如果你曾经使用过大型语言模型(LLMs),你就会知道它们是无状态的。如果你没有使用过,不妨把它们想象成没有短期记忆。
这方面的一个例子是电影
《记忆碎片》
,主角不断需要被提醒发生了什么,他用写有事实的便利贴来拼凑出下一步该做什么。
与大语言模型对话时,每次互动我们都需要不断提醒它们对话内容。
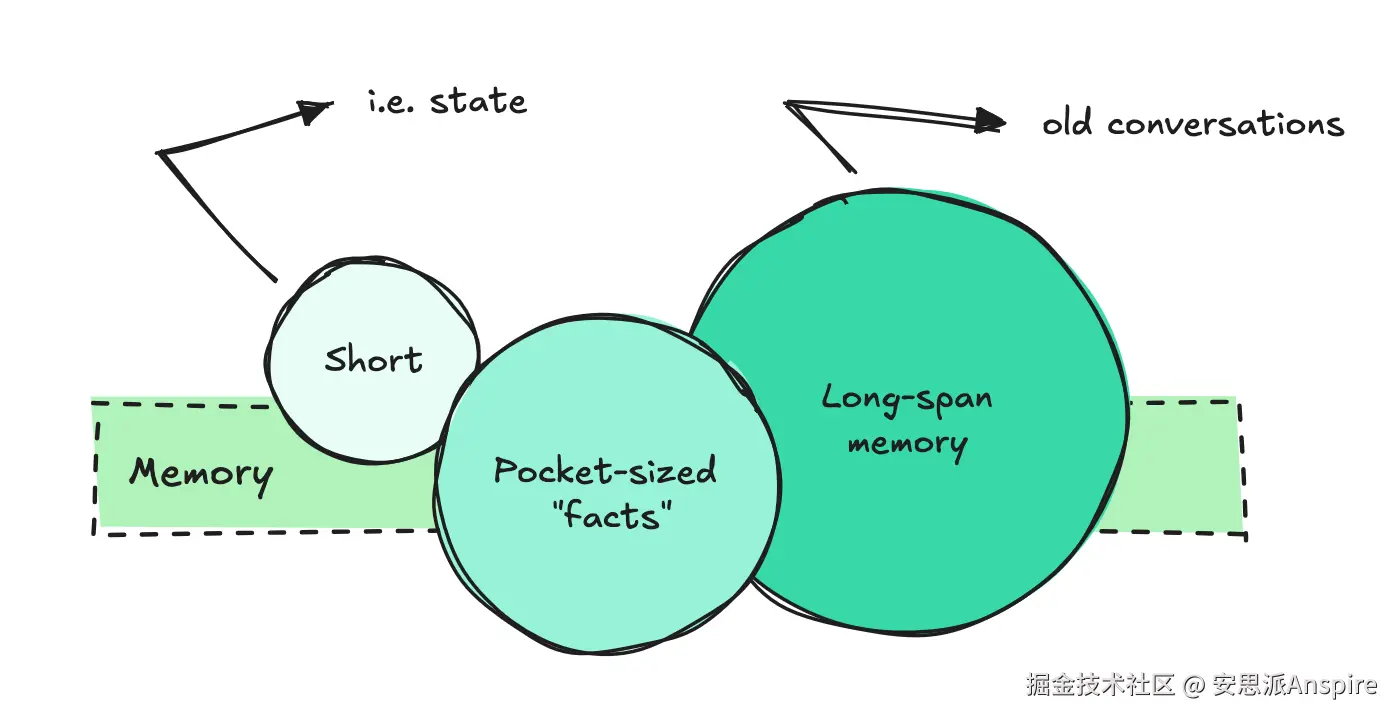
实现我们所说的"短期记忆"或状态很容易。我们只需抓取几个之前的问答对,并将它们包含在每次调用中。
另一方面,长期记忆则是完全不同的一回事。
为确保大语言模型(LLM)能够提取正确的事实、理解之前的对话并关联信息,我们需要构建一些相当复杂的系统。
按回车键或点击以查看全尺寸图像
本文将深入探讨问题,而非堆砌大量术语,探究构建高效系统所需的要素,研究不同的架构选择,并考察能为我们提供帮助的开源和云服务提供商。
思考解决方案
首先,让我们来梳理一下为大语言模型(LLMs)构建记忆的思考过程,以及要使其高效运行所需的条件。
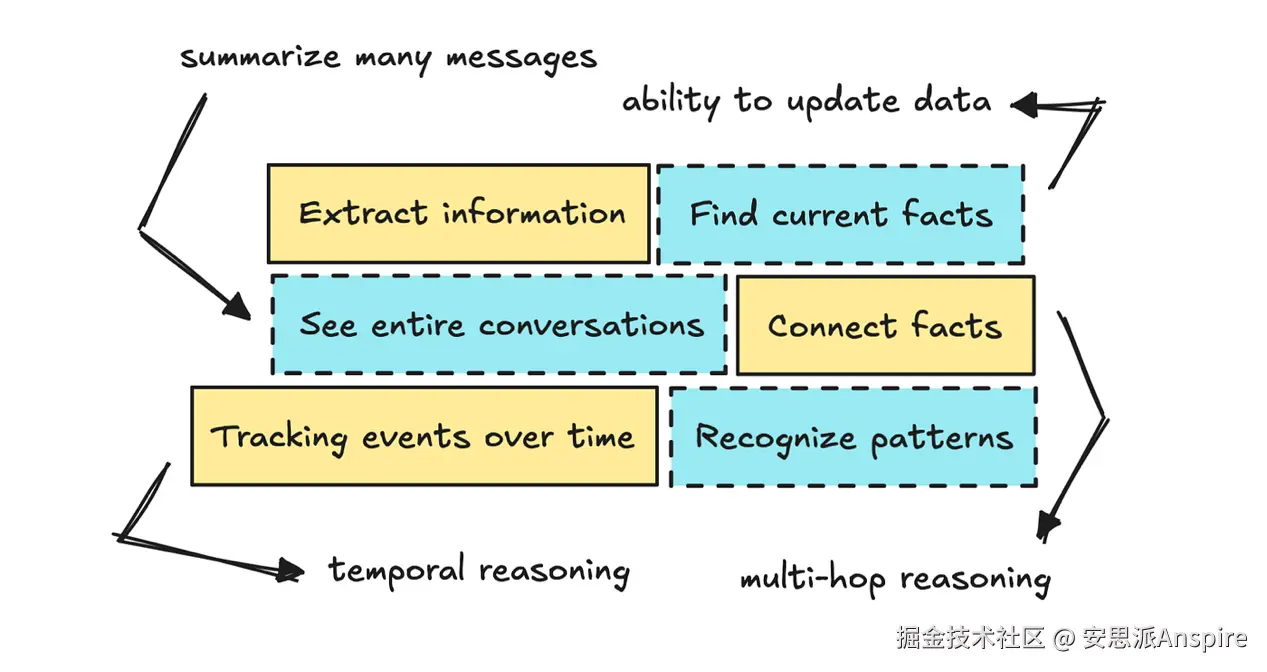
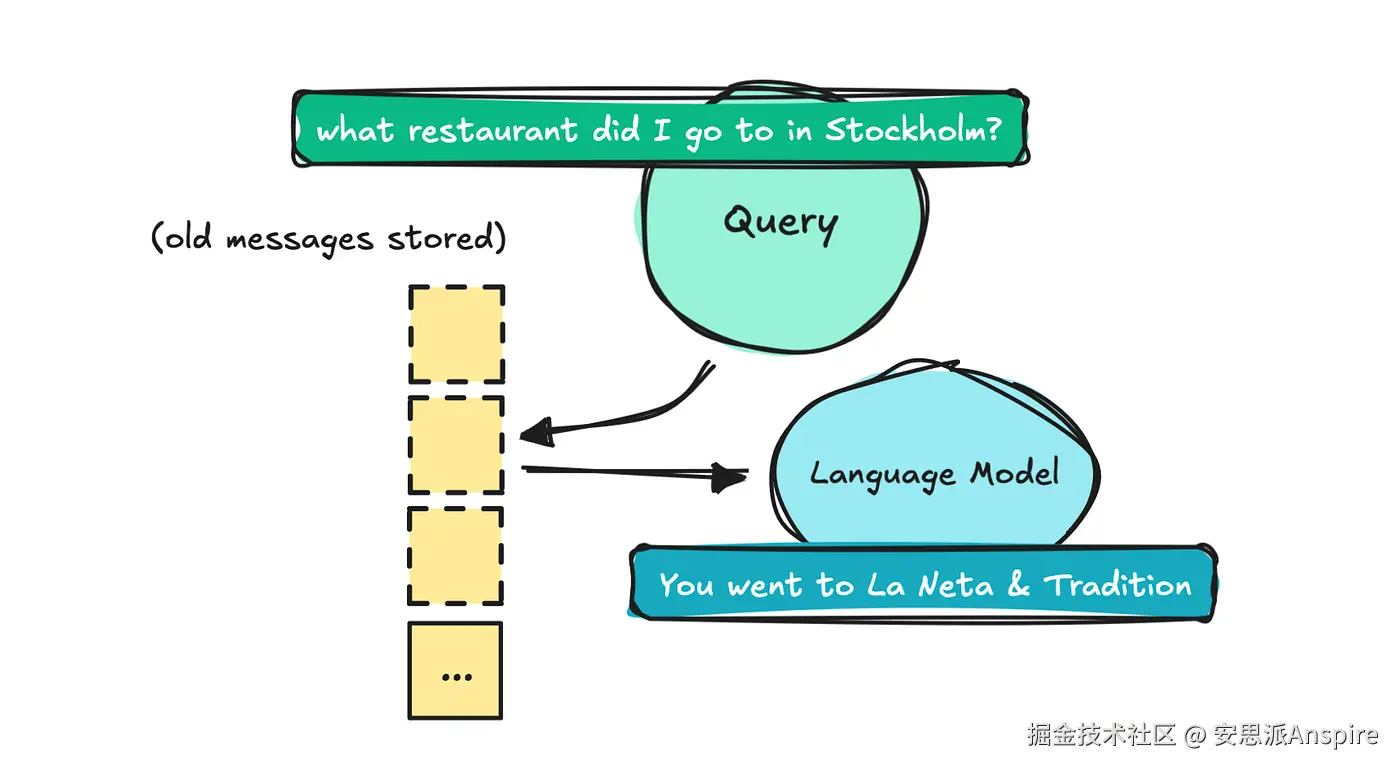
我们首先需要大语言模型(LLM)能够调出旧消息,告诉我们之前说了什么。这样我们就可以问它:"你之前推荐我去的斯德哥尔摩那家餐厅叫什么名字?"这属于基本信息提取。
如果你对构建大语言模型(LLM)系统完全陌生,你的第一反应可能是将整个对话直接塞进上下文窗口,然后让大语言模型去理解它。
然而,这种策略会让大语言模型难以分辨哪些重要、哪些不重要,这可能导致它生成虚构的答案。一旦这些对话的规模增大,你还得对其进行限制。
你的第二个想法可能是存储每一条消息及其摘要,并在查询到来时使用语义搜索(即RAG中的检索)来获取信息。
按回车键或点击以查看全尺寸图像
这与构建标准的朴素检索系统的方式类似。
这个问题在于,一旦它开始扩展(除了存储消息之外不做任何其他事情),你就会遇到内存膨胀、事实过时或相互矛盾,以及不断需要修剪的不断增长的向量数据库等问题。
你可能还需要了解事情发生的时间,这样你就可以问:"你什么时候告诉我的第一家餐厅的事?"这意味着你需要一定程度的时间推理能力。
这可能会促使你实施带有时间戳的更好的元数据,以及可能的自我编辑系统,该系统可以更新和总结输入内容。
虽然更复杂,但自我编辑系统可以更新事实,并在必要时使其失效。
如果你继续深入思考这个问题,你可能还希望大语言模型(LLM)能够关联不同的事实(进行多跳推理)并识别模式。
所以你可以向它提问,比如"我今年参加了多少场音乐会?"或"你认为基于此我的音乐品味如何?"这些问题可能会引导你尝试知识图谱。
组织解决方案
这个问题变得如此严重,促使人们更好地组织它。大多数团队似乎将长期记忆分为两部分:简短的事实 和之前对话的长期记忆。
按回车键或点击以查看全尺寸图像
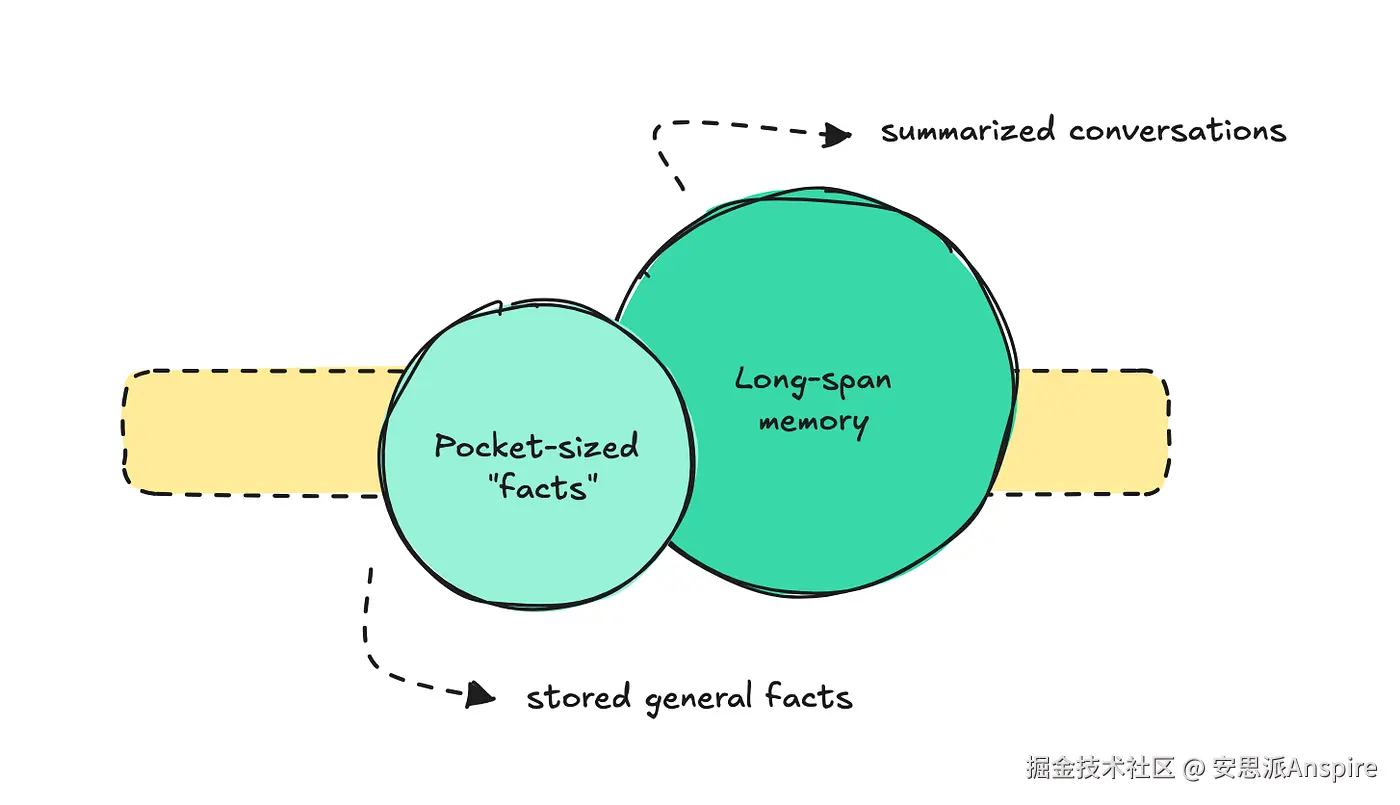
对于第一部分,即袖珍型事实,我们可以以ChatGPT的记忆系统为例。
为了构建这种类型的记忆,他们可能会使用分类器来判断一条消息是否包含应该存储的事实。
按回车键或点击以查看全尺寸图像
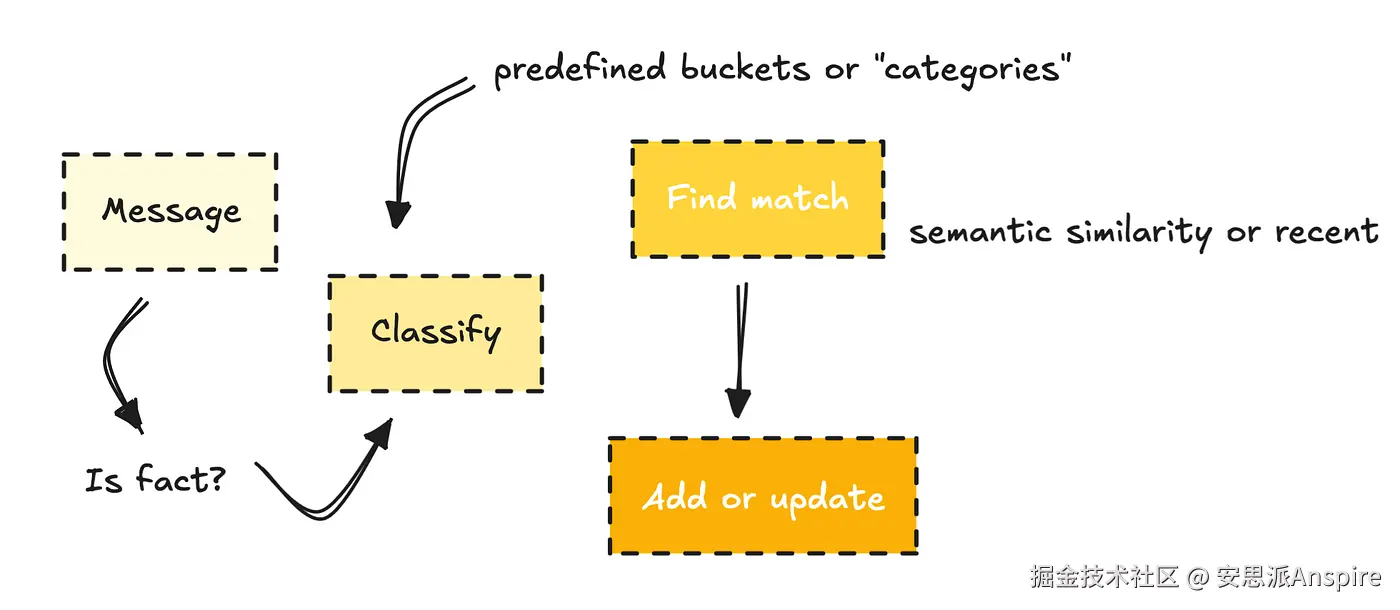
然后,它们将事实分类到预定义的类别(如个人资料、偏好或项目)中,如果与现有记忆相似,则更新现有记忆;如果不相似,则创建新的记忆。
另一部分,即长跨度记忆,指的是存储所有消息并总结整个对话,以便日后参考。ChatGPT中也有这一功能,但就像口袋大小的记忆一样,你必须手动启用它。
在这里,如果您自己构建这个,您需要决定保留多少细节,同时要注意内存膨胀和我们之前提到的不断增长的数据库。
标准建筑解决方案
如果我们看看其他人的做法,这里有两个主要的架构选择可供你考虑:向量和知识图谱。
我一开始采用了基于检索的方法。这通常是人们刚开始时会选择的方式。检索使用向量存储(通常还会结合稀疏搜索),这意味着它同时支持语义搜索和关键词搜索。
检索一开始很简单:你嵌入文档,然后根据用户问题进行提取。
但正如我们之前所讨论的,简单地这样做意味着每个输入都是不可变的。这意味着即使事实发生了变化,文本仍然会保留在那里。
这里可能出现的问题包括获取多个相互冲突的事实,这可能会让智能体感到困惑。最糟糕的是,相关事实可能被掩埋在大量检索到的文本之中。
智能体也不会知道某件事是何时说的,或者它指的是过去还是未来。
正如我们之前讨论的,有办法解决这个问题。
您可以搜索旧记忆并更新它们,为元数据添加时间戳,并定期总结对话,以帮助大语言模型(LLM)理解所获取细节的上下文。
但使用向量时,你还会面临数据库不断增长的问题。最终,你需要修剪旧数据或对其进行压缩,这可能会迫使你舍弃有用的细节。
如果我们来看知识图谱(KGs),它们将信息表示为实体(节点)及其之间关系(边)的网络,而不是像向量那样的非结构化文本。
按回车键或点击以查看全尺寸图像
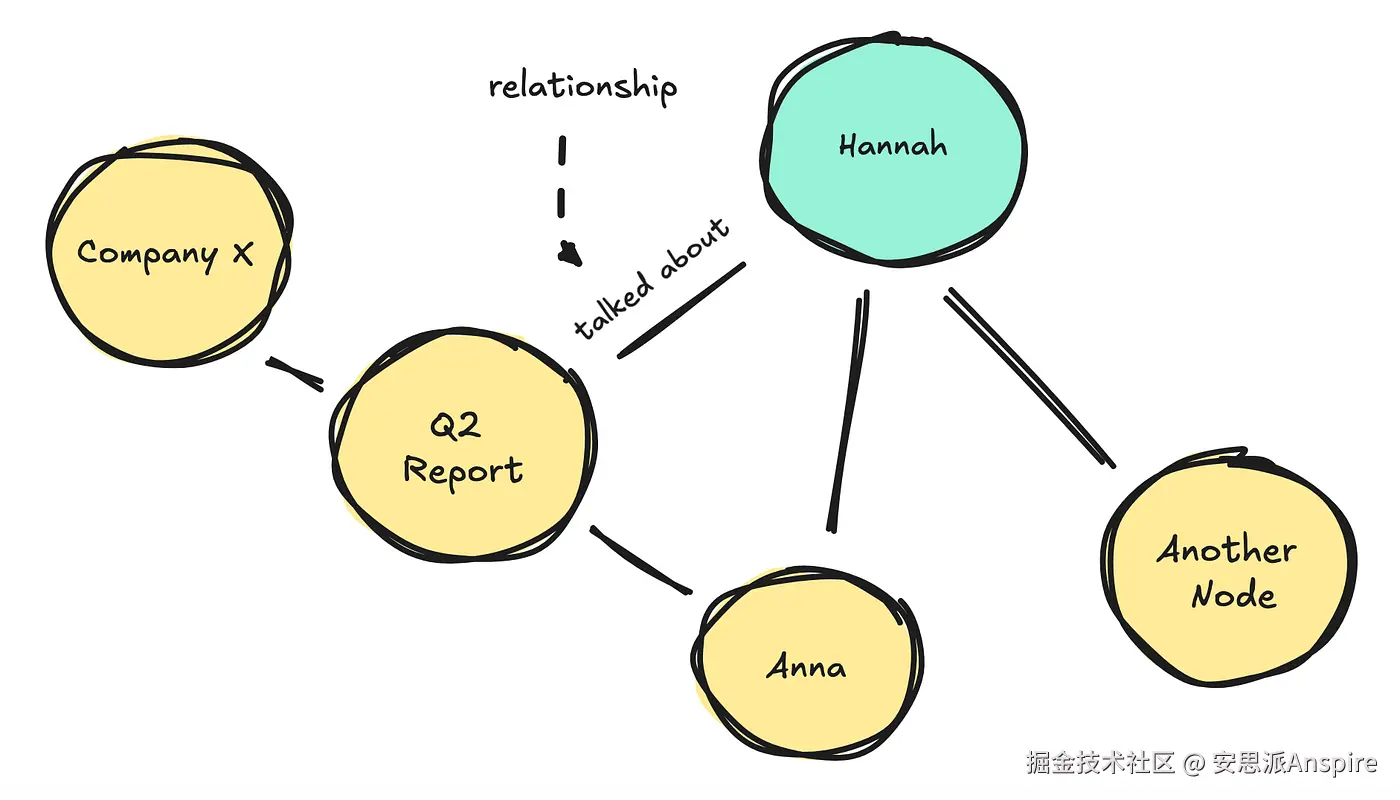
知识图谱(KGs)不会覆盖数据,而是可以为旧事实分配一个失效日期,这样你仍然可以追溯其历史。它们使用图遍历的方式来获取信息,这使你能够跨多个跳追踪关系。
但正如我们提到的,我们可以通过提取旧事实并更新它们,对向量做类似的事情。
但由于知识图谱(KGs)可以在相连的节点之间跳转,并以更结构化的方式更新事实,因此它们在多跳推理方面往往表现更优。
不过,知识图谱(KGs)确实也有其自身的挑战。随着它们的发展,基础设施变得更加复杂,当系统必须深入查找才能找到正确信息时,你可能会开始注意到深度遍历期间的延迟增加。
维护成本也可能相当高。
不过,总的来说,无论解决方案是基于向量还是基于知识图谱,人们通常会更新记忆,而不仅仅是不断添加新的记忆,同时还会增加设置特定存储桶的能力,就像我们在"袖珍型"事实中看到的那样。
他们还经常在处理消息之前使用大语言模型(LLMs)对消息进行总结和提取信息。
如果我们回到最初的目标(既有口袋大小的记忆又有长跨度的记忆),你可以将RAG和KG方法结合起来,以实现你想要的目标。
当前供应商解决方案(即插即用)
我将介绍几种不同的独立解决方案,这些方案可帮助你设置内存,同时探讨它们的工作原理、采用的架构以及框架的成熟度。
按回车键或点击以查看全尺寸图像
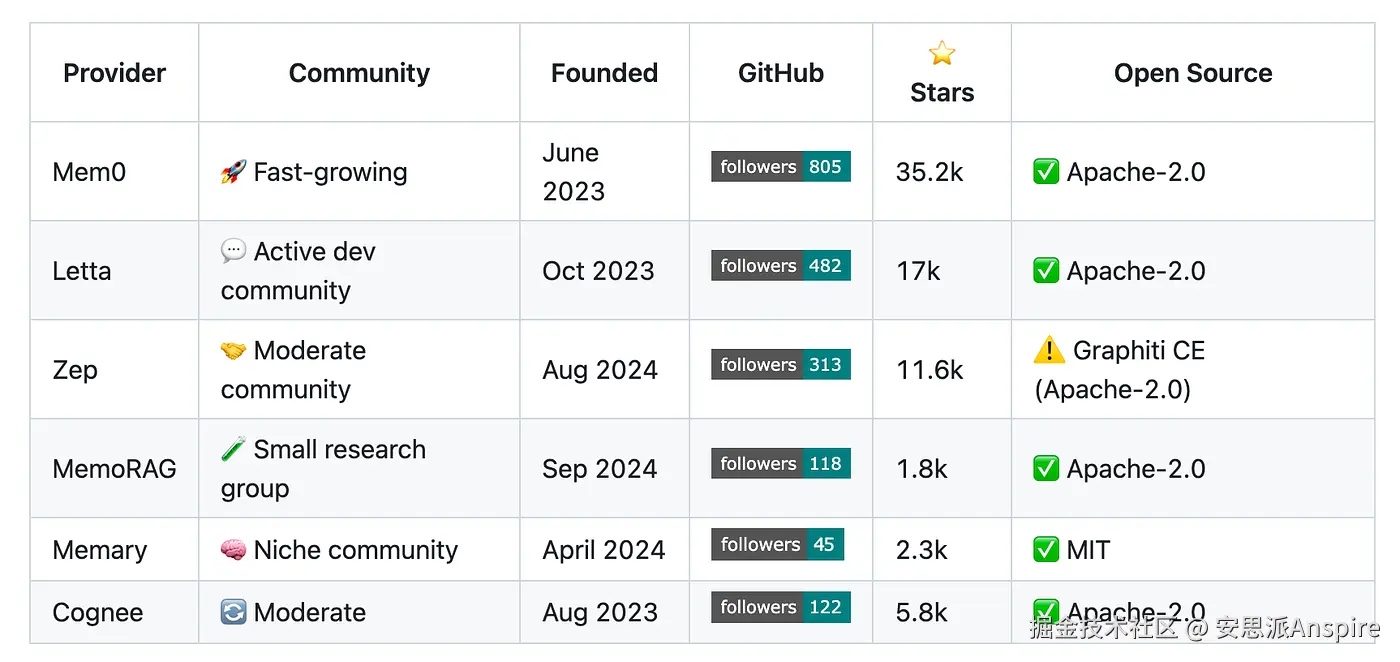
长期内存提供者 --- 我总是在这个存储库中收集资源 | 图片由作者提供
构建先进的大语言模型应用仍然非常新颖,因此这些解决方案大多是在过去一两年才发布的。
刚开始的时候,查看这些框架是如何构建的,有助于了解自己可能需要什么。
如前所述,它们大多属于知识图谱优先或向量优先类别。
按回车键或点击以查看全尺寸图像
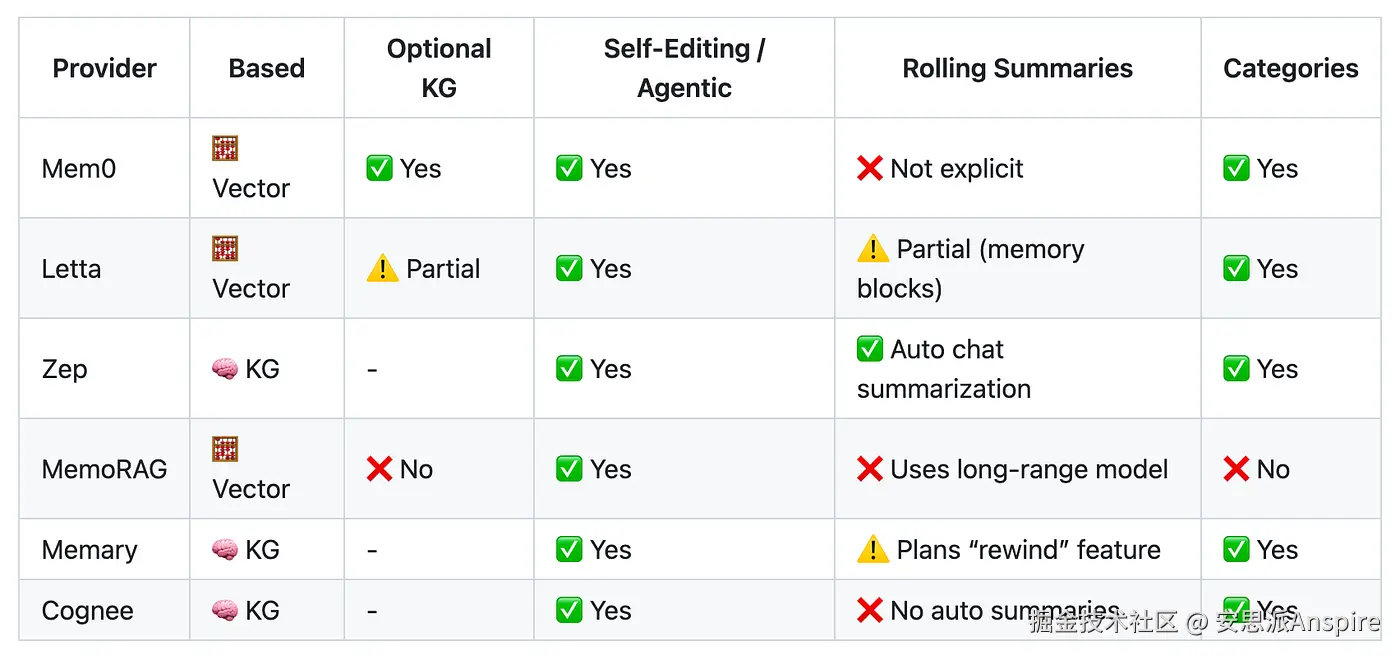
内存提供程序功能 --- 我总是在这个存储库中收集资源 | 图片由作者提供
如果我们先看基于知识图谱(KG)的解决方案Zep(或Graphiti),它们使用大语言模型(LLMs)来提取、添加、使无效和更新节点(实体)以及边(带时间戳的关系)。
按回车键或点击以查看全尺寸图像
当你提出一个问题时,它会执行语义和关键词搜索来查找相关节点,然后遍历到相连的节点以获取相关事实。
如果收到包含矛盾事实的新消息,它会在保留旧事实的同时更新节点。
这与基于向量的解决方案Mem0不同,Mem0将提取的事实相互叠加,并使用自我编辑系统来识别并完全覆盖无效事实。
Letta的工作方式类似,但还包含额外功能,如核心内存,它会存储对话摘要以及定义应填充内容的块(或类别)。
所有解决方案都具备设置类别的能力,我们可以在其中定义系统需要捕捉的内容。例如,如果您正在开发一款正念应用,其中一个类别可以是用户的"当前情绪"。这些就是我们之前在ChatGPT系统中看到的基于口袋的分类。
我之前提到过的一件事,就是以向量为先的方法在时间推理和多跳推理方面存在问题。
例如,如果我说我将在两个月后搬到柏林,但之前提到过住在斯德哥尔摩和加利福尼亚,那么几个月后我询问时,系统会理解我现在住在柏林吗?
它能识别模式吗?借助知识图谱,信息已经结构化,这使得大语言模型(LLM)更容易利用所有可用的上下文。
对于向量而言,随着信息的增加,噪声可能会变得过强,导致系统无法将各个点联系起来。
对于Letta和Mem0,虽然总体上更为成熟,但这两个问题仍可能出现。
对于知识图谱而言,人们关注的是其在扩展过程中的基础设施复杂性,以及如何管理不断增长的信息量。
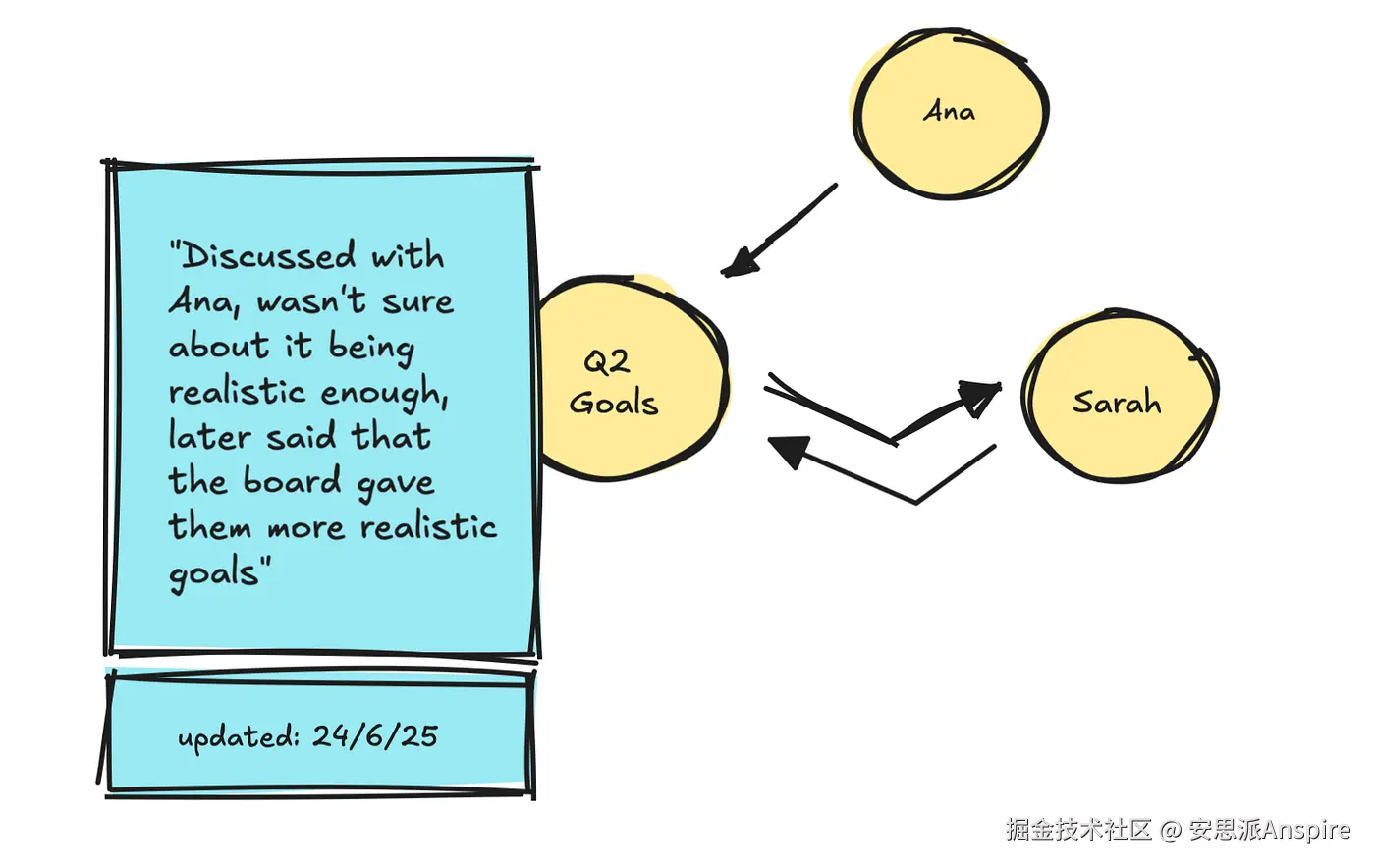
虽然我还没有对它们全部进行全面测试,而且仍有一些信息缺失(如延迟数据),但我想提及一下它们如何处理企业安全问题,以防你打算在公司内部使用这些产品。
按回车键或点击以查看全尺寸图像
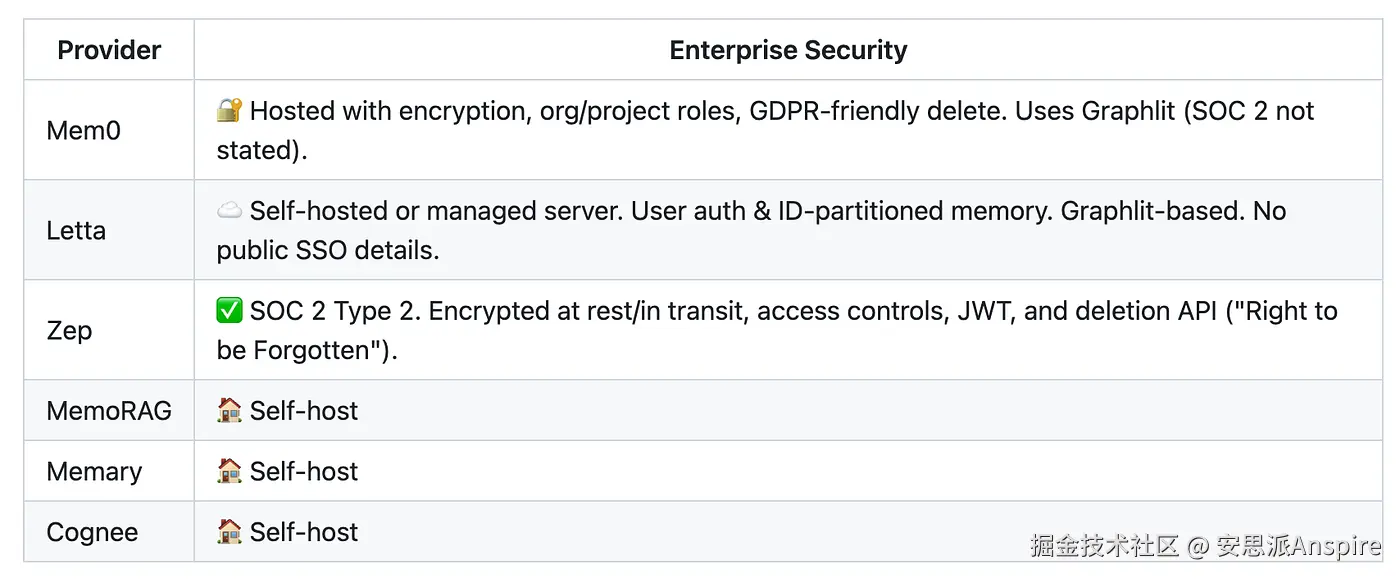
内存云安全------我总是在这个存储库中收集资源 | 图片由作者提供
我找到的唯一获得SOC 2 Type 2认证的云服务选项是Zep。不过,其中许多服务可以自行托管,在这种情况下,安全性取决于你自己的基础设施。
这些解决方案仍然非常新颖。你可能最终会自己构建,但我建议先测试一下,看看它们如何处理极端情况。
使用供应商的经济学
能够为你的大语言模型(LLM)应用程序添加功能固然很好,但你需要记住,这也会增加成本。
我在介绍技术实施时总会包含一个关于经济层面的章节,这次也不例外。在引入新内容时,这是我首先要查看的内容。我需要了解它在后续会如何影响应用的单位经济效益。
大多数供应商的解决方案都允许你免费开始使用。但一旦你发送的消息数量超过几千条,成本就会迅速增加。
按回车键或点击以查看全尺寸图像
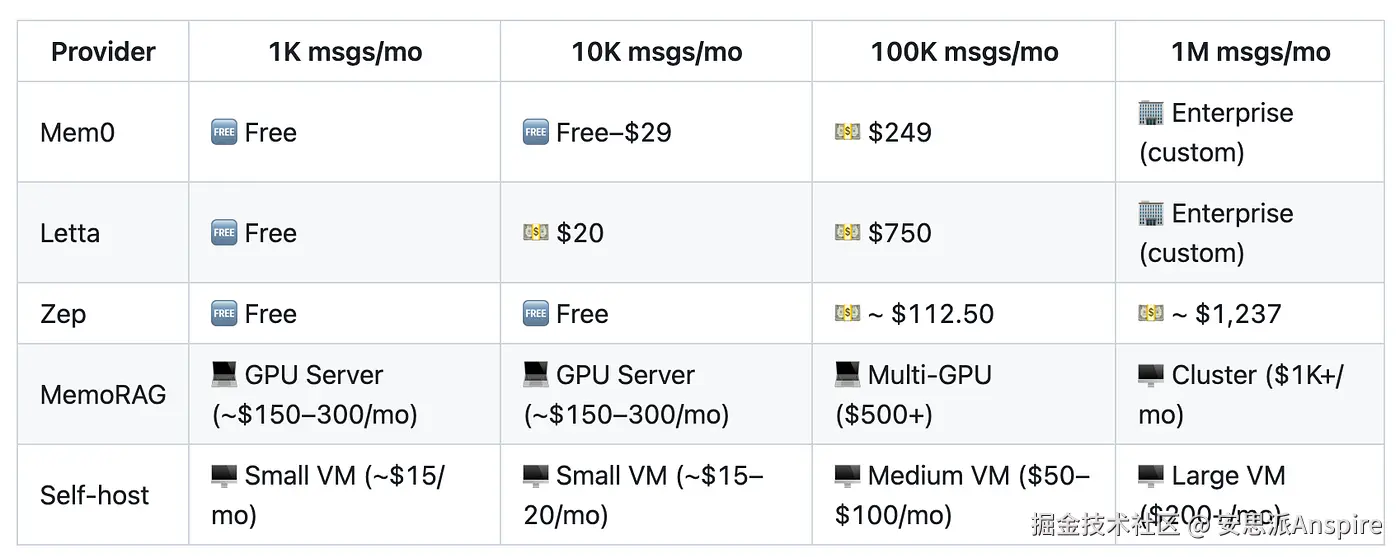
"估算"每条消息的内存定价 --- 我总是在这个存储库中收集资源 | 图片由作者提供
请记住,如果您所在的组织每天有几百次对话,那么当您通过这些云解决方案发送每一条消息时,费用就会开始累积。
从云解决方案起步可能是理想之选,然后随着业务发展再切换到自建托管。
你也可以尝试混合方法。
例如,实现自己的分类器来决定哪些消息值得作为事实存储,以降低成本,同时将其他所有内容推送到自己的向量存储中,以便定期进行压缩和总结。
话虽如此,在上下文窗口中使用简短的事实应该比粘贴一个5000个标记的历史片段更有效。提前向大语言模型(LLM)提供相关事实也有助于减少幻觉,并总体上降低大语言模型的生成成本。
注释
需要注意的是,即使有记忆系统,也不应期望达到完美。这些系统有时仍会产生幻觉或遗漏答案。
与其追求100%的准确性,不如带着接受不完美的心态去做,这样你就不会感到沮丧。
目前没有一个系统能达到完美的准确率,至少现在还没有。研究表明,幻觉是大语言模型(LLMs)固有的一部分。即使添加记忆层也无法完全消除这个问题。