一、SQL优化
1.概念
在应用的的开发过程中,由于初期数据量小,开发人员写 SQL 语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多 SQL 语句开始逐渐显露出性能问题,对生产的影响也越来越大,此时这些有问题的 SQL 语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化.
优化方法
从设计上优化:如合理设计表结构、数据类型等。
从查询上优化:优化SQL查询语句的写法等。
从索引上优化:合理创建和使用索引,提升查询效率。
从存储上优化:如优化存储引擎、表空间等。
2.优化技巧
(1)原则
减小查询的数据量、提升SQL的索引命中率
(2)查询时尽量不要使用 *
开发中为方便会用 * 代替所有字段,但这种写法对数据库性能不友好。
原因:
分析成本变高:增加SQL解析器的额外解析成本。
网络开销变大:返回无意义数据多,网络数据包体积大。
内存占用变高:SQL查到的结果集更大,占用内存也越多。
维护性变差:增加业务维护量。
(3)连表查询时尽量不要关联太多表
关联表过多会导致执行效率变慢、执行时间变长。
建议:
交互型业务:关联表数量控制在5张以内。
后台型业务:虽对用户体验要求低且业务复杂,但最好控制在16~18张以内(阿里开发规范要求控制在3张以内)。
(4)多表查询时一定要以小驱大
先查询小表,再用小表的结果去大表中检索数据。写SQL时最好将小表放在前面,大表放在后面。
(5)不要使用like左模糊和全模糊查询
原因:
like 以 % 开头(如 %xxx 、 %xxx% )会导致索引失效,触发全表查询,降低查询效率。
解决方案:
如需模糊查询,应避免左模糊和全模糊;若确实需要,可建立全文索引,或在数据量较大时使用ES、Solr等搜索引擎替代。
(6)查询时尽量不要对字段做空值判断
对字段进行 is null 或 not is null 判断时,索引会失效,导致全表扫描。
如:

优化建议:
设计字段时尽量用 not null 定义,若字段需为空,可用 0 、空字符串 "" 等空字符代替,这样查询空值时可通过空字符走索引检索。
(7)不要在条件查询 = 前对字段做任何运算
即使字段建立了索引,这类操作还是会导致索引失效,触发全表查询。因为如果MySQL优化器字段前有运算,生成执行计划时不会为运算后的字段选择索引。
如:

(8)!=、!<>、not in、not like、or...要慎用
这些操作可能会导致索引失效。
如:

上述SQL虽然变长了,但查询效率会而更高,因为后面的SQL可以走索引
(9)避免频繁创建、销毁临时表
临时表是数据缓存,对常用查询结果建立临时表可基于内存快速查询(速度远快于磁盘检索)。
注意事项:
仅对频繁查询的数据建立临时表,盲目无限制创建、销毁会给MySQL带来较大负担。
(10)从业务设计层面减少大量数据返回的情况
一次性返回大量数据会引发网络阻塞、内存占用过高、资源开销大等问题。
优化建议:
若业务存在一次性返回全量数据的情况,需拆分业务逻辑,例如分批返回数据给客户端。
(11)尽量避免深分页的情况出现
如:

这类深分页SQL,MySQL会先查询出100010条数据,再丢弃前10万条,仅返回最后10条,极其浪费资源。
改进方法:
情况1(结果集有递增连续字段):基于有序字段筛选后再分页,如:

情况2(搜索分页,结果无序):从业务上限制深分页,例如参考百度搜索,一般只提供前30页,避免用户进行极深分页操作。
(12)SQL务必要写完整,不要使用缩写法
示例:

注意:
所有隐式的这种写法,在底层都需要做一次转换,将其转换为完整的写法,因此简写的SQL会比完整的SQL多一步转化过程,如果需要极致程度的优化,切记将SQL写成完整语法。
(13)明确仅返回一条数据的语句可以使用 limit 1
示例:

上述这两条SQL语句都是根据姓名查询一条数据,但后者大多数情况下会比前者好,因为加上limit 1关键字后,当程序匹配到一条数据时就会停止扫描,如果不加的情况下会将所有数据都扫描一次。所以一般情况下,如果确定了只需要查询一条数据,就可以加上 limit 1提升性能。
(14)客户端的一些操作可以批量化完成

批量新增某些数据、批量修改某些数据的状态...,若使用上述接口的结构,即insert语句嵌入在for循环中,由于每次都需要往MySQL发送SQL语句,则会带来额外的网络开销以及耗时,应更改为如下:

上述修改,会组合成一条SQL发送给MySQL执行,能够在很大程度上节省网络资源的开销,提升批量操作的执行效率。
3.查看SQL执行频率
(1)作用
MySQL 客户端连接成功后,通过 show session\|global status 命令可以查看服务器状态信息。通过查看状态信息可以查看对当前数据库的主要操作类型。
(2)格式
查看当前会话统计结果(7个下划线):
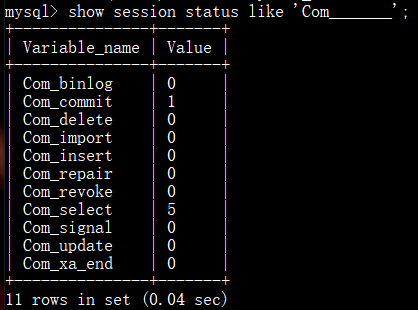
查看自数据库上次启动至今统计结果:
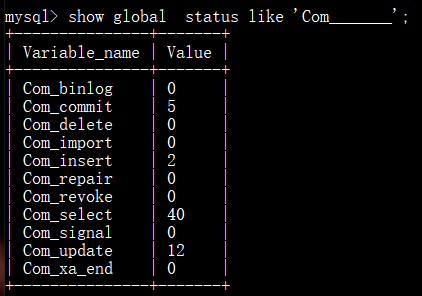
查看针对Innodb引擎的统计结果:
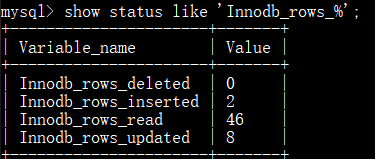
(3)重要参数分析
|----------------------|----------------------------------------|
| 参数 | 含义 |
| Com_select | 执行 select 操作的次数,一次查询只累加1 |
| Com_insert | 执行 insert操作的次数,对于批量插入的 insert 操作,只累加一次 |
| Com_update | 执行 update 操作的次数 |
| Com_delete | 执行 delete 操作的次数 |
| Innodb_rows_read | select 查询返回的行数 |
| Innodb_rows_inserted | 执行 insert 操作插入的行数 |
| Innodb_rows_updated | 执行 update 操作更新的行数 |
| Innodb_rows_deleted | 执行 delete 操作删除的行数 |
| Connections | 试图连接 MySQL 服务器的次数 |
| Uptime | 服务器工作时间 |
| Slow_queries | 慢查询的次数 |
(4)定位低效率执行SQL
可以通过以下两种方式定位执行效率较低的 SQL 语句:
慢查询日志 : 通过慢查询日志定位那些执行效率较低的 SQL 语句。
show processlist:该命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。
慢查询:
查看慢日志配置信息:
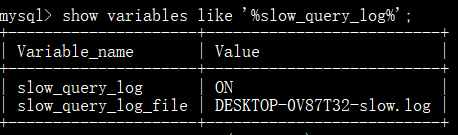
开启慢日志查询:

查看慢日志记录SQL的最低阈值时间(单位为秒) :
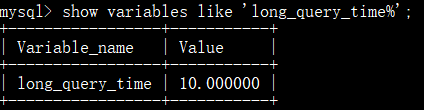
修改慢日志记录SQL的最低阈值时间,需要重启mysql服务:

show processlist:

分析:
id列------用户登录mysql时,系统分配的"会话id",可以使用函数 connection_id() 查看
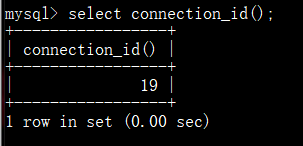
user列------显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句
host列------显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户
db列------显示这个进程目前连接的是哪个数据库
command列------显示当前连接的执行的命令,一般取值为休眠(sleep),查询(query),连接(connect)等
time列------显示这个状态持续的时间,单位是秒
state列------显示使用当前连接的sql语句的状态,很重要的列。state描述的是语句执行中的某一个状态。一个sql语句,以查询为例,可能需要经过copying to tmp table、sorting result、sending data等状态才可以完成
info列------显示这个sql语句,是判断问题语句的一个重要依据
(5)explain 分析执行计划
作用:
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN 命令获取 MySQL如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
格式:
explain sql
示例:
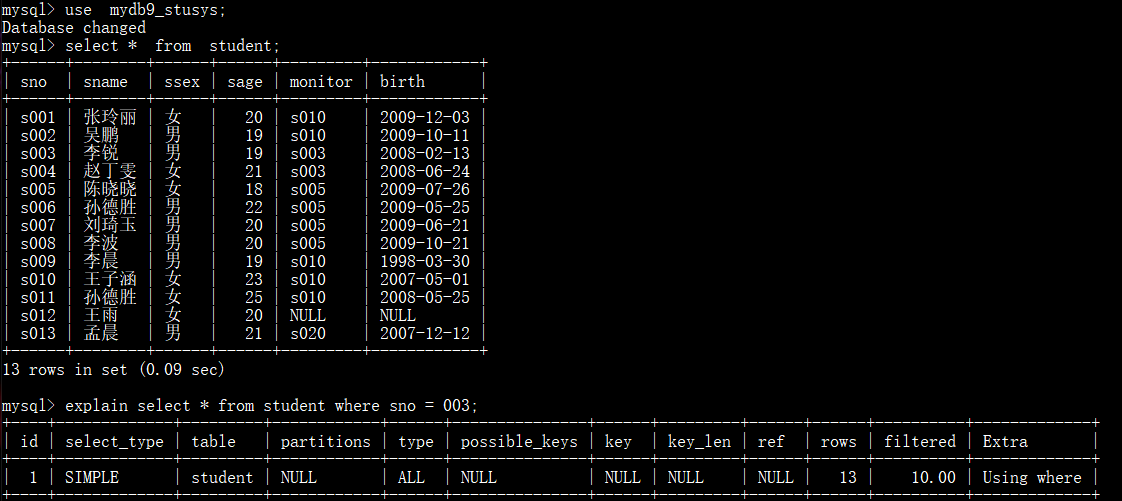
分析:
|----------------|-----------------------------------------------------------------------------------------------------------------------------------------------------|
| 字段 | 含义 |
| id | select 查询的序列号,是一组数字,表示的是查询中执行 select 子句或者是操作表的顺序。 |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个SELECT)等 |
| table | 输出结果集的表 |
| partitions | 匹配的分区信息,若表未分区则为NULL,用于展示查询涉及的分区情况 |
| type | 表示表的连接类型,性能由好到差的连接类型为(system --> const --> eq_ref --> ref --> ref_or_null --> index_merge --> index_subquery --> range --> index --> all ) |
| prossible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| ref | 表示与索引列进行比较的列或常量,例如某列与另一列的关联、或列与常量的比较。NULL表示没有使用到基于列的索引关联 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
参数使用:
key:如果该值为空,则表示未使用索引查询,此时需要调整SQL或建立索引。
type:这个字段决定了查询的类型,如果为index、all就需要进行优化。
rows:这个字段代表着查询时可能会扫描的数据行数,较大时也需要进行优化。
filtered:这个字段代表着查询时,表中不会扫描的数据行占比,较小时需要进行优化。
Extra:这个字段代表着查询时的具体情况,在某些情况下需要根据对应信息进行优化。
(6)show profile 分析SQL
作用:
show profiles 能够在做SQL优化时帮我们了解时间都耗费到哪里。
查看是否开启:
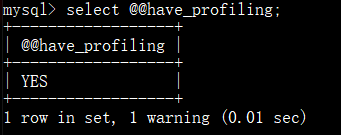
设置开启:

示例:
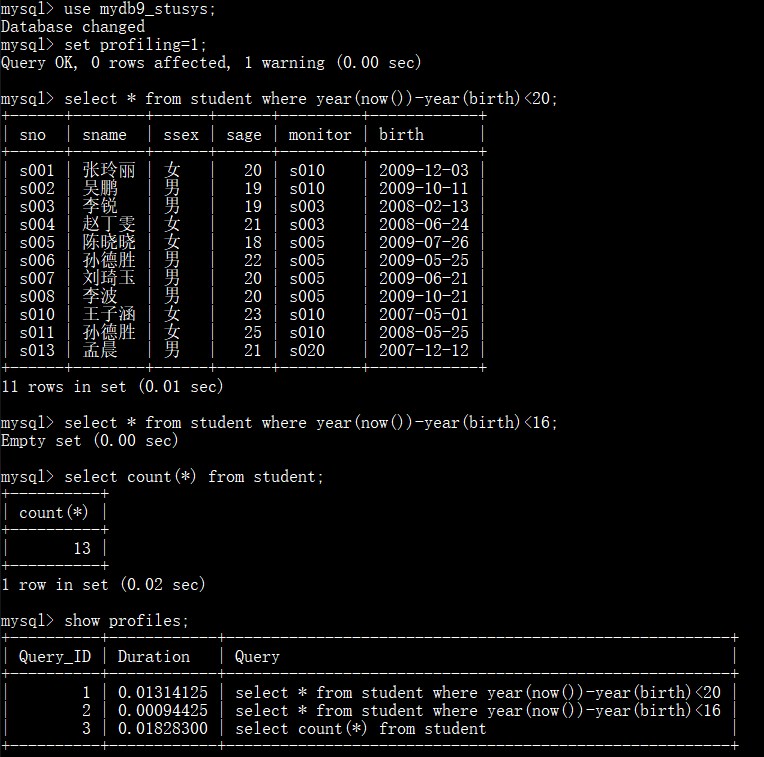
通过 show profile for query query_id 语句可以查看到该SQL执行过程中每个线程的状态和消耗的时间:
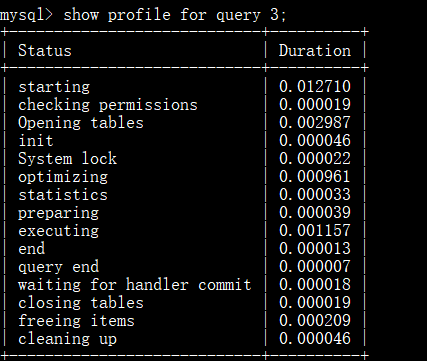
在获取到最消耗时间的线程状态后,MySQL 支持进一步选择 all、cpu、block io 、context switch、page faults 等明细类型类查看 MySQL 在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间 :
分析:
|------------|-------------------|
| 字段 | 含义 |
| Status | SQL 语句执行的状态 |
| Duration | SQL 执行过程中每一个步骤的耗时 |
| CPU_user | 当前用户占有的 CPU |
| CPU_system | 系统占有的 CPU |
(7)trace 分析优化器执行计划
作用:
MySQL 提供了对 SQL 的跟踪 trace , 通过 trace 文件能够进一步了解为什么优化器选择 A 计划, 而不是选择 B 计划。
方法:
打开 trace ,设置格式为 JSON,并设置 trace 最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整展示。

示例:
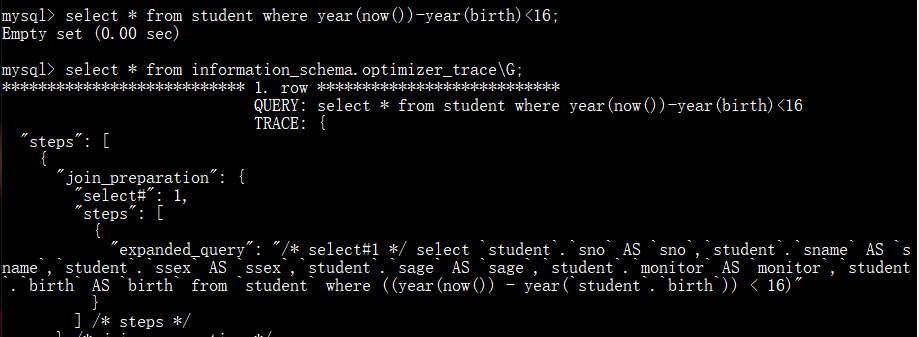
(8)使用索引优化
作用:
索引是数据库优化最常用也是最重要的手段之一, 通过索引通常可以帮助用户解决大多数的MySQL的性能优化问题。
建立原则:
一般针对数据分散的关键字进行建立索引,比如ID、QQ,像性别、状态值等建立索引没有意
对大数据量表建立聚集索引,避免更新操作带来的碎片
尽量使用短索引,一般对int、char/varchar、date/time 等类型的字段建立索引
需要的时候建立联合索引,但是要注意查询SQL语句的编写
谨慎建立 unique 类型的索引(唯一索引)
大文本字段不建立为索引,如果要对大文本字段进行检索,可以考虑全文索引
频繁更新的列不适合建立索引
order by 字句中的字段,where 子句中字段,最常用的sql语句中字段,应建立索引。
对于只是做查询用的数据库索引越多越好,但对于在线实时系统建议控制在5个以内。
(9)架构优化
业务拆分:搜索功能,like ,前后都有%,一般不用MySQL数据库
业务拆分:某些应用使用nosql持久化存储,例如memcahcedb、redis、ttserver 比如粉丝关注、好友关系等;
数据库前端必须要加cache,例如memcached,用户登录,商品查询
动态数据静态化。整个文件静态化,页面片段静态化
数据库集群与读写分离;
单表超过2000万,拆库拆表,人工或自动拆分(登录、商品、订单等)