文章目录
- 1.什么是GRU
- 2.GRU的内部结构
-
- [2.1 重置门(Reset Gate)](#2.1 重置门(Reset Gate))
- [2.2 更新门(Update Gate)](#2.2 更新门(Update Gate))
- [2.3 候选隐状态](#2.3 候选隐状态)
- [2.4 隐状态](#2.4 隐状态)
- 代码
1.什么是GRU
GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,可以解决RNN中不能长期记忆和反向传播中的梯度等问题,与LSTM的作用类似,不过比LSTM简单,容易进行训练。
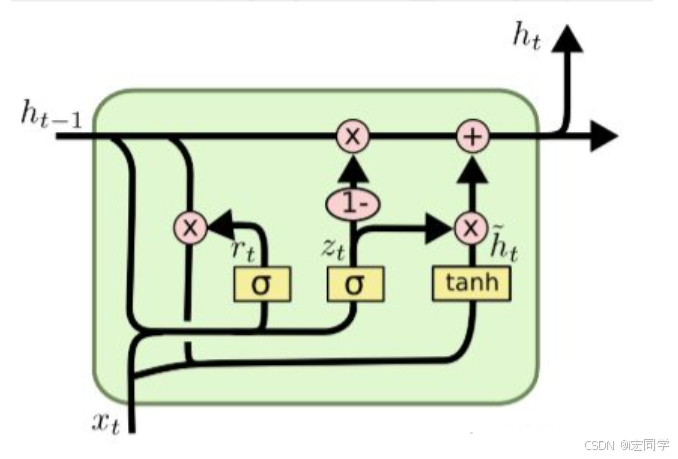
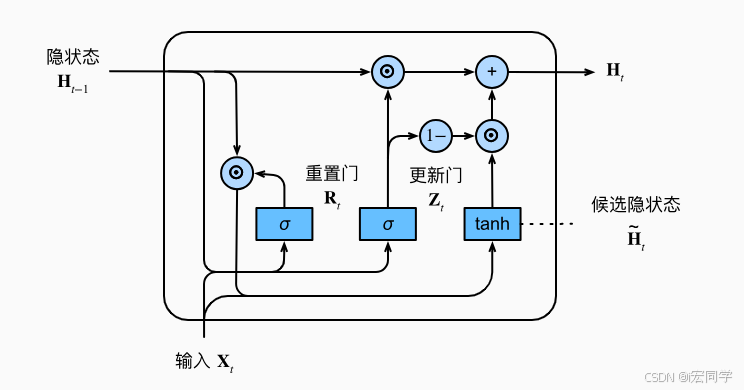

先不看内部具体的复杂关系,将上图简化为下图:
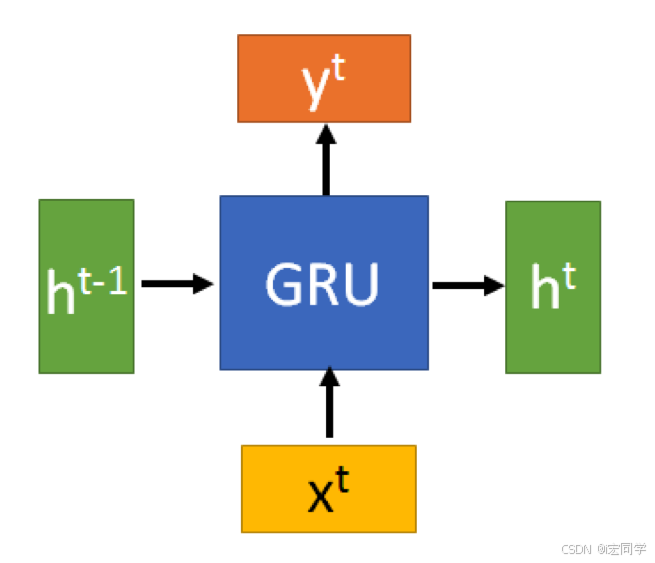
结合xt 和 h(t-1),GRU会得到当前隐藏节点的输出y_{t}和传递给下一个节点的隐藏状态ht,这个ht的推导是GRU的关键所在,我们看一下GRU所用到的公式:
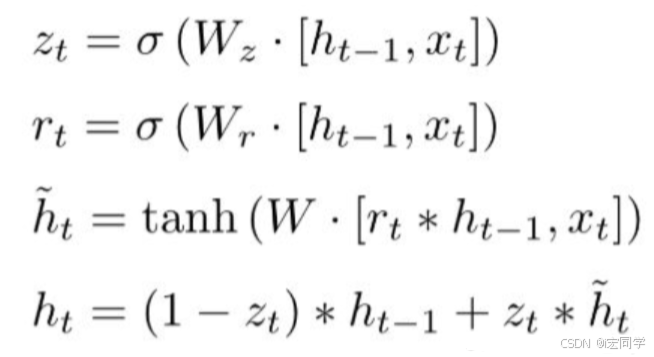
2.GRU的内部结构
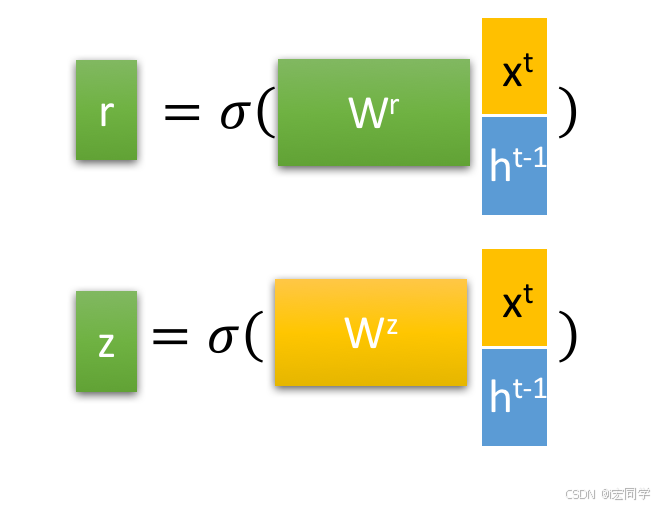
2.1 重置门(Reset Gate)
r是重置门,重置门决定了如何将新的输入信息与前面的记忆相结合,它控制过去的信息是否重要。如果旧的信息很重要,就保留;如果不重要,就忽略。这有点像在"刷脑子",看哪些旧记忆还需要用,哪些可以被新内容覆盖。
2.2 更新门(Update Gate)
它决定哪些信息需要更新,哪些不需要更新。你可以理解成一个选择器,判断"哪些新知识值得记进脑子里"。
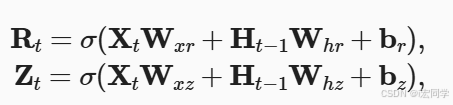


2.3 候选隐状态
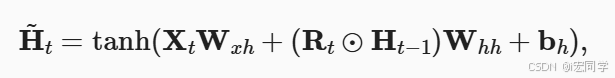


2.4 隐状态
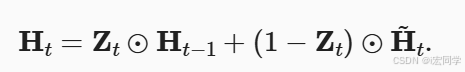
zt越接近1,代表"记忆"下来的数据越多;而越接近0则代表"遗忘"的越多。
代码
python
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)