背景意义
研究背景与意义
随着农业科技的不断发展,精准农业的理念逐渐深入人心,尤其是在作物病虫害监测与管理方面,计算机视觉技术的应用展现出了巨大的潜力。水果叶片的健康状况直接影响到作物的产量和品质,因此,如何快速、准确地对水果叶片进行分割与识别,成为了农业研究中的一个重要课题。近年来,深度学习技术的飞速发展为图像分割任务提供了新的解决方案,其中YOLO(You Only Look Once)系列模型因其高效的实时处理能力而备受关注。YOLOv8作为该系列的最新版本,具备了更强的特征提取能力和更高的分割精度,为水果叶片的实例分割提供了良好的基础。
本研究旨在基于改进的YOLOv8模型,构建一个高效的水果叶片分割系统,以实现对黑莓和树莓等水果叶片的精确识别与分割。数据集包含1200张图像,涵盖了四个类别:向下生长的黑莓叶片、向上生长的黑莓叶片、向下生长的树莓叶片以及向上生长的树莓叶片。这些类别的选择不仅体现了不同生长状态的叶片特征,也为模型的训练提供了丰富的样本。通过对这些图像的深入分析,我们可以提取出不同叶片在形态、颜色和纹理等方面的特征,从而提高模型的分割精度。
水果叶片的分割不仅是对图像处理技术的挑战,更是对农业生产实践的直接影响。准确的叶片分割可以为后续的病虫害检测、营养状态评估以及生长监测提供可靠的数据支持。通过本研究开发的分割系统,农业工作者能够实时获取叶片的健康信息,及时采取措施应对潜在的病虫害威胁,从而实现精准施药和科学管理,提高农业生产效率和可持续发展水平。
此外,改进YOLOv8模型的研究也具有重要的学术意义。通过对模型架构的优化与调整,我们不仅可以提升其在水果叶片分割任务中的表现,还能够为其他领域的实例分割问题提供借鉴。这种跨领域的应用潜力,使得本研究不仅限于水果叶片的分割,更为深度学习技术在农业领域的推广与应用提供了新的思路。
综上所述,基于改进YOLOv8的水果叶片分割系统的研究,不仅具有重要的实践意义,还在理论层面上推动了计算机视觉技术在农业领域的应用发展。通过对水果叶片的精准分割,我们期望能够为现代农业的智能化、信息化进程贡献一份力量,助力实现更高效、更可持续的农业生产模式。
图片效果
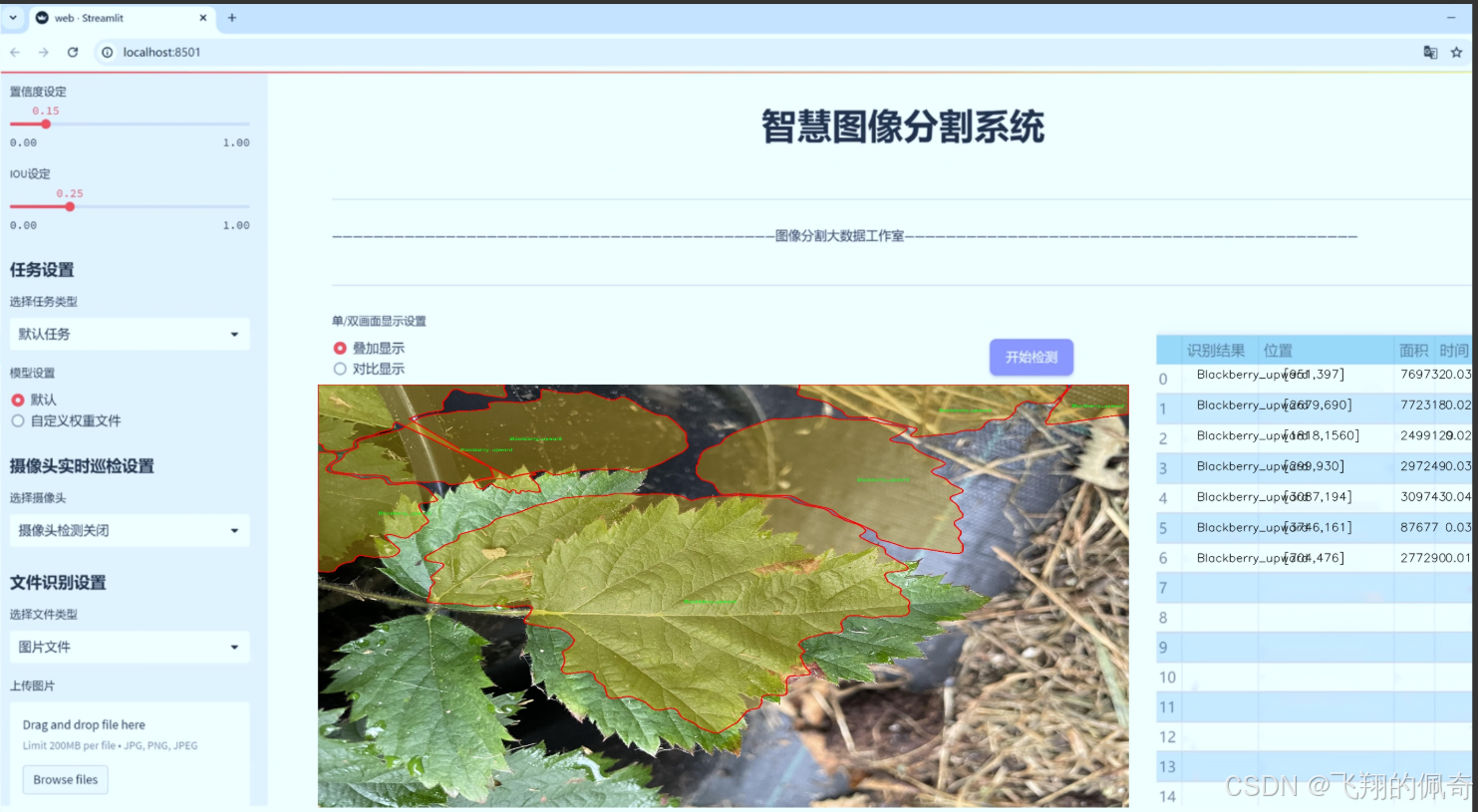
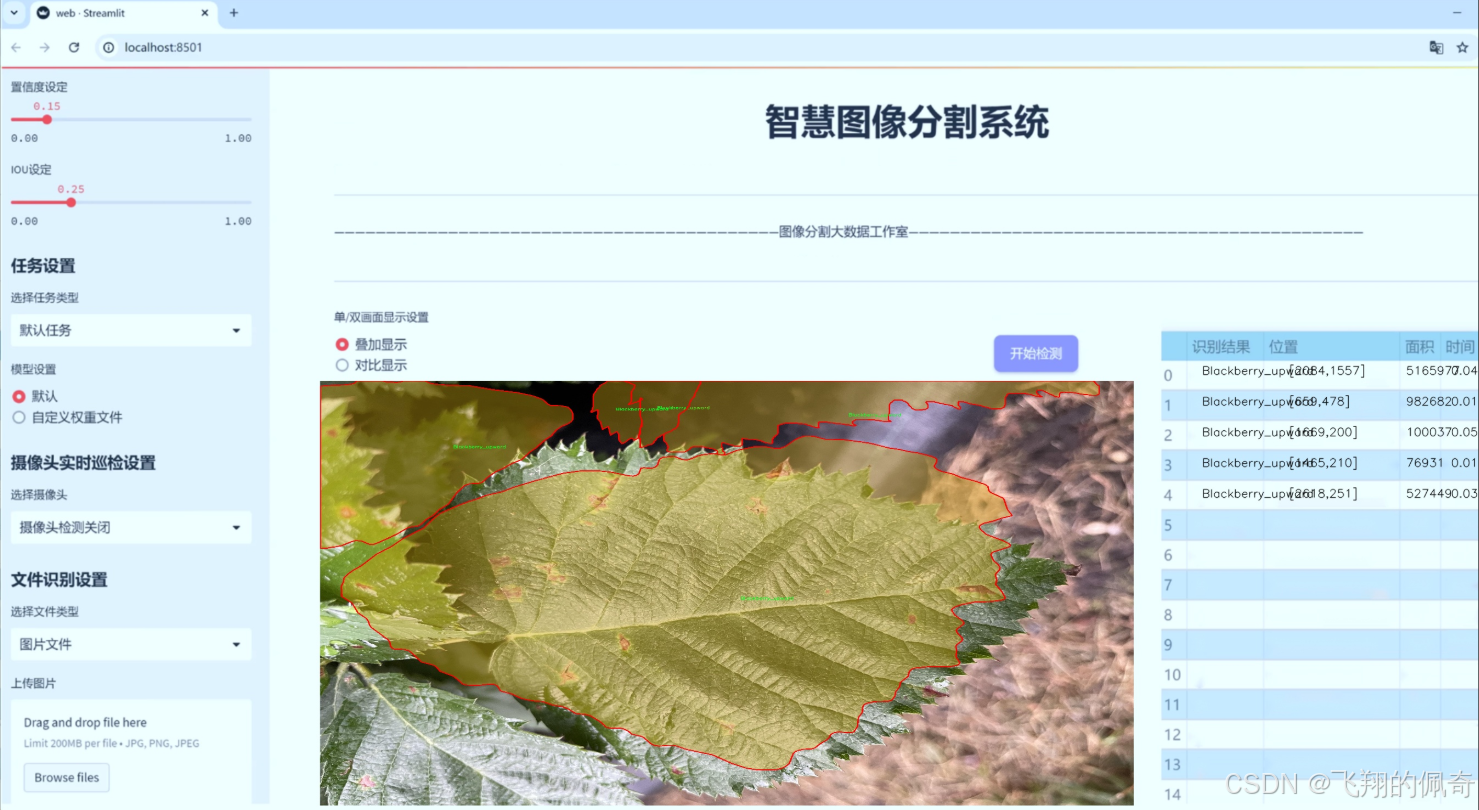
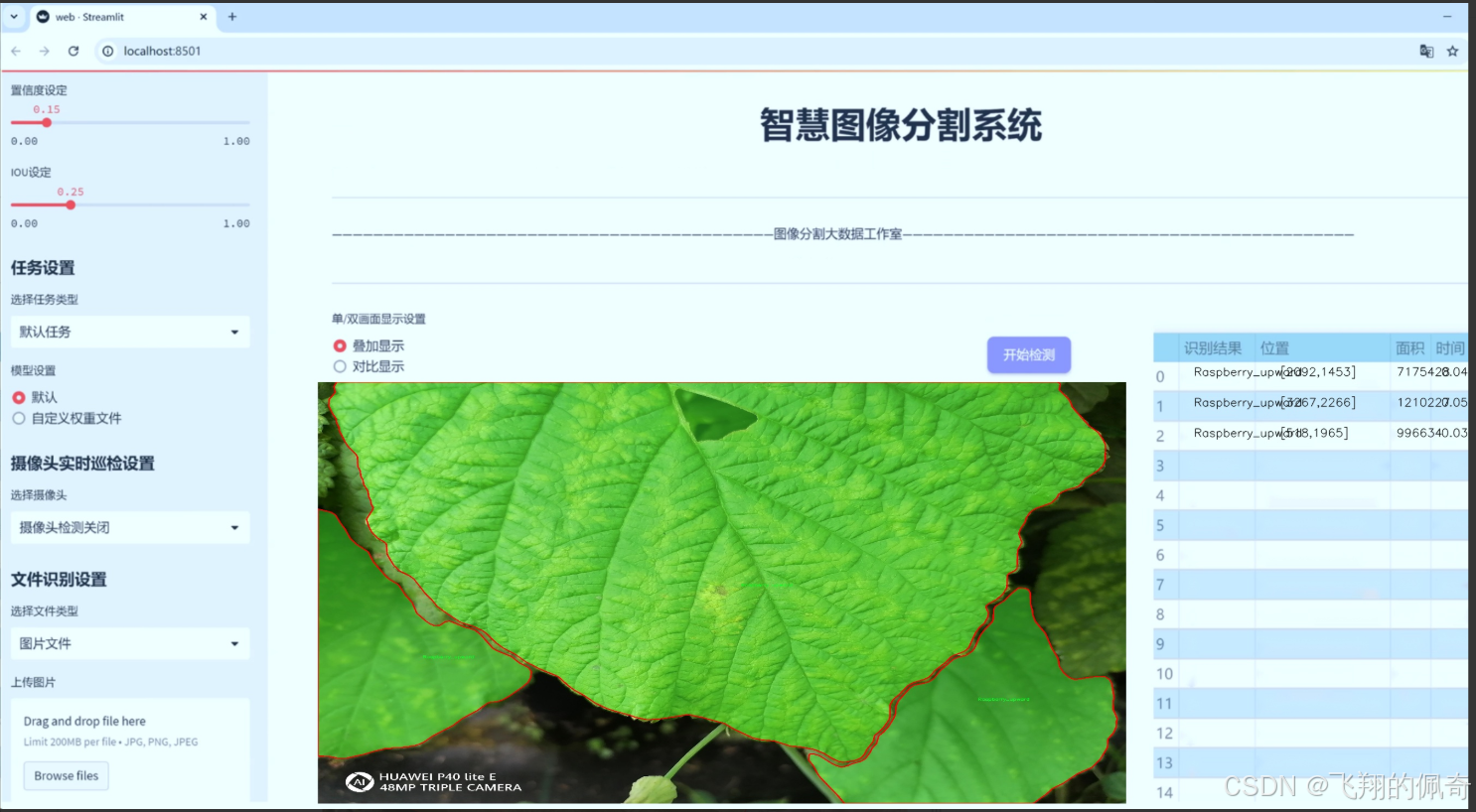
数据集信息
数据集信息展示
在本研究中,我们采用了名为"sport"的数据集,以训练和改进YOLOv8-seg模型,旨在实现高效的水果叶片分割系统。该数据集专注于特定类型的水果叶片,涵盖了四个主要类别,分别是"Blackberry_downward"、"Blackberry_upward"、"Raspberry_downward"和"Raspberry_upward"。这些类别的选择不仅反映了水果植物的多样性,还为模型提供了丰富的特征和变异性,从而增强了分割系统的泛化能力。
"sport"数据集的构建过程注重数据的多样性和代表性。每个类别的样本均经过精心挑选,确保涵盖不同生长阶段、光照条件和背景环境下的叶片图像。这种多样性使得模型在训练过程中能够学习到更为全面的特征,从而提高其在实际应用中的表现。例如,黑莓叶片在不同生长方向(向下和向上)下的外观差异,以及覆盆子叶片在不同环境光照条件下的变化,均为模型提供了丰富的训练数据。这些因素共同作用,使得模型能够更好地适应复杂的自然环境,提高其在真实场景中的应用效果。
在数据集的标注过程中,我们采用了高精度的标注工具,确保每个图像中的叶片区域被准确地标记出来。标注的准确性对于训练深度学习模型至关重要,因为它直接影响到模型的学习效果和最终的分割精度。为此,我们的标注团队经过专业培训,严格遵循标注规范,确保每个类别的标注一致性和准确性。此外,为了进一步提升数据集的质量,我们还进行了多轮的审核和校正,确保每个样本的标注都经过严格的验证。
在数据集的使用过程中,我们还考虑到了数据增强技术的应用,以进一步提升模型的鲁棒性。通过对原始图像进行旋转、缩放、翻转和颜色调整等操作,我们能够生成更多的训练样本,从而有效地扩展数据集的规模。这种方法不仅能够缓解过拟合问题,还能提高模型在不同条件下的适应能力,使其在面对未见过的样本时仍能保持良好的分割性能。
总的来说,"sport"数据集为改进YOLOv8-seg的水果叶片分割系统提供了坚实的基础。通过精心挑选的类别、严格的标注过程以及有效的数据增强策略,我们相信该数据集将为研究人员和开发者提供强有力的支持,推动水果叶片分割技术的进一步发展。未来,我们期待该系统能够在农业监测、病虫害防治等领域发挥重要作用,为现代农业的智能化发展贡献力量。





核心代码
以下是经过简化和注释的核心代码部分:
import cv2
from ultralytics.utils.plotting import Annotator
class AIGym:
"""管理实时视频流中基于姿势的健身步骤的类。"""
def __init__(self):
"""初始化AIGym,设置默认的视觉和图像参数。"""
self.im0 = None # 当前帧图像
self.tf = None # 线条厚度
self.keypoints = None # 姿势关键点
self.poseup_angle = None # 上升姿势角度
self.posedown_angle = None # 下降姿势角度
self.threshold = 0.001 # 阈值
self.angle = None # 当前角度
self.count = None # 当前计数
self.stage = None # 当前阶段
self.pose_type = 'pushup' # 姿势类型
self.kpts_to_check = None # 需要检查的关键点
self.view_img = False # 是否显示图像
self.annotator = None # 注释器实例
def set_args(self, kpts_to_check, line_thickness=2, view_img=False, pose_up_angle=145.0, pose_down_angle=90.0, pose_type='pullup'):
"""
配置AIGym的参数。
Args:
kpts_to_check (list): 用于计数的3个关键点
line_thickness (int): 边界框的线条厚度
view_img (bool): 是否显示图像
pose_up_angle (float): 上升姿势的角度
pose_down_angle (float): 下降姿势的角度
pose_type: "pushup", "pullup" 或 "abworkout"
"""
self.kpts_to_check = kpts_to_check
self.tf = line_thickness
self.view_img = view_img
self.poseup_angle = pose_up_angle
self.posedown_angle = pose_down_angle
self.pose_type = pose_type
def start_counting(self, im0, results, frame_count):
"""
计数健身步骤的函数。
Args:
im0 (ndarray): 当前视频流帧
results: 姿势估计数据
frame_count: 当前帧计数
"""
self.im0 = im0 # 保存当前帧
if frame_count == 1:
# 初始化计数和角度
self.count = [0] * len(results[0])
self.angle = [0] * len(results[0])
self.stage = ['-' for _ in results[0]]
self.keypoints = results[0].keypoints.data # 获取关键点数据
self.annotator = Annotator(im0, line_width=2) # 创建注释器实例
for ind, k in enumerate(reversed(self.keypoints)):
# 计算姿势角度
self.angle[ind] = self.annotator.estimate_pose_angle(
k[int(self.kpts_to_check[0])].cpu(),
k[int(self.kpts_to_check[1])].cpu(),
k[int(self.kpts_to_check[2])].cpu()
)
self.im0 = self.annotator.draw_specific_points(k, self.kpts_to_check, shape=(640, 640), radius=10)
# 根据姿势类型更新阶段和计数
if self.pose_type == 'pushup':
if self.angle[ind] > self.poseup_angle:
self.stage[ind] = 'up'
if self.angle[ind] < self.posedown_angle and self.stage[ind] == 'up':
self.stage[ind] = 'down'
self.count[ind] += 1
elif self.pose_type == 'pullup':
if self.angle[ind] > self.poseup_angle:
self.stage[ind] = 'down'
if self.angle[ind] < self.posedown_angle and self.stage[ind] == 'down':
self.stage[ind] = 'up'
self.count[ind] += 1
# 绘制角度、计数和阶段信息
self.annotator.plot_angle_and_count_and_stage(
angle_text=self.angle[ind],
count_text=self.count[ind],
stage_text=self.stage[ind],
center_kpt=k[int(self.kpts_to_check[1])],
line_thickness=self.tf
)
self.annotator.kpts(k, shape=(640, 640), radius=1, kpt_line=True) # 绘制关键点
# 显示图像
if self.view_img:
cv2.imshow('Ultralytics YOLOv8 AI GYM', self.im0)
if cv2.waitKey(1) & 0xFF == ord('q'):
returnif name == 'main ':
AIGym() # 实例化AIGym类
代码说明:
类的定义:AIGym类用于管理实时视频流中人的健身动作计数。
初始化方法:__init__方法初始化类的属性,包括图像、关键点、计数和阶段等。
设置参数:set_args方法用于配置健身动作计数所需的参数。
计数方法:start_counting方法处理每一帧图像,计算姿势角度,更新计数和阶段,并在图像上绘制相关信息。
显示图像:如果设置了显示图像的参数,则使用OpenCV显示当前帧图像。
这个程序文件定义了一个名为 AIGym 的类,旨在通过实时视频流监测和计数人们的健身动作,主要是针对特定的姿势(如俯卧撑、引体向上和腹部锻炼)。程序使用了 OpenCV 库来处理图像,并通过 Annotator 类来进行可视化标注。
在 AIGym 类的初始化方法中,设置了一些默认值,包括图像参数、关键点信息、计数和角度信息等。类中定义了一些属性,例如 im0 用于存储当前帧图像,keypoints 用于存储关键点数据,count 用于记录动作的次数,stage 用于记录当前的动作阶段(如向上或向下),以及 pose_type 用于指定当前的锻炼类型。
set_args 方法用于配置 AIGym 的参数,包括需要检查的关键点、线条厚度、是否显示图像、姿势的上下角度以及锻炼类型。这个方法允许用户根据需要自定义参数。
start_counting 方法是核心功能,用于在每一帧中进行健身动作的计数。它接收当前帧图像、姿势估计结果和帧计数作为输入。方法首先检查帧计数,如果是第一帧,则初始化计数和角度列表。接着,程序提取关键点数据,并通过 Annotator 实例进行可视化处理。
在循环中,程序根据不同的锻炼类型(俯卧撑、引体向上、腹部锻炼)计算每个关键点的姿势角度,并根据角度判断当前的动作阶段。根据阶段的变化,程序会更新计数并在图像上绘制角度、计数和阶段信息。
最后,如果设置了 view_img 为 True,程序会使用 OpenCV 显示当前处理的图像,并在按下 'q' 键时退出显示。
总的来说,这个程序通过实时视频流分析用户的健身动作,提供了一个互动的健身监测工具,能够帮助用户实时了解自己的锻炼情况。
11.4 ultralytics\trackers\utils_init_.py
Ultralytics YOLO 🚀, AGPL-3.0 license
这段代码是Ultralytics YOLO(You Only Look Once)模型的开源实现,遵循AGPL-3.0许可证。
YOLO是一种用于目标检测的深度学习模型,能够在图像中快速识别和定位多个对象。
下面是YOLO模型的核心部分
class YOLO:
def init (self, model_path):
初始化YOLO模型
model_path: 预训练模型的路径
self.model = self.load_model(model_path) # 加载模型
def load_model(self, model_path):
# 加载预训练的YOLO模型
# 这里可以使用深度学习框架(如PyTorch或TensorFlow)来加载模型
pass # 实际加载模型的代码
def predict(self, image):
# 对输入图像进行目标检测
# image: 输入的图像数据
detections = self.model(image) # 使用模型进行预测
return detections # 返回检测结果该类的使用示例
yolo = YOLO('path/to/model.pt') # 创建YOLO对象并加载模型
results = yolo.predict(input_image) # 对输入图像进行预测
注释说明:
类定义:class YOLO 定义了一个YOLO模型的类,封装了模型的加载和预测功能。
初始化方法:init 方法用于初始化YOLO对象,接受模型路径作为参数,并调用load_model方法加载模型。
加载模型:load_model 方法负责加载预训练的YOLO模型,具体实现依赖于所使用的深度学习框架。
预测方法:predict 方法接受输入图像,使用加载的模型进行目标检测,并返回检测结果。
使用示例:最后的注释展示了如何创建YOLO对象并使用其进行预测的示例。
这个文件是Ultralytics YOLO项目的一部分,属于一个名为trackers的模块。文件的开头包含了一行注释,表明该项目是Ultralytics开发的YOLO(You Only Look Once)目标检测算法的一部分,并且使用AGPL-3.0许可证。这意味着该代码是开源的,用户可以自由使用和修改,但在分发修改后的版本时需要遵循相同的许可证条款。
虽然文件内容非常简短,仅包含这一行注释,但它的存在表明了代码的版权信息和使用条款。通常,在一个模块的__init__.py文件中,开发者会初始化模块,导入必要的类和函数,使得用户在导入该模块时能够直接使用其中的功能。
总的来说,这个文件的主要作用是提供版权信息,并可能作为模块的入口文件,帮助用户理解该模块的用途和法律条款。
11.5 ultralytics\utils\callbacks_init_.py
以下是经过简化和注释的核心代码部分:
导入必要的函数和模块
from .base import add_integration_callbacks, default_callbacks, get_default_callbacks
定义模块的公开接口,指定可以被外部访问的函数
all = 'add_integration_callbacks', 'default_callbacks', 'get_default_callbacks'
详细注释:
from .base import add_integration_callbacks, default_callbacks, get_default_callbacks:
这一行代码从当前包的 base 模块中导入了三个函数:add_integration_callbacks、default_callbacks 和 get_default_callbacks。这些函数可能用于处理回调函数的集成、获取默认回调等功能。
all = 'add_integration_callbacks', 'default_callbacks', 'get_default_callbacks':
这一行定义了模块的 all 属性,它是一个字符串元组,指定了在使用 from module import * 语句时,哪些名称是可以被导入的。这有助于控制模块的公共接口,避免不必要的名称泄露。
这个程序文件是Ultralytics YOLO项目中的一个初始化文件,位于ultralytics/utils/callbacks目录下。文件的主要功能是导入和暴露一些与回调函数相关的工具。
首先,文件开头的注释部分表明了该项目的名称(Ultralytics YOLO)以及其使用的许可证类型(AGPL-3.0)。这意味着该项目是开源的,并且遵循特定的许可证条款。
接下来,文件通过相对导入的方式,从同一目录下的base模块中导入了三个函数:add_integration_callbacks、default_callbacks和get_default_callbacks。这些函数的具体功能可能与回调机制的实现有关,回调函数通常用于在特定事件发生时执行特定的操作,例如在训练过程中记录日志、调整学习率等。
最后,__all__变量被定义为一个元组,包含了刚刚导入的三个函数名。这一做法的目的是为了明确该模块对外暴露的接口,使用from module import *语句时,只会导入__all__中列出的名称。这有助于避免命名冲突,并使得模块的使用更加清晰。
总的来说,这个文件的作用是为回调函数提供一个统一的接口,使得其他模块可以方便地使用这些功能。
12.系统整体结构(节选)
整体功能和构架概括
Ultralytics YOLO项目是一个开源的目标检测框架,提供了多种模型和工具,旨在简化目标检测任务的实现。该项目的架构模块化,包含多个子模块,每个模块负责特定的功能。以下是各个模块的功能概述:
配置管理:ultralytics/cfg/init.py文件负责管理模型的配置参数,提供命令行接口,允许用户自定义训练和推理过程中的参数。
模型训练:ultralytics/models/rtdetr/train.py文件专注于RT-DETR模型的训练过程,定义了训练器类,负责模型的初始化、数据集构建和验证。
健身动作监测:ultralytics/solutions/ai_gym.py文件实现了一个实时视频流分析工具,用于监测和计数用户的健身动作,结合姿势估计技术,提供实时反馈。
回调机制:ultralytics/trackers/utils/init.py文件用于初始化回调函数模块,导入与回调相关的工具,方便在训练和推理过程中执行特定操作。
回调函数工具:ultralytics/utils/callbacks/init.py文件提供了回调函数的基本实现,允许用户在训练过程中添加集成回调和默认回调。
文件功能整理表
文件路径 功能描述
ultralytics/cfg/init .py 管理YOLO模型的配置参数,提供命令行接口,允许用户自定义训练和推理参数。
ultralytics/models/rtdetr/train.py 实现RT-DETR模型的训练过程,定义训练器类,负责模型初始化、数据集构建和验证。
ultralytics/solutions/ai_gym.py 实现实时视频流分析工具,用于监测和计数用户的健身动作,结合姿势估计技术提供实时反馈。
ultralytics/trackers/utils/init .py 初始化回调函数模块,导入与回调相关的工具,方便在训练和推理过程中执行特定操作。
ultralytics/utils/callbacks/init .py 提供回调函数的基本实现,允许用户在训练过程中添加集成回调和默认回调。
这个表格总结了每个文件的主要功能,帮助理解Ultralytics YOLO项目的整体结构和各个模块之间的关系。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
...
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
...
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype("simsun.ttc", font_size, encoding="unic")
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info'class_name', info'bbox', info'score', info'class_id', info'mask'
adjust_param = adjust_parameter(image.shape:2)
spacing = int(20 * adjust_param)
if mask is None:
x1, y1, x2, y2 = bbox
aim_frame_area = (x2 - x1) * (y2 - y1)
cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))
image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:
mask_points = np.concatenate(mask)
aim_frame_area = calculate_polygon_area(mask_points)
mask_color = generate_color_based_on_name(name)
try:
overlay = image.copy()
cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)
image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)
cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))
# 计算面积、周长、圆度
area = cv2.contourArea(mask_points.astype(np.int32))
perimeter = cv2.arcLength(mask_points.astype(np.int32), True)
......
# 计算色彩
mask = np.zeros(image.shape[:2], dtype=np.uint8)
cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)
color_points = cv2.findNonZero(mask)
......
# 绘制类别名称
x, y = np.min(mask_points, axis=0).astype(int)
image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param)
# 绘制面积、周长、圆度和色彩值
metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]
for idx, (metric_name, metric_value) in enumerate(metrics):
......
return image, aim_frame_area处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred0 if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == "main ":
cls_name = Label_list
model = Web_Detector()
model.load_model("./weights/yolov8s-seg.pt")
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
......
# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:
processed_image = process_frame(model, image)
......
# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
......源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式