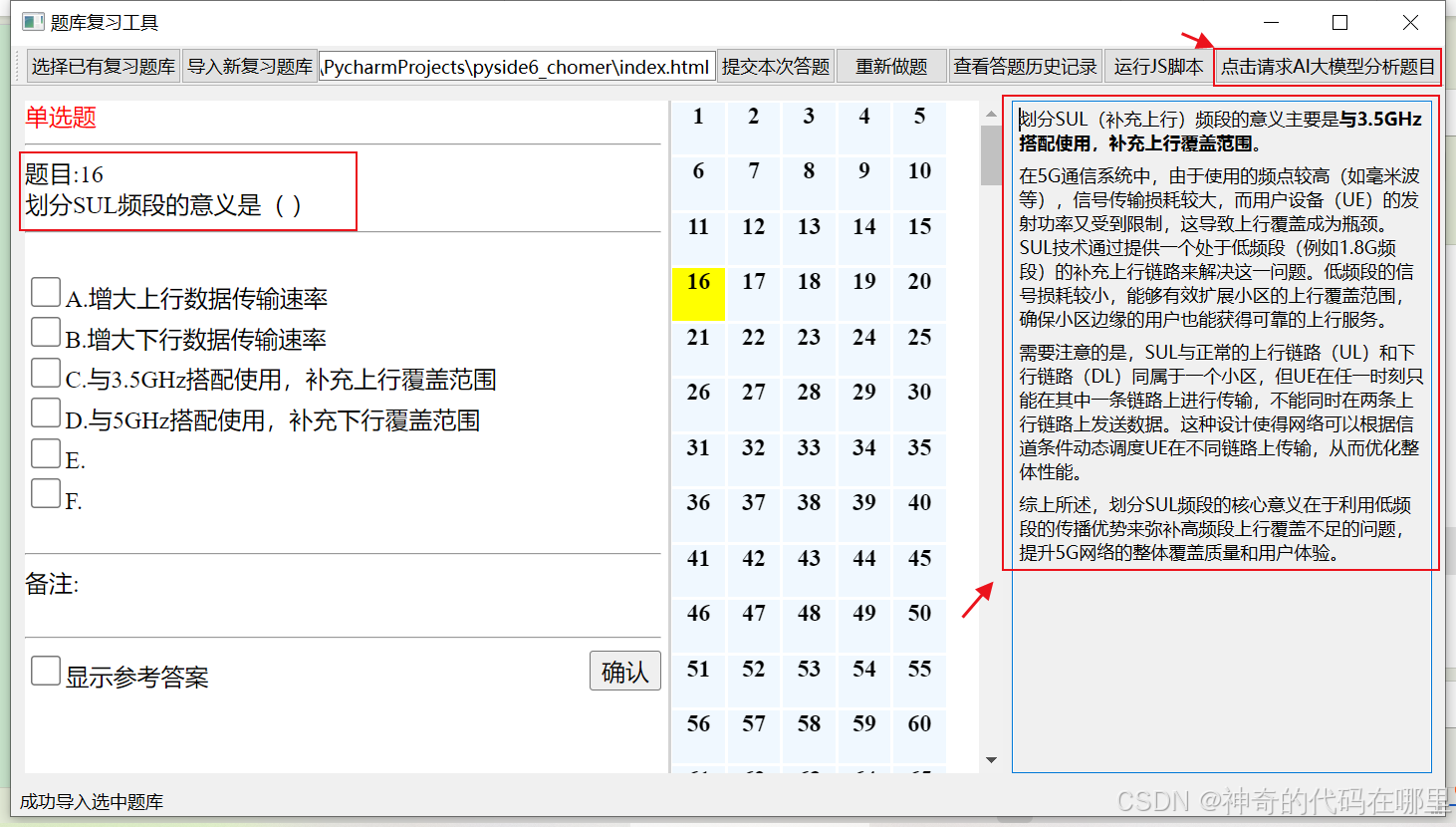
背景:之前博主使用PySide6开发了一个刷题复习软件实用刷题复习软件【单机版】 | 使用PySide6自制刷题软件【源码+解析】| 支持自定义excel题库。当前AI大模型火爆,可以借助AI在刷题复习软件中加入AI分析作答功能,提升刷题体验,更好的理解题目背后的逻辑和原理,同时也可以了解一下当前AI开放平台的开发过程。进行了一系列搜索后,决定还是使用免费、比较权威一点的AI大模型平台讯飞星火来完成这项研究工作。这里先放结果测试图,大模型分析的答案还是挺厉害的。
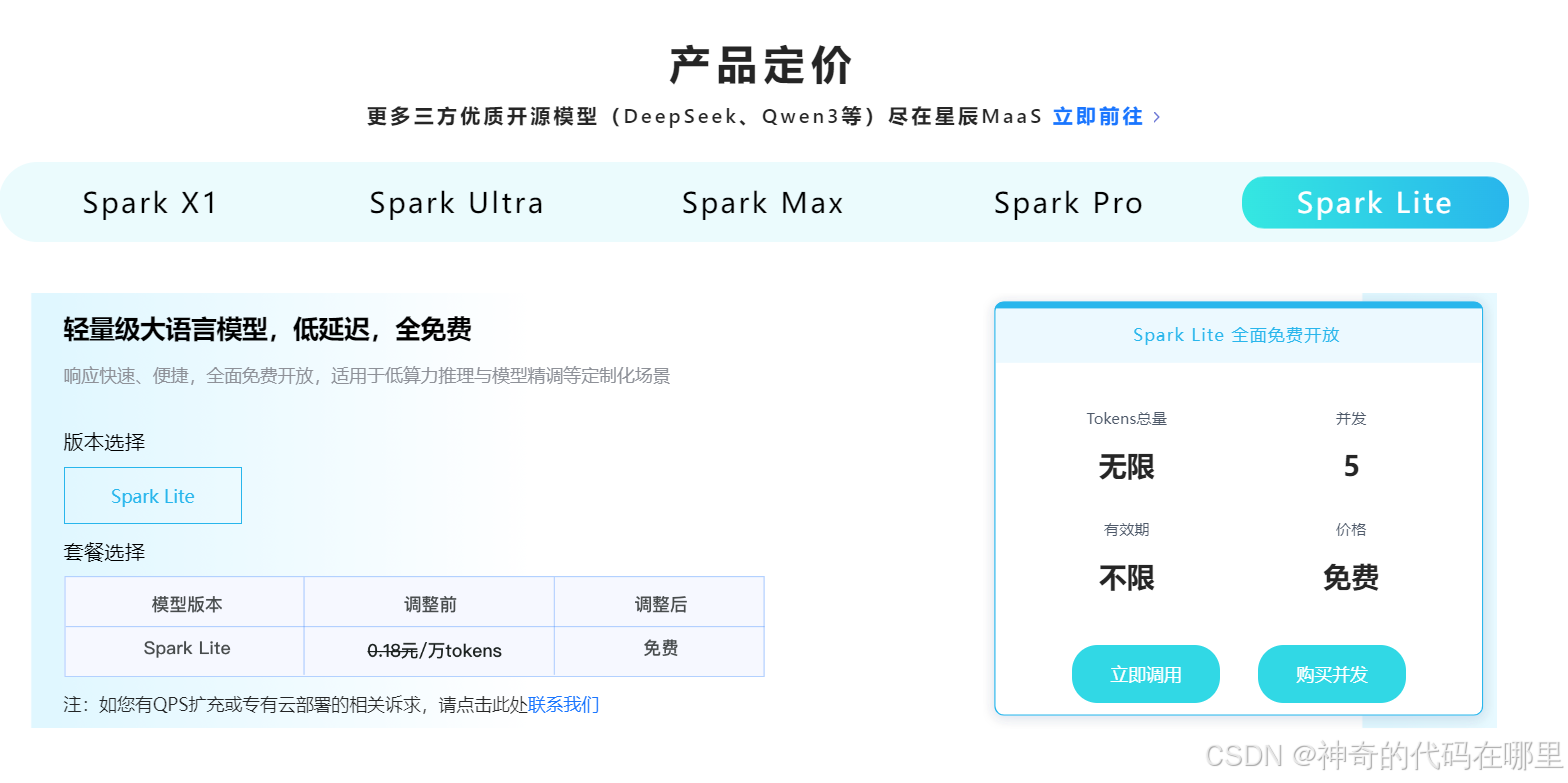
根据官网的描述,讯飞星火 Spark Lite是一个轻量级大语言模型,具备响应快速、便捷,全面免费开放等特点,适用于低算力推理与模型精调等定制化场景。以下是官网的产品截图:
接下来进入正文。
基于【讯飞星火 Spark Lite】轻量级大语言模型的【PySide6应用】开发与实践
- 一、查阅官方API开发文档
- [二、下载官方的Python 调用示例并进行调试](#二、下载官方的Python 调用示例并进行调试)
- [三、在PySide6中使用 【讯飞星火 Spark Lite】](#三、在PySide6中使用 【讯飞星火 Spark Lite】)
-
- 3.1创建QTextEdit组件
- 3.2创建工作线程,实现异步更新QTextEdit
- 3.3启动大模型请求线程
- [3.4 测试结果](#3.4 测试结果)
- 四、结语
一、查阅官方API开发文档
通过以下网址https://xinghuo.xfyun.cn/sparkapi,进入星火大模型API首页。

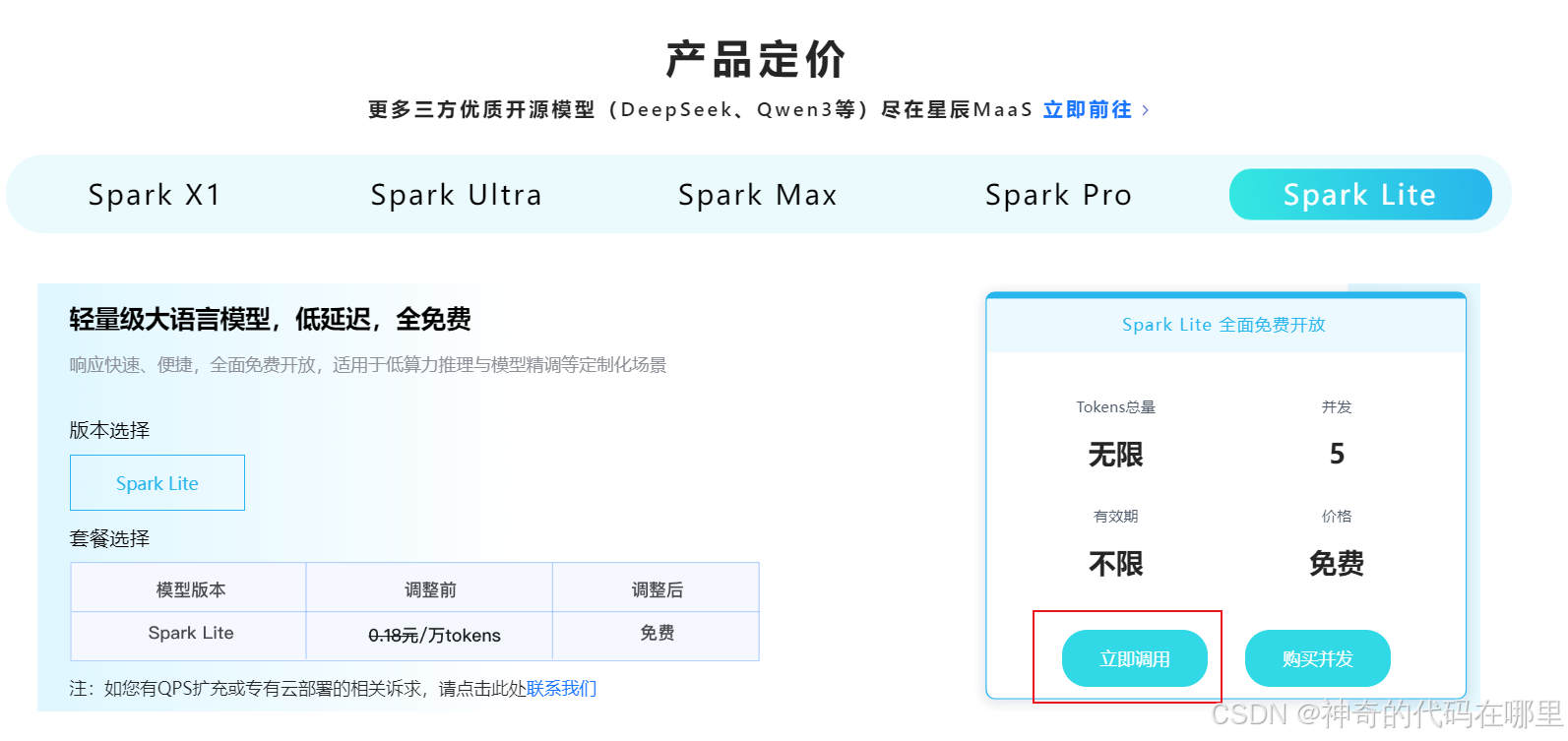
找到产品定价页面,点击立即调用。
然后需要进行注册授权之类的操作,最后进入讯飞开放平台控制台,如下图:
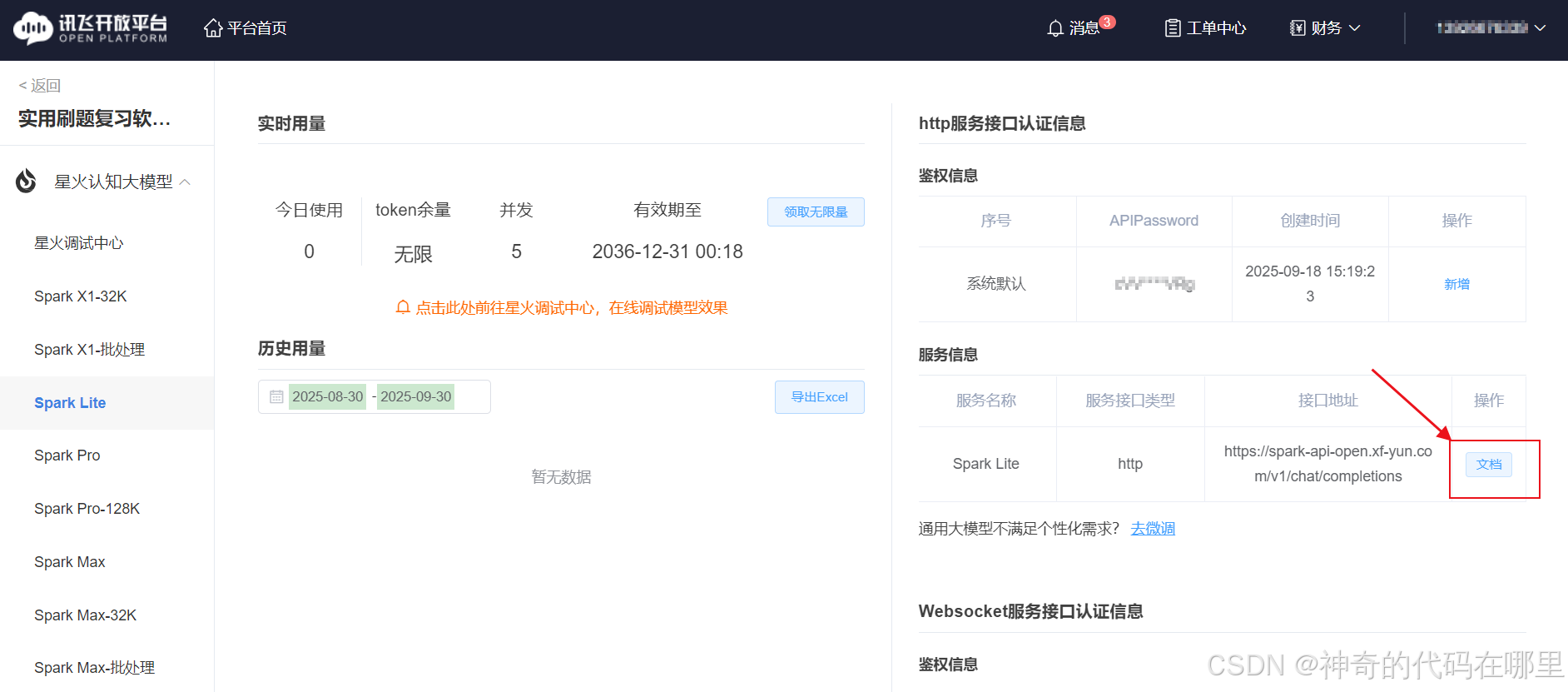
然后点击右下角的文档,进入【星火认知大模型Web API文档】使用教程页面。
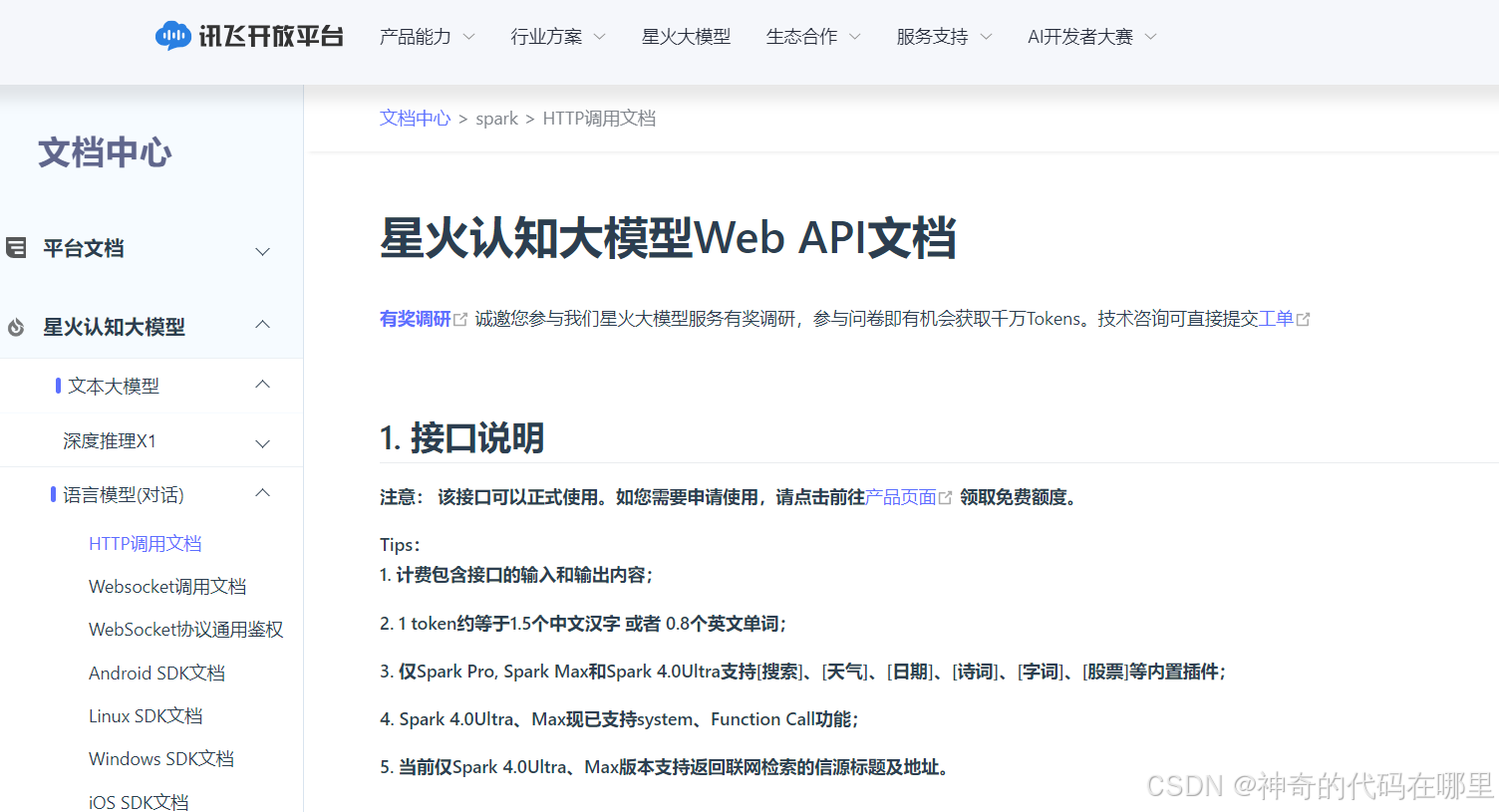
二、下载官方的Python 调用示例并进行调试
把API文档拉到第三部分【3.请求说明】,找到【Python调用示例】链接,并点击下载。
解压后,把【http_demo.py】文件用pycharm打开。如下图:
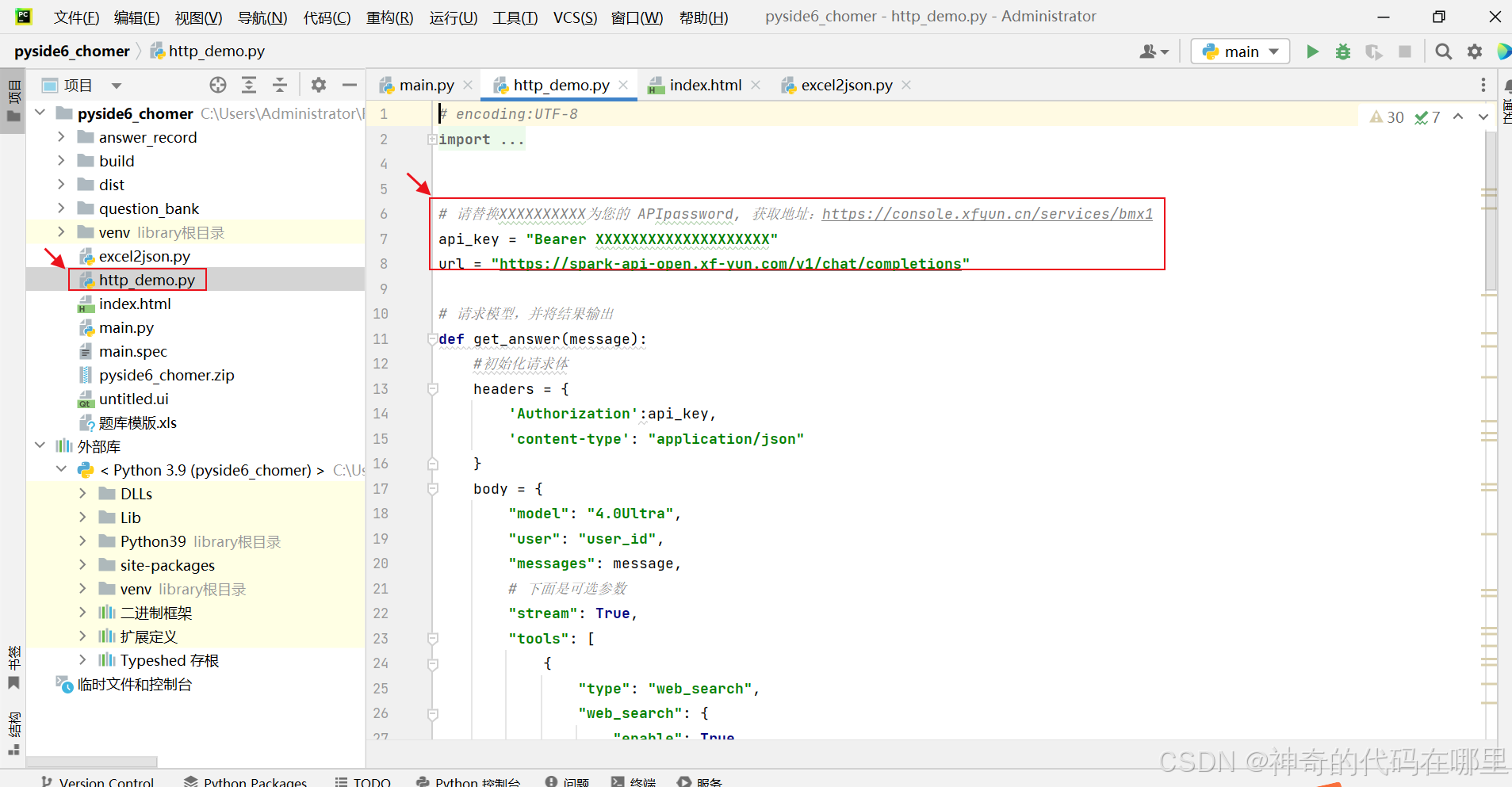
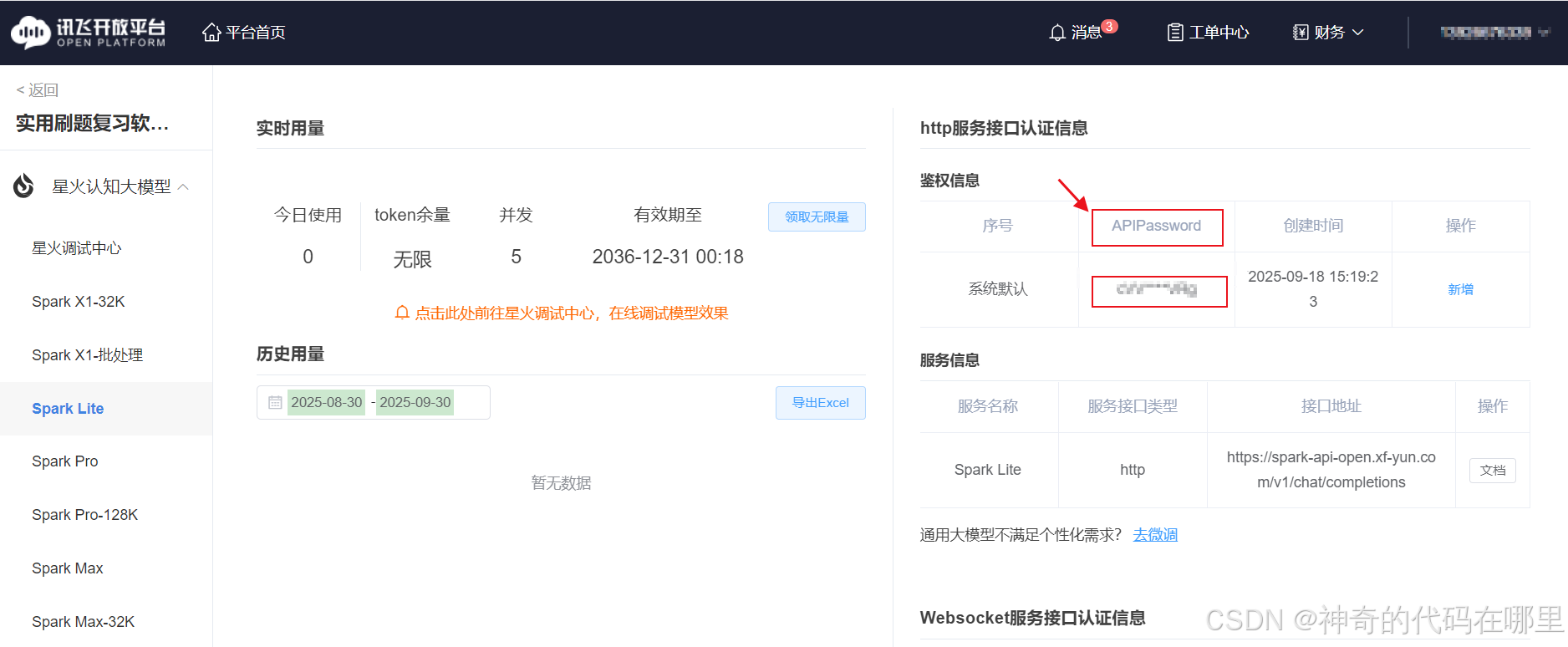
接着把代码中的【api_key】换成之前注册后获得的【api_key】,注册时获得的【api_key】在下图网页的右上侧。
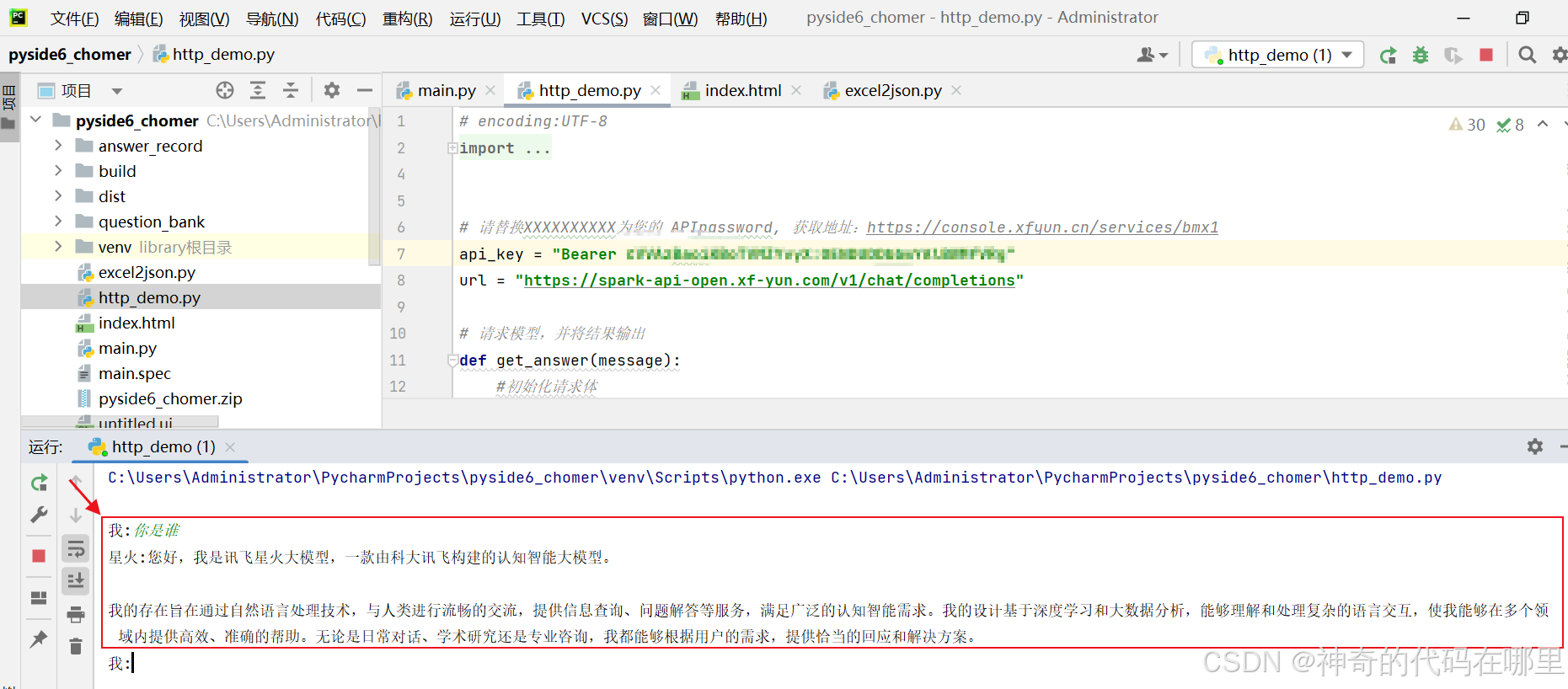
最后点击pycharm的运行按钮。可以尝试输入你是谁,如果出现答复,如下图,证明已经调试通过。
三、在PySide6中使用 【讯飞星火 Spark Lite】
为了显示大模型返回的文字,我们使用PySide6的QTextEdit组件进行开发。以下是核心示例代码:
3.1创建QTextEdit组件
python
from PySide6.QtWidgets import QTextEdit
class MainWindow(QMainWindow):
def __init__(self, ):
super().__init__()
self.ai_answer = QTextEdit()3.2创建工作线程,实现异步更新QTextEdit
其中AIAssistant类是刚才【讯飞星火 Spark Lite】示例代码的一个封装类,方便线程调用。
python
# 1. 创建工作线程,继承自 QThread
class WorkerThread(QThread):
def __init__(self, question_text): # 增加新参数 doors
super().__init__() # 调用父类的__init__方法初始化brand和model
self.question_text = question_text
# 自定义一个信号,用于传递要更新的文本 (str 类型)
update_signal = Signal(str)
def run(self):
ai_assistant = AIAssistant(self.update_signal)
question = ai_assistant.checklen(ai_assistant.getText(ai_assistant.chatHistory, "user",self.question_text))
ai_assistant.get_answer(question) AIAssistant类的实现如下:
python
class AIAssistant():
def __init__(self, update_signal):
super().__init__()
self.chatHistory = []
# 请替换XXXXXXXXXX为您的 APIpassword, 获取地址:https://console.xfyun.cn/services/bmx1
self.api_key = "Bearer xxxxxx"
self.url = "https://spark-api-open.xf-yun.com/v1/chat/completions"
self.update_signal = update_signal
# 请求模型,并将结果输出
def get_answer(self, message):
# 初始化请求体
headers = {
'Authorization': self.api_key,
'content-type': "application/json"
}
body = {
"model": "4.0Ultra",
"user": "user_id",
"messages": message,
# 下面是可选参数
"stream": True,
"tools": [
{
"type": "web_search",
"web_search": {
"enable": True,
"search_mode": "deep"
}
}
]
}
full_response = "" # 存储返回结果
isFirstContent = True # 首帧标识
response = requests.post(url=self.url, json=body, headers=headers, stream=True)
# print(response)
for chunks in response.iter_lines():
# 打印返回的每帧内容
# print(chunks)
if (chunks and '[DONE]' not in str(chunks)):
data_org = chunks[6:]
chunk = json.loads(data_org)
text = chunk['choices'][0]['delta']
# 判断最终结果状态并输出
if ('content' in text and '' != text['content']):
content = text["content"]
if (True == isFirstContent):
isFirstContent = False
#print(content, end="")
full_response += content
self.update_signal.emit(full_response)
return full_response
# 管理对话历史,按序编为列表
def getText(self, text, role, content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
# 获取对话中的所有角色的content长度
def getlength(self, text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
# 判断长度是否超长,当前限制8K tokens
def checklen(self, text):
while (self.getlength(text) > 11000):
del text[0]
return text核心代码是在for chunks in response.iter_lines():这句循环中加入更新PySide6信号的代码:self.update_signal.emit(full_response)。
3.3启动大模型请求线程
最后添加按钮,启动线程即可。示例代码如下:
python
self.ai_button.setText("点击请求AI大模型分析题目")
self.ai_button.clicked.connect(self.start_task)
self.toolBar.addWidget(self.ai_button)
def start_task(self):
self.ai_button.setEnabled(False) # 任务开始时禁用按钮,防止重复点击
self.thread = WorkerThread(result)
self.thread.update_signal.connect(self.update_text) # 连接信号到槽函数
self.thread.finished.connect(lambda: self.ai_button.setEnabled(True)) # 任务完成后启用按钮
self.thread.start() # 启动线程3.4 测试结果
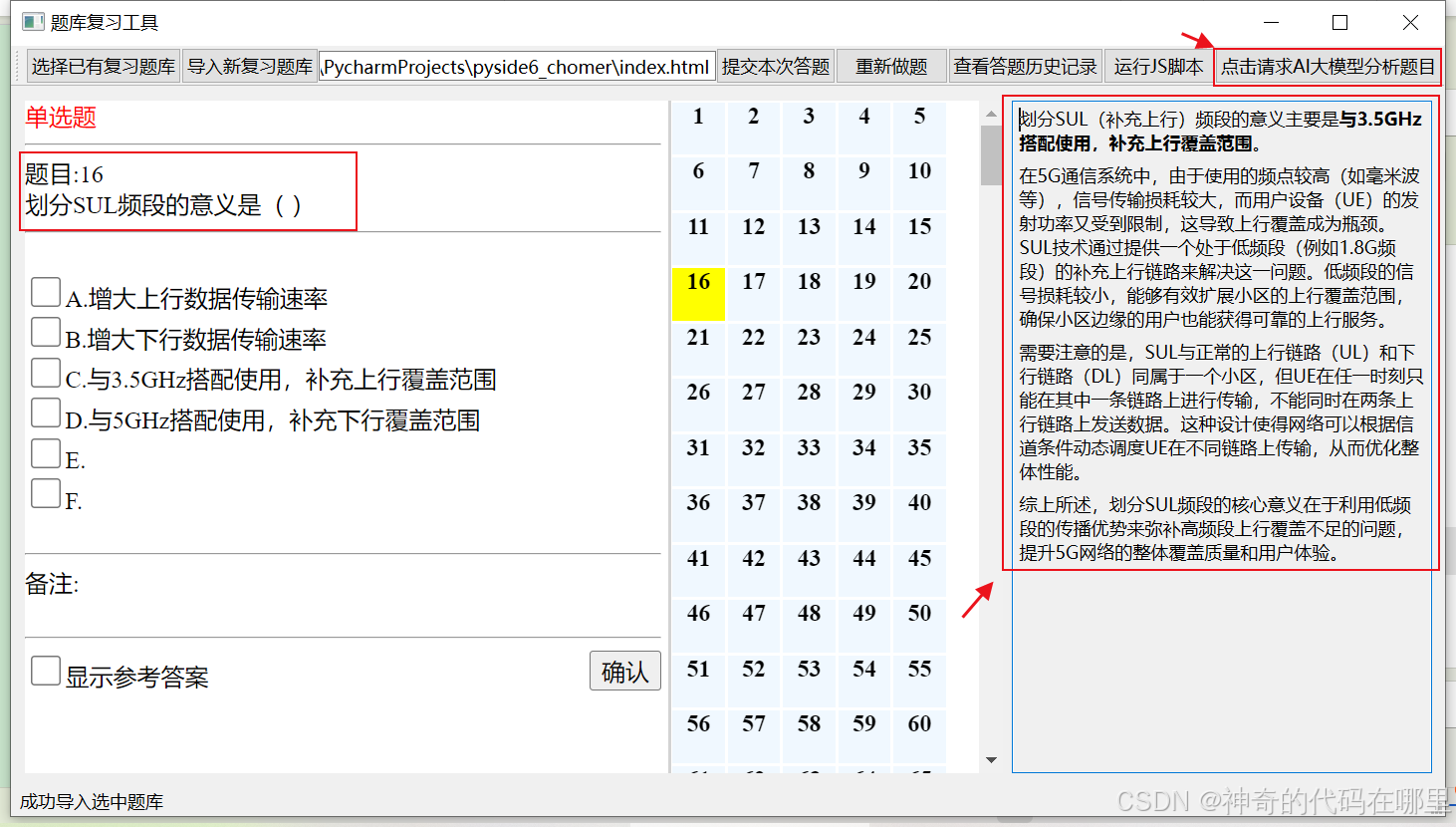
结合博主之前做的一个刷题工具,点击右上角的请求按钮,就会得到这道题目的AI大模型分析的结果,回答的还是挺准的,的确可以指导用户答题和复习。测试效果如下:
四、结语
当前大模型的发展非常迅速,接口使用的成本已经非常低,快速免费调用已经成为可能。随着大模型和传统应用的深度融合,估计很快就会成为开发应用的标配,大大提升用户使用的体验。