- JOINT AUDIO AND SPEECH UNDERSTANDING
- LTU-AS:listen to, think of, and understand audio and speech,也就是在LTU基础上增加语音识别能力
- 一种模型优化技术:其实就是在LTU具有音频感知和理解能力的基础上,引入识别能力。看这篇文章前建议先看完《Whisper-AT:一个统一语音识别和音频标签的模型》和《LTU:一种能听、能想、能理解的大模型架构》。
章节1:背景介绍
人类生活在一个多样化的音频信号环境中,包括语音和各种非语音声音。人可以准确辨识、解释和整合这些语音和非语音音频元素,以及深刻理解它们之间的关系。无所不能的人工智能也应该具备这样的能力!
于是论文提出了一种新的模型结构LTU-AS,下图展示了LTU-AS效果,我们看一下第一个示例:感知到了人声和篮球弹跳的声音,同时基于识别出的说话内容,推测出这个说话人正在指导别人打篮球教练。可以看出这个模型同时具备了音频感知、理解能力、识别能力。

章节2:方案阐述
框架设计
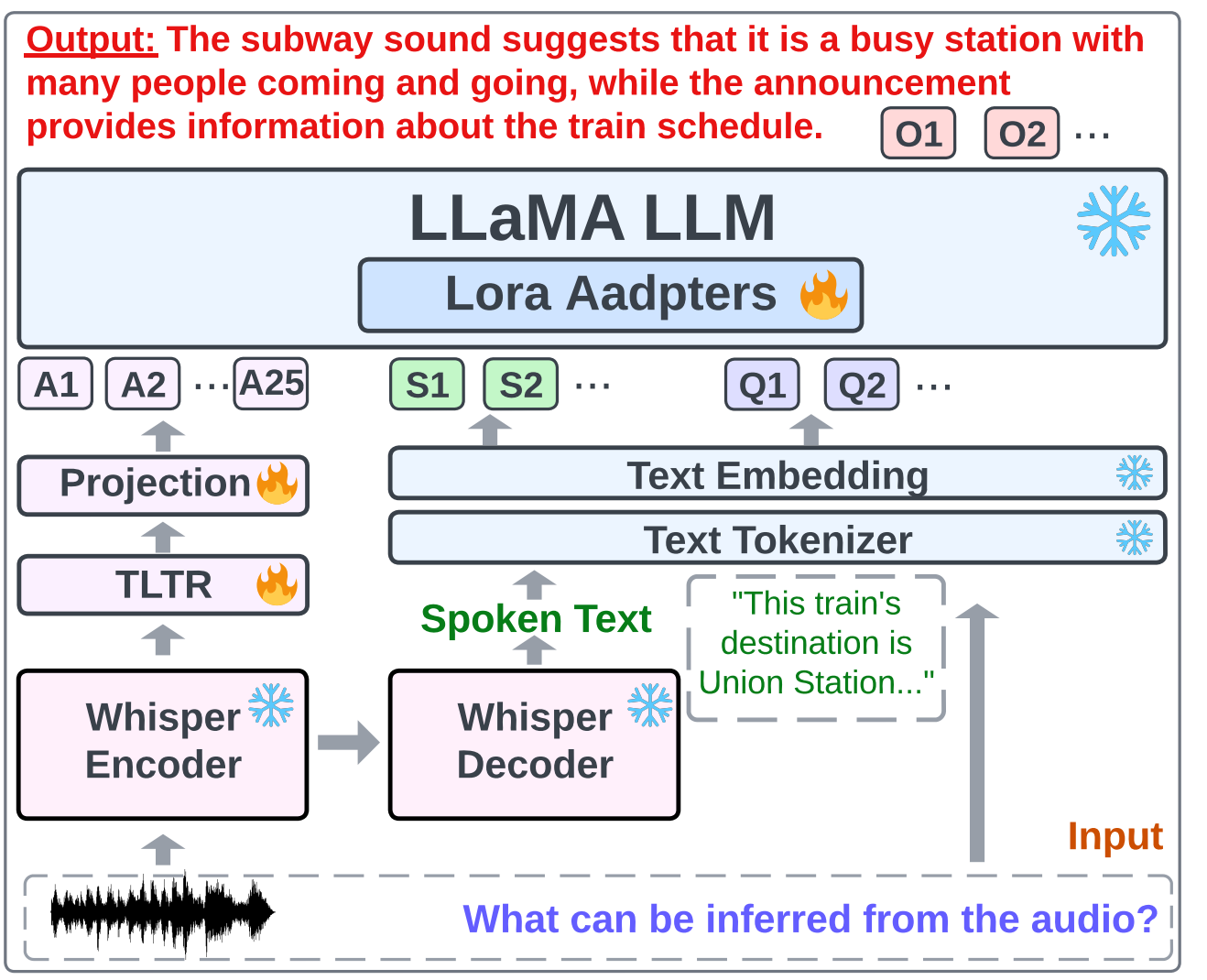
LTU-AS模型架构如上图,对比一下LTU可以发现就是将原来的AST换成"whisper+TLTR",在《Whisper-AT:一个统一语音识别和音频标签的模型》这篇文章中,已经比较详细的讲解了"whisper+TLTR"模块,这里不做赘述。所以,可以简单的将LTU-AS理解为Whisper-AT和LTU融合,技术上没有太多可讲的。
数据准备
论文构建了一个9.6M的训练集:OpenAQA-5M、2.7M语音问答集(speechrelated AQAs)、1.2M音频语音问答集(joint audio and speech AQAs)。
与LTU一样,作者并没有新录制音频数据,而是重新标注了13个开源数据集,下边详细讲解数据集构建过程。
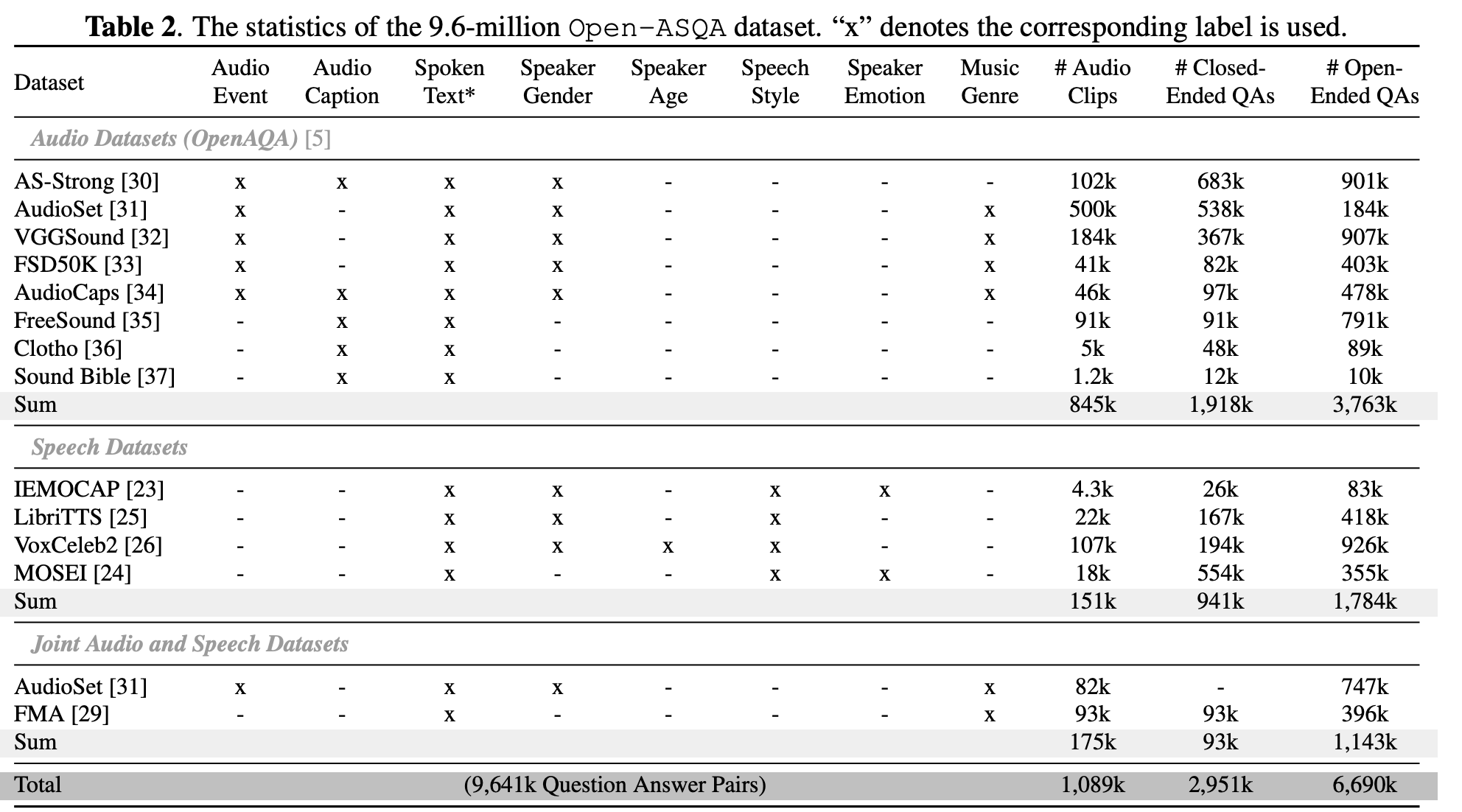
封闭式音频问答数据集构建(closed-ended AQA)
- Open-Ended Audio AQA:这部分的构建在《LTU:一种能听、能想、能理解的大模型架构》已经详细描述,这里不再赘述
- Closed-Ended Speech AQA:941K的封闭式语音问答数据集是基于4个常用的语音数据集(IEMOCAP/LibriTTS/VoxCeleb2/MOSEI)构建,元信息的构成主要包括以下几个部分:
-
- 数据集原始标注:不同数据集包含的元信息不一致,如IEMOCAP标注了性别,但MOSEI就没有标注性别,上表中"x"就表示原数据集提供的标注信息
- 标注说话人风格:提取音高、语速、音量等信息,由此生成说话人风格问答集
- 对音频内容进行识别:对其中150K数据进行识别,构成形如(音频,Q,A)这样的识别问题集
- Closed-Ended Joint Audio and Speech AQA:该数据集基于音乐分析数据集FMA构建,首先用Whisper识别出歌词,把歌词以及数据集原来的标签(如风格、标题)一同输入GPT生成问答,大小为93K
开放式音频问答数据集构建(open-ended AQA)
论文仍基于一种名为AIG的数据生成方法。简单描述就是:提取音频的元信息(音频事件、说话内容、说话风格等),输入GPT-3.5-Turbo,让GPT根据特定的prompt生成答案。
- Open-Ended Audio AQA:这部分的构建在《LTU:一种能听、能想、能理解的大模型架构》已经详细描述,这里不再赘述
- Open-Ended Speech AQA:仍基于4个常用的语音数据集(IEMOCAP/LibriTTS/VoxCeleb2/MOSEI)构建,原信息输入GPT生成答案,这里需要特别指出:
-
- 不同数据集包含的元信息不一致:如IEMOCAP标注了性别,但MOSEI就没有标注性别,上表中"x"就表示原数据集提供的标注信息
- 根据音高、语速、音量等参数的值从低到高划分为5个等级: 主要是方便GPT理解值的含义,如语速3.0对应的高语速
- Open-Ended Joint Audio and Speech AQA:基于数据集AudioSet和FMA构建
-
- AudioSet:从AudioSet-2M挑选50万条构成一个子集,然后用下边3个条件(①音频标签分布均匀;②非语音音频占比要小于20%; ③每个音频识别结果长度要超过5个单词)进行过滤,筛选出82K的子集,在用GPT生成问答集

-
- FMA:首先用Whisper识别出歌词,把歌词以及数据集原来的标签(如风格、标题)一同输入GPT生成问答集,如下图示例

训练
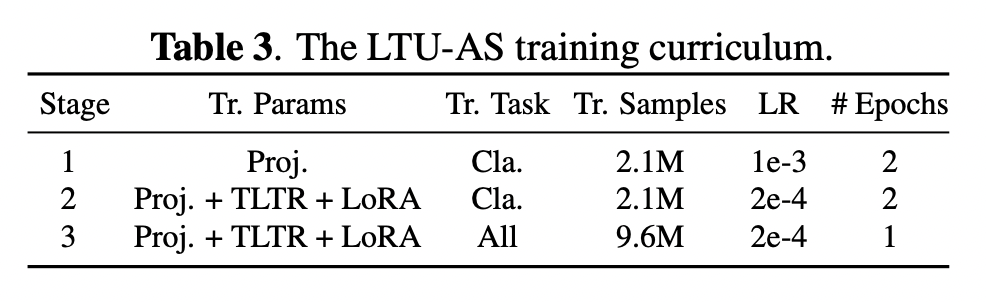
因为大语言模型直接采用的Vicuna,语音识别直接使用whisper,所以只需要训练三个相对比较小的部分:TLTR、投影层和LoRA。整个训练作者用4块RTX A6000 GPUs 耗时80个小时。和LTU训练方式相似,LTU-AS也是分阶段进行,如上表分共为3个阶段:
- 阶段1:投影层权重训练,先冻结TLTR和LoRA,用closed-ended AQA中涉及分类任务的数据(2.1M = 1.2M + 0.9M)进行训练
- 阶段2:所有权重训练,用closed-ended AQA中涉及分类任务的数据(2.1M = 1.2M + 0.9M)进行训练
- 阶段3:所有权重训练,用closed-ended AQA 和 open-ended AQA全部数据(9.6M)进行训练
开源
同样的LTU-AS也提供了完整的训练和测试样例。因为个人硬件条件受限,就没有复现,有条件的朋友可以试一下,代码及说明都还是比较清晰的。
代码仓库地址:https://github.com/YuanGongND/ltu
归纳总结
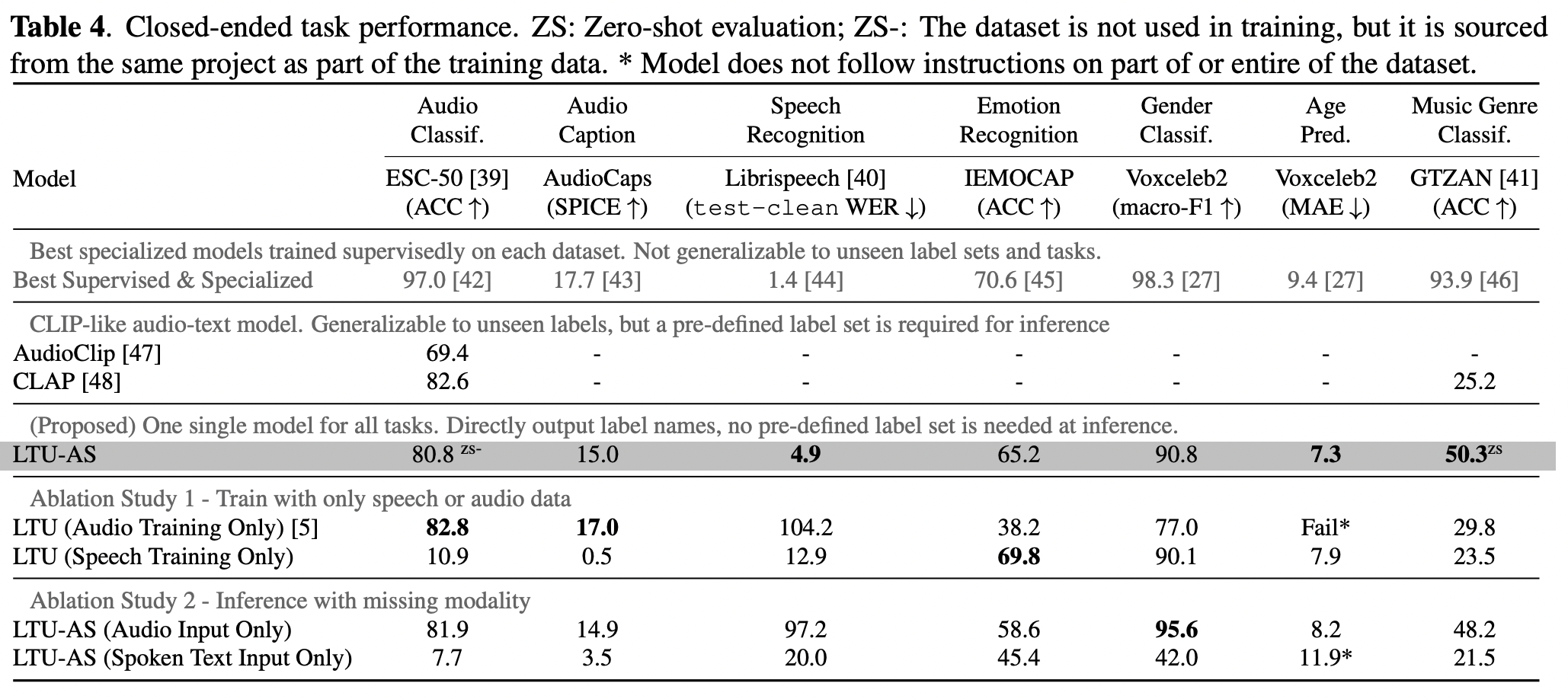
下表给出了在音频分类、音频字幕、语音识别、情感识别、性别分类、年龄预测、音乐风格分类这8个任务上 LTU-AS效果
- 从加黑部分结果来看,LTU-AS在各个场景效果都非常不错
- 在零样本音乐风格分类任务上的准确率几乎是CLAP的两倍
- 年龄预测任务:绝对误差(MAE)低于最先进(SOTA)专业模型
- 训练时,联合音频和语音两种数据,在大多数任务上都要比单独使用一种数据效果好
- 推理时,联合音频和文本两种模态,在大多数任务上都要比单独使用一种模态效果好
参考文献
- JOINT AUDIO AND SPEECH UNDERSTANDING:https://arxiv.org/pdf/2309.14405.pdf