发送处理(Tx Handling)
概述
本文基于Bosch的《M_CAN Controller Area Network User's Manual》
定位
-
Tx Handling(发送处理)是 M_CAN 发送链路的 "中枢",由Tx Handler(发送处理器) 主导
-
负责协调 "消息存储载体(专用 Tx Buffer/Tx FIFO/Tx Queue)" 与 "CAN Core(CAN 核心协议单元)" 之间的数据流
-
确保消息按优先级、无冲突地传输到 CAN 总线
-
作用
-
"平衡 Host CPU 的消息配置速度" 与 "CAN 总线的实际传输速率"
-
同时支持灵活的传输模式(Classic CAN/CAN FD)
-
职责与硬件
-
硬件资源
-
Tx Buffer 总数
-
最多支持32 个 Tx Buffer,可灵活配置为
-
"专用 Tx Buffer"
-
"Tx FIFO 元素"
-
"Tx Queue 元素"
-
-
-
传输模式配置
-
每个 Tx Buffer 的传输模式(Classic CAN / CAN FD)可独立配置
-
由 "CCCR 寄存器的全局配置" 与 "Tx Buffer 元素的局部配置" 共同决定
-
-
-
传输模式配置
-
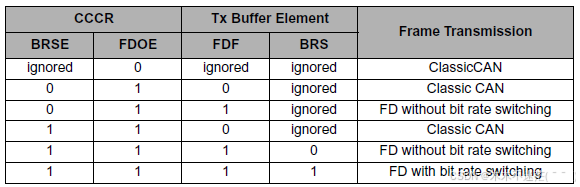
|CCCR 寄存器(全局控制)|Tx Buffer 元素(局部控制)|帧传输格式|
Possible Configurations for Frame Transmission
-
CCCR 配置
- BRSE = 任意,FDOE=0
-
Tx Buffer 元素配置
- FDF = 任意,BRS = 任意
-
CCCR 配置
- BRSE=0,FDOE=1
-
Tx Buffer 元素配置
- FDF=1,BRS = 任意
-
CCCR 配置
- BRSE=1,FDOE=1
-
Tx Buffer 元素配置
- FDF=1,BRS=1
-
-
CAN FD 传输的启用需满足 "CCCR.FDOE=1"
-
比特率切换需额外满足 "CCCR.BRSE=1 + Tx Buffer.FDF=1 + Tx Buffer.BRS=1"
-
-
动作
-
接收传输请求
-
处理 Host 通过TXBAR(Tx Buffer Add Request)发起的传输请求
-
或TXBCR(Tx Buffer Cancellation Request)发起的取消请求
-
-
管理消息存储
-
控制 Tx Buffer/FIFO/Queue 中的消息传输到 CAN Core
-
更新TXFQS(Tx FIFO/Queue Status)的 Put/Get 索引
-
-
维护 Tx Event FIFO
-
消息传输后,将 "消息 ID + 时间戳" 存入 Tx Event FIFO
-
供 Host 查询传输状态
-
-
触发 Tx 扫描
-
当TXBRP(Tx Buffer Request Pending)寄存器更新时
-
启动 "Tx 扫描" 找最高优先级的待传输消息
-
-
Tx 扫描(Tx Scan)与优先级管理
-
Tx 扫描是 Tx Handler 实现 "按优先级传输" 的核心机制
-
触发 Tx 扫描的条件
-
Tx 扫描仅在TXBRP寄存器更新时启动,TXBRP更新场景包括:
-
传输完成
-
某 Tx Buffer 的消息成功发送或被取消
-
TXBRP对应位复位
-
-
Host 发起传输
-
Host 向TXBAR写 "1",请求某 Tx Buffer 传输
-
TXBRP对应位置位
-
-
Host 取消传输
-
Host 向TXBCR写 "1",取消某 Tx Buffer 的传输
-
TXBRP对应位复位
-
-
-
-
扫描逻辑
-
找最高优先级的待传输请求
-
M_CAN 的传输优先级由消息 ID 大小决定:
- ID 越小,优先级越高(符合 CAN 协议仲裁规则)
-
Tx 扫描的核心动作:
-
1.遍历TXBRP寄存器中所有置 "1" 的位
- 表示待传输请求
-
2.读取对应 Tx Buffer 的消息 ID
- 存储在 Message RAM 中
-
3.筛选出 ID 最小的 Tx Buffer
- 标记为 "最高优先级待传输请求"
-
4.预加载该 Tx Buffer 的前 4 个 32 位 RAM 字到 "临时缓冲区"
-
目的是加快后续传输
-
当目前传输结束后,可直接从临时缓冲区向 CAN Core 发送数据,减少延迟
-
-
-
-
扫描时间带来的两种场景
-
由于 Tx 扫描需要时间,取决于:
-
Host 时钟频率
-
Tx Buffer 数量
-
共享 Message RAM 的 M_CAN 数量
-
-
可能出现两种情况,需特别注意 "优先级反转" 风险:
-
临时缓冲区预加载完成
-
触发条件
- 扫描 + 预加载在当前传输 / 接收结束前完成
-
结果与影响
- 当前传输一结束,立即启动预加载消息的传输,无优先级问题
-
-
临时缓冲区预加载未完成
-
触发条件
- Tx 扫描 + 临时缓冲区预加载的总耗时,超过当前传输 / 接收的剩余时间
-
结果与影响
-
无法及时启动高优先级消息传输,其他节点可能趁机发送低优先级消息
-
导致 "优先级反转"
- 低优先级消息先于高优先级发送
-
-
-
-
示例
-
M_CAN 的 Tx 扫描需要 5 个 Host 时钟周期,而当前传输仅剩 3 个周期结束,预加载未完成
- M_CAN 的高优先级消息(如 ID=0x001)因未完成预加载,无法在当前传输结束后立即启动
-
其他节点的低优先级消息(如 ID=0x100)检测到总线空闲,无需与 M_CAN 的高优先级消息仲裁,直接插入传输
-
导致 外部优先级反转(outer priority inversion)
- 低优先级消息先于 M_CAN 的高优先级消息发送,区别于 CAN 总线原生的仲裁优先级逻辑
-
-
小结
-
Tx Handler 核心
- 接收传输请求→启动 Tx 扫描找最高优先级(小 ID)→预加载数据→控制传输到 CAN Core
-
注意事项
-
AUTOSAR 合规
-
需配置至少 3 个 Tx Queue Buffer
-
并支持 "传输取消" 功能
- Tx Handler 通过TXBCR处理取消请求
-
-
优先级反转规避
-
设计时需评估 Tx 扫描时间
- 结合 Host 时钟、Tx Buffer 数量
-
尽量让扫描 + 预加载耗时小于最短传输周期
-
-
CAN FD 配置
-
需同时配置 "CCCR.FDOE=1+CCCR.BRSE=1" 与 "Tx Buffer.FDF=1+Tx Buffer.BRS=1"
-
才能启用 CAN FD 比特率切换

-
-
1.传输暂停
(Transmit Pause)
缓解总线占用问题
- Transmit Pause 是针对 "单节点 burst 传输导致总线拥堵" 的优化功能
应用场景
-
解决固定 ID 优先级与实际需求的冲突
-
CAN 协议中,ID 优先级是固定的(小 ID 优先级高)
-
但实际应用中可能出现高优先级 ID 消息连续传输(burst)
-
导致低优先级 ID 消息长期延迟" 的问题
-
-
例如:
-
ECU A 的消息 ID=0x001(高优先级)
- 因应用需求需连续发送 10 条消息
-
ECU B 的消息 ID=0x100(低优先级)
-
需实时发送控制指令,但 ECU A 的 burst 传输占满总线
-
ECU B 的消息延迟超过阈值
-
-
此时需通过 Transmit Pause 调整总线占用,让低优先级消息有机会插入传输
-
工作原理
-
成功传输后等待两个 CAN 位时间
-
Transmit Pause 由CCCR.TXP位控制
-
默认 0 = 禁用,1 = 启用
-
-
启用后的核心逻辑
(含接收消息的特殊规则)
-
成功传输后的常规等待
-
当某 Tx Buffer 的消息成功传输后,M_CAN 不会立即发起下一个传输请求
-
而是等待两个 CAN 位时间的 "总线空闲"
- 即总线持续两个位时间为隐性电平
-
等待结束后,才启动下一个最高优先级消息的传输
-
-
接收消息后的特殊处理
-
若 M_CAN 在等待期间接收到其他节点的消息,无需等待剩余的位时间
-
当接收消息释放 CAN 总线(总线恢复空闲)后
-
可立即启动下一个最高优先级消息的传输,无需再等待两个位时间
-
如 ECU-1 等待期间收到 ECU-B 的消息
-
ECU-B 传输完成后,ECU-1 直接发送下一条消息
-
-
-
-
例如:
-
ECU-1 启用 Transmit Pause 的传输流程
-
假设 CAN 位时间 = 1μs(对应 1Mbps 速率),ECU A需发送 10 条消息
-
1.发送第 1 条消息(ID=0x001)
- 成功后等待 2μs(两个位时间)
-
2.等待期间
- ECU B 的消息(ID=0x100)检测到总线空闲,插入传输
-
3.ECU B 传输完成后,ECU A 继续发送第 2 条消息,重复 "发送→等待 2μs" 流程
-
结果:
- ECU A 的 burst 传输被 "拆分",ECU B 的消息无需长期等待,缓解总线拥堵
-
-
作用
-
缓解单节点 burst 传输
-
避免单个 ECU 的高优先级消息长期占用总线
-
给其他节点 "插空传输" 的机会
-
-
防止 "babbling idiot" 场景
-
若应用程序错误地向 M_CAN 请求大量传输
- 如无限循环请求发送
-
Transmit Pause 可限制传输频率
- 避免总线被无效消息占满
-
小结
-
Transmit Pause 核心
- CCCR.TXP=1→成功传输后等两个位时间→缓解总线拥堵与优先级反转风险
-
注意事项
-
Transmit Pause 适用场景
-
仅当 CAN ID 优先级固定但需灵活调整总线占用时启用
-
若需严格按 ID 优先级传输(如安全相关消息),需禁用(CCCR.TXP=0)
-
-
2.专用发送缓冲区
(Dedicated Tx Buffers)
概述
-
Dedicated Tx Buffers(专用发送缓冲区)是 M_CAN 为需要 CPU 直接、精准控制的发送场景设计的存储单元
-
与 "Tx FIFO(发送先进先出队列)""Tx Queue(发送队列)" 的 "自动顺序处理" 不同:
-
差异
-
CPU 完全掌控
-
每个专用缓冲区绑定固定消息 ID,传输请求由 CPU 主动发起
-
适合 "高优先级、固定 ID、需即时发送" 的场景
-
车载 ECU 的控制指令
-
工业设备的紧急命令帧
-
-
-
-
硬件
-
最多支持32 个专用发送缓冲区(索引 0~31)
-
与 Tx FIFO/Queue 共享 32 个 Tx Buffer 资源
- 需通过TXBC寄存器分配专用缓冲区数量NDTB与 FIFO/Queue 数量TFQS,且两者之和≤32
-
特性
-
绑定 "特定 Message ID",同 ID 按缓冲区编号排序
-
每个 Dedicated Tx Buffer 配置一个特定的 Message ID
- 或一组相同 ID 但需按顺序发送的消息
-
单 ID 绑定
-
1 个专用缓冲区对应 1 个 Message ID
-
CPU 向该缓冲区写入数据后,仅发送该 ID 的消息
-
-
同 ID 优先级
-
若多个专用缓冲区配置相同 Message ID
- 如 Buffer 2 和 Buffer 5 均为 ID=0x005
-
则缓冲区编号更小的优先发送
- Buffer 2 先于 Buffer 5
-
这是专用缓冲区特有的 "次级优先级" 规则
- 补充了 CAN 协议 "ID 小优先级高" 的基础规则
-
-
-
传输请求由 CPU 主动发起:依赖 TXBAR 寄存器
-
专用缓冲区的传输不会自动触发
- 仅当数据段(data section)已更新时,发起请求才有效
-
必须由 CPU 通过TXBAR(Tx Buffer Add Request,地址 0xD0)寄存器发起 "添加请求"
-
流程:
-
1.更新数据
-
CPU 向专用缓冲区的 Message RAM 地址写入完整消息
- ID、DLC、数据字节等
-
-
2.发起请求
-
向TXBAR寄存器的对应位(ARn,n 为缓冲区编号,0~31)写 "1"
-
请求传输该缓冲区的消息
-
-
3.请求置位
-
M_CAN 收到请求后
-
置位TXBRP(Tx Buffer Request Pending,地址 0xCC)的对应位(TRPn)
- 标记 "该缓冲区有未完成的传输请求"
-
-
4.Tx Handler 扫描
-
TXBRP更新后,Tx Handler 启动 "Tx 扫描"
-
筛选出最高优先级的请求
- 按 Message ID 小→同 ID 按缓冲区编号小
-
等待总线空闲后传输
-
-
注意:
- 若TXBRP.TRPn已为 1(已有未完成请求),再写TXBAR.ARn=1会被忽略,避免重复请求
-
-
-
仲裁逻辑:内外竞争均按 Message ID 优先级
-
专用缓冲区的消息在发送前需参与 "两级仲裁"
-
均遵循 CAN 协议的 "ID 越小优先级越高" 规则:
-
内部仲裁
-
与 Tx FIFO/Queue 中的消息竞争
-
Tx Handler 扫描时,同时检查所有有请求的专用缓冲区和 Tx FIFO/Queue 的消息
- 选择 ID 最小的优先传输
-
-
外部仲裁
-
与 CAN 总线上其他节点的消息竞争
-
发送时按 CAN 总线仲裁规则,ID 小的消息优先获得总线控制权
-
若 ID 相同则专用缓冲区的消息与其他节点消息按位仲裁
-
-
-
-
Message RAM 地址计算
-
Tx Buffer / FIFO / Queue Element Size
-
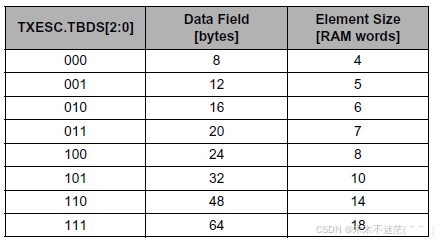
TXESC(Tx Buffer Element Size Configuration,地址 0xC8)的TBDS2:0位决定每个专用缓冲区的 "元素大小"
-
即存储 1 帧消息所需的 32 位 RAM 字数
-
TXESC是全局配置,所有 Tx Buffer(含 FIFO 元素)共用该配置
-
-
-
专用缓冲区在 Message RAM 中的地址需通过 "起始地址 + 索引 × 元素大小" 计算
-
专用缓冲区 n 的起始地址 =
- TXBC.TBSA + n × Element Size
-
TXBC.TBSA
-
Tx Buffers 起始地址,由TXBC寄存器配置,地址 0xC0
-
32 位 "字地址"
- 仅 bit15~bit2 有效,bit1~bit0 忽略
-
-
n
- 专用缓冲区编号(0~31)
-
Element Size
- 由TXESC.TBDS和(Tx Buffer / FIFO / Queue Element Size)图中确定的 32 位 RAM 字数
-
-
示例
-
TXBC.TBSA = 0x200
- Tx Buffer 起始地址为 0x200,32 位字地址
-
专用缓冲区编号 n=2
-
TXESC.TBDS = 000
- 对应 Element Size=4 字,看(Tx Buffer / FIFO / Queue Element Size)图
-
则缓冲区 2 的地址 = 0x200 + 2 × 4 = 0x208(32 位字地址)
- 对应 Message RAM 中存储该缓冲区消息的起始位置
-
-
配置与注意事项
-
关键寄存器配置
-
使用专用发送缓冲区前,需先配置以下寄存器:
-
TXBC(0xC0)
-
配置项
- NDTB5:0
-
作用
-
配置专用发送缓冲区的数量
-
0~32,>32 按 32 处理
-
-
-
TXBC(0xC0)
-
配置项
- TBSA15:2
-
作用
- 配置 Tx Buffer 在 Message RAM 的起始地址
-
-
TXESC(0xC8)
-
配置项
- TBDS2:0
-
作用
-
配置专用缓冲区的 Element Size
-
参考(Tx Buffer / FIFO / Queue Element Size)图
-
-
-
TXBAR(0xD0)
-
配置项
- ARn(n=0~31)
-
作用
- 向对应位写 1,发起专用缓冲区 n 的传输请求
-
-
TXBRP(0xCC)
-
配置项
- TRPn(n=0~31)
-
作用
- 只读,查看专用缓冲区 n 是否有未完成的传输请求(1 = 有请求)
-
-
-
硬件限制与配置约束
-
资源共享
-
32 个 Tx Buffer 需在 "专用缓冲区(NDTB)" 与 "Tx FIFO/Queue(TFQS)" 之间分配
-
两者之和必须≤32(M_CAN 不检查冲突,配置错误会导致数据覆盖)
-
-
数据完整性
-
向专用缓冲区写入数据时,需确保完整
- ID、DLC、数据字节等
-
未写完时不要发起传输请求,避免发送不完整帧
-
-
取消传输
-
若需取消专用缓冲区的传输请求,需向TXBCR(Tx Buffer Cancellation Request,0xD4)的CRn位写 1
-
成功后TXBRP.TRPn复位,TXBCF.CFn置位
- 标记取消完成
-
-
专用发送缓冲区与 Tx FIFO 的核心差异
-
控制方式
-
Dedicated Tx Buffers
-
CPU 完全控制
- 主动发起请求
-
-
Tx FIFO(Tx BC.TFQM=0)
-
自动顺序处理
- 按 Put Index 写入,Get Index 发送
-
-
-
ID 绑定
-
Dedicated Tx Buffers
- 每个缓冲区绑定特定 ID
-
Tx FIFO(Tx BC.TFQM=0)
- 无绑定,按接收顺序存储任意 ID
-
-
优先级规则
-
Dedicated Tx Buffers
- ID 小优先,同 ID 按缓冲区编号小优先
-
Tx FIFO(Tx BC.TFQM=0)
-
按写入顺序
- FIFO 先进先出
-
-
-
适用场景
-
Dedicated Tx Buffers
-
高优先级、固定 ID、需即时控制的消息
- 如控制指令
-
-
Tx FIFO(Tx BC.TFQM=0)
-
批量、无特定 ID 顺序要求的消息
- 如传感器数据
-
-
-
地址访问
-
Dedicated Tx Buffers
-
直接计算地址
- CPU 可随机访问
-
-
Tx FIFO(Tx BC.TFQM=0)
-
按 Get Index 顺序访问
- 不可随机
-
-
小结
-
定位
-
CPU 完全控制的发送存储单元
-
绑定特定 Message ID,适合精准控制场景
-
-
配置
-
通过TXBC设数量和起始地址→
-
TXESC设 Element Size→
- TXBAR发起传输请求
-
-
-
仲裁
-
内外均按 ID 优先级
-
ID 小优先,同 ID 编号小优先
-
-
地址
-
TBSA + 编号×Element Size
- 参考(Tx Buffer / FIFO / Queue Element Size)图
-
-
优势
-
无 FIFO 顺序依赖,CPU 直接掌控
-
适合高优先级固定 ID 消息
-
3.Tx FIFO(发送先进先出队列)
适用场景与配置前提
-
概述
-
Tx FIFO是 M_CAN 为批量、按写入顺序发送的场景设计的发送载体
-
与专用 Tx Buffer 核心差异在于 "自动顺序处理"
- 无需 CPU 为每个消息单独指定发送顺序,按 "先写入、先发送" 自动调度
-
适合无即时优先级要求、需批量传输的场景。
-
-
基础配置:启用 Tx FIFO 模式
-
寄存器TXBC(Tx Buffer Configuration,地址 0xC0)的TFQM位(Tx FIFO/Queue Mode):
-
TFQM = 0
- 启用Tx FIFO 模式
-
TFQM = 1
- 启用 Tx Queue 模式
-
-
资源分配:与专用 Tx Buffer 共享硬件
-
Tx FIFO 与 "专用 Tx Buffer" 共享 M_CAN 的 32 个 Tx Buffer 硬件资源
-
需通过TXBC寄存器明确分配
-
TXBC.TFQS5:0
-
配置 Tx FIFO 的大小
-
1~32,>32 按 32 处理
-
0 表示禁用 FIFO
-
-
-
TXBC.NDTB5:0
-
配置专用 Tx Buffer 的数量
-
1~32,>32 按 32 处理
-
0 表示禁用专用缓冲区
-
-
-
约束
-
TFQS + NDTB ≤ 32
- M_CAN 不检查冲突,配置错误会导致消息覆盖或丢失
-
-
-
核心机制:索引与空闲水位
-
Tx FIFO 的正常工作依赖两个核心索引(Get Index/Put Index)和一个空闲水位(Free Level)
-
三者共同控制 "消息写入位置""下一个发送消息" 和 "剩余存储容量"
-
核心索引:Get Index 与 Put Index
-
两个索引均通过TXFQS寄存器(Tx FIFO/Queue Status,地址 0xC4)读取
-
Get Index
-
寄存器字段
- TXFQS.TFGI4:0
-
核心作用
- 指向 "下一个要发送的 FIFO 元素"
-
操作逻辑
-
每成功发送 1 个消息后,循环递增
- 0→1→...→TFQS-1→0
-
-
-
Put Index
-
寄存器字段
- TXFQS.TFQPI4:0
-
核心作用
- 指向 "下一个可写入的 FIFO 元素位置"
-
操作逻辑
-
每写入 1 个消息后,循环递增
- 0→1→...→TFQPI-1→0
-
-
-
示例:
-
若 Tx FIFO 大小TFQS=4(元素 0~3),初始TFGI=0、TFQPI=0
-
写入 1 个消息→TFQPI=1
-
发送 1 个消息→TFGI=1
-
循环特性:
-
当TFQPI=3时写入→TFQPI=0
-
循环到起始位置
-
-
-
-
空闲水位:Free Level(TFFL)
-
TXFQS.TFFL5:0(Tx FIFO Free Level)表示 Tx FIFO 当前可写入的 "空闲元素数量"
-
是 M_CAN 自动计算的关键参数:
-
计算逻辑
-
TFFL = (TFQPI - TFGI) mod TFQS
-
若TFQPI ≥ TFGI,直接相减
-
若TFQPI < TFGI,则TFQPI + TFQS - TFGI
-
-
-
核心作用
-
防止 FIFO 溢出
-
CPU 写入消息前需检查TFFL,确保写入数量≤TFFL
-
否则会触发 "FIFO 满"(TXFQS.TFQF=1)
-
-
-
示例:
-
TFQS=4,TFGI=2,TFQPI=1
-
因TFQPI < TFGI,TFFL = 1 + 4 - 2 = 3
- 可再写入 3 个元素
-
-
消息处理流程
-
概述
-
Tx FIFO 的完整流程包括 "消息写入→发起传输请求→自动发送→索引更新"
-
需区分 "单个消息" 和 "多个消息" 的场景,同时注意 "FIFO 满" 的处理
-
-
1:消息写入(按 Put Index 定位)
-
CPU 需先将消息写入 Tx FIFO 的 "空闲位置",位置由TFQPI确定
- 包含 ID、DLC、数据字节等
-
且每个 FIFO 元素占用的 RAM 字数由(Tx Buffer / FIFO / Queue Element Size)图定义
-
-
2:发起传输请求(通过 TXBAR 寄存器)
-
写入消息后,需通过TXBAR(Tx Buffer Add Request,地址 0xD0)发起传输请求
-
分 "单个消息" 和 "多个消息" 两种情况:
-
(1)单个消息写入与请求
-
确定目标位置
-
当前TXFQS.TFQPI指向的 FIFO 元素
-
如TFQPI=2,对应 Tx Buffer 2
-
-
发起请求
- 向TXBAR.AR2(ARn 对应 FIFO 元素索引 n)写 "1"
-
索引更新
-
M_CAN 收到请求后
-
TFQPI自动递增 1(如从 2→3)
-
TFFL同步递减 1
-
-
-
-
(2)多个消息写入与请求
-
批量场景
-
需连续写入 n 个消息(如 n=3)
- 并向对应的 n 个 Tx Buffer 发起传输请求
-
起始位置为当前 TXFQS.TFQPI
-
写入 / 请求的 Tx Buffer 为 TFQPI~TFQPI+n-1
- (连续)
-
-
-
写入约束
-
写入数量 n = 请求的 Tx Buffer 数量
- 且必须≤Tx FIFO Free Level(TFFL)
-
TFFL 即当前空闲的 Tx FIFO 元素数量
- 超限会导致 FIFO 满(TXFQS.TFQF=1),无法写入 / 请求
-
-
连续请求
- 向TXBAR的ARTFQPI~ARTFQPI+n-1连续写 "1"
-
索引更新
-
M_CAN 收到请求后,TFQPI 按 n 循环递增
-
如TFQPI=1、n=3→TFQPI=4
-
若TFQS=4则循环为 0
-
-
TFFL 按 n 递减(空闲数量同步减少)
-
-
-
-
-
3:自动发送与索引更新
-
Tx Handler 会自动监控TXBRP(Tx Buffer Request Pending,地址 0xCC)中置位的请求位
-
按 "FIFO 顺序" 处理:
-
1.选择发送
-
优先发送TFGI指向的 FIFO 元素
-
遵循 "先写入、先发送"
-
-
2.总线仲裁
-
该元素的消息参与 CAN 总线仲裁
- ID 越小优先级越高
-
仲裁成功后发送
-
-
3.索引递增
-
发送完成后
-
TFGI自动递增 1(循环递增)
-
TFFL同步递增 1
-
-
-
4.空状态
-
当TFGI = TFQPI时
-
TFFL = TFQS(FIFO 空),停止发送
-
-
-
-
4:FIFO 满处理(TFQF=1)
-
当TFQPI = TFGI且已写入TFQS个元素时
-
TXFQS.TFQF(Tx FIFO Full)置位 "1",表示 FIFO 满:
-
禁止写入
-
此时不可再向 FIFO 写入消息
-
否则会覆盖未发送的消息
- M_CAN 不保护冲突数据
-
-
恢复写入
-
需等待至少 1 个消息发送完成(TFGI递增)
-
TFQPI ≠ TFGI后,TFQF复位为 0,TFFL恢复为正值,方可继续写入
-
-
-
传输取消规则(Tx FIFO 不支持传输取消)
-
核心限制
-
传输取消(TXBCR)不针对 Tx FIFO 设计
-
禁止通过 TXBCR 取消 FIFO 中任何元素的传输
-
否则可能导致 FIFO 索引混乱或消息发送异常
-
-
特殊说明
-
仅当 Tx FIFO 与专用 Tx Buffer 混合配置时
-
对 "TFGI 指向的 FIFO 元素" 的取消请求才会触发 TFGI 递增
-
但此场景非 Tx FIFO 独立使用的标准流程,不建议主动操作
-
-
若需停止 FIFO 传输
-
建议通过 "禁止新请求写入(监控 TFFL=0)+ 等待已请求消息发送完成" 的方式
-
而非 TXBCR 取消
-
-
元素的地址计算
-
Tx FIFO 元素在 Message RAM 中的地址需通过 "起始地址 + Put Index× 元素大小" 计算
-
核心依赖TXBC.TBSA(Tx Buffer 起始地址)和(Tx Buffer / FIFO / Queue Element Size)图
-
地址计算公式
-
FIFO 元素 n 的起始 RAM 地址 =
- TXBC.TBSA + TXFQS.TFQPI × 元素大小
-
TXBC.TBSA
-
Tx Buffer 在 Message RAM 的起始地址
-
32 位字地址,仅 bit15~bit2 有效
-
-
TXFQS.TFQPI
-
当前 FIFO 的写索引
-
0~TFQS-1
-
-
元素大小
- 由TXESC.TBDS和(Tx Buffer / FIFO / Queue Element Size)图确定的 32 位 RAM 字数
-
-
示例:
-
TXBC.TBSA = 0x300
- Tx Buffer 起始地址为 0x300,32 位字地址
-
TXESC.TBDS = 000
- 对应元素大小 = 4 字,Tx Buffer / FIFO / Queue Element Size)图
-
当前TXFQS.TFQPI = 2
- 下一个写入位置为 FIFO 元素 2
-
则元素 2 的起始地址 = 0x300 + 2 × 4 = 0x308
- 对应 RAM 中存储该 FIFO 元素的起始位置
-
与专用 Tx Buffer 的核心差异
-
控制方式
-
Tx FIFO(Tx BC.TFQM=0)
- 自动顺序处理(FIFO),CPU 无需干预顺序
-
Dedicated Tx Buffers
-
CPU 完全控制
- 主动发起请求,按 ID / 编号排序
-
-
-
索引机制
-
Tx FIFO(Tx BC.TFQM=0)
-
依赖 TFGI(发送)
-
TFQPI(写入)
-
TFFL(空闲)
-
-
Dedicated Tx Buffers
- 无索引,直接绑定固定 ID
-
-
适用场景
-
Tx FIFO(Tx BC.TFQM=0)
-
批量、无特定 ID 顺序要求的消息
- 如传感器数据
-
-
Dedicated Tx Buffers
-
高优先级、固定 ID、需即时控制的消息
- 如控制指令
-
-
-
传输请求
-
Tx FIFO(Tx BC.TFQM=0)
-
批量请求(连续 ARn)
-
索引自动更新
-
-
Dedicated Tx Buffers
-
单个请求(ARn)
-
需手动管理 ID
-
-
-
取消传输影响
-
Tx FIFO(Tx BC.TFQM=0)
- 仅取消 TFGI 元素时索引变化,顺序不打乱
-
Dedicated Tx Buffers
- 取消任意元素均不影响其他,灵活但需 CPU 管理
-
注意事项
-
资源冲突避免
-
Tx FIFO 的大小TFQS与专用 Tx Buffer 的数量NDTB之和必须≤32
-
M_CAN 不检查,配置错误会导致数据覆盖
-
-
消息格式一致性
-
FIFO 中所有元素需遵循相同的TXESC.TBDS配置
- 数据字段大小
-
否则会导致发送数据错误
-
-
空 / 满状态监控
-
CPU 需定期读取TXFQS的TFQF(满)和TFFL(空闲)
-
避免溢出或空读
-
-
仲裁优先级
-
FIFO 元素的消息仍需参与 CAN 总线仲裁
- ID 越小优先级越高
-
FIFO 顺序仅决定 "同一节点内的发送顺序"
- 不改变总线仲裁规则
-
小结
-
1.配置
-
配置TXBC.TFQM=0启用 FIFO
-
设置TFQS(大小)和TBSA(起始地址)
-
-
2.写入
- 按TFQPI写入消息
-
3.请求
-
通过TXBAR发起请求
-
TFQPI递增
-
-
4.发送
-
Tx Handler 按TFGI顺序发送
-
发送后TFGI递增
-
-
5.更新
-
监控TFQF(满)和TFFL(空闲)
- 确保无溢出
-
取消传输仅影响TFGI指向的元素
- 维持 FIFO 顺序
-
-
Tx FIFO 实现了 "批量消息的自动顺序发送",减少 CPU 干预,适合对发送顺序有要求但无需精准控制单条消息的场景
4.Tx Queue(发送队列)
概述
-
Tx Queue(发送队列)是 M_CAN 为需按 Message ID 优先级自动发送的场景设计的发送载体
-
与 Tx FIFO(先进先出)、专用 Tx Buffer(CPU 完全控制)的核心差异在于:
-
硬件自动按 ID 优先级排序发送,无需 CPU 干预优先级判断
-
适合 "多优先级消息共存、需硬件自动调度" 的场景
-
如车载 ECU 的多等级控制指令
-
工业设备的优先级数据帧
-
-
配置:启用 Tx Queue 模式
-
配置项
-
启用 Queue 模式
-
寄存器 / 字段
- TXBC.TFQM(地址 0xC0)
-
取值与含义
-
TFQM = 1
- 启用Tx Queue 模式
-
TFQM = 0
- 启用 Tx FIFO 模式
-
-
-
配置 Queue 大小
-
寄存器 / 字段
- TXBC.TFQS5:0
-
取值与含义
-
1~32
-
32 按 32 处理,0 表示禁用 Queue
-
-
定义 Tx Queue 占用的 Tx Buffer 数量
-
-
-
资源分配约束
-
寄存器 / 字段
- TXBC.NDTB + TXBC.TFQS
-
取值与含义
-
与专用 Tx Buffer 的数量NDTB之和≤32
-
共享 32 个 Tx Buffer 硬件资源
- M_CAN 不检查冲突
-
-
-
Queue 起始地址
-
寄存器 / 字段
- TXBC.TBSA15:2
-
取值与含义
- 所有 Tx Buffer(含 Queue)在 Message RAM 的起始地址(32 位字地址)
-
-
特性
-
传输优先级规则
-
按 Message ID 排序,同 ID 按缓冲区编号排序
-
一级优先级
-
Message ID 越小,优先级越高
- 符合 CAN 协议仲裁规则
-
Tx Handler 会自动扫描所有待发送的 Queue 缓冲区,筛选 ID 最小的优先发送
-
-
二级优先级
-
若多个 Queue 缓冲区配置相同 Message ID
- 如 Buffer 3 和 Buffer 7 均为 ID=0x008
-
则缓冲区编号更小的优先发送
- Buffer 3 先于 Buffer 7
-
-
优先级调度触发
-
每当TXBRP(Tx Buffer Request Pending,地址 0xCC)更新时
- Add 请求、发送完成、取消请求
-
Tx Handler 启动 "Tx 扫描",重新筛选最高优先级的 Queue 缓冲区
-
-
示例
-
Tx Queue 包含 3 个缓冲区
- ID 分别为 Buffer 2(ID=0x005)、Buffer 5(ID=0x003)、Buffer 1(ID=0x005)
-
则发送顺序为:Buffer 5(ID 最小)→ Buffer 1(同 ID 编号小)→ Buffer 2(同 ID 编号大)
-
-
-
消息写入逻辑
-
灵活定位空闲缓冲区
-
Tx Queue 的消息写入无需严格连续
- 区别于 Tx FIFO 的 "连续写入"
-
核心依赖Put Index和TXBRP寄存器
-
-
(1)强制默认写入:按 Put Index 定位空闲缓冲区
-
定位空闲位置
-
新消息必须先写入TXFQS.TFQPI(Put Index)指向的 Queue 缓冲区
- 该索引默认指向 "下一个可写入的空闲缓冲区"
-
-
写入消息
- CPU 将消息(ID、DLC、数据等,格式见Tx Buffer Element)写入该缓冲区
-
发起请求
- 向TXBAR(Tx Buffer Add Request,地址 0xD0)对应位写 "1",发起传输请求
-
更新索引
-
M_CAN 收到请求后,自动将 TFQPI循环递增到下一个空闲缓冲区
- 如当前 = 3,Queue 大小 = 5→下一个 = 4;当前 = 4→下一个 = 0
-
同时TXBRP对应位置位
- 标记待发送
-
-
-
(2)灵活写入:用 TXBRP 寄存器跳过 Put Index
-
应用可直接通过TXBRP寄存器(只读)查看哪些 Queue 缓冲区无待发送请求(TRPn=0)
-
将消息直接写入这些 "空闲缓冲区",无需严格按TFQPI顺序
-
优势
-
适合 "随机插入高优先级消息" 场景
-
例如
-
CPU 需紧急插入 ID=0x001 的消息
-
将消息直接写入这些 "空闲缓冲区"
-
无需严格按TFQPI顺序
-
-
-
对比 Tx FIFO
-
Tx FIFO 必须按TFQPI连续写入
-
无法跳过,灵活性远低于 Tx Queue
-
-
-
-
满状态处理
-
TXFQS.TFQF=1 时禁止写入
-
当 Tx Queue 的所有缓冲区均有待发送请求
- TXBRP对应位全 1
-
TXFQS.TFQF(Tx FIFO/Queue Full)置位 "1"
- 表示 Queue 满
-
-
写入限制
-
此时TFQPI失效,不可再向 Queue 写入消息
-
否则会覆盖未发送的消息
-
-
恢复写入
-
需等待至少 1 个 Queue 缓冲区的
-
消息发送完成(TXBRP对应位复位)
-
或被取消(TXBCR请求后TXBRP复位)
-
-
TFQF复位为 0,TFQPI重新指向空闲缓冲区
- 方可继续写入
-
-
-
地址计算
-
与 Tx FIFO 共享公式
-
Tx Queue 缓冲区在 Message RAM 中的地址计算逻辑与 Tx FIFO 完全一致
-
核心依赖(Tx Buffer/Queue Element Size)图 和TXBC.TBSA(Tx Buffer 起始地址)
-
-
(1)确定 Element Size(元素大小)
-
TXESC(Tx Buffer Element Size Configuration,地址 0xC8)的TBDS2:0位决定每个 Queue 缓冲区占用的 32 位 RAM 字数
-
参考(Tx Buffer/Queue Element Size)图
-
-
(2)地址计算公式
-
Tx Queue 缓冲区 n 的起始 RAM 地址 =
- TXBC.TBSA + TXFQS.TFQPI × Element Size
-
TXBC.TBSA
-
Tx Buffer 在 Message RAM 的起始地址
- 32 位字地址,仅 bit15~bit2 有效
-
-
TXFQS.TFQPI
-
当前 Queue 的写索引
- 0~TFQS-1
-
-
Element Size
-
由TXESC.TBDS和 (Tx Buffer/Queue Element Size)图
-
确定的 32 位 RAM 字数
-
-
示例:
-
配置:
-
TXBC.TBSA=0x400
-
TXESC.TBDS=000
- Element Size=4 字
-
对应 RAM 中该 Queue 缓冲区的起始位置
-
-
-
-
与 Tx FIFO、专用 Tx Buffer 的核心差异
-
核心控制逻辑
-
Tx Queue(TFQM=1)
-
硬件按 ID 优先级自动发送
- ID 小→编号小优先
-
-
Tx FIFO(TFQM=0)
-
硬件按写入顺序发送
- 先进先出
-
-
专用 Tx Buffer(NDTB>0)
-
CPU 主动发起请求
- 完全控制
-
-
-
优先级依据
-
Tx Queue(TFQM=1)
- Message ID(主)+ 缓冲区编号(次)
-
Tx FIFO(TFQM=0)
- 写入顺序(FIFO)
-
专用 Tx Buffer(NDTB>0)
- CPU 请求顺序(可自定义)
-
-
消息写入灵活性
-
Tx Queue(TFQM=1)
- 支持按 Put Index 或 TXBRP 随机写入空闲缓冲区
-
Tx FIFO(TFQM=0)
- 仅支持按 Put Index 连续写入
-
专用 Tx Buffer(NDTB>0)
- CPU 直接指定缓冲区,无索引限制
-
-
传输取消适配性
-
Tx Queue(TFQM=1)
- 适配(取消不影响优先级排序)
-
Tx FIFO(TFQM=0)
- 不适配(取消易打乱 FIFO 顺序)
-
专用 Tx Buffer(NDTB>0)
- 适配(CPU 灵活控制单个缓冲区)
-
-
适用场景
-
Tx Queue(TFQM=1)
- 多优先级消息自动调度(如控制指令)
-
Tx FIFO(TFQM=0)
- 批量顺序发送(如传感器数据)
-
专用 Tx Buffer(NDTB>0)
- 高优先级即时控制(如紧急命令)
-
-
资源分配
-
Tx Queue(TFQM=1)
- 占用 TFQS 个 Tx Buffer,与 NDTB 之和≤32
-
Tx FIFO(TFQM=0)
- 占用 TFQS 个 Tx Buffer,与 NDTB 之和≤32
-
专用 Tx Buffer(NDTB>0)
- 占用 NDTB 个 Tx Buffer,与 TFQS 之和≤32
-
注意事项
-
资源冲突避免
-
Tx Queue 的大小TFQS与专用 Tx Buffer 的数量NDTB之和必须≤32
-
M_CAN 不检查配置错误,超量会导致缓冲区覆盖
-
-
消息格式一致性
-
Queue 中所有缓冲区需遵循相同的TXESC.TBDS配置(数据字段大小)
-
否则会导致发送数据长度错误
-
-
优先级与总线仲裁
-
Tx Queue 的优先级仅决定 "同一 M_CAN 节点内的发送顺序"
-
消息发送到总线后仍需参与 CAN 总线仲裁(ID 小的优先)
-
Queue 优先级不改变总线仲裁规则
-
-
TXBRP 的使用场景
-
仅当需要 "随机插入消息" 时使用TXBRP定位空闲缓冲区
-
常规场景按TFQPI写入即可,避免过度复杂的 CPU 逻辑
-
小结
-
配置
-
配置TXBC.TFQM=1启用 Queue
-
设置TFQS(大小)和TBSA(起始地址)
-
-
写入
- 按TFQPI或TXBRP写入消息
-
调度
- 通过TXBAR发起请求,TFQPI循环递增
-
发送
-
Tx Handler 扫描 Queue 缓冲区
-
按 "ID 小→编号小" 筛选最高优先级
-
-
更新
-
发送完成后TXBRP复位,TFQF更新空闲状态
-
满状态时等待发送 / 取消,恢复后继续写入
-
-
Tx Queue 实现了 "多优先级消息的硬件自动调度"
-
减少 CPU 对优先级排序的干预
-
适合需按 ID 优先级发送但无需精准控制单条消息的场景
5.混合发送模式
(Mixed Tx Buffers)
混合模式的核心前提
-
资源共享与拆分
- 无论是 "专用 Tx Buffer+Tx FIFO" 还是 "专用 Tx Buffer+Tx Queue",本质都是对 M_CAN 的32 个 Tx Buffer 硬件资源进行 "分区复用"
-
核心约束:
-
资源分配寄存器
-
均通过TXBC(Tx Buffer Configuration,地址 0xC0)配置
-
TXBC.NDTB5:0:
-
配置专用 Tx Buffer 的数量
-
1~32,>32 按 32 处理,0 = 禁用专用缓冲区
-
-
TXBC.TFQS5:0:
-
配置Tx FIFO/Queue 的大小
-
1~32,>32 按 32 处理,0 = 禁用 FIFO/Queue
-
-
强制约束:
-
NDTB + TFQS ≤ 32
-
M_CAN 不检查冲突,超量会导致缓冲区覆盖
-
-
-
Message RAM 地址顺序
-
Tx Buffers 段在 Message RAM 中固定为:
-
专用 Tx Buffer 在前,Tx FIFO/Queue 在后
-
示例:
-
配置:
-
NDTB=12(12 个专用缓冲区,索引 0~11)
-
TFQS=20(20 个 FIFO/Queue 缓冲区,索引 12~31)
-
-
地址范围:
-
专用缓冲区地址 =
-
TXBC.TBSA + 索引×Element Size
- (索引 0~11)
-
-
FIFO/Queue 地址 =
-
TXBC.TBSA + 12×Element Size + 索引×Element Size
- (索引 0~19)
-
-
-
-
-
混合专用 Tx Buffer / Tx FIFO
-
专用控制 + FIFO 顺序调度
-
该模式是 "专用 Tx Buffer 的 CPU 控制" 与 "Tx FIFO 的先进先出(FIFO)" 的结合
-
核心特点是 "FIFO 区保持顺序,调度时仅对比专用区与 FIFO 最早待发消息"
-
-
核心特性:资源与调度规则
-
资源划分:专用在前,FIFO 在后
-
专用 Tx Buffer
-
数量由NDTB决定
-
每个绑定固定 Message ID
-
CPU 通过TXBAR单独发起请求
-
-
Tx FIFO
-
大小由TFQS决定
- 1~32,>32 按 32 处理
-
关键约束
- 若 TXBC.TFQS=0,则仅启用专用 Tx Buffer,FIFO 功能禁用
-
按 "写入顺序(Put Index)" 存储
-
发送时按 "最早写入(Get Index,TXFQS.TFGI)" 顺序
-
不单独绑定 ID
-
-
-
-
优先级调度:仅对比 "专用区 + FIFO 最早待发消息"
-
Tx Handler 在调度时,仅扫描两类缓冲区,而非全扫
- 该模式的关键差异点
-
1.所有 "有传输请求的专用 Tx Buffer"
- TXBRP.TRPn=1,n<NDTB
-
2.Tx FIFO 中 "最早待发的缓冲区"
-
由TXFQS.TFGI指向
-
即 FIFO 中最早写入且未发送的缓冲区
-
-
3.优先级判定:
-
比较上述两类缓冲区的 Message ID
-
ID 最小的优先发送
-
-
示例:
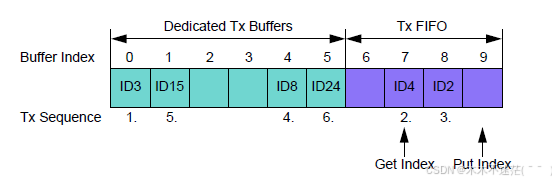
-
Example of mixed Configuration Dedicated Tx Buffers / Tx FIFO
-
缓冲区资源划分(Message RAM 布局)
-
专用发送缓冲区(Dedicated Tx Buffers):
-
TXBC.NDTB=6
- 占据索引 0~5(共 6 个)
-
每个专用缓冲区可绑定固定的 Message ID
- 如索引 0 绑定ID3、索引 1 绑定ID15等
-
-
发送 FIFO(Tx FIFO):
-
TXBC.TFQS=4
- 占据索引 6~9(共 4 个)
-
FIFO 遵循 "先进先出(FIFO)" 规则
- 通过Get Index(取数索引)和Put Index(存数索引)管理数据流转
-
-
-
缓冲区的 ID 与状态
-
专用区(0~5):
-
索引 0(ID3)、1(ID15)、4(ID8)、5(ID24)有明确 ID
-
索引 2、3 为空白(无发送请求或未配置)
-
-
FIFO 区(6~9):
-
索引 7(ID4)、8(ID2)为 FIFO 内待发数据
-
索引 6 为空闲单元(未写入数据)
-
索引 9 为 Put Index 指向的下一个写入单元
-
-
Get Index
- 指向索引 7 → 表示 FIFO 中最早待发送的缓冲区是索引 7(ID4)
-
Put Index
- 指向索引 9 → 表示 FIFO 中下一个要写入数据的缓冲区是索引 9
-
-
发送顺序
-
扫描范围:
- 专用区有请求的ID3、ID15、ID8、ID24 + FIFO Get Index指向的ID4
-
优先级比较:
-
第 1 步:发送ID3(专用 0)
-
专用区剩余请求:ID15、ID8、ID24
-
FIFO Get Index指向ID4
-
ID3 < ID4 < ID8 < ID15 < ID24
-
因此 ID3(专用 0)最小 ,优先发送
-
-
第 2 步:发送ID4(FIFO7)
-
专用区剩余请求:ID15、ID8、ID24
-
FIFO Get Index指向ID4
-
ID4 < ID8 < ID15 < ID24
-
因此 D4(FIFO7)最小,发送ID4
-
-
第 3 步:发送ID2(FIFO8)
-
专用区剩余请求:ID15、ID8、ID24
-
FIFO Get Index指向ID2
-
ID2< ID8 < ID15 < ID24
-
因此 D2(FIFO8)最小,发送ID2
-
-
...
-
发送顺序为:
- ID3(专用0)→ ID4(FIFO7)→ ID2(FIFO8)→ ID8(专用4)→ ID15(专用1)→ ID24(专用5)
-
-
-
-
-
-
FIFO 区的保留特性
-
Tx FIFO 区仍保持单一模式的 "先进先出" 特性:
-
写入:
- 需按TXFQS.TFQPI连续写入,不可跳过
-
满状态:
-
TXFQS.TFQF=1时禁止写入,需等待TFGI递增
- 发送完成
-
-
取消传输:
-
仅取消TFGI指向的 FIFO 缓冲区时,TFGI才递增
-
否则不影响 FIFO 顺序
-
-
-
混合专用 Tx Buffer / Tx Queue
-
专用控制 + Queue ID 全扫
-
该模式是 "专用 Tx Buffer 的 CPU 控制" 与 "Tx Queue 的 ID 优先级调度" 的结合
-
核心特点是 "Queue 区按 ID 全扫,调度时覆盖所有有请求的缓冲区"
-
-
核心特性:资源与调度规则
-
资源划分:专用在前,Queue 在后
-
专用 Tx Buffer
- 数量NDTB,固定 ID,CPU 主动请求
-
Tx Queue
-
大小TFQS,不固定 ID
- 1~32,>32 按 32 处理
-
关键约束
- 若 TXBC.TFQS=0,则仅启用专用 Tx Buffer,Queue 功能禁用
-
按 "ID 优先级" 发送(非顺序)
- 与单一 Queue 模式一致
-
-
-
优先级调度:扫描 "所有有请求的缓冲区"
-
Tx Handler 调度时,全扫两类缓冲区中所有有传输请求的单元
- 与 FIFO 混合模式的核心差异
-
1.所有 "有传输请求的专用 Tx Buffer"
- TXBRP.TRPn=1,n<NDTB
-
2.所有 "有传输请求的 Tx Queue 缓冲区"
- TXBRP.TRPn=1,n≥NDTB
-
优先级判定:
-
比较所有扫描到的缓冲区的 Message ID
- ID 最小的优先发送
-
若 ID 相同,"缓冲区编号更小的优先"
- 同单一 Queue 模式的二级优先级
-
-
示例:
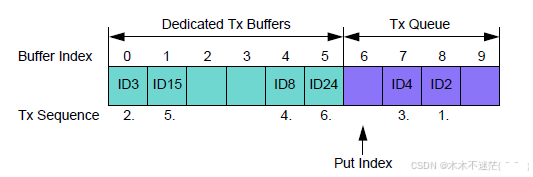
-
Example of mixed Configuration Dedicated Tx Buffers / Tx Queue
-
缓冲区资源划分(Message RAM 布局)
-
专用发送缓冲区(Dedicated Tx Buffers):
-
TXBC.NDTB=6
- 占据索引 0~5(共 6 个)
-
每个专用缓冲区可绑定固定的 Message ID
- 如索引 0 绑定ID3、索引 1 绑定ID15等
-
-
发送队列(Tx Queue)
-
TXBC.TFQS=4
- 占据索引 6~9(共 4 个)
-
队列缓冲区用于动态写入消息
-
ID 不固定,由队列调度逻辑管理
-
-
-
缓冲区的 ID 与状态
-
专用区(0~5):
-
索引 0(ID3)、1(ID15)、4(ID8)、5(ID24)有明确 ID
-
索引 2、3 为空白(无发送请求或未配置)
-
-
FIFO 区(6~9):
-
索引 7(ID4)、8(ID2)有明确 ID
-
6 是 "Put Index" 指向的下一个写入位置
-
-
-
发送顺序
-
扫描范围:
- 所有 "有激活发送请求" 的缓冲区
-
优先级比较:
-
按 "ID 从小到大" 排序后
-
发送顺序为:
- ID2(队列 8)→ ID3(专用 0)→ ID4(队列 7)→ ID8(专用 4)→ ID15(专用 1)→ ID24(专用 5)
-
-
-
-
-
-
Queue 区的保留特性
-
Tx Queue 区仍保持单一模式的 "ID 优先级" 特性:
-
写入:
- 支持按TXFQS.TFQPI或TXBRP(空闲缓冲区)灵活写入,无需连续
-
满状态:
-
TXFQS.TFQF=1时TFQPI失效
-
需等待任意 Queue 缓冲区发送 / 取消
-
-
取消传输:
-
取消任意 Queue 缓冲区请求,仅复位TXBRP对应位
-
不影响其他 Queue 缓冲区的优先级排序
-
-
-
两种混合模式的核心差异对比
-
调度扫描范围
-
混合专用 Tx Buffer / Tx FIFO
- 仅扫描 "专用区有请求的 Buffer + FIFO 的 TFGI 指向 Buffer"
-
混合专用 Tx Buffer / Tx Queue
- 全扫 "专用区有请求的 Buffer + Queue 区有请求的 Buffer"
-
-
FIFO/Queue 特性保留
-
混合专用 Tx Buffer / Tx FIFO
- 保留 FIFO "先进先出",仅最早写入的参与调度
-
混合专用 Tx Buffer / Tx Queue
- 保留 Queue "ID 优先级",所有有请求的参与调度
-
-
优先级判定效率
-
混合专用 Tx Buffer / Tx FIFO
-
扫描范围小,效率高
-
适合 FIFO 消息量大但调度简单场景
-
-
混合专用 Tx Buffer / Tx Queue
-
扫描范围大,效率略低
-
适合 Queue 消息多优先级场景
-
-
-
适用场景
-
混合专用 Tx Buffer / Tx FIFO
-
需 "固定 ID 专用消息 + 批量顺序消息"
-
如传感器数据 + 控制指令
-
-
混合专用 Tx Buffer / Tx Queue
-
需 "固定 ID 专用消息 + 多优先级消息"
-
如多等级控制指令
-
-
-
同 ID 处理
-
混合专用 Tx Buffer / Tx FIFO
- 专用区同 ID 按编号,FIFO 同 ID 按写入顺序
-
混合专用 Tx Buffer / Tx Queue
-
所有缓冲区同 ID 按编号
-
专用 + Queue 统一按编号排序
-
-
注意事项
-
资源冲突必避:
-
NDTB + TFQS必须≤32
-
M_CAN 不检查配置错误,超量会导致专用区与 FIFO/Queue 区地址重叠,数据覆盖
-
-
地址区分:
-
Message RAM 中 Tx Buffers 段 "专用在前,FIFO/Queue 在后",计算地址时:
-
专用 Buffer 地址 =
-
TXBC.TBSA + 专用索引×Element Size
- 索引 0~NDTB-1
-
-
FIFO/Queue 地址 =
-
TXBC.TBSA + NDTB×Element Size + FIFO/Queue索引×Element Size
- 索引 0~TFQS-1
-
-
-
中断与状态监控:
-
需同时监控
-
专用区(TXBTO/TXBCF)
-
FIFO/Queue 区(TXFQS)
-
-
避免漏检发送完成 / 取消事件
-
-
优先级与总线仲裁:
-
混合模式的优先级仅决定 "同一 M_CAN 节点内的发送顺序"
-
消息发送到总线后,仍需参与 CAN 总线仲裁
- ID 小的优先
-
节点内优先级不改变总线规则
-
6.发送取消
(Transmit Cancellation)
概述
-
本质是允许主机(Host CPU)主动终止 "已请求但未完成" 的发送任务
-
适用场景:
-
网关应用
-
网关需动态调度多节点的 CAN 消息转发
-
可能因优先级调整或链路状态变化,需取消已排队的低优先级发送任务
-
-
AUTOSAR 架构应用
-
AUTOSAR 对 CAN 通信有严格的时序和故障管理要求
-
发送取消可配合故障恢复机制
- 如总线错误时终止无效发送
-
符合 AUTOSAR 的通信管理规范
-
-
-
关键限制
-
仅支持两种发送取消
-
专用 Tx 缓冲区(Dedicated Tx Buffer)
-
Tx 队列缓冲区(Tx Queue Buffer)
-
-
不支持
-
Tx FIFO(发送先进先出缓冲区)
-
发送取消并非用于Tx FIFO操作
-
-
操作步骤
-
主机需执行唯一操作:
-
向 "发送缓冲区取消请求寄存器(TXBCR)" 的对应位写入 "1"
-
约束:
-
仅针对 "专用 Tx Buffer" 或 "Tx Queue Buffer"
-
禁止对 Tx FIFO 相关缓冲区发起取消请求
-
-
位位置规则:
-
"对应位的位置 = 目标 Tx 缓冲区的编号"
-
例如:
- 取消第 3 个专用 Tx 缓冲区的发送,需将 TXBCR 的 Bit3 置 1
-
-
-
寄存器 TXBCR 的作用:
-
专门记录 "待取消的发送请求"
-
每 1 位对应 1 个 Tx 缓冲区
- 共 32 位,对应最多 32 个 Tx 缓冲区
-
-
写入 "1" 的含义
-
触发对该 Tx 缓冲区的取消请求
-
写入 "0" 无效果
- 不改变现有状态
-
取消成功的判断标志
-
通过 发送缓冲区取消完成寄存器(TXBCF)判断
-
当某个 Tx 缓冲区的取消请求完成后,M_CAN 会自动将TXBCF 的对应位设置为 "1"
-
例如:
- 第 3 个 Tx 缓冲区取消成功,TXBCF 的 Bit3 置 1
-
-
TXBCF 的核心作用:
-
反馈 "取消请求的最终状态"
-
是主机确认取消结果的唯一依据
-
-
位的复位:
-
当主机向该 Tx 缓冲区重新发起发送请求时
- 通过 TXBAR 寄存器写 1
-
TXBCF 的对应位会自动复位
-
特殊场景
-
发送进行中取消
- 主机在某个 Tx 缓冲区的发送已启动(数据正在总线传输) 时发起取消请求
-
寄存器的状态变化:
-
TXBRP(发送请求待处理)
-
发送进行中时,该寄存器的对应位保持置 1
- 直到发送结束
-
因为取消请求无法中断 "已启动的物理层传输"
-
-
TXBTO(发送发生)
-
仅当 "被取消的发送最终成功完成" 时置 1
- 表示 "发送动作已执行"
-
若发送失败(如总线错误),该位不置 1
-
-
TXBCF(取消完成)
-
无论发送成功 / 失败,发送结束后该寄存器对应位都会置 1
-
表示 "取消请求已处理完成"
-
-
-
两种子场景的具体结果:
-
发送成功 + 取消请求
-
传输过程中发起取消请求,但传输仍正常完成
-
结果:
-
TXBTO(发送发生)和 TXBCF(取消完成)对应位均置 1
-
表示 "发送完成 + 取消请求已处理"
-
-
-
发送失败 + 取消请求
-
传输过程中发起取消请求,且传输因错误终止
- 如总线错误
-
取消后不再重发,区别于正常发送的自动重发逻辑
-
结果:
-
仅 TXBCF 对应位置 1(取消请求处理完成)
-
TXBTO 不置 1(发送未成功)
-
-
-
注意事项
-
取消时序导致的总线空闲窗口
-
若 "待发送(pending)的任务" 在即将启动发送前被取消
- 如:总线刚空闲,M_CAN 准备启动该任务时收到取消请求
-
会出现一个短暂的 "总线空闲窗口"
- 即使该节点还有其他待发送消息,也不会立即启动下一个发送
-
-
导致的潜在影响
-
其他节点的 "低优先级消息" 可能抢占总线
-
因为 M_CAN 的短暂空闲让其他节点检测到总线空闲,从而发起发送
-
-
本质是 "取消操作的时序延迟"
-
取消请求的处理需要极短时间
-
而总线空闲时其他节点的发送请求会快速抢占
-
导致 M_CAN 的下一个待发消息无法即时启动
-
小结
-
发送取消的本质是 "主机对发送任务的动态干预"
-
操作 - 反馈 - 异常处理
-
主机写TXBCR(发起取消) → M_CAN处理取消请求 → TXBCF置1(反馈完成)
-
同时需区分 "未启动发送" 和 "已启动发送" 的不同处理规则
-
避免因时序问题误解总线行为
-
如空闲窗口导致的低优先级消息抢占
-
-
7.发送事件处理
(Tx Event Handling)
Tx Event FIFO(发送事件先进先出缓冲区)
-
M_CAN 中专门用于存储 "消息发送后状态信息" 的独立存储单元
-
当 M_CAN 在 CAN 总线上成功发送一条消息后,会自动将该消息的 "发送事件数据"
- 如 Message ID、时间戳、发送状态关联标识
-
存入 Tx Event FIFO 的一个 "元素" 中
-
作用
-
将 "发送消息的内容" 与 "发送后的状态信息" 彻底分离
-
避免 Tx Buffer(发送缓冲区)被状态信息占用
- 提升 Tx Buffer 的复用效率
-
核心组件与配置
-
是构成 Tx Event Handling 的关键要素
-
Tx Event FIFO 本身
-
存储容量
-
最大支持 32 个元素
-
通过寄存器TXEFC.EFS配置
-
范围 0~32,超过 32 按 32 处理
-
-
每个元素对应一条消息的 "发送事件记录"
-
-
元素结构
-
参考手册 2.4.4,每个元素占 2 个 32 位字
- 共 64 位
-
E0:
-
消息的 ESI(错误状态标识)
-
XTD(扩展 ID 标识)
-
RTR(远程帧标识)
-
ID 28:0(消息 ID)
-
-
E1A/B:
-
Message Marker(消息标识)
-
ET(事件类型)
-
FDF(CAN FD 标识)
-
BRS(比特率切换标识)
-
DLC(数据长度)
-
时间戳(或 TSU 指针)
-
-
-
-
Message Marker(消息标识)
-
关联 Tx Buffer 与 Tx Event
-
作用
-
作为 "Tx Buffer(待发消息)" 与 "Tx Event FIFO(发送状态)" 的 "关联钥匙"
- 唯一用于关联 Tx Buffer 与 Tx Event FIFO 元素,无其他替代关联方式
-
发送前
- 主机需在 Tx Buffer 中写入 Message Marker
-
发送后
- M_CAN 会自动将该 Marker 复制到对应的 Tx Event FIFO 元素中
-
主机通过 Marker 即可确定 "哪个 Tx Buffer 的消息对应哪个发送事件"
-
-
配置
-
通过CCCR.WMM选择 Marker 长度
- CC 控制寄存器的 "宽消息标识" 位
-
CCCR.WMM = 0
-
使用 8 位 Marker(默认)
-
此时 Tx Event FIFO 元素中存储 16 位内部时间戳
-
-
CCCR.WMM = 1
-
使用 16 位 Wide Message Marker(宽标识)
-
此时内部时间戳禁用
- 需依赖外部 TSU 实现时间戳,参考手册 2.4.4
-
-
-
-
关键配置寄存器
-
Tx Event FIFO 的初始化和状态查询依赖以下寄存器
-
TXEFC
-
地址
- 0xF0
-
字段与作用
-
EFSA15:2
-
Tx Event FIFO 在 Message RAM 中的起始地址
-
32 位字地址
-
-
EFS5:0
-
FIFO 大小
-
0 = 禁用,1~32 = 元素数量
-
-
EFWM5:0
-
水位线
-
触发预警中断的填充量
-
-
-
-
TXEFS
-
地址
- 0xF4
-
字段与作用
-
EFGI4:0
-
FIFO 的 "读索引"
-
当前需读取的元素位置
-
-
EFPI4:0
-
FIFO 的 "写索引"
-
下一个待存储元素的位置
-
-
EFFL5:0
- FIFO 当前填充量
-
EFF
-
FIFO 满标志
-
1 = 满
-
-
TEFL
-
元素丢失标志
-
1 = 有事件因 FIFO 满被丢弃
-
-
-
-
IR(中断寄存器)
-
地址
- 0x50
-
字段与作用
-
IR.TEFF(位 14)
- FIFO 满中断标志
-
IR.TEFL(位 15)
- 元素丢失中断标志
-
IR.TEFW(位 13)
- 水位线达到中断标志
-
-
-
解耦的意义
-
解耦 "Tx Buffer 的消息存储" 与 "发送状态记录",解决传统设计中 "Tx Buffer 被状态占用导致复用效率低" 的问题
-
- 传统设计的痛点
-
若 Tx Buffer 同时存储 "待发消息内容" 和 "发送后状态",则:
- 如 "是否发送成功""发送时间戳"
-
即使消息已发送完成,Tx Buffer 也需等待主机读取状态后才能被新消息覆盖
-
对于动态管理的发送队列
-
如 AUTOSAR 要求的 Tx Queue
-
频繁的 "状态读取 - 清空" 会导致 Tx Buffer 复用延迟,影响发送效率
-
-
- Tx Event FIFO 的解决方案
-
Tx Buffer 仅存 "待发消息"
-
仅包含 ID、数据、DLC、发送配置(如 FDF、BRS)
-
发送完成后可立即被新消息覆盖
- 无需等待状态读取
-
-
Tx Event FIFO 存 "发送状态"
-
发送完成后,状态信息(ID、时间戳、Marker)自动存入 FIFO
-
主机可在 "空闲时批量读取",不影响 Tx Buffer 的复用
-
-
典型场景:
-
网关应用中,M_CAN 需频繁转发不同 ID 的消息
-
Tx Buffer 发完一条消息后立即接收下一条待转发消息
-
发送状态则由 Tx Event FIFO 记录
-
主机后续读取 FIFO 即可确认每条消息的发送结果
-
异常处理
-
避免 Tx Event FIFO 满 / 溢出
-
Tx Event FIFO 存在 "满" 和 "溢出" 两种异常场景
-
M_CAN 通过 "中断预警 + 溢出标志" 进行异常处理
-
-
1:Tx Event FIFO 满(EFF=1)
-
触发条件
-
当 FIFO 的 "写索引(EFPI)" 追上 "读索引(EFGI)" 时
- FIFO 满(TXEFS.EFF=1)
-
此时 M_CAN不再写入新的发送事件元素
-
-
中断提示
-
F 满时自动置位中断标志IR.TEFF(位 14)
-
若已通过IE.TEFFE(中断使能寄存器)使能该中断
- 则会触发中断,提醒主机 "立即读取 FIFO 以释放空间"
-
-
-
2:Tx Event FIFO 溢出(事件丢失)
-
触发条件
-
FIFO 已满(EFF=1),但 M_CAN 仍有新的发送事件需存储
-
此时新事件会被丢弃,同时置位
-
TXEFS.TEFL(元素丢失标志)
-
中断标志IR.TEFL(位 15)
-
-
-
中断提示
-
IR.TEFL触发中断后,主机可通过该标志确认 "有发送事件未被记录"
-
需排查 FIFO 大小是否不足或读取是否及时
-
-
-
预防措施:水位线预警(EFWM)
-
为避免 "满" 和 "溢出",可通过TXEFC.EFWM(水位线)配置 "提前预警"
-
当 FIFO 的填充量(TXEFS.EFFL)达到EFWM配置的值时
- M_CAN 自动置位中断标志IR.TEFW(位 13)
-
主机收到该中断后
-
可在 FIFO 满之前提前读取元素
-
避免后续事件丢失
-
-
-
示例:
-
若 FIFO 大小配置为 16,可将EFWM=12
- EFS=16
-
当 FIFO 存满 12 个元素时触发预警,主机有 4 个元素的缓冲时间读取,避免满溢
-
-
读取方法
-
读取 Tx Event FIFO 时,需根据 "起始地址 + 读索引" 计算目标元素的地址
-
核心是明确每个 Event 元素的存储占用:
-
- 地址计算逻辑
-
Tx Event FIFO 的每个元素占2 个 32 位字
-
参考 2.4.4 的元素结构:
-
E0和E1A/B各为 1 个 32 位字
-
-
计算公式
-
目标元素地址 =
- TXEFC.EFSA(FIFO起始地址) + 2 × TXEFS.EFGI(读索引)
-
TXEFC.EFSA:
-
配置的 FIFO 在 Message RAM 中的起始地址
-
32 位字地址,仅 bit15~2 有效
-
-
2 × EFGI:
-
因每个元素占 2 个 32 位字
-
需用读索引乘以 2 定位到具体元素的起始位置
-
-
-
- 读取流程示例
-
状态查询:读取 TXEFS 寄存器,确认:
-
EFFL(填充量)>0(确保有元素可读)
-
EFGI(当前读索引)
-
EFF(是否满)
-
-
2.计算地址
-
若EFSA=0x100、EFGI=2
-
则目标元素地址 = 0x100 + 2×2 = 0x104
-
-
- 数据读取:
- 从计算地址读取完整的 Tx Event 元素数据(E0+E1A/E1B)
-
4.索引更新
-
主机必须将 "最后读取的元素索引"写入 TXEFA.EFAI
- 如连续读 2 个元素,索引为 EFGI+1
-
M_CAN 仅通过该操作更新:
-
Tx Event FIFO Get Index(TXEFS.EFGI = EFAI + 1)
-
FIFO 填充量(TXEFS.EFFL = EFFL - 读取元素数量)
-
-
注意
- 不写入 EFAI 会导致 EFGI 和 EFFL 不更新,后续读取会重复获取旧元素
-
-
注意事项
-
内部时间戳的禁用条件
-
当CCCR.WMM=1(使用 16 位 Wide Message Marker)时
-
Tx Event FIFO 中的 "16 位内部时间戳" 会被禁用
-
需依赖外部 TSU(时间戳单元)提供 32 位时间戳
-
-
元素与 Tx Buffer 的关联
-
必须通过Message Marker关联
-
发送前在 Tx Buffer 的T1.MM字段写入 Marker
-
发送后该 Marker 会自动复制到 Event 元素的E1A/B.MM字段
-
主机通过比对 Marker 即可确定 "哪个 Tx Buffer 的消息对应哪个 Event"
-
-
地址配置建议
-
Tx Event FIFO 的起始地址 TXEFC.EFSA 需配置在 Message RAM 的合法区域
- 32 位字地址,仅 bit15~2 有效
-
应用层需自行确保 TXEFC.EFSA 不与 Rx FIFO、Tx Buffer 等其他段地址重叠,避免数据覆盖
- M_CAN 硬件不主动检查地址冲突
-
小结
-
Tx Event Handling 的本质是 "用独立 FIFO 记录发送状态,解放 Tx Buffer 的复用能力"
-
通过分离 "消息内容" 和 "发送状态",解决动态发送场景中 Tx Buffer 被状态占用的问题
- 如网关、AUTOSAR 队列
-
同时通过 "预警 + 满溢标志" 确保状态记录不丢失
-
最终实现 "高效发送 + 可靠状态追溯" 的双重目标