引言(Introduction)
本章将深入解析实时(real-time)模式,并让读者熟悉如何用该模式构建解决方案。内容涵盖实时模式可解决的用例;同时讨论如何使用开源技术设计实时系统,并通过示例应用与代码片段加以演示。此外,还将介绍实时模式在真实场景中的应用实例。
结构(Structure)
本章涵盖以下主题:
- 实时系统的用例
- 实时系统的设计
- 实时系统的技术选型
- 真实案例
目标(Objectives)
在本章结束时,你将对实时模式有深入理解;你也能够基于实时模式设计并构建数据管道,并编写代码实现该设计。你将了解应选择的技术栈,以及如何将各组件"缝合"起来,搭建端到端的管道。最后,你还将理解哪些真实业务场景适合采用该模式,并看到来自支付 与电商行业的示例。
实时系统的用例(Use cases for real-time systems)
实时模式适用于多种场景:从构建实时分析 数据管道到机器学习实时打分(ML scoring) 。与批处理系统不同,实时系统在数据到达时持续处理 ,实现低延迟的处理与即时洞察/动作;而批处理系统在预定时间窗口内成批处理大量数据,延迟更高,更适合历史分析与报表。以下是适合实时模式的一些用例。
实时分析的数据管道(Pipelines for real-time analytics)
实时分析系统在上游事务系统产生数据的当下 即刻摄取,并在数据生成后立刻进行分析。这类系统对需要事件一发生就采取行动 的场景至关重要,而不是等事件被攒成批次后再处理。典型领域包括欺诈检测、物流、库存管理等。
以欺诈检测为例:关键在于发生时就阻断 欺诈,因此用于识别欺诈的数据必须实时可用;依赖批处理等会引入延迟的方式不可行。
通常,实时系统的构建难度高于批处理系统:它需要能在实时中进行消息传递并提供投递保障 的技术。Apache Kafka 已被证明是构建实时数据管道的高性能、可靠的消息系统,并围绕其形成了丰富生态,为主流数据源与数据汇提供连接器。
考虑一个使用 Web 或移动应用点击流(clickstream)的实时分析系统。点击流记录用户的导航轨迹:浏览的页面、点击的按钮、注册行为、看到的广告等。对点击流进行实时分析可以识别用户在网站/应用中的行为,并据此在用户仍停留在页面时推送推荐或优惠,实现即时定向广告,从而显著提升转化率。
该系统的关键挑战在于:点击流需在生成时即可用于分析 以产出合适的推荐/优惠;并且一旦生成推荐/优惠,需实时回传 至应用侧展示给用户。Apache Kafka 可通过不同 topic 同时支持这类双向/双通道通信。
下图给出了利用 Kafka 处理点击流信息的系统架构(图 4.1):
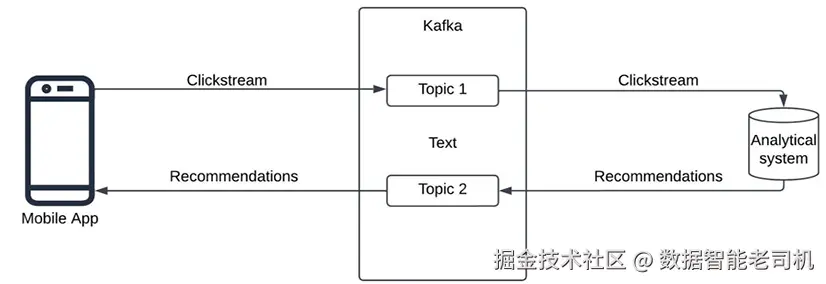
图 4.1:基于 Kafka 的点击流分析(Clickstream analysis with Kafka)
高可用性的变更数据捕获(Change data capture for high availability)
关键任务型(mission-critical)应用的数据库需要始终可用 ,即使在自然灾害等可能导致机房中断的场景下亦然。为实现这种高可用性,需要将主库 的数据实时 传播到从库/备库 。备库通常部署在异地的数据中心。
主从间的数据变更传播有多种方式。一些数据库(如 Couchbase )在数据库内部原生支持从主库到备库的实时变更流 。即便数据库未内建该能力,也可结合**数据库事务日志(change/transaction logs)**与可靠的消息传递框架(如 Apache Kafka)来实现。
具体做法是:几乎所有数据库都会生成事务日志 ,以预定义格式记录数据库中的变更。这些日志可被读取并处理,用于将变更传播到备库。Kafka 提供了可读取这些事务日志并将其推送为消息到 Kafka 的源连接器 ;随后由汇连接器 消费消息,并在目标数据库端将其转换为相应的 INSERT/UPDATE/DELETE 语句。一旦这些语句应用到目标备库,备库即可与主库保持同步。根据需求,备库可以与主库在同一区域(仅高可用)或异地区域(同时支持灾难恢复)。
下图展示了利用变更日志捕获构建数据库高可用的系统设计(图 4.2):
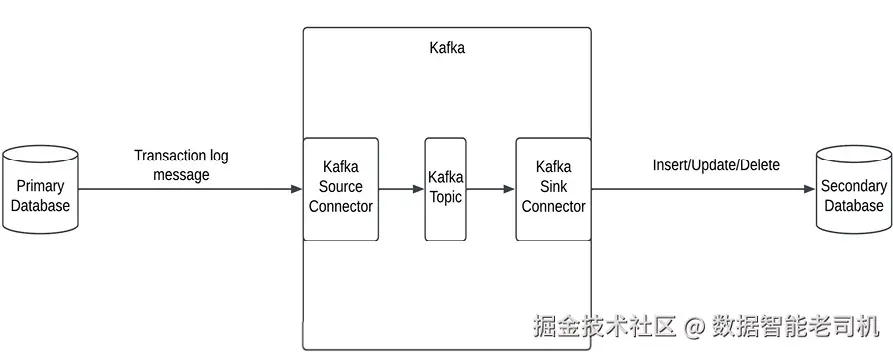
图 4.2:基于变更日志捕获的高可用架构(High availability using change log capture)
实时机器学习打分(Real-time ML scoring)
实时 ML 打分要求在极低延迟 下生成预测分数,以便系统能据此立即采取行动 ,从而预防 问题发生。相较于事后检测,实时打分能在问题扩大前阻断或缓解,因而已广泛应用于多个行业,如:工厂设备故障预警、支付与银行欺诈识别、库存缺货预测、网络安全攻击预警等。
以网络安全 为例:任何系统行为都可通过一组参数来度量;在正常运行时,这些参数处于可接受范围(即遥测数据,telemetry )。在网络攻击期间,许多参数会出现异常偏移。用这些遥测数据作为特征训练的 ML 模型,在持续输入 当前遥测数据进行打分时,能够预测/识别异常。例如,系统在一定时间窗口内的网络活动与内存使用具有特定模式;模型可用长期收集的数据训练,然后用当前值进行异常分数推断。
构建这类实时异常检测框架分两步:
- 模型训练数据收集 :从各源系统收集遥测信息(如 SAR 指标、操作系统日志、网络日志 等),通过 Apache Kafka 等流式平台写入离线特征库 ;对原始数据进行特征工程,提取特征并训练模型。
如下图所示(图 4.3):
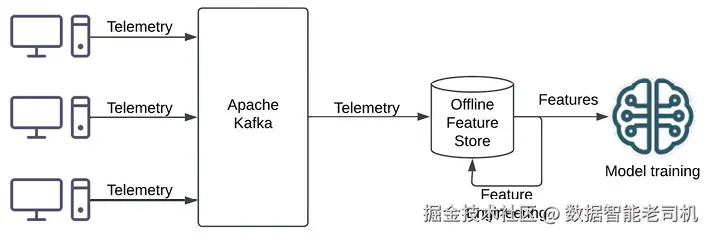
图 4.3:基于遥测数据的模型训练(Model training on telemetry data)
- 在线推理与告警 :将训练好的模型部署到推理服务 以进行低间隔打分;打分所需的特征从在线特征库 读取以确保低延迟;最后基于打分结果触发潜在网络攻击的告警与处置。
如下图所示(图 4.4):
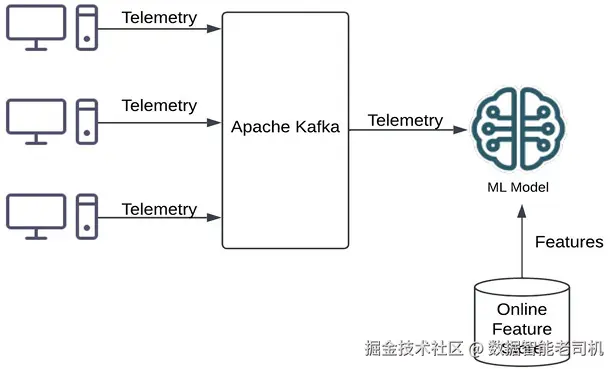
图 4.4:基于遥测数据的在线推理(Online inferencing on telemetry data)
设计实时系统(Designing a real-time system)
本节我们设计一个实时分析系统 :从基于文档的 NoSQL 事务系统摄取数据,导入到分析系统中,并由分析系统驱动实时看板 。相较于在关系型数据上做实时分析,在文档型 NoSQL 上做实时分析会面临更多挑战,这些挑战因文档数据模型的无模式(schema-less)特性而加剧。为在文档数据模型上构建实时系统,我们需要能够对文档数据执行分析的专用技术 。在本示例中,我们使用 MongoDB 作为事务系统,使用 Couchbase 作为实时分析的分析系统。
要在 JSON 文档数据上实现实时分析,我们需要具备以下能力的系统:
- 列式存储(Columnar storage) :查询时只读取所选列,避免扫描所有列,加速检索。列式存储是各类分析系统的首选,可显著降低 I/O 开销。市面上主流分析系统(从 Oracle Exadata、AWS Redshift 到 Snowflake)均采用列式存储。
- 大规模并行处理(MPP) :将单条查询并行分发到多台服务器执行,缩短查询耗时,从而逼近实时分析。在无明显 I/O 等瓶颈时,MPP 通过横向扩展计算资源可获得近线性扩展性。
- 基于 SSD 的缓存存储:SSD 缓存提供更快的数据访问,进一步降低查询时延。相较于机械盘,SSD 具备数量级更高的 IOPS 与更低的延迟。
- 智能基于成本的查询优化器(CBO) :将次优的用户查询自动重写为高效的执行计划。优化器基于复杂代价模型在多个候选计划中挑选最优方案,减少人工调优,即便是机器生成的次优 SQL 也能转化为高效计划。
- 模式灵活性(Schema flexibility) :MongoDB 存储 JSON 文档,模式灵活,文档间模式可变,且可包含嵌套文档与数组。将 JSON 建模为"行列式"的关系表既复杂又难以实时完成。要对 MongoDB 中的数据做分析,分析系统本身也需要具备无模式能力。
实现方案步骤如下:
- 创建 Apache Kafka 集群,并在集群中创建 topic,用于承载从 MongoDB 迁移到 Couchbase 的数据。
- 在 MongoDB 上启用 副本集(replica set) ,以便执行变更数据捕获(CDC)并将变更推送到 Kafka。
- 部署 MongoDB Source Kafka Connector,把 MongoDB 的数据写入 Kafka topic。
- 在 Couchbase 集群中创建 Kafka link,配置 Kafka 集群与 topic 信息。
- 连接该 Kafka link,启动从 MongoDB 到 Couchbase 的数据传输。
下图展示了一个利用 Couchbase 与 Apache Kafka 对 JSON 数据进行实时分析的数据系统架构(图 4.5):
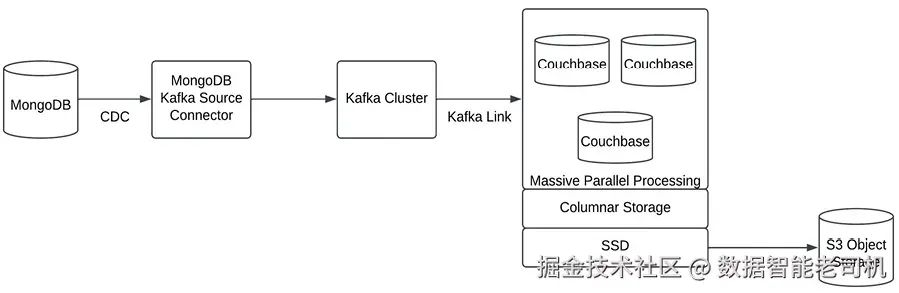
图 4.5:基于 Couchbase 的实时 JSON 分析(Real-time JSON analysis with Couchbase)
实时系统的技术选型(Technologies for real-time systems)
如本章所示,实时系统有两个关键特征:
- 以流式方式(而非成批)实时处理数据;
- 为处理提供极低延迟 的数据访问。
要实现上述目标,需要两大技术栈:流式处理 与数据存储/服务层。
在高吞吐、低延迟 的流式场景中,消息/流处理技术如 Apache Kafka 、Apache Flink 与 Spark Structured Streaming 非常流行。其中 Kafka 因其对各类源与汇系统提供丰富连接器而最为常用;Kafka 提供**至少一次(at-least-once)**投递语义,在很大程度上简化了实时应用的开发。
表 4.1 概述了 Apache Kafka、Apache Flink 与 Spark Structured Streaming 的最适配用例。
实时系统在存储与服务 层通常选用能提供高吞吐、低时延 访问的数据库。诸如 Redis、Couchbase、Aerospike 在实时系统中颇为常见,因为它们可为处理提供极快的数据访问。
- 若实时系统处理的数据量较小、可完全驻留主内存,则可优先考虑 Redis 这类内存型缓存数据库。
- 若数据规模更大,需要既能从主内存快速服务、又需持久化到二级存储 ,则更适合选择 Couchbase 这类带集成缓存的持久化存储。
参考下表:
表 4.1:技术与用例匹配
| 技术(Technology) | 工作负载类型与用例(Workload type & use case) |
|---|---|
| Kafka | 低毫秒级延迟;事件采集;消息传递;数据集成 |
| Flink | 低到中等毫秒级延迟;事件处理;实时事件分析 |
| Spark Structured Streaming | 高毫秒至秒级延迟;近实时数据管道;实时 ETL |
真实世界示例(Real-world examples)
本节讨论信用卡支付反欺诈 与游戏行业 中的若干真实案例,展示实时模式如何帮助数据系统在事件发生当下采取行动,而非延后处理。对这两类系统而言,能够在事件触发时即刻响应至关重要。本节同样说明:我们日常交互的系统中,实时模式早已深度嵌入其中。
支付反欺诈(Payment fraud detection)
在任何数字支付系统中,防范欺诈对保护消费者免受财务损失至关重要。欺诈必须在发生时即被识别并阻断,而不是事后再处理。实时系统在支付反欺诈中发挥关键作用:交易在进行中就需要被实时评估,同时又不能让用户感知到支付延迟。
反欺诈通常借助 ML 模型 完成:模型会对入站交易进行风险打分。若分数较高,交易将被拦截或触发与用户确认的工作流;若分数较低,则允许交易完成。
为了在实时 中完成打分,系统需按如下流程运作:用户发起交易后,支付网关处理请求,并通过 Kafka 等消息总线将交易详情发送至 ML 平台 进行打分。在 ML 平台中,首先从在线特征库(online feature store)提取与该交易相关的特征。在线特征库是一种具有极低延迟 服务能力的数据存储,持有模型打分所需的全部特征,使特征可即时用于推断。可选工具包括 Tecton 与 Feast。特征示例:用户常住地、用户平均交易金额、交易频率等。基于这些特征,ML 模型为交易生成欺诈分数。
下图展示了该反欺诈系统的组件(图 4.6):
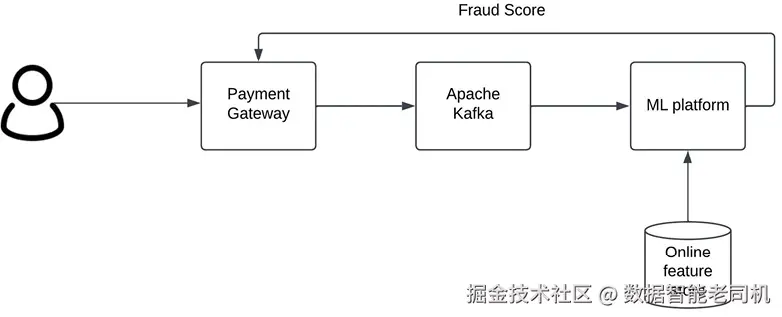
图 4.6:实时反欺诈(Fraud detection in real-time)
游戏(Gaming)
实时系统在游戏行业被广泛使用,以支撑多种场景。无延迟的丰富交互体验是优质游戏(如 PUBG、Fortnite)的基石。为达此目标,游戏行业高度依赖实时系统。
以下列举实时系统在游戏中的应用示例:
- 多人联机 :需要快速同步各玩家的操作,确保互动体验。一名玩家的行为(如选定武器、射击)必须实时 对其他玩家可见。任何反映延迟都会破坏体验,影响游戏成败。为实现该实时体验,游戏会使用 Couchbase 等数据库以获得超低延迟的数据服务。
- 个性化体验 :许多游戏会依据玩家的水平、偏好、行为与购买记录进行个性化定制。要在实时 中完成个性化,系统需实时采集并分析玩家偏好与行为。常见做法是使用 Apache Flink 与 Kafka 进行实时数据流处理,并采用 Redis、Couchbase 等数据库作为存储与服务层。
下图展示了基于 Apache Kafka 与 Couchbase/Redis 缓存构建的实时游戏系统架构(图 4.7):
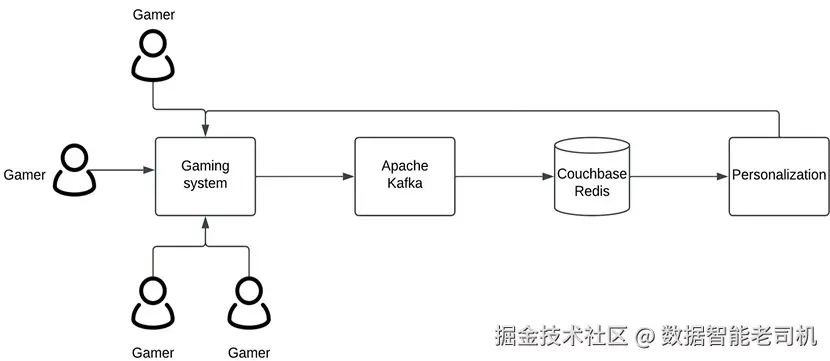
图 4.7:实时游戏系统(Real-time gaming system)
结语(Conclusion)
本章介绍了实时系统的一些常见用例,并设计了一个将 MongoDB 中的 NoSQL 事务数据迁移到类似 Couchbase Columnar 的分析型 NoSQL 系统的实时 方案;我们看到该设计如何借助 Apache Kafka 落地实现。同时,我们讨论了银行与零售媒体领域的实时系统示例,理解了这些案例的高层架构;并回顾了实时系统常用的技术栈及其应用。
下一章将讲解**批处理(batching)设计模式,并回顾各领域中采用微批(micro-batching)**的系统用例与真实案例。