DAY 43 复习日
作业 :
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
作业
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Subset
from torchvision import datasets, transforms, models
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import cv2
from PIL import Image
import os
python
# 1. 定义图像变换(训练集增强,验证集仅resize+归一化)
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # 统一尺寸为224×224(适配预训练模型)
transforms.RandomHorizontalFlip(), # 水平翻转增强
transforms.RandomRotation(10), # 随机旋转增强
transforms.ToTensor(), # 转为Tensor
transforms.Normalize( # ImageNet数据集的均值和标准差,用于归一化
[0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]
)
])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 2. 加载数据集(利用torchvision的ImageFolder自动按文件夹分类)
root_dir = "archive" # 数据集根目录(含glioma、meningioma等子文件夹)
full_dataset = datasets.ImageFolder(root=root_dir, transform=train_transform)
# 3. 划分训练集与验证集(按8:2比例,保证类别分布均匀)
train_indices, val_indices = train_test_split(
list(range(len(full_dataset))),
test_size=0.2,
random_state=42,
stratify=full_dataset.targets # 按类别分层抽样
)
train_data = Subset(full_dataset, train_indices)
val_data = Subset(full_dataset, val_indices)
# 4. 创建数据加载器(按batch加载,训练集打乱)
batch_size = 32
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_data, batch_size=batch_size, shuffle=False)
# 查看类别映射
class_names = full_dataset.classes
print("数据集类别:", class_names) # 输出:['glioma', 'meningioma', 'no_tumor', 'pituitary']数据集类别: 'glioma', 'meningioma', 'no_tumor', 'pituitary'
python
# 1. 加载预训练ResNet18,修改分类层
model = models.resnet18(pretrained=True) # 加载在ImageNet上预训练的ResNet18
# 冻结特征提取层(仅训练分类层,减少计算量)
for param in model.parameters():
param.requires_grad = False
# 修改最后一层全连接,适配4分类任务
num_ftrs = model.fc.in_features # 提取原全连接层输入维度
model.fc = nn.Linear(num_ftrs, len(class_names)) # 新全连接层(输出4个类别)
# 设备选择(GPU优先)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 2. 定义损失函数与优化器
criterion = nn.CrossEntropyLoss() # 多分类交叉熵损失
optimizer = optim.Adam(model.fc.parameters(), lr=0.001) # 仅优化新的全连接层
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1) # 学习率衰减
# 3. 模型训练
num_epochs = 20
train_losses, val_losses, train_accs, val_accs = [], [], [], []
for epoch in range(num_epochs):
# ---------- 训练阶段 ----------
model.train()
running_loss = 0.0
correct, total = 0, 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 梯度清零
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
_, predicted = outputs.max(1) # 取预测概率最大的类别
total += labels.size(0)
correct += predicted.eq(labels).sum().item() # 统计正确数
train_loss = running_loss / len(train_loader)
train_acc = 100. * correct / total
train_losses.append(train_loss)
train_accs.append(train_acc)
# ---------- 验证阶段 ----------
model.eval()
val_loss = 0.0
correct, total = 0, 0
with torch.no_grad(): # 验证时不计算梯度
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
val_loss = val_loss / len(val_loader)
val_acc = 100. * correct / total
val_losses.append(val_loss)
val_accs.append(val_acc)
scheduler.step() # 学习率衰减
print(f'Epoch {epoch+1}/{num_epochs} | '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}% | '
f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 保存训练好的模型
torch.save(model.state_dict(), "brain_tumor_cnn.pth")d:\Anaconda\envs\DL39\lib\site-packages\torchvision\models_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
d:\Anaconda\envs\DL39\lib\site-packages\torchvision\models_utils.py:223: UserWarning: Arguments other than a weight enum or None for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing weights=ResNet18_Weights.IMAGENET1K_V1. You can also use weights=ResNet18_Weights.DEFAULT to get the most up-to-date weights.
warnings.warn(msg)
Epoch 1/20 | Train Loss: 1.3136, Train Acc: 39.29% | Val Loss: 1.0863, Val Acc: 51.19%
Epoch 2/20 | Train Loss: 0.8945, Train Acc: 64.29% | Val Loss: 0.8440, Val Acc: 67.86%
Epoch 3/20 | Train Loss: 0.7204, Train Acc: 73.81% | Val Loss: 0.6816, Val Acc: 76.19%
Epoch 4/20 | Train Loss: 0.6108, Train Acc: 82.14% | Val Loss: 0.6059, Val Acc: 77.38%
Epoch 5/20 | Train Loss: 0.5456, Train Acc: 82.14% | Val Loss: 0.5572, Val Acc: 82.14%
Epoch 6/20 | Train Loss: 0.5227, Train Acc: 83.63% | Val Loss: 0.4884, Val Acc: 82.14%
Epoch 7/20 | Train Loss: 0.4761, Train Acc: 86.31% | Val Loss: 0.5070, Val Acc: 83.33%
Epoch 8/20 | Train Loss: 0.4262, Train Acc: 86.01% | Val Loss: 0.4602, Val Acc: 83.33%
Epoch 9/20 | Train Loss: 0.4613, Train Acc: 86.31% | Val Loss: 0.4730, Val Acc: 82.14%
Epoch 10/20 | Train Loss: 0.4128, Train Acc: 88.99% | Val Loss: 0.4731, Val Acc: 82.14%
Epoch 11/20 | Train Loss: 0.4203, Train Acc: 87.50% | Val Loss: 0.4654, Val Acc: 84.52%
Epoch 12/20 | Train Loss: 0.4601, Train Acc: 86.31% | Val Loss: 0.4829, Val Acc: 82.14%
Epoch 13/20 | Train Loss: 0.4203, Train Acc: 85.42% | Val Loss: 0.4696, Val Acc: 82.14%
Epoch 14/20 | Train Loss: 0.4465, Train Acc: 83.63% | Val Loss: 0.4708, Val Acc: 84.52%
Epoch 15/20 | Train Loss: 0.4139, Train Acc: 88.99% | Val Loss: 0.4651, Val Acc: 84.52%
Epoch 16/20 | Train Loss: 0.4149, Train Acc: 88.99% | Val Loss: 0.4327, Val Acc: 82.14%
Epoch 17/20 | Train Loss: 0.4221, Train Acc: 88.10% | Val Loss: 0.4601, Val Acc: 82.14%
Epoch 18/20 | Train Loss: 0.4231, Train Acc: 86.31% | Val Loss: 0.5142, Val Acc: 83.33%
Epoch 19/20 | Train Loss: 0.4303, Train Acc: 87.50% | Val Loss: 0.4667, Val Acc: 83.33%
Epoch 20/20 | Train Loss: 0.4144, Train Acc: 87.50% | Val Loss: 0.4814, Val Acc: 82.14%
python
class GradCAM:
def __init__(self, model, target_layer):
self.model = model
self.target_layer = target_layer
self.feature_maps = None
self.gradients = None
self.fwd_hook = None
self.bwd_hook = None
# 强化:彻底清除目标层所有钩子(兼容更多PyTorch版本)
self._force_remove_hooks()
# 改用旧版本的backward hook(避免与残留钩子冲突,接受警告)
self.fwd_hook = target_layer.register_forward_hook(self.save_feature_maps)
self.bwd_hook = target_layer.register_backward_hook(self.save_gradients) # 改回旧钩子
def _force_remove_hooks(self):
"""强制清除目标层所有前向/反向钩子(更彻底的方式)"""
# 清除前向钩子
if hasattr(self.target_layer, '_forward_hooks'):
# 迭代并移除所有前向钩子句柄
for hook_id in list(self.target_layer._forward_hooks.keys()):
self.target_layer._forward_hooks[hook_id].remove()
self.target_layer._forward_hooks.clear()
# 清除反向钩子
if hasattr(self.target_layer, '_backward_hooks'):
# 迭代并移除所有反向钩子句柄
for hook_id in list(self.target_layer._backward_hooks.keys()):
self.target_layer._backward_hooks[hook_id].remove()
self.target_layer._backward_hooks.clear()
# 重置PyTorch内部标记(关键)
self.target_layer._is_full_backward_hook = False # 无论之前是什么状态,强制重置
def save_feature_maps(self, module, input, output):
self.feature_maps = output.detach()
# 旧版本backward hook的参数格式(注意:grad_input是输入梯度,grad_output是输出梯度)
def save_gradients(self, module, grad_input, grad_output):
# 旧钩子中,grad_output是元组,取第一个元素为当前层的输出梯度
self.gradients = grad_output[0].detach()
def __call__(self, x, class_idx=None):
self.model.eval()
x.requires_grad_()
outputs = self.model(x)
if class_idx is None:
class_idx = outputs.argmax(dim=1)
self.model.zero_grad()
one_hot = torch.zeros_like(outputs)
one_hot.scatter_(1, class_idx.unsqueeze(1), 1)
outputs.backward(gradient=one_hot)
# 计算CAM(逻辑不变)
weights = torch.nn.functional.adaptive_avg_pool2d(self.gradients, (1, 1))
cam = (weights * self.feature_maps).sum(dim=1, keepdim=True)
cam = torch.nn.functional.relu(cam)
cam = torch.nn.functional.interpolate(
cam, size=(x.shape[2], x.shape[3]),
mode='bilinear', align_corners=False
)
cam = cam - cam.min()
cam = cam / (cam.max() + 1e-8)
return cam, outputs
def remove_hooks(self):
"""使用后主动移除钩子"""
if self.fwd_hook is not None:
self.fwd_hook.remove()
if self.bwd_hook is not None:
self.bwd_hook.remove()
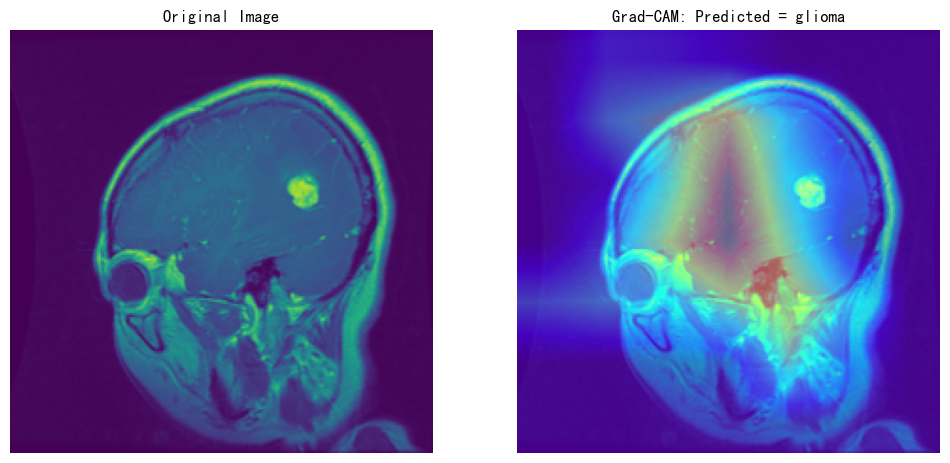
# ---------------------- 可视化代码 ----------------------
# 确保目标层正确(ResNet18的最后一个卷积层)
target_layer = model.layer4[-1].conv2
# 替换为你的图像路径(务必确保文件存在)
img_path = "archive/glioma/glioma20.png" # 检查路径是否正确,比如是否有拼写错误
img = Image.open(img_path).convert('RGB')
# 预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_tensor = transform(img).unsqueeze(0).to(device)
# 生成Grad-CAM(实例化前再次手动清除钩子,双重保险)
# 双重保险:实例化前手动清除一次
if hasattr(target_layer, '_backward_hooks'):
target_layer._backward_hooks.clear()
if hasattr(target_layer, '_forward_hooks'):
target_layer._forward_hooks.clear()
target_layer._is_full_backward_hook = False
grad_cam = GradCAM(model, target_layer)
cam, outputs = grad_cam(img_tensor)
grad_cam.remove_hooks() # 立即移除钩子
# 可视化
plt.figure(figsize=(12, 6))
# 处理原始图像
img_np = img_tensor.squeeze(0).detach().cpu().numpy()
img_np = img_np.transpose(1, 2, 0)
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
img_np = std * img_np + mean
img_np = np.clip(img_np, 0, 1)
# 处理热力图
cam_np = cam.squeeze(0).squeeze(0).cpu().numpy()
heatmap = cv2.applyColorMap(np.uint8(255 * cam_np), cv2.COLORMAP_JET)
heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB)
heatmap = np.float32(heatmap) / 255
# 叠加图像
superimposed = heatmap * 0.4 + img_np
superimposed = np.clip(superimposed, 0, 1)
# 显示
plt.subplot(1, 2, 1)
plt.imshow(img_np)
plt.title("Original Image")
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(superimposed)
pred_class = class_names[outputs.argmax(dim=1).item()]
plt.title(f"Grad-CAM: Predicted = {pred_class}")
plt.axis("off")
plt.show()