
在高并发场景下,任务队列是削峰和线程间通信的重要手段,是线程池的重要组件,而我自己从零写了一个线程池,当我在优化性能的时候,降低锁粒度就成了必不可少的手段,在我一步一步的优化下,我写的线程池在锁竞争激烈的场景下吞吐量和稳定性都超过jdk线程池的50%,那么话不多说,具体来看我是如何一步步优化的。
1.全局锁改分离锁
在最开始我是用一个全局锁,包装了一个链表,当时和jdk的lbq对比的时候差距真是巨大。那么我就想着,自己也实现一个双锁分离的队列,中间也是踩了不少坑,但是最终还是写出来了,与jdk的lbq相比我的去掉了入队阻塞的那些逻辑,也就去掉了notFull的条件变量,但是逻辑是与jdk的差不多的(其实是因为自己写了好久没写出来,借鉴了一下)。
在这个队列写出来后与jdk的lbq性能就差不多了,但这不是我想要的,我是想要超越jdk的队列,我想到了改造成无锁出队(依旧踩了不少坑,甚至想过放弃),最后终于是实现了,但是性能还不如有锁的队列,仔细想想正是由于无锁化,并发量大,导致cas操作难以成功,所以开销更大了。我后来想着借鉴一下ConcurruntHashMap的分段锁思想,正当我准备行动,一个念头跑出来了,何不把分段"切断"呢?
2.分区化概念
分段锁是将一条队列分成好几段,但始终是在一个队列上操作,并且分段应该只能是建立在数组的基础上才能把性能发挥出来,如果是链表光找到相应的段的时间可能都比的上任务的执行时间了。
所以我的想法是将一条队列切断,分成多个队列,这样无论是数组还是链表都可以兼容。具体实现如下:
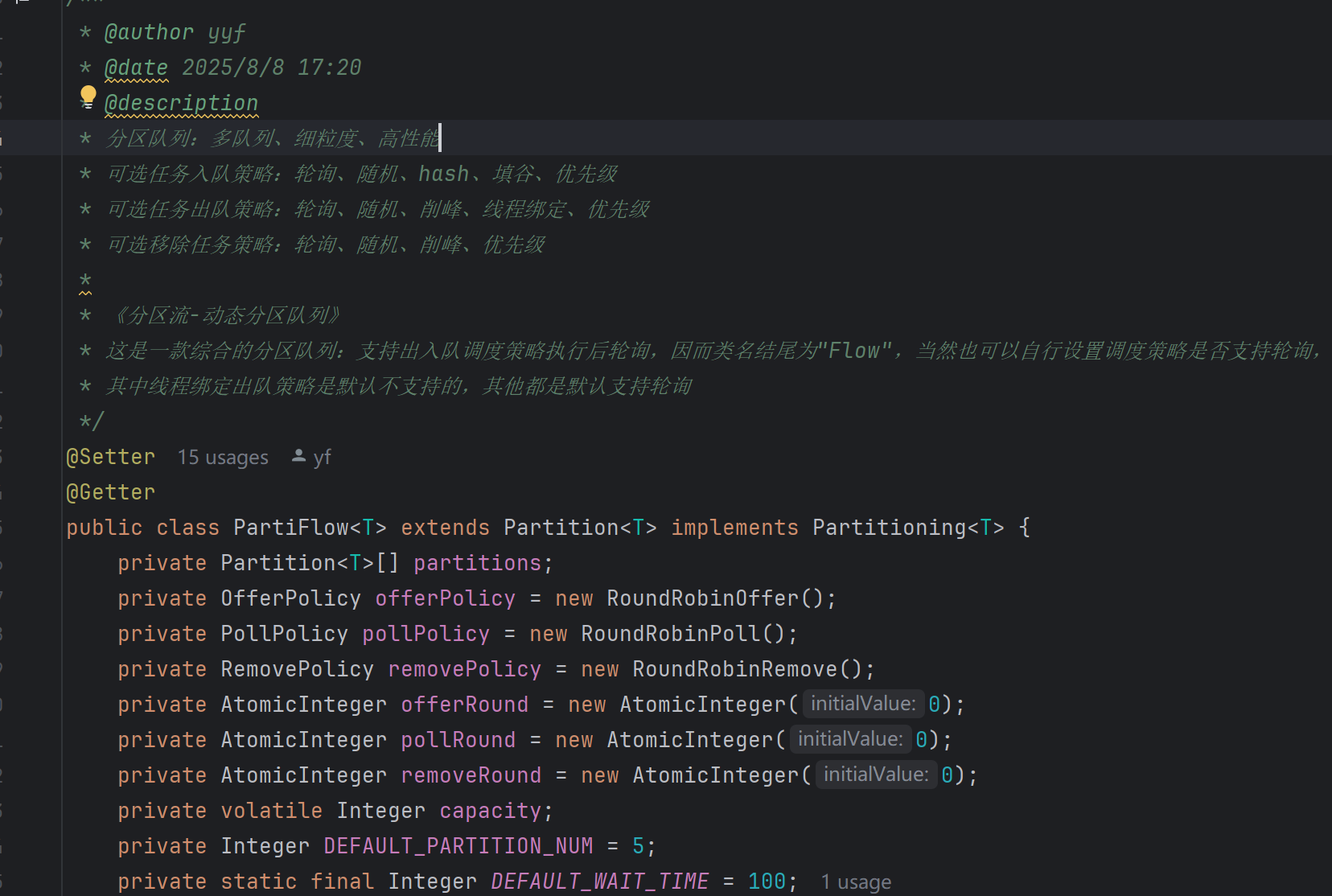
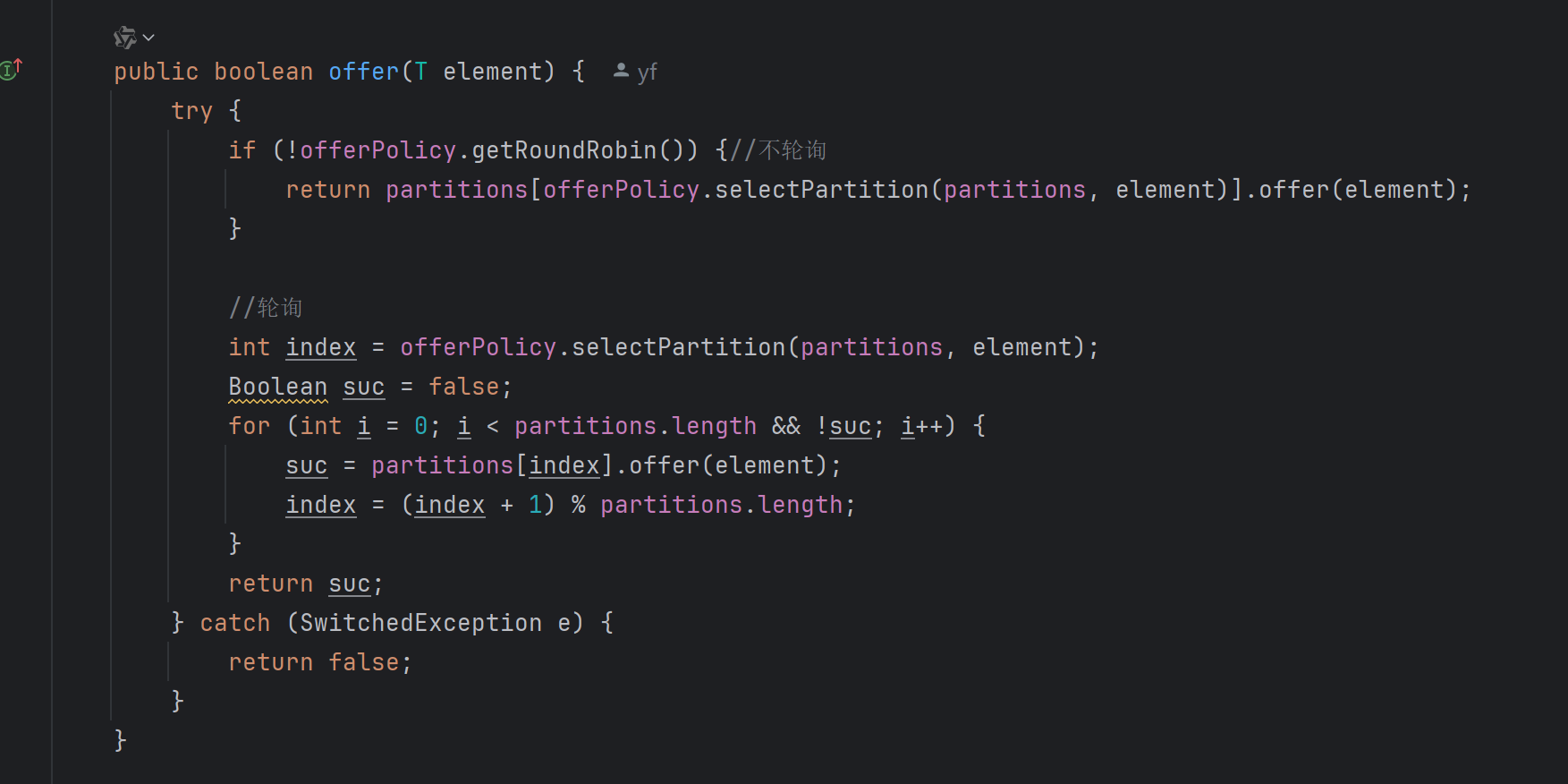
在我的项目中,队列都继承Partition(分区),分区可以进行分区化,而分区化就是用分区化队列(就是上方的PartiFlow,我还实现了一个PartiStill,两种分区化,前者可以选择在入队或者出队失败后轮询到下一个分区,后者性能为先,无论成功与否不给予轮询的选项)包装分区数组,Partitioning是分区化队列的顶级接口。
在这段代码中需要重要注意的是1、 partitions变量(队列数组,我后面都会称之为分区数组),2、offerPolicy、pollPolicy、removePolicy(入队调度规则、出队调度规则和移除调度规则)。首先要确定的是PartiFlow也继承了Partition,所以offer和poll方法他都有,在执行出入队的时候会利用对应的调度规则找到相应的分区,然后让分区执行出入队。
讲到这里,其实所谓分区化,就是利用组合模式,包装一个分区数组实现的锁粒度降低。那么有n个分区那么锁粒度就会是单个分区的1/n。但是分区太多也不一定好,太多分区就会造成有些调度策略执行时间过长,例如填谷和削峰策略,这两个是需要遍历所有分区的,所以分区越多,锁粒度是下降了,但是耗时上升起到反效果。另外我的项目中是建议大家分区是2的次幂。因为调度策略中有很多取余的操作,如果分区数量是2的幂次的话就可以直接和分区数量-1进行与运算,这样比直接使用%运算性能高不少。
3、调度策略
那么这就够了吗?在上方的分析中,我们可以得知,锁粒度被大幅度降低了,但是另一个问题出来了,调度策略成为性能瓶颈了。例如上方提到的填谷和削峰,这两个需要遍历所有的分区,时间复杂度为o(n)。轮询和随机都是o(1),但是前者是cas操作,竞争激烈的场景依旧容易降低性能,后者呢容易负载不均衡。
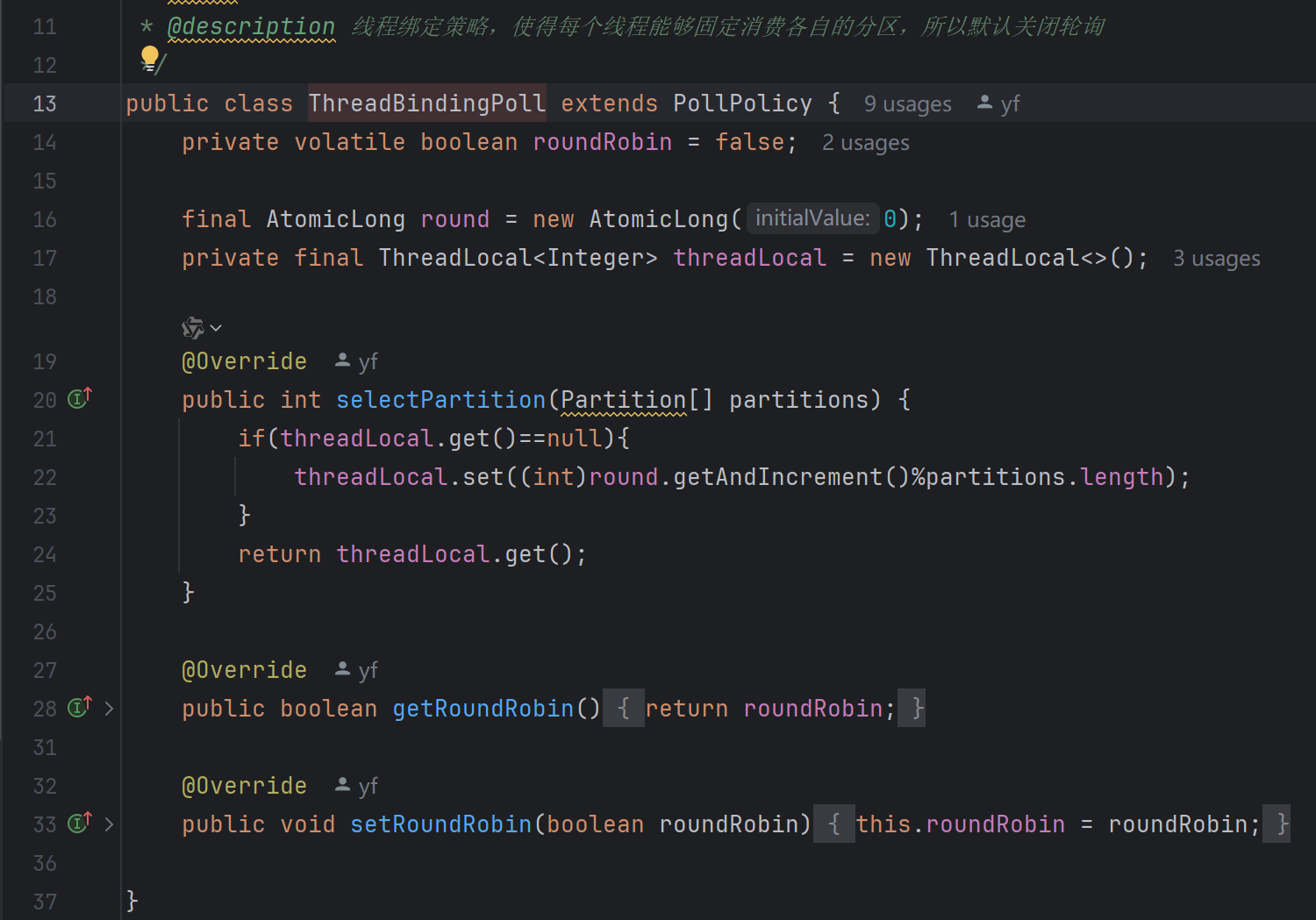
那么这时候就有兄弟要问了:"小co小co,有没有复杂度为o(1)又不被并发量影响,并且负载还均衡的呢?" "有的兄弟!有的!",他们就是BalencedHashOffer和ThreadBindingPoll,前者为均衡hash出队,后者为线程绑定出队,话不多说,上代码:
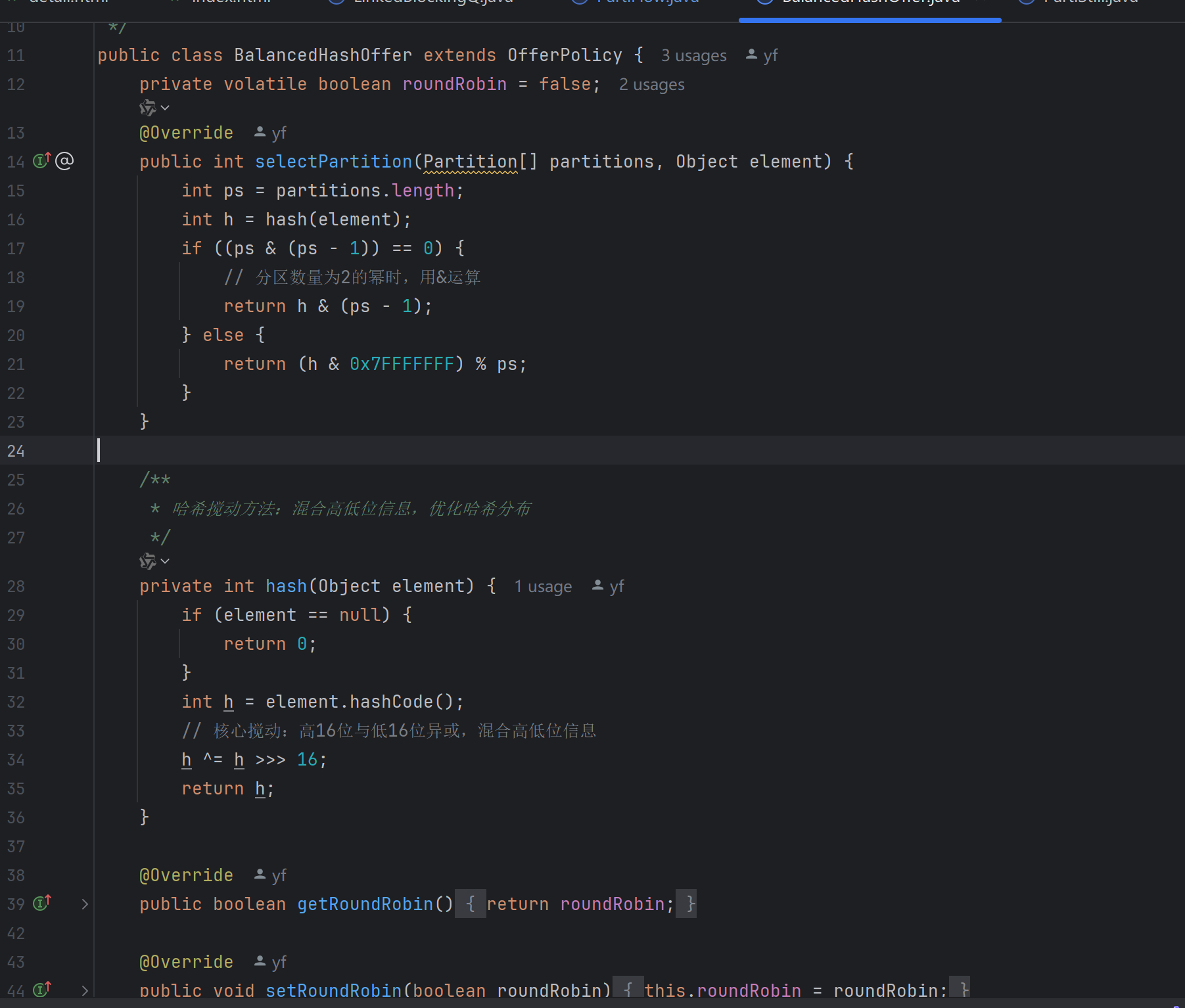
BalancedHashOffer是由hashmap的hash策略借鉴而来的,在此之前我是直接调方法的hashcode(),那么这样容易负载不均。hashmap的hash算法是先调用hashcode,再将前16位和后16为进行异或运算,这是一种搅动思路,如此保证后16为也能够参与到后续的与运算当中去。并且思路很简单,实现不复杂,性能开销极小。
ThreadBindingPoll是利用ThreadLocal实现的,大家想想,执行poll方法的线程其实就是核心线程或者非核心线程,那么就可以在第一次执行调度策略的时候将线程和分区进行绑定,这样之后就能够直接在ThreadLocalMap中取得了,性能开销极小。
当然,其实上述的作为反面例子的削峰、填谷和轮询,其实也只是不适合多分区或者高并发的场景,不代表好坏。例如线程绑定策略,其实就有个很大的问题:内存泄漏问题!其实一般情况下是不会发生这种问题的,但是我做的线程池是动态线程池,需要做到运行中改变参数切换组件,包括切换队列。所以要解决这个问题其实蛮复杂的,光解决队列安全切换这个问题就需要一整套的解决方案,而解决Threadlocal造成的内存泄漏问题还需要保底策略才能够彻底的解决,这个问题我会留到之后与大家分享,或者大家可以看看我的仓库,在Reflection文件夹中有我的一整套思考,并且项目还做了分布式考量和ai赋能的探索:
DynaPart-TP: 动态线程池,with参数动态配置和监控页面,以及分区化低粒度队列![]() https://gitee.com/ycodef/DynaPart-TP
https://gitee.com/ycodef/DynaPart-TP
https://github.com/p-yf/Dynapart-TP![]() https://github.com/p-yf/Dynapart-TP
https://github.com/p-yf/Dynapart-TP
https://gitcode.com/2401_82379797/DGA-Pool![]() https://gitcode.com/2401_82379797/DGA-Pool
https://gitcode.com/2401_82379797/DGA-Pool
以上就是我对于队列的整个优化的思路了,希望能够对大家有帮助,也希望大家能够讨论。可以想想如何实现一些更加有趣的调度规则。
补充一句结果:我的利用分区化和锁分离队列的线程池,相比较jdk线程池利用lbq在我自己写的测试场景下吞吐量和稳定性都提升了50%以上