锋哥原创的TensorFlow2 Python深度学习视频教程:
https://www.bilibili.com/video/BV1X5xVz6E4w/
课程介绍

本课程主要讲解基于TensorFlow2的Python深度学习知识,包括深度学习概述,TensorFlow2框架入门知识,以及卷积神经网络(CNN),循环神经网络(RNN),生成对抗网络(GAN),模型保存与加载等。
TensorFlow2 Python深度学习 - TensorFlow2框架入门 - 使用Keras实现逻辑回归
在 TensorFlow 2 中使用 Keras 实现逻辑回归是非常简单的。逻辑回归可以看作是一个二分类问题,Keras 提供了非常方便的接口来搭建模型。
逻辑回归虽然名字中有"回归",但实际上是一种用于二分类问题的线性模型。它通过sigmoid函数将线性输出映射到0,1区间,表示属于正类的概率。
下面是使用 TensorFlow 2 和 Keras 实现逻辑回归的示例,使用乳腺癌数据集进行训练和测试。我们将使用 sklearn.datasets.load_breast_cancer 来加载乳腺癌数据集,并使用 Keras 构建一个简单的逻辑回归模型来对其进行分类。
1,乳腺癌数据集介绍
该数据集共有 569 个样本,每个样本有 30 个特征。这些特征是乳腺肿瘤的细胞核属性的量化值,例如半径、纹理、周长、面积、光滑度等。特征数据是通过显微镜分析细胞样本获取的。
特征
每个样本由 30 个特征组成,这些特征描述了肿瘤细胞的几何形状、纹理、面积等。特征的详细描述如下:
-
半径(radius): 肿瘤的半径大小
-
纹理(texture): 肿瘤表面的纹理粗糙度
-
周长(perimeter): 肿瘤的外周长
-
面积(area): 肿瘤的表面积
-
平滑度(smoothness): 细胞核边缘的平滑度
-
其他的特征还包括紧凑度、对称性、均匀性等。
类别标签
目标变量(即标签)只有两个类别:
-
恶性肿瘤(Malignant,标记为 0)
-
良性肿瘤(Benign,标记为 1)
数据集的特点
-
样本数:569个样本
-
特征数:30个特征(所有特征都是数字型)
-
类别数:2(良性或恶性)
-
数据分布:在 569 个样本中,357 个为良性肿瘤,212 个为恶性肿瘤。
2,Keras实例
import tensorflow as tf
from keras import Input, layers
from sklearn.datasets import load_breast_cancer
# 1,加载乳腺癌数据集
data = load_breast_cancer()
X = data.data
y = data.target
print(X, y)
print(data.feature_names)
print(X.shape, y.shape)
# 2,构建逻辑回归模型
model = tf.keras.models.Sequential([
Input(shape=(X.shape[1],)),
layers.Dense(1, activation='sigmoid') # 使用sigmoid激活函数
])
# 3,模型编译
model.compile(
optimizer='adam',
loss='binary_crossentropy', # 损失函数 二分类交叉熵
metrics=['accuracy'] # 评估指标 accuracy准确率
)
# 4,模型训练
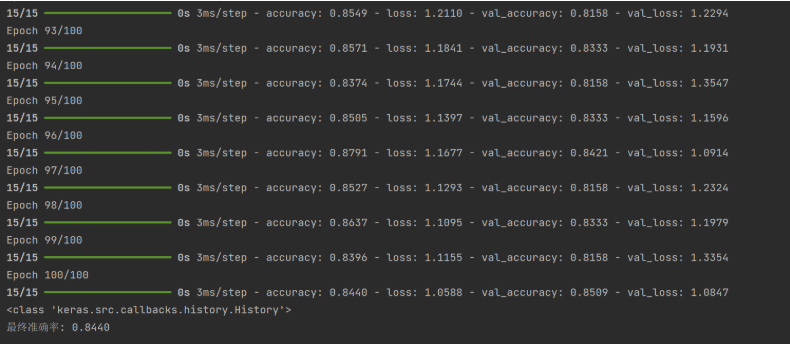
history = model.fit(X, y, epochs=100, batch_size=32, validation_split=0.2, verbose=1)
print(type(history))
print(f"最终准确率: {history.history['accuracy'][-1]:.4f}")运行结果:
3,训练历史History
keras.src.callbacks.History 对象是 Keras 中用于存储模型训练过程中各项指标历史的类,通常作为 fit() 函数的返回值。通过 History 对象,你可以访问训练过程中各个 epoch 的训练和验证指标,包括损失、精度、学习率等。
使用场景:
在模型训练过程中,History 对象会记录每个 epoch 结束时的训练和验证指标。你可以利用这些数据进行后续分析或可视化,帮助你了解模型的学习过程。
主要功能:
-
存储训练过程中的历史数据 :
History对象包含了每个 epoch 的训练和验证损失(loss)、精度(accuracy)等指标。 -
获取历史数据 : 通过
history.history属性,你可以访问包含训练过程中的所有指标的字典。 -
方便的可视化 : 你可以直接利用
History对象中的数据来绘制损失曲线、准确率曲线等图表,从而分析模型的训练情况。
属性:
-
history
:一个字典,存储每个 epoch 中的训练和验证指标。例如:
-
'loss': 训练过程中的损失值。 -
'accuracy': 训练过程中的准确率。 -
'val_loss': 验证集上的损失值(如果有验证集的话)。 -
'val_accuracy': 验证集上的准确率(如果有验证集的话)。
-
我们可以通过matplotlib来看下损失值的可视化图表:
from matplotlib import pyplot as plt
history.history.keys()
plt.plot(history.epoch, history.history['loss'], label='loss')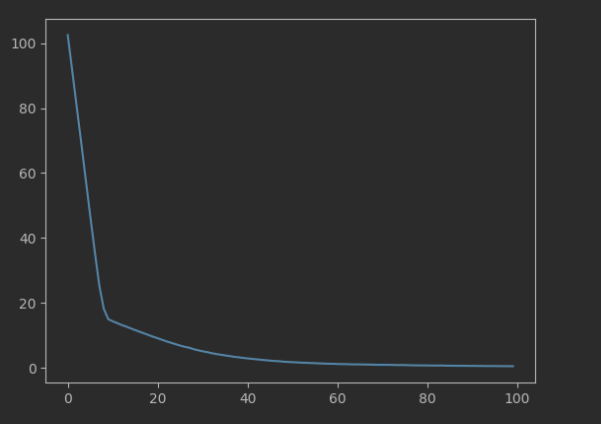
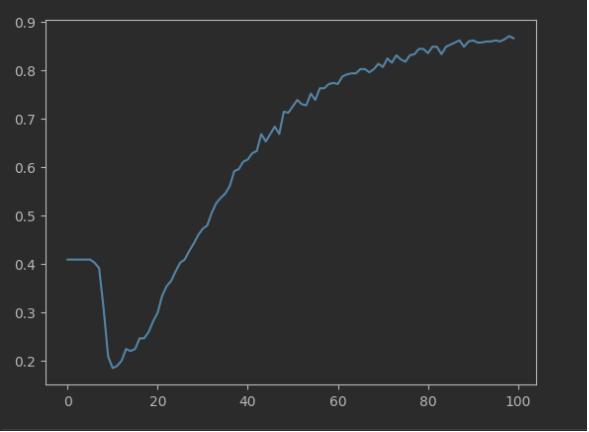
也可以看下准确率图表:
plt.plot(history.epoch, history.history['accuracy'], label='accuracy')