note
Qwen3-Omni-MoE代码实现可以理解为三层拼装:
- Processor 把"多模态对话消息"打包成张量(文本 token、图像/视频视觉特征、音频特征);
- Thinker(文本解码器, MoE) 做多模态→文本的自回归推理;
- Talker(Code2Wav) 把 Thinker 产出的离散语音码本进一步解码成 波形(可选)。
最终的统一入口是 Qwen3OmniMoeForConditionalGeneration.generate(),既能只出文本,也能同时出文本+音频;文本/音频两路的采样参数还可以分别设置(以 thinker_*/talker_* 参数前缀区分)。(Hugging Face1)
文章目录
- note
- 一、模型回顾
- 二、源码解读
-
- 1、一句话总览
- 2、目录里各文件是干嘛的
-
- 1) `processing_qwen3_omni_moe.py` :统一的多模态 Processor
processing_qwen3_omni_moe.py:统一的多模态 Processor) - 2) `modeling_qwen3_omni_moe.py` :核心模型拼装
modeling_qwen3_omni_moe.py:核心模型拼装) - 3) `configuration_qwen3_omni_moe.py`:配置
configuration_qwen3_omni_moe.py:配置)
- 1) `processing_qwen3_omni_moe.py` :统一的多模态 Processor
- 3、完整调用链
- 三、相关问题
- 四、整体的设计思想
- Reference
一、模型回顾
模型架构:
- 音频编码:模型的音频编码器采用基于 2000 万小时数据训练的 AuT 模型,为音视频理解提供了强大的通用表征基础。
- 推理加速:为实现毫秒级实时交互,Talker 采用了创新的多codebook自回归方案,在每一步解码中,MTP(Multi-Token Prediction)模块会预测当前音频帧的残差codebook。随后,Code2Wav 模块将这些codebook即时合成为波形,实现逐帧流式音频生成。
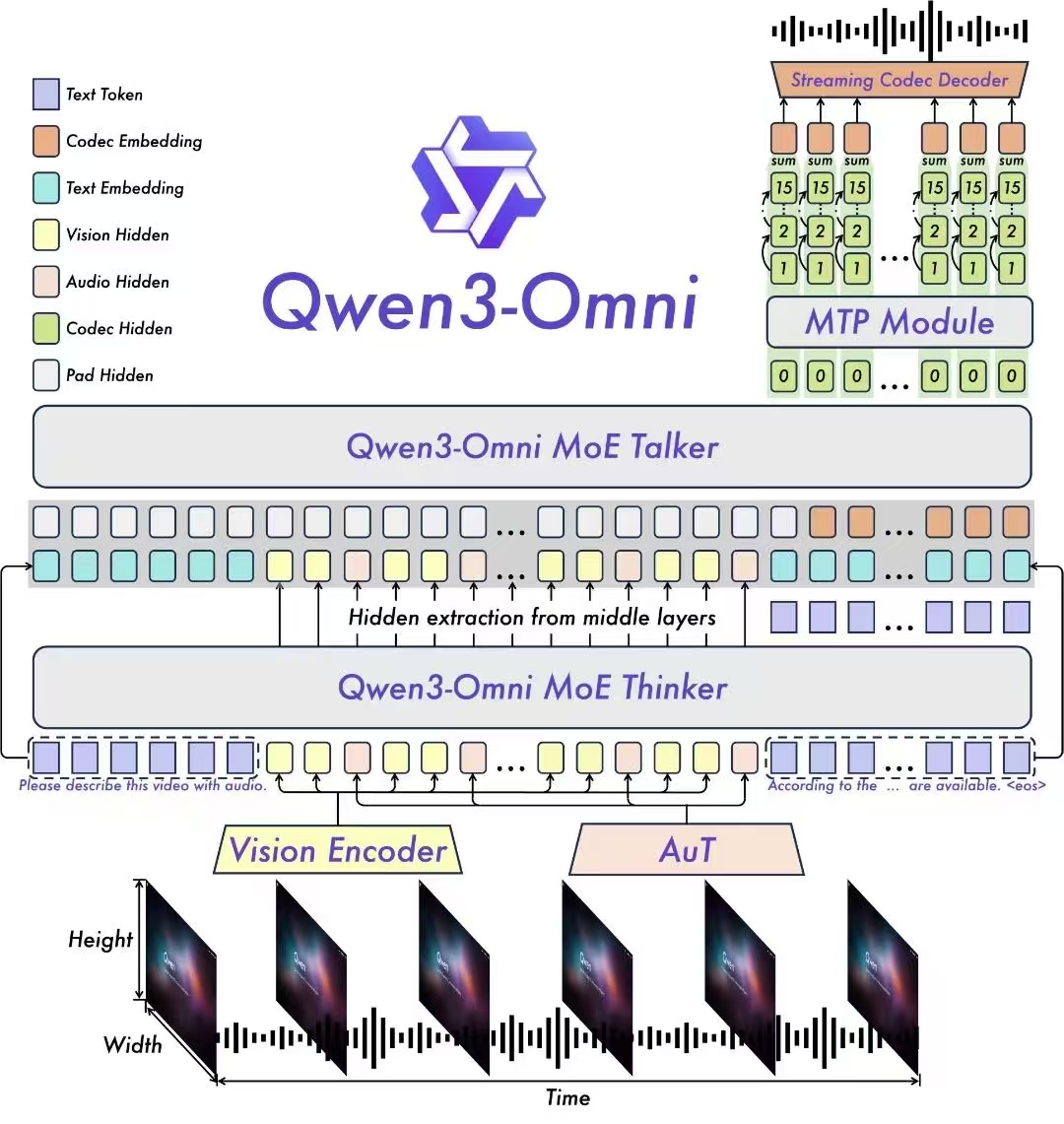
Qwen3-Omni 通过 Vision Encoder 和 AuT 音频编码器将图文音视频输入编码为隐藏状态,由 MoE Thinker 负责文本生成与语义理解,再由 MoE Talker 结合 MTP 模块,实现超低延迟的流式语音生成。
推理效果:得益于这一协同设计,Qwen3-Omni 纯模型端到端的音频对话延迟可低至 211ms,视频对话延迟可低至 507ms,交互体验如真人对话般自然流畅。
二、源码解读
代码部分:https://github.com/huggingface/transformers/tree/main/src/transformers/models/qwen3_omni_moe
1、一句话总览
Qwen3-Omni-MoE 在 HF 这套实现里可以把它理解为三层拼装:
- Processor 把"多模态对话消息"打包成张量(文本 token、图像/视频视觉特征、音频特征);
- Thinker(文本解码器, MoE) 做多模态→文本的自回归推理;
- Talker(Code2Wav) 把 Thinker 产出的离散语音码本进一步解码成 波形(可选)。
最终的统一入口是 Qwen3OmniMoeForConditionalGeneration.generate(),既能只出文本,也能同时出文本+音频;文本/音频两路的采样参数还可以分别设置(以 thinker_*/talker_* 参数前缀区分)。(Hugging Face1)
项目中不同类之间的使用关系:
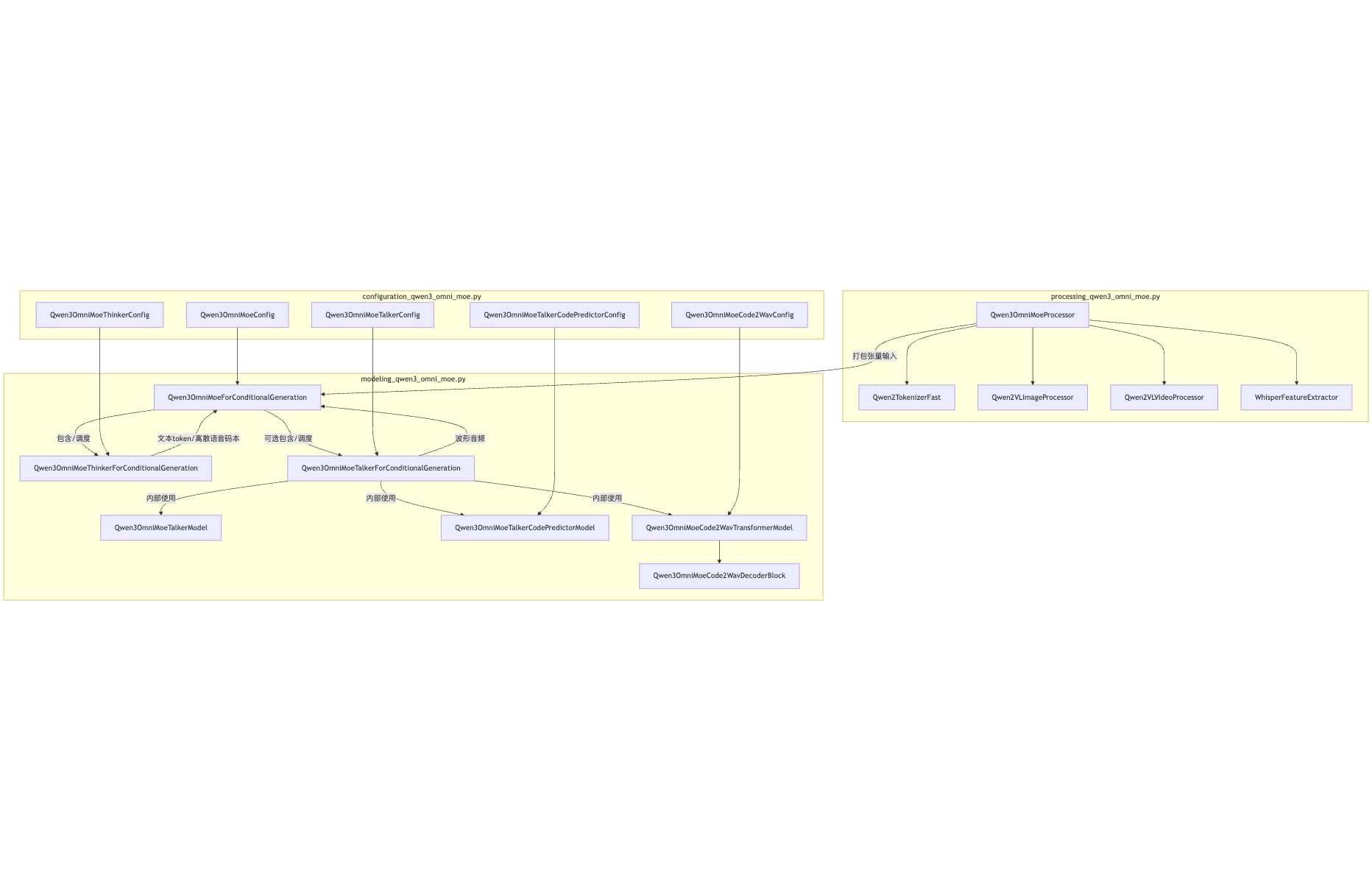
2、目录里各文件是干嘛的
1) processing_qwen3_omni_moe.py :统一的多模态 Processor
-
类 :
Qwen3OmniMoeProcessor -
职责:
- 组合了 文本 tokenizer (
Qwen2TokenizerFast)、图像/视频处理器 (Qwen2VLImageProcessor/Qwen2VLVideoProcessor)、音频特征器 (WhisperFeatureExtractor)为一个总入口; - 提供
apply_chat_template():直接把你给的"对话消息(含 text / image / video / audio)"转为模型需要的输入张量(含可选的视频抽帧、从视频里抽音频等)。
- 组合了 文本 tokenizer (
-
你要点 :Processor 内置 chat template,不必手写拼接;做视频时可以设
video_fps和use_audio_in_video;O O M 时可以把processor.max_pixels调小。(Hugging Face1)
文档里明确写了:
Qwen3OmniMoeProcessor同时封装了 Qwen2VLImageProcessor / Qwen2VLVideoProcessor / WhisperFeatureExtractor / Qwen2TokenizerFast ,并自带apply_chat_template()。(Hugging Face1)
2) modeling_qwen3_omni_moe.py :核心模型拼装
这个文件里会看到几类"可训练/推理"模块与头部:
-
Thinker 系列(文本)
Qwen3OmniMoeThinkerForConditionalGeneration:只生成文本侧(Thinker),做纯文本生成,适合你只想要文本、避免加载语音侧权重时用。(Hugging Face1)
-
Talker 系列(语音)
Qwen3OmniMoeTalkerForConditionalGeneration:只生成语音侧(Talker),用于把离散码本解到波形;通常配合 Thinker 的输出一起用。(Hugging Face1)
-
Code2Wav(语音解码器子网络)
Qwen3OmniMoeCode2Wav{TransformerModel, DecoderBlock}等:Talker 的具体实现,多码本(multi-codebook)自回归 + 轻量 causal ConvNet,把离散 codec 转最终音频波形;这是它低首包延迟的关键。(Hugging Face1)
-
整合模型
-
Qwen3OmniMoeForConditionalGeneration:最常用的统一入口。它会:- 接收 Processor 打包好的 batch;
- 先走 Thinker 做文本/离散语音码本的生成;
- 若启用音频输出(
enable_audio_output=True或在generate里传相关参数),再把码本喂给 Talker(Code2Wav)生成 波形; - 返回
(text_token_ids, audio_waveform)或者仅返回文本(取决于你的生成参数)。
-
注意 :目前 音频生成只支持单 batch(单样本)这一点在文档有明确说明。(Hugging Face1)
-
3) configuration_qwen3_omni_moe.py:配置
- 类 :
Qwen3OmniMoeConfig(以及 Talker/Code2Wav 的 config) - 职责 :把 Thinker(文本解码器的 MoE 架构超参)、视觉/音频侧桥接维度、Talker 的 codebook 数目与解码结构等都放在一个/多个 config 里,供
from_pretrained正确构建模型子模块。 - 对应逻辑 :这些配置在文档页的类签名、forward 注释里能对上(例如哪些张量字段会被读取、哪些返回项包含在
BaseModelOutputWithPast中)。(Hugging Face1)
3、完整调用链
以官方文档的多模态示例为准:
-
processor.apply_chat_template(conversations, ...)- 把你构造的对话(系统/用户消息;其中用户消息可以混合 text / image / video / audio)转成输入张量 ;可选从视频里抽音频、抽帧;这一步已经把多模态预处理完毕。(Hugging Face1)
-
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(..., device_map="auto", dtype="auto")- 会按 配置 装好 Thinker(文本 MoE)与 Talker(Code2Wav);
-
text_ids, audio = model.generate(**inputs, thinker_*, talker_*, use_audio_in_video=True)thinker_*参数只影响文本侧(温度、top-p 等),talker_*只影响语音侧(如声线spk、码本采样等);- 若你只要文本,可直接用
Qwen3OmniMoeThinkerForConditionalGeneration,节省显存/加载时间; - 若你要语音,记住目前只支持单 batch音频生成;
-
processor.batch_decode(text_ids, ...)得到最终文本;音频sf.write(..., audio, samplerate=24000)落盘即可。(Hugging Face1)
三、相关问题
-
文本/音频两路参数分家 :
在
generate()里,文本与音频的采样/解码参数需要前缀区分 :thinker_do_sample=...、talker_do_sample=...等;否则容易误以为一个参数能同时控制两路。(Hugging Face1) -
声线切换 :
Instruct 检查点目前内置
Chelsie(女声)与Ethan(男声),通过spk="Ethan"切换。(Hugging Face1) -
FlashAttention 2 :
官方建议装
flash-attn并使用torch.float16/bfloat16才会生效;这点能有效降低 Thinker 的生成时延。(Hugging Face1) -
视频/大图 OOM :
如果你把原始 4K/8K 视频直接丢进去,可能 OOM;可以把
processor.max_pixels调小,或降低video_fps。(Hugging Face1) -
只要文本更省资源 :
只做文本输出时,直接用
Qwen3OmniMoeThinkerForConditionalGeneration,不加载 Talker,能显著减少显存占用与权重加载时间。(Hugging Face1)
四、整体的设计思想
- Thinker--Talker 架构 :论文与文档都强调:Thinker 统一"感知+推理",Talker 负责"把离散语音码本转波形",多码本 + 轻量因果 ConvNet 让首包延迟 非常低(理论 E2E 首包 234ms)。你在代码里能看到对应的 Code2Wav 子模块与推理路径。(arXiv2)
- Processor 统一多模态 :不是"额外加个视觉/音频分支"的拼接范式,而是从输入端就统一在 Processor,输入消息列表里每条 content 都带 type (text / image / video / audio),
apply_chat_template()一把梭输出张量;这也解释了为什么 一个generate就能同时处理多模态。(Hugging Face1) - MoE / Qwen 家族的复用:视觉处理沿用 Qwen2VL 系列的处理器,音频特征沿用 Whisper 的特征器,文本 tokenizer 用 Qwen2 的 fast 版
Reference
1 https://huggingface.co/docs/transformers/main/en/model_doc/qwen3_omni_moe "Qwen3-Omni-MOE"
2 https://arxiv.org/html/2509.17765v1?utm_source=chatgpt.com "Qwen3-Omni Technical Report"
3 https://github.com/QwenLM/Qwen3-Omni "GitHub - QwenLM/Qwen3-Omni: Qwen3-omni is a natively end-to-end, omni-modal LLM developed by the Qwen team at Alibaba Cloud, capable of understanding text, audio, images, and video, as well as generating speech in real time."