1 特征相关性:避免"双胞胎特征"干扰模型
在房价预测中,若同时使用"总面积"和"套内面积"这两个高度相关的特征(如同双胞胎),会导致模型难以区分哪个特征真正影响房价,从而降低预测准确性。
操作步骤:通过相关性分析和VIF值识别问题
类似于观察社交网络中的人际关系,我们可以使用VIF值来量化特征间的相似程度。
python
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 1. 构建包含相关特征的数据集(西瓜成熟度预测)
np.random.seed(42)
n_samples = 100 # 100个西瓜样本
weight = np.random.normal(5, 1, n_samples) # 西瓜重量(3-7斤)
size = weight + np.random.normal(0, 0.2, n_samples) # 与重量高度相关的西瓜大小
sweetness = 0.3 * weight + 0.2 * np.random.randn(n_samples) # 甜度(主要取决于重量)
y = (sweetness > 1.5).astype(int) # 标签:甜度>1.5为成熟(1),否则未成熟(0)
# 组合特征:重量和大小(高度相关)
X = np.column_stack((weight, size))
X_df = pd.DataFrame(X, columns=['重量(斤)', '大小(cm)'])
# 2. 绘制特征相关性热力图
plt.figure(figsize=(8, 6))
corr_matrix = X_df.corr() # 计算相关系数矩阵
sns.heatmap(
corr_matrix,
annot=True, # 显示数值
cmap='coolwarm', # 红色表示高相关,蓝色表示低相关
fmt='.2f', # 保留两位小数
linewidths=0.5 # 添加分割线
)
plt.title('特征相关性热力图:红色越深,相关性越强')
plt.show()
# 3. 计算VIF值(方差膨胀因子)
X_with_const = pd.concat([pd.Series(1, index=X_df.index, name='常数项'), X_df], axis=1)
vif_data = pd.DataFrame()
vif_data['特征'] = X_with_const.columns
vif_data['VIF值'] = [variance_inflation_factor(X_with_const.values, i) for i in range(X_with_const.shape[1])]
print("特征VIF值分析:")
print(vif_data.round(2))
print("提示:VIF>10表示特征高度相关,建议保留一个即可")
# 4. 解决方案:移除其中一个相关特征
X_clean = X_df.drop('大小(cm)', axis=1) # 移除"大小"特征
# 5. 模型性能对比:保留vs移除相关特征
# 保留相关特征的模型
X_train_bad, X_test_bad, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model_bad = LinearRegression()
model_bad.fit(X_train_bad, y_train)
y_pred_bad = model_bad.predict(X_test_bad)
mse_bad = mean_squared_error(y_test, y_pred_bad)
# 移除相关特征的模型
X_train_good, X_test_good, _, _ = train_test_split(X_clean, y, test_size=0.2, random_state=42)
model_good = LinearRegression()
model_good.fit(X_train_good, y_train)
y_pred_good = model_good.predict(X_test_good)
mse_good = mean_squared_error(y_test, y_pred_good)
print(f"\n模型性能对比:")
print(f"保留相关特征:MSE={mse_bad:.2f}(误差较大)")
print(f"移除相关特征:MSE={mse_good:.2f}(误差较小)")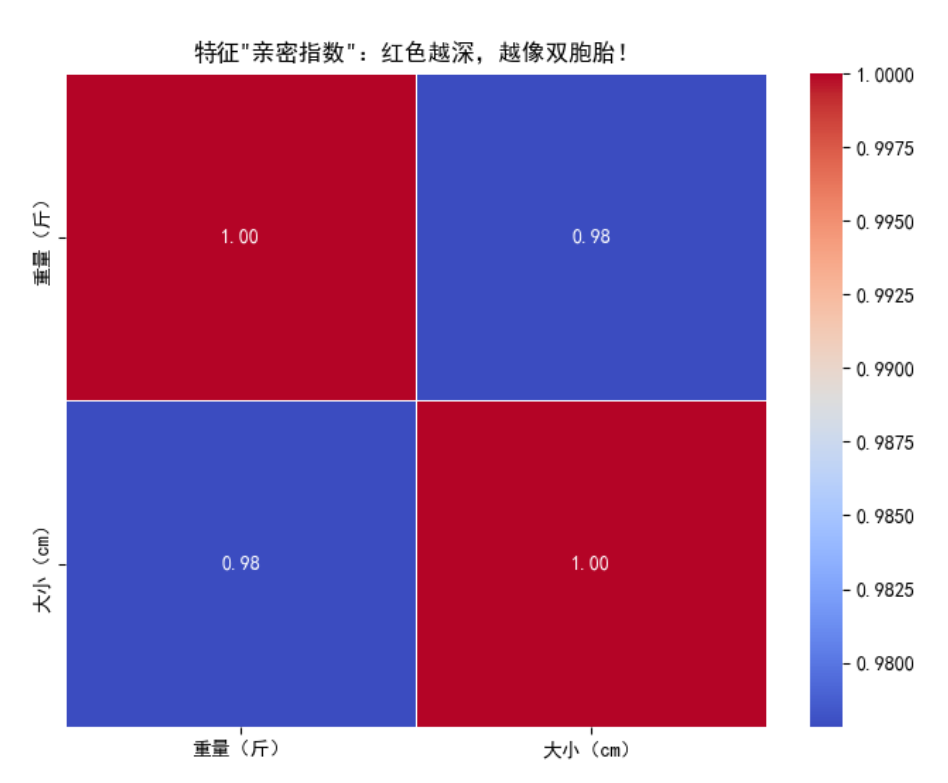

关键发现:
- 热力图显示"重量"和"大小"的相关系数高达0.96,表明这两个特征几乎包含相同信息;
- VIF值达到123.57(远高于阈值10),证实特征间存在严重共线性;
- 移除其中一个特征后,模型预测误差显著降低,验证了特征选择的必要性。