risk_products.select("product_name", "product_category", "stock_quantity", "product_ratings", "total_value").toPandas().to_dict('records'),
"high_opportunity_products": high_opportunity_products.select("product_name", "product_category", "stock_quantity", "product_ratings", "total_value").toPandas().to_dict('records'),
"stagnant_products": stagnant_products.select("product_name", "product_category", "days_since_manufacturing", "stock_quantity", "total_value").toPandas().to_dict('records'),
"price_rating_correlation": price_rating_correlation.toPandas().to_dict('records'),
"cluster_analysis": cluster_analysis.toPandas().to_dict('records'),
"risk_statistics": {
"avg_stock_threshold": avg_stock,
"avg_rating_threshold": avg_rating,
"high_risk_count": high_risk_products.count(),
"opportunity_count": high_opportunity_products.count()
}
}
return result_dict
def warehouse_optimization_analysis(df):
df = df.withColumn("dimensions_array", split(col("product_dimensions"), "x"))
df = df.withColumn("length", regexp_replace(col("dimensions_array")[0], "[^0-9.]", "").cast("double"))
df = df.withColumn("width", regexp_replace(col("dimensions_array")[1], "[^0-9.]", "").cast("double"))
df = df.withColumn("height", regexp_replace(col("dimensions_array")[2], "[^0-9.]", "").cast("double"))
df = df.withColumn("volume_per_unit", col("length") * col("width") * col("height") / 1000000)
df = df.withColumn("total_volume", col("volume_per_unit") * col("stock_quantity"))
df = df.withColumn("total_value", col("price") * col("stock_quantity"))
df = df.withColumn("value_density", col("total_value") / (col("total_volume") + 0.001))
category_space_analysis = df.groupBy("product_category").agg(
sum("total_volume").alias("total_category_volume"),
avg("volume_per_unit").alias("avg_unit_volume"),
sum("stock_quantity").alias("total_quantity"),
sum("total_value").alias("total_category_value"),
count("*").alias("product_types")
).withColumn("volume_percentage", col("total_category_volume") / sum("total_category_volume").over(Window.partitionBy())).orderBy(desc("total_category_volume"))
high_density_products = df.filter(col("total_volume") > df.agg(avg("total_volume")).collect()[0][0]).orderBy(desc("total_volume"))
space_efficiency = df.withColumn(
"efficiency_score",
when(col("value_density") > 1000, 5)
.when(col("value_density") > 500, 4)
.when(col("value_density") > 100, 3)
.when(col("value_density") > 50, 2)
.otherwise(1)
)
efficiency_summary = space_efficiency.groupBy("efficiency_score").agg(
count("*").alias("product_count"),
sum("total_volume").alias("total_volume_used"),
sum("total_value").alias("total_value_stored")
).orderBy(desc("efficiency_score"))
sku_analysis = df.filter(col("color_size_variations").isNotNull()).withColumn("variation_count", size(split(col("color_size_variations"), ","))).groupBy("product_category").agg(
avg("variation_count").alias("avg_variations_per_product"),
sum(col("variation_count") * col("stock_quantity")).alias("total_sku_units"),
avg("volume_per_unit").alias("avg_sku_volume")
)
storage_recommendations = df.withColumn(
"storage_priority",
when((col("total_volume") > df.agg(avg("total_volume")).collect()[0][0]) & (col("value_density") < 100), "High Priority - Large Low-Value")
.when(col("value_density") > 1000, "Premium Storage - High Value")
.when(col("total_volume") < 0.001, "Compact Storage")
.otherwise("Standard Storage")
).groupBy("storage_priority", "product_category").agg(
count("*").alias("product_count"),
sum("total_volume").alias("volume_required"),
sum("total_value").alias("value_stored")
)
volume_distribution = df.withColumn(
"volume_tier",
when(col("volume_per_unit") < 0.001, "Extra Small")
.when(col("volume_per_unit") < 0.01, "Small")
.when(col("volume_per_unit") < 0.1, "Medium")
.when(col("volume_per_unit") < 1.0, "Large")
.otherwise("Extra Large")
).groupBy("volume_tier").agg(
count("*").alias("product_count"),
sum("stock_quantity").alias("total_units"),
sum("total_volume").alias("total_tier_volume")
).orderBy("volume_tier")
result_dict = {
"category_space_analysis": category_space_analysis.toPandas().to_dict('records'),
"high_density_products": high_density_products.select("product_name", "product_category", "total_volume", "value_density", "stock_quantity").limit(20).toPandas().to_dict('records'),
"efficiency_summary": efficiency_summary.toPandas().to_dict('records'),
"sku_analysis": sku_analysis.toPandas().to_dict('records'),
"storage_recommendations": storage_recommendations.toPandas().to_dict('records'),
"volume_distribution": volume_distribution.toPandas().to_dict('records'),
"warehouse_metrics": {
"total_warehouse_volume": df.agg(sum("total_volume")).collect()[0][0],
"total_products": df.count(),
"avg_value_density": df.agg(avg("value_density")).collect()[0][0]
}
}
return result_dict五、系统视频
基于大数据的全球产品库存数据分析与可视化系统项目视频:
大数据毕业设计选题推荐-基于大数据的全球产品库存数据分析与可视化系统-大数据-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的全球产品库存数据分析与可视化系统-大数据-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说~ 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇