DNN技术详解:从感知机到深度学习的演进
摘要
深度神经网络(Deep Neural Networks, DNN)是人工智能领域的核心技术之一,通过多层非线性变换学习复杂的特征表示。本文深入解析DNN的基本原理、网络架构、训练算法以及从感知机到现代深度网络的发展历程,帮助读者全面理解这一重要技术。
关键词: 深度神经网络、DNN、多层感知机、反向传播、深度学习
文章目录
- DNN技术详解:从感知机到深度学习的演进
-
- 摘要
- [1. 引言](#1. 引言)
-
- [1.1 DNN的发展历程](#1.1 DNN的发展历程)
- [2. DNN的基本概念](#2. DNN的基本概念)
-
- [2.1 神经元模型](#2.1 神经元模型)
- [2.2 多层感知机(MLP)](#2.2 多层感知机(MLP))
- [3. 激活函数](#3. 激活函数)
-
- [3.1 常用激活函数](#3.1 常用激活函数)
- [3.2 激活函数的选择](#3.2 激活函数的选择)
- [4. 反向传播算法](#4. 反向传播算法)
-
- [4.1 手动实现反向传播](#4.1 手动实现反向传播)
- [4.2 使用PyTorch自动微分](#4.2 使用PyTorch自动微分)
- [5. 网络架构设计](#5. 网络架构设计)
-
- [5.1 深度vs宽度](#5.1 深度vs宽度)
- [5.2 残差连接](#5.2 残差连接)
- [6. 训练技巧](#6. 训练技巧)
-
- [6.1 权重初始化](#6.1 权重初始化)
- [6.2 正则化技术](#6.2 正则化技术)
-
- ①Dropout随机失活
- [② Batch Normalization批归一化](#② Batch Normalization批归一化)
- [③ Early Stopping](#③ Early Stopping)
- [④ 数据增强](#④ 数据增强)
- [6.3 学习率调度](#6.3 学习率调度)
-
- [① StepLR步长衰减](#① StepLR步长衰减)
- [② ExponentialLR指数衰减](#② ExponentialLR指数衰减)
- [③ CosineAnnealingLR余弦退火](#③ CosineAnnealingLR余弦退火)
- [④ ReduceLROnPlateau(自适应调度)](#④ ReduceLROnPlateau(自适应调度))
- [7. 优化算法](#7. 优化算法)
-
- [7.1 常用优化器](#7.1 常用优化器)
- [7.2 自适应学习率](#7.2 自适应学习率)
- [8. 应用案例](#8. 应用案例)
-
- [8.1 手写数字识别](#8.1 手写数字识别)
- [8.2 回归任务](#8.2 回归任务)
- [9. 相关论文与研究方向](#9. 相关论文与研究方向)
-
- [9.1 经典论文](#9.1 经典论文)
- [9.2 现代发展](#9.2 现代发展)
- [10. 未来发展趋势](#10. 未来发展趋势)
-
- [10.1 技术趋势](#10.1 技术趋势)
- [10.2 应用趋势](#10.2 应用趋势)
- 参考文献
1. 引言
深度神经网络是一种由多个隐藏层 组成的神经网络,能够学习输入数据的复杂非线性映射关系。自1950年代感知机的提出以来,DNN经历了从简单到复杂、从浅层到深层的发展历程,成为现代人工智能系统的核心。
1.1 DNN的发展历程
- 1950s: 感知机(Perceptron)的提出
- 1980s: 反向传播算法的发明
- 2000s: 深度学习的复兴
- 2010s至今: 深度网络的广泛应用
2. DNN的基本概念
2.1 神经元模型
神经元是神经网络的基本单元,模拟生物神经元的功能,结构如下
权重 + w₁ w₂ w₃ b x₁ x₂ x₃ Σ(w·x)+b φ(·)
激活函数 输出 y
代码实现神经元
py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Neuron:
def __init__(self, input_size):
self.weights = torch.randn(input_size, requires_grad=True)
self.bias = torch.randn(1, requires_grad=True)
self.activation = torch.sigmoid
def forward(self, inputs):
# 线性变换
linear_output = torch.dot(inputs, self.weights) + self.bias
# 激活函数
output = self.activation(linear_output)
return output
#单个神经元
neuron = Neuron(3)
inputs = torch.tensor([1.0, 2.0, 3.0])
output = neuron.forward(inputs)
print(f"输入: {inputs}")
print(f"输出: {output}")2.2 多层感知机(MLP)
多层感知机 ,也称为前馈神经网络 或全连接网络 ,是一种最基础、也是最经典的人工神经网络模型。
核心组成部分
-
输入层:接收原始数据。该层的神经元数量由输入数据的特征维度决定(例如,一张28x28的灰度图像会被展平为784个特征,输入层就有784个神经元)。
标准的MLP的层要求输入是一个一维的向量 ,而不是一个二维的矩阵。它无法直接处理二维结构,故二维矩阵在输入MLP之前需要先展平为一维,缺点是在展平的过程中,像素之间的二维空间关系 被完全破坏了,卷积神经网络 才成为了图像处理任务的主流选择
-
隐藏层 :位于输入层和输出层之间。一个MLP可以有一个或多个隐藏层,这些层是模型能够学习复杂模式的关键。隐藏层的层数和每层的神经元数量是重要的超参数。
-
输出层:产生最终的预测结果。其神经元数量和激活函数取决于任务类型:
- 二分类:1个神经元(Sigmoid激活函数)
- 多分类:N个神经元(N是类别数,使用Softmax激活函数)
- 回归:1个或多个神经元(通常使用线性激活函数)
每一层的所有神经元都与下一层的所有神经元相连接,因此也被称为全连接层。
python
class MLP(nn.Module):
def __init__(self, input_size, hidden_sizes, output_size, activation='relu'):
super().__init__()
self.layers = nn.ModuleList()
# 输入层到第一个隐藏层
self.layers.append(nn.Linear(input_size, hidden_sizes[0]))
# 隐藏层之间
for i in range(len(hidden_sizes) - 1):
self.layers.append(nn.Linear(hidden_sizes[i], hidden_sizes[i+1]))
# 最后一个隐藏层到输出层
self.layers.append(nn.Linear(hidden_sizes[-1], output_size))
# 激活函数
if activation == 'relu':
self.activation = nn.ReLU()
elif activation == 'sigmoid':
self.activation = nn.Sigmoid()
elif activation == 'tanh':
self.activation = nn.Tanh()
# Dropout层
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# 通过所有隐藏层
for i, layer in enumerate(self.layers[:-1]):
x = layer(x)
x = self.activation(x)
x = self.dropout(x)
# 输出层(不使用激活函数)
x = self.layers[-1](x)
return x
# 构建一个MLP
mlp = MLP(input_size=784, hidden_sizes=[256, 128, 64], output_size=10)
print(f"MLP结构: {mlp}")输出如下
MLP结构: MLP(
(layers): ModuleList(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=128, bias=True)
(2): Linear(in_features=128, out_features=64, bias=True)
(3): Linear(in_features=64, out_features=10, bias=True)
)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)3. 激活函数
激活函数是神经元中**"是否激活"的决策开关,决定了"加权和"之后信号要不要继续往下一层传、传多少。它把线性运算 y = w·x + b 映射到 非线性空间**,使神经网络具备逼近任意函数的能力。
3.1 常用激活函数
| 激活 | 公式 | 输出范围 | 单调/可导 | 零均值? | 饱和 | 计算量 | 典型用途 |
|---|---|---|---|---|---|---|---|
| ReLU | max(0,x) |
[0, ∞) | 单调,x=0处非处处可导 | 否 | 右侧不饱和,左侧"死亡" | 非常低 | 默认卷积/全连接隐层 |
| LeakyReLU | max(αx,x) (α≈0.01) |
(-∞, ∞) | 单调,可导(点处可定义) | 接近零 | 不饱和 | 非常低 | 当 ReLU 出现"dead neurons" |
| ELU | x (x>0); α(e^x-1) (x≤0) |
(-α, ∞) | 平滑,可导 | 较好 | 负侧不饱和 | 中等(exp) | 加速收敛,减少偏移(α≈1) |
| Sigmoid | σ(x)=1/(1+e^{-x}) |
(0,1) | 单调,可导 | 否 | 两侧饱和(大) | 高(exp) | 输出层二分类概率;传统网络(已少用) |
| Tanh | tanh(x) |
(-1,1) | 单调,可导 | 是(零中心) | 两侧饱和 | 高(exp) | RNN隐藏层、需零均值场景 |
| Swish | x * σ(βx) (β通常=1) |
(-∞, ∞)(近似) | 非单调,光滑 | 接近零 | 弱饱和 | 较高(sigmoid + mul) | 高级卷积/MLP(EfficientNet 中) |
| GELU | x * Φ(x)(Φ为标准正态CDF) |
(-∞, ∞) | 非单调,光滑 | 接近零 | 弱饱和 | 较高(erf/Φ 或 tanh 近似) | Transformer、BERT/ViT 等现代架构 |
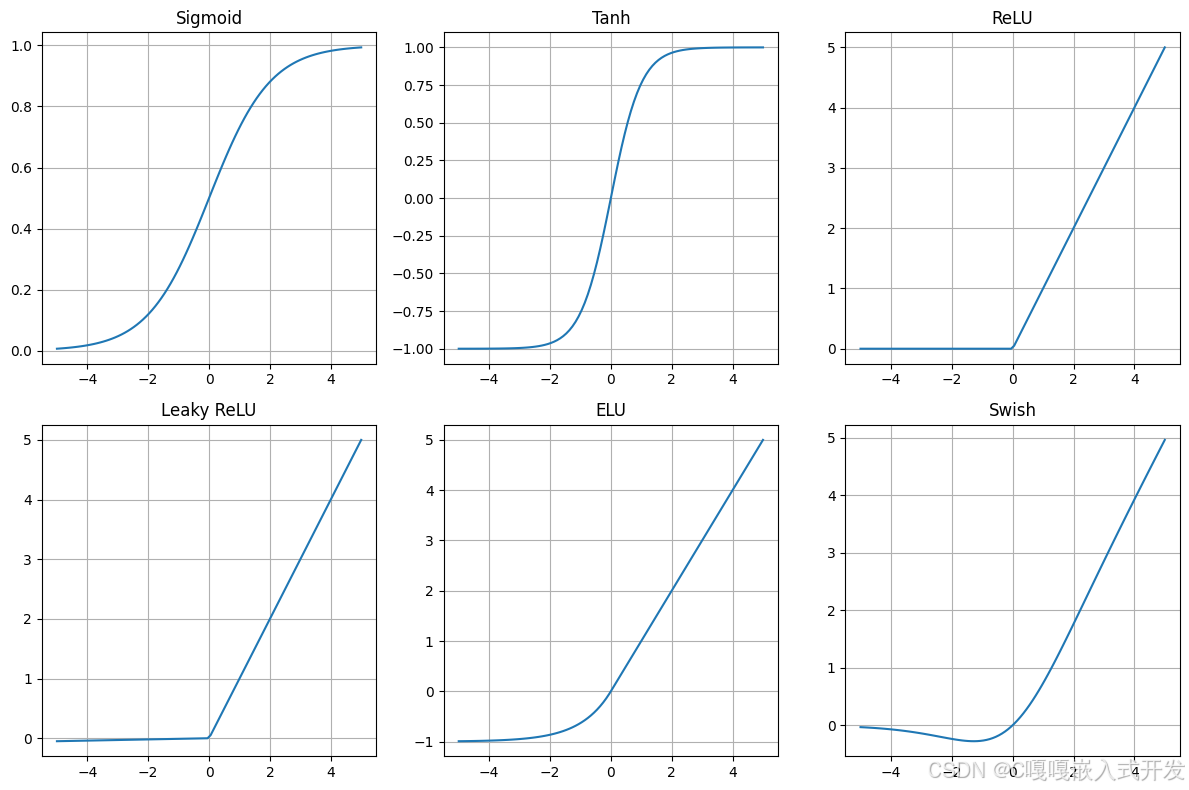
横坐标表示输入,纵坐标表示输出
3.2 激活函数的选择
选型原则
| 场景 | 首选激活 | 备注 |
|---|---|---|
| 普通 CNN/FC | ReLU | 简单快速;注意学习率和 BN |
| 深层 CNN | Swish/Mish/GELU | 轻微涨点,计算稍贵 |
| 轻量移动端 | ReLU6 (min(max(z,0),6)) | 量化友好,上限 6 |
| 循环网络 | Tanh/Sigmoid 用于门控,ReLU/PReLU 用于候选状态 | |
| 回归输出层 | 线性(无激活) | |
| 二分类输出 | Sigmoid | |
| 多分类输出 | Softmax |
4. 反向传播算法
目标:通过梯度下降最小化损失函数
前向传播:输入数据 → 层层计算 → 输出预测 → 损失函数。
反向传播:根据 链式法则 计算梯度,逐层把误差信号传回去
4.1 手动实现反向传播
python
class SimpleNN:
def __init__(self, input_size, hidden_size, output_size):
# 权重初始化
self.W1 = torch.randn(input_size, hidden_size, requires_grad=True)
self.b1 = torch.randn(hidden_size, requires_grad=True)
self.W2 = torch.randn(hidden_size, output_size, requires_grad=True)
self.b2 = torch.randn(output_size, requires_grad=True)
def forward(self, x):
# 前向传播
self.z1 = torch.matmul(x, self.W1) + self.b1
self.a1 = torch.sigmoid(self.z1)
self.z2 = torch.matmul(self.a1, self.W2) + self.b2
self.output = torch.sigmoid(self.z2)
return self.output
def backward(self, x, y, output):
# 计算损失
loss = F.mse_loss(output, y)
# 反向传播
loss.backward()
return loss
nn_model = SimpleNN(2, 3, 1)
x = torch.tensor([[0.5, 0.3]], dtype=torch.float32)
y = torch.tensor([[0.8]], dtype=torch.float32)
output = nn_model.forward(x)
loss = nn_model.backward(x, y, output)
print(f"输入: {x}")
print(f"输出: {output}")
print(f"损失: {loss}")4.2 使用PyTorch自动微分
PyTorch提供自动求导机制 ,核心是计算图
- 前向传播:PyTorch动态记录运算(操作、输入、输出)。
- 反向传播 :调用
loss.backward(),autograd 会沿着计算图自动应用链式法则。 - 更新参数:通过优化器进行
python
class AutoDiffNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.activation = nn.ReLU()
def forward(self, x):
x = self.activation(self.fc1(x))
x = self.fc2(x)
return x
# 训练
model = AutoDiffNN(2, 3, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
criterion = nn.MSELoss()
# 训练数据
X = torch.tensor([[0.5, 0.3], [0.2, 0.8], [0.9, 0.1]], dtype=torch.float32)
y = torch.tensor([[0.8], [0.6], [0.9]], dtype=torch.float32)
# 训练循环
for epoch in range(100):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')5. 网络架构设计
5.1 深度vs宽度
ResNet 证明了"非常深"网络可以训练并提升性能(靠残差连接解决优化难题)。
WideResNet 指出:在 ResNet 框架下,适当加宽(而非无限加深)能在某些数据集上带来明显提升(更短训练时间、良好性能)。
DenseNet:通过密集连接提升特征重用,能用相对少的参数获得好的表现。
EfficientNet:提出"复合缩放"------同时按比例缩放深度、宽度和输入分辨率,往往比只单独缩放某一项更高效
python
class NetworkArchitecture:
@staticmethod
def create_deep_network(input_size, output_size, depth=10, width=64):
"""创建深层网络"""
layers = []
layers.append(nn.Linear(input_size, width))
layers.append(nn.ReLU())
for _ in range(depth - 2):
layers.append(nn.Linear(width, width))
layers.append(nn.ReLU())
layers.append(nn.Dropout(0.2))
layers.append(nn.Linear(width, output_size))
return nn.Sequential(*layers)
@staticmethod
def create_wide_network(input_size, output_size, depth=3, width=512):
"""创建宽网络"""
layers = []
layers.append(nn.Linear(input_size, width))
layers.append(nn.ReLU())
for _ in range(depth - 2):
layers.append(nn.Linear(width, width))
layers.append(nn.ReLU())
layers.append(nn.Dropout(0.3))
layers.append(nn.Linear(width, output_size))
return nn.Sequential(*layers)
# 比较不同架构
deep_net = NetworkArchitecture.create_deep_network(784, 10, depth=10, width=64)
wide_net = NetworkArchitecture.create_wide_network(784, 10, depth=3, width=512)
print(f"深层网络参数量: {sum(p.numel() for p in deep_net.parameters())}")
print(f"宽网络参数量: {sum(p.numel() for p in wide_net.parameters())}")5.2 残差连接
(1)梯度消失 和 梯度爆炸
在神经网络训练中,我们使用反向传播 来计算梯度
∂ L ∂ θ = ∂ L ∂ h L ⋅ ∂ h L ∂ h L − 1 ⋅ ⋯ ⋅ ∂ h 1 ∂ θ \frac{\partial L}{\partial\theta}=\frac{\partial L}{\partial h_{L}}\cdot\frac{\partial h_{L}}{\partial h_{L-1}}\cdot\cdots\cdot\frac{\partial h_{1}}{\partial\theta} ∂θ∂L=∂hL∂L⋅∂hL−1∂hL⋅⋯⋅∂θ∂h1
其中
-
L :损失函数 L:损失函数 L:损失函数
-
h i :第 i 层的输出 h_i:第i层的输出 hi:第i层的输出
-
θ :模型参数 \theta:模型参数 θ:模型参数
注意这里的梯度是多个偏导数的连乘积。如果每一层的梯度因子很小或很大,连乘之后就会导致
- 越传越小 → 梯度消失
- 越传越大 → 梯度爆炸
(2)残差连接的提出
在深度学习早期,人们尝试通过加深网络来提升模型能力,但发现
- 网络越深,训练误差反而可能不降反升(出现"退化问题")。
- 梯度在反向传播中可能消失 或爆炸,导致优化困难。
- 深层网络即使能收敛,往往训练效果比浅层网络更差。
👉 2015 年,何恺明等人提出ResNet Deep Residual Learning for Image Recognition,引入了残差连接,使得网络可以堆叠到 152 层甚至更深,同时保持良好的收敛性和精度
python
class ResidualBlock(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, input_size)
self.activation = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
residual = x
out = self.activation(self.fc1(x))
out = self.dropout(out)
out = self.fc2(out)
out += residual # 残差连接
out = self.activation(out)
return out
class ResidualMLP(nn.Module):
def __init__(self, input_size, hidden_size, num_blocks, output_size):
super().__init__()
self.input_layer = nn.Linear(input_size, hidden_size)
self.blocks = nn.ModuleList([
ResidualBlock(hidden_size, hidden_size) for _ in range(num_blocks)
])
self.output_layer = nn.Linear(hidden_size, output_size)
self.activation = nn.ReLU()
def forward(self, x):
x = self.activation(self.input_layer(x))
for block in self.blocks:
x = block(x)
x = self.output_layer(x)
return x6. 训练技巧
6.1 权重初始化
为什么需要权重初始化?
神经网络的训练本质是梯度下降优化,如果初始权重设置不当,会导致以下问题
- 梯度消失/爆炸:层数较深时,误差的反向传播梯度会随着层数相乘,过大或过小的权重方差会加剧梯度消失或爆炸。
- 收敛变慢:如果权重初始化不合适,网络需要很长时间才能找到合适的参数空间。
- 对称性问题:如果所有神经元的初始参数相同,那么前向传播和反向传播都会产生相同的更新 → 神经元失去差异性。
因此,合理的权重初始化方法可以让信号在前向传播和反向传播中保持合适的方差,从而避免梯度消失/爆炸,加快收敛速度。
- 常见初始化方法及原理
(1) Xavier 初始化(Glorot 初始化)
-
公式 (均匀分布版)
W ∼ U ( − 6 n i n + n o u t , 6 n i n + n o u t ) W \sim U\left(-\sqrt{\frac{6}{n_{in} + n_{out}}}, \, \sqrt{\frac{6}{n_{in} + n_{out}}}\right) W∼U(−nin+nout6 ,nin+nout6 )其中 n i n 是输入神经元数, n o u t 是输出神经元数。 其中n_{in} 是输入神经元数,n_{out} 是输出神经元数。 其中nin是输入神经元数,nout是输出神经元数。
核心思想:保持前向传播和反向传播中,激活值和梯度的方差尽量一致。
-
适用激活函数:Sigmoid、Tanh。
-
优点:梯度不会太快消失,收敛更平稳。
PyTorch 对应方法
py
nn.init.xavier_uniform_(layer.weight)(2) He 初始化(Kaiming 初始化)
-
公式 (均匀分布版):
W ∼ U ( − 6 n i n , 6 n i n ) W \sim U\left(-\sqrt{\frac{6}{n_{in}}}, \, \sqrt{\frac{6}{n_{in}}}\right) W∼U(−nin6 ,nin6 ) -
核心思想 :专门为 ReLU 激活函数设计,因为 ReLU 只保留一半的输入(正数部分),所以需要更大的初始方差来补偿。
-
适用激活函数:ReLU 及其变种LeakyReLU、ELU 。
-
优点:解决 ReLU 网络中"梯度消失"的问题,收敛速度快。
PyTorch 对应方法
py
nn.init.kaiming_uniform_(layer.weight, nonlinearity='relu')(3) 正态分布初始化
-
公式
W ∼ N ( m e a n , s t d 2 ) W \sim \mathcal{N}(mean, \, std^2) W∼N(mean,std2) -
缺点:如果方差选得不合适,容易导致梯度消失/爆炸。
-
PyTorch 对应方法
py
nn.init.normal_(layer.weight, mean=0, std=0.1)
python
class WeightInitializer:
@staticmethod
def xavier_init(layer):
"""Xavier初始化"""
if isinstance(layer, nn.Linear):
nn.init.xavier_uniform_(layer.weight)
if layer.bias is not None:
nn.init.constant_(layer.bias, 0)
@staticmethod
def he_init(layer):
"""He初始化(适用于ReLU)"""
if isinstance(layer, nn.Linear):
nn.init.kaiming_uniform_(layer.weight, nonlinearity='relu')
if layer.bias is not None:
nn.init.constant_(layer.bias, 0)
@staticmethod
def normal_init(layer, mean=0, std=0.1):
"""正态分布初始化"""
if isinstance(layer, nn.Linear):
nn.init.normal_(layer.weight, mean, std)
if layer.bias is not None:
nn.init.constant_(layer.bias, 0)
# 应用初始化
def init_weights(model, init_type='xavier'):
init_methods = {
'xavier': WeightInitializer.xavier_init,
'he': WeightInitializer.he_init,
'normal': WeightInitializer.normal_init
}
for layer in model.modules():
init_methods[init_type](layer)6.2 正则化技术
定义
正则化是一种防止模型过拟合的技术。通过在损失函数中加入额外的"约束项",限制模型参数的自由度,使模型更平滑、更具泛化能力。
为什么需要正则化
过拟合问题
- 模型在训练集上表现很好,但在测试集上性能差;
- 模型学习到了噪声、偶然性规律;
- 参数权值过大,导致模型对输入变化过于敏感。
正则化通过
- 限制参数大小;
- 提高损失函数对复杂模型的惩罚;
- 强制模型学习到"平滑"的决策边界;
从而降低方差、提高泛化能力。
常见正则化类型
| 类型 | 主要思想 | 公式表示 | 对参数的影响 |
|---|---|---|---|
| L1 正则化(Lasso) | 约束参数绝对值之和 | ( \lambda \sum | w_i |
| L2 正则化(Ridge) | 约束参数平方和 | λ∑wi2\lambda \sum w_i^2λ∑wi2 | 权重被"压小",但一般不为0 |
| Elastic Net | L1 + L2混合 | ( \lambda_1 \sum | w_i |
| Dropout | 随机丢弃神经元 | - | 防止神经元间共适应,提高鲁棒性 |
| Batch Normalization | 归一化中间层输入 | - | 稳定训练、隐含正则化效果 |
| Early Stopping | 提前停止训练 | - | 防止模型过拟合到训练集 |
| Data Augmentation | 增加样本多样性 | - | 提高数据层面的泛化性 |
数学推导与直观理解
L2 正则化
损失函数
J ( θ ) = L ( y , y ^ ) + λ ∑ i = 1 n w i 2 J(\theta) = L(y, \hat{y}) + \lambda \sum_{i=1}^{n} w_i^2 J(θ)=L(y,y^)+λi=1∑nwi2
在梯度下降时的权重更新为
w i ← w i − η ( ∂ L ∂ w i + 2 λ w i ) w_i \leftarrow w_i - \eta(\frac{\partial L}{\partial w_i} + 2\lambda w_i) wi←wi−η(∂wi∂L+2λwi)
👉 理解:
L2 正则相当于在每次更新时都"拉回"权重,避免它们无限增大。
📌 结果:权值较小但非零,模型平滑稳定。
L1 正则化
损失函数:
J ( θ ) = L ( y , y ^ ) + λ ∑ i = 1 n ∣ w i ∣ J(\theta) = L(y, \hat{y}) + \lambda \sum_{i=1}^{n} |w_i| J(θ)=L(y,y^)+λi=1∑n∣wi∣
更新时
w i ← w i − η ( ∂ L ∂ w i + λ sign ( w i ) ) w_i \leftarrow w_i - \eta(\frac{\partial L}{\partial w_i} + \lambda \text{sign}(w_i)) wi←wi−η(∂wi∂L+λsign(wi))
👉 理解:
L1 正则会将部分参数直接压缩为 0,使模型稀疏化,常用于特征选择。
Elastic Net 正则化
J ( θ ) = L ( y , y ^ ) + λ 1 ∑ ∣ w i ∣ + λ 2 ∑ w i 2 J(\theta) = L(y, \hat{y}) + \lambda_1 \sum |w_i| + \lambda_2 \sum w_i^2 J(θ)=L(y,y^)+λ1∑∣wi∣+λ2∑wi2
👉 兼具 L1 的稀疏性与 L2 的稳定性,适合高维稀疏数据。
深度学习中的正则化方法
①Dropout随机失活
原理
-
在训练过程中,以概率
p随机丢弃一部分神经元; -
让网络在不同子网络上学习,降低共适应。
训练时:随机屏蔽部分神经元
测试时:使用所有神经元,但输出缩放为 p 倍
py
import torch.nn as nn
model = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(p=0.5), # 丢弃50%
nn.Linear(64, 10)
)② Batch Normalization批归一化
虽然主要目的是加快收敛 、稳定梯度 ,但它也有隐式正则化作用
-
降低模型对权重初始化的敏感性;
-
提高泛化性能。
nn.BatchNorm1d(64) # 全连接层
nn.BatchNorm2d(32) # 卷积层
③ Early Stopping
原理
在验证集上监控损失函数
-
若连续若干轮验证集损失不再下降,则停止训练;
-
防止模型继续过拟合训练集。
best_loss = float('inf')
patience, counter = 5, 0
for epoch in range(num_epochs):
train(...)
val_loss = validate(...)
if val_loss < best_loss:
best_loss = val_loss
counter = 0
else:
counter += 1
if counter >= patience:
print("Early stopping!")
break
④ 数据增强
在图像任务中最常见的正则化手段之一。
如
- 翻转、旋转、裁剪;
- 颜色扰动;
- Mixup、Cutout 增强方式。
py
from torchvision import transforms
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor()
])PyTorch 优化器中的 weight_decay 参数就是 L2 正则化。
L2 正则化
py
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)L1 正则化需手动添加
py
l1_lambda = 1e-5
l1_norm = sum(p.abs().sum() for p in model.parameters())
loss = loss_fn(output, target) + l1_lambda * l1_norm
python
class RegularizedMLP(nn.Module):
def __init__(self, input_size, hidden_sizes, output_size, dropout_rate=0.5):
super().__init__()
layers = []
# 输入层
layers.append(nn.Linear(input_size, hidden_sizes[0]))
layers.append(nn.BatchNorm1d(hidden_sizes[0]))
layers.append(nn.ReLU())
layers.append(nn.Dropout(dropout_rate))
# 隐藏层
for i in range(len(hidden_sizes) - 1):
layers.append(nn.Linear(hidden_sizes[i], hidden_sizes[i+1]))
layers.append(nn.BatchNorm1d(hidden_sizes[i+1]))
layers.append(nn.ReLU())
layers.append(nn.Dropout(dropout_rate))
# 输出层
layers.append(nn.Linear(hidden_sizes[-1], output_size))
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
# 使用L2正则化
def train_with_regularization(model, train_loader, optimizer, criterion, weight_decay=1e-4):
model.train()
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
# L2正则化
l2_reg = torch.tensor(0.)
for param in model.parameters():
l2_reg += torch.norm(param)
loss += weight_decay * l2_reg
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)6.3 学习率调度
在深度学习训练过程中,学习率(Learning Rate, LR) 是最关键的超参数之一。
它决定了参数更新的步伐大小
学习率太大 → 可能导致损失震荡、发散;
学习率太小 → 收敛缓慢,陷入局部最优。
为了在训练早期快速下降、后期稳定收敛,常采用 动态调整学习率 的策略,即"学习率调度器(LR Scheduler)"。
学习率调度器会在训练的不同阶段 自动修改优化器中的学习率。
常见学习率调度策略
① StepLR步长衰减
py
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)原理
每隔 step_size 个 epoch,将学习率乘以一个系数 gamma。
数学表达式:
l r n e w = l r o l d × γ ⌊ e p o c h / s t e p _ s i z e ⌋ lr_{new} = lr_{old} \times \gamma^{\lfloor epoch / step\_size \rfloor} lrnew=lrold×γ⌊epoch/step_size⌋
特点与适用场景
- 简单有效;
- 常用于训练稳定的网络如ResNet、VGG;
- 常见组合:
step_size=30, gamma=0.1。
优点:
- 控制直观;
- 对训练时间长的模型收敛效果明显。
② ExponentialLR指数衰减
py
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)原理:
每个 epoch 以固定比例衰减学习率。
l r n e w = l r o l d × γ lr_{new} = lr_{old} \times γ lrnew=lrold×γ
特点与适用场景:
- 学习率平滑衰减;
- 适合连续、长时间训练的模型;
- 当损失下降平稳时,指数衰减可避免突变。
③ CosineAnnealingLR余弦退火
py
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100)原理:
- 学习率按余弦曲线从初始值缓慢下降至 0;
- 模拟"退火"过程,使模型在后期探索更细致。
l r t = 1 2 ( 1 + cos ( t T m a x π ) ) × l r 0 lr_t = \frac{1}{2}\left(1 + \cos\left(\frac{t}{T_{max}}\pi\right)\right) \times lr_0 lrt=21(1+cos(Tmaxtπ))×lr0
特点与适用场景:
- 无需手动设定衰减点;
- 常用于 Transformer、ViT、ResNet 等现代架构;
- 可与 Warmup 结合使用(即前若干 epoch 学习率逐步升高)。
优点:
- 平滑且稳定;
- 后期学习率逐渐趋近 0,有助于稳定收敛。
④ ReduceLROnPlateau(自适应调度)
py
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=10, factor=0.5)原理:
- 根据验证集损失的变化动态调整;
- 当 val_loss 在
patience个 epoch 内未改善时,学习率 *= factor。
特点与适用场景:
- 自适应调整,无需预设 epoch;
- 特别适用于损失曲线震荡的任务如NLP、复杂分类。
使用方式不同:
与其他调度器不同,它必须在 验证阶段调用:
py
val_loss = validate(model, val_loader)
scheduler.step(val_loss)不同调度器的比较
| 调度器类型 | 控制参数 | 调整依据 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| StepLR | step_size, gamma | 固定步长 | 简单高效 | 变化突兀 | 长时间稳定训练 |
| ExponentialLR | gamma | 每个 epoch | 平滑衰减 | 不够灵活 | 持续衰减任务 |
| CosineAnnealingLR | T_max | epoch 进度 | 平滑退火,效果佳 | 需确定 T_max | 高性能模型训练 |
| ReduceLROnPlateau | patience, factor | 验证损失 | 自适应性强 | 需验证集 | 验证驱动任务 |
实现
python
import torch.optim as optim
class LearningRateScheduler:
@staticmethod
def step_scheduler(optimizer, step_size=30, gamma=0.1):
"""步长调度器"""
return optim.lr_scheduler.StepLR(optimizer, step_size, gamma)
@staticmethod
def exponential_scheduler(optimizer, gamma=0.95):
"""指数调度器"""
return optim.lr_scheduler.ExponentialLR(optimizer, gamma)
@staticmethod
def cosine_scheduler(optimizer, T_max=100):
"""余弦退火调度器"""
return optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max)
@staticmethod
def reduce_on_plateau(optimizer, patience=10, factor=0.5):
"""基于验证损失的自适应调度器"""
return optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=patience, factor=factor)
model = RegularizedMLP(784, [256, 128, 64], 10)
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = LearningRateScheduler.cosine_scheduler(optimizer, T_max=100)
for epoch in range(100):
# 训练
train_loss = train_epoch(model, train_loader, optimizer, criterion)
# 更新学习率
scheduler.step()
print(f'Epoch {epoch}, LR: {optimizer.param_groups[0]["lr"]:.6f}, Loss: {train_loss:.4f}')7. 优化算法
7.1 常用优化器
优化器是引导机器学习模型朝着正确方向更新的算法。
python
class OptimizerComparison:
@staticmethod
def compare_optimizers(model, train_loader, criterion, num_epochs=50):
optimizers = {
'SGD': optim.SGD(model.parameters(), lr=0.01, momentum=0.9),
'Adam': optim.Adam(model.parameters(), lr=0.001),
'AdamW': optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4),
'RMSprop': optim.RMSprop(model.parameters(), lr=0.001),
'Adagrad': optim.Adagrad(model.parameters(), lr=0.01)
}
results = {}
for name, optimizer in optimizers.items():
print(f"训练 {name} 优化器...")
model_copy = copy.deepcopy(model)
optimizer_copy = type(optimizer)(model_copy.parameters(), **optimizer.defaults)
losses = []
for epoch in range(num_epochs):
epoch_loss = train_epoch(model_copy, train_loader, optimizer_copy, criterion)
losses.append(epoch_loss)
results[name] = losses
return results
# 可视化优化器比较
def plot_optimizer_comparison(results):
plt.figure(figsize=(10, 6))
for name, losses in results.items():
plt.plot(losses, label=name)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Optimizer Comparison')
plt.legend()
plt.grid(True)
plt.show()7.2 自适应学习率
在传统的梯度下降法中,我们为所有参数 设置一个全局的、固定不变的学习率。
自适应学习率的解决方案 :
放弃"一刀切"的策略,为每一个参数 都维护一个独属于它自己的、动态变化的学习率。
- 对于频繁更新、梯度较大 的参数,我们希望它的学习率小一些,这样步伐会更稳重,防止震荡。
- 对于不常更新、梯度较小 的参数,我们希望它的学习率大一些,这样它能更快地前进。
python
class AdaptiveLearningRate:
def __init__(self, initial_lr=0.001, min_lr=1e-6, patience=10, factor=0.5):
self.initial_lr = initial_lr
self.min_lr = min_lr
self.patience = patience
self.factor = factor
self.best_loss = float('inf')
self.wait = 0
self.current_lr = initial_lr
def step(self, val_loss):
if val_loss < self.best_loss:
self.best_loss = val_loss
self.wait = 0
else:
self.wait += 1
if self.wait >= self.patience:
self.current_lr = max(self.current_lr * self.factor, self.min_lr)
self.wait = 0
return self.current_lr8. 应用案例
8.1 手写数字识别
python
import torchvision
from torchvision import transforms
class MNISTClassifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 10)
self.dropout = nn.Dropout(0.2)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(x.size(0), -1) # 展平
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.dropout(x)
x = self.relu(self.fc3(x))
x = self.dropout(x)
x = self.fc4(x)
return x
# 数据加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = torchvision.datasets.MNIST(
root='./data', train=True, download=True, transform=transform
)
test_dataset = torchvision.datasets.MNIST(
root='./data', train=False, download=True, transform=transform
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 训练模型
model = MNISTClassifier()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train_epoch(model, train_loader, optimizer, criterion):
model.train()
total_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
accuracy = 100. * correct / total
return total_loss / len(train_loader), accuracy
# 训练循环
for epoch in range(10):
train_loss, train_acc = train_epoch(model, train_loader, optimizer, criterion)
print(f'Epoch {epoch+1}: Loss={train_loss:.4f}, Accuracy={train_acc:.2f}%')8.2 回归任务
python
class RegressionMLP(nn.Module):
def __init__(self, input_size, hidden_sizes, output_size):
super().__init__()
layers = []
# 输入层
layers.append(nn.Linear(input_size, hidden_sizes[0]))
layers.append(nn.ReLU())
layers.append(nn.Dropout(0.1))
# 隐藏层
for i in range(len(hidden_sizes) - 1):
layers.append(nn.Linear(hidden_sizes[i], hidden_sizes[i+1]))
layers.append(nn.ReLU())
layers.append(nn.Dropout(0.1))
# 输出层
layers.append(nn.Linear(hidden_sizes[-1], output_size))
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
# 生成回归数据
def generate_regression_data(n_samples=1000, n_features=10, noise=0.1):
X = torch.randn(n_samples, n_features)
# 创建非线性关系
y = torch.sum(X ** 2, dim=1, keepdim=True) + noise * torch.randn(n_samples, 1)
return X, y
# 训练回归模型
X, y = generate_regression_data()
model = RegressionMLP(10, [64, 32, 16], 1)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练
for epoch in range(100):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')9. 相关论文与研究方向
9.1 经典论文
-
"Learning representations by back-propagating errors" (1986) - Rumelhart et al.
- 反向传播算法的经典论文
- 奠定了神经网络训练的基础
-
"Gradient-based learning applied to document recognition" (1998) - LeCun et al.
- 卷积神经网络的早期应用
- 展示了深度学习的潜力
-
"Deep learning" (2015) - LeCun, Bengio & Hinton
- 深度学习的综述论文
- 总结了深度学习的发展历程
9.2 现代发展
-
"Batch Normalization: Accelerating Deep Network Training" (2015) - Ioffe & Szegedy
- 批归一化技术
- 加速了深度网络的训练
-
"Dropout: A Simple Way to Prevent Neural Networks from Overfitting" (2014) - Srivastava et al.
- Dropout正则化技术
- 有效防止过拟合
-
"Adam: A Method for Stochastic Optimization" (2014) - Kingma & Ba
- Adam优化算法
- 成为最流行的优化器之一
10. 未来发展趋势
10.1 技术趋势
- 神经架构搜索: 自动设计网络结构
- 可解释AI: 理解神经网络的决策过程
- 联邦学习: 分布式训练保护隐私
- 量子神经网络: 结合量子计算的优势
10.2 应用趋势
- 边缘计算: 在移动设备上部署DNN
- 实时系统: 低延迟的推理系统
- 多模态学习: 处理多种类型的数据
- 自监督学习: 减少对标注数据的依赖
参考文献
-
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533-536.
-
LeCun, Y., et al. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
-
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-444.
-
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. International conference on machine learning, 448-456.
-
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.