Transformer实战(21)------文本表示(Text Representation)
0. 前言
我们已经学习了如何使用 transformers 库解决分类和生成问题。文本表示 (Text Representation) 是现代自然语言处理 (Natural Language Processing, NLP) 中的另一个关键任务,特别是对于无监督任务,如聚类、语义搜索和主题建模。在本节中,将介绍如何通过使用不同的模型)如通用句子编码器 (Universal Sentence Encoder, USE) 和 Sentence-BERT (SBERT) 以及附加框架(如 SentenceTransformers )来表示句子,还将解释如何使用 BART 进行零样本学习。
1. 句子嵌入
预训练的 BERT 模型并不能直接生成高效且独立的句子嵌入,因为它们需要在端到端的监督设置下进行微调。我们可以把预训练的 BERT 模型视为一个不可分割的整体,语义分布在所有网络层中,而不仅仅是最后一层。如果没有进行微调,单独使用其内部表示可能效果不佳。此外,在处理无监督任务(如聚类、主题建模、信息检索或语义搜索)时也面临挑战。例如,在聚类任务中,必须评估大量的句子对,这会导致巨大的计算开销。
针对以上问题,提出了许多对原始 BERT 模型的改进,如 SBERT,旨在生成具有语义意义且独立的句子嵌入。SBERT 采用与 BERT 不同的目标函数,在 SBERT 方法中,句子可以通过一个双网络进行配对,并根据相似度进行评估。在 NLP 领域,有多种神经网络句子嵌入方法,用于将单个句子映射到一个共同的特征空间(向量空间模型),通常使用余弦函数(或点积)来衡量相似度,使用欧几里得距离来衡量不相似度。
以下是一些可以通过句子嵌入高效解决的应用场景:
- 句子对任务
- 信息检索
- 问答系统
- 重复问题检测
- 同义句检测
- 文档聚类
- 主题建模
最简单但高效的神经网络句子嵌入方法是平均池化操作,它通过对句子中各个词的嵌入求均值进行处理。为了获得更好的表示,一些早期的神经网络方法采用无监督方式学习句子嵌入,例如 Doc2Vec、Skip-Thought、FastSent 和 Sent2Vec。Doc2Vec 利用词级分布理论和目标函数来预测相邻词,类似于 word2Vec。该方法在每个句子中注入一个额外的记忆词元(称为段落 ID),这与 transformers 库中的 CLS 或 SEP 词元 (token) 类似。这个额外的词元充当一个记忆单元,表示上下文或文档嵌入。Skip-Thought 和 FastSent 是句子级方法,其目标函数用于预测相邻句子,通过提取句子的含义,并从相邻句子及其上下文中获取必要的信息。
InferSent 等方法则利用监督学习和多任务迁移学习来学习通用的句子嵌入。InferSent 通过训练多个监督任务来获得更高效的嵌入。基于递归神经网络 (Recurrent Neural Network, RNN)的监督模型,如长短期记忆 (Long Short Term Memory, LSTM) 和门控循环单元 (Gated Recurrent Unit, GRU),通过最后的隐藏状态获得句子嵌入,并在监督设置下进行训练。
2. Cross-encoder 与 Bi-encoder 对比
我们已经学习了如何训练基于 Transformer 的语言模型,并在半监督和监督设置下对其进行微调。一旦为预训练模型添加了一个特定任务的线性层,网络的所有权重(不仅仅是最后的任务特定层)都会通过任务特定的标注数据进行微调。我们还学习了如何在不进行任何架构修改的情况下,对 BERT 架构进行微调,以适应两类不同的任务(单句或句子对)。唯一的区别在于,对于句子对任务,句子会被连接在一起,并用 SEP 词元分隔,自注意力机制会应用于连接后的所有词元。这是 BERT 模型的一大优势,输入的两个句子可以在每一层中都能获取彼此必要的信息,最终被同时编码,这种方法称为交叉编码 (cross-encoding)。
但交叉编码存在以下两个缺点:
- 计算效率低:交叉编码器设置对于许多句子对任务并不方便,因为需要处理的可能组合过多。例如,为了从
1000个句子中找出两个最相近的句子,交叉编码器模型(如BERT)需要大约500000次推理计算 (n * (n-1) / 2)。SBERT或通用句子编码器 (Universal Sentence Encoder,USE) 等现代架构可以高效地执行相似性计算,相较之下,交叉编码器方法非常缓慢。此外,通过优化的索引结构,可以在比较或聚类大量文档时将计算复杂度从数小时降低到几分钟 - 无监督任务表现不佳:由于
BERT模型的监督学习特性,无法产生独立且有意义的句子嵌入。很难直接利用预训练的BERT模型来处理无监督任务,如聚类、语义搜索或主题建模。BERT模型为文档中的每个词元生成固定大小的向量。在无监督设置下,文档级的表示可以通过对词元向量(包括SEP和CLS标记)进行平均或池化获得。但BERT的这种表示方法生成的句子嵌入效果较差,其性能通常低于基于词嵌入池化的技术(如Word2Vec、FastText或GloVe)
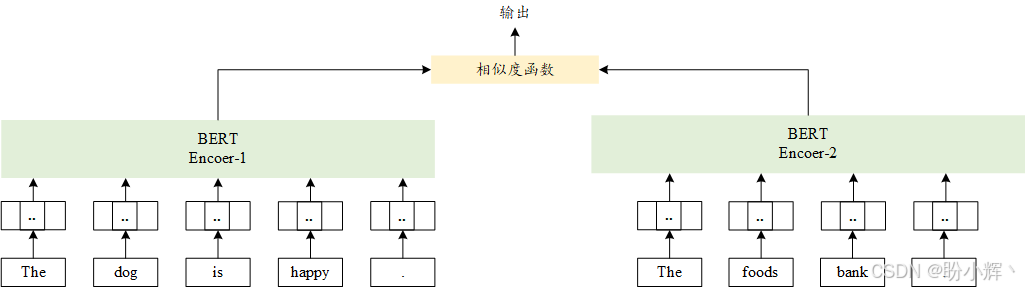
相比之下,双编码器(如 SBERT )将句子对独立的映射到语义向量空间,如下图所示。由于表示是独立的,双编码器可以缓存每个输入的编码表示,从而实现快速推理。SBERT 是 BERT 的一个双编码器改进版本,基于孪生网络 (Siamese) 和三元组网络 (Triplet) 的结构,SBERT 对 BERT 模型进行改进,以生成具有语义意义且独立的句子嵌入。双编码器架构如下所示:
3. 基准测试句子相似度模型
目前有许多语义文本相似性模型可供使用,我们可以通过基准测试和度量指标来评估并了解它们的能力和差异,可以在Papers With Code中找到相关数据集列表。此外,每个数据集中都有多个模型输出,并按照其结果进行排名。
通用语言理解评估 (General Language Understanding Evaluation, GLUE)提供了多种相关数据集和测试,不仅限于语义文本相似度。GLUE 是一个评估模型在不同 NLP 任务上表现的通用基准。
(1) 为了加载度量标准和数据集,首先导入 datasets 库的相关函数:
python
from datasets import load_dataset
import evaluate(2) 假设模型输出了预测值,这些值存储数组 predictions 中。可以通过以下使用 metric,查看 F1 分数和准确率值:
python
labels = [i['label'] for i in dataset['test']]
metric.compute(predictions=predictions, references=labels)(3) 一些语义文本相似度数据集使用了不同的度量标准,如语义文本相似度基准 (Semantic Textual Similarity Benchmark, STSB)使用 Spearman 相关系数和 Pearson 相关系数,因为输出和预测值是在 0 到 5 之间的浮点值,而不是多个 0 和 1 的离散值,这实际上是一个回归问题。以下代码展示了该基准的一个示例:
python
metric = evaluate.load('glue', 'stsb')
metric.compute(predictions=[1,2,3],references=[5,2,2]) 其中,predictions 是模型的输出,而 references 是数据集的标签。
(4) 为了获得两个模型之间的比较结果,我们将使用 RoBERTa 的蒸馏版本,并在 STSB 上进行测试。首先,安装所需的库,在加载和使用模型之前进行设置:
shell
$ pip install tensorflow-hub
$ pip install sentence-transformers
$ pip install kagglehub(5) 加载数据集和度量标准:
python
from datasets import load_dataset
import evaluate
stsb_metric = evaluate.load('glue', 'stsb')
stsb = load_dataset('glue', 'stsb') (6) 之后,加载模型:
python
import kagglehub
import tensorflow_hub as hub
path = kagglehub.model_download("google/universal-sentence-encoder/tensorFlow2/universal-sentence-encoder")
use_model = hub.load(path)
from sentence_transformers import SentenceTransformer
distilroberta = SentenceTransformer('stsb-distilroberta-base-v2') (7) 以上两个模型都能为给定的句子提供嵌入 (embeddings) 表示。为了比较两个句子之间的相似度,使用余弦相似度。定义函数 use_sts_benchmark() 接受句子作为批数据,并通过使用 USE(Universal Sentence Encoder) 计算每对句子的余弦相似度:
python
import tensorflow as tf
import math
def use_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(use_model(tf.constant(batch['sentence1'])),axis=1)
sts_encode2 = tf.nn.l2_normalize(use_model(tf.constant(batch['sentence2'])),axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1,sts_encode2),axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities,-1.0,1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
return scores(8) 通过简单修改,可以使用相同的函数来处理 RoBERTa。修改仅涉及替换嵌入函数,因为 TensorFlow Hub 模型和 Transformer 模型的嵌入函数不同:
python
def roberta_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(distilroberta.encode(batch['sentence1']),axis=1)
sts_encode2 = tf.nn.l2_normalize(distilroberta.encode(batch['sentence2']),axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1,sts_encode2),axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities,-1.0,1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
return scores (9) 将函数应用于数据集后,将会得到每个模型的相似度得分:
python
use_results = use_sts_benchmark(stsb['validation'])
distilroberta_results = roberta_sts_benchmark(stsb['validation'])
references = [item['label'] for item in stsb['validation']](10) 对两个结果进行评估,可以得到 Spearman 相关系数和 Pearson 相关系数:
python
results = {
"USE":stsb_metric.compute(
predictions=use_results,
references=references),
"DistillRoberta":stsb_metric.compute(
predictions=distilroberta_results,
references=references)
} (11) 使用 pandas 查看结果:
python
import pandas as pd
pd.DataFrame(results)输出结果如下所示:

在本节中,了解了语义文本相似度的关键基准,学习了如何使用这些度量标准量化模型的性能。在下一节中,将学习关于少样本学习模型,探索其独特优势和应用场景。
4. 使用 BART 进行零样本学习
在机器学习领域,零样本学习是指一种可以在没有明确训练的情况下完成任务的模型。在 NLP 中,零样本学习通常指模型能够预测某段文本被分配到某个类别的概率,而这些类别在训练时并没有显式提供给模型,也就是说,模型并未针对这些类别进行训练。
随着能够执行迁移学习的语言模型的兴起,零样本学习也得以发展。在 NLP 领域,这种学习是在测试时进行的,模型会接收到属于新类别的样本,而这些类别的样本在训练阶段从未出现过。
这种学习方式通常用于分类任务,其中类别和文本都需要进行表示,并比较它们的语义相似性。这两者的表示形式通常是嵌入向量,而相似性度量(如余弦相似度或预训练分类器)则输出文本/句子被分类为某个类别的概率。
训练这种模型有许多方法,其中最早的方法是使用从互联网上抓取的包含关键词标签的网页元数据。
而除了使用大规模数据集外,还有一些语言模型,如 BART,使用多领域自然语言推理 (Multi-Genre Natural Language Inference, MultiNLI) 数据集进行微调,并检测两个不同句子之间的关系。此外,Hugging Face 模型库中包含了许多已实现的零样本学习模型,并提供了零样本学习管道 (pipeline)。
(1) 在开始实现之前,首先需要安装 transformers[sentencepiece]:
shell
$ pip install transformers[sentencepiece](2) 例如,Meta 的 FAIR 开发的 BART 模型,可以使用以下代码执行零样本文本分类:
python
from transformers import pipeline
import pandas as pd
classifier = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli")
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel',
'cooking',
'dancing',
'exploration']
result = classifier(sequence_to_classify, candidate_labels)
pd.DataFrame(result)输出结果如下所示:

可以看到,travel 和 exploration 这两个标签的概率最高,而其中 travel 的概率最大。
(3) 然而,有时一个样本可以属于多个类别(多标签)。Hugging Face 提供了参数 multi_label 来处理这个问题。使用该参数:
python
result = classifier(sequence_to_classify,
candidate_labels,
multi_label=True)
pd.DataFrame(result)使用 multi_lable 参数后,输出结果如下:

可以进一步测试结果,观察如果使用与 Travel 标签非常相似的标签,模型的表现如何。例如,可以查看如果将移动 (moving) 和去 (going) 添加到标签列表中,模型的表现如何。
还有一些模型利用标签与上下文之间的语义相似性来执行零样本分类。在少样本学习的情况下,模型会接收一些样本,但这些样本不足以单独训练模型。模型可以利用这些样本来执行任务,例如语义文本聚类。
(4) 我们已经学习了如何使用BART进行零样本学习,接下来了解它的工作原理。BART 在自然语言推理 (Natural Language Inference, NLI) 数据集(如 MultiNLI )上进行了微调。这些数据集包含句子对以及每个句子对的三个类别标签:中立 (Neutral)、蕴含 (Entailment) 和矛盾 (Contradiction)。在这些数据集上训练的模型可以捕捉两个句子的语义,并通过分配独热编码格式的标签对它们进行分类。如果去掉中立标签,只使用蕴含和矛盾作为输出标签,那么如果两个句子可以相互衔接,就意味着它们在语义上密切相关。换句话说,可以将第一个句子变为标签(例如 Travel),将第二个句子变为内容(例如 one day I will see the world)。如果这两者可以相互衔接,就意味着标签和内容在语义上是相关的。以下代码展示了如何直接使用 BART 模型,而不使用零样本分类管道:
python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
nli_model = AutoModelForSequenceClassification.from_pretrained("facebook/bart-large-mnli")
tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-mnli")
premise = "one day I will see the world"
label = "travel"
hypothesis = f'This example is {label}.'
x = tokenizer.encode(
premise,
hypothesis,
return_tensors='pt',
truncation=True)
logits = nli_model(x)[0]
entail_contradiction_logits = logits[:,[0,2]]
probs = entail_contradiction_logits.softmax(dim=1)
prob_label_is_true = probs[:,1]
print(prob_label_is_true) 输出结果如下所示:
shell
tensor([0.9945], grad_fn=<SelectBackward0>)也可以将第一个句子称为假设 (hypothesis),将包含标签的句子称为前提 (premise)。根据结果,如果前提可以蕴含假设,则表示前提为假设的标签。
小结
在本节中,我们了解了文本表示 (Text Representation) 方法。我们学习了如何使用不同的语义模型执行零样本、少样本和单样本学习等任务。我们还了解了自然语言推理 (Natural Language Inference, NLI) 及其在捕捉文本语义中的重要性。这些技术为语义搜索、语义聚类等场景提供了高效解决方案,平衡了计算效率与语义精度。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务