from flask import Flask, render_template_string, request, Response # 新增Response支持SSE
import threading
import time
import json
import requests
from bs4 import BeautifulSoup
app = Flask(__name__)
# 全局变量
is_crawling = False
crawl_thread = None
results_stream = [] # 存储推送结果流
# 增强版HTML页面,支持SSE实时接收
HTML_TEMPLATE = '''
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>实时文件搜索引擎</title>
<style>
body { font-family: Arial, sans-serif; margin: 40px; }
input[type=text] { width: 300px; padding: 10px; font-size: 16px; }
button { padding: 10px 20px; font-size: 16px; margin-left: 10px; }
.file-item {
border-bottom: 1px solid #eee; padding: 15px 0;
background: #f9f9f9; border-radius: 8px; margin: 10px 0;
transition: all 0.3s;
}
.file-item:hover { transform: translateY(-2px); box-shadow: 0 4px 8px rgba(0,0,0,0.1); }
.filename {
color: #1a0dab; font-weight: bold; font-size: 1.1em;
}
.source {
color: #006621; font-size: 0.9em; margin: 5px 0;
}
.link {
color: #0066cc; text-decoration: none; word-break: break-all;
display: block; margin: 8px 0; font-size: 0.95em;
}
.timestamp {
color: #666; font-size: 0.8em;
}
#status { margin: 20px 0; padding: 10px; background: #e6f7ff; border-radius: 4px; }
</style>
</head>
<body>
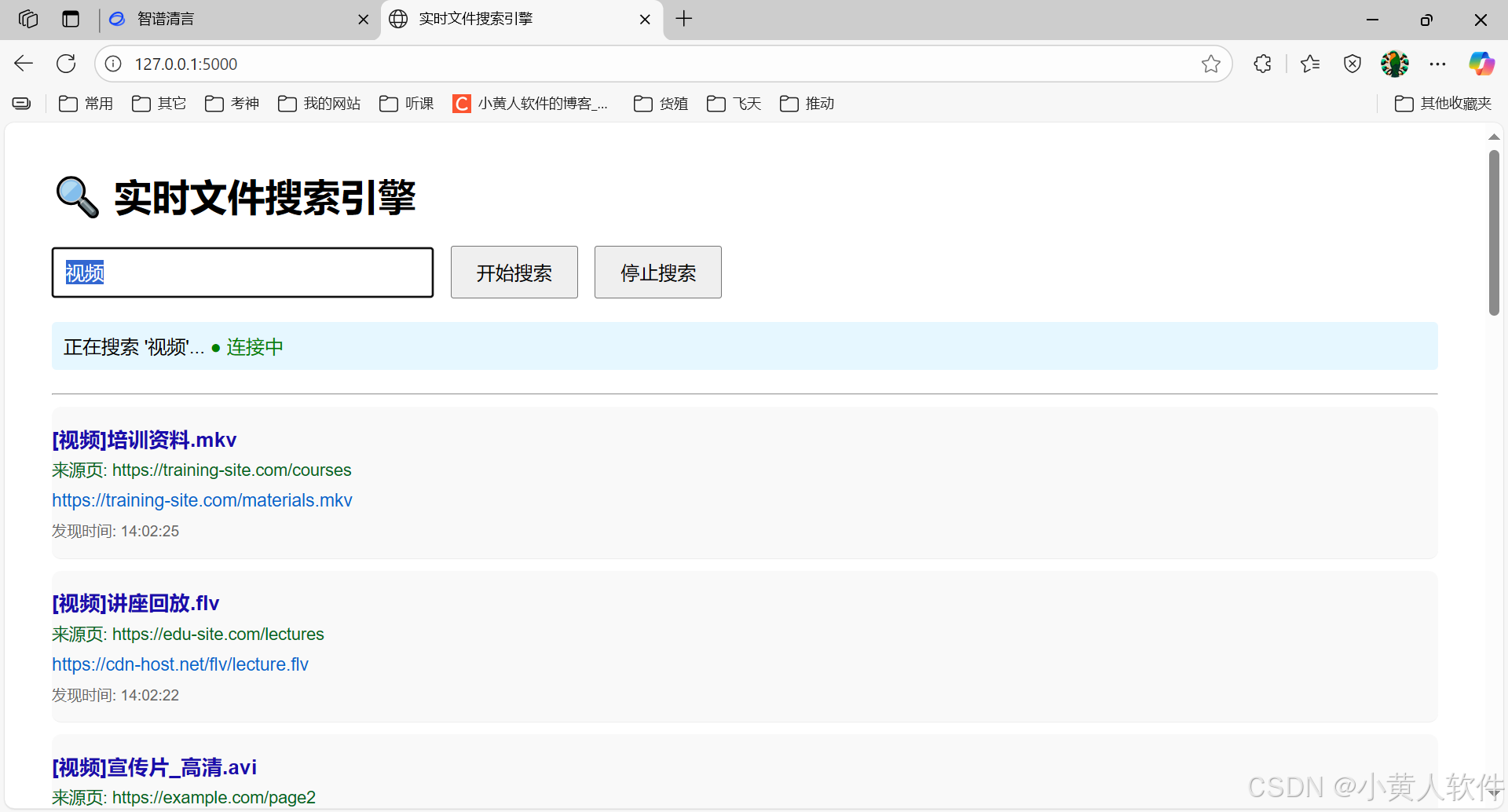
<h1>🔍 实时文件搜索引擎</h1>
<div>
<input type="text" id="keyword" placeholder="请输入要搜索的文件类型,例如:视频、文档、PDF..." value="视频">
<button onclick="startSearch()">开始搜索</button>
<button onclick="stopSearch()">停止搜索</button>
</div>
<div id="status">等待用户操作...</div>
<hr>
<div id="results"></div>
<script>
let eventSource = null;
function startSearch() {
const keyword = document.getElementById('keyword').value;
if (!keyword) return alert("请输入关键词!");
// 关闭旧连接
if (eventSource) eventSource.close();
// 更新状态
document.getElementById('status').innerHTML = `正在搜索 '${keyword}'... <span style="color:green">● 连接中</span>`;
document.getElementById('results').innerHTML = '';
// 创建SSE连接
eventSource = new EventSource('/stream?keyword=' + encodeURIComponent(keyword));
eventSource.onmessage = function(event) {
const data = JSON.parse(event.data);
const resultsDiv = document.getElementById('results');
const item = document.createElement('div');
item.className = 'file-item';
item.innerHTML = `
<div class="filename">${data.filename}</div>
<div class="source">来源页: ${data.source}</div>
<a href="${data.url}" target="_blank" class="link">${data.url}</a>
<div class="timestamp">发现时间: ${data.timestamp}</div>
`;
resultsDiv.prepend(item); // 最新结果在最上面
};
eventSource.onerror = function() {
document.getElementById('status').innerHTML += " ● 连接异常";
};
// 开始爬取
fetch('/start?keyword=' + encodeURIComponent(keyword));
}
function stopSearch() {
if (eventSource) {
eventSource.close();
document.getElementById('status').innerHTML += " <span style='color:orange'>● 已手动断开</span>";
}
fetch('/stop');
}
</script>
</body>
</html>
'''
@app.route('/')
def index():
return render_template_string(HTML_TEMPLATE)
@app.route('/start')
def start_crawling():
global is_crawling, crawl_thread
keyword = request.args.get('keyword', '视频')
if not is_crawling:
is_crawling = True
crawl_thread = threading.Thread(target=crawl_task, args=(keyword,))
crawl_thread.start()
return "爬取已启动"
else:
return "已在爬取中..."
@app.route('/stop')
def stop_crawling():
global is_crawling
is_crawling = False
return "已发送停止信号"
@app.route('/stream')
def stream():
"""SSE端点,实时推送结果"""
def generate():
while True:
if len(results_stream) > 0:
# 取出最新一条
result = results_stream.pop(0)
yield 'data: {}\n\n'.format(json.dumps(result))
else:
time.sleep(0.1) # 小休一下避免过度占用CPU
return Response(generate(), mimetype='text/event-stream')
def crawl_task(keyword):
"""模拟爬取任务"""
global is_crawling
mock_urls = [
("教学视频.mp4", "https://example.com/video1.mp4", "https://example.com/page1"),
("宣传片_高清.avi", "https://mirror-site.org/vid.avi", "https://example.com/page2"),
("讲座回放.flv", "https://cdn-host.net/flv/lecture.flv", "https://edu-site.com/lectures"),
("培训资料.mkv", "https://training-site.com/materials.mkv", "https://training-site.com/courses"),
("演示文稿.mov", "https://media-host.com/demo.mov", "https://corp-site.com/media")
]
while is_crawling:
for filename, link, source in mock_urls:
if not is_crawling:
break
result_item = {
"filename": f"[{keyword}]{filename}",
"url": link,
"source": source,
"timestamp": time.strftime("%H:%M:%S")
}
print(f"找到文件并推送: {result_item}")
results_stream.append(result_item) # 添加到推送队列
time.sleep(3)
print("爬取结束")
if __name__ == '__main__':
app.run(port=5000, debug=True, use_reloader=False)