最近碰见个新的验证码,觉得挺有意思,它不是点选,而是连线。
并且还利用了 requestAnimationFrame 来对题目信息进行干扰,如下图:
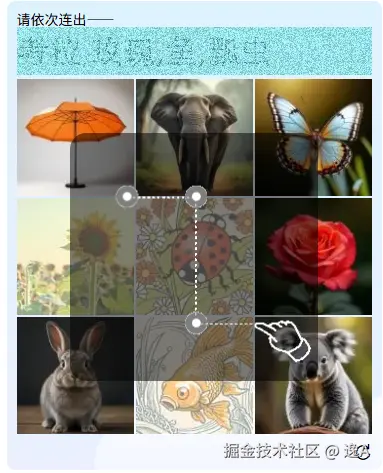
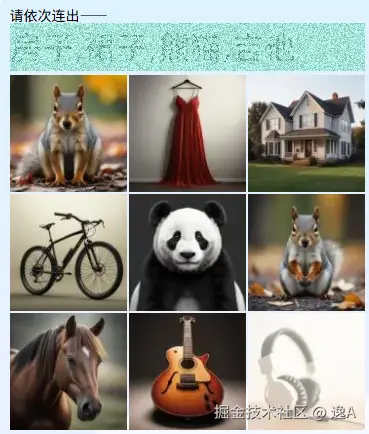
在网站上,屏幕会以高频率交替显示不同的题目图层,我们的人眼会将它们融合成清晰的图像
但截图下来的题目信息,就很模糊
这时我还不死心的想着能不能从它的接口返回信息里找见明文题目信息....
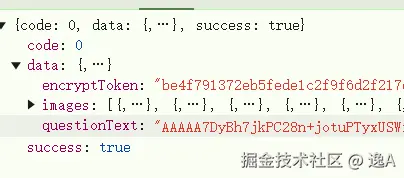 显然不能.......并且这看着既不像寻常aes加密,又不像png或jpg图片的base64格式
显然不能.......并且这看着既不像寻常aes加密,又不像png或jpg图片的base64格式
图片解密
开发者工具里边也没发现关于图片的抓包信息
那大概率是canvas前端算法解析处理了获取验证码接口的这些加密信息了,试着去断下canvas,发现一下断到好几个地方,一直跳过
直到显示验证码框体,再开始下一步,否则没有意义

断到这里:
一直跟下去,直到出现前边接口里看到的图像以及token信息:
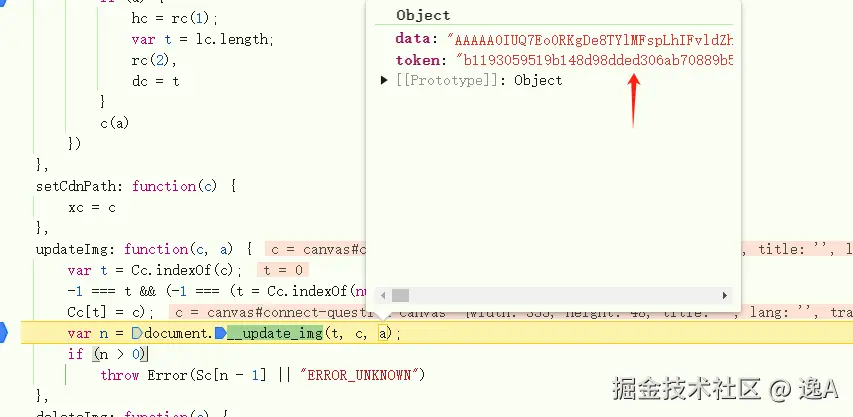
进去走几步就会发现跑wasm里边去了


并且后续几乎都在重复的进document.__update_img这个自己挂载的方法里,重复了 9+1次,第一次是题目图片信息,后面九次则是对应九宫格的每个小图
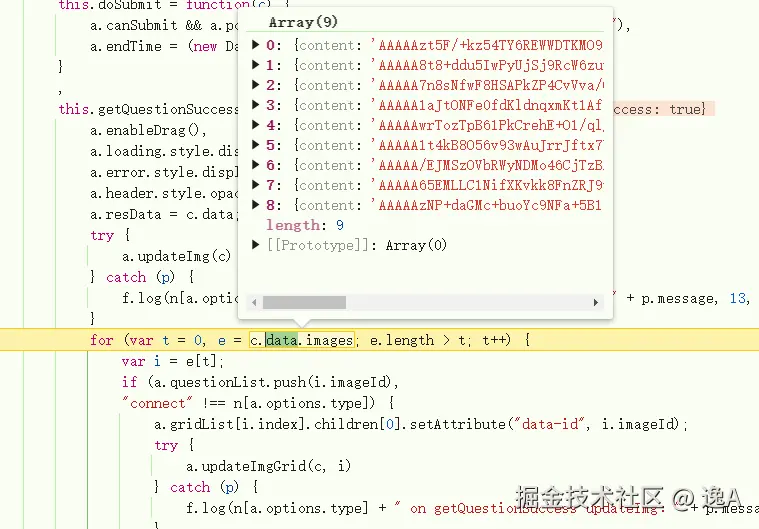
这里也可以看出它在挨个循环 updateImgGridConnect 方法,而这个方法进去就是

updateImg 再点进去就是上文所提到的 document.__update_img, 再之后便是 wasm
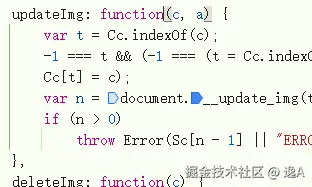
并且 wasm 内部操作中途,还会跳出来跑到这里的以数字为key的方法里边:
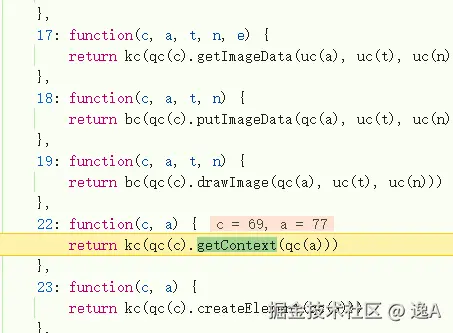
好,那这次wasm不解决是不行了,关于用到wasm的加密或混淆的解决方式常用的两种:
1、逆向wasm,将wasm反编译为可读的高级语言,再对照浏览器上走过的代码
优点:逆向成功后效率性能极高,且有成就感
缺点:极其费劲
2、浏览器咋干咱咋干
优点:简单粗暴
缺点:臃肿
我这里选的第2种...
看到它是有操作一个lc数组:
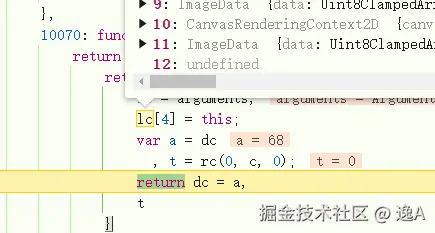
并且10次循环过后,lc 里边正好,有着和题目尺寸以及九宫格小图一样宽高的 ImageData

这时候直接点进去生成的url里边是空白且无任何内容的


10070这个方法里跳几次后又有了:
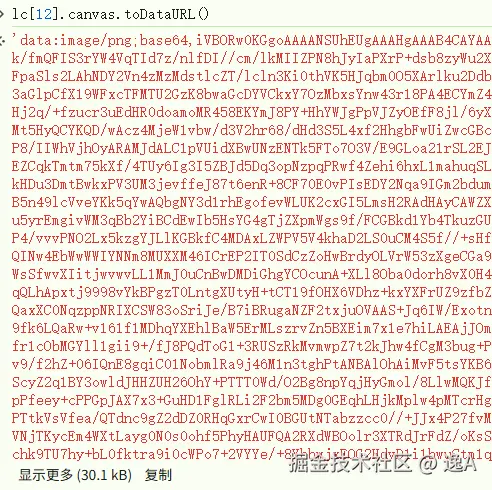 复制到浏览器显示为:
复制到浏览器显示为: 
至于是如何如此的,笔者当时也没看出来,后面本地复刻好之后也没再继续研究,有了解的可以在评论区交流。
图像识别
这种的看题目信息没有涉及"红色椅子"、"紫色篮子"一类的,所以直接选择训练个分类模型,笔者选择是ResNet50。
在此模型基础上对其进行再一次的专门训练,用于我们的特定任务。
由于样本没法直接做到绝对统一,且有的就是多,有的就是少,多的有五六十张,少的只有十几张,那可以通过给样本少的类别更高的权重,让模型在训练时更"关照"它们。
数据集按这样的形式分好类:
准备好数据集后,我们便可以开始直接训练,训练代码如下:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
import os
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import time
import json
# 配置与超参数 ---
class Config:
# 数据集路径
DATA_DIR = 'dataset_final'
TRAIN_DIR = os.path.join(DATA_DIR, 'train')
VAL_DIR = os.path.join(DATA_DIR, 'val')
# 模型参数
MODEL_NAME = 'resnet50'
NUM_CLASSES = len(os.listdir(TRAIN_DIR)) # 自动获取类别数量
# 训练参数
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
BATCH_SIZE = 32
NUM_EPOCHS = 25
LEARNING_RATE = 0.001
# 输出路径
OUTPUT_DIR = 'output'
MODEL_SAVE_PATH = os.path.join(OUTPUT_DIR, 'best_model.pth')
HISTORY_SAVE_PATH = os.path.join(OUTPUT_DIR, 'training_history.json')
PLOT_SAVE_PATH = os.path.join(OUTPUT_DIR, 'training_plot.png')
def get_data_loaders(config):
"""
准备数据加载器, 包括数据增强和处理样本不均衡
"""
# 训练集使用较强的数据增强,增加模型泛化能力
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 验证集不需要数据增强,只需进行必要的尺寸和格式转换
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_dataset = datasets.ImageFolder(config.TRAIN_DIR, train_transform)
val_dataset = datasets.ImageFolder(config.VAL_DIR, val_transform)
# ★★★ 处理样本不均衡问题 ★★★
# 核心思想:给样本少的类别更高的权重,让模型在训练时更"关照"它们。
print("\n处理样本不均衡问题...")
# 统计训练集中每个类别的样本数
class_counts = np.bincount(train_dataset.targets)
# 计算每个类别的权重 (总样本数 / (类别数 * 该类别样本数))
class_weights = 1. / class_counts
weights = torch.from_numpy(class_weights).float().to(config.DEVICE)
print(f"类别权重计算完毕,共 {len(weights)} 个类别。")
train_loader = DataLoader(train_dataset, batch_size=config.BATCH_SIZE, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=config.BATCH_SIZE, shuffle=False, num_workers=4, pin_memory=True)
return train_loader, val_loader, weights, train_dataset.class_to_idx
def get_model(config):
print(f"\n加载预训练模型: {config.MODEL_NAME}...")
# 加载在ImageNet上预训练的ResNet-50
model = models.resnet50(pretrained=True)
# 冻结所有层,只训练我们修改的部分
for param in model.parameters():
param.requires_grad = False
# 获取最后全连接层的输入特征数
num_ftrs = model.fc.in_features
# 替换掉原来的全连接层,换成我们自己的,输出维度为我们的类别数
model.fc = nn.Linear(num_ftrs, config.NUM_CLASSES)
# 将模型移动到指定的设备 (CPU或GPU)
model = model.to(config.DEVICE)
print("模型加载并修改完毕。")
return model
def train_model(model, train_loader, val_loader, class_weights, config):
"""
完整训练和验证流程
"""
criterion = nn.CrossEntropyLoss(weight=class_weights)
optimizer = optim.Adam(model.fc.parameters(), lr=config.LEARNING_RATE)
history = {
'train_loss': [], 'train_acc': [],
'val_loss': [], 'val_acc': []
}
best_val_acc = 0.0
start_time = time.time()
print("\n--- 开始训练 ---")
for epoch in range(config.NUM_EPOCHS):
model.train()
running_loss = 0.0
running_corrects = 0
train_pbar = tqdm(train_loader, desc=f"Epoch {epoch + 1}/{config.NUM_EPOCHS} [训练]")
for inputs, labels in train_pbar:
inputs = inputs.to(config.DEVICE)
labels = labels.to(config.DEVICE)
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step() # 更新权重
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
train_pbar.set_postfix({'loss': loss.item()})
epoch_train_loss = running_loss / len(train_loader.dataset)
epoch_train_acc = running_corrects.double() / len(train_loader.dataset)
history['train_loss'].append(epoch_train_loss)
history['train_acc'].append(epoch_train_acc.item())
# --- 验证阶段 ---
model.eval()
running_loss = 0.0
running_corrects = 0
val_pbar = tqdm(val_loader, desc=f"Epoch {epoch + 1}/{config.NUM_EPOCHS} [验证]")
with torch.no_grad(): # 验证阶段不计算梯度
for inputs, labels in val_pbar:
inputs = inputs.to(config.DEVICE)
labels = labels.to(config.DEVICE)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_val_loss = running_loss / len(val_loader.dataset)
epoch_val_acc = running_corrects.double() / len(val_loader.dataset)
history['val_loss'].append(epoch_val_loss)
history['val_acc'].append(epoch_val_acc.item())
print(f"Epoch {epoch + 1}/{config.NUM_EPOCHS} -> "
f"训练损失: {epoch_train_loss:.4f}, 训练准确率: {epoch_train_acc:.4f} | "
f"验证损失: {epoch_val_loss:.4f}, 验证准确率: {epoch_val_acc:.4f}")
# 保存效果最好的模型
if epoch_val_acc > best_val_acc:
best_val_acc = epoch_val_acc
torch.save(model.state_dict(), config.MODEL_SAVE_PATH)
print(f" **发现新最佳模型!已保存到: {config.MODEL_SAVE_PATH} (准确率: {best_val_acc:.4f})**")
time_elapsed = time.time() - start_time
print(f"\n--- 训练完成 ---")
print(f"总耗时: {time_elapsed // 60:.0f}分 {time_elapsed % 60:.0f}秒")
print(f"最佳验证准确率: {best_val_acc:.4f}")
return history
# --- 主函数 ---
def main():
# 初始化配置
config = Config()
os.makedirs(config.OUTPUT_DIR, exist_ok=True)
print(f"设备: {config.DEVICE}")
print(f"类别数: {config.NUM_CLASSES}")
# 获取数据加载器
train_loader, val_loader, class_weights, class_to_idx = get_data_loaders(config)
# 保存类别到索引的映射,预测时会用到
class_map_path = os.path.join(config.OUTPUT_DIR, 'class_to_idx.json')
with open(class_map_path, 'w') as f:
json.dump(class_to_idx, f)
print(f"类别映射已保存到: {class_map_path}")
# 获取模型
model = get_model(config)
# 训练模型
history = train_model(model, train_loader, val_loader, class_weights, config)
if __name__ == '__main__':
main()之后有自己gpu或者对速度不敏感的可以自己用cpu慢慢训练,没的话建议去简单租个算力,几块钱一小时,各位可以自行寻找,这里就不打这类广告了哈哈,直接看下最终结果吧
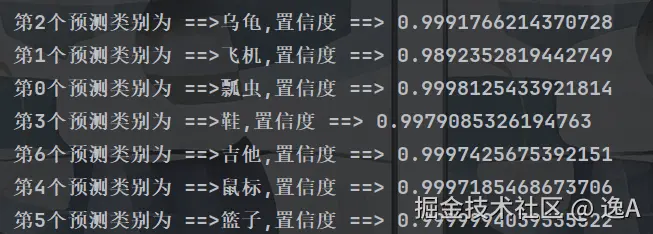

结尾
关于数据集,以及图片wasm解密的更详细文章说明,甚至标注手法 ,可以加入星球内自取,有好的图片处理方案也可以一起交流 t.zsxq.com/GEIze