在现代软件开发中,JSON (JavaScript Object Notation) 已成为数据交换的通用语言。无论是与 Web API 通信、存储应用程序配置,还是在不同服务间传递信息,JSON 的身影无处不在。Python 凭借其强大的标准库,内置了功能完备的 json 模块来应对这一切。
然而,对于许多初学者来说,load、loads、dump、dumps 这四个核心函数似乎总是有点令人困惑。它们的名字如此相似,功能又各有侧重。本文将彻底厘清它们的区别,从基础用法到高级技巧,在处理 JSON 数据时游刃有余。
一、核心法则:解密神秘的 s 后缀
要掌握这四个函数,我们首先要理解一个最关键的区别:函数名末尾的 s。
这里的 s 代表 string (字符串)。
-
带
s的函数 (loads,dumps) : 它们操作的对象是内存中的 Python 字符串。 -
不带
s的函数 (load,dump) : 它们操作的对象是 文件(或类文件)对象,负责数据的读写。
记住这个"黄金法则",就已经掌握了它们一半的奥秘。接下来,围绕两大核心操作------序列化 和反序列化来展开。
1、序列化:将 Python 对象转换为 JSON
序列化(也称编码)是将 Python 对象(如字典或列表)转换为 JSON 格式的过程。
1.1 json.dumps(): 转换成 JSON 字符串
当需要将一个 Python 对象变成一个 JSON 格式的字符串,以便通过网络发送或在程序中进一步处理时,dumps() 是不二之选。
python
import json
# 一个 Python 字典
data = {
"name": "张三",
"age": 30,
"courses": ["数学", "英语"]
}
# 转换为 JSON 字符串
# ensure_ascii=False 确保中文字符正常显示
# indent=4 让输出格式更美观
json_string = json.dumps(data, ensure_ascii=False, indent=4)
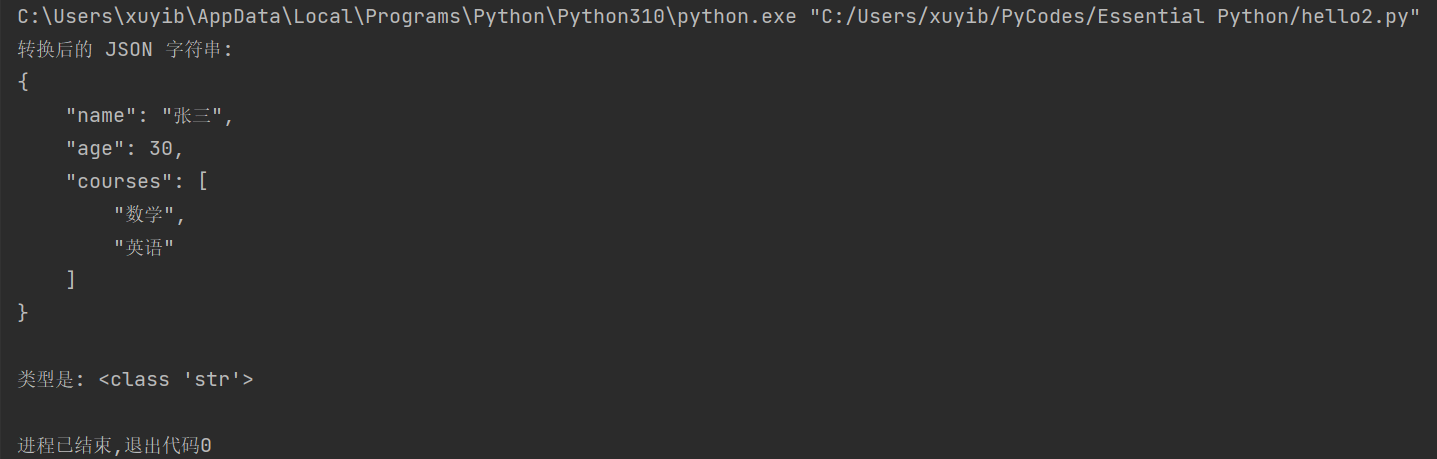
print("转换后的 JSON 字符串:")
print(json_string)
print("\n类型是:", type(json_string))运行结果:
1.2 json.dump(): 写入到 JSON 文件
当需要将数据持久化存储,例如保存配置文件或程序状态时,dump() 可以直接将 Python 对象写入文件中。
python
import json
data = {
"name": "李四",
"age": 25,
"courses": ["数学", "英语"]
}
# 'w' 表示写入模式,encoding='utf-8' 支持中文
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print("数据已成功写入 data.json 文件。")1.3 ensure_ascii 详解
ensure_ascii 是 json.dump() 和 **json.dumps()**函数中的一个布尔类型参数,它控制着输出结果中如何处理非 ASCII 字符(例如中文、日文、特殊符号等)。
- 当调用
json.dumps()或json.dump()而不指定ensure_ascii参数时,它默认为True。在这种模式下,所有非 ASCII 字符都会被"转义"成\uXXXX的形式。\uXXXX是一种 Unicode 转义序列。这种做法的初衷是为了保证最大的兼容性。因为 ASCII 编码是计算机世界里最基础、最通用的字符集,任何系统都可以无误地处理纯 ASCII 文本。通过将所有特殊字符转换为 ASCII 范围内的\u序列,可以确保生成的 JSON 字符串在任何环境下(即使是那些不支持 UTF-8 的老旧系统)都能被安全地传输和存储,不会产生编码错误或乱码。 - 推荐: 当明确地将
ensure_ascii设置为False时,是在告诉json模块:"请不要转义这些非 ASCII 字符,直接将它们原样输出。" - 注意: 当使用
ensure_ascii=False并且要将结果写入文件 (json.dump()) 时,有一个非常重要的配套操作:必须在open()函数中指定编码,通常是encoding='utf-8'。ensure_ascii=False产生了包含原生非 ASCII 字符的输出。如果不指定编码,Python 可能会使用操作系统的默认编码(在某些 Windows 系统上可能是 GBK 或 CP936)来尝试写入文件。此时如果字符(比如某些特殊符号或生僻字)不在该默认编码范围内,程序就会抛出UnicodeEncodeError错误。
在今天,UTF-8 已经成为事实上的标准。因此,在 Python 项目中,强烈推荐始终使用 ensure_ascii=False 并配合 encoding='utf-8' 来处理 JSON 数据。这会让数据文件更易于管理、调试,也更节省空间。
2、反序列化:将 JSON 解析为 Python 对象
2.1 json.loads(): 从 JSON 字符串 中加载
从 API 响应或消息队列中收到一个 JSON 格式的字符串时,loads() 会将其解析为 Python 的字典或列表。
python
import json
json_string = '''
{
"name": "王五",
"isAlive": true,
"hobbies": ["篮球", "游戏"]
}
'''
# 从字符串加载
python_dict = json.loads(json_string)
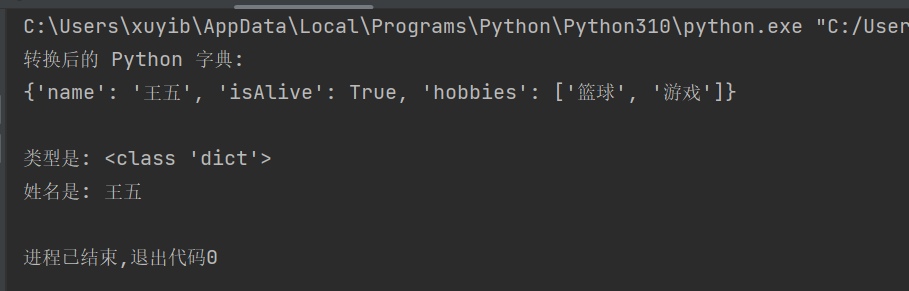
print("转换后的 Python 字典:")
print(python_dict)
print("\n类型是:", type(python_dict))
print("姓名是:", python_dict["name"])运行结果:
2.2 json.load(): 从 JSON 文件 中读取
当需要从一个配置文件(如 user_data.json)中读取数据并加载到程序中时,load() 是最直接的方法。
python
import json
# 'r' 表示读取模式,encoding='utf-8' 支持中文
with open('data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print("从文件读取的数据:")
print(data)
print("\n类型是:", type(data))
print("课程是:", data["courses"])3、表格对比
|--------------|------|------------------|-------------|----------------|
| 函数 | 操作 | 输入 | 输出 | 主要用途 |
| json.dumps() | 序列化 | Python 对象 | JSON 格式的字符串 | 网络传输、内存处理 |
| json.dump() | 序列化 | Python 对象 + 文件对象 | None (写入文件) | 数据持久化、保存配置 |
| json.loads() | 反序列化 | JSON 格式的字符串 | Python 对象 | 解析 API 响应、文本数据 |
| json.load() | 反序列化 | 文件对象 | Python 对象 | 从文件加载配置或数据 |
二、超越基础:json 模块的进阶工具
上述四个函数能满足 99% 的需求,同时在某些特殊场景下,json 模块还提供了更强大的工具:
1、处理自定义对象 ( JSONEncoder )
当试图序列化一个 Python 自定义对象(比如一个类的实例)时,json.dumps() 默认是不知道如何处理的,会抛出 TypeError。为了解决这个问题,json 模块提供了 JSONEncoder 和 JSONDecoder 类。
json.JSONEncoder: 你可以通过继承这个类并重写default()方法,来告诉dumps如何处理你自定义的数据类型。场景示例 :你想将一个包含datetime对象的字典序列化,但 JSON 标准里没有日期时间类型。
python
import json
from datetime import datetime
# 默认情况下,这会报错
# data = {'name': 'test', 'time': datetime.now()}
# json.dumps(data) # TypeError: Object of type datetime is not JSON serializable
# 使用自定义 Encoder
class DateTimeEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
# 将 datetime 对象格式化为字符串
return obj.isoformat()
# 其他类型调用父类的默认处理方法
return super().default(obj)
data = {'name': 'test', 'time': datetime.now()}
json_string = json.dumps(data, cls=DateTimeEncoder, indent=4)
print(json_string)
# 输出:
# {
# "name": "test",
# "time": "2025-10-06T22:01:28.123456"
# }json.JSONDecoder: 与上面对应,可以通过继承这个类,使用object_hook参数来定义如何将特定的 JSON 数据结构转换回自定义的 Python 对象。
python
import json
from datetime import datetime
def datetime_decoder_hook(json_dict):
"""
一个用于 json.loads 的 object_hook 函数。
它会检查字典中的值,尝试将符合 ISO 8601 格式的字符串转换回 datetime 对象。
"""
for key, value in json_dict.items():
# 检查值是否为字符串,并尝试进行转换
if isinstance(value, str):
try:
# 尝试用 fromisoformat 解析
# Python 3.7+ 支持解析带 Z 和微秒的完整 ISO 格式
json_dict[key] = datetime.fromisoformat(value)
except (ValueError, TypeError):
# 如果转换失败(说明它不是我们想要的日期格式),则保持原样
pass
return json_dict
# 1. 准备一个包含 ISO 日期格式字符串的 JSON
json_string = """
{
"name": "test_event",
"user_id": 123,
"created_at": "2025-10-06T22:01:28.123456",
"metadata": {
"source": "api",
"processed_at": "2025-10-07T10:55:00.543210"
}
}
"""
# 2. 使用 object_hook 进行解码
data_with_datetime = json.loads(json_string, object_hook=datetime_decoder_hook)
# 3. 验证结果
print("解码后的 Python 对象:")
print(data_with_datetime)
print("\n--- 类型验证 ---")
print(f"'created_at' 的类型是: {type(data_with_datetime['created_at'])}")
print(f"'processed_at' 的类型是: {type(data_with_datetime['metadata']['processed_at'])}")
print(f"'name' 的类型是: {type(data_with_datetime['name'])}")运行结果:

直接使用 object_hook 参数通常是最简单直接的方式。但如果想创建一个可重用的、配置更复杂的解码器,或者在某个类中封装解码逻辑,也可以选择继承 json.JSONDecoder。
python
import json
from datetime import datetime
class CustomDateTimeDecoder(json.JSONDecoder):
def __init__(self, *args, **kwargs):
# 将我们的钩子函数绑定到解码器实例上
json.JSONDecoder.__init__(self, object_hook=self.datetime_hook, *args, **kwargs)
def datetime_hook(self, json_dict):
for key, value in json_dict.items():
if isinstance(value, str):
try:
json_dict[key] = datetime.fromisoformat(value)
except (ValueError, TypeError):
pass
return json_dict
# 使用自定义的解码器类
json_string = '{"name": "test", "time": "2025-10-06T22:01:28.123456"}'
# 通过 cls 参数传入自定义的解码器类
data = json.loads(json_string, cls=CustomDateTimeDecoder)
print(data)
print(f"time 字段的类型是: {type(data['time'])}")2、健壮的错误处理 ( JSONDecodeError ):
当解析格式错误的 JSON 时,程序会抛出 json.JSONDecodeError。在生产环境中,应该使用 try...except 块来捕获这个异常,避免程序因此崩溃。
场景示例:从一个 API 获取了一段不完整的 JSON 字符串。
python
import json
invalid_json = '{"name": "John", "age": 30,' # 注意这里缺少了结尾的 '}'
try:
data = json.loads(invalid_json)
except json.JSONDecodeError as e:
print(f"JSON 解析失败: {e}")
# 输出: JSON 解析失败: Unexpected end of document: line 1 column 29 (char 28)3、便捷的 命令行工具 ( json.tool ):
Python 提供了一个方便的命令行工具,可以快速验证 JSON 文件的合法性并将其格式化输出。只需在终端运行 python -m json.tool your_file.json 即可。
三、总结
|-------|--------------------------|----------------------------------|---------------|
| 功能分类 | 主要成员 | 用途 | 使用频率 |
| 核心功能 | load, loads, dump, dumps | 在 Python 对象和 JSON 之间进行转换(文件/字符串) | 非常高 (99%) |
| 高级定制 | JSONEncoder, JSONDecoder | 处理非标准/自定义数据类型的序列化和反序列化 | 较低 |
| 错误处理 | JSONDecodeError | 捕获和处理格式错误的 JSON 数据 | 中等(在生产代码中很重要) |
| 命令行工具 | json.tool | 从命令行快速验证和格式化 JSON 文件 | 偶尔(对开发者调试很有用) |