本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
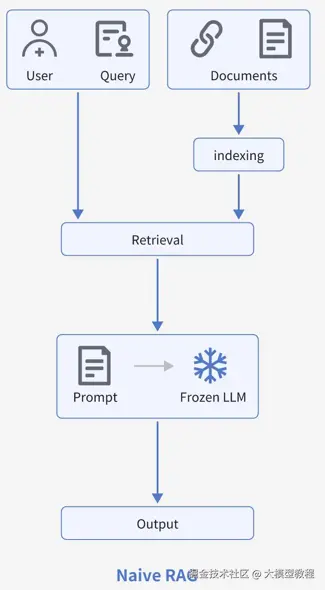
在 LangChain 的 RAG(检索增强生成)流程中,检索(Retrieval) 和召回(Recall) 的核心是通过 "文本嵌入(Embedding)+ 向量匹配" 找到与用户查询最相关的文档片段,而docid(文档唯一标识)是连接 "原始文本" 与 "嵌入向量" 的关键纽带。下面结合 LangChain 的具体实现逻辑,拆解检索、召回原理及docid的作用:
一、LangChain RAG 的核心流程:从 "数据准备" 到 "检索召回"
RAG 的核心目标是:让 LLM 在生成回答时,先 "检索" 到相关的外部文档(而非仅依赖自身训练数据),再基于这些文档 "生成" 答案。LangChain 将这个过程拆解为数据加载→文档分割→嵌入存储→检索召回→生成回答5 个步骤,其中 "检索召回" 是连接用户查询与文档的核心环节。
我们重点看与检索、召回相关的 3 个步骤:
1. 数据预处理:为文档生成嵌入向量和docid
在 RAG 启动前,需要先将原始文档(如 PDF、TXT、网页等)处理成可检索的格式,关键操作包括:
-
文档分割(Chunking) :长文档会被拆分为短片段(Chunk),例如将一篇 1000 字的文章拆成 5 个 200 字的片段。原因是:短片段的嵌入向量更精准(避免长文本中无关信息干扰),且匹配用户查询时更高效。
-
生成嵌入向量(Embedding) :对每个分割后的片段,用嵌入模型(如 OpenAI 的
text-embedding-ada-002、HuggingFace 的all-MiniLM-L6-v2)转化为固定长度的向量(例如 1536 维)。这个向量捕捉了片段的核心语义。 -
分配
docid并存储 :每个文档片段会被分配一个唯一标识(docid,可以是自定义字符串、UUID 等),同时存储 3 类信息:这些信息通常被存入向量数据库 (如 Chroma、Pinecone、FAISS),形成 "
docid→嵌入向量→原始文本" 的映射关系。
-
docid:片段的唯一 ID; -
embedding:该片段的嵌入向量; -
content:片段的原始文本(或元数据,如来源、页码等)。
2. 检索(Retrieval):用户查询与文档向量的匹配
当用户输入查询(如 "LangChain 如何实现 RAG?")时,检索的核心是 "找到与查询语义最相似的文档片段",步骤如下:
-
查询嵌入化:用与文档预处理时相同的嵌入模型,将用户查询转化为嵌入向量(例如 1536 维,与文档片段向量维度一致)。
-
向量相似度计算:在向量数据库中,用相似度算法(如余弦相似度、欧氏距离)计算 "查询向量" 与 "所有文档片段向量" 的相似度得分。得分越高,说明两者语义越相关。
-
筛选 Top-K 结果 :根据相似度得分排序,取前 K 个(如前 3 个)最相关的文档片段,返回它们的
docid和原始文本。例如:用户查询 "RAG 的检索原理",向量数据库中 "讲解向量匹配的片段" 会因语义高度相关,得分最高,被优先检索出来。
3. 召回(Recall):获取相关文档并传递给 LLM
"召回" 在 RAG 中可理解为 "将检索到的相关文档片段提取出来,作为上下文传递给 LLM"。具体来说:
-
基于检索步骤返回的
docid,从向量数据库中提取对应的原始文本片段(content)。 -
将这些片段与用户查询一起拼接成提示词(Prompt),例如:

-
将提示词输入 LLM,让其基于召回的文档生成回答(避免编造信息)。
二、docid的核心作用:连接 "嵌入向量" 与 "原始文本" 的桥梁
在整个流程中,docid是一个不起眼但关键的 "中间标识符",其作用体现在:
-
唯一标识文档片段 :无论是长文档分割后的片段,还是单条短文本,
docid确保每个待检索单元都有唯一 ID(避免重复或混淆)。 -
关联向量与原始文本 :向量数据库中存储的是 "嵌入向量" 和 "
docid",而原始文本(content)可能单独存储(或与docid绑定)。通过docid,可以快速从 "检索到的向量" 定位到 "对应的原始文本"(这是召回的前提)。 -
支持元数据管理 :
docid通常会关联元数据(如文档来源、作者、时间),方便后续过滤(例如 "只检索 2023 年后的文档")。
例如:假设docid=chunk_123对应 "向量匹配的原理是通过余弦相似度计算",当检索到该片段的向量时,通过docid=chunk_123即可找到原始文本,进而传递给 LLM。
三、检索召回的核心原理:"语义相似性" 而非 "关键词匹配"
传统搜索引擎依赖 "关键词匹配"(如查询含 "RAG" 则返回所有含 "RAG" 的文档),而 LangChain RAG 的检索召回基于 "语义相似性",这是由嵌入向量的特性决定的:
- 嵌入向量捕捉的是文本的 "语义含义",而非字面关键词。例如,"如何用 LangChain 做检索增强?" 和 "LangChain 的 RAG 实现方法" 这两个查询,字面不同但语义相似,它们的嵌入向量会非常接近,因此会检索到相同的文档片段。
- 这种特性让 RAG 能处理 "同义词查询""意译查询" 甚至 "跨语言查询"(如英文查询匹配中文文档,前提是嵌入模型支持跨语言)。
总结:LangChain RAG 中检索、召回与docid的关系
-
检索 :通过 "查询向量" 与 "文档片段向量" 的语义相似度计算,找到最相关的
docid列表。 -
召回 :根据
docid提取对应的原始文本片段,作为上下文传递给 LLM。 -
docid:是连接 "嵌入向量" 和 "原始文本" 的唯一标识,确保检索结果能准确映射到可用于生成的文本内容。
简言之,整个流程的核心逻辑是:用嵌入向量实现语义级别的检索,用docid实现向量到文本的精准召回,最终让 LLM 基于召回的信息生成可靠回答。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。