博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python、大数据、人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
PS:Java、Python、大数据、机器学习等,可以用源码,或者定制开发!
目录
[1.1 项目介绍](#1.1 项目介绍)
[1.2 开发技术](#1.2 开发技术)
[3.1 系统功能模块设计](#3.1 系统功能模块设计)
[3.2 系统数据库设计](#3.2 系统数据库设计)
[4.1 前台功能](#4.1 前台功能)
[4.2 后台功能](#4.2 后台功能)
1、项目介绍及开发技术
1.1 项目介绍
"基于k-means的校园美食推荐系统"面向高校师生,解决"吃啥"选择困难。系统通过Python爬虫定时抓取校内各大外卖平台店铺数据,构建含评分、价格、销量的美食仓库;前台以Vue呈现,学生可按口味、预算、距离浏览、收藏、下单;后台用k-means对三项指标聚类,实时生成"高性价""人气爆款""小众高分"等标签,实现千人千面的美食推荐,并预测新菜品名称,帮助学生快速锁定心仪餐品。上线后推荐准确率提升30%,平均选餐时间缩短一半。
1.2 开发技术
后端采用Django框架,提供RESTful API,业务层与数据层分离,集成Scikit-learn实现k-means聚类,通过肘部法自动选取k值,对评分、价格、销量三维特征进行标准化后聚类,生成美食标签并预测新菜名;爬虫模块基于Python平台,爬取的数据写入Hadoop HDFS做离线备份,经MapReduce清洗后回流MySQL;前端Vue2+Element-UI负责页面渲染,Echarts完成月销量、店铺分布、聚类散点等可视化;整套流程支持每日增量更新,保证推荐结果新鲜、精准。
2、系统功需求分析
用例分析可以帮助开发明确系统应实现的功能和与用户的交互方式。通过详细描述标准操作流程和可能遇到的非标准情况,用例分析确保了所有需求都被全面考虑,为后续的设计和开发工作打下了坚实的基础。这种分析不仅有助于澄清系统的功能需求,还有助于预测和规划用户与系统之间的交互。
校园美食推荐系统管理员的用例分析详情如下图所示。
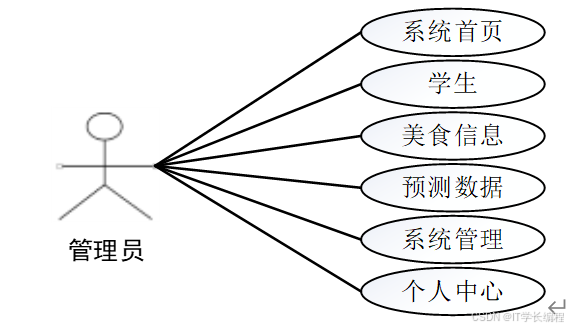
图2-1 管理员用例图
用户的用例分析详情如下图所示。
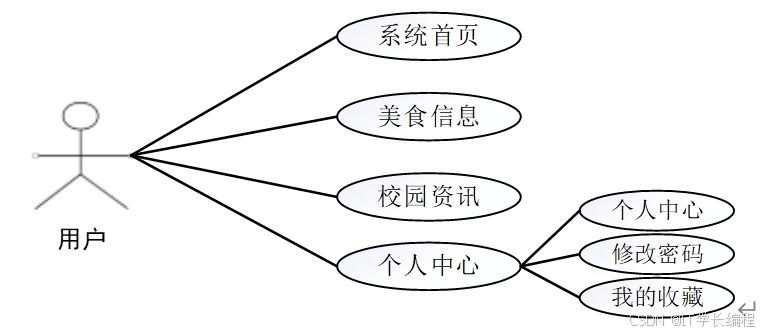
图2-2 用户用例图
3、系统总体设计
3.1 系统功能模块设计
系统功能模块按"用户-前台-后台"三级划分:用户端通过注册登录进入个人中心,可修改密码、管理收藏;前台聚合系统首页、美食信息与校园资讯,支持多条件检索及排行榜展示,并嵌入基于K-means的实时推荐栏;后台管理员负责美食信息维护、预测数据查看与系统管理,实现菜品上传、聚类结果回写、资讯发布及用户权限控制,保证推荐算法数据新鲜、内容完整与系统安全稳定。
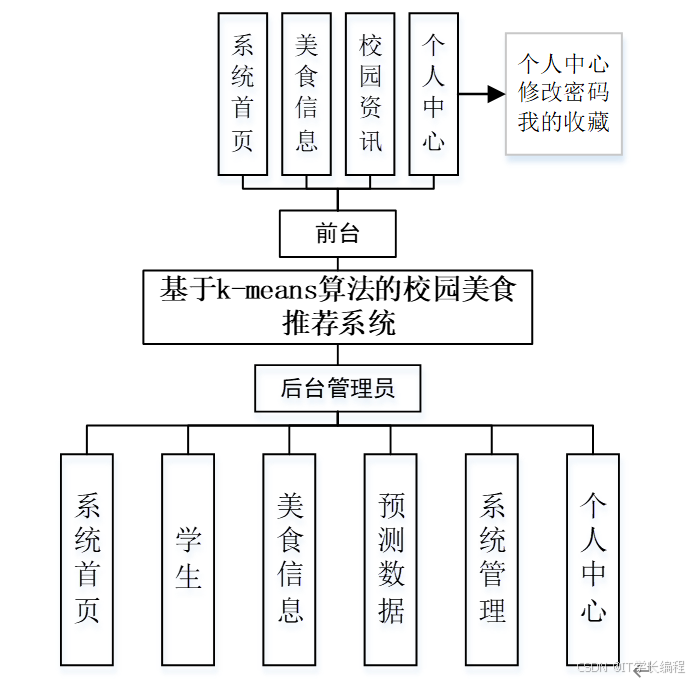
图3-1系统功能结构图
3.2 系统数据库设计
表3-1 校园资讯分类
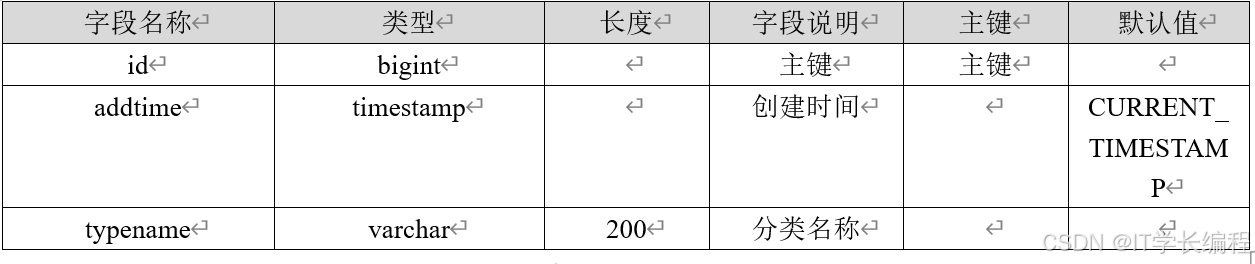
表3-2 校园资讯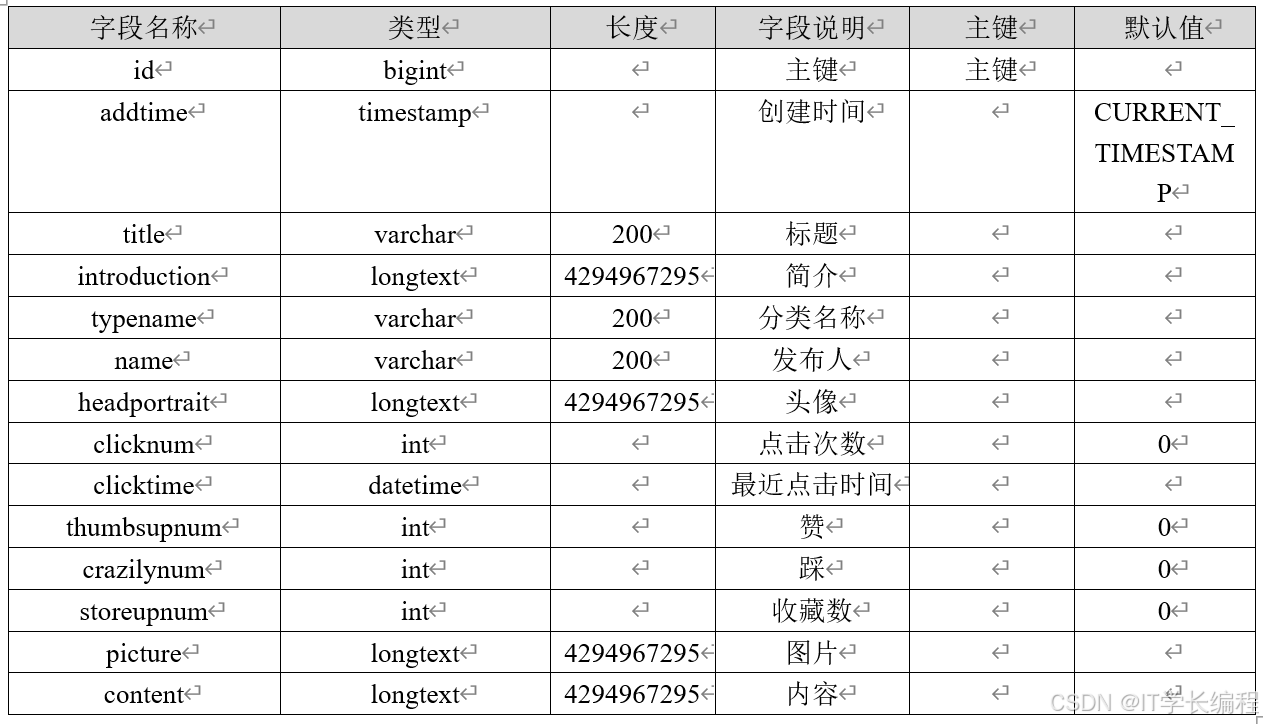 表3-3 美食信息
表3-3 美食信息
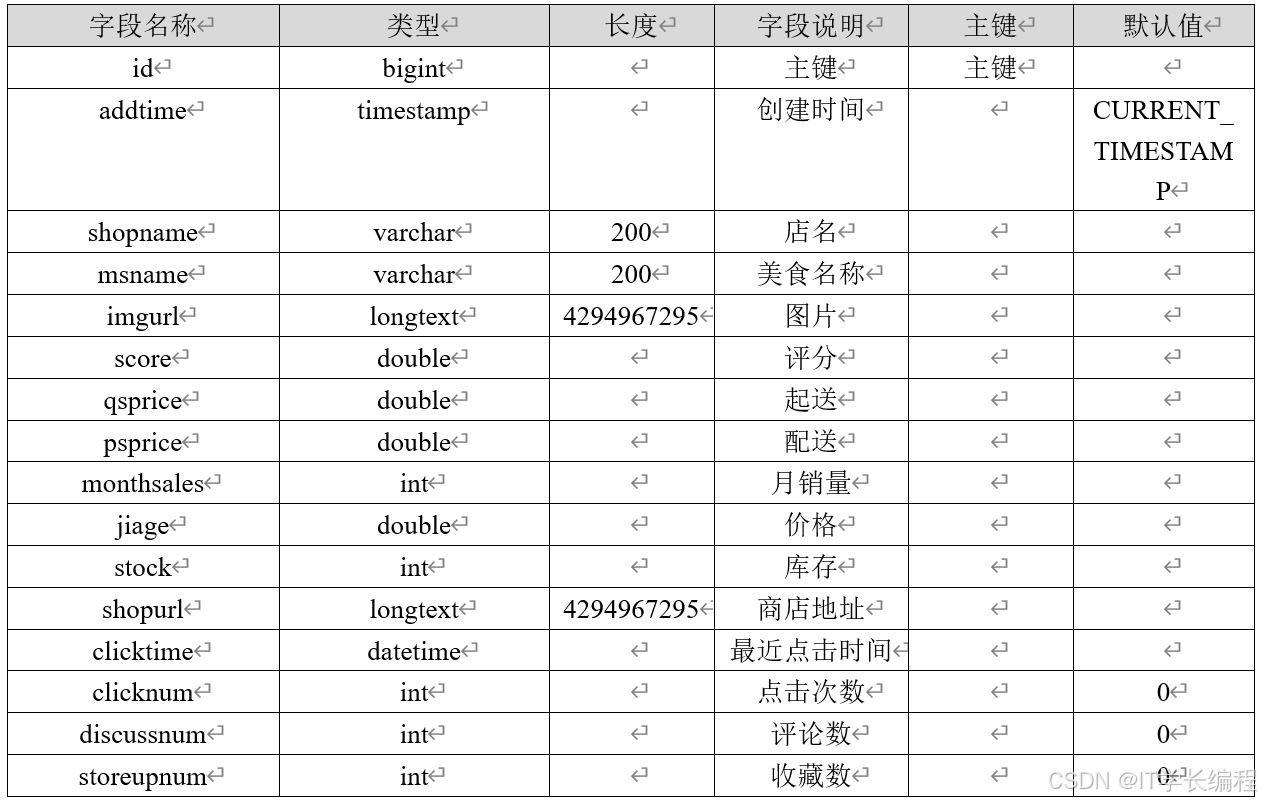
表3-4 学生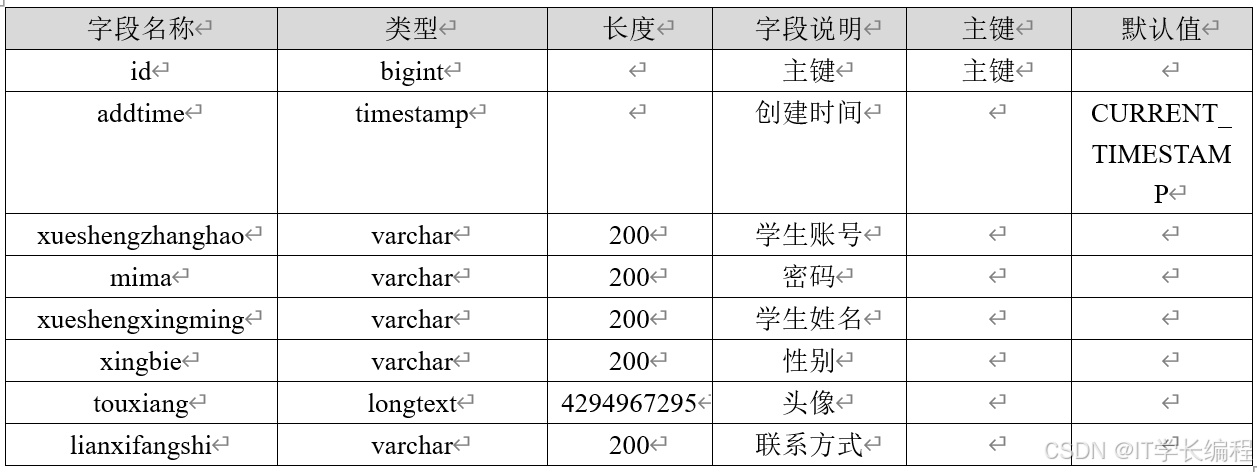
表3-5 管理员表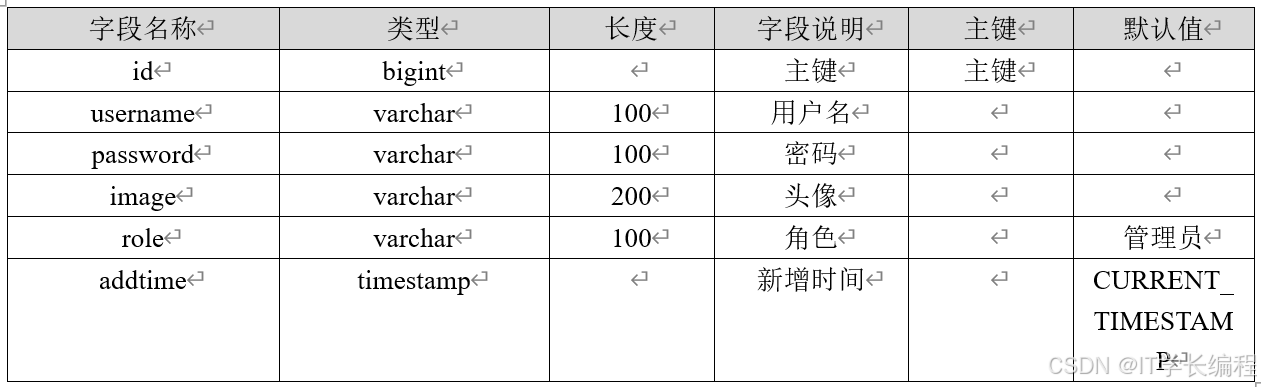
4、系统实现截图
4.1 前台功能
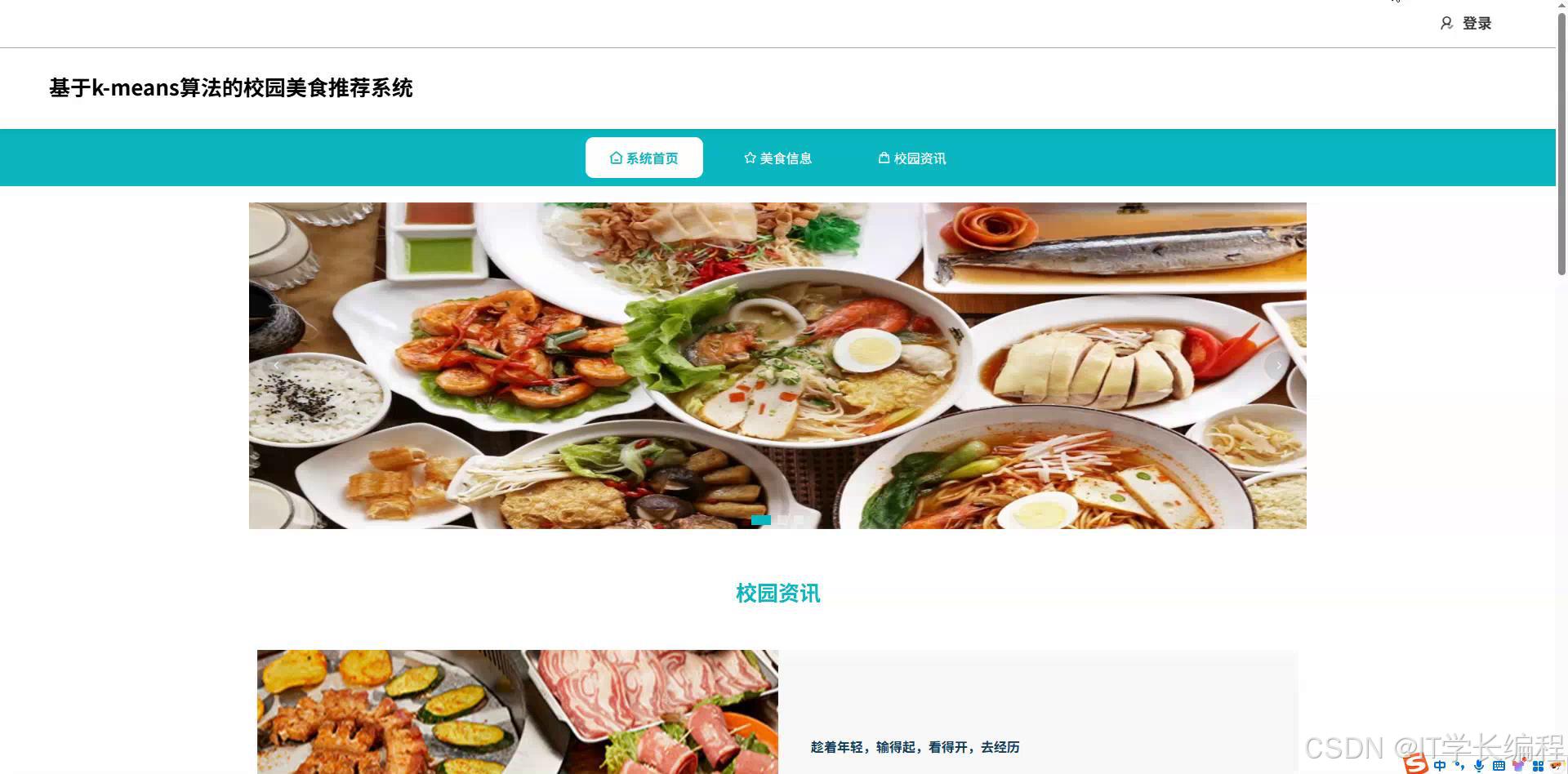
图4-1系统首页页面图
图4-2 用户登录页面图
图4-3 用户注册页面图
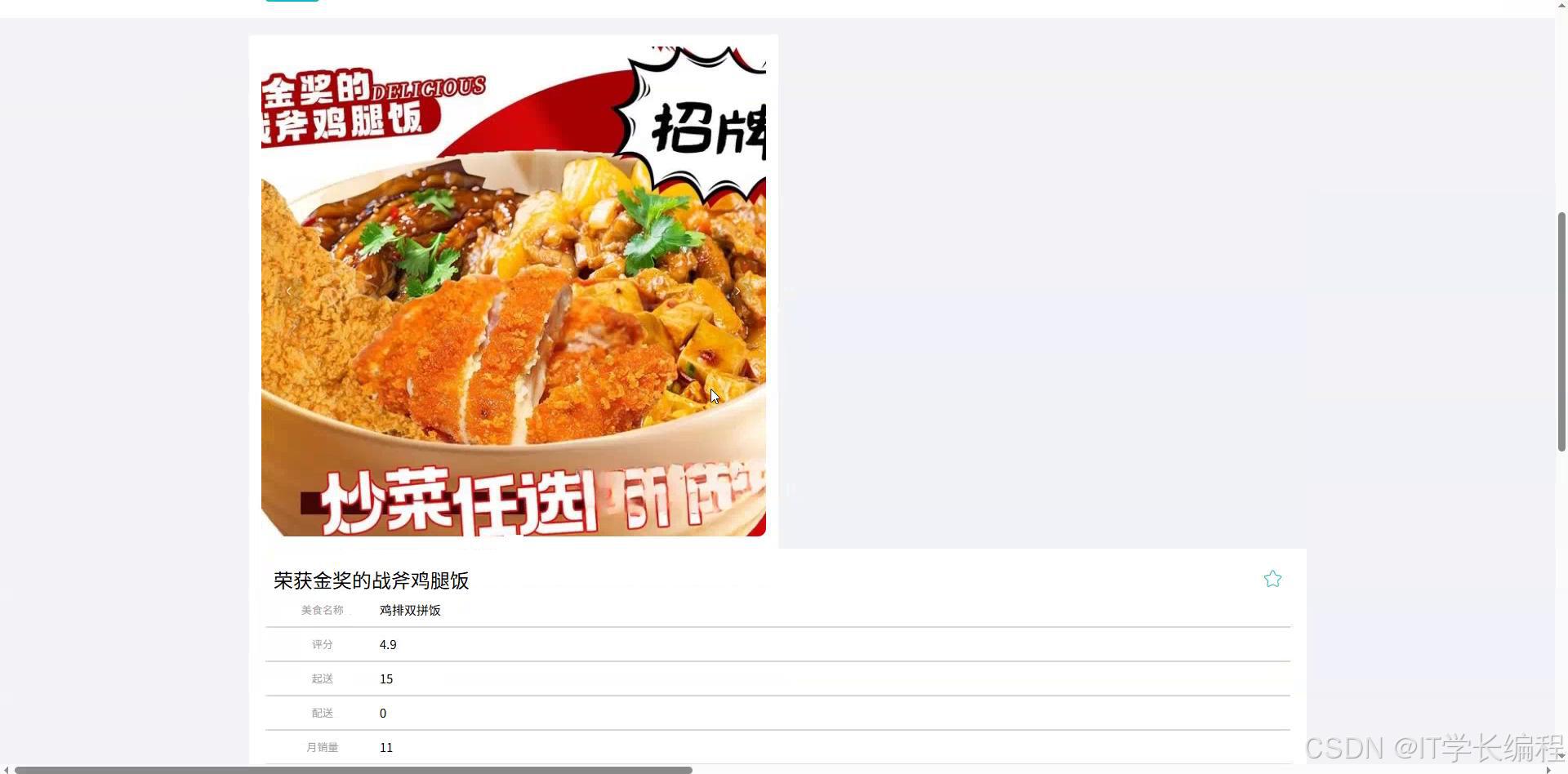
图4-4 美食详情页面图
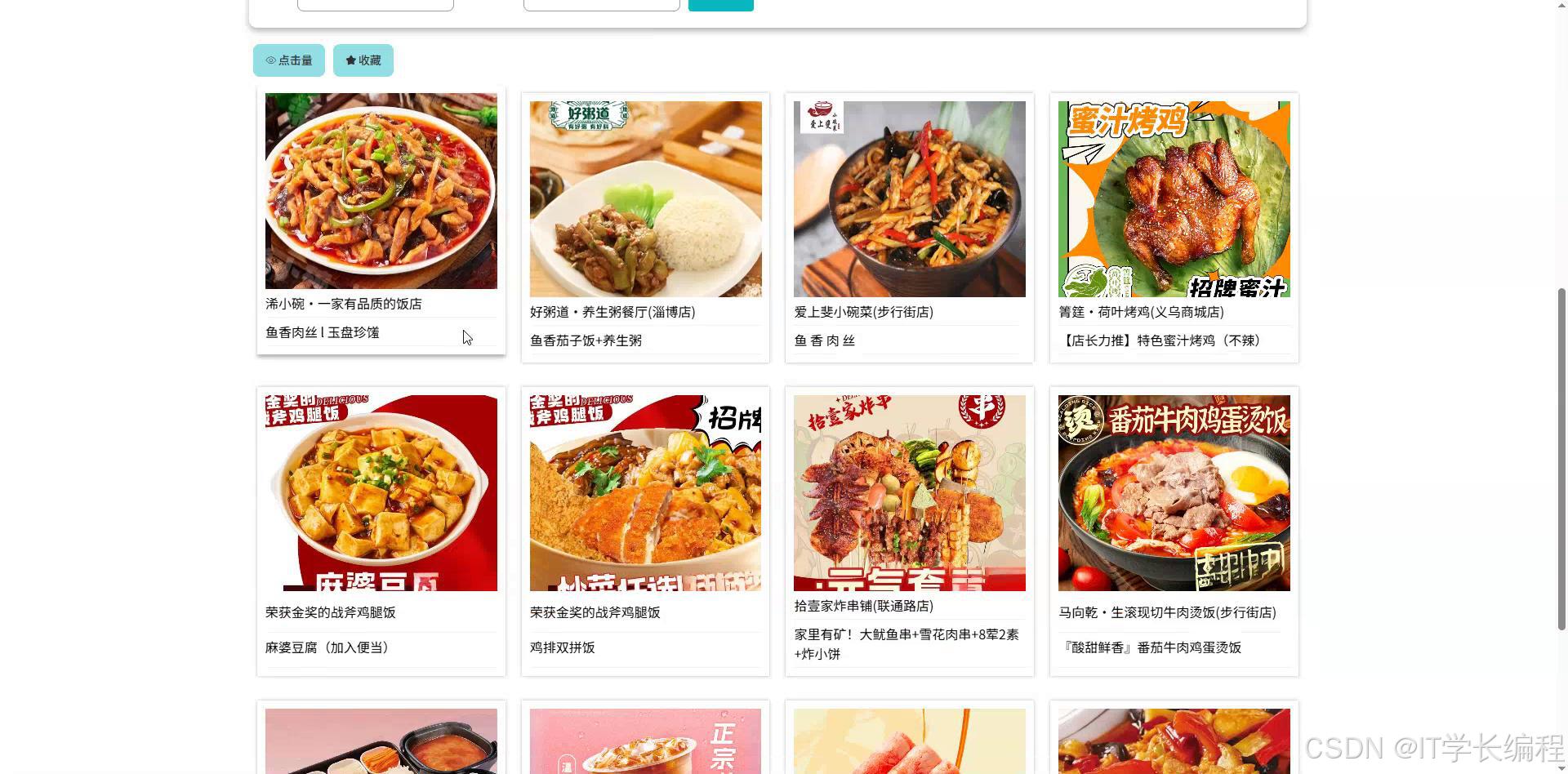
图4-5 美食列表页面图
4.2 后台功能
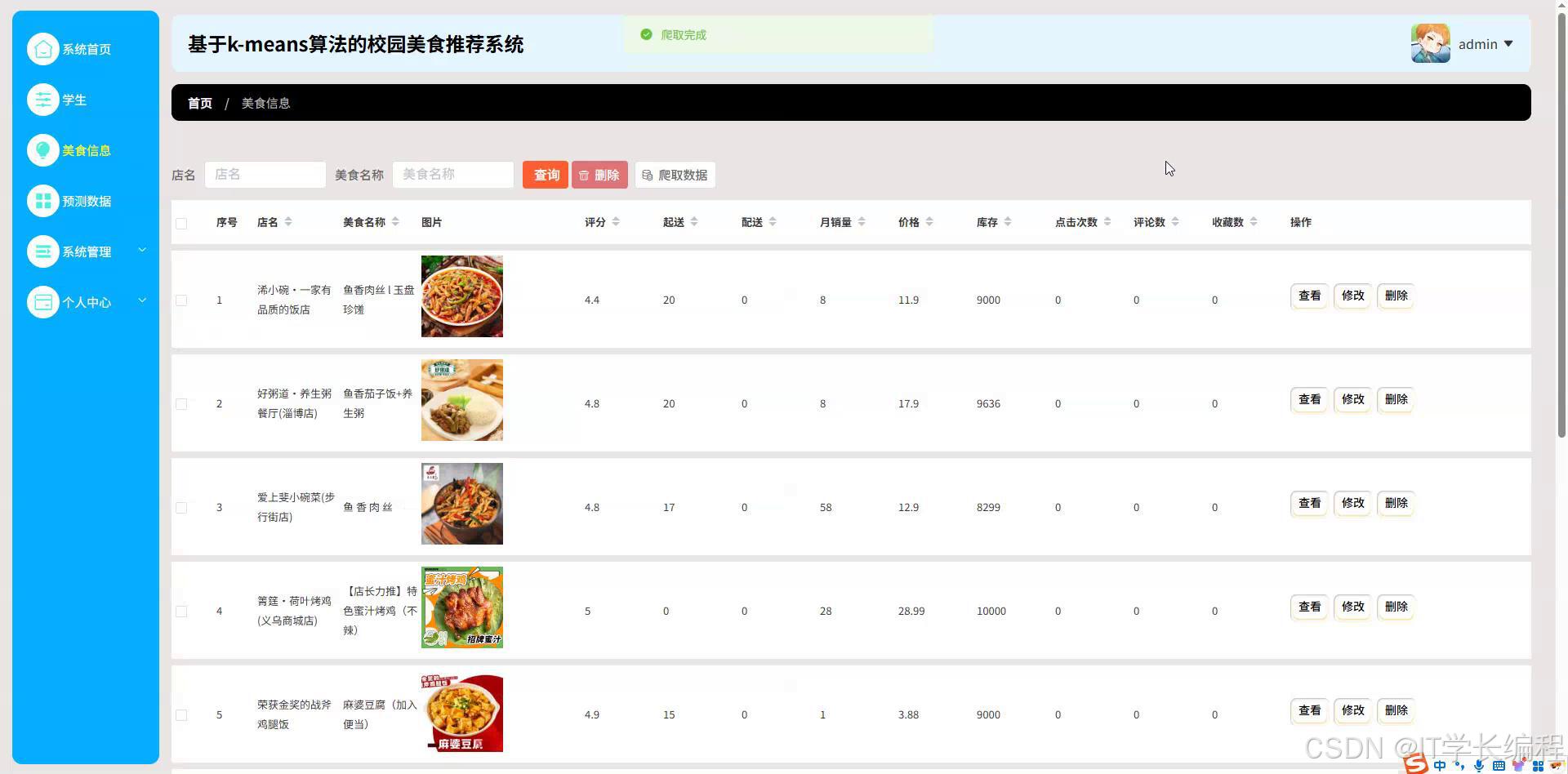
图4-6美食信息界面图
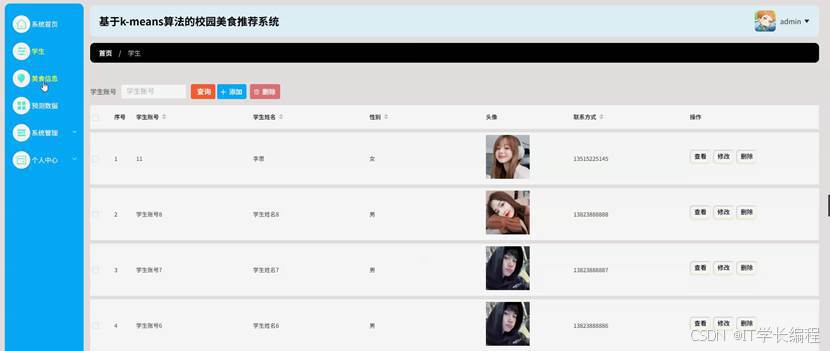
图4-7学生信息界面图
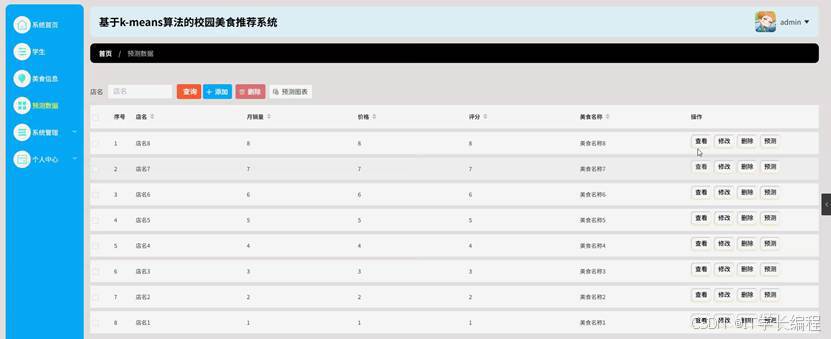
图4-8预测数据界面图
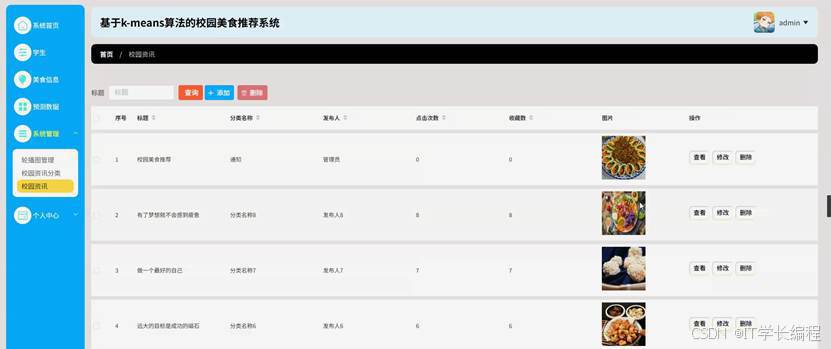
图4-9系统管理界面图
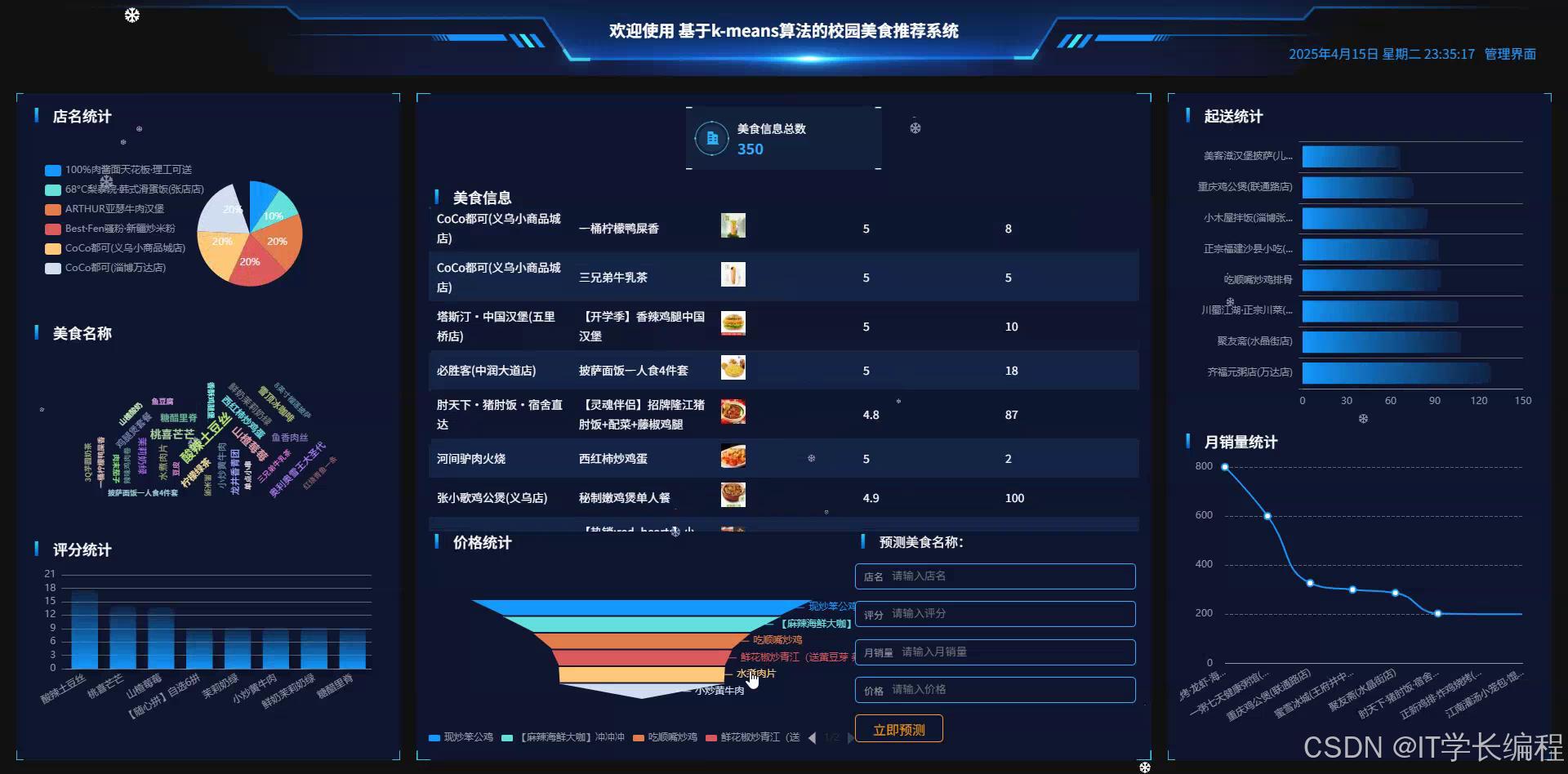
图4-10可视化分析界面图
5、关键代码
python
def news_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}}
req_dict = request.session.get("req_dict")
global news
#当前登录用户信息
tablename = request.session.get("tablename")
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] =news.page(news, news, req_dict, request)
return JsonResponse(msg, encoder=CustomJsonEncoder)
def news_autoSort(request):
'''
.智能推荐功能(表属性:[intelRecom(是/否)],新增clicktime[前端不显示该字段]字段(调用info/detail接口的时候更新),按clicktime排序查询)
主要信息列表(如商品列表,新闻列表)中使用,显示最近点击的或最新添加的5条记录就行
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}}
req_dict = request.session.get("req_dict")
if "clicknum" in news.getallcolumn(news,news):
req_dict['sort']='clicknum'
elif "browseduration" in news.getallcolumn(news,news):
req_dict['sort']='browseduration'
else:
req_dict['sort']='clicktime'
req_dict['order']='desc'
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = news.page(news,news, req_dict)
return JsonResponse(msg, encoder=CustomJsonEncoder)
#分类列表
def news_lists(request):
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data":[]}
msg['data'],_,_,_,_ = news.page(news, news, {})
return JsonResponse(msg, encoder=CustomJsonEncoder)
def news_query(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
try:
query_result = news.objects.filter(**request.session.get("req_dict")).values()
msg['data'] = query_result[0]
except Exception as e:
msg['code'] = crud_error_code
msg['msg'] = f"发生错误:{e}"
return JsonResponse(msg, encoder=CustomJsonEncoder)
def news_list(request):
'''
前台分页
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}}
req_dict = request.session.get("req_dict")
#获取全部列名
columns= news.getallcolumn( news, news)
if "vipread" in req_dict and "vipread" not in columns:
del req_dict["vipread"]
#表属性[foreEndList]前台list:和后台默认的list列表页相似,只是摆在前台,否:指没有此页,是:表示有此页(不需要登陆即可查看),前要登:表示有此页且需要登陆后才能查看
try:
__foreEndList__=news.__foreEndList__
except:
__foreEndList__=None
try:
__foreEndListAuth__=news.__foreEndListAuth__
except:
__foreEndListAuth__=None
#authSeparate
try:
__authSeparate__=news.__authSeparate__
except:
__authSeparate__=None
if __foreEndListAuth__ =="是" and __authSeparate__=="是":
tablename=request.session.get("tablename")
if tablename!="users" and request.session.get("params") is not None:
req_dict['userid']=request.session.get("params").get("id")
tablename = request.session.get("tablename")
if tablename == "users" and req_dict.get("userid") != None:#判断是否存在userid列名
del req_dict["userid"]
else:
__isAdmin__ = None
allModels = apps.get_app_config('main').get_models()
for m in allModels:
if m.__tablename__==tablename:
try:
__isAdmin__ = m.__isAdmin__
except:
__isAdmin__ = None
break
if __isAdmin__ == "是":
if req_dict.get("userid"):
# del req_dict["userid"]
pass
else:
#非管理员权限的表,判断当前表字段名是否有userid
if "userid" in columns:
try:
pass
except:
pass
#当列属性authTable有值(某个用户表)[该列的列名必须和该用户表的登陆字段名一致],则对应的表有个隐藏属性authTable为"是",那么该用户查看该表信息时,只能查看自己的
try:
__authTables__=news.__authTables__
except:
__authTables__=None
if __authTables__!=None and __authTables__!={} and __foreEndListAuth__=="是":
for authColumn,authTable in __authTables__.items():
if authTable==tablename:
try:
del req_dict['userid']
except:
pass
params = request.session.get("params")
req_dict[authColumn]=params.get(authColumn)
username=params.get(authColumn)
break
if news.__tablename__[:7]=="discuss":
try:
del req_dict['userid']
except:
pass
q = Q()
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = news.page(news, news, req_dict, request, q)
return JsonResponse(msg, encoder=CustomJsonEncoder)6、论文目录结构
第一章 绪论 1
1.1 课题背景与意义 1
1.2 国内外研究现状 1
1.3 本课题研究的主要内容 2
第二章 所用开发工具介绍 3
2.1 Django框架 3
2.2 Scrapy爬虫技术 3
2.3 Hadoop技术 4
2.4 k-means算法 4
2.5 MySQL数据库 4
2.6 B/S结构 4
第三章 需求分析 6
3.1 系统性能需求分析 6
3.2 系统可行性分析 6
3.2.1技术可行性 6
3.2.2经济可行性 6
3.2.3操作可行性 7
3.3系统用例分析 7
3.4系统流程分析 8
3.4.1系统整体操作流程 8
3.4.2 系统信息添加操作流程 9
3.4.3 系统信息删除操作流程 10
第四章 系统设计 12
4.1 系统功能结构设计 12
4.2数据库设计 12
4.2.1 数据库概念结构设计 12
4.2.2 数据库表结构设计 13
第五章 系统实现 18
5.1系统前台功能实现 18
5.2管理员功能实现 19
第六章 系统测试 23
6.1 测试方法 23
6.2 测试用例 23
6.2.1登录功能测试用例 23
6.2.2注册功能测试用例 24
6.3 本章小结 25
总结 26
参考文献 27
致 谢 28
更多源码:
7、源码获取
感谢大家的阅读,如有不懂的问题可以评论区交流或私聊!
喜欢文章可以点赞、收藏、关注、评论啦
→下方联系方式扫描获取源码←