金融 - 图谱挖掘工作流 调研
- 背景
- [1. 基于确定的一堆知识信息构建知识图谱,是否具备唯一性?如果不具备,那么,影响的变量有哪些?](#1. 基于确定的一堆知识信息构建知识图谱,是否具备唯一性?如果不具备,那么,影响的变量有哪些?)
- [2. 构建金融领域的图谱挖掘工作流,是什么样的定位?应如何站在巨人的肩膀上?巨人有哪些?](#2. 构建金融领域的图谱挖掘工作流,是什么样的定位?应如何站在巨人的肩膀上?巨人有哪些?)
背景
尝试了从免费论文库中免费下载pdf格式论文,并基于论文堆提取信息后,利用大模型的提示构建知识图谱。遇到较大阻力,难以成功。有可能是提示词模板没构建好。
基于这些尝试后,认为,单凭自己的经验,试错时间成本太高,还是尽可能站在巨人的肩膀上。
先了解几个问题:
1. 基于确定的一堆知识信息构建知识图谱,是否具备唯一性?如果不具备,那么,影响的变量有哪些?
答 :知识图谱并不是 对一堆信息机械、唯一 的映射 结果。同一组信息,完全可能构建出多个不同的知识图谱。其最终形态高度依赖于建模目标、语义抽象深度、唯一性规则、数据处理方式 以及技术选型 。
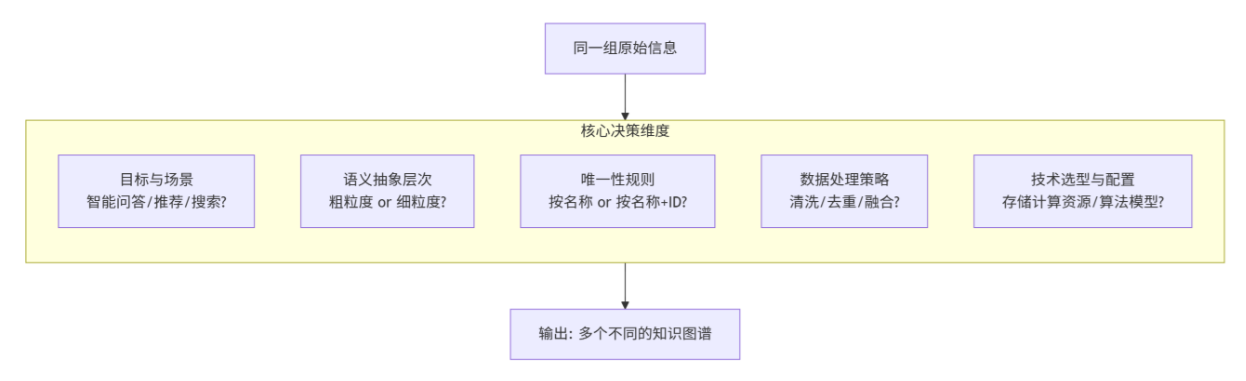
(1) 建模目标与应用场景
你希望图谱回答什么问题,直接决定了需哪些实体、关系及它们的详细程度。
示例:同样是处理电影数据,如果你的目标是影片推荐 ,图谱可能会重点关注"电影"、"类型"、"演员"、"导演"等实体,并包含"评分"、"用户偏好"等属性。但如果目标是分析电影投资 ,图谱则可能需要加入"制片公司"、"投资额"、"票房"等实体和属性,甚至"导演"与"制片公司"的"合作次数"等关系。
(2)语义抽象与层次结构
这是知识建模的核心 ,即你如何理解和定义现实世界中的事物 及其关联 。
实体粒度 :对于"苹果",你可以将其定义为一個实体 实体: 苹果 (类型: 水果),也可以根据场景细分为 实体: 红富士苹果 (类型: 苹果品种)和 实体: 嘎拉苹果 (类型: 苹果品种),并将它们与"水果"这个上位词关联。
关系 定义:"A为B工作"这种关系,既可以简单抽象为 EMPLOYED_BY(A, B),也可以细化为 CURRENTLY_EMPLOYED_BY(当前雇佣)和 PREVIOUSLY_EMPLOYED_BY(曾经雇佣),这取决于你对时间维度和历史信息的需求。
(3) 唯一性规则 与身份解析
这是确保知识图谱一致性 的基石,是同一数据产生不同图谱的常见原因。
规则制定:如何判断两个名称指的是否是同一实体?例如,数据中出现的"MIT"和"Massachusetts Institute of Technology"必须被识别并合并为同一个"麻省理工学院"实体。反之,同名不同指的实体(如"苹果公司"和"苹果(水果)")必须被区分开。这个判断过程就是实体链接。
不同选择的影响:如果唯一性规则设置不同,有的图谱可能将"B(aa,600)"和"B(aa,700)"视为同一实体的两个属性,而另一套规则可能根据ID不同将其判定为两个不同的实体,这直接改变 了图谱的节点 和连接结构 。
(4)数据处理与知识融合策略
原始数据充满噪声、重复和不一致。如何清洗、转换和集成这些数据,直接影响图谱的质量和内容。
策略差异:不同数据清洗(如处理异常值、去噪)、实体对齐(判断不同来源的"纽约"是否指同一城市)和冲突解决(一个来源说某人生于1960年,另一个说是1961年,以哪个为准?)策略,会产出不同纯净度和一致性的知识图谱。
(5)技术选型与资源配置
虽然不像前几点那样直接决定语义,但技术和资源限制了你能构建多大规模和深度的图谱。
工具与算法:使用不同的关系抽取模型(如基于规则的方法、机器学习模型或深度学习模型),从同一段文本中抽取出的实体和关系在数量和准确性上可能会有差异。
计算资源:强大的计算资源(如高端GPU)可以处理更大规模的数据、运行更复杂的模型,从而有可能构建出更庞大、更精细、更准确的知识图谱。
(6)小结
知识图谱并非原始数据的"唯一正确"呈现,而是一个高度依赖于构建目的、语义理解和技术选择的、对世界的某种解释模型。因此,为同一堆信息构建多个不同侧重点的知识图谱不仅是可能的,有时甚至是必要的,以满足不同的应用场景和分析需求。
构建可靠知识图谱的建议
A、定义清晰目标:始终明确图谱要解决什么问题,这将指导所有后续决策。
B、设计严谨的Schema:精心设计实体、关系和属性,这是图谱的蓝图。
C、制定一致的唯一性规则:明确实体身份解析的规则,并始终坚持,这是保证质量的关键。
D、迭代和验证:知识图谱的构建是一个迭代过程。用典型问题测试它,并根据反馈不断完善Schema和数据。
2. 构建金融领域的图谱挖掘工作流,是什么样的定位?应如何站在巨人的肩膀上?巨人有哪些?
(1)服务目标对象
A、AI时代有就业需求无方向规划有效信息的人群,包括:要转业待业的学士硕士博士;想要进行清晰未来规划的大学在校生、高中生甚至中小学生。
逻辑:AI时代必然伴随科技的进一步大发展,科技的最显著特点是颠覆。社会化大生产相关的就业市场,AI时代必伴随着越来越频繁的颠覆性重构(体现在各个层次,包括岗位职能、公司、行业、区域),技能需求剧变与"颠覆"成为新常态。同时,AI在替代部分岗位,也在创造大量新职业和新工作模式,人工智能训练师、AI算法工程师、数据科学家等创新型工作形态正在涌现。
超级个体基于AI的支持,逐步成为社会生产主要生产力形态。但并非每个人都适合成为超级个体。
这个渐变过程,无疑会持续带来巨大压力和焦虑。而伴随的是,一个同样持续扩大的信息鸿沟。简单粗暴的学历至上规则渐次被打破,技能与AI是否能有效互补,成为个人就业寿命的关键。
这种情形一直持续,直到绝大多数人类无法跟上步伐。社会化大生产,最终切割出一个ASI自博弈的游戏,这与大多数人无关
这条路径目前看起来,必然发生。AI带来的未来并非注定是"取代人类"的零和游戏,而更可能是一场艰难且充满不确定性的转型。而人群需要有效信息去拥抱人机协作的新模式。
B、AI时代需要深度有效价值信息的投资人群,包括:个人、机构、各级政府。
无论是否进入AI时代,投资人群都需要深度有效的实时价值信息。
C、创投
颠覆加速,意味着,危与机。抓住机会就能实现百万倍的创投资产变现。
(2)技术路线与要素
" 知识图谱 + 图知识库 + LLM + 多智能体 + 交互协议" 的技术路线是当前研究信息挖掘的必然选择。
知识图谱 结构化表示实体和关系,在信息挖掘中提供高效语义查询和推理能力。
结合Cypher 查询和GDS(Graph Data Science ),可实现复杂关系挖掘。
图知识库 (如Neo4j )为知识图谱提供存储和计算支持,是信息挖掘的核心基础设施。
LLM 擅长处理非结构 化文本,提取实体、关系和语义信息,可为知识图谱提供动态内容填充。
多智能体 系统通过分工协作,提高信息挖掘的效率和模块化能力,擅长解决复杂 问题。
标准化的交互协议 (如REST API、GraphQL或Agent间通信协议)确保系统组件间高效协作,支持分布式信息挖掘和实时更新,便于快速扩展和无缝融入全球分工协作 。
学术研究(如Google Scholar、Semantic Scholar)广泛采用KG和LLM结合的架构,用于文献推荐和关系挖掘。产业中,企业的知识管理平台(如IBM Watson)也依赖类似技术栈,验证了其可行性。
(3)会遇到的一些问题
A、LLM 的输出可能与KG 的模式不一致,需额外的实体对齐 和清洗。
B、LLM 和GDS分析 对硬件要求 高,可能超出个人或小型团队的计算能力。
C、多智能体间 的交互协议 可能因缺乏统一标准导致兼容性 问题,增加开发成本。
D、信息挖掘效果依赖输入数据质量 。例如,免费资源库(如arXiv)可能存在元数据不完整或PDF格式不规范的问题,影响LLM提取和KG构建。
E、多智能体协作 可能因任务分配 不当导致效率低下。
F、LLM的"黑盒"特性 可能导致提取的实体/关系不可靠 ,需人工验证或后处理,增加维护成本。
G、长期维护KG需要动态更新机制,否则可能因数据陈旧降低实用性。
H、该技术路线在学术文献挖掘中表现良好,但在其他领域(如社交媒体、实时新闻)可能需调整。
(4)巨人有哪些?
A、findpapers或paperscraper进行关键词搜索和PDF下载;
B、MinerU解析PDF;
C、llm-graph-builder将解析结果存入Neo4j(KG+图知识库);
D、多智能体可分工处理搜索(findpapers)、提取和图谱构建,交互协议(如APOC插件)连接各模块;
E、图知识库管理:利用Neo4j的模式约束(如CREATE CONSTRAINT ON (p:Paper) ASSERT p.title IS UNIQUE)确保KG一致性;定期运行GDS算法(如Louvain社区检测)发现研究领域集群。
F、开源工具(如pdf2doi)验证PDF的DOI,确保引文关系的准确性;
G、开发可视化界面(如Streamlit或Gradio),允许用户通过GUI输入关键词、查看KG结构,降低技术门槛。
H、AutoGen(microsoft/autogen):多智能体框架,支持LLM驱动的任务分配,适合协调搜索、提取和图谱化。LangChain(langchain-ai/langchain):提供LLM与外部工具的集成,适合连接MinerU和Neo4j。
I、APOC库(Neo4j官方扩展):支持JSON导入和复杂Cypher操作,简化LLM输出到KG的转换。