一、引言
在前面我们了解了Deployment、ReplicaSet、DaemonSet ,它们在容器编排中各自扮演着重要角色,尤其是 Deployment,作为管理无状态应用的得力助手 ,通过控制 ReplicaSet,让无状态应用的部署、扩展、更新变得轻而易举,你只需要简单地定义好 Pod 模板和副本数量,Kubernetes 就能自动帮你维持应用的运行状态。但当我们遇到像数据库(如 MySQL )、消息队列(如 Kafka )这类有状态应用时,之前那些管理无状态应用的控制器就显得力不从心了。因为有状态应用和无状态应用有着本质区别:无状态应用就像一个个独立的 "工作机器",每个实例都能独立处理请求,它们之间没有共享的状态,也不需要记住之前的请求信息,就好比一个简单的 Web 服务器,每次收到 HTTP 请求,都能根据请求内容独立返回响应,不会受之前请求的影响,所以可以随意增加或减少实例数量来应对不同的负载。而有状态应用则像是一个个 "记忆大师",它们在处理请求的过程中会保存客户端的状态信息 ,并且在后续请求中需要依赖这些信息来做出响应。为了应对有状态应用的这些复杂需求,Kubernetes 引入了 StatefulSet 这个强大的工具,它就像是为有状态应用量身定制的 "管家",专门负责管理有状态应用的生命周期,从 Pod 的创建、启动顺序,到网络标识的分配,再到数据的持久化存储,StatefulSet 都能精心照料,确保有状态应用在 Kubernetes 集群中稳定、可靠地运行。
二、StatefulSet 是什么
StatefulSet 是 Kubernetes 中的一种工作负载 API 对象 ,专门为管理有状态应用而生。与我们熟悉的 Deployment 管理无状态应用不同,StatefulSet 在有状态应用的部署、管理方面有着独特的优势。
在 StatefulSet 中,每个 Pod 都拥有独一无二的 "身份信息" ,包括稳定的网络标识符和持久化存储。比如说,当你创建一个包含 3 个副本的 StatefulSet 时,Kubernetes 会为这 3 个 Pod 分别命名为statefulset-name-0、statefulset-name-1、statefulset-name-2 ,这个编号会成为 Pod 的一部分,无论 Pod 如何重启、迁移,它的编号和对应的网络标识都不会改变,就像给每个 Pod 都发了一张独一无二的 "身份证",凭借这张 "身份证",其他服务可以准确无误地找到对应的 Pod。
而且,StatefulSet 对 Pod 的创建和删除顺序有着严格的控制,它会按照顺序依次创建和删除 Pod 。在扩容时,先创建编号为 0 的 Pod,等它运行稳定且处于 Ready 状态后,才会创建编号为 1 的 Pod,依此类推;缩容时则正好相反,先删除编号最大的 Pod 。这种有序性对于有状态应用非常重要,比如在一个分布式数据库集群中,节点之间需要相互通信并保持数据的一致性,如果节点的启动顺序混乱,可能会导致数据同步失败、集群无法正常工作等问题 。
此外,StatefulSet 还支持为每个 Pod 分配独立的持久卷声明(PersistentVolumeClaim,PVC) ,这意味着每个 Pod 都能拥有自己专属的持久化存储空间,并且当 Pod 被删除重建时,新的 Pod 依然可以挂载到原来的持久卷上,保证数据不会丢失 ,就像每个 Pod 都有一个属于自己的 "专属仓库",无论它搬到哪里,都能找到自己的 "仓库" 并取用里面的数据。
三、StatefulSet 的核心特性
3.1 稳定的网络标识
在 StatefulSet 中,每个 Pod 都拥有一个基于 DNS 的唯一稳定网络标识符 。假设你创建了一个名为nginx-statefulset的 StatefulSet ,并指定了一个名为nginx-service的无头服务(Headless Service) ,那么其中的 Pod 将会拥有类似nginx-statefulset-0.nginx-service.default.svc.cluster.local这样的域名 。无论这个 Pod 在集群中如何迁移、重启,它的网络标识符始终保持不变 。对于像 Kafka 这样的分布式消息队列,各个 Broker 节点之间需要通过稳定的网络标识进行通信和数据同步 ,如果网络标识不稳定,Broker 之间就无法准确地找到彼此,导致消息传递失败、集群状态不一致等问题 。而 StatefulSet 提供的稳定网络标识就像是给每个节点都配备了一个不会改变的 "通信地址",确保了它们之间的通信畅通无阻 。
3.2 有序且稳定的部署和扩展
StatefulSet 对 Pod 的创建和删除顺序有着严格的控制 。当你创建一个包含多个副本的 StatefulSet 时,Kubernetes 会按照从 0 开始的顺序依次创建 Pod ,比如先创建statefulset-name-0,只有当这个 Pod 处于 Running 和 Ready 状态后,才会接着创建statefulset-name-1 ,依此类推 。在缩容时,顺序则相反,会从最大序号的 Pod 开始删除 。以一个 MySQL 主从集群为例,主节点需要先启动并完成初始化配置,从节点才能正确地连接到主节点并进行数据同步 。如果 Pod 的启动顺序混乱,从节点可能会因为无法找到主节点或者连接到错误的主节点而导致数据同步失败 。StatefulSet 这种有序的部署和扩展方式,就像是给集群中的节点安排了一场有条不紊的 "入场和退场仪式",保证了集群的正常运行 。而且,这种有序性也大大简化了备份、恢复等操作 ,因为你可以按照固定的顺序对各个节点进行操作,不用担心因为顺序问题导致数据丢失或不一致 。
3.3 持久存储
StatefulSet 支持为每个 Pod 分配独立的持久卷声明(PersistentVolumeClaim,PVC) 。通过在 StatefulSet 的配置文件中定义volumeClaimTemplates字段 ,可以为每个 Pod 自动创建一个对应的 PVC 。当 Pod 被删除并重新创建时,新的 Pod 会挂载到原来的 PVC 上,从而保证数据的持久性 。以一个电商网站的用户订单数据存储为例,每个订单数据都非常重要,不能因为 Pod 的重启或迁移而丢失 。使用 StatefulSet 管理订单数据存储的 Pod,每个 Pod 都有自己专属的 PVC ,这些 PVC 可以绑定到持久卷(PersistentVolume,PV)上,PV 可以是 NFS、Ceph 等各种存储类型 。这样,无论 Pod 在集群中如何变化,订单数据都能安全地存储在对应的 PV 中 ,就像每个 Pod 都有一个坚固的 "数据保险箱",始终保护着重要的数据 。
3.4 自动化的更新策略
StatefulSet 提供了滚动更新和回滚的能力 。在进行滚动更新时,它会按照从最大序号到最小序号的顺序,依次更新每个 Pod 。例如,有一个包含 3 个副本的 StatefulSet ,在更新时,会先更新statefulset-name-2,等这个 Pod 更新完成并处于 Ready 状态后,再更新statefulset-name-1 ,最后更新statefulset-name-0 。这种更新方式相比 Deployment 更加保守,默认情况下不会同时更新所有 Pod ,从而减少了对服务的影响 。而且,如果你在更新过程中发现问题,比如新的镜像版本存在严重的 Bug ,可以随时执行回滚操作,将 StatefulSet 恢复到之前的稳定版本 。你可以通过配置Partition字段来控制哪些 Pod 参与更新,哪些保持不变 ,这就像是给更新过程设置了一个灵活的 "开关",让你能够根据实际情况精确地控制更新的范围和节奏 。
3.5 稳定的身份
每个 Pod 在 StatefulSet 中都有一个稳定的身份,包括名称和主机名 。Pod 的名称遵循statefulset-name-ordinal的格式 ,其中ordinal是从 0 开始的整数 。这种稳定的身份使得 Pod 在网络中可以被可靠地识别和访问 。比如在一个分布式文件系统中,各个存储节点需要有稳定的身份标识,以便其他节点能够准确地与它们进行数据交互 。如果节点的身份不稳定,就可能导致数据读取错误、写入失败等问题 。StatefulSet 赋予 Pod 稳定的身份,就像是给每个节点颁发了一张独一无二的 "身份名片",让它们在复杂的网络环境中能够被准确地识别和找到 。
3.6 服务发现
Kubernetes 会为 StatefulSet 创建的每个 Pod 自动生成 Headless Service(无头服务) ,这种服务没有 Cluster IP ,它的主要作用是通过 DNS 为每个 Pod 提供一个唯一的域名 ,允许客户端通过 DNS 查询找到这些 Pod 。以一个分布式数据库集群为例,客户端需要能够准确地找到集群中的每个数据库节点 。通过 Headless Service,客户端只需要知道 StatefulSet 的名称和服务名称 ,就可以通过 DNS 查询到对应的 Pod 域名,进而获取到 Pod 的 IP 地址 ,实现与数据库节点的通信 。你还可以为 StatefulSet 配置常规的 ClusterIP 类型服务,以便外部访问 ,这就像是为 StatefulSet 提供了内外两套 "通信渠道",满足了不同场景下的访问需求 。
四、StatefulSet 的应用场景
4.1 数据库集群
对于像 MySQL、PostgreSQL 这样的关系型数据库,以及 MongoDB 这样的非关系型数据库,StatefulSet 简直是它们在 Kubernetes 集群中的 "最佳拍档" 。在数据库集群中,每个节点都有自己独特的角色和任务 ,比如主节点负责写入数据,从节点负责从主节点同步数据并提供读服务 。这些节点之间需要通过稳定的网络标识进行通信 ,以确保数据的一致性和集群的正常运行 。而且,每个节点都需要有自己独立的持久化存储,用来保存数据库文件 。如果使用 Deployment 来管理数据库集群,由于 Pod 的网络标识不稳定,可能会导致节点之间通信失败 ,数据同步出现问题 。而 StatefulSet 为每个 Pod 分配的稳定网络标识和独立持久化存储,正好满足了数据库集群的这些严格要求 。以一个 MySQL 主从集群为例,主节点可以通过稳定的网络标识被从节点准确地找到 ,从节点也能通过自己的稳定标识与主节点进行数据同步 ,保证了数据的可靠复制和集群的高可用性 。
4.2 分布式缓存
在分布式系统中,缓存是提高系统性能的重要手段 ,像 Redis 集群这样的分布式缓存,通常需要每个节点有自己的持久化存储来保存缓存数据 ,并且需要一个稳定的网络标识以便于其他节点进行访问和数据交互 。StatefulSet 可以确保每个 Redis 节点都有稳定的身份和持久化存储 ,使得分布式缓存集群能够稳定、高效地运行 。当系统中的某个 Redis 节点出现故障时,StatefulSet 会自动重建该节点,并挂载原来的持久化存储,保证缓存数据不会丢失 。而且,在集群扩展时,新加入的节点也能通过稳定的网络标识与其他节点协同工作 ,共同为系统提供高效的缓存服务 。
4.3 消息队列集群
Kafka 作为一种高性能的分布式消息队列,广泛应用于大数据领域 ,它对节点的稳定性和有序性有着很高的要求 。每个 Kafka Broker 节点都需要有稳定的网络标识,以便生产者和消费者能够准确地与它们进行通信 。同时,为了保证消息的可靠性,Broker 节点需要将消息持久化存储在磁盘上 。StatefulSet 的稳定网络标识和持久化存储特性,使得 Kafka 集群能够在 Kubernetes 环境中稳定运行 。在 Kafka 集群的扩容过程中,StatefulSet 会按照顺序依次创建新的 Broker 节点 ,确保新节点能够正确地加入集群并与其他节点进行数据同步 。在缩容时,也会按照顺序依次删除节点,避免因为节点的突然删除而导致消息丢失或集群状态异常 。
4.4 分布式文件系统
比如 Ceph 这样的分布式文件系统,它由多个存储节点组成 ,这些节点之间需要通过稳定的网络标识进行通信和数据同步 ,并且每个节点都需要有自己的持久化存储来保存文件数据 。StatefulSet 能够为 Ceph 存储节点提供稳定的身份标识和持久化存储支持 ,保证分布式文件系统的正常运行 。在 Ceph 集群的部署和扩展过程中,StatefulSet 的有序部署和扩展特性,可以确保每个存储节点都能正确地加入集群,并与其他节点协同工作 ,为用户提供可靠的文件存储服务 。
五、StatefulSet 与 Deployment 的区别
通过上面的介绍,相信你对 StatefulSet 和 Deployment 都有了一定的了解,接下来我们就来深入对比一下它们之间的区别 。
5.1 网络标识
在 Deployment 中,Pod 的 IP 地址是动态分配的,每次重启或重新调度后,IP 地址都可能发生变化 ,这就好比你每次搬家都要换一个新的门牌号,对于那些需要稳定通信的服务来说,这显然不太方便 。而且 Deployment 中的 Pod 没有稳定的 DNS 名称 ,你很难通过一个固定的域名去访问它 。而 StatefulSet 则为每个 Pod 提供了稳定的网络标识 ,每个 Pod 都有一个基于 DNS 的唯一稳定域名 ,格式为<statefulset-name>-<ordinal>.<service-name>.<namespace>.svc.cluster.local ,其中<ordinal>是从 0 开始的序号 。无论 Pod 如何重启、迁移,它的域名和 IP 地址在其生命周期内都保持不变 ,就像给每个 Pod 都安排了一个永远不变的 "通信地址",确保了通信的稳定性 。
5.2 存储方式
Deployment 通常使用共享存储或不使用持久化存储 。在更新 Pod 时,它不太关注存储数据的保留 ,这就像是你住在一个随时可能被替换的临时住所里,里面的东西也随时可能消失 。如果你的应用需要持久化存储,Deployment 可能就不太适合了 。而 StatefulSet 支持为每个 Pod 分配独立的持久卷声明(PVC) ,每个 Pod 都有自己专属的持久化存储空间 。当 Pod 被删除重建时,新的 Pod 依然可以挂载到原来的 PVC 上 ,保证数据不会丢失 ,就像每个 Pod 都有一个属于自己的坚固 "数据保险箱",无论遇到什么情况,数据都能安全保存 。
5.3 部署与扩展
Deployment 在部署和扩展时非常灵活,它可以根据你的需求快速地创建或删除多个 Pod ,这些 Pod 的创建和删除是无序的 ,可以并行进行 。这就像是一群工人同时开工,快速地搭建起一座建筑 。对于无状态应用来说,这种方式非常高效,可以快速地满足业务的负载需求 。而 StatefulSet 在部署和扩展时则非常注重顺序 ,它会按照从 0 开始的顺序依次创建 Pod ,只有当前一个 Pod 处于 Running 和 Ready 状态后,才会创建下一个 Pod 。在缩容时,也是从最大序号的 Pod 开始删除 。这种有序性对于有状态应用非常重要,比如在一个分布式数据库集群中,节点之间需要按照特定的顺序启动和停止 ,以保证数据的一致性和集群的正常工作 。
5.4 更新策略
Deployment 支持滚动更新和回滚功能 。在进行滚动更新时,它可以同时更新多个 Pod ,通过控制maxSurge和maxUnavailable参数 ,可以灵活地控制更新过程中 Pod 的数量变化 ,从而实现零停机时间的更新 。如果更新过程中出现问题,还可以随时回滚到之前的版本 。这就像是你在给房子装修时,可以同时对多个房间进行改造,如果发现某个房间的装修效果不理想,还可以随时恢复原状 。而 StatefulSet 在更新时则更加保守 ,默认采用顺序方式,逐个更新 Pod ,以确保数据的一致性 。它也支持滚动更新,但需要你更加谨慎地配置和管理 。你可以通过配置Partition字段来控制哪些 Pod 参与更新,哪些保持不变 。这就像是你在给房子装修时,每次只改造一个房间,确保每个房间都装修好后,再进行下一个房间的改造 。
5.5 适用场景
Deployment 主要适用于无状态应用 ,比如 Web 服务器、API 服务等 。这些应用不需要保存客户端的状态信息 ,每个实例都可以独立处理请求 ,所以可以随意增加或减少实例数量来应对不同的负载 。而且 Deployment 的快速扩展和更新特性,非常适合那些需要频繁迭代和快速响应业务变化的应用 。而 StatefulSet 则主要适用于有状态应用 ,比如数据库、分布式文件系统、消息队列等 。这些应用需要保存客户端的状态信息 ,并且在后续请求中需要依赖这些信息来做出响应 。StatefulSet 提供的稳定网络标识和持久化存储特性,正好满足了有状态应用的这些严格要求 。
六、使用 YAML 描述 StatefulSet
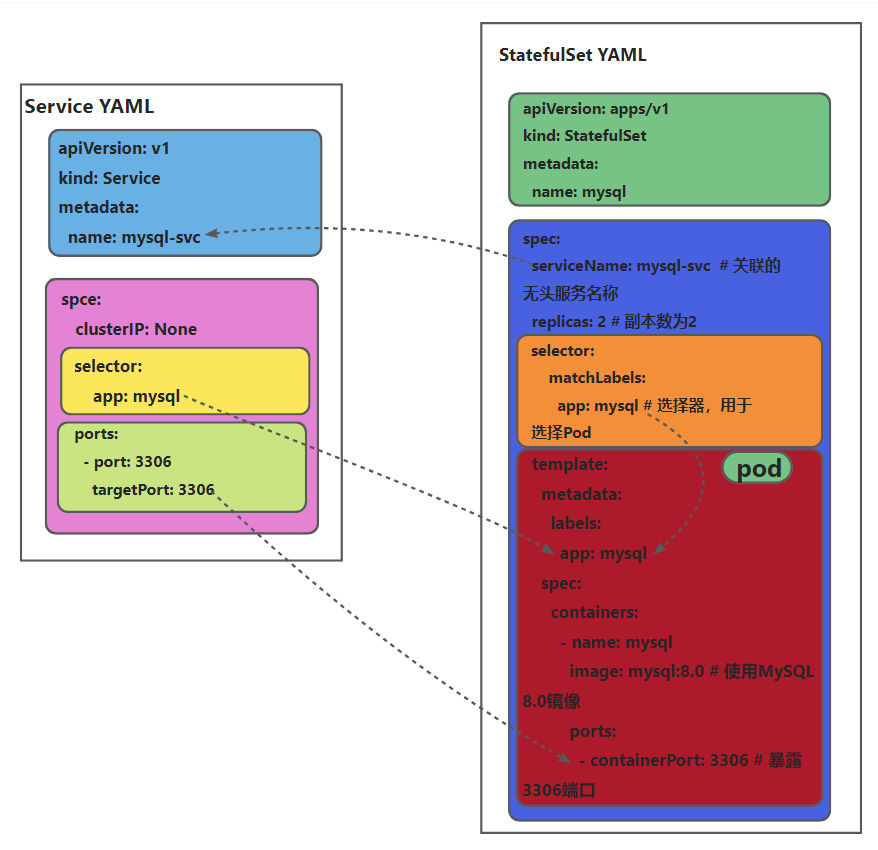
我们创建一个 StatefulSet 来部署 MySQL 。下面是 MySQL StatefulSet 的 YAML 文件示例 :
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: mysql # 关联的无头服务名称
replicas: 2 # 副本数为2
selector:
matchLabels:
app: mysql # 选择器,用于选择Pod
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0 # 使用MySQL 8.0镜像
ports:
- containerPort: 3306 # 暴露3306端口在这个配置文件中,serviceName指定了关联的无头服务名称 ,replicas指定了副本数 ,selector用于选择 Pod ,template定义了 Pod 的模板 ,包括容器的镜像、端口存储卷挂载等信息 。
创建好上述配置文件后,我们可以使用kubectl命令来创建这些资源 :
kubectl apply -f mysql-pv.yaml
kubectl apply -f mysql-pvc.yaml
kubectl apply -f mysql-statefulset.yaml接下来我们就需要去创建一个service对象了,当我们把 Service 对象应用于 StatefulSet 的时候,情况就不一样了。 Service 发现这些 Pod 不是一般的应用,而是有状态应用,需要有稳定的网络标识,所以就会为 Pod 再多创建出一个新的域名,格式是"Pod 名. 服务名. 名字空间.svc.cluster.local"。当然,这个域名也可以简写成"Pod 名. 服务名"。
在 StatefulSet 里的这两个 Pod 都有了各自的域名,也就是稳定的网络标识。那么接下来,外部的客户端只要知道了 StatefulSet 对象,就可以用固定的编号去访问某个具体的实例 了,虽然 Pod 的 IP 地址可能会变,但这个有编号的域名由 Service 对象维护,是稳定不变的。
关于 Service,有一点值得再多提一下。 Service 原本的目的是负载均衡,应该由它在 Pod 前面来转发流量,但是对 StatefulSet 来说,这项功能反而是不必要的,因为 Pod 已经有了稳定的域名,外界访问服务就不应该再通过 Service 这一层了。所以,从安全和节约系统资源的角度考虑,我们可以在 Service 里添加 一个字段 clusterIP: None ,告诉 Kubernetes 不必再为这个对象分配 IP 地址。
下面我们用一张图来看一下两者之间的关系:
七、实战演练StatefulSet 的数据持久化
创建 PersistentVolume (PV) 和 PersistentVolumeClaim (PVC)MySQL 需要持久化存储来保存数据 ,因此我们需要创建 PersistentVolume (PV) 和 PersistentVolumeClaim (PVC) 。PV 是集群中的一块存储资源,而 PVC 则是对 PV 的请求 。下面是一个简单的 PV 和 PVC 的 YAML 文件示例 :
PV 配置文件( mysql-pv.yaml ):
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 10Gi # 定义PV的存储容量为10Gi
accessModes:
- ReadWriteOnce # 访问模式为ReadWriteOnce,意味着只能被一个Pod以读写方式挂载
persistentVolumeReclaimPolicy: Retain # 回收策略为Retain,即当PVC被删除时,PV的数据不会被删除
storageClassName: "" # 不指定存储类
hostPath:
path: /data/mysql # PV在宿主机上的路径PVC 配置文件(mysql-pvc.yaml):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi # 请求的存储容量为5Gi,不能大于PV的容量
storageClassName: ""创建 StatefulSet 资源
接下来,我们创建一个 StatefulSet 来部署 MySQL 。下面是 MySQL StatefulSet 的 YAML 文件示例 :
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: mysql # 关联的无头服务名称
replicas: 1 # 副本数为1
selector:
matchLabels:
app: mysql # 选择器,用于选择Pod
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0 # 使用MySQL 8.0镜像
ports:
- containerPort: 3306 # 暴露3306端口
env:
- name: MYSQL_ROOT_PASSWORD
value: "password" # 设置root用户密码
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql # 将PVC挂载到容器内的/var/lib/mysql目录
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi # PVC请求的存储容量
storageClassName: ""在这个配置文件中,serviceName指定了关联的无头服务名称 ,replicas指定了副本数 ,selector用于选择 Pod ,template定义了 Pod 的模板 ,包括容器的镜像、端口、环境变量以及存储卷挂载等信息 。volumeClaimTemplates定义了 PVC 模板,每个 Pod 都会创建一个对应的 PVC 。
应用配置
创建好上述配置文件后,我们可以使用kubectl命令来创建这些资源 :
kubectl apply -f mysql-pv.yaml
kubectl apply -f mysql-pvc.yaml
kubectl apply -f mysql-statefulset.yaml验证部署
使用以下命令检查 Pod 的状态,确保 MySQL Pod 已经成功创建并处于 Running 状态 :
kubectl get pods -l app=mysql如果 Pod 处于 Running 状态,你可以使用以下命令查看 Pod 的日志,确认 MySQL 是否正常启动 :
kubectl logs -l app=mysql访问 MySQL 数据库
要访问 MySQL 数据库,我们可以使用 Port Forwarding 将本地端口映射到 MySQL Pod 的 3306 端口 :
kubectl port-forward svc/mysql 3306:3306然后,你可以使用 MySQL 客户端连接到本地的 3306 端口 ,例如:
mysql -uroot -ppassword -h127.0.0.1至此我们就能看到MySQL服务已经部署成功。
八、总结
StatefulSet 作为 Kubernetes 管理有状态应用的关键工具,凭借其稳定的网络标识、有序的部署和扩展、持久的存储保障等特性,为数据库集群、分布式缓存、消息队列集群等有状态应用在容器化环境中的稳定运行提供了坚实支撑。它与 Deployment 在功能和适用场景上的差异,也让开发者能够根据应用的特点选择最合适的管理方式 。