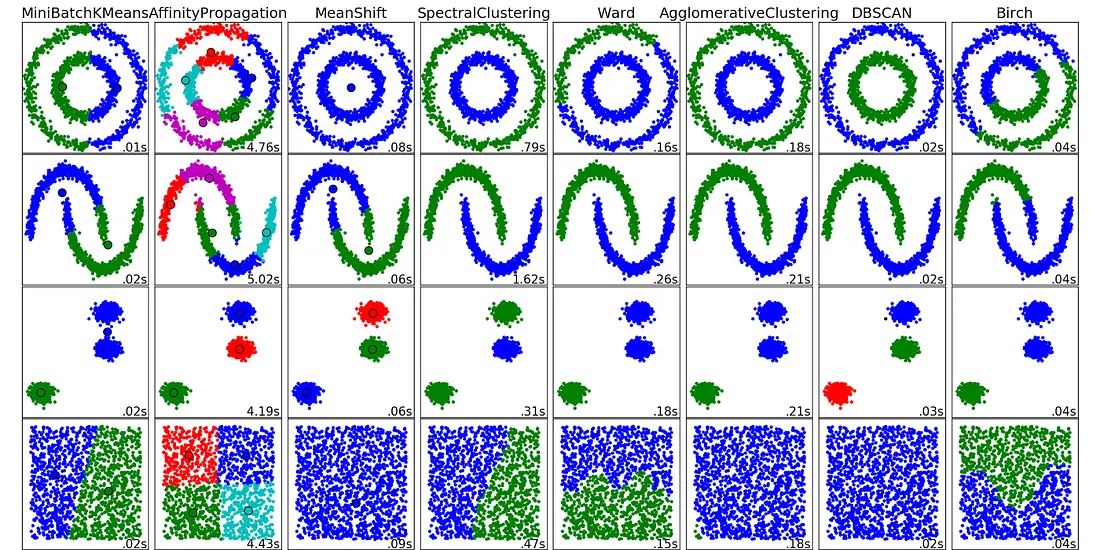
- [K-Means 聚类](#K-Means 聚类)
-
- [标准 K-Means 算法](#标准 K-Means 算法)
- [K-Means 评估:肘部法则(Elbow Method)与轮廓系数(Silhouette Score)](#K-Means 评估:肘部法则(Elbow Method)与轮廓系数(Silhouette Score))
-
- [1. 肘部法则(Elbow Method)](#1. 肘部法则(Elbow Method))
- [2. 轮廓系数(Silhouette Score)](#2. 轮廓系数(Silhouette Score))
- [DBSCAN 聚类(Density-Based Spatial Clustering of Applications with Noise)](#DBSCAN 聚类(Density-Based Spatial Clustering of Applications with Noise))
-
- [DBSCAN 的关键参数](#DBSCAN 的关键参数)
- [DBSCAN 算法](#DBSCAN 算法)
K-Means 聚类
K‑Means 聚类 是一种 无监督机器学习算法 ,通过 数据点的内在相似性 将其 分组为簇 。目标 是 将数据集划分为 k k k 个簇,使得每个簇内的数据点彼此之间的相似度高于与其他簇中的数据点的相似度。
不同于使用带标签数据进行模型训练的监督学习,K‑Means 适用于没有标签的数据,目标是发现隐藏的模式或结构。
例如,在线商店可以使用 K‑Means 将客户根据购买历史划分为"💰预算购物者""🛒常买者"和"💎大额消费者"等群体。
Wiki :k‑means 聚类是一种向量量化方法,最初来自信号处理,旨在将 n n n 个观测值划分为 k k k 个簇,使每个观测值属于与其最近均值(簇中心)最近的簇。k‑means 聚类 最小化簇内方差 (平方欧氏距离),而不是普通欧氏距离。
标准 K-Means 算法
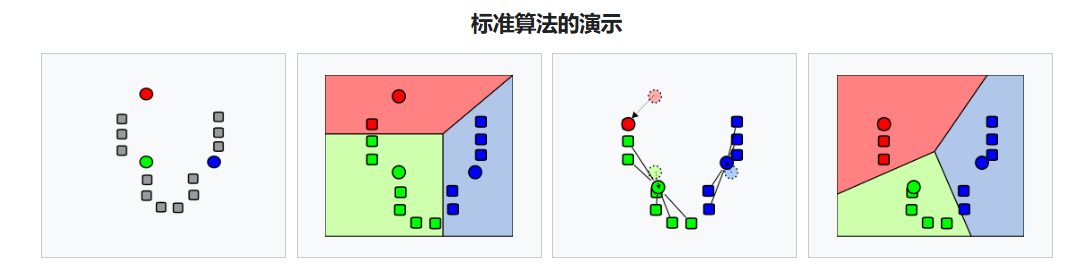
- 在数据域内 随机生成 k 个初始 "means" (此处 k = 3 k=3 k=3)
- 通过 将每个观测值与最近的均值关联 ,创建 k k k 个簇
- 每个 k k k 簇的质心 成为 新的均值
- 重复 步骤 2 和步骤 3,直至 收敛
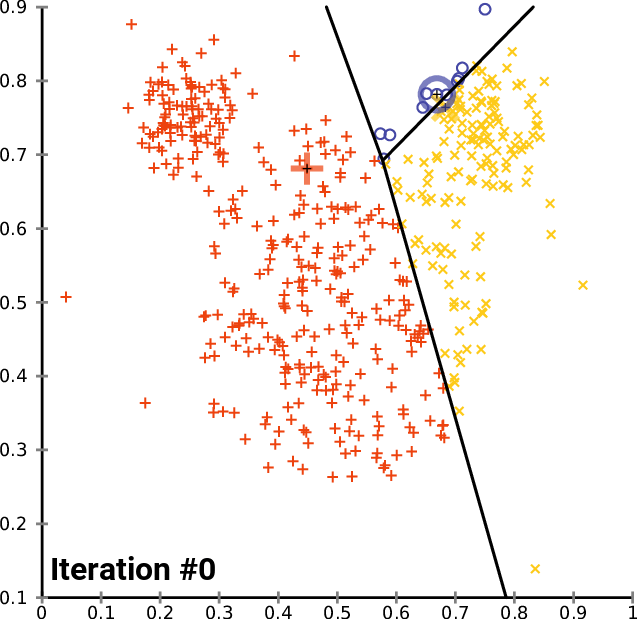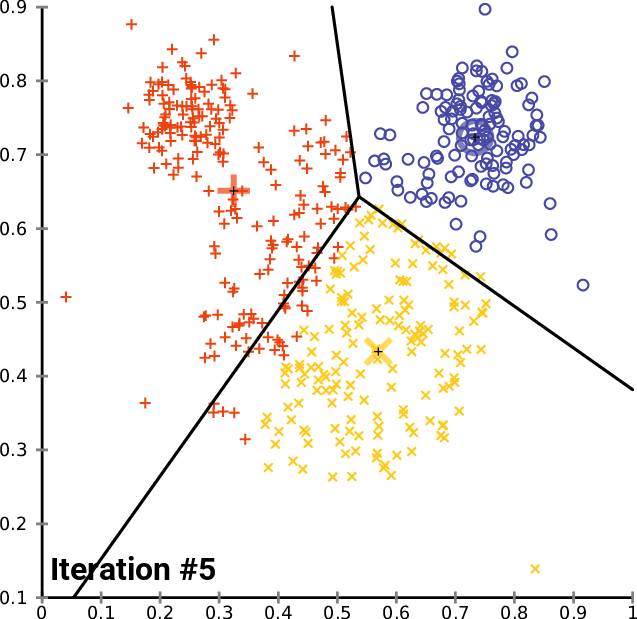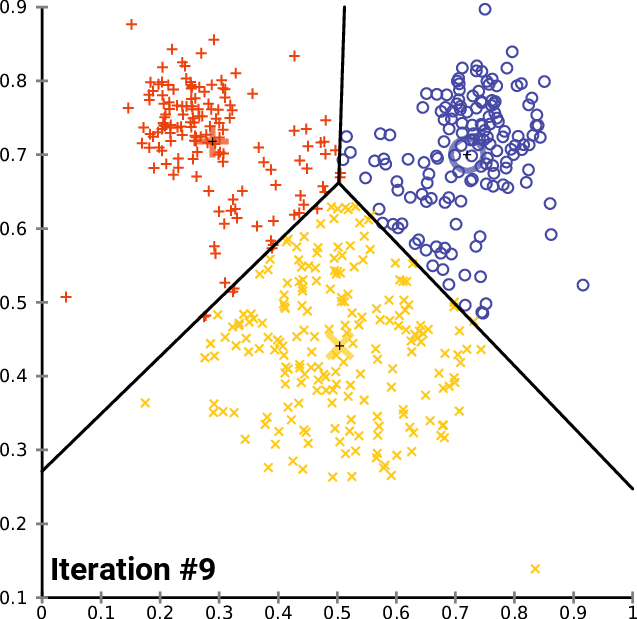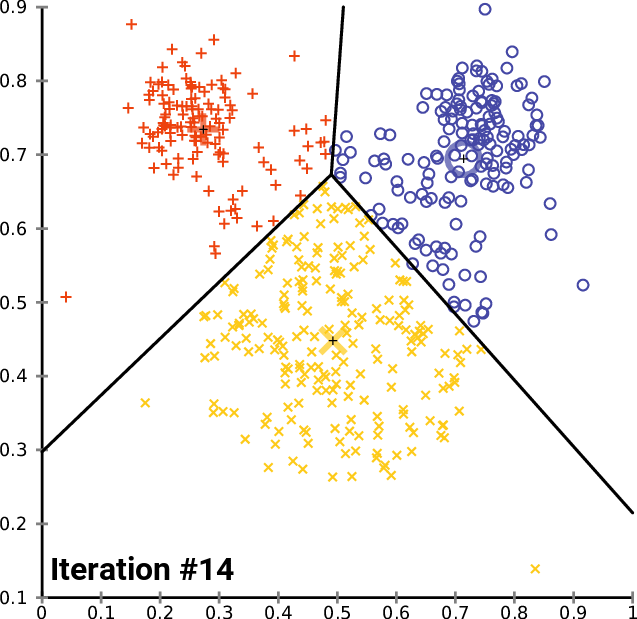
该算法并 不能保证收敛到全局最优解 ,结果可能取决于初始聚类。由于该算法通常很快,常会 在不同的初始条件下多次运行它。
常用的 初始化方法 有 Forgy 和 Random Partition,Forgy 方法倾向于 将初始均值分散开来 ,而 Random Partition 方法则 把初始均值全部放在数据集中心附近。
- Forgy 方法 从 数据集中随机选择 k k k 条观测 ,并将这些观测 作为初始均值。
- Random Partition 方法 首先 随机为每条观测分配一个簇 ,然后进入更新步骤,从而 将初始均值计算为该簇随机分配点的质心。
K-Means 评估:肘部法则(Elbow Method)与轮廓系数(Silhouette Score)
K-means 聚类简单,但 对初始条件和离群点敏感 。重要的是 优化中心点的初始化 以及 簇的数目 k k k,以获得最有意义的簇。实践中常结合如 "肘部法则 (Elbow Method)" 或 "轮廓系数(Silhouette Score)" 等指标来评估最佳簇数,可先用 肘部法则 做快速筛选(确定一个可能的范围,例如 k ∈ 2 , 10 k \in 2,10 k∈2,10),再用 轮廓系数 在该范围内做更精细的评估。
1. 肘部法则(Elbow Method)
核心思想 :肘部法则通过观察不同簇数 k k k 下的 簇内误差平方和(Within-Cluster Sum of Squares, 简称 WCSS 或 inertia) 随 k k k 的变化来选择合适的 k k k。
当 k k k 增加时,inertia 会下降(簇更细,点到质心距离减小 );在某个点以后,inertia 的 下降幅度会显著变小 ,图形看起来像 肘部拐点 ------ 那个"拐点"对应的 k k k 就是推荐的簇数。
常用指标是 KMeans 的 inertia_:
inertia = ∑ j = 1 k ∑ x i ∈ C j ∣ x i − μ j ∣ 2 \text{inertia} = \sum_{j=1}^{k}\sum_{x_i \in C_j} |x_i - \mu_j|^2 inertia=j=1∑kxi∈Cj∑∣xi−μj∣2
其中 μ j \mu_j μj 是簇 C j C_j Cj 的均值(质心)。
2. 轮廓系数(Silhouette Score)
核心思想 :轮廓系数衡量 单个样本 在其 所属簇内的紧密程度 与 与最近邻簇的分离程度 ,取值范围 − 1 , 1 -1, 1 −1,1。对整个聚类,用平均轮廓系数衡量聚类质量。
对样本 i i i:
- a ( i ) a(i) a(i) = 平均簇内 距离(样本 i i i 与同簇其它点的平均距离)
- b ( i ) b(i) b(i) = 与最近的其他簇 的平均距离(即 其它簇中到 i i i 的平均距离,取最小者)
- 轮廓系数:
s ( i ) = b ( i ) − a ( i ) max a ( i ) , b ( i ) s(i) = \frac{b(i) - a(i)}{\max{a(i), b(i)}} s(i)=maxa(i),b(i)b(i)−a(i)
s ( i ) ≈ 1 s(i) \approx 1 s(i)≈1:样本在自己簇内很好(紧密且远离其他簇); s ( i ) ≈ 0 s(i) \approx 0 s(i)≈0:样本在两个簇的边界上; s ( i ) ≈ − 1 s(i) \approx -1 s(i)≈−1:样本更像被错分到了当前簇。
对整个数据集常取 平均轮廓分数 s ˉ \bar s sˉ。阈值参考: s ˉ > 0.5 \bar s > 0.5 sˉ>0.5,聚类明显、良好; 0.25 < s ˉ ≤ 0.5 0.25 < \bar s \le 0.5 0.25<sˉ≤0.5,聚类尚可; s ˉ ≤ 0.25 \bar s \le 0.25 sˉ≤0.25,聚类效果差,可能不显著。
尽管 K-Means 在结构清晰、球状簇的数据上表现良好,但它存在一些局限:
-
必须 预先指定簇数 k k k
-
对 离群点和非凸形簇 表现不佳
-
聚类边界由 欧氏距离 决定,不适用于密度不均的数据
为了解决这些问题,出现了另一种 基于"密度" 的聚类算法------ DBSCAN。
DBSCAN 聚类(Density-Based Spatial Clustering of Applications with Noise)
DBSCAN 是一种 基于密度 的聚类算法,它 将紧密聚集在一起的数据点归为一类 ,并根据特征空间中的密度 将离群点标记为噪声。它将 簇 识别为数据空间中 密度较高的区域,这些高密度区域被密度较低的区域所分隔。
不同于假设簇是紧凑且呈球形的 K-Means 或层次聚类 ,DBSCAN 在处理现实数据的 不规则性方面表现良好,例如:
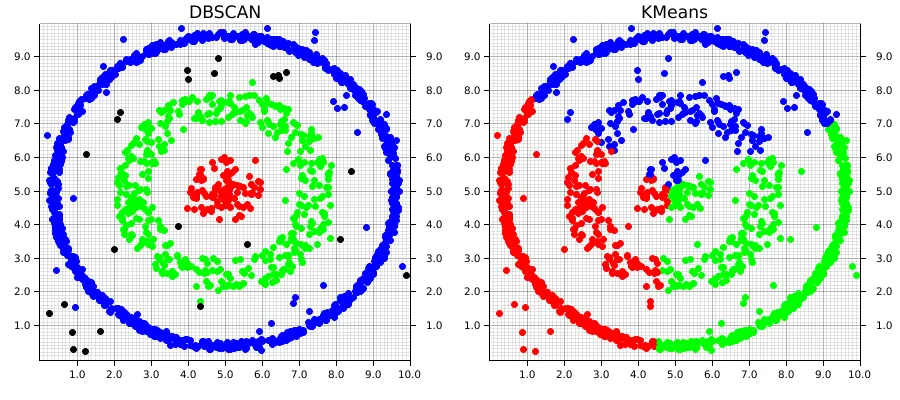
- 任意形状的簇:簇可以呈现任何形状,而不仅限于圆形或凸形。
- 噪声和离群点:它能够有效识别和处理噪声点,而不将其分配到任何簇。
DBSCAN 的关键参数
-
eps:这定义了 数据点周围邻域的半径 。如果两个点之间的距离小于等于eps,则它们被视为邻居。确定eps的常用方法是分析 k-distance 图。选择合适的eps很重要:如果eps设得太小,大多数点会被归类为噪声;如果eps设得太大,簇可能会合并,算法可能无法区分它们。 -
MinPts:这是 在eps半径内形成致密区域所需的最少点数 。一个常用经验法则是将MinPts设置为≥ D+1,其中D是数据集的维度数。在大多数情况下,建议将MinPts的最小值设为 3。
DBSCAN 算法
DBSCAN 通过 将数据点划分为三种类型 来工作:
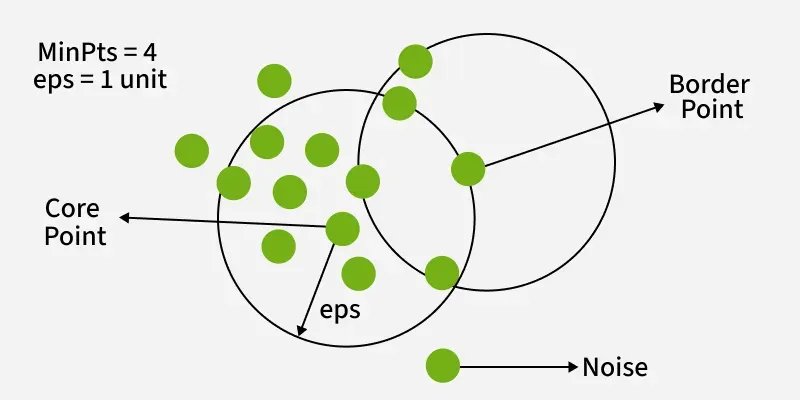
- 核心点 是指在指定半径(epsilon)内拥有 足够数量邻居 的点;
- 边界点 靠近核心点,但自身缺乏足够的邻居,无法成为核心点;
- 噪声点 不属于任何簇。
通过 从核心点迭代扩展簇并连接密度可达点,DBSCAN 在不依赖于其形状或大小的严格假设的情况下形成簇。
DBSCAN 算法步骤 :
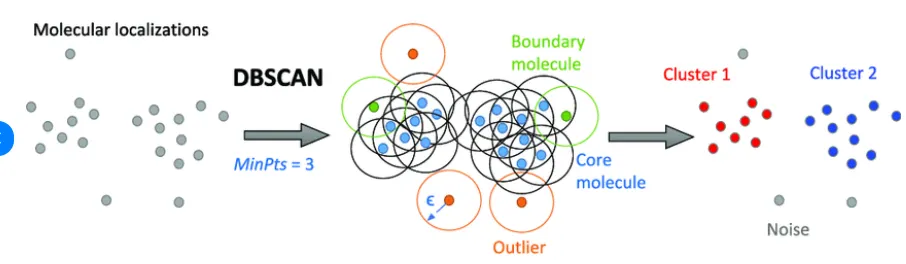
- 标识核心点 :对数据集中每个点,统计其
eps邻域内的点的数量 。如果该计数达到或超过MinPts,则将该点标记为核心点。 - 形成簇 :对每个 尚未分配到任何簇的核心点 ,创建一个 新簇 。递归地寻找所有密度相连的点,即位于该核心点
eps半径内的点,并将其加入簇中。 - 密度连通性 :如果 存在一个点链 ,使得链中的每个点都位于下一个点的
eps半径内,并且链中至少有一个点是核心点,则点 a a a 与点 b b b 是密度连通的。此链式过程确保簇中的所有点都通过一系列密集区域相连。 - 标记噪声点:在处理完所有点后,任何不属于簇的点都被标记为噪声。