DISCOG:知识图谱+LLM双引擎驱动的法律电子取证系统
一句话总结 :DISCOG将法律文档检索问题转化为知识图谱上的链接预测任务,结合GNN和LLM推理,在真实部署中实现了98%的成本节约。
📖 论文信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Learning from Litigation: Graphs and LLMs for Retrieval and Reasoning in eDiscovery |
| 作者 | Sounak Lahiri, Sumit Pai, Tim Weninger, Sanmitra Bhattacharya |
| 机构 | Deloitte(德勤)、University of Notre Dame(圣母大学) |
| 发表会议 | ACL 2025 Industry Track |
| 论文链接 | arXiv:2405.19164 |
🎯 1. 研究背景:法律文档审查的"大海捞针"困境
1.1 什么是电子取证(eDiscovery)?
想象一下这个场景:一家大型企业正在进行诉讼,法院要求双方提交所有与案件相关的文档。问题是,这家企业有数百万封邮件、合同、内部通讯等电子文档。如何从这座"文档山"中找出真正相关的那几千份?
这就是 电子取证(eDiscovery) 要解决的核心问题。它是法律诉讼中识别、收集、审查电子证据的关键流程。
| 挑战维度 | 具体问题 | 实际影响 |
|---|---|---|
| 📚 文档规模 | 单案可涉及100万+文档 | 人工审查成本可达数百万美元 |
| 🏛️ 法律实体识别 | 案件引用、法规编号等专业术语 | 通用NER模型识别效果差 |
| 🔗 复杂引用关系 | 法律文档间的多级引用链 | 传统向量检索难以捕捉关联 |
| 📝 上下文依赖 | 法律术语的语境含义 | 脱离上下文易误判相关性 |
1.2 现有方法为何"水土不服"?
传统的 技术辅助审查(TAR) 方法主要依赖:
- BM25等关键词检索:只看字面匹配,无法理解语义
- BERT等语言模型 :虽能理解语义,但忽略了法律文档间的结构化关系
举个例子:如果一份邮件提到了"Smith v. Jones案",而这个案件引用了"15 U.S.C. § 78j"法规,传统方法很难自动建立这种引用链关系。
🏗️ 2. DISCOG系统架构:图谱+LLM的双重增强
2.1 整体框架
DISCOG的核心思想是:将文档相关性判断转化为知识图谱上的链接预测问题。
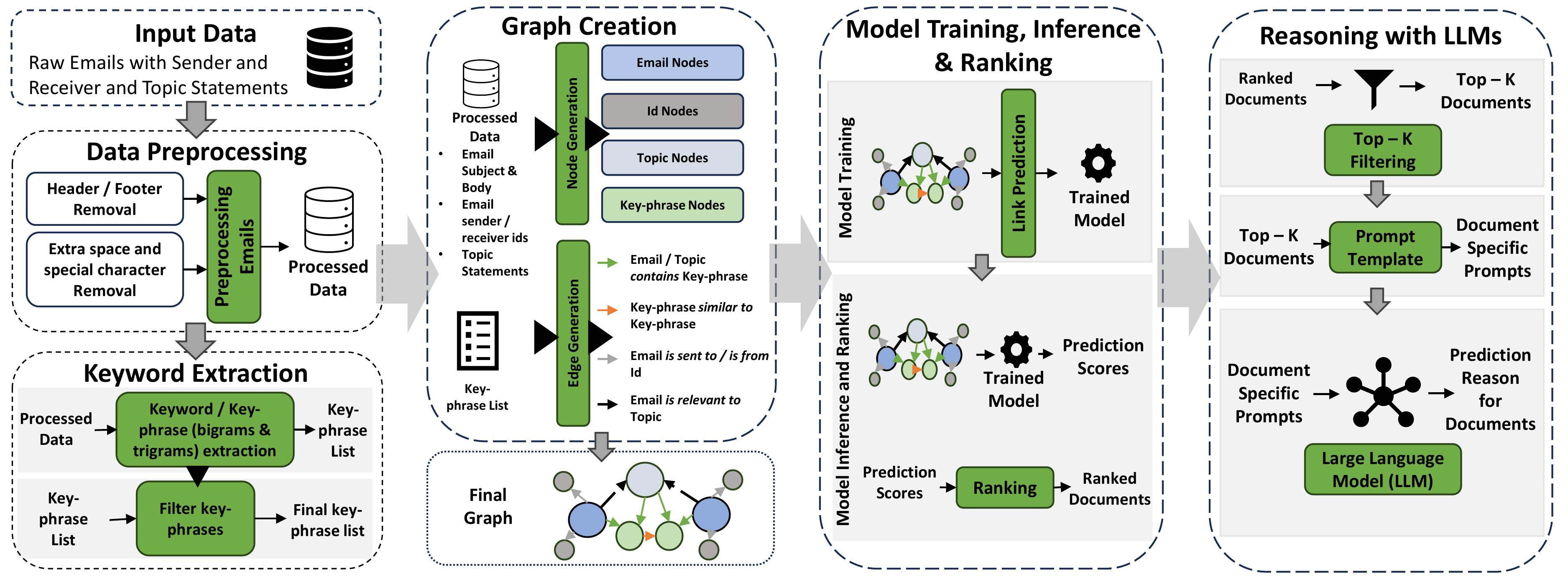
图1:DISCOG系统框架------从文档集合到知识图谱构建,再到图增强检索和LLM推理的完整流程
整体流程可以概括为四个阶段:
📄 文档集合 → 🕸️ 知识图谱构建 → 🔍 图神经网络预测 → 🤖 LLM推理验证2.2 知识图谱构建:把文档变成"关系网"
DISCOG构建的是一个异构知识图谱,包含四种类型的节点:
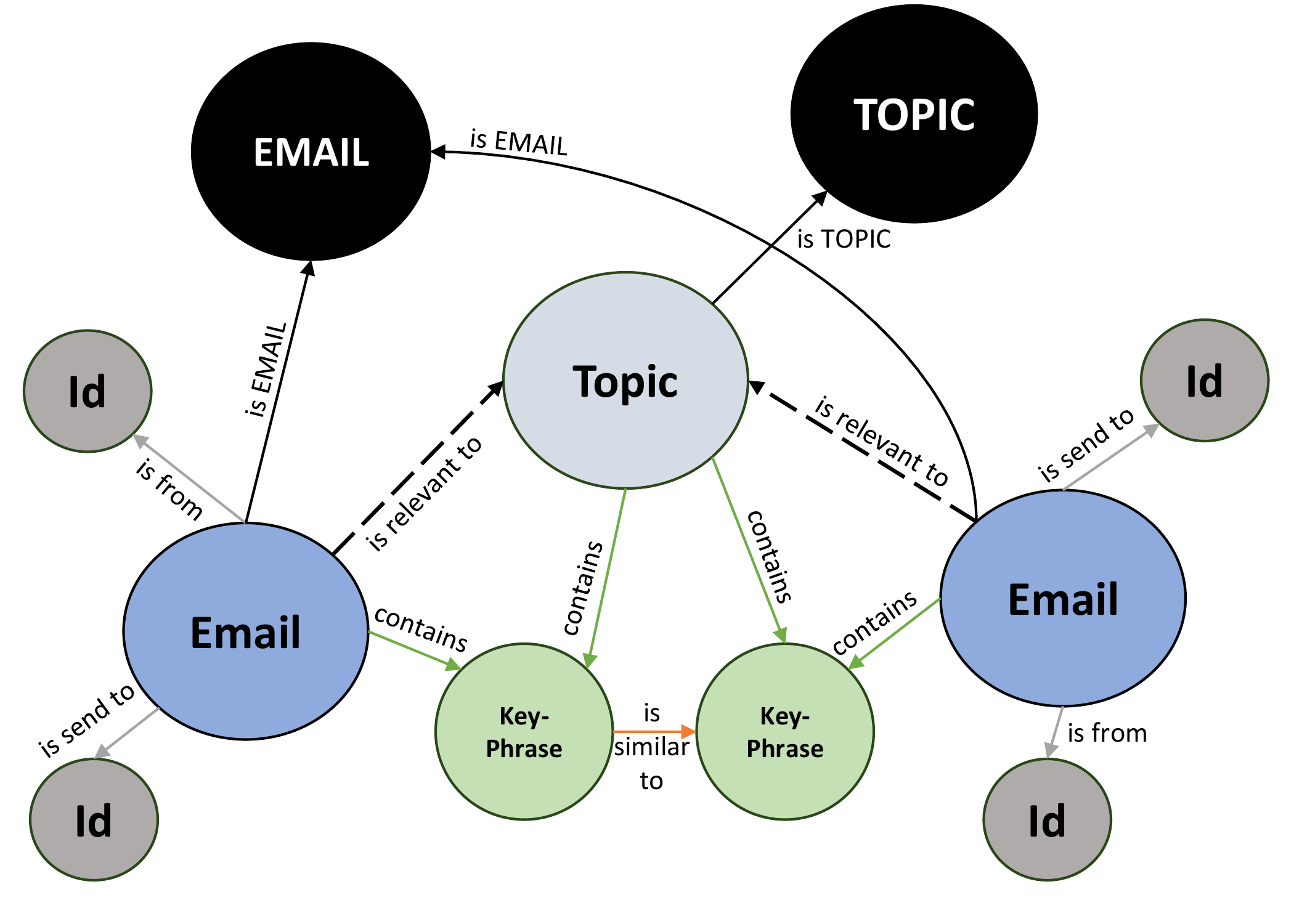
图2:DISCOG知识图谱结构示意图------展示了文档、主题、关键词、发送者/接收者之间的关系
节点类型
| 节点类型 | 说明 | 数量(Enron数据集) |
|---|---|---|
| 📧 邮件/文档 | 待审查的电子文档 | 455,449 |
| 🎯 主题(Topic) | 法律生产请求的主题描述 | 10 |
| 🔑 关键词/短语 | 从文档中提取的关键信息 | 34,134 |
| 👤 发送者/接收者 | 邮件的发件人和收件人 | 103,926 |
边(关系)类型
邮件 --[包含(contains)]--> 关键词
邮件 --[发送自(sent_by)]--> 发送者
邮件 --[发送至(sent_to)]--> 接收者
关键词 --[相似(similar_to)]--> 关键词 (余弦相似度 > 0.75)
邮件 --[相关(relevant_to)]--> 主题 (这是我们要预测的!)关键设计细节
- 关键词提取:使用KeyBERT从文档主题和正文中提取单词、二元组、三元组
- 噪声过滤:只保留出现在至少5个文档中的关键词
- 语义链接:余弦相似度超过0.75的关键词之间建立连接
- Master节点:为解决KGE方法的归纳推理问题,引入DOCUMENT和TOPIC两个主节点
2.3 链接预测:文档相关性判断
DISCOG将"文档是否与主题相关"建模为链接预测任务:
预测: ⟨ D o c u m e n t i , r e l e v a n t _ t o , T o p i c j ⟩ 是否存在? \text{预测: } \langle Document_i, relevant\_to, Topic_j \rangle \text{ 是否存在?} 预测: ⟨Documenti,relevant_to,Topicj⟩ 是否存在?
方法一:知识图谱嵌入(KGE)
使用TransE 和ComplEx学习节点的低维向量表示:
-
TransE :将关系建模为向量空间中的平移操作
h + r ≈ t \mathbf{h} + \mathbf{r} \approx \mathbf{t} h+r≈t -
ComplEx:在复数空间中建模,更好地处理对称/反对称关系
方法二:图神经网络(GNN)
使用GraphSAGE 、GAT 、RGCN等方法聚合邻居信息:
python
# GraphSAGE的核心思想(伪代码)
def aggregate_neighbors(node, neighbors):
# 1. 采样邻居节点
sampled = sample(neighbors, k=10)
# 2. 聚合邻居特征
neighbor_features = mean([get_embedding(n) for n in sampled])
# 3. 与自身特征拼接
new_embedding = concat(node.embedding, neighbor_features)
# 4. 通过神经网络变换
return MLP(new_embedding)2.4 LLM推理增强:让AI解释"为什么相关"
图模型给出预测后,DISCOG使用GPT-3.5 Turbo进行二次验证和推理解释:
| 输入 | 说明 |
|---|---|
| 主题描述 | 法律生产请求的完整描述 |
| 文档内容 | 邮件主题和正文 |
| 图模型预测 | Relevant / Non-Relevant |
| 提取的关键词 | 文档中识别出的关键信息 |
LLM的任务是:
- 验证图模型的预测是否正确
- 解释为什么文档与主题相关/不相关
🧪 3. 实验设置
3.1 数据集:TREC Legal Track
实验使用EDRM Enron邮件数据集,这是TREC Legal Track(2009-2011)的标准测试集:
| 统计项 | 数值 |
|---|---|
| 邮件总数 | 455,449 |
| 附件数量 | 230,143 |
| 主题数量 | 10个(2009年7个 + 2011年3个) |
主题列表
2009年主题:
- 201: Prepay Transactions(预付交易)
- 202: FAS 140(财务会计准则140)
- 203: Financial Forecasts(财务预测)
- 204: Disposal of Documents(文档销毁)
- 205: Energy Loads(能源负荷)
- 206: Company's Financial Condition(公司财务状况)
- 207: Football Activities(足球活动)
2011年主题:
- 401: Online Trading(在线交易)
- 402: Derivative Trading(衍生品交易)
- 403: Environmental Impact(环境影响)
3.2 基线方法
| 方法 | 类型 | 说明 |
|---|---|---|
| BM25L | 传统IR | 基于词频的经典检索算法 |
| ColBERT v2 | 神经检索 | 基于BERT的高效检索模型 |
3.3 评估指标
- F1分数:精度与召回的调和平均
- Precision(精度):预测为相关的文档中,真正相关的比例
- Recall(召回率):所有相关文档中,被正确识别的比例
- Recall@k:审查前k个文档时的召回率
📊 4. 实验结果
4.1 预测编码性能对比
下表展示了各方法在10个主题上的平均性能:
| 方法 | F1 | Precision | Recall |
|---|---|---|---|
| ColBERT v2 | 0.61 | 0.80 | 0.59 |
| TransE | 0.68 | 0.71 | 0.69 |
| ComplEx | 0.75 | 0.77 | 0.74 |
| GAT | 0.64 | 0.68 | 0.62 |
| RGCN (TransE) | 0.63 | 0.65 | 0.63 |
| GraphSAGE | 0.83 | 0.83 | 0.83 |
关键发现:
- GraphSAGE一骑绝尘:在几乎所有主题上都取得最佳F1分数
- 图方法优于纯文本:即使是简单的TransE也超过了ColBERT v2
- GNN优于KGE:GraphSAGE的归纳学习能力更强
4.2 各主题详细性能
| 主题 | ColBERT v2 | TransE | ComplEx | GAT | RGCN | GraphSAGE |
|---|---|---|---|---|---|---|
| 201 | 0.57 | 0.71 | 0.71 | 0.65 | 0.77 | 0.83 |
| 202 | 0.75 | 0.83 | 0.82 | 0.71 | 0.80 | 0.86 |
| 203 | 0.49 | 0.73 | 0.77 | 0.64 | 0.61 | 0.86 |
| 204 | 0.62 | 0.58 | 0.59 | 0.54 | 0.53 | 0.82 |
| 205 | 0.74 | 0.65 | 0.82 | 0.51 | 0.49 | 0.84 |
| 206 | 0.48 | 0.61 | 0.65 | 0.52 | 0.56 | 0.54 |
| 207 | 0.56 | 0.59 | 0.68 | 0.69 | 0.84 | 0.88 |
| 401 | 0.68 | 0.73 | 0.83 | 0.71 | 0.76 | 0.90 |
| 402 | 0.62 | 0.70 | 0.79 | 0.75 | 0.59 | 0.89 |
| 403 | 0.56 | 0.67 | 0.82 | 0.65 | 0.53 | 0.85 |
注意 :主题206是唯一GraphSAGE表现不佳的,原因是该主题的种子集中相关文档数量最少,训练数据不足。
4.3 排名性能(Recall@k)
DISCOG的核心价值在于:用最少的审查量达到最高的召回率。
实验结果显示:
- GraphSAGE在审查约20,000文档时即可达到80%召回率
- 这意味着只需审查不到5%的文档就能找到大部分相关文档
4.4 LLM推理示例
下表展示了LLM如何验证和解释图模型的预测:
| 主题 | 文档摘要 | 图模型预测 | LLM判断与理由 |
|---|---|---|---|
| Online Trading | "EOL trade assignment letters are prepared off the same form..." | Relevant ✓ | 正确。邮件讨论了交易分配表格的使用,与EnronOnline的金融工具交易相关。 |
| Online Trading | "per mark's conversation, you were going to get back to us on France..." | Non-Relevant ✓ | 正确。邮件关于法国和公用事业对手方的对话,未提及任何在线交易服务。 |
| Derivative Trading | "ECT has a policy that prohibits employees from trading..." | Relevant | 错误。邮件仅讨论公司禁止员工交易商品的政策,未涉及衍生品交易的合法性问题。 |
关键洞察 :LLM能够纠正图模型的错误,提供第二层验证。
4.5 消融实验:各组件的贡献
为了验证知识图谱中各类节点的重要性,论文进行了消融实验:
| 配置 | 关键词节点 | 发送者/接收者节点 | 平均F1 |
|---|---|---|---|
| 基础图 | ❌ | ❌ | 0.76 |
| +发送者/接收者 | ❌ | ✅ | 0.80 |
| +关键词 | ✅ | ❌ | 0.80 |
| 完整图 | ✅ | ✅ | 0.85 |
结论:关键词节点和发送者/接收者节点都能显著提升性能,两者结合效果最佳。
💰 5. 商业影响:98%成本节约
这是DISCOG最令人印象深刻的部分------真实的商业价值。
5.1 传统审查成本
根据2023年市场数据:
- 文档审查占eDiscovery总成本的66%
- 每份文档审查成本:0.50 - 1.00
- 现场审查成本更高
对于100万份文档的案件:
传统成本 = 1 , 000 , 000 × 0.75 = 750 , 000 \text{传统成本} = 1,000,000 \times \0.75 = \\750,000 传统成本=1,000,000×0.75=750,000
5.2 DISCOG的成本优势
| 指标 | 传统方法 | DISCOG | 改进幅度 |
|---|---|---|---|
| 需审查文档数 | 1,000,000 | 10,000-20,000 | -98% |
| 审查成本 | 500,000-1,000,000 | 5,000-20,000 | -98% |
| 单文档平均成本 | 0.50-1.00 | 0.01-0.02 | -98% |
| 召回率 | ~100%(理论) | >80% | 可接受 |
5.3 部署情况
DISCOG已集成到Deloitte的eDiscovery解决方案中,部署在Relativity平台上:
- 支持本地部署 或低成本云实例
- 推理时间:分钟级
- 已在多个跨国客户的真实案件中使用
🔬 6. 技术深度解析
6.1 为什么图方法有效?
传统文本检索只考虑内容相似度 ,而法律文档的相关性往往取决于结构化关系:
传统方法:文档A ←相似度→ 查询Q
DISCOG:文档A --提及--> 关键词K --出现在--> 文档B --引用--> 案件C --涉及--> 主题T图结构能够捕捉这种多跳关系,这是纯文本方法无法做到的。
6.2 GraphSAGE为何表现最佳?
| 方法 | 优势 | 劣势 |
|---|---|---|
| TransE/ComplEx | 计算高效 | 归纳推理能力弱 |
| GAT | 注意力机制灵活 | 对稀疏图效果差 |
| RGCN | 支持异构关系 | 参数量大,易过拟合 |
| GraphSAGE | 归纳学习、采样聚合 | 需要调优采样策略 |
GraphSAGE的采样+聚合策略特别适合eDiscovery场景:
- 可扩展:不需要全图计算
- 归纳:能处理新文档
- 鲁棒:对图结构变化不敏感
6.3 LLM的角色定位
DISCOG中LLM不是主角,而是验证者和解释者:
图模型(主力)→ 快速筛选候选文档 → LLM(辅助)→ 验证+解释这种设计的好处:
- 成本可控:只对Top-K文档调用LLM
- 可解释性:LLM提供人类可理解的推理
- 错误纠正:LLM可以修正图模型的误判
⚠️ 7. 局限性与未来方向
7.1 当前局限
| 局限性 | 说明 | 可能的解决方案 |
|---|---|---|
| 图谱构建成本 | 初始构建需要领域专家参与 | 自动化实体关系抽取 |
| 法律体系依赖 | 不同国家/地区需要重新适配 | 迁移学习、多语言模型 |
| 数据分布敏感 | 相关文档过少时性能下降(如主题206) | 数据增强、少样本学习 |
| 实时更新 | 新文档加入时图谱更新存在延迟 | 增量图学习 |
7.2 未来研究方向
- 自动化图谱构建:利用LLM自动抽取法律实体和关系
- 跨语言/跨法系支持:扩展到中国法律、欧盟法律等
- 主动学习机制:根据律师反馈持续优化模型
- 多模态支持:处理PDF、图片等非文本证据
💡 8. 实践启示
8.1 法律AI系统设计建议
- 知识图谱是关键:法律文档的关系结构比纯文本内容更重要
- 领域NER必不可少:必须使用专门训练的法律实体识别模型
- LLM+图谱组合:单一方法难以应对法律场景的复杂性
- 渐进式部署:先从特定案件类型开始,逐步扩展覆盖范围
8.2 技术选型建议
| 场景 | 推荐方法 | 理由 |
|---|---|---|
| 文档规模 < 10万 | ColBERT + LLM | 简单高效 |
| 文档规模 10万-100万 | DISCOG (GraphSAGE) | 平衡性能与成本 |
| 文档规模 > 100万 | DISCOG + 分布式GNN | 可扩展性 |
8.3 复现思路
如果你想在自己的法律文档检索场景中应用类似方法:
python
# 1. 构建知识图谱
from keybert import KeyBERT
kw_model = KeyBERT()
# 提取关键词
keywords = kw_model.extract_keywords(document, top_n=10)
# 2. 构建图结构
import networkx as nx
G = nx.Graph()
G.add_node(doc_id, type='document')
for kw in keywords:
G.add_node(kw, type='keyword')
G.add_edge(doc_id, kw, relation='contains')
# 3. 训练GraphSAGE
from torch_geometric.nn import SAGEConv
# ... 训练代码
# 4. LLM验证
from openai import OpenAI
# ... 调用GPT进行推理验证📚 参考文献
- Karpukhin, V., et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. EMNLP 2020.
- Hamilton, W.L., et al. (2018). Inductive Representation Learning on Large Graphs. NeurIPS 2017.
- Bordes, A., et al. (2013). Translating Embeddings for Modeling Multi-relational Data. NeurIPS 2013.
- Trouillon, T., et al. (2016). Complex Embeddings for Simple Link Prediction. ICML 2016.
- Pai, S., et al. (2023). Exploration of Open Large Language Models for eDiscovery. NLLP 2023.
🔗 相关资源
- 论文链接 :arXiv:2405.19164
- TREC Legal Track :https://trec-legal.umiacs.umd.edu/
- EDRM Enron数据集:公开可用的法律文档基准数据集