文章目录
- [1 概述](#1 概述)
- [2 FoundationStereo Dataset](#2 FoundationStereo Dataset)
- [3 网络结构](#3 网络结构)
-
- [3.1 Side-Tuning Adapter](#3.1 Side-Tuning Adapter)
- [3.2 Attentive Hybrid Cost Filtering](#3.2 Attentive Hybrid Cost Filtering)
-
- [3.2.1 混合代价体构建](#3.2.1 混合代价体构建)
- [3.2.2 轴平面卷积滤波(APC)](#3.2.2 轴平面卷积滤波(APC))
- [3.2.3 Disparity Transformer(DT)](#3.2.3 Disparity Transformer(DT))
- [4 效果](#4 效果)
- 参考资料
1 概述
由于训练数据集的激增和深度神经网络架构的进步,最近的立体匹配算法可以取得惊人的结果,几乎使最具挑战性的基准测试饱和。然而,对目标域的数据集进行微调仍然是获得有竞争力的结果的首选方法。鉴于通过scaling law在计算机视觉中的其他问题上表现出的零样本泛化能力,是什么阻止了立体匹配算法实现类似的泛化水平?作者认为,无法实现零样本泛化能力,要么是网络架构的结构不足,要么是训练数据贫乏,或者两者兼而有之。
FoundationStereo从网络结构和数据集两个方面进行创新,得到了零样本泛化能力极强的立体匹配模型。
在数据集方面 ,本文创建了一个大规模 (1M) 高保真合成数据集FSD(FoundationStereo Dataset),用于立体匹配学习。该数据集的数据具有高多样性和照片级真实感。合成数据中会存在许多不良样本,本文也提出了一个自修正流程,用来修正数据集。
在网络结构方面 ,本文提出了用于结合单目深度估计模型特征的适配器STA(Side-Tuning Adapter)和更强大的代价过滤模块Attentive Hybrid Cost Filtering(AHCF)。
网络的整体架构和IGEV类似,最好先了解下。
2 FoundationStereo Dataset
作者使用 NVIDIA Omniverse 创建了一个大规模合成训练数据集。此 FoundationStereo 数据集 (FSD) 主要是为了解决了关键的立体匹配挑战,例如反射、低纹理表面和严重遮挡。作者进行域随机化以增强数据集的多样性,包括随机基线距离、焦距、相机视角、照明条件和对象配置。同时,利用具有丰富纹理和路径跟踪渲染的高质量 3D 资产来增强渲染和布局的真实感。图2-1展示了数据集中的一些样本,包括结构化的室内和室外场景,以及在复杂而逼真的照明下具有各种几何形状和纹理的更多样化的随机飞行物体。

图2-1 FSD数据集示例
虽然合成数据生成理论上可以产生无限量的数据并通过随机化实现较大的多样性,但不可避免地会引入歧义,尤其是对于具有飞行物体的结构化程度较低的场景,这会使学习过程感到困惑。图2-2演示了此过程并检测到模棱两可的图例,第一行是整图的重复纹理;第二行是相机距离物体太近,导致参考较少;第三行是边界不完整的纯色背景。这些例子,即使人也无法判断哪两个像素点是匹配的。

图2-2 模棱两可的图例
为了消除这些样本,设计了一个自动迭代自修正策略。
首先在 FSD 上训练 FoundationStereo 的初始版本,然后在 FSD 上对其进行评估。BP-2大于 60% 的样本被视为不明确样本,并被重新生成的新样本取代。训练和修正过程交替进行,以迭代方式(在本文的例子中为两次)更新 FSD 和 FoundationStereo。
"BP-X" 表示计算视差误差大于X像素的像素百分比。
数据集生成基于 NVIDIA Omniverse 构建。使用每像素 32 到 128 个样本的 RTX 路径追踪,以实现高保真逼真的渲染。数据生成在 48 个 NVIDIA A40 GPU 上执行,为期 10 天。从不同来源收集了超过 5K 的对象资产,包括艺术家设计和具有高频几何细节的 3D 扫描。对象资产分为以下几组:家具、开放式容器、车辆、机器人、地板胶带、独立墙壁、楼梯、植物、叉车、动态动画数字人、其他障碍物和干扰物。每个组都定义了一个单独的随机化范围,用于采样位置、比例和外观。此外,还策划了 12 个大型场景模型、16 个天空盒图像、150 多种材质和 400 个纹理,用于在对象几何图形上平铺包裹,以增强外观。这些纹理是从真实世界的照片和程序生成的随机图案中获得的。图2-3是场景的示例,其中第三列表示了随机的金属材质,第四列表示了真实场景和虚拟场景的对比。

图2-3 合成数据场景示例
对于每个数据样本,首先对立体基线相机焦距进行随机采样,以多样化视野和视差分布的覆盖范围。接下来,以两种不同的方法将对象生成到场景中,以随机化场景配置:
1)以随机姿势生成摄像机,并在随机位置相对于摄像机添加对象
2)对象在随机位置附近生成,摄像机在附近生成并朝向对象杂波的质心。
以两种样式生成布局:混乱和现实。这种更逼真的结构化布局与飞行物体的更随机设置的这种组合已被证明有利于模拟到现实的泛化。具体来说,混沌风格的场景涉及大量的飞行干扰物和简单的场景布局,其中包括无限远的天空盒和一个背景平面。光照和对象外观(纹理和材质)是高度随机的。真实风格数据使用室内和室外场景模型,其中照相机被限制在预定义区域。对象资源被丢弃并应用于物理属性以进行碰撞。模拟在 0.25 到 2 秒之间随机执行,以创建物理上逼真的布局,没有穿透,涉及固定和掉落的物体。保留对象资产原生的材质和缩放,并应用更自然的照明。
光源类型包括全局照明、定向天空光线、烘焙到 3D 扫描资产中的光源,以及在表面附近生成时添加动态照明的球体。灯光颜色、强度和方向是随机的。白天、黄昏和黑夜等照明氛围包含在随机采样范围内。
图2-4展示了 FSD 数据集的视差分布。
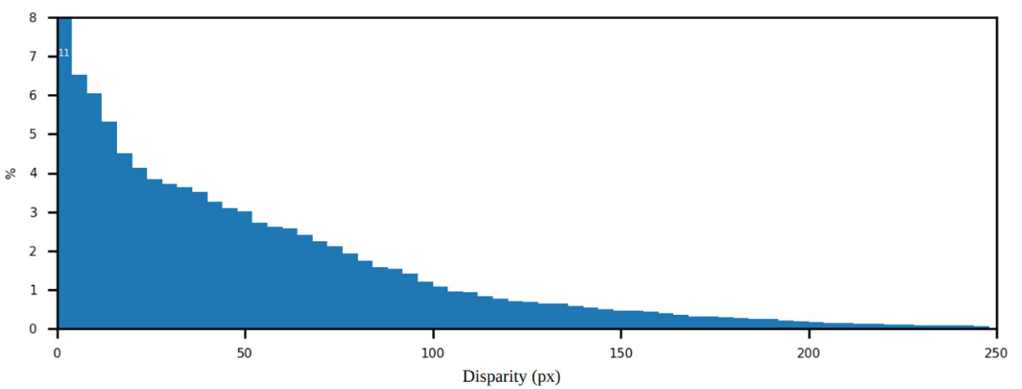
图2-4 FSD数据集的视差分布
3 网络结构
整个网络结构如图3-1所示,主要的创新点就在Side-Tuning CNN和AHCF这两个部分,其余部分可以参考IGEV。
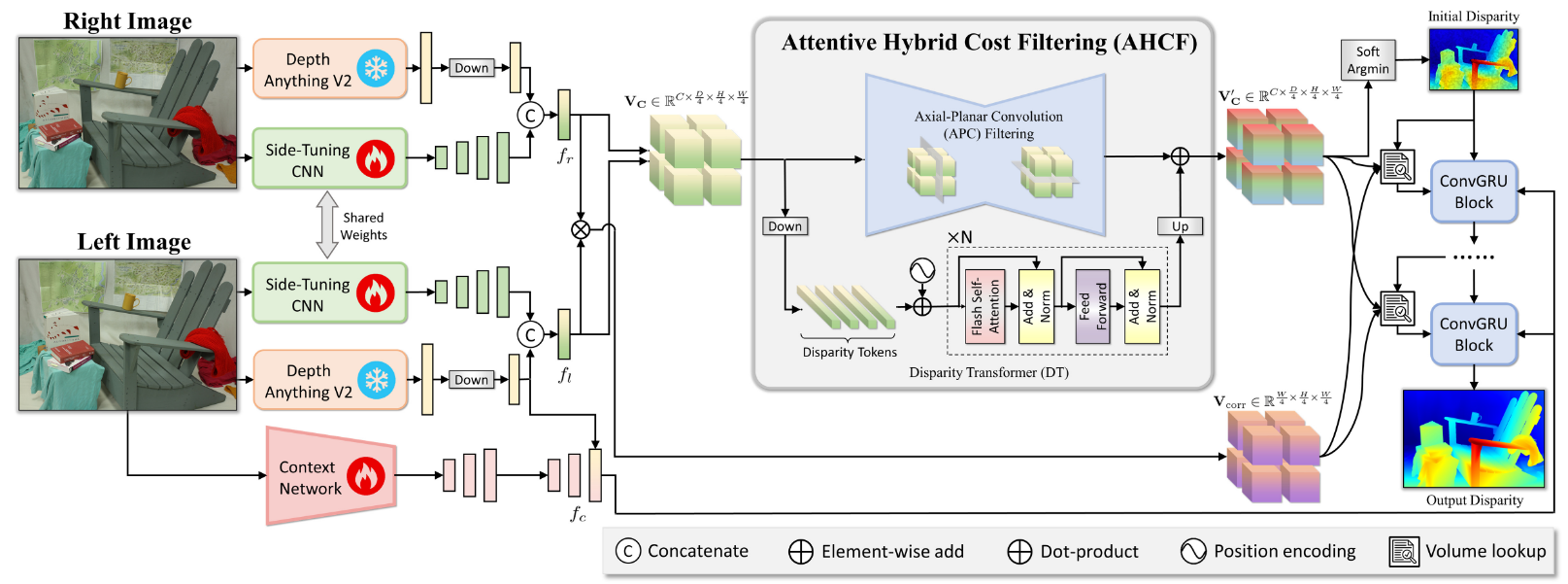
图3-1 整体网络结构
3.1 Side-Tuning Adapter
当立匹配体网络主要在合成数据集上训练时,为了减少sim2real的差距,利用了在互联网规模的真实数据上训练的单目深度估计模型。作者使用 CNN 网络将基于 ViT 的单目深度估计网络适配到立体匹配网络,从而协同 CNN 和 ViT 架构的优势。
作者探索了结合 CNN 和 ViT 方法的多种设计选择,如图3-2所示。
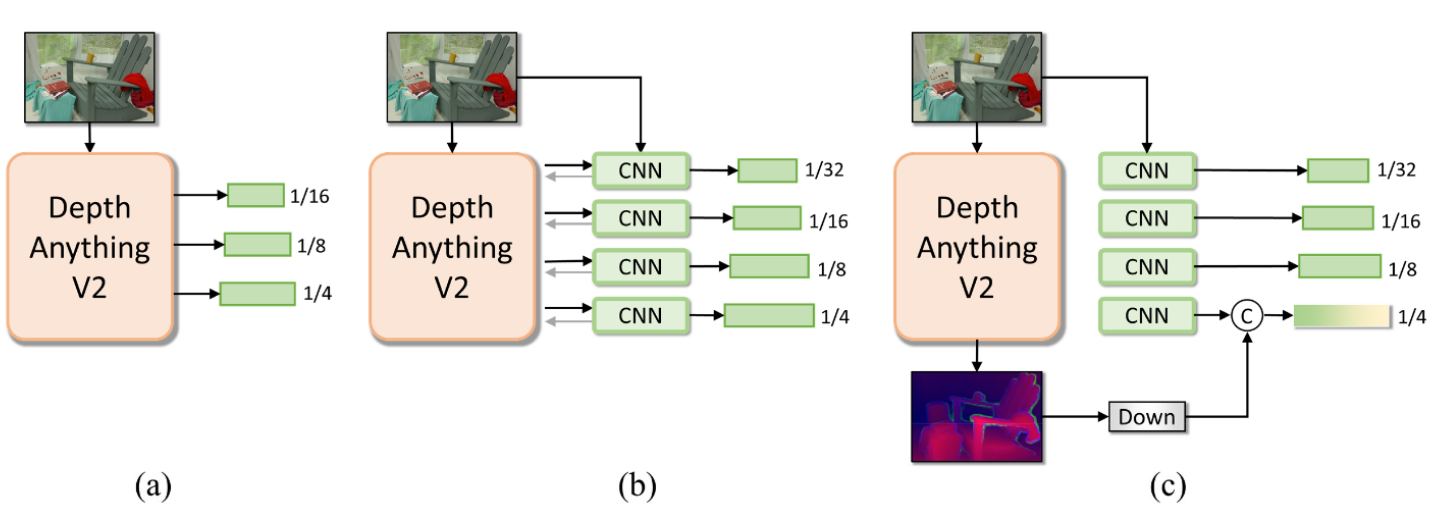
图3-2 CNN和ViT结合设计
(a)在冻结的 DepthAnythingV2 中直接使用来自 DPT 头部的特征金字塔,而不使用 CNN 特征
(b)通过在 CNN 和 ViT 之间交换特征来类似于 ViT 适配器
(c) 应用步幅4的 4 × 4 4×4 4×4卷积,以在 DepthAnythingV2 最终输出头之前缩小特征。然后将该特征与相同级别的 CNN 特征连接起来,以获得 1/4 比例的混合特征。其中,CNN网络部分被训练,以使最终特征适应立体匹配任务。
令人惊讶的是,虽然很简单,但作者发现(c)明显超过了其他两种方案。因此,采用(c)作为 STA 模块的主要设计。
具体来说,给定一对左右图像 I l I_l Il 和 I r ∈ R H × W × 3 I_r∈R^{H×W×3} Ir∈RH×W×3 ,采用EdgeNeXt-S作为 STA 中的 CNN 模块来提取多级金字塔特征,其中 1/4 级特征配备了 DepthAnythingV2 特征: f l ( i ) , f r ( i ) ∈ R C i × H i × W i , i ∈ { 4 , 8 , 16 , 32 } f^{(i)}_l, f^{(i)}_r ∈ R^{C_i× \frac{H}{i}×\frac{W}{i}}, i∈\{4, 8, 16, 32\} fl(i),fr(i)∈RCi×iH×iW,i∈{4,8,16,32} 。选择EdgeNeXt-S是因为它的内存效率,而且在本文的研究中,更大的 CNN 主干没有产生额外的好处。前向到 DepthAnythingV2 时,作者首先将图像大小调整为可被 14 整除,以与其预训练的补丁大小保持一致。STA 权重在应用于 I l I_l Il, I r I_r Ir 时共享。
同样,使用 STA 来提取上下文特征,不同之处在于 CNN 模块设计有一系列残差块和下采样层。注意,这里只有CNN部分,没有DepthAnythingV2的部分了,这从图3-1也可以看出来,Context Network是整个模块都需要训练的。
它生成多个尺度的上下文特征: f c ( i ) ∈ R C i × H i × W i , i ∈ { 4 , 8 , 16 } f^{(i)}_c∈R^{C_i×\frac{H}{i}×\frac{W}{i}},i∈\{4, 8, 16\} fc(i)∈RCi×iH×iW,i∈{4,8,16} 。 f c f_c fc 参与初始化 ConvGRU 模块的隐状态特征,并在每次迭代时输入到 ConvGRU 区块中,以逐步细化的上下文信息有效指导迭代过程。图3-3可视化了丰富的单目先验的力量,它有助于可靠地预测模糊区域,这很难通过沿外极线的直接对应搜索来处理。

图3-3 有无STA可视化示例
可以看出图3-3中左图和右图的光照条件是不同的,特别是左图右上角的过曝区域,STA可以通过单目深度估计提供的特征来恢复相对准确的深度值。
我们从代码上来看下抽取左右图特征的STA的具体实现,代码只截取了和STA相关的部分,添加了便于理解的注释,代码中的DINO就是DepthAnythingV2的特征抽取部分。与其说是在DepthAnythingV2的基础上,增加了一路CNN分支;对比IGEV部分的代码,不如说在IGEV的架构上,增加了一路ViT分支。
python
class FoundationStereo(nn.Module, huggingface_hub.PyTorchModelHubMixin):
def __init__(self, args):
# STA就在Feature模块中
self.feature = Feature(args)
def forward(self, image1, image2, iters=12, flow_init=None, test_mode=False, low_memory=False, init_disp=None):
with autocast(enabled=self.args.mixed_precision):
# 抽取左右图的特征,这里是把image1和image2拼接起来抽取特征的,IGEV中是用self.feature分别抽取的
out, vit_feat = self.feature(torch.cat([image1, image2], dim=0))
class Feature(nn.Module):
def __init__(self, args):
super(Feature, self).__init__()
self.args = args
# 使用timm库加载预训练的edgenext_small模型作为基础特征提取器
model = timm.create_model('edgenext_small', pretrained=True, features_only=False)
self.stem = model.stem
self.stages = model.stages
# 各阶段输出通道数配置
chans = [48, 96, 160, 304]
self.chans = chans
# 初始化DepthAnything(DINO)特征提取器并冻结参数
self.dino = DepthAnythingFeature(encoder=self.args.vit_size)
self.dino = freeze_model(self.dino)
vit_feat_dim = DepthAnythingFeature.model_configs[self.args.vit_size]['features']//2
# 定义反卷积层用于特征上采样与融合 (32→16→8→4倍下采样)
self.deconv32_16 = Conv2x_IN(chans[3], chans[2], deconv=True, concat=True)
self.deconv16_8 = Conv2x_IN(chans[2]*2, chans[1], deconv=True, concat=True)
self.deconv8_4 = Conv2x_IN(chans[1]*2, chans[0], deconv=True, concat=True)
# 特征融合后的处理模块
self.conv4 = nn.Sequential(
BasicConv(chans[0]*2+vit_feat_dim, chans[0]*2+vit_feat_dim, kernel_size=3, stride=1, padding=1, norm='instance'),
ResidualBlock(chans[0]*2+vit_feat_dim, chans[0]*2+vit_feat_dim, norm_fn='instance'),
ResidualBlock(chans[0]*2+vit_feat_dim, chans[0]*2+vit_feat_dim, norm_fn='instance'),
)
# DINO模型的 patch size
self.patch_size = 14
# 输出通道数配置
self.d_out = [chans[0]*2+vit_feat_dim, chans[1]*2, chans[2]*2, chans[3]]
def forward(self, x):
B,C,H,W = x.shape
# 计算图像调整尺寸 (确保能被14x16=224整除)
divider = np.lcm(self.patch_size, 16)
H_resize, W_resize = get_resize_keep_aspect_ratio(H,W, divider=divider, max_H=1344, max_W=1344)
x_in_ = F.interpolate(x, size=(H_resize, W_resize), mode='bicubic', align_corners=False)
# 单目深度估计特征
# 使用DINO模型提取视觉Transformer特征 (冻结参数)
self.dino = self.dino.eval()
with torch.no_grad():
output = self.dino(x_in_)
vit_feat = output['out']
# 将DINO特征插值到1/4原图尺寸,与CNN特征对齐
vit_feat = F.interpolate(vit_feat, size=(H//4,W//4), mode='bilinear', align_corners=True)
# 新增的CNN适配器特征
# CNN特征提取 (edgenext_small)
x = self.stem(x)
x4 = self.stages[0](x) # 1/4尺度特征
x8 = self.stages[1](x4) # 1/8尺度特征
x16 = self.stages[2](x8) # 1/16尺度特征
x32 = self.stages[3](x16) # 1/32尺度特征
# 特征上采样与融合 (自底向上)
x16 = self.deconv32_16(x32, x16) # 32倍→16倍特征融合
x8 = self.deconv16_8(x16, x8) # 16倍→8倍特征融合
x4 = self.deconv8_4(x8, x4) # 8倍→4倍特征融合
# 融合CNN特征与Transformer特征
x4 = torch.cat([x4, vit_feat], dim=1) # 通道维度拼接
x4 = self.conv4(x4) # 融合后特征处理
# 返回多尺度特征 [4倍, 8倍, 16倍, 32倍下采样] 和Transformer特征
return [x4, x8, x16, x32], vit_featContext Network这部分的代码就留给读者自行阅读了,这里不展示了,可以参见ContextNetDino。这部分其实并没有Dino,作者取名叫ContextNetDino其实有点奇怪。
3.2 Attentive Hybrid Cost Filtering
3.2.1 混合代价体构建
给定从上一步中提取的 1/4 尺度的一元特征 f l 4 f^4_l fl4 和 f r 4 f^4_r fr4 ,作者构建了代价体 V C ∈ R C × D 4 × H 4 × W 4 V_C∈R^{C×\frac{D}{4}×\frac{H}{4}×\frac{W}{4}} VC∈RC×4D×4H×4W,如下式3-1。
V g w c ( g , d , h , w ) = < f ^ l , g ( 4 ) ( h , w ) , f ^ r , g ( 4 ) ( h , w − d ) > V c a t ( d , h , w ) = C o n v ( f l ( 4 ) ) ( h , w ) , C o n v ( f r ( 4 ) ) ( h , w − d ) V C ( d , h , w ) = V g w c ( g , d , h , w ) , V c a t ( d , h , w ) (3-1) V_{gwc} (g,d,h,w) = <\hat{f}{l, g}^{(4)}(h, w), \hat{f}{r, g}^{(4)}(h, w-d)> \\ V_{cat}(d, h, w) = Conv(f_l\^{(4)})(h, w), Conv(f_r\^{(4)})(h, w - d) \\ V_C(d, h, w) = V_{gwc} (g,d,h,w), V_{cat}(d, h, w) \tag{3-1} Vgwc(g,d,h,w)=<f^l,g(4)(h,w),f^r,g(4)(h,w−d)>Vcat(d,h,w)=Conv(fl(4))(h,w),Conv(fr(4))(h,w−d)VC(d,h,w)=Vgwc(g,d,h,w),Vcat(d,h,w)(3-1)
其中, f ^ \hat{f} f^ 表示 L 2 L_2 L2 归一化特征,具有更好的训练稳定性; ⟨ ⋅ , ⋅ ⟩ ⟨·, ·⟩ ⟨⋅,⋅⟩ 表示点积, g ∈ { 1 , 2 , . . . , G } g∈\{1, 2, ..., G\} g∈{1,2,...,G}是总 G = 8 G=8 G=8 个特征组中的组索引,将总特征均匀划分为这些特征; d ∈ { 1 , 2 , . . . , D 4 } d∈\{1, 2, ..., \frac{D}{4}\} d∈{1,2,...,4D} 是视差索引。 ⋅ , ⋅ ·, · ⋅,⋅ 表示沿通道维度的串联。按组关联 V g w c V_{gwc} Vgwc 利用了传统的基于相关性的匹配成本的优势,提供了来自每个组的不同相似度测量特征。 V c a t V_{cat} Vcat 通过在移位视差处连接左和右特征来保留特征,包括丰富的单目先验。为了减少内存消耗,在连接之前使用核大小为1的卷积(权重在 f l 4 f^4_l fl4 和 f r 4 f^4_r fr4 之间共享)将特征维度线性缩小到14。
这部分的代码如下所示,只截取了相关部分。
python
class FoundationStereo(nn.Module, huggingface_hub.PyTorchModelHubMixin):
def forward(self, image1, image2, iters=12, flow_init=None, test_mode=False, low_memory=False, init_disp=None):
with autocast(enabled=self.args.mixed_precision):
# 构建 V_{gwc}, 组相关体(B, N_group, max_disp, H, W)
gwc_volume = build_gwc_volume(features_left[0], features_right[0], self.args.max_disp//4, self.cv_group)
# 构建 V_{cat}
left_tmp = self.proj_cmb(features_left[0])
right_tmp = self.proj_cmb(features_right[0])
concat_volume = build_concat_volume(left_tmp, right_tmp, maxdisp=self.args.max_disp//4)
del left_tmp, right_tmp
# 构建 V_C
comb_volume = torch.cat([gwc_volume, concat_volume], dim=1)
def groupwise_correlation(fea1, fea2, num_groups):
B, C, H, W = fea1.shape
assert C % num_groups == 0, f"C:{C}, num_groups:{num_groups}"
channels_per_group = C // num_groups
fea1 = fea1.reshape(B, num_groups, channels_per_group, H, W)
fea2 = fea2.reshape(B, num_groups, channels_per_group, H, W)
with torch.cuda.amp.autocast(enabled=False):
# 对L2归一化特征进行点积
cost = (F.normalize(fea1.float(), dim=2) * F.normalize(fea2.float(), dim=2)).sum(dim=2) #!NOTE Divide first for numerical stability
assert cost.shape == (B, num_groups, H, W)
return cost
def build_gwc_volume(refimg_fea, targetimg_fea, maxdisp, num_groups, stride=1):
"""
@refimg_fea: left image feature
@targetimg_fea: right image feature
"""
B, C, H, W = refimg_fea.shape
volume = refimg_fea.new_zeros([B, num_groups, maxdisp, H, W])
for i in range(maxdisp):
if i > 0:
volume[:, :, i, :, i:] = groupwise_correlation(refimg_fea[:, :, :, i:], targetimg_fea[:, :, :, :-i], num_groups)
else:
volume[:, :, i, :, :] = groupwise_correlation(refimg_fea, targetimg_fea, num_groups)
volume = volume.contiguous()
return volume
def build_concat_volume(refimg_fea, targetimg_fea, maxdisp):
B, C, H, W = refimg_fea.shape
volume = refimg_fea.new_zeros([B, 2 * C, maxdisp, H, W])
for i in range(maxdisp):
if i > 0:
volume[:, :C, i, :, :] = refimg_fea[:, :, :, :]
volume[:, C:, i, :, i:] = targetimg_fea[:, :, :, :-i]
else:
volume[:, :C, i, :, :] = refimg_fea
volume[:, C:, i, :, :] = targetimg_fea
volume = volume.contiguous()
return volume3.2.2 轴平面卷积滤波(APC)
一个由 3D 卷积组成的沙漏网络,具有三个下采样块和三个带有残差连接的上采样块,用于代价体聚合。虽然核大小为 3 × 3 × 3 3×3×3 3×3×3的 3D 卷积通常用于相对较小的视差大小,但作者观察到,当应用于高分辨率图像时,它不利于较大的视差。但是,由于内存消耗很大,直接增加内核大小是不切实际的。事实上,即使将内核大小设置为 5 × 5 × 5 5×5×5 5×5×5,也会观察到80G的GPU上的内存使用情况难以管理。这极大地限制了模型在扩展大量训练数据时的表示能力。因此,开发了"轴向平面卷积",它将单个 3 × 3 × 3 3×3×3 3×3×3 卷积解耦为两个单独的卷积:一个在空间维度上(核大小 K s × K s × 1 K_s×K_s×1 Ks×Ks×1 ),另一个在视差上( 1 × 1 × K d 1×1×K_d 1×1×Kd ),每个卷积后跟 BatchNorm 和 ReLU。APC 可以看作是 3D 版本的可分离卷积,不同之处在于只分离空间和视差维度,而不将通道细分为牺牲表示能力的组。视差维度是通过比较相关性得到的,因此在这里单独分离。作者在沙漏网络中尽可能使用APC,但下采样和上采样层除外。
其相关代码如下所示,核心实现在Conv3dNormActReduced这个类中,使用是在hourglass中,其实就是把IGEV中BasicConv替换为了Conv3dNormActReduced。
python
class FoundationStereo(nn.Module, huggingface_hub.PyTorchModelHubMixin):
def __init__(self, args):
self.cost_agg = hourglass(cfg=self.args, in_channels=volume_dim, feat_dims=self.feature.d_out)
def forward(self, image1, image2, iters=12, flow_init=None, test_mode=False, low_memory=False, init_disp=None):
with autocast(enabled=self.args.mixed_precision):
comb_volume = self.cost_agg(comb_volume, features_left)
class hourglass(nn.Module):
def __init__(self, cfg, in_channels, feat_dims=None):
super().__init__()
self.cfg = cfg
self.conv1 = nn.Sequential(
BasicConv(in_channels, in_channels*2, is_3d=True, bn=True, relu=True, kernel_size=3, padding=1, stride=2, dilation=1),
Conv3dNormActReduced(in_channels*2, in_channels*2, kernel_size=3, kernel_disp=17)
)
self.conv2 = nn.Sequential(
BasicConv(in_channels*2, in_channels*4, is_3d=True, bn=True, relu=True, kernel_size=3, padding=1, stride=2, dilation=1),
Conv3dNormActReduced(in_channels*4, in_channels*4, kernel_size=3, kernel_disp=17)
)
self.conv3 = nn.Sequential(BasicConv(in_channels*4, in_channels*6, is_3d=True, bn=True, relu=True, kernel_size=3,
padding=1, stride=2, dilation=1),
Conv3dNormActReduced(in_channels*6, in_channels*6, kernel_size=3, kernel_disp=17))
self.conv_out = nn.Sequential(
Conv3dNormActReduced(in_channels, in_channels, kernel_size=3, kernel_disp=17),
Conv3dNormActReduced(in_channels, in_channels, kernel_size=3, kernel_disp=17),
)
self.agg_0 = nn.Sequential(
BasicConv(in_channels*8, in_channels*4, is_3d=True, kernel_size=1, padding=0, stride=1),
Conv3dNormActReduced(in_channels*4, in_channels*4, kernel_size=3, kernel_disp=17),
Conv3dNormActReduced(in_channels*4, in_channels*4, kernel_size=3, kernel_disp=17),
)
self.agg_1 = nn.Sequential(
BasicConv(in_channels*4, in_channels*2, is_3d=True, kernel_size=1, padding=0, stride=1),
Conv3dNormActReduced(in_channels*2, in_channels*2, kernel_size=3, kernel_disp=17),
Conv3dNormActReduced(in_channels*2, in_channels*2, kernel_size=3, kernel_disp=17)
)
class Conv3dNormActReduced(nn.Module):
def __init__(self, C_in, C_out, hidden=None, kernel_size=3, kernel_disp=None, stride=1, norm=nn.BatchNorm3d):
super().__init__()
# 空间维度
self.conv1 = nn.Sequential(
nn.Conv3d(C_in, hidden, kernel_size=(1,kernel_size,kernel_size), padding=(0, kernel_size//2, kernel_size//2), stride=(1, stride, stride)),
norm(hidden),
nn.ReLU(),
)
# 视差维度
self.conv2 = nn.Sequential(
nn.Conv3d(hidden, C_out, kernel_size=(kernel_disp, 1, 1), padding=(kernel_disp//2, 0, 0), stride=(stride, 1, 1)),
norm(C_out),
nn.ReLU(),
)
def forward(self, x):
"""
@x: (B,C,D,H,W)
"""
x = self.conv1(x)
x = self.conv2(x)
return x3.2.3 Disparity Transformer(DT)
作者引入 DT 以进一步增强 4D 代价体中的远程上下文推理 。给定在式3-1中获得的 V C V_C VC ,首先应用一个核大小为 4 × 4 × 4 4×4×4 4×4×4 的 3D 卷积,步幅为4,以缩小代价体。然后,将代价体重塑为一批标记序列,每个序列都有视差长度。在将其馈送到一系列(在本例中为 4) transformer encoder block之前,应用位置编码,其中利用 FlashAttention来执行多头自注意力。该过程可以写成
Q 0 = P E ( R ( C o n v 4 × 4 × 4 ( V C ) ) ) ∈ R ( H 16 × W 16 ) × C × D 16 M u l t i H e a d ( Q , K , V ) = h e a d 1 , . . . , h e a d h W O w h e r e h e a d i = F l a s h A t t e n t i o n ( Q i , K i , V i ) Q 1 = N o r m ( M u l t i H e a d ( Q 0 , Q 0 , Q 0 ) + Q 0 ) Q 2 = N o r m ( F F N ( Q 1 ) + Q 1 ) (3-2) Q_0 = PE(R(Conv_{4\times4\times4}(V_C))) \in R^{(\frac{H}{16} \times \frac{W}{16}) \times C \times \frac{D}{16}}\\ MultiHead(Q, K, V) = head_1, ..., head_hW_O\\ where\ head_i = FlashAttention(Q_i, K_i, V_i)\\ Q_1 = Norm(MultiHead(Q_0, Q_0, Q_0) + Q_0)\\ Q_2 = Norm(FFN(Q_1) + Q_1) \tag{3-2} Q0=PE(R(Conv4×4×4(VC)))∈R(16H×16W)×C×16DMultiHead(Q,K,V)=head1,...,headhWOwhere headi=FlashAttention(Qi,Ki,Vi)Q1=Norm(MultiHead(Q0,Q0,Q0)+Q0)Q2=Norm(FFN(Q1)+Q1)(3-2)
其中, R ( ⋅ ) R(·) R(⋅) 表示 reshape操作; P E ( ⋅ ) PE(·) PE(⋅) 表示位置编码; ⋅ , ⋅ ·, · ⋅,⋅ 表示沿通道维度的串联; W O W_O WO 是线性权重。在本文的例子中,正面数为 h = 4 h = 4 h=4 。最后,使用三线性插值将 D T DT DT 输出上采样到与 V C V_C VC 相同的大小,并与沙漏网络输出相加,如图3-1所示。
其相关代码如下所示。
python
class hourglass(nn.Module):
def __init__(self, cfg, in_channels, feat_dims=None):
self.atts = nn.ModuleDict({
"4": CostVolumeDisparityAttention(d_model=in_channels, nhead=4, dim_feedforward=in_channels, norm_first=False, num_transformer=4, max_len=self.cfg['max_disp']//16),
})
self.conv_patch = nn.Sequential(
nn.Conv3d(in_channels, in_channels, kernel_size=4, stride=4, padding=0, groups=in_channels),
nn.BatchNorm3d(in_channels),
)
def forward(self, x, features):
# 4x4x4的卷积核,缩小代价体
x = self.conv_patch(x)
x = self.atts["4"](x)
class CostVolumeDisparityAttention(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward, dropout=0.1, act=nn.GELU, norm_first=False, num_transformer=6, max_len=512, resize_embed=False):
super().__init__()
self.resize_embed = resize_embed
self.sa = nn.ModuleList([])
for _ in range(num_transformer):
self.sa.append(FlashAttentionTransformerEncoderLayer(embed_dim=d_model, num_heads=nhead, dim_feedforward=dim_feedforward, act=act, dropout=dropout))
self.pos_embed0 = PositionalEmbedding(d_model, max_len=max_len)
def forward(self, cv, window_size=(-1,-1)):
"""
@cv: (B,C,D,H,W) where D is max disparity
"""
x = cv
B,C,D,H,W = x.shape
x = x.permute(0,3,4,2,1).reshape(B*H*W, D, C)
# 位置编码
x = self.pos_embed0(x, resize_embed=self.resize_embed) #!NOTE No resize since disparity is pre-determined
# 多头注意力
for i in range(len(self.sa)):
x = self.sa[i](x, window_size=window_size)
x = x.reshape(B,H,W,D,C).permute(0,4,3,1,2)
return x4 效果
表4-1展示了四个公开真实世界数据集上零样本泛化结果的定量比较。即使仅在 Scene Flow 上进行训练,本文的方法在所有数据集中也始终优于比较方法,这要归功于从视觉基础模型中调整丰富的单目先验的有效性。
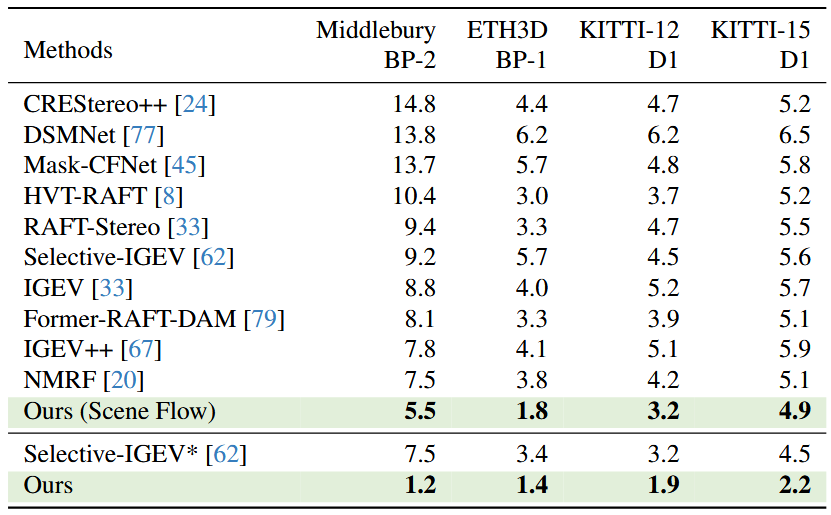
表4-1 SOTA模型零样本效果对比
图4-1展示了各种场景的定性比较,包括来自 DROID 数据集的机器人场景和涵盖室内和室外的自定义捕获。
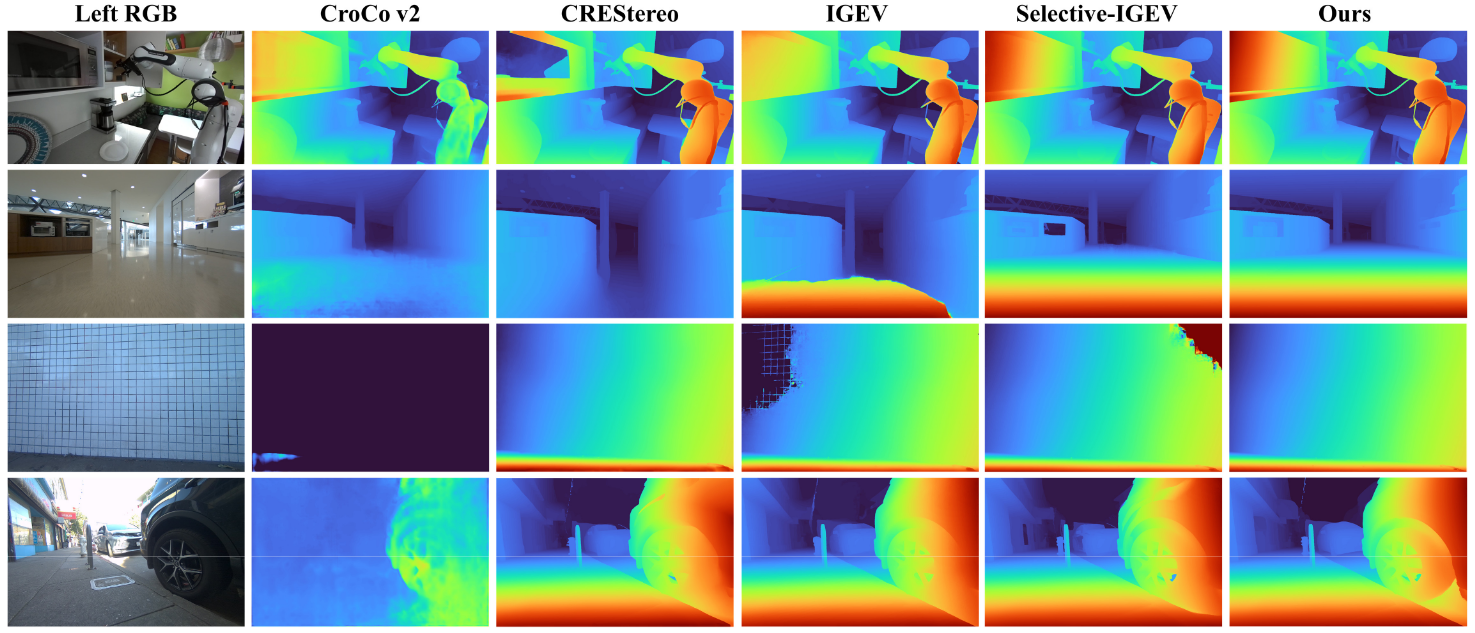
图4-1 SOTA模型不同场景可视化效果对比
表4-2显示了 SceneFlow 的定量比较,其中所有方法都遵循相同的官方划分的 train 和 test split。本文的 FoundationStereo 模型的性能大大优于比较方法,将之前的最佳 EPE 从 0.41 降低到 0.33。虽然域内训练不是这项工作的重点,但结果反映了本文模型设计的有效性。

表4-2 SOTA模型在SceneFlow数据集训练效果
表4-3显示了 ETH3D 测试集的定量比较。对于本文的方法,在两种设置中执行评估。首先,使用相同的学习率计划和数据增强,在默认训练数据集和 ETH3D 训练集的混合上微调本文的基础模型,以执行另外 50K 个步骤。本文的模型显著降低了一半以上的错误率,大大超越了之前的最佳方法,并在提交时在排行榜上排名第一。这表明,如果需要域内微调,本文的基础模型有较强的迁移能力。其次,作者还在不使用 ETH3D 的任何数据的情况下评估了本文的基础模型。值得注意的是,本文的基础模型的 zeroshot 推理取得了与执行域内训练的领先方法相当甚至更好的结果。
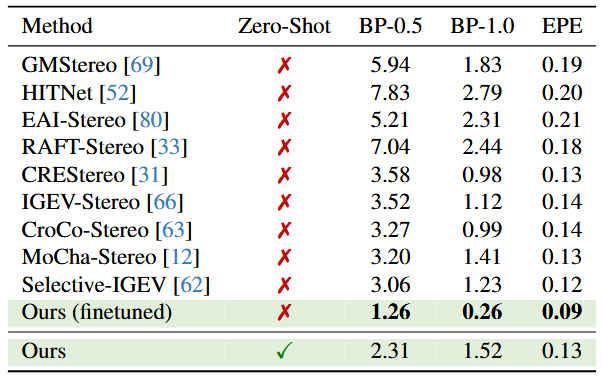
表4-3 SOTA模型在ETH-3D数据集的效果对比