还记得你第一次看到无人驾驶汽车在街头"自己开"的震撼吗?
或者监控画面里,AI 自动圈出一个可疑人物?
又或者无人机在空中灵巧地避开障碍?
这些都离不开同一个核心技术------实时视频目标检测(Real-time Video Object Detection) 。
它是让机器"看懂世界"的关键技术之一:能在视频流中实时识别、分类、跟踪物体。无论是行人、汽车,还是球场上那颗飞速滚动的足球,它都能一帧不落地捕捉到。

过去十年,这项技术的速度和精度都经历了飞跃式提升。如今在 2025 年,主流模型已经能在一台普通笔电上跑到 300 FPS+ 的速度,同时保持堪比人类直觉的准确率。
这意味着,不论你是研究者、创业者,还是只是一个爱折腾的开发者,都能轻松上手,做出属于自己的"AI 眼睛"。
一切从"图像识别"进化而来
视频目标检测,其实是图像检测的"进阶版"。
它不是处理单张图,而是要在连续的视频帧中快速决策------既要"看到",又要"跟上" 。
简单来说,核心流程是这样的👇:
- 输入视频流: 来自摄像头、RTSP 或视频文件
- 检测模型: 输出目标类别、边界框和置信度
- 后处理: NMS 去除重复框
- 输出结果: 画框、显示或保存
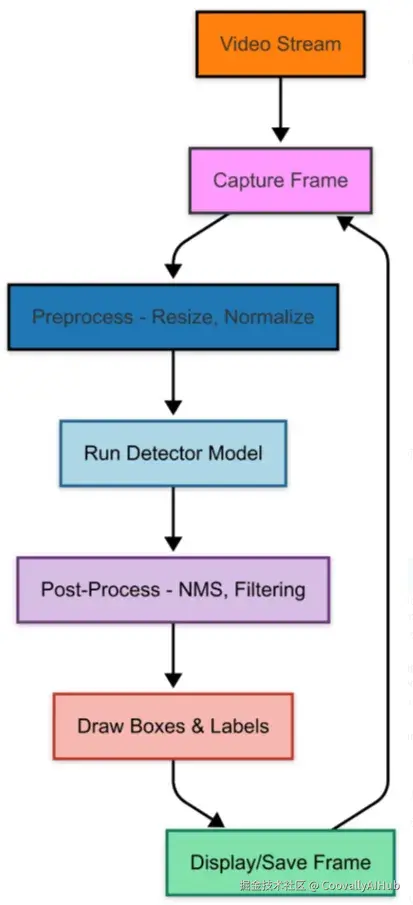
想要更稳定?那就要加上"多目标跟踪"(MOT)。比如 DeepSORT、ByteTrack 等算法能给每个目标加上唯一 ID,实现跨帧跟踪,让检测结果更流畅。
实时检测的五大挑战
实时视频检测不是单纯"跑得快"就行,它要同时兼顾速度、精度、硬件限制。主要难点包括:
- 延迟(Latency): 每帧最好 < 30ms,才能流畅显示;
- 硬件限制: 边缘设备算力有限,模型必须轻量;
- 环境变化: 光照、运动模糊、遮挡都会干扰检测;
- 多流场景: 同时处理多个视频源的扩展性;
- 速度 vs 准确率: 这是一场永恒的拉扯。
解决思路包括:
- 模型量化(Quantization)、剪枝(Pruning)
- 使用 TensorRT / OpenVINO 等硬件加速
- 降分辨率或跳帧推理
这些方法能显著提升帧率,而几乎不损失太多精度。
2025 年主流模型
目前实时检测领域已经炸开了锅,YOLO 系列依然是王者,YOLOv12 优化了主干网络,在速度与精度间找到新平衡;而 RF-DETR 在复杂场景下表现亮眼,mAP 可达 60,速度也不慢。
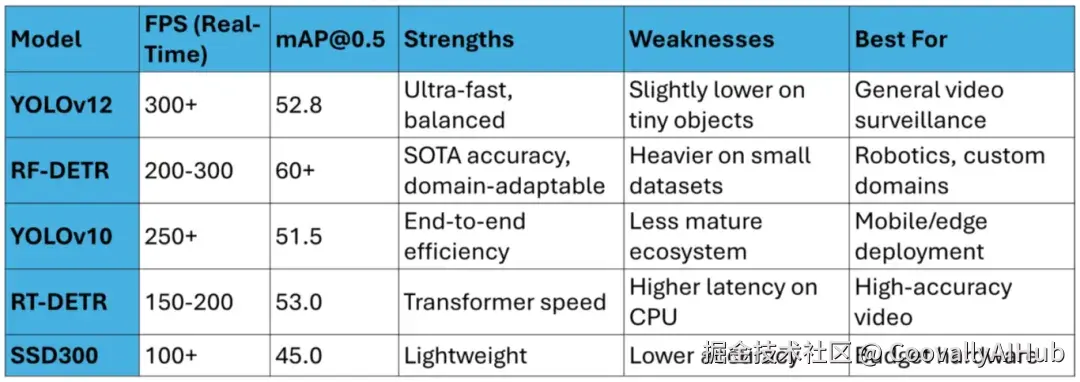
视频检测常与 ByteTrack 等追踪器搭配,效果更稳定。
在社区平台上,很多人还用 TensorFlow.js 在浏览器里跑实时检测------真正做到了"边看边算"。
一段简单的代码,跑起来!
以下是一个用 YOLOv8(也可升级 YOLOv12)实现实时检测的简单 Python 例子👇:
ini
from ultralytics import YOLO
import cv2
model = YOLO('yolov8n.pt')
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
results = model(frame)
annotated = results[0].plot()
cv2.imshow('Real-Time Detection', annotated)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()这段代码在一块中端 GPU 上能跑到 50+ FPS。
如果你想实现多目标跟踪,只需加几行:
ini
from supervision import ByteTrack
tracker = ByteTrack()
tracked = tracker.update(results[0].boxes)是不是很简单?😉
优化秘籍:让检测更"飞"
想要在笔电或嵌入式设备上跑得更快,可以这样做:
- 模型量化: 8-bit/4-bit 模型可提速 50%;
- 硬件加速: 用 TensorRT、OpenVINO;
- 降分辨率: 输入图像缩到 320x320;
- 帧跳推理: 每隔几帧检测一次;
- 模型剪枝: 去掉冗余权重。
实测中,量化后的 YOLOv10 在 Jetson 上 FPS 提升近 60%,且精度几乎不变。
应用无处不在
实时视频目标检测早已融入生活的方方面面:
- 自动驾驶: 识别行人、车辆、红绿灯
- 智能安防: 实时异常行为检测
- 无人机与机器人: 自主避障、路径规划
- AR/MR 应用: 实时叠加虚拟元素
- 医疗影像: 跟踪手术工具位置
未来趋势
接下来几年,这个领域会迎来更大的爆发。
- 多模态视觉语言模型(VLM)
首先是多模态视觉语言模型(VLM)的崛起,比如 Qwen2.5-VL。这类模型能同时理解画面与语义------不仅识别出"有辆车",还能推理出"它正在朝人行道开"。这让系统能实时回答问题,比如:"这辆车是否正在靠近人群?"或"这个场景的氛围是紧张还是平静?"
- 生成式 AI
其次是生成式 AI 的加入。它能实时修复视频质量,如低光、模糊等问题,让检测结果更准。甚至还能生成合成训练数据,加快模型适配新场景的速度。
- Agent 化系统
未来的检测模型不只是"看见",还能"思考并行动"。
比如无人机检测到障碍物后,不仅知道那是"树",还会自主规划路径绕过去。这种能力来自于多智能体(Multi-Agent)AI 框架的结合,未来甚至可用于灾区群体无人机的实时协作。
- 零样本与小样本学习(Zero/Few-shot Learning)
零样本与小样本学习(Zero/Few-shot Learning)也是趋势。像 Grounding DINO 就能只靠文本描述识别新目标,不用额外标注。这在制造业、农业等定制化场景中价值巨大。
- 硬件层面
5G、低时延芯片(如 Jetson 系列)和本地推理让边缘部署更高效,隐私性也更强。加上联邦学习(Federated Learning) 的结合,设备还能协同优化而无需共享原始视频数据。
未来还会有节能优化,例如动态电压控制、模型蒸馏,让电池设备(如无人机、摄像头)也能高 FPS 运行。
总之,未来的实时检测不仅更快更准,还会更"聪明"。它会与生成模型、强化学习等技术融合,形成真正能"理解场景并自适应"的视觉系统。
总结
从实验室研究课题到如今的AI核心技术,实时视频目标检测已经成为现代智能系统的基石。
无论是自动驾驶还是智慧安防,从 YOLOv12 到 RF-DETR,这些模型让高精度、低延迟检测触手可及。
这篇文章我们聊了整个体系:
从核心原理、实现流程、技术挑战,到实战代码和应用案例。
我最喜欢它的一点是:它是动态的。
每一帧都不一样,光照、遮挡、动作都在变,系统必须时刻调整。
通过轻量化模型、量化与跳帧等优化,就能在普通设备上跑出实时性能。
比如我用 YOLOv8 + ByteTrack 的组合,在中端 GPU 上从 30 FPS 提升到了 50 FPS,几乎没掉精度。
这项技术的应用空间太广了------
机器人可以靠它避障、导航;
医生可以实时追踪手术器械;
甚至在 AR 创作中,也能让虚拟元素"识别现实"。
未来,当检测系统与生成式 AI、Agent 系统融合,它就不再只是"看得见",而是"看得懂、能决策"。
比如,安防系统不止检测入侵,还能判断意图;无人机不止避障,还能自主规划路径。
实时视频目标检测,正在成为智能世界的视觉底座。
而此刻,正是加入这场浪潮的最好时机。