2.1.2 扩展知识:AI 语音通话
在前面,我们已经掌握了构建基于文本的智能应用的核心技术。现在,让我们将视野拓展到更具挑战性、也更自然的交互形式:AI 语音通话。
AI 语音通话的目标是让用户能够像与真人对话一样,与 AI 进行实时、流畅的语音交流。这背后涉及多项技术的协同工作,而不仅仅是简单的文本转语音(TTS)和语音转文本(ASR)。
核心技术
一个完整的 AI 语音通话系统通常由以下几个核心组件构成:
- 语音转文本(ASR): 将用户的语音实时转换成文字。这是整个系统的第一步,也是最关键的一环。它需要有极高的准确率和极低的延迟。
- LLM 推理: ASR 输出的文字被送入 LLM 进行理解和推理。这部分利用了我们之前学到的 RAG、Function Calling 等技术,来处理用户的复杂请求。
- 文本转语音(TTS): LLM 生成的文字回答,需要通过 TTS 技术转换成自然、流畅的语音。高质量的 TTS 不仅能准确发音,还能模拟人类的语调、情感和停顿。
- 实时流式处理: 为了实现低延迟的实时对话,所有组件都必须采用流式处理(Streaming)的方式。例如,ASR 会一边接收用户的语音流,一边输出文字流;LLM 也需要能以流式方式生成回答,而 TTS 则一边接收 LLM 的文字流,一边输出语音流。
AI 语音通话工作流时序图
下面的时序图展示了一个理想的、低延迟的 AI 语音通话系统的端到端流程。
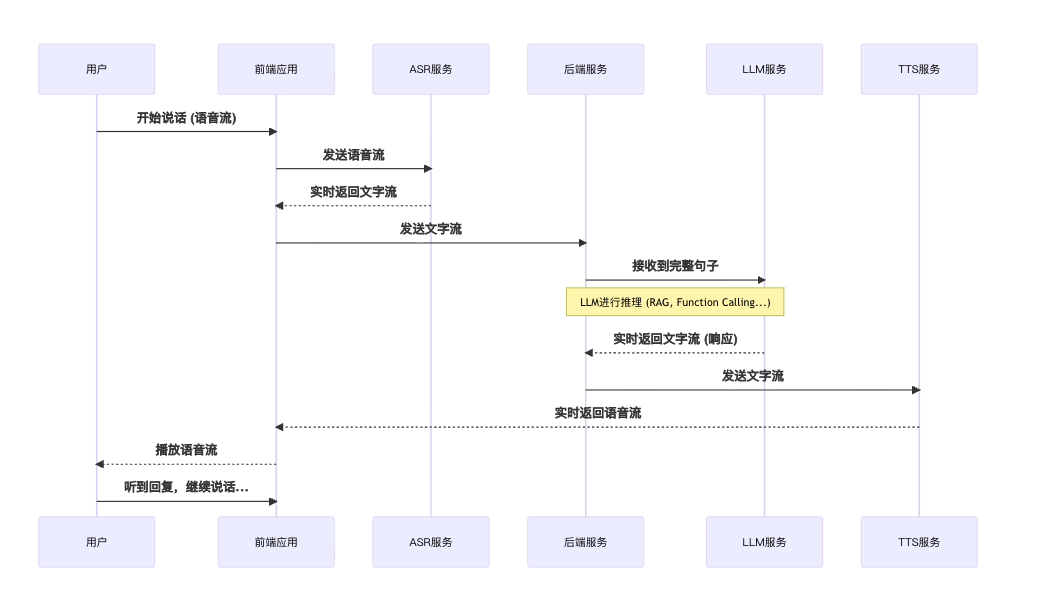
时序图解读:
- 这个流程强调了流式处理的重要性。LLM 在收到用户完整句子后开始推理,而 TTS 在收到 LLM 的第一个词后就可以开始生成语音并播放,这极大地减少了用户等待时间。
2.0 实战:WebRTC 实时语音问答 (Python)
这个项目是一个典型的 多技术融合 示例,它将前端的实时通信技术与后端的 AI 能力无缝结合,成功构建了一个低延迟、高交互性的语音问答应用。
准备工作:
- 安装 uv
- 使用python 3.12 版本
2.1 前端与后端:各自的职责
在 WebRTC 语音通话中,前端和后端扮演着不同的角色,但又紧密协作。
前端职责:
- 本地媒体采集: 获取麦克风音频流。
- 信令发起方: 作为连接的发起者,创建 SDP Offer 并通过 HTTP POST 发送给后端。
- 音频流传输: 使用
RTCPeerConnection将本地音频流传输给后端。 - 数据流接收与播放: 接收来自后端的实时 ASR 结果和 TTS 音频流,并进行播放和可视化。
后端职责:
- 信令响应方: 接收前端的 SDP Offer,创建 SDP Answer 并返回,完成 WebRTC 握手。
- 音频流接收: 接收并处理来自前端的音频流。
- AI 核心处理: 串联 ASR、LLM 和 TTS 服务,将语音流转换成有意义的回复。
- 数据流推送: 通过 WebSocket,将处理后的 ASR 文本和 TTS 音频主动推送给前端。
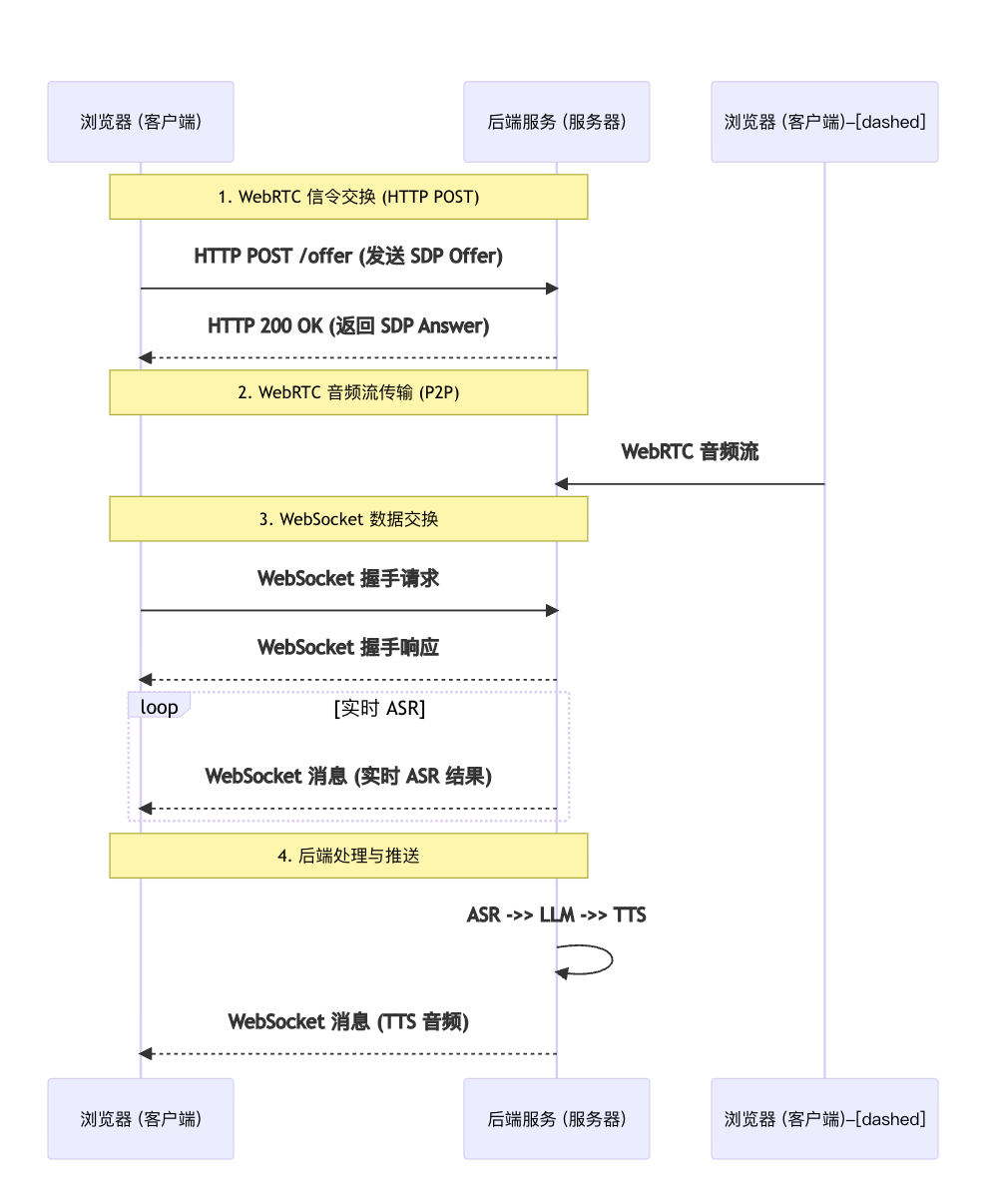
2.2 信令与数据交换时序图
这个时序图详细展示了前端 WebRTC 的信令交换(蓝色)和 WebSocket 的数据交换(红色)过程,这两种机制共同构成了整个应用的实时通信基础。
2.3 核心代码解析
为了便于理解,我们对你提供的完整代码进行分模块解析,并突出核心部分。
前端核心:WebRTC 信令交换与音频流处理
这段前端代码展示了 WebRTC 连接建立的核心步骤。当用户点击"开始对话"后,浏览器会执行以下操作:
- 获取媒体流 :
navigator.mediaDevices.getUserMedia()请求用户麦克风权限。 - 创建 RTCPeerConnection :
pc = new RTCPeerConnection(...)创建一个用于管理 WebRTC 连接的对象。 - 添加本地音频轨道 :
stream.getTracks().forEach(track => pc.addTrack(track, stream))将麦克风音频流的轨道添加到RTCPeerConnection中,使其可以传输到对端。 - SDP Offer 生成与发送 :
pc.createOffer():生成一个 SDP (Session Description Protocol) Offer,其中包含了本地音频流的媒体信息。pc.setLocalDescription(offer):将这个 Offer 设置为本地描述。fetch('/offer', ...):通过 HTTP POST 将这个 Offer 发送给后端,这是 WebRTC 连接建立的第一步信令交换。
- SDP Answer 接收与设置 :
const answer = await response.json():等待后端处理 Offer 并返回一个 SDP Answer。pc.setRemoteDescription(answer):将这个 Answer 设置为远程描述,完成了信令握手,双方现在已经知道了如何相互通信。
javascript
// 获取麦克风权限并建立 WebRTC 连接
document.getElementById('start').onclick = async () => {
// ...省略音频可视化代码
// 创建 RTCPeerConnection
pc = new RTCPeerConnection({
iceServers: [{ urls: 'stun:stun.l.google.com:19302' }]
});
stream = await navigator.mediaDevices.getUserMedia({ audio: true, video: false });
stream.getTracks().forEach(track => pc.addTrack(track, stream));
const offer = await pc.createOffer();
await pc.setLocalDescription(offer);
// 发送 Offer 进行信令交换
const response = await fetch('/offer', {
method: 'POST',
body: JSON.stringify({ sdp: pc.localDescription.sdp, type: pc.localDescription.type }),
headers: { 'Content-Type': 'application/json' }
});
const answer = await response.json();
await pc.setRemoteDescription(answer);
};
// WebSocket 消息监听,用于接收后端实时数据
ws.onmessage = function(event) {
const data = JSON.parse(event.data);
if (data.type === 'asr_result_ing' || data.type === 'asr_result') {
// 更新前端 ASR 识别结果
// ...
} else if (data.type === 'tts_audio') {
// 播放后端传来的 TTS 音频
// ...
}
};后端核心:模型注册与 AudioTrackReceiver
这段 Python 代码是整个后端逻辑的精髓,它将来自 WebRTC 的音频流与 AI 服务无缝对接。
python
# 1. 模型初始化与配置
import sherpa_onnx
# ...省略模型文件路径定义...
# 初始化 ASR 模型
stt_recognizer = None
try:
if not all(os.path.exists(f) for f in [ASR_ENCODER_MODEL, ASR_DECODER_MODEL, ASR_JOINER_MODEL, ASR_TOKENS_FILE]):
print(f"ASR 模型文件未找到,请检查路径: {ASR_MODEL_DIR}")
else:
stt_recognizer = sherpa_onnx.OnlineRecognizer.from_transducer(
tokens=ASR_TOKENS_FILE,
encoder=ASR_ENCODER_MODEL,
decoder=ASR_DECODER_MODEL,
joiner=ASR_JOINER_MODEL,
)
print("Sherpa-ONNX ASR 模型加载成功。")
except Exception as e:
print(f"加载 Sherpa-ONNX ASR 模型失败: {e}")
# 初始化 TTS 模型
tts_model = None
try:
if not all(os.path.exists(f) for f in [TTS_MODEL_FILE, TTS_LEXICON_FILE, TTS_TOKENS_FILE]):
print(f"TTS 模型文件未找到,请检查路径: {TTS_MODEL_DIR}")
else:
tts_config = sherpa_onnx.OfflineTtsConfig(
model=sherpa_onnx.OfflineTtsModelConfig(
vits=sherpa_onnx.OfflineTtsVitsModelConfig(
model=TTS_MODEL_FILE, lexicon=TTS_LEXICON_FILE, tokens=TTS_TOKENS_FILE,
),
),
)
tts_model = sherpa_onnx.OfflineTts(tts_config)
print("Sherpa-ONNX TTS 模型加载成功。")
except Exception as e:
print(f"加载 Sherpa-ONNX TTS 模型失败: {e}")
# aiortc.contrib.media.AudioTrackReceiver 的核心实现
class AudioTrackReceiver(MediaStreamTrack):
kind = "audio"
def __init__(self, track):
super().__init__()
self.track = track
# 在这里创建 ASR 流,而非在外部
self.asr_stream = stt_recognizer.create_stream()
async def recv(self):
global asr_id
frame = await self.track.recv() # 循环接收 WebRTC 音频帧
# 核心逻辑: VAD 和音频数据处理
pcm_array = frame.to_ndarray().flatten().astype(np.int16)
is_speech = self.vad.is_speech(pcm_array.tobytes(), frame.sample_rate)
# 如果是语音活动...
if is_speech:
self.audio_buffer.append(pcm_array.tobytes())
# 当静音时间超过阈值,处理完整句子
if (current_time - self.last_audio_time) >= self.silence_threshold:
# 1. 组合音频并送入 ASR 模型
combined_audio = b''.join(self.audio_buffer)
self.asr_stream.accept_waveform(...)
result = stt_recognizer.get_result(self.asr_stream)
if result:
# 2. 调用 LLM 服务获取回复
response = await call_zhipu_llm_api(result)
# 3. 使用 TTS 生成音频
audio_data = tts_model.generate(response, sid=0, speed=1.0)
audio_bytes = audio_data.samples.astype(np.int16).tobytes()
audio_base64 = base64.b64encode(audio_bytes).decode('utf-8')
# 4. 通过 WebSocket 将音频推送回前端
await ws.send_json({
'type': 'tts_audio',
'audio': audio_base64,
'sample_rate': audio_data.sample_rate
})
# 清空缓冲区,为下一轮对话做准备
self.audio_buffer = []
self.asr_stream = stt_recognizer.create_stream()
return frame2.4 关键技术亮点
- 本地化推理 :项目中使用的 Sherpa-ONNX 实现了 ASR 和 TTS 模型的本地推理。这极大地减少了对云端服务的依赖,降低了延迟和成本。
- 流式处理 :从前端的 WebRTC 音频流,到后端的 ASR/TTS 处理,再到 WebSocket 的数据传输,整个流程都采用了流式处理。这意味着系统无需等待所有数据处理完成,就可以开始传输和播放,从而实现了亚秒级的实时对话延迟。
- VAD(语音活动检测):这是实现流畅对话的关键。VAD 能够智能地识别出用户何时停止说话,从而避免了不完整的句子被发送给 LLM,提高了交互的准确性和自然性。
通过以上模块的协同工作,我们构建了一个从语音输入到语音输出,端到端完整且高效的 AI 语音问答系统。
其他资源
火山音频引擎: https://www.volcengine.com/product/veRTC
TTS 模型配置: https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/vits-icefall-zh-aishell3.tar.bz2