视频生成技术Deepfake
-
- [0. 前言](#0. 前言)
- [1. 视频生成简介](#1. 视频生成简介)
- [2. DeepFake 概述](#2. DeepFake 概述)
- [3. 实现人脸图像处理](#3. 实现人脸图像处理)
-
- [3.1 从视频中提取图像](#3.1 从视频中提取图像)
- [3.2 检测和定位人脸](#3.2 检测和定位人脸)
- [3.3 检测面部关键点](#3.3 检测面部关键点)
- [3.4 人脸对齐](#3.4 人脸对齐)
- [3.5 人脸变形](#3.5 人脸变形)
- [4. 构建 DeepFake 模型](#4. 构建 DeepFake 模型)
-
- [4.1 构建编码器](#4.1 构建编码器)
- [4.2 构建解码器](#4.2 构建解码器)
- [4.3 训练自编码器](#4.3 训练自编码器)
- [5. 人脸交换](#5. 人脸交换)
- [6. 使用 GAN 改善 DeepFake](#6. 使用 GAN 改善 DeepFake)
0. 前言
我们已经了解并建立了多种用于图像生成的模型,包括 StyleGAN、Self-Attention GAN (SAGAN)和扩散模型等,在本节中我们将继续学习视频生成(合成)。本质上,视频只是一系列图像。因此,最基本的视频生成方法是单独生成图像,并按顺序将它们放在一起以制作视频。在本节中,我们将概述视频生成。然后,我们将实现视频生成技术 Deepfake。我们将使用此功能将视频中的人脸与其他人的脸部交换。
1. 视频生成简介
视频可以看作是依次播放一系列图像。图像数据具有三个维度,即 (H, W, C);视频数据具有四个维度 (T, H, W, C),其中 T 是时间维度。视频只是一大批图像,图像之间必须在时间上保持一致。
假设我们从一些视频数据集中提取图像,然后训练无条件生成对抗网络 (Generative Adversarial Network, GAN) 从随机噪声输入生成图像。可以想象,图像看起来彼此非常不同,由这些图像制成的视频同样无法观看。像图像生成一样,视频生成(合成)也可以分为无条件生成和条件生成两类。
在无条件视频合成中,模型不仅需要生成高质量的内容,而且还必须控制时间内容或运动。因此,对于一些简单的视频内容,输出视频通常很短。
另一方面,条件视频合成以输入内容为条件进行生成,因此会产生质量更好的结果。在某些应用中,缺乏随机性可能是一个缺点,但是生成的图像的一致性是视频合成的优势。因此,许多视频合成模型都以图像或视频为条件。
人脸视频合成的最常见形式是面部重演和面部交换。在面部重现时,我们希望将目标视频中的面部表情转移到源图像的面部以在中间生成图像。数字人已经用于计算机动画和电影制作中,其中演员的面部表情用于控制数字化人物。使用AI进行面部重现有可能使这种事情更容易实现。面部交换则保留目标视频的面部表情,但要使用源图像中的面部。
尽管在技术上有所不同,但是面部重演和面部交换是相似的。就生成的视频而言,两者都可用于创建虚假视频。顾名思义,面部交换只交换人脸,因此,目标人脸和源人脸都应具有相似的形状,以提高虚假视频的保真度。可以将其用作视觉提示,以区分面部交换和面部重演视频。从技术上来说,面部重演更具挑战性,并且并不止用于视频,它可以使用面部关键点或草图代替。接下来,我们将重点介绍如何使用 DeepFake 算法实现人脸交换。
2. DeepFake 概述
人们已经使用 deepfake 算法创建了各种视频,包括一些用于电视广告和电影的视频。但是,由于这些虚假视频太过逼真,因此也引发了一些道德问题,研究人员也一直在研究检测这些伪造视频的方法。
Deepfake 算法可以大致分为两部分:
- 用于执行人脸交换的深度学习模型。我们首先收集两个人(例如
A和B)的数据集,并使用自编码器分别训练它们以学习其潜编码,如下图所示。有一个共享的编码器,但是我们为不同的人使用单独的解码器。图中的顶部图显示了训练体系结构。
首先,将人脸A(源)编码为一个小的潜编码。潜编码包含面部表情,例如头部姿势(角度),面部表情,眼睛睁开或闭合等。然后,使用解码器B将潜编码转换为FaceB。其目的是使用Face A的姿势和表情生成Face B:
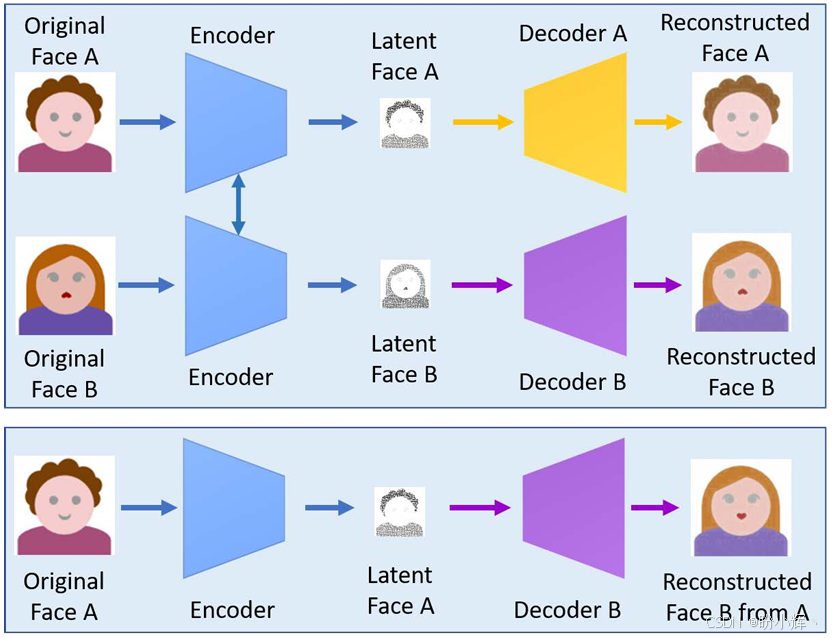
在正常的图像生成设置中,我们需要做的就是将输入图像发送到模型以产生输出图像。但是,有关Deepfake的生成步骤更加复杂一些。 - 我们需要一系列传统的计算机视觉技术来执行预处理和后处理,包括:
- 人脸检测
- 人脸关键点检测
- 人脸对齐
- 人脸变形
- 人脸掩码检测
下图显示了 Deepfake 流程:
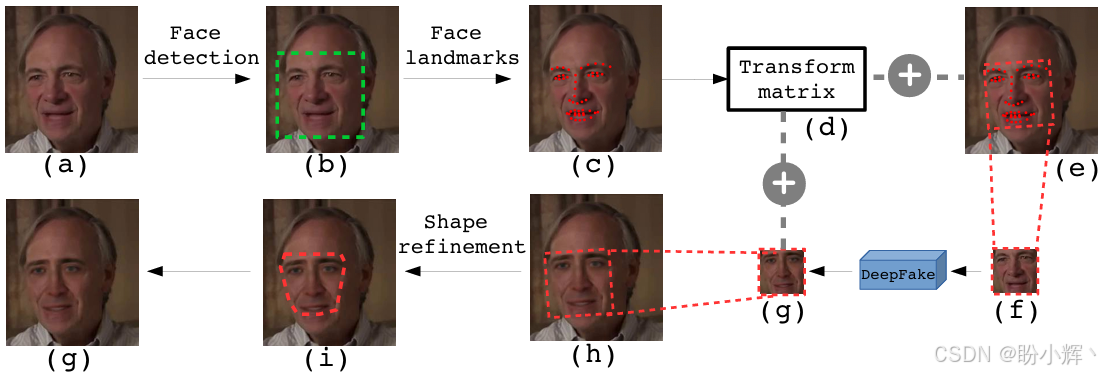
这些步骤可以分为三个阶段:
- 步骤
(a)至(f)是预处理步骤,用于从图像中提取并对齐源面部 - 进行面部交换以生成目标面部
(g) - 步骤
(h)至(j)是将目标面部粘贴到图像中的后处理步骤
接下来,我们将一步一步地执行面部处理步骤。然后,实现自编码器,并最终进行整合以生成 Deepfake 视频。
3. 实现人脸图像处理
我们将主要使用两个 Python 库 dlib 和 OpenCV 来实现大多数人脸处理任务。OpenCV 适用于通用计算机视觉任务,并且包含底层函数和算法。dlib 最初是用于机器学习的 C++ 工具包,但它也具有 Python 接口,它是用于人脸关键点检测的机器学习 Python 库。
3.1 从视频中提取图像
制作流程中的第一件事是从视频中提取图像。视频由一系列固定时间间隔的图像组成。如果检查视频文件的属性,则可能会发现帧率 (frames per second, FPS)。FPS 表示视频中每秒的图像帧数,25 fps 是标准视频帧率。这意味着在 1 秒钟的时间内播放 25 张图像,或者每张图像播放 1/25 = 0.04 秒。有很多软件包和工具可以将视频分割成图像,例如 ffmpeg,使用以下命令将 .mp4 视频文件拆分,并使用数字序列进行命名:
shell
$ ffmpeg -i video.mp4 /images/image_%04d.png或者,我们也可以使用 OpenCV 逐帧读取视频并将帧保存到图像文件中:
python
import cv2
cap = cv2.VideoCapture('driving.mp4')
count = 0
while cap.isOpened():
ret, frame = cap.read()
cv2.imwrite('images/images_%04d.png' % count, frame)
count += 1我们将使用提取的图像进行所有后续处理,而不再使用源视频。
3.2 检测和定位人脸
传统的计算机视觉技术使用定向梯度直方图 (Histogram of Oriented Gradient, HOG) 来检测人脸。图像的梯度可以通过获取水平和垂直方向上的前后像素之差来计算。梯度的大小和方向告诉我们有关脸部的线条和角落的信息。然后,我们可以将 HOG 用作特征描述符来检测人脸的形状。现代方法多使用卷积神经网络 (Convolutional Neural Network, CNN),该方法更准确但速度较慢。
face_recognition 是建立在 dlib 之上的库。默认情况下,它使用 dlib 的 HOG 作为面部检测器,但是它也可以选择使用 CNN:
python
import face_recognition
coords = face_recognition.face_locations(image, model='cnn')[0]这将返回图像中检测到的每个面部的坐标列表。在我们的代码中,我们假设图像中只有一张脸。返回的坐标为 css 格式 (top, right, bottom, left),因此我们需要执行额外的步骤将其转换为 dlib 面部关键点检测器的 dlib.rectangle 对象:
python
import dlib
def _css_to_rect(css):
return dlib.rectangle(css[3], css[0], css[1], css[2])
face_coords = _css_to_rect(coords)我们可以从 dlib.rectangle 中读取边界框坐标,并从图像中裁剪出面部:
python
def crop_face(image, coords, pad=0):
x_min = coords.left() - pad
x_max = coords.right() + pad
y_min = coords.top() - pad
y_max = coords.bottom() + pad
return image[y_min:y_max, x_min:x_max]如果在图像中检测到人脸,则可以继续进行下一步以检测人脸关键点。
3.3 检测面部关键点
面部关键点是人脸图像上特征点(也称为关键点)的位置。这些点围绕下巴,眉毛,鼻梁,鼻尖,眼睛和嘴唇的边缘。
dlib 使面部关键点检测变得十分容易。我们只需要在使用模型之前下载模型载并加载到 dlib 中:
python
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
face_shape = predictor(face_image, face_coords)需要注意的是:我们还将面部坐标传递到预测变量中,以传递面部位置。这意味着,在调用函数之前,我们不需要裁剪面部。
面部关键点是机器学习问题中非常有用的特征。例如,如果我们想知道一个人的面部表情,则可以将嘴唇关键点用作机器学习算法的输入特征,以检测嘴巴是否张开。这比查看图像中的每个像素更为有效。我们还可以使用面部特征来估计头部姿势。
在 DeepFake 中,我们使用面部关键点来进行面部对齐。在此之前,我们需要将关键点从 lib 格式转换为 NumPy 数组:
python
def shape_to_np(shape):
coords = []
for i in range(0, shape.num_parts):
coords.append((shape.parts(i).x, shape.parts(i).y))
return np.array(coords)
face_shape = shape_to_np(face_shape)3.4 人脸对齐
视频中的面孔会以各种姿势出现,例如向左看或张嘴。为了使自编码器更容易学习,我们需要将人脸对齐至裁剪图像的中心位置,使其保持直视摄像头的姿态,这称为面部对齐,可视为数据标准化的一种形式。Deepfake 的作者定义了一组面部关键点作为参考脸,并将其称为平均脸 (mean face)。该平均脸包含除下巴前 18 个点外的全部 68 个 dlib 关键点------这是因为人们的下巴形状差异巨大,若将其作为参考可能会影响对齐效果,故予以排除。
我们将需要对面部执行以下操作以使其与平均脸的位置和角度对齐:
- 旋转
- 缩放
- 平移
这些操作可以使用2×3仿射变换矩阵表示。仿射矩阵M由矩阵A和B组成:
M = A B = a 00 a 01 b 00 a 10 a 11 b 10 M=\left \\begin{matrix} A \& B \\end{matrix} \\right=\left \\begin{matrix} a_{00} \& a_{01} \& b_{00} \\\\ a_{10} \& a_{11} \& b_{10} \\end{matrix} \\right M=AB=a00a10a01a11b00b10
矩阵A包含用于线性变换(缩放和旋转)的参数,而矩阵B用于平移。deepfake使用S. Umeyama的算法来估计参数。我们通过传递检测到的面部关键点和平均脸标志来调用该函数。如前所述,我们省略了下巴关键点,因为它们不包含在平均脸中:
python
from utils.umeyama import umeyama
def get_align_mat(face_landmarks):
return umeyama(face_landmarks[17:], mean_landmarks, False)[0:2]
affine_matrix = get_align_mat(face_image)接下来,我们可以将仿射矩阵传递到 cv2.warpAffine() 中,以执行仿射变换:
python
def align_face(face_image, affine_matrix, size, padding=50):
affine_matrix = affine_matrix * (size[0] - 2 * padding)
affine_matrix[:, 2] += padding
aligned_face = cv2.warpAffine(face_image, affine_matrix, (size, size))
return aligned_face实际上,对齐输出的人脸进行了放大处理,仅保留眉毛到下巴之间的区域。添加了填充来略微缩小显示范围,以便在最终图像中包含边界框。接下来,我们将了解最后一个图像预处理步骤:人脸变形。
3.5 人脸变形
训练自编码器需要两张图像:输入图像和目标图像。在 Deepfake 中,目标图像是对齐后的人脸,而输入图像则是对齐人脸的变形版本。通过前一节实现的仿射变换后,图像中人脸的形状并未改变,但变形操作(例如扭曲人脸一侧)可以改变面部形状。Deepfake 通过扭曲人脸来模拟真实视频中多样的面部姿态,以此作为数据增强手段。
在图像处理中,变换是指将源图像中某个位置的像素映射到目标图像中的不同位置。例如平移和旋转属于一对一映射,它们改变位置和角度但保持尺寸和形状不变。而对于变形操作而言,映射可以是不规则的,同一个点可能被映射到多个点,从而产生扭曲和弯曲的效果。
我们将执行一些随机翘曲操作以稍微扭曲脸部,但幅度不会太大,以免造成严重扭曲。以下代码显示了如何执行面部变形,利用前文所述的映射原理将人脸扭曲至较小维度:
python
coverage = 2000
range_ = np.linspace(128-coverage//2, 128+coverage//2, 5)
mapx = np.broadcast_to(range_, (5, 5))
mapy = mapx.T
mapx = mapx + np.random.normal(size=(5, 5), scale=5)
mapy = mapy + np.random.normal(size=(5, 5), scale=5)
interp_mapx = cv2.resize(mapx, (80, 80))[8:72, 8:72].astype('float32')
interp_mapy = cv2.resize(mapy, (80, 80))[8:72, 8:72].astype('float32')
warped_image = cv2.remap(image, interp_mapx, interp_mapy, cv2.INTER_LINEAR)4. 构建 DeepFake 模型
原始的 Deepfake 中使用的深度学习模型是基于自编码器的模型。总共有两个自编码器,每个面部编码器一个。它们共享相同的编码器,因此模型中总共有一个编码器和两个解码器。自编码器期望输入和输出的图像大小均为 64×64。接下来,首先构建编码器。
4.1 构建编码器
编码器负责将高维图像转换为低维表示。首先,我们将编写一个函数来封装卷积层;LeakyReLU 激活用于下采样:
python
def downsample(filters):
return Sequential([
Conv2D(filters, kernel_size=5, strides=2, padding='same'),
LeakyReLU(0.1)
])在通常的自编码器实现中,编码器的输出是一维向量,大小约为 100 到 200,但 deepfake 使用的尺寸较大,为 1024。此外,它还可以对 1D 潜编码进行整形并将其按比例放大回 3D 激活状态。因此,编码器的输出不是大小为 1024 的一维向量,而是大小为 (8, 8, 512) 的张量:
python
def Encoder(z_dim=1024):
inputs = Input(shape=IMAGE_SHAPE)
x = inputs
x = downsample(128)(x)
x = downsample(256)(x)
x = downsample(512)(x)
x = downsample(1024)(x)
x = Flatten()(x)
x = Dense(z_dim)(x)
x = Dense(4 * 4 * 1024)(x)
x = Reshape((4, 4, 1024))(x)
x = UpSampling2D((2, 2))(x)
out = Conv2D(512, kernel_size=3, strides=1, padding='same')(x)
return Model(inputs=inputs, outputs=out, name='encoder')我们可以看到编码器可以分为三个阶段:
- 卷积层,将一幅
(64, 64, 3)图像一直缩小到(4, 4, 1024) - 两个全连接层。第一个产生大小为
1024的潜编码,然后第二个将其投影到更高的维度,然后将其重塑为(4, 4, 1024) - 上采样和卷积层使输出达到大小
(8, 8, 512)
4.2 构建解码器
解码器的输入来自编码器的输出,因此它期望张量的大小 (8, 8, 512)。我们使用几层上采样来逐步将激活放大到目标图像尺寸 (64, 64, 3),我们首先为上采样块编写一个函数,其中包含一个上采样函数,一个卷积层和 LeakyReLU:
python
def upsample(fliters, name=''):
return Sequential([
UpSampling2D((2, 2)),
Conv2D(filters, kernel_size=3, strides=1, padding='same')
LeakyReLU(0.1)
], name=name)然后,我们将上采样块堆叠在一起。最后一层是卷积层,将通道数设为 3 以匹配 RGB 颜色通道:
python
def Decoder(input_shape=(8, 8, 512)):
inputs = Input(shape=input_shape)
x = inputs
x = upsample(256, 'Upsample_1')(x)
x = upsample(128, 'Upsample_2')(x)
x = upsample(64, 'Upsample_3')(x)
out = Conv2D(filters=3, kernel_size=5, padding='same', activation='sigmoid')(x)
return Model(inputs=inputs, output=out, name='decoder')接下来,我们将编码器和解码器放在一起以构造自编码器。
4.3 训练自编码器
DeepFake 模型由两个共享同一编码器的自编码器组成。要构建自编码器,第一步是实例化编码器和解码器:
python
class deepfake:
def __init__(self, z_dim=1024):
self.encoder = Encoder(z_dim)
self.decoder_a = Decoder()
self.decoder_b = Decoder()然后,通过将编码器与相应的解码器连接起来,构建两个单独的自编码器:
python
x = Input(shape=IMAGE_SHAPE)
self.ae_a = Model(x, self.decoder_a(self.encoder(x)), name='Autoencoder_A')
self.ae_b = Model(x, self.decoder_b(self.encoder(x)), name='Autoencoder_B')
optimizer = Adam(5e-5, beta_1=0.5, beta_2=0.999)
self.ae_a.compile(optimizer=optimizer, loss='mae')
self.ae_b.compile(optimizer=optimizer, loss='mae')下一步是准备训练数据集。尽管自编码器的输入图像尺寸为 64×64,但是图像预处理管道期望的图像尺寸为 256×256。每个脸部区域我们需要约 300 张图像。
另外,也可以使用我们之前学习的图像处理技术,通过从收集的图像或视频中裁剪面部来自己创建数据集。数据集中的人脸不需要对齐,因为对齐将在图像预处理管道中执行。图像预处理生成器将返回两个图像,一张对齐后的人脸和一张变形版本,两者的分辨率均为 64×64。
现在,我们可以将这两个生成器传递给 train_step(),以训练自编码器模型:
python
def train_step(self, gen_a, gen_b):
warped_a, target_a = next(gen_a)
warped_b, target_b = next(gen_b)
loss_a = self.ae_a.train_on_batch(warped_a, target_a)
loss_b = self.ae_b.train_on_batch(warped_b, target_b)
return loss_a, loss_b编写和训练自编码器可能是 Deepfake 管道中最简单的部分。我们不需要大量数据;每个脸域大约需要 300 张图像就足够了。当然,更多的数据应该提供更好的结果。由于数据集和模型都不大,因此即使不使用 GPU,训练也可以相对快速地进行。一旦我们有了训练有素的模型,最后一步就是执行人脸交换。
5. 人脸交换
这是 Deepfake 管道的最后一步,但让我们首先回顾一下该管道。Deepfake 生成流程涉及三个主要阶段:
- 使用
dlib和OpenCV从图像中提取人脸 - 使用训练后的编码器和解码器转换人脸
- 使用新面孔替换原始图像
自编码器生成的新面孔是尺寸为 64×64 的对齐面孔,因此我们需要将其变形为原始图像中面孔的位置、大小和角度。在面部提取阶段,我们将使用从步骤 1 获得的仿射矩阵。我们使用 cv2.warpAffine,cv2.WARP_INVERSE_MAP 标志用于反转图像变换的方向:
python
h, w, _, image.shape
size = 64
new_image = np.zeros_like(image, dtype=np.uint8)
new_image = cv2.warpAffine(np.array(new_face, dtype=np.uint8),
mat*size, (w, h),
new_image,
flags=cv2.WARP_INVERSE_MAP,
borderMode=cv2.BORDER_TRANSPARENT)但是,将新面孔直接粘贴到原始图像上会在边缘周围产生伪像。如果新人脸的任何部分超出了原始人脸边界,这一点将尤其明显。为了减轻伪影,我们将使用面部掩码修剪新脸。
我们将创建的第一个掩码是在原始图像中的面部轮廓周围轮廓化的掩码。下面的代码将首先找到给定面部轮廓的轮廓,然后在轮廓内部填充 (1),然后将其返回为凸包 (hull) 掩码:
python
def get_hull_mask(image, landmarks):
hull = cv2.convexHull(face_shape)
hull_mask = np.zeros_like(image, dtype=float)
hull_mask = cv2.fillConvexPoly(hull_mask, hull, (1, 1, 1))
return hull_mask由于凸包掩码大于新的脸部正方形,因此我们将需要修剪凸包掩码以适合新的正方形。为此,我们可以利用新面部创建一个矩形掩码,然后将其与凸包掩码相乘。
然后,我们使用掩码从原始图像中删除面孔,并使用以下代码用新面孔进行填充:
python
def apply_face(image, new_image, mask):
base_image = np.copy(image).astype(np.float32)
foreground = cv2.multiply(mask, new_image)
background = cv2.multiply(1 - mask, base_image)
output_image = cv2.add(foreground, background)
return output_image所得的面孔可能仍然看起来并不完美。例如,如果两个脸部的肤色或阴影相差很大,那么我们可能需要使用更多更复杂的方法来消除伪影。
到此结束了面部交换。我们对从视频中提取的每个图像执行此操作,然后将图像转换回视频序列。一种方法是使用 ffmpeg,如下所示:
shell
$ ffmpeg -start_number 1 -i image_%04d.png -vcodec mpeg4 output.mp4本节中使用的 Deepfake 模型和计算机视觉技术是相当基本的,因为我想使其易于理解。因此,此代码可能不会产生逼真的伪造视频。接下来,我们将快速研究如何通过使用 GAN 来改善 Deepfake。
6. 使用 GAN 改善 DeepFake
Deepfake 的自编码器的输出图像可能有点模糊,那么我们如何改善呢?概括地说,deepfake 算法可以分为两种主要技术------人脸图像处理和人脸生成。后者可以看作是图像到图像的翻译问题。因此,自然要做的就是使用 GAN 来提高质量。其中一个模型是 faceswap-GAN,接下来我们将对其进行概述。原始 Deepfake 的自编码器通过残差块和自注意力块得到了增强,并用作 faceswap-GAN 中的生成器。判别器架构如下:
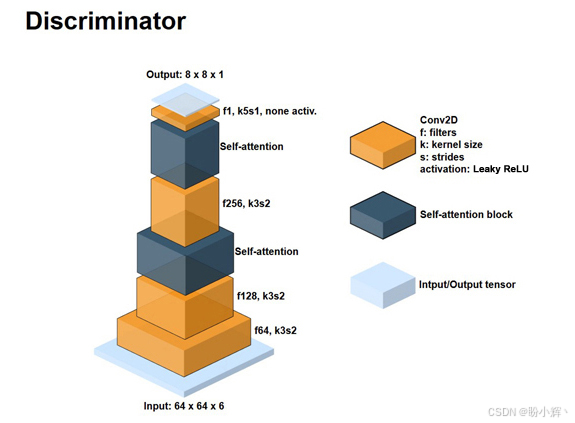
首先,输入张量的通道维数为 6,这表明它是两个图像的堆叠-真实图像和伪图像。然后有两个自注意力块。输出的形状为 8×8×1,因此每个输出特征都对应于输入图像的色块。换句话说,判别器是具有自注意层的 PatchGAN。
下图显示了编码器和解码器的体系结构:
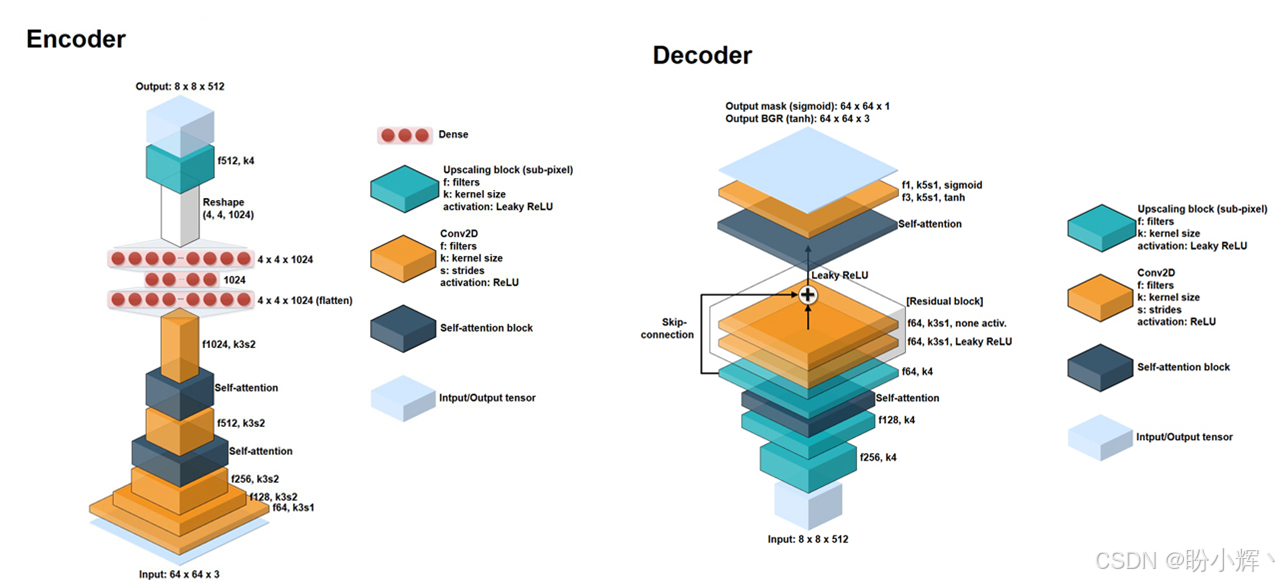
编码器和解码器没有太多更改。自注意力层被添加到编码器和解码器,并且在解码器添加一个残差块。训练中使用的损失包括:
- 最小二乘损失是对抗性损失
- 感知损失是
VGG在真实面部和虚假面部之间具有L2损失 L1重建损失- 边缘损失是指眼睛周围的梯度的
L2损失,这有助于模型生成逼真的眼睛