联合索引是我们在实践的过程中必然会遇到的一种索引使用场景,当使用联合索引时,"最左匹配原则"又是必须知道的知识点。
今天这篇文章带大家一起学习一下MySQL的联合索引以及MySQL对联合索引执行的最左匹配原则。
什么是联合索引?
联合索引(Composite Index),也称为多列索引或复合索引,是一种包含多个列的单个索引。它是为了优化多列查询的性能而创建的。在表中创建联合索引可以帮助MySQL根据实际查询条件快速定位数据。
创建联合索引示例:
arduino
CREATE INDEX idx_users_name_age ON users (name, age);在上述示例中,在name和age两个字段上创建了联合索引。该索引不仅可以加速基于 name 和 age 的查询,还能在某些情况下加速单列查询。
联合索引的核心原理是根据索引的顺序将多个字段的数据进行组合存储。当查询中的条件与联合索引的列顺序一致时,数据库可以直接利用索引进行查找,大大提高查询性能。
使用联合索引的目的通常包含以下三种:
- 多列查询频繁 :如果查询中经常用到多个列作为条件(比如
WHERE col1 AND col2),联合索引可以避免逐列扫描。 - 减少索引数量 :比如,为了同时优化
WHERE col1 = ...和WHERE col1 = ... AND col2 = ...的查询,可以用联合索引(col1, col2)代替两个单列索引。 - 索引覆盖:如果查询的所有字段都包含在联合索引中,MySQL可以直接从索引返回结果,避免 "回表查询"(即不需要访问原表数据)。
关于联合索引对查询性能的优化以及避免回表查询的场景,在前面《MySQL中,什么是回表查询,如何避免和优化?》一文中,关于通过创建覆盖索引从而避免回表中也有相关的案例。
联合索引的创建顺序
在MySQL的InnoDB存储引擎中,索引的数据结构是一个B+树(关于B+树可参考《MySQL之进阶:一篇文章搞懂MySQL索引之B+树》一文)。联合索引当然也是一颗B+树,只不过联合索引的健值数量不是一个,而是多个。
构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。假如创建一个(a,b)的联合索引,那么它的索引树是这样的:
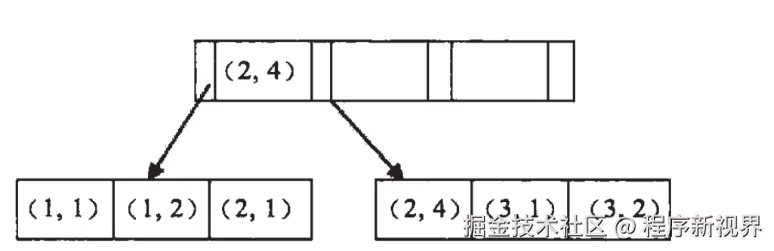
在建立联合索引时,索引的排序是按照字段在索引中的出现顺序排序的,排序优先级为从左到右。首先会按照联合索引的第一个字段排序,如果第一个字段的值相同,则按照第二个字段排序,如果第二个字段的值也相同,则按照第三个字段排序,以此类推。
在上述示例中,当如果单看第二个字段,会发现它们是无序的,因此直接用第二列作为条件查询,是无法利用索引。
联合索引的查询顺序
当查询时,MySQL会采用从左到右的顺序使用索引中的字段,排序首先依据联合索引的第一个字段(列),如果第一个字段存在重复值,再依据第二个字段排序,以此类推。一个查询可以只使用索引中的一部份,但只能是最左侧部分。
例如,如果在一个表中创建了一个联合索引 (col1, col2, col3),它实际上是一个按顺序排列的多列索引。这个索引不仅可以用于同时查询这三个列的场景,还可以根据索引的最左前缀原则(后面会专门讲到)优化部分的查询。上述索引可以支持col1、col1,col2、col1, col2, col3,这三种组合进行查找,但不支持根据col2, col3进行查找。
创建联合索引需考虑的因素
在创建和使用联合索引时,首先需要考虑一下,如何让联合索引发挥最大的优势。
除了前面聊到的在查询时保证索引覆盖场景之外,关于联合索引中各个字段的排序也十分重要,它会影响到查询的排序和分组等。
这里会涉及到索引字段的选择性和基数两个维度:
- 基数(Cardinality) 是列中不同值的数量。
- 选择性(Selectivity) 是指这些值的独特程度(计算公式为
COUNT(DISTINCT column) / COUNT(*))。
比如,可以通过以下查询计算基数和选择性:
scss
SELECT
COUNT(DISTINCT first_name) as first_name_cardinality,
COUNT(DISTINCT state) as state_cardinality,
COUNT(DISTINCT first_name) / COUNT(*) as first_name_selectivity,
COUNT(DISTINCT state) / COUNT(*) as state_selectivity
FROM people;结果如下:
| first_name_cardinality | state_cardinality | first_name_selectivity | state_selectivity |
|---|---|---|---|
| 3009 | 2 | 0.0060 | 0.0000 |
first_name字段的不同值非常多,因此选择性较高。state列选择性极低,导致通过state索引进行过滤时,效果较差。
高选择性索引通常性能较优,而低选择性索引在过滤数据时作用有限。因此,在创建联合索引时,一般性的原则是:优先将选择性高的字段放在索引的最前面。当然,这只是一般性的原则,在使用时还要根据具体的场景进行综合考虑。
最左前缀原则
联合索引的一个关键规则是 "最左前缀原则"。它决定了哪些查询可以使用联合索引。简单来说,MySQL 在使用联合索引时会从索引的第一列开始匹配,如果SQL语句中用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配。MySQL会严格按照索引的定义顺序进行匹配。
例如,对于一个联合索引 (col1, col2, col3):
- 可以使用完整的索引匹配,比如
WHERE col1 = A AND col2 = B AND col3 = C。 - 可以利用部分前缀,比如
WHERE col1 = A AND col2 = B或WHERE col1 = A。 - 可以利用部分前缀:比如
WHERE col1 = A AND col3 = C,这里只利用到了col1的索引。 - 不能跳过前面的列,比如
WHERE col2 = B AND col3 = C是无法直接使用这个联合索引的。
在上面的示例中可以看到,在 InnoDB存储引擎中,联合索引只有先确定了前一个(左侧的值)后,才能确定下一个值。
联合索引失效的情况
在上面的最左前缀原则中我们已经看到了一种联合索引失效的情况,也就是"不能跳过前面的列"的场景。除此之外,还有一些失效的场景。
范围查询会阻止后续字段的索引匹配
当查询条件涉及联合索引中的某一列执行范围查询 (>, <, BETWEEN, LIKE)时,会导致对于后续字段的匹配能力下降,但并非完全不能匹配。这意味着后续字段不能用于加速查找,但在某些情况下仍然可以通过"覆盖索引"等方式提升性能。例如,查询仍有可能是索引覆盖的形式,可以避免回表。
范围查询对B+树的规则影响
在联合索引中,索引是按字典序排序的。但范围条件的查询会导致匹配过程只能在索引的一部分上"范围查找",这使得后续字段无法充分利用索引的排序信息。索引查找的行为如下:
- 对于范围条件的字段,它会在索引树的某个范围内进行遍历。
- 对于后续字段,由于索引的排序已经不连续,它无法通过树快速定位后续字段的具体值。
依旧假设有一个联合索引 (col1, col2, col3),以下两种情况会破坏索引的连续性,无法重复利用索引。
场景一:
sql
SELECT * FROM table WHERE col1 = 100 AND col2 > 200 AND col3 = 300对 col1 的匹配仍然可以精确定位到某个范围,然后 col2 > 200 会进行范围查找。但由于范围查找破坏了索引的连续性,col3 = 300 无法充分利用索引进行查找,因此后续字段的匹配效率较低。
场景二:
sql
SELECT * FROM table WHERE col1 LIKE 'abc%' AND col2 = 200 AND col3 = 300如果 col1 LIKE 'abc%' 是前缀匹配(非通配符如 'abc_%'),索引仍能够匹配。而对于后续字段的匹配效果会受到限制,尤其是通配符位置(例如 '%abc')。
范围查询并不影响索引覆盖功能
如果查询只涉及联合索引中的字段,并且查询的字段为所需字段(不涉及回表),联合索引仍然可以起到覆盖索引的作用。例如以下查询:
sql
SELECT col1, col2 FROM table WHERE col1 = 100 AND col2 > 200;虽然范围查询会导致部分列无法继续匹配,但由于返回的字段完全存在于索引中,仍然能够实现索引的覆盖查询。
小结
联合索引在日常开发中是非常重要的一个索引类型,根据具体的情况,创建核实的联合索引可以有效提升查询速度。当然,索引的存在必然是以空间来换时间的,并不是越多越好。在使用联合索引进行查询时,查询条件按照索引的字段的顺序一次匹配,不能跳过前面的字段,否则会导致联合索引失效。同时,一些范围匹配的条件,也会导致后面的索引失效。希望这篇文章能够让你更全面的了解联合索引以及最左前缀原则。